 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Understanding the merging behavior patterns and evolutionary mechanism at freeway on-ramps
Jul 31, 2021
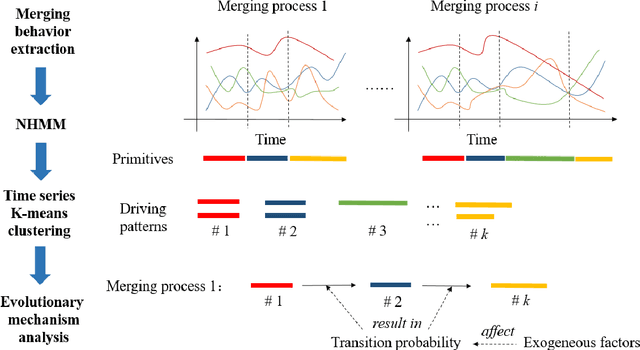
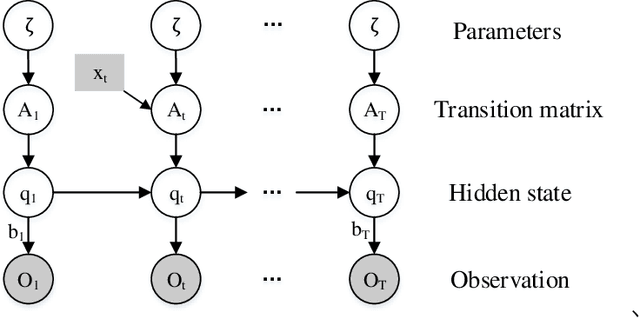


Understanding the merging behavior patterns at freeway on-ramps is important for assistanting the decisions of autonomous driving. This study develops a primitive-based framework to identify the driving patterns during merging processes and reveal the evolutionary mechanism at freeway on-ramps in congested traffic flow. The Nonhomogeneous Hidden Markov Model is introduced to decompose the merging processes into primitives containing semantic information. Then, the time-series K-means clustering is utilized to gather these primitives with variable-length time series into interpretable merging behavior patterns. Different from traditional state segmentation methods (e.g. Hidden Markov Model), the model proposed in this study considers the dependence of transition probability on exogenous variables, thereby revealing the influence of covariates on the evolution of driving patterns. This approach is evaluated in the merging area at a freeway on-ramp using the INTERACTION dataset. Results demonstrate that the approach provides an insight about the complicated merging processes. The findings about interpretable merging behavior patterns as well as the evolutionary mechanism can be used to design and improve the merging decision-making for autonomous vehicles.
Progressive Coordinate Transforms for Monocular 3D Object Detection
Aug 13, 2021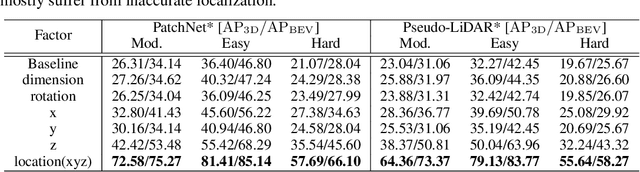

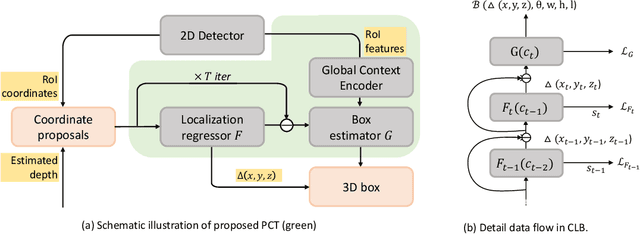
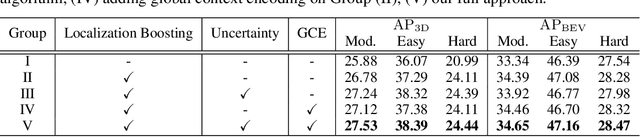
Recognizing and localizing objects in the 3D space is a crucial ability for an AI agent to perceive its surrounding environment. While significant progress has been achieved with expensive LiDAR point clouds, it poses a great challenge for 3D object detection given only a monocular image. While there exist different alternatives for tackling this problem, it is found that they are either equipped with heavy networks to fuse RGB and depth information or empirically ineffective to process millions of pseudo-LiDAR points. With in-depth examination, we realize that these limitations are rooted in inaccurate object localization. In this paper, we propose a novel and lightweight approach, dubbed {\em Progressive Coordinate Transforms} (PCT) to facilitate learning coordinate representations. Specifically, a localization boosting mechanism with confidence-aware loss is introduced to progressively refine the localization prediction. In addition, semantic image representation is also exploited to compensate for the usage of patch proposals. Despite being lightweight and simple, our strategy leads to superior improvements on the KITTI and Waymo Open Dataset monocular 3D detection benchmarks. At the same time, our proposed PCT shows great generalization to most coordinate-based 3D detection frameworks. The code is available at: https://github.com/amazon-research/progressive-coordinate-transforms .
Learning The Sequential Temporal Information with Recurrent Neural Networks
Jul 08, 2018
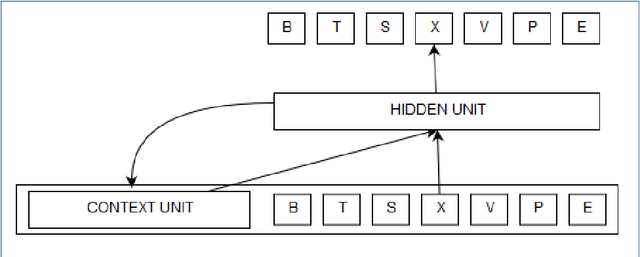
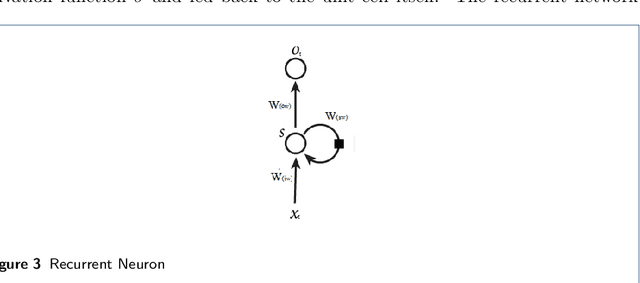
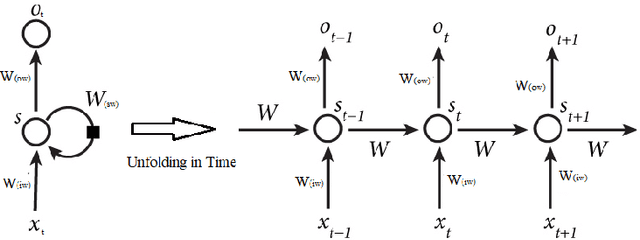
Recurrent Networks are one of the most powerful and promising artificial neural network algorithms to processing the sequential data such as natural languages, sound, time series data. Unlike traditional feed-forward network, Recurrent Network has a inherent feed back loop that allows to store the temporal context information and pass the state of information to the entire sequences of the events. This helps to achieve the state of art performance in many important tasks such as language modeling, stock market prediction, image captioning, speech recognition, machine translation and object tracking etc., However, training the fully connected RNN and managing the gradient flow are the complicated process. Many studies are carried out to address the mentioned limitation. This article is intent to provide the brief details about recurrent neurons, its variances and trips & tricks to train the fully recurrent neural network. This review work is carried out as a part of our IPO studio software module 'Multiple Object Tracking'.
Ranking Clarifying Questions Based on Predicted User Engagement
Apr 01, 2021
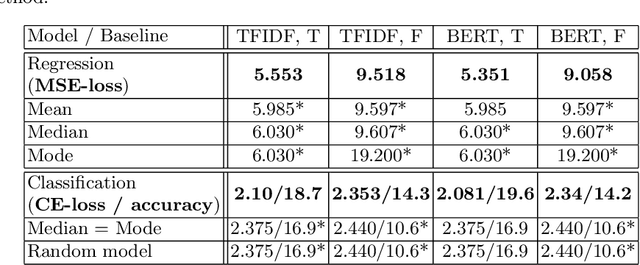
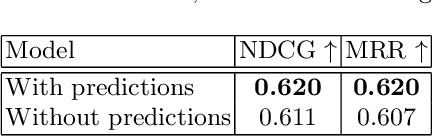
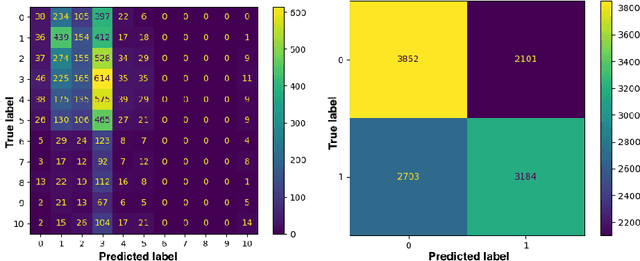
To improve online search results, clarification questions can be used to elucidate the information need of the user. This research aims to predict the user engagement with the clarification pane as an indicator of relevance based on the lexical information: query, question, and answers. Subsequently, the predicted user engagement can be used as a feature to rank the clarification panes. Regression and classification are applied for predicting user engagement and compared to naive heuristic baselines (e.g. mean) on the new MIMICS dataset [20]. An ablation study is carried out using a RankNet model to determine whether the predicted user engagement improves clarification pane ranking performance. The prediction models were able to improve significantly upon the naive baselines, and the predicted user engagement feature significantly improved the RankNet results in terms of NDCG and MRR. This research demonstrates the potential for ranking clarification panes based on lexical information only and can serve as a first neural baseline for future research to improve on. The code is available online.
Variational Co-embedding Learning for Attributed Network Clustering
Apr 15, 2021
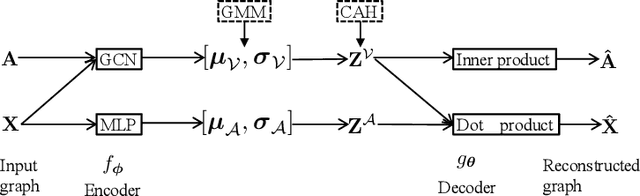
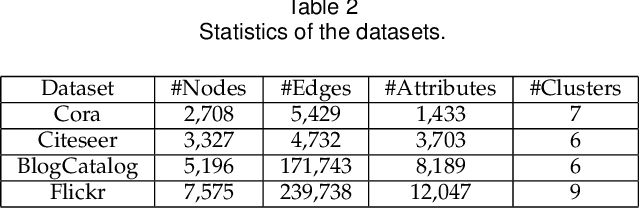
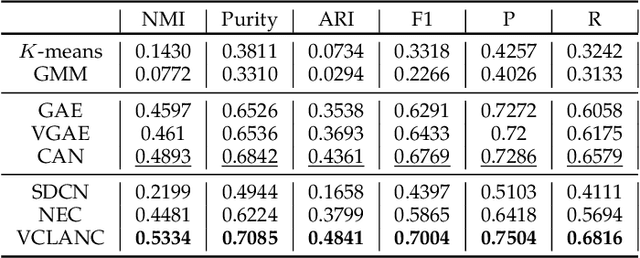
Recent works for attributed network clustering utilize graph convolution to obtain node embeddings and simultaneously perform clustering assignments on the embedding space. It is effective since graph convolution combines the structural and attributive information for node embedding learning. However, a major limitation of such works is that the graph convolution only incorporates the attribute information from the local neighborhood of nodes but fails to exploit the mutual affinities between nodes and attributes. In this regard, we propose a variational co-embedding learning model for attributed network clustering (VCLANC). VCLANC is composed of dual variational auto-encoders to simultaneously embed nodes and attributes. Relying on this, the mutual affinity information between nodes and attributes could be reconstructed from the embedding space and served as extra self-supervised knowledge for representation learning. At the same time, trainable Gaussian mixture model is used as priors to infer the node clustering assignments. To strengthen the performance of the inferred clusters, we use a mutual distance loss on the centers of the Gaussian priors and a clustering assignment hardening loss on the node embeddings. Experimental results on four real-world attributed network datasets demonstrate the effectiveness of the proposed VCLANC for attributed network clustering.
Point-Voxel Transformer: An Efficient Approach To 3D Deep Learning
Aug 13, 2021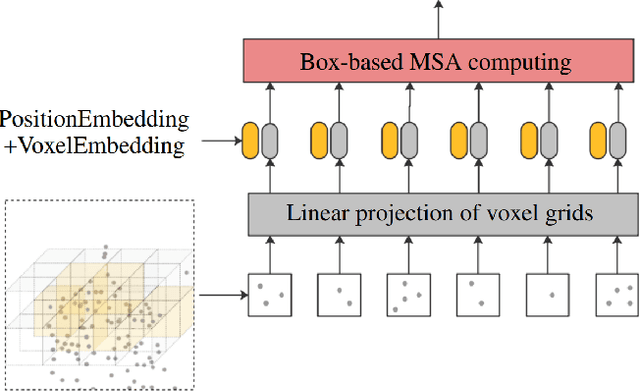
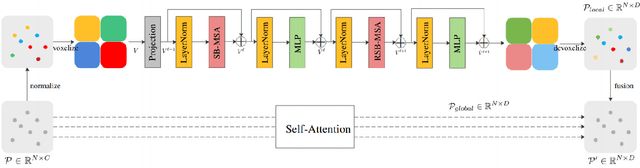
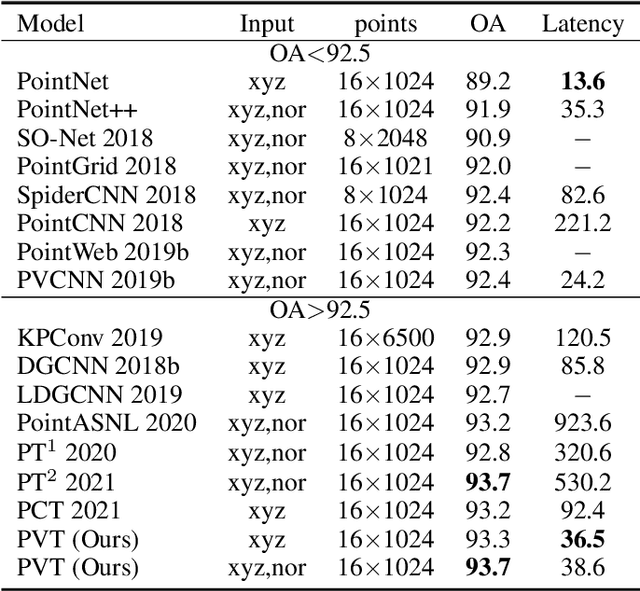
Due to the sparsity and irregularity of the 3D data, approaches that directly process points have become popular. Among all point-based models, Transformer-based models have achieved state-of-the-art performance by fully preserving point interrelation. However, most of them spend high percentage of total time on sparse data accessing (e.g., Farthest Point Sampling (FPS) and neighbor points query), which becomes the computation burden. Therefore, we present a novel 3D Transformer, called Point-Voxel Transformer (PVT) that leverages self-attention computation in points to gather global context features, while performing multi-head self-attention (MSA) computation in voxels to capture local information and reduce the irregular data access. Additionally, to further reduce the cost of MSA computation, we design a cyclic shifted boxing scheme which brings greater efficiency by limiting the MSA computation to non-overlapping local boxes while also preserving cross-box connection. Our method fully exploits the potentials of Transformer architecture, paving the road to efficient and accurate recognition results. Evaluated on classification and segmentation benchmarks, our PVT not only achieves strong accuracy but outperforms previous state-of-the-art Transformer-based models with 9x measured speedup on average. For 3D object detection task, we replace the primitives in Frustrum PointNet with PVT layer and achieve the improvement of 8.6%.
Separation of Powers in Federated Learning
May 19, 2021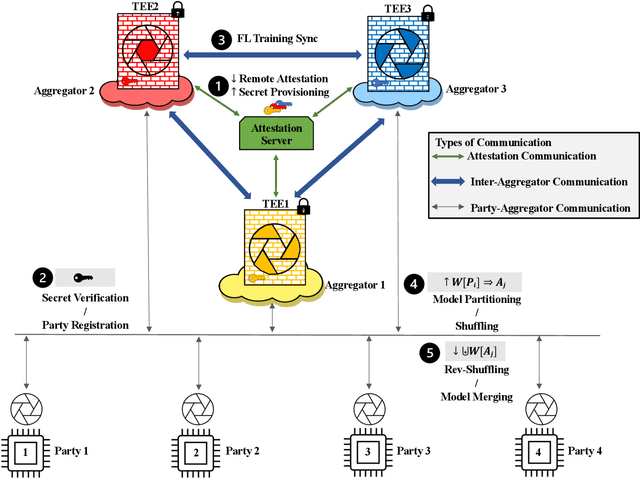
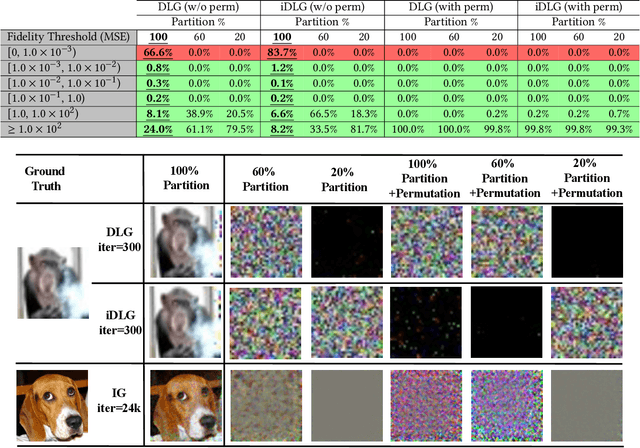
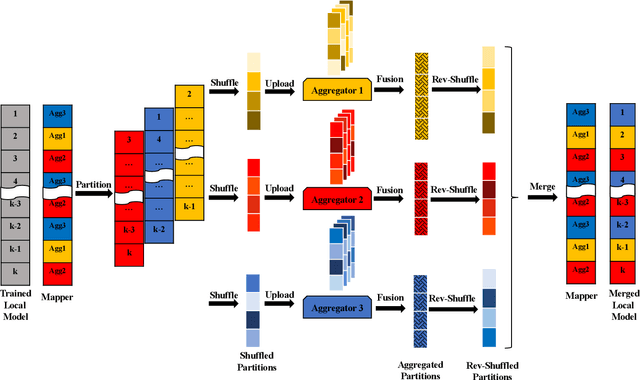

Federated Learning (FL) enables collaborative training among mutually distrusting parties. Model updates, rather than training data, are concentrated and fused in a central aggregation server. A key security challenge in FL is that an untrustworthy or compromised aggregation process might lead to unforeseeable information leakage. This challenge is especially acute due to recently demonstrated attacks that have reconstructed large fractions of training data from ostensibly "sanitized" model updates. In this paper, we introduce TRUDA, a new cross-silo FL system, employing a trustworthy and decentralized aggregation architecture to break down information concentration with regard to a single aggregator. Based on the unique computational properties of model-fusion algorithms, all exchanged model updates in TRUDA are disassembled at the parameter-granularity and re-stitched to random partitions designated for multiple TEE-protected aggregators. Thus, each aggregator only has a fragmentary and shuffled view of model updates and is oblivious to the model architecture. Our new security mechanisms can fundamentally mitigate training reconstruction attacks, while still preserving the final accuracy of trained models and keeping performance overheads low.
GP-S3Net: Graph-based Panoptic Sparse Semantic Segmentation Network
Aug 18, 2021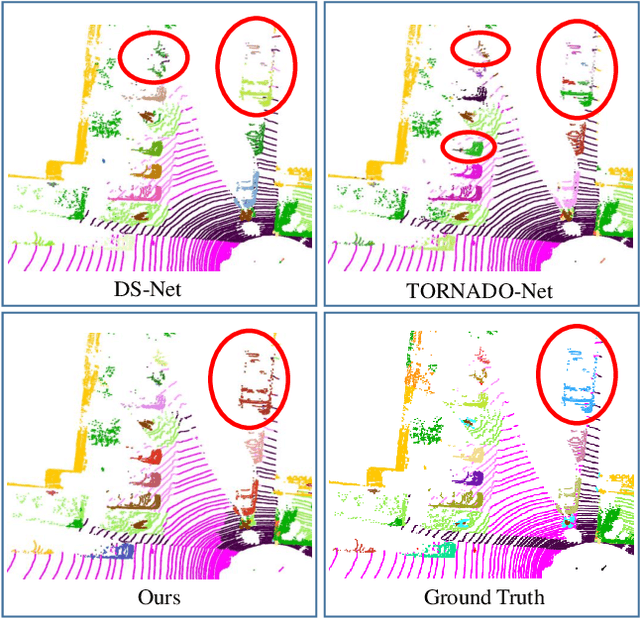
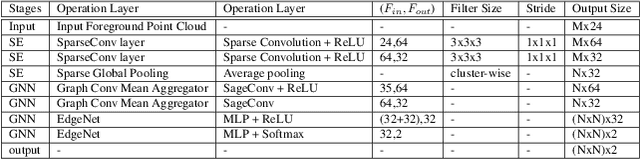
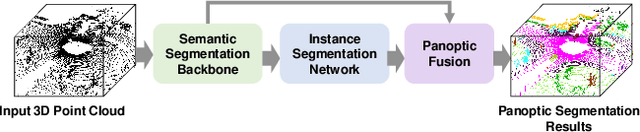
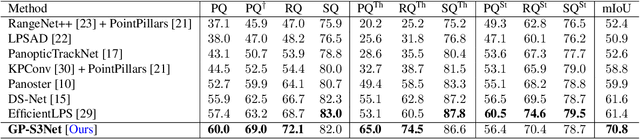
Panoptic segmentation as an integrated task of both static environmental understanding and dynamic object identification, has recently begun to receive broad research interest. In this paper, we propose a new computationally efficient LiDAR based panoptic segmentation framework, called GP-S3Net. GP-S3Net is a proposal-free approach in which no object proposals are needed to identify the objects in contrast to conventional two-stage panoptic systems, where a detection network is incorporated for capturing instance information. Our new design consists of a novel instance-level network to process the semantic results by constructing a graph convolutional network to identify objects (foreground), which later on are fused with the background classes. Through the fine-grained clusters of the foreground objects from the semantic segmentation backbone, over-segmentation priors are generated and subsequently processed by 3D sparse convolution to embed each cluster. Each cluster is treated as a node in the graph and its corresponding embedding is used as its node feature. Then a GCNN predicts whether edges exist between each cluster pair. We utilize the instance label to generate ground truth edge labels for each constructed graph in order to supervise the learning. Extensive experiments demonstrate that GP-S3Net outperforms the current state-of-the-art approaches, by a significant margin across available datasets such as, nuScenes and SemanticPOSS, ranking first on the competitive public SemanticKITTI leaderboard upon publication.
Avoiding bias when inferring race using name-based approaches
May 03, 2021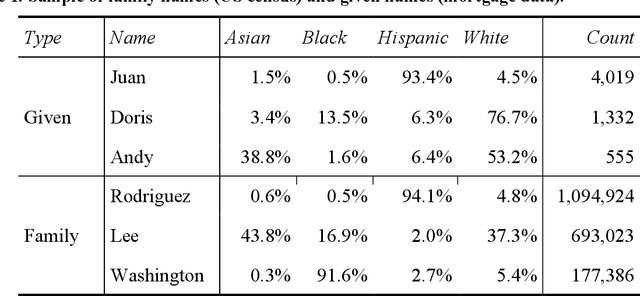
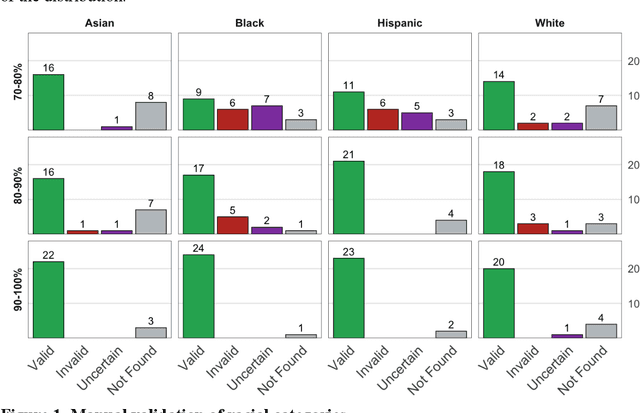
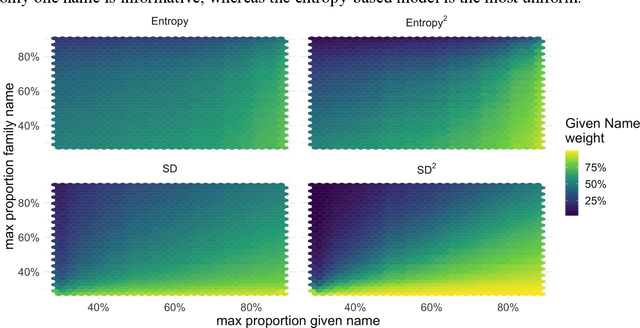
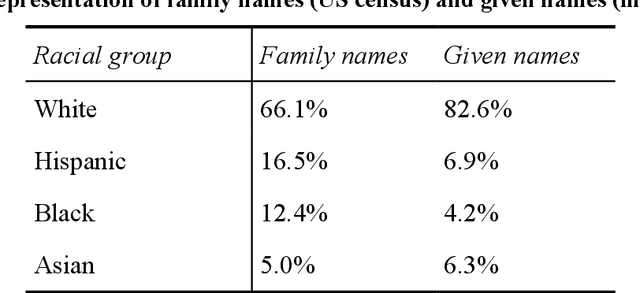
Racial disparity in academia is a widely acknowledged problem. The quantitative understanding of racial-based systemic inequalities is an important step towards a more equitable research system. However, few large-scale analyses have been performed on this topic, mostly because of the lack of robust race-disambiguation algorithms. Identifying author information does not generally include the author's race. Therefore, an algorithm needs to be employed, using known information about authors, i.e., their names, to infer their perceived race. Nevertheless, as any other algorithm, the process of racial inference can generate biases if it is not carefully considered. When the research is focused on the understanding of racial-based inequalities, such biases undermine the objectives of the investigation and may perpetuate inequities. The goal of this article is to assess the biases introduced by the different approaches used name-based racial inference. We use information from US census and mortgage applications to infer the race of US author names in the Web of Science. We estimate the effects of using given and family names, thresholds or continuous distributions, and imputation. Our results demonstrate that the validity of name-based inference varies by race and ethnicity and that threshold approaches underestimate Black authors and overestimate White authors. We conclude with recommendations to avoid potential biases. This article fills an important research gap that will allow more systematic and unbiased studies on racial disparity in science.
A Realistic Simulation Framework for Learning with Label Noise
Jul 23, 2021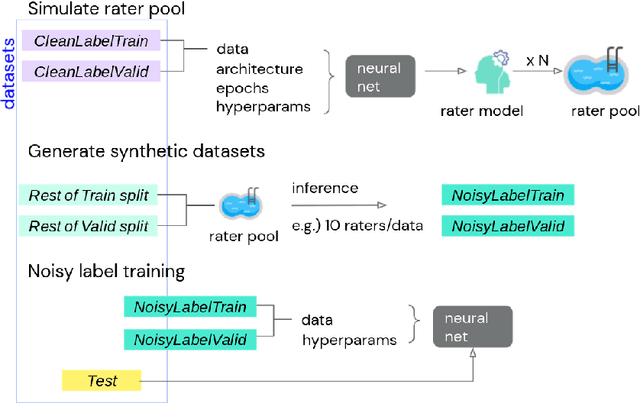
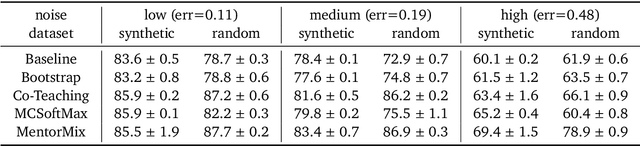
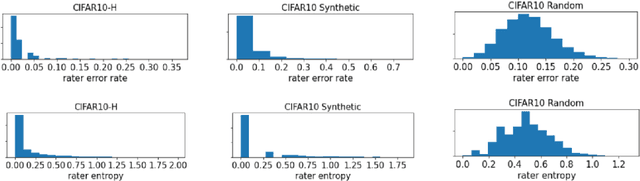
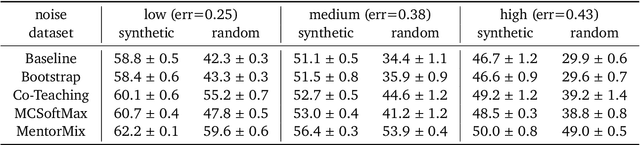
We propose a simulation framework for generating realistic instance-dependent noisy labels via a pseudo-labeling paradigm. We show that this framework generates synthetic noisy labels that exhibit important characteristics of the label noise in practical settings via comparison with the CIFAR10-H dataset. Equipped with controllable label noise, we study the negative impact of noisy labels across a few realistic settings to understand when label noise is more problematic. We also benchmark several existing algorithms for learning with noisy labels and compare their behavior on our synthetic datasets and on the datasets with independent random label noise. Additionally, with the availability of annotator information from our simulation framework, we propose a new technique, Label Quality Model (LQM), that leverages annotator features to predict and correct against noisy labels. We show that by adding LQM as a label correction step before applying existing noisy label techniques, we can further improve the models' performance.