 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Autoencoder-based cleaning in probabilistic databases
Jun 17, 2021
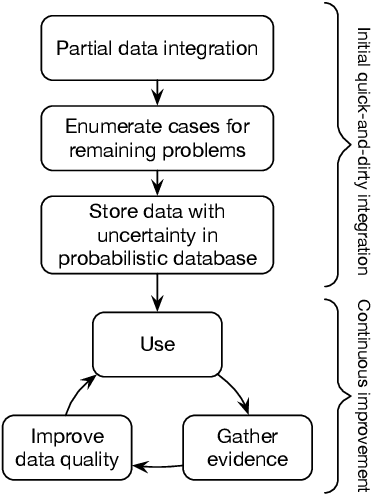
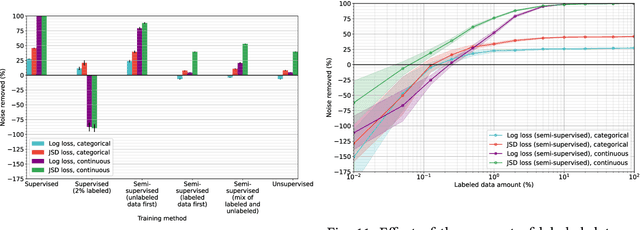
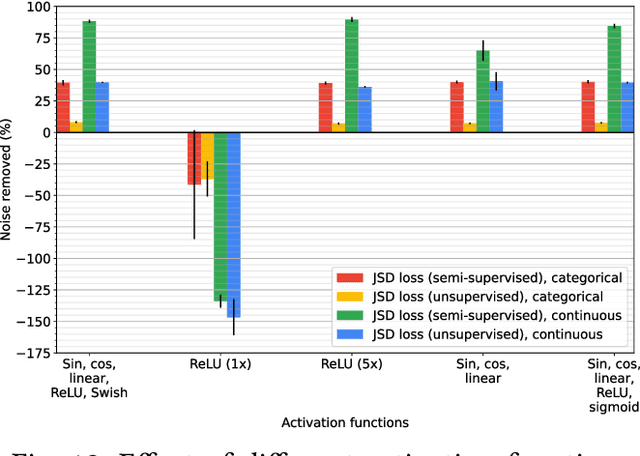
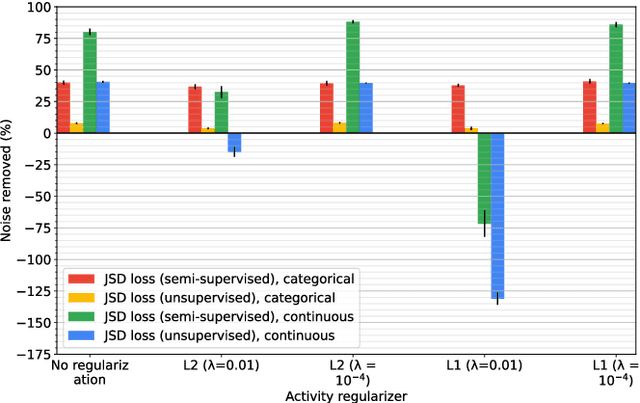
In the field of data integration, data quality problems are often encountered when extracting, combining, and merging data. The probabilistic data integration approach represents information about such problems as uncertainties in a probabilistic database. In this paper, we propose a data-cleaning autoencoder capable of near-automatic data quality improvement. It learns the structure and dependencies in the data to identify and correct doubtful values. A theoretical framework is provided, and experiments show that it can remove significant amounts of noise from categorical and numeric probabilistic data. Our method does not require clean data. We do, however, show that manually cleaning a small fraction of the data significantly improves performance.
Tri-Branch Convolutional Neural Networks for Top-$k$ Focused Academic Performance Prediction
Jul 22, 2021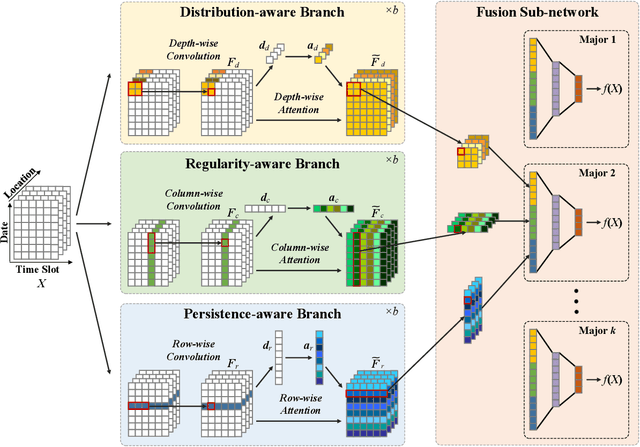
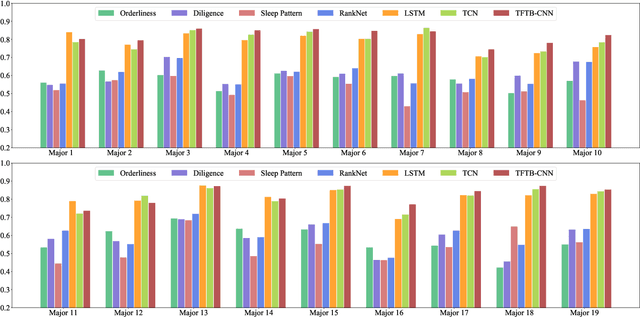
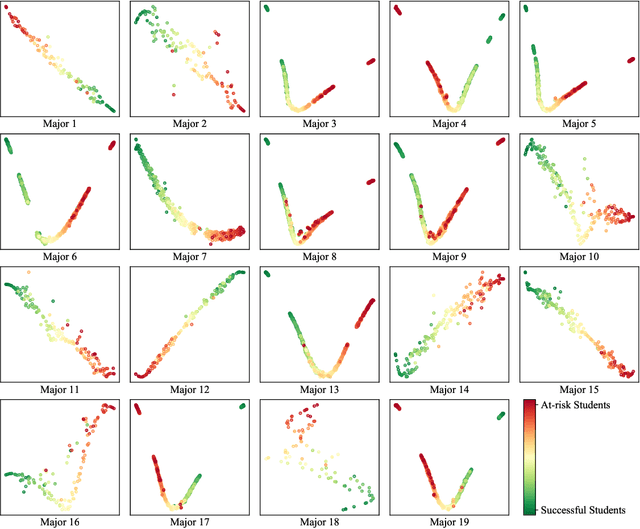

Academic performance prediction aims to leverage student-related information to predict their future academic outcomes, which is beneficial to numerous educational applications, such as personalized teaching and academic early warning. In this paper, we address the problem by analyzing students' daily behavior trajectories, which can be comprehensively tracked with campus smartcard records. Different from previous studies, we propose a novel Tri-Branch CNN architecture, which is equipped with row-wise, column-wise, and depth-wise convolution and attention operations, to capture the characteristics of persistence, regularity, and temporal distribution of student behavior in an end-to-end manner, respectively. Also, we cast academic performance prediction as a top-$k$ ranking problem, and introduce a top-$k$ focused loss to ensure the accuracy of identifying academically at-risk students. Extensive experiments were carried out on a large-scale real-world dataset, and we show that our approach substantially outperforms recently proposed methods for academic performance prediction. For the sake of reproducibility, our codes have been released at https://github.com/ZongJ1111/Academic-Performance-Prediction.
Inferring Missing Categorical Information in Noisy and Sparse Web Markup
Mar 01, 2018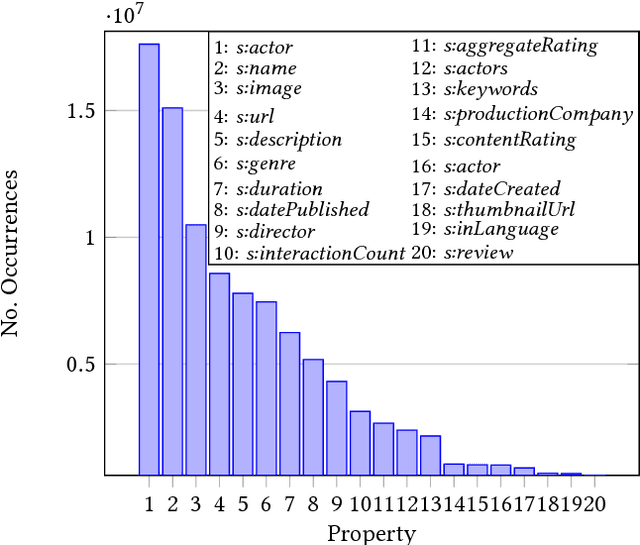

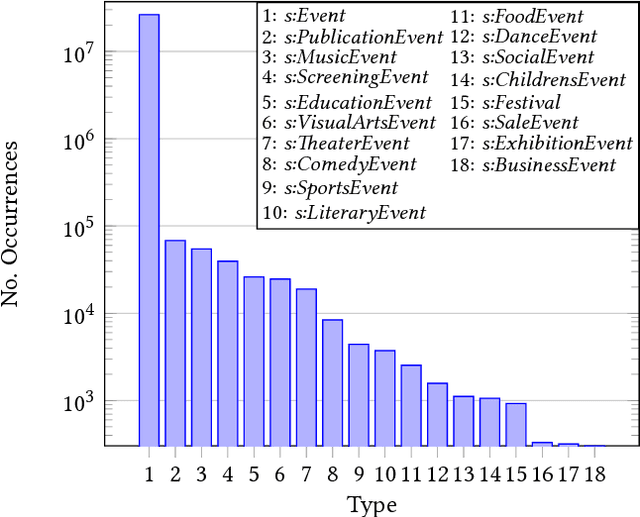
Embedded markup of Web pages has seen widespread adoption throughout the past years driven by standards such as RDFa and Microdata and initiatives such as schema.org, where recent studies show an adoption by 39% of all Web pages already in 2016. While this constitutes an important information source for tasks such as Web search, Web page classification or knowledge graph augmentation, individual markup nodes are usually sparsely described and often lack essential information. For instance, from 26 million nodes describing events within the Common Crawl in 2016, 59% of nodes provide less than six statements and only 257,000 nodes (0.96%) are typed with more specific event subtypes. Nevertheless, given the scale and diversity of Web markup data, nodes that provide missing information can be obtained from the Web in large quantities, in particular for categorical properties. Such data constitutes potential training data for inferring missing information to significantly augment sparsely described nodes. In this work, we introduce a supervised approach for inferring missing categorical properties in Web markup. Our experiments, conducted on properties of events and movies, show a performance of 79% and 83% F1 score correspondingly, significantly outperforming existing baselines.
Tensor networks and efficient descriptions of classical data
Mar 11, 2021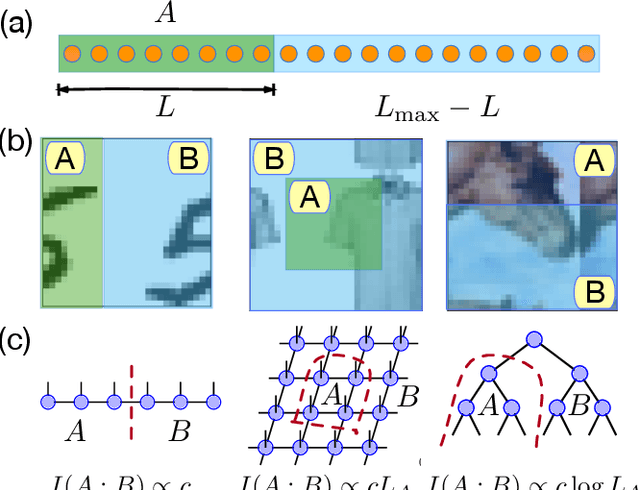
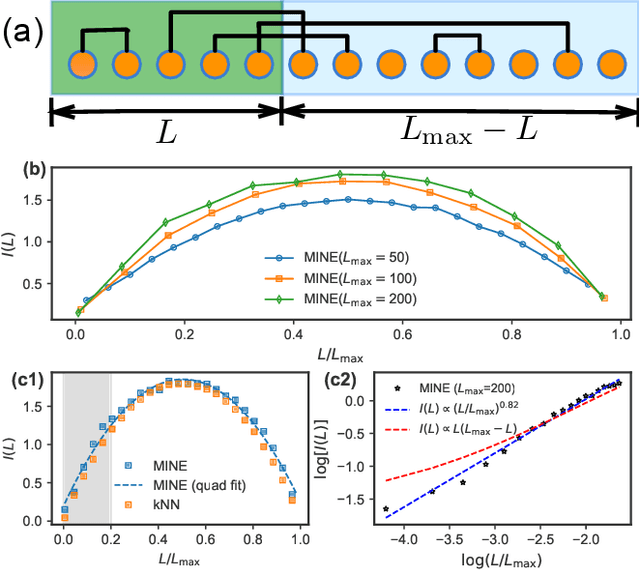
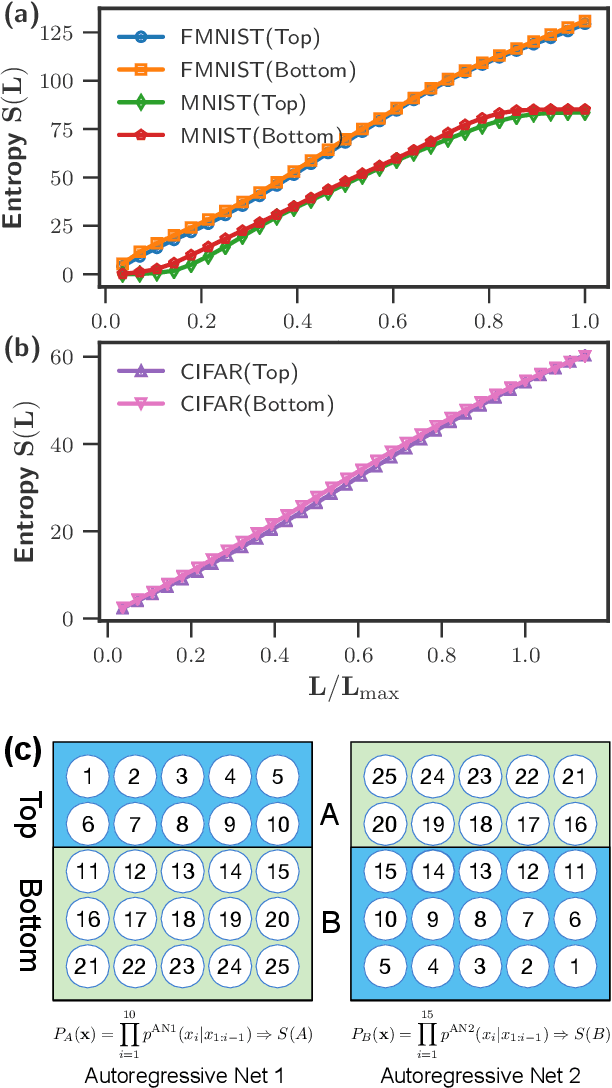
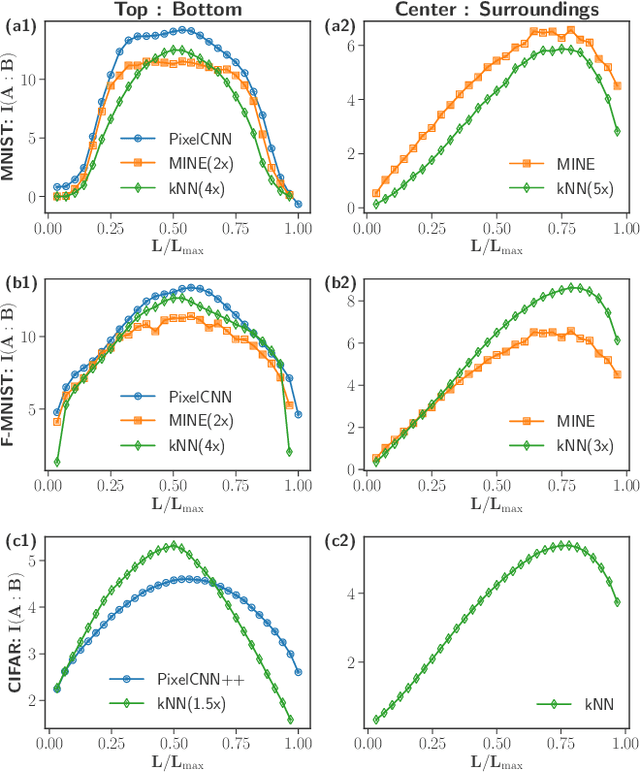
We investigate the potential of tensor network based machine learning methods to scale to large image and text data sets. For that, we study how the mutual information between a subregion and its complement scales with the subsystem size $L$, similarly to how it is done in quantum many-body physics. We find that for text, the mutual information scales as a power law $L^\nu$ with a close to volume law exponent, indicating that text cannot be efficiently described by 1D tensor networks. For images, the scaling is close to an area law, hinting at 2D tensor networks such as PEPS could have an adequate expressibility. For the numerical analysis, we introduce a mutual information estimator based on autoregressive networks, and we also use convolutional neural networks in a neural estimator method.
GasHis-Transformer: A Multi-scale Visual Transformer Approach for Gastric Histopathology Image Classification
Apr 29, 2021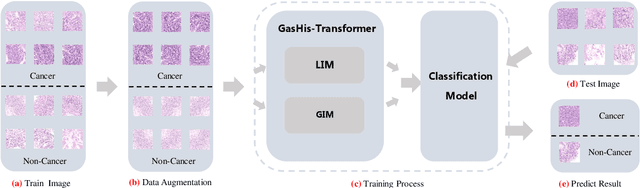

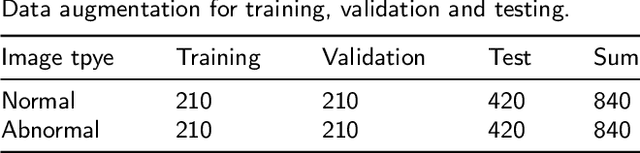
For deep learning methods applied to the diagnosis of gastric cancer intelligently, existing methods concentrate more on Convolutional Neural Networks (CNN) but no approaches are available using Visual Transformer (VT). VT's efficient and stable deep learning models with the most recent application in the field of computer vision, which is capable of improving the recognition of global information in images. In this paper, a multi-scale visual transformer model (GasHis-Transformer) is proposed for a gastric histopathology image classification (GHIC) task, which enables the automatic classification of gastric histological images of abnormal and normal cancer by obtained by optical microscopy to facilitate the medical work of histopathologists. This GasHis-Transformer model is built on two fundamental modules, including a global information module (GIM) and a local information module (LIM). In the experiment, an open source hematoxylin and eosin (H&E) stained gastric histopathology dataset with 280 abnormal or normal images are divided into training, validation, and test sets at a ratio of 1:1:2 first. Then, GasHis-Transformer obtains precision, recall, F1-score, and accuracy on the testing set of 98.0%, 100.0%, 96.0%, and 98.0%. Furthermore, a contrast experiment also tests the generalization ability of the proposed GatHis-Transformer model with a lymphoma image dataset including 374 images and a breast cancer dataset including 1390 images in two extended experiments and achieves an accuracy of 83.9% and 89.4%, respectively. Finally, GasHis-Transformer model demonstrates high classification performance and shows its effectiveness and enormous potential in GHIC tasks.
Contextualized Knowledge-aware Attentive Neural Network: Enhancing Answer Selection with Knowledge
Apr 12, 2021
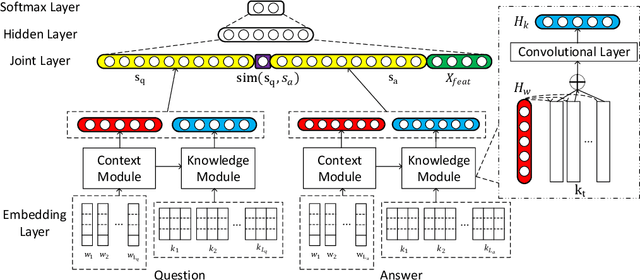
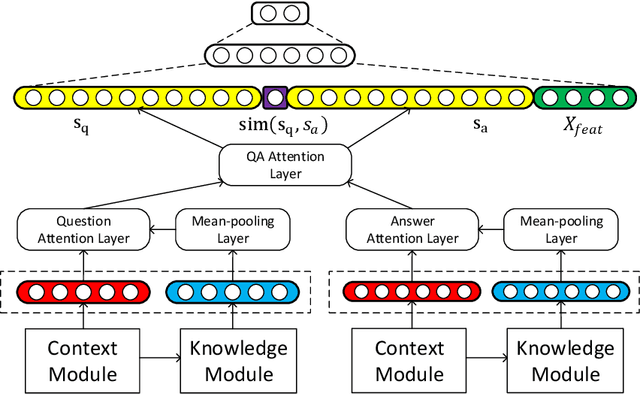
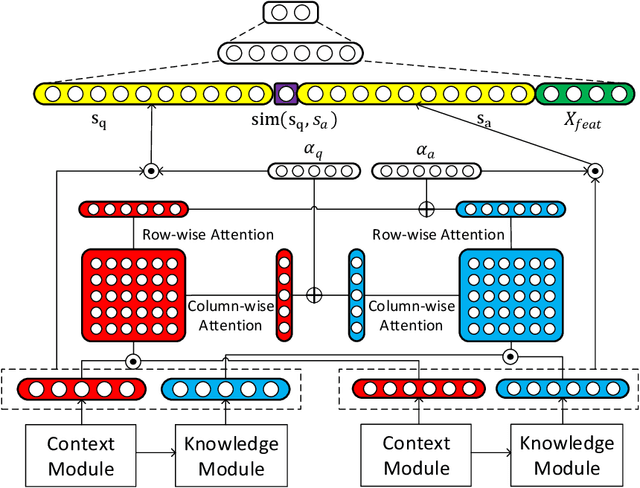
Answer selection, which is involved in many natural language processing applications such as dialog systems and question answering (QA), is an important yet challenging task in practice, since conventional methods typically suffer from the issues of ignoring diverse real-world background knowledge. In this paper, we extensively investigate approaches to enhancing the answer selection model with external knowledge from knowledge graph (KG). First, we present a context-knowledge interaction learning framework, Knowledge-aware Neural Network (KNN), which learns the QA sentence representations by considering a tight interaction with the external knowledge from KG and the textual information. Then, we develop two kinds of knowledge-aware attention mechanism to summarize both the context-based and knowledge-based interactions between questions and answers. To handle the diversity and complexity of KG information, we further propose a Contextualized Knowledge-aware Attentive Neural Network (CKANN), which improves the knowledge representation learning with structure information via a customized Graph Convolutional Network (GCN) and comprehensively learns context-based and knowledge-based sentence representation via the multi-view knowledge-aware attention mechanism. We evaluate our method on four widely-used benchmark QA datasets, including WikiQA, TREC QA, InsuranceQA and Yahoo QA. Results verify the benefits of incorporating external knowledge from KG, and show the robust superiority and extensive applicability of our method.
Optimal Transport for Unsupervised Restoration Learning
Aug 04, 2021
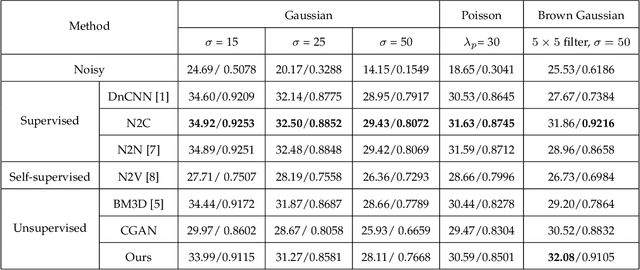
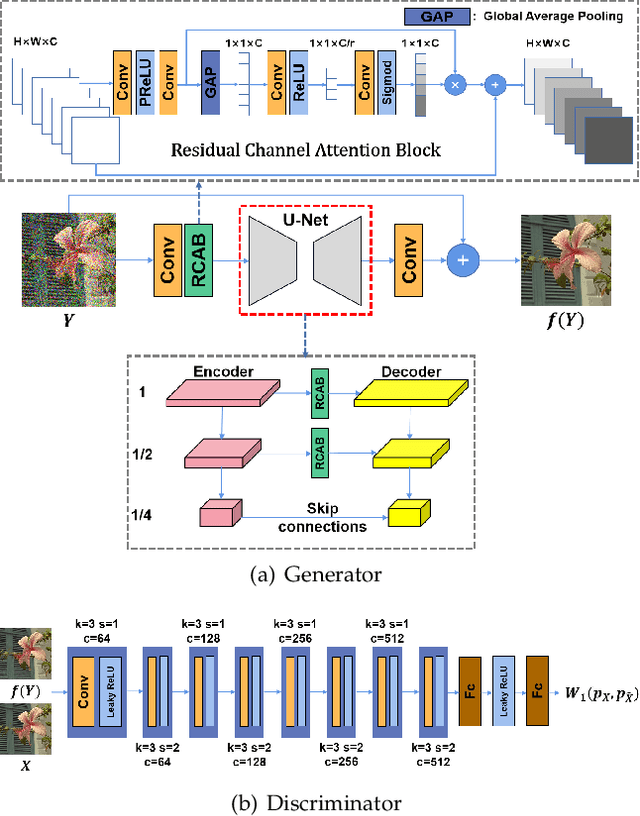

Recently, much progress has been made in unsupervised restoration learning. However, existing methods more or less rely on some assumptions on the signal and/or degradation model, which limits their practical performance. How to construct an optimal criterion for unsupervised restoration learning without any prior knowledge on the degradation model is still an open question. Toward answering this question, this work proposes a criterion for unsupervised restoration learning based on the optimal transport theory. This criterion has favorable properties, e.g., approximately maximal preservation of the information of the signal, whilst achieving perceptual reconstruction. Furthermore, though a relaxed unconstrained formulation is used in practical implementation, we show that the relaxed formulation in theory has the same solution as the original constrained formulation. Experiments on synthetic and real-world data, including realistic photographic, microscopy, depth, and raw depth images, demonstrate that the proposed method even compares favorably with supervised methods, e.g., approaching the PSNR of supervised methods while having better perceptual quality. Particularly, for spatially correlated noise and realistic microscopy images, the proposed method not only achieves better perceptual quality but also has higher PSNR than supervised methods. Besides, it shows remarkable superiority in harsh practical conditions with complex noise, e.g., raw depth images.
Non-local Patch-based Low-rank Tensor Ring Completion for Visual Data
May 30, 2021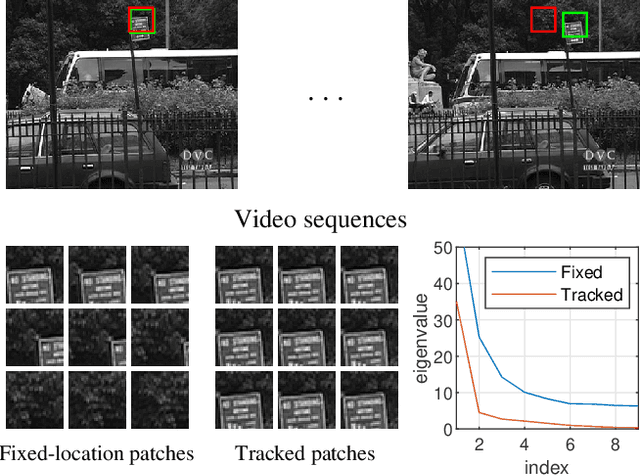
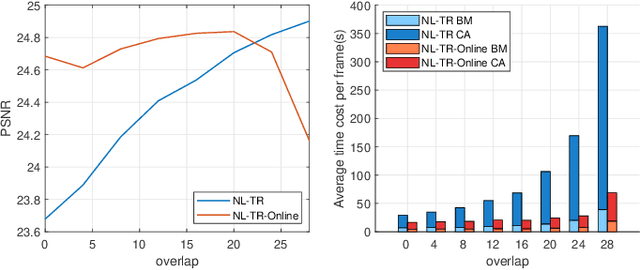
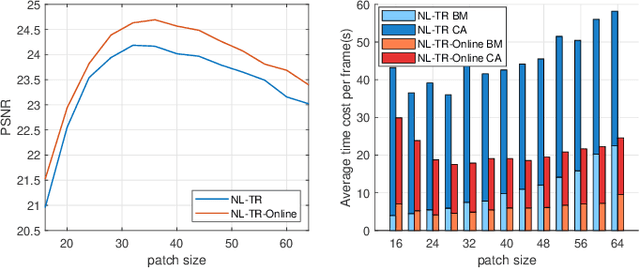
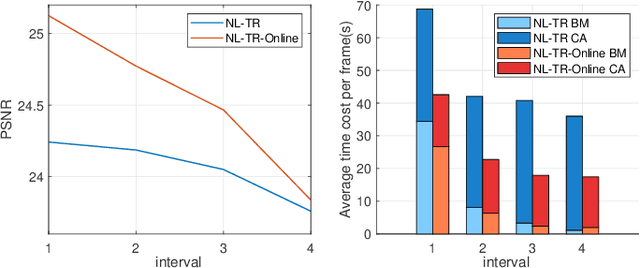
Tensor completion is the problem of estimating the missing entries of a partially observed tensor with a certain low-rank structure. It improves on matrix completion for image and video data by capturing additional structural information intrinsic to such data. % With more inherent information involving in tensor structure than matrix, tensor completion has shown better performance compared with matrix completion especially in image and video data. Traditional completion algorithms treat the entire visual data as a tensor, which may not always work well especially when camera or object motion exists. In this paper, we develop a novel non-local patch-based tensor ring completion algorithm. In the proposed approach, similar patches are extracted for each reference patch along both the spatial and temporal domains of the visual data. The collected patches are then formed into a high-order tensor and a tensor ring completion algorithm is proposed to recover the completed tensor. A novel interval sampling-based block matching (ISBM) strategy and a hybrid completion strategy are also proposed to improve efficiency and accuracy. Further, we develop an online patch-based completion algorithm to deal with streaming video data. An efficient online tensor ring completion algorithm is proposed to reduce the time cost. Extensive experimental results demonstrate the superior performance of the proposed algorithms compared with state-of-the-art methods.
Spatio-Temporal Representation Factorization for Video-based Person Re-Identification
Aug 15, 2021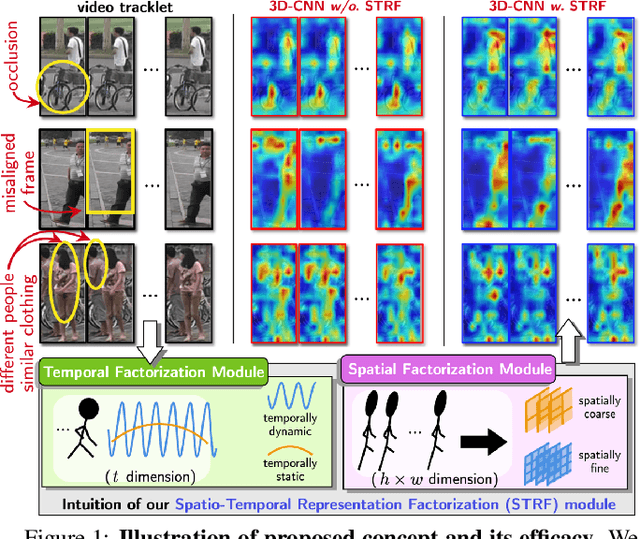

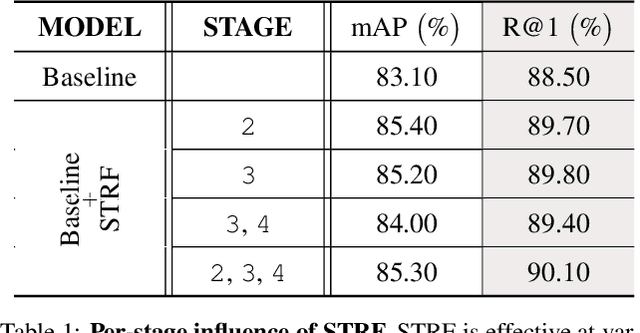
Despite much recent progress in video-based person re-identification (re-ID), the current state-of-the-art still suffers from common real-world challenges such as appearance similarity among various people, occlusions, and frame misalignment. To alleviate these problems, we propose Spatio-Temporal Representation Factorization (STRF), a flexible new computational unit that can be used in conjunction with most existing 3D convolutional neural network architectures for re-ID. The key innovations of STRF over prior work include explicit pathways for learning discriminative temporal and spatial features, with each component further factorized to capture complementary person-specific appearance and motion information. Specifically, temporal factorization comprises two branches, one each for static features (e.g., the color of clothes) that do not change much over time, and dynamic features (e.g., walking patterns) that change over time. Further, spatial factorization also comprises two branches to learn both global (coarse segments) as well as local (finer segments) appearance features, with the local features particularly useful in cases of occlusion or spatial misalignment. These two factorization operations taken together result in a modular architecture for our parameter-wise light STRF unit that can be plugged in between any two 3D convolutional layers, resulting in an end-to-end learning framework. We empirically show that STRF improves performance of various existing baseline architectures while demonstrating new state-of-the-art results using standard person re-ID evaluation protocols on three benchmarks.
Target-dependent UNITER: A Transformer-Based Multimodal Language Comprehension Model for Domestic Service Robots
Jul 02, 2021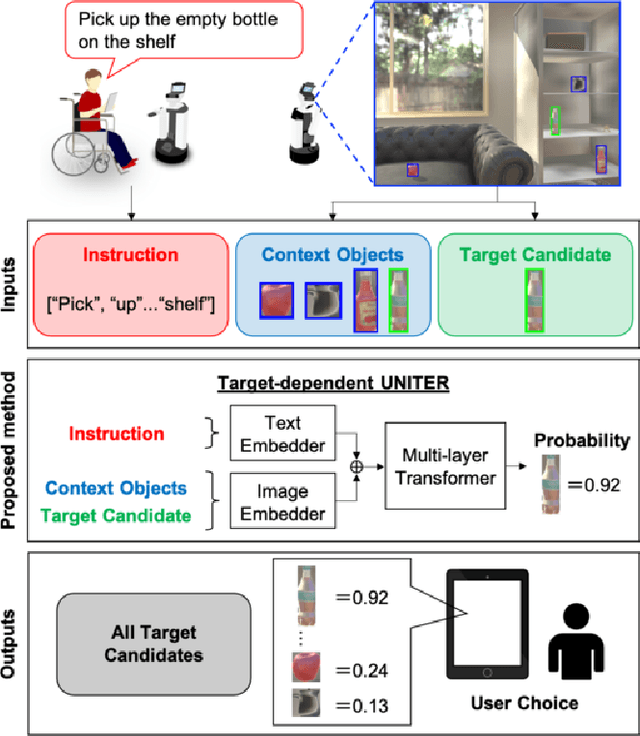

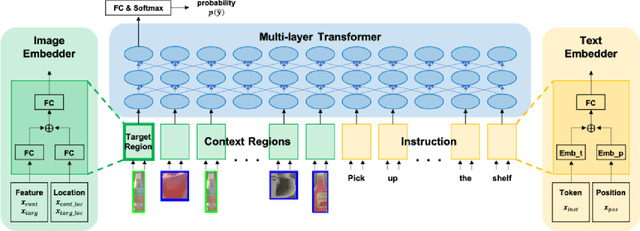
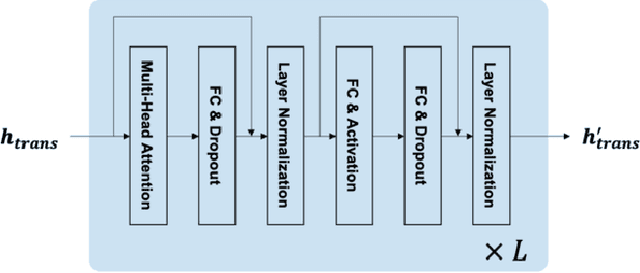
Currently, domestic service robots have an insufficient ability to interact naturally through language. This is because understanding human instructions is complicated by various ambiguities and missing information. In existing methods, the referring expressions that specify the relationships between objects are insufficiently modeled. In this paper, we propose Target-dependent UNITER, which learns the relationship between the target object and other objects directly by focusing on the relevant regions within an image, rather than the whole image. Our method is an extension of the UNITER-based Transformer that can be pretrained on general-purpose datasets. We extend the UNITER approach by introducing a new architecture for handling the target candidates. Our model is validated on two standard datasets, and the results show that Target-dependent UNITER outperforms the baseline method in terms of classification accuracy.