 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Caveats for the use of Web of Science Core Collection in old literature retrieval and historical bibliometric analysis
Jul 24, 2021
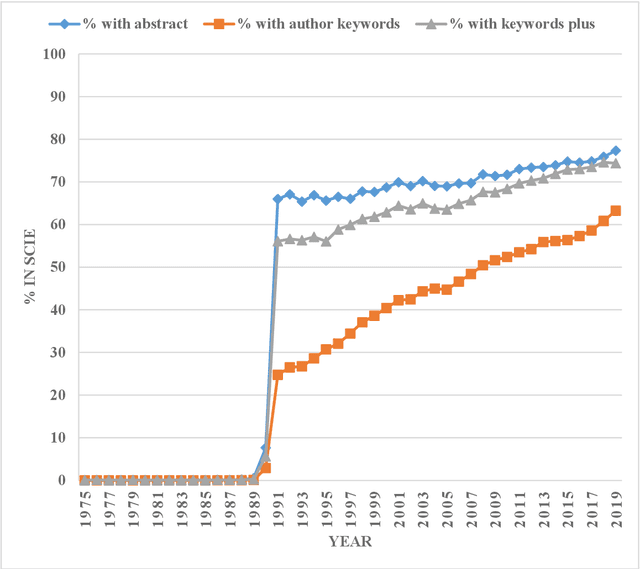
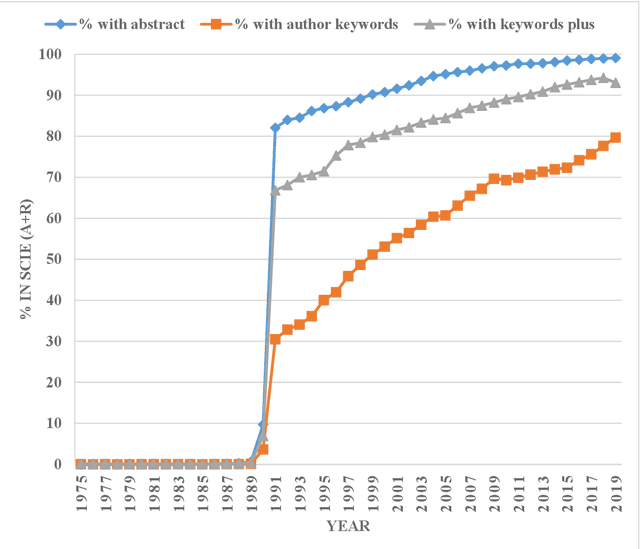
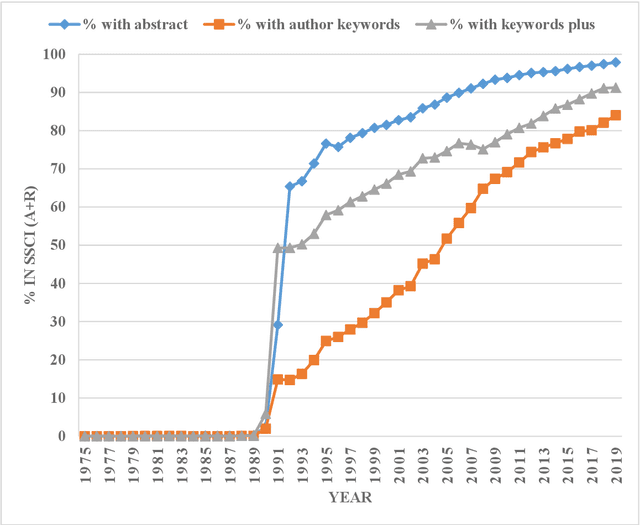
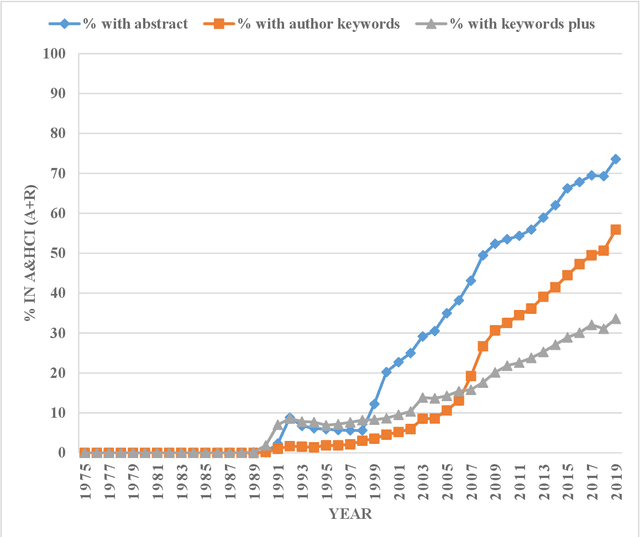
By using publications from Web of Science Core Collection (WoSCC), Fosso Wamba and his colleagues published an interesting and comprehensive paper in Technological Forecasting and Social Change to explore the structure and dynamics of artificial intelligence (AI) scholarship. Data demonstrated in Fosso Wamba's study implied that the year 1991 seemed to be a "watershed" of AI research. This research note tried to uncover the 1991 phenomenon from the perspective of database limitation by probing the limitations of search in abstract/author keywords/keywords plus fields of WoSCC empirically. The low availability rates of abstract/author keywords/keywords plus information in WoSCC found in this study can explain the "watershed" phenomenon of AI scholarship in 1991 to a large extent. Some other caveats for the use of WoSCC in old literature retrieval and historical bibliometric analysis were also mentioned in the discussion section. This research note complements Fosso Wamba and his colleagues' study and also helps avoid improper interpretation in the use of WoSCC in old literature retrieval and historical bibliometric analysis.
How Vulnerable Are Automatic Fake News Detection Methods to Adversarial Attacks?
Jul 16, 2021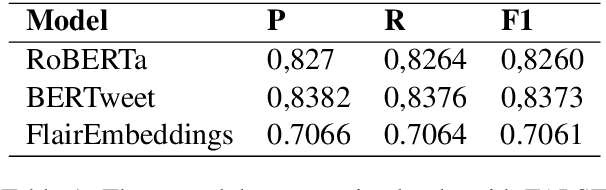
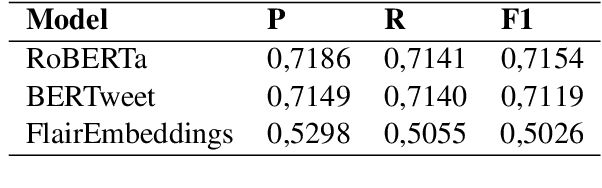
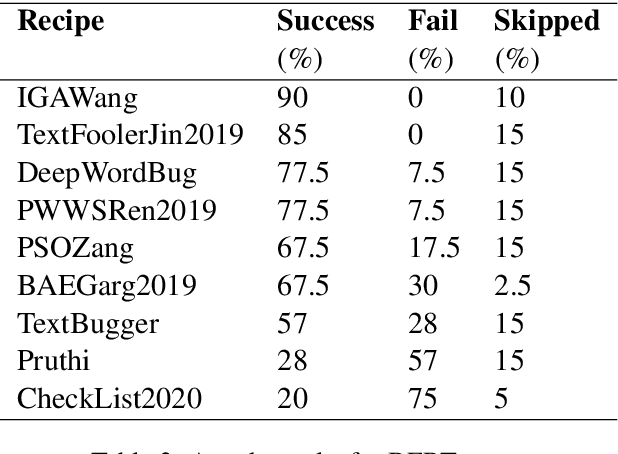
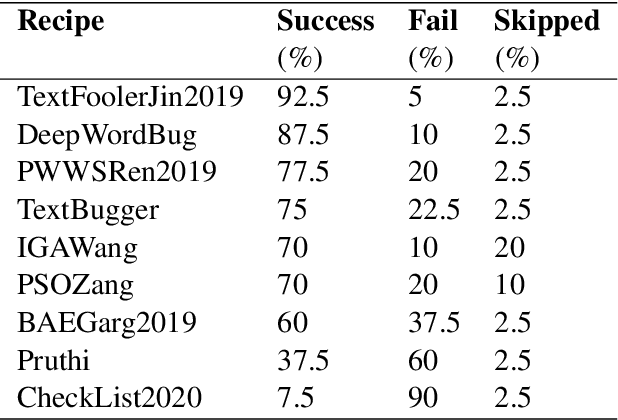
As the spread of false information on the internet has increased dramatically in recent years, more and more attention is being paid to automated fake news detection. Some fake news detection methods are already quite successful. Nevertheless, there are still many vulnerabilities in the detection algorithms. The reason for this is that fake news publishers can structure and formulate their texts in such a way that a detection algorithm does not expose this text as fake news. This paper shows that it is possible to automatically attack state-of-the-art models that have been trained to detect Fake News, making these vulnerable. For this purpose, corresponding models were first trained based on a dataset. Then, using Text-Attack, an attempt was made to manipulate the trained models in such a way that previously correctly identified fake news was classified as true news. The results show that it is possible to automatically bypass Fake News detection mechanisms, leading to implications concerning existing policy initiatives.
Predicting Flight Delay with Spatio-Temporal Trajectory Convolutional Network and Airport Situational Awareness Map
May 19, 2021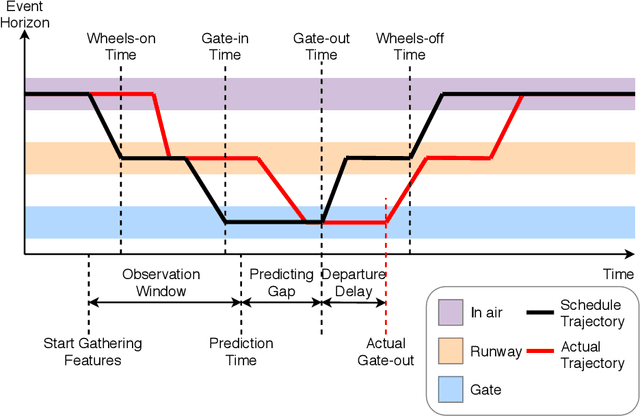
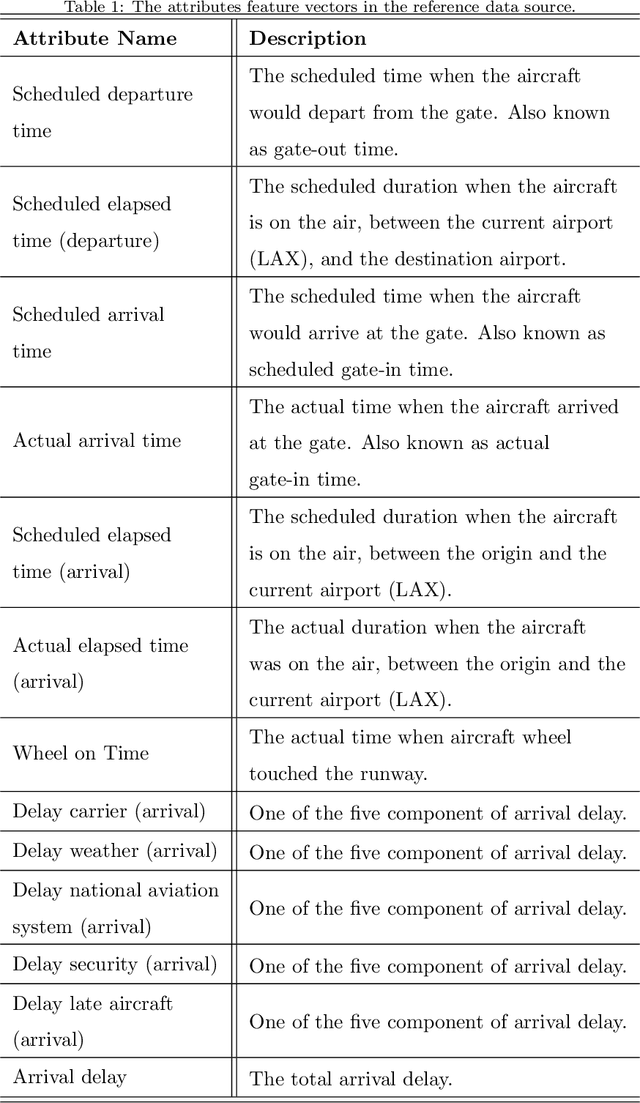
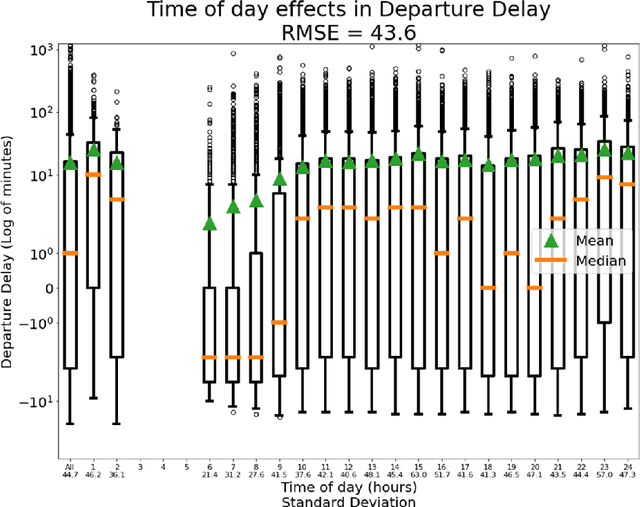
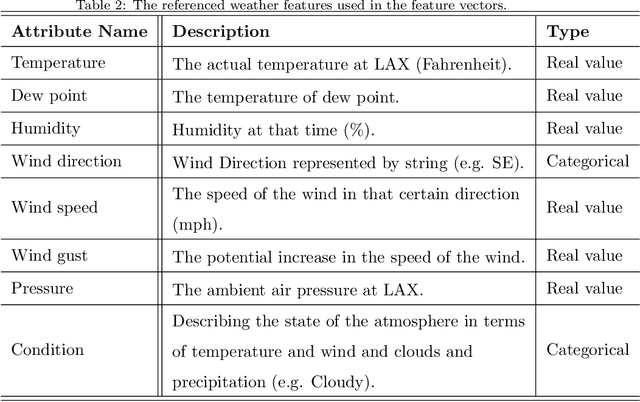
To model and forecast flight delays accurately, it is crucial to harness various vehicle trajectory and contextual sensor data on airport tarmac areas. These heterogeneous sensor data, if modelled correctly, can be used to generate a situational awareness map. Existing techniques apply traditional supervised learning methods onto historical data, contextual features and route information among different airports to predict flight delay are inaccurate and only predict arrival delay but not departure delay, which is essential to airlines. In this paper, we propose a vision-based solution to achieve a high forecasting accuracy, applicable to the airport. Our solution leverages a snapshot of the airport situational awareness map, which contains various trajectories of aircraft and contextual features such as weather and airline schedules. We propose an end-to-end deep learning architecture, TrajCNN, which captures both the spatial and temporal information from the situational awareness map. Additionally, we reveal that the situational awareness map of the airport has a vital impact on estimating flight departure delay. Our proposed framework obtained a good result (around 18 minutes error) for predicting flight departure delay at Los Angeles International Airport.
Spectral Splitting and Aggregation Network for Hyperspectral Face Super-Resolution
Aug 31, 2021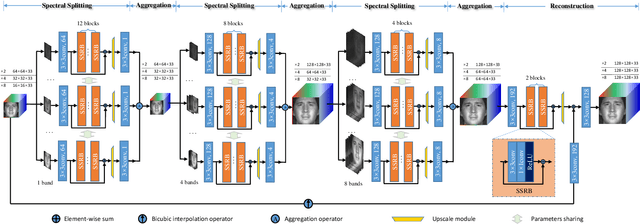

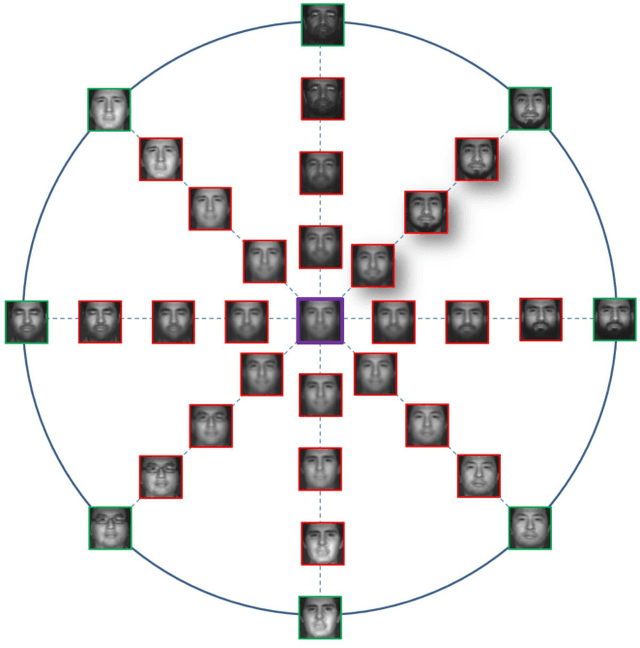
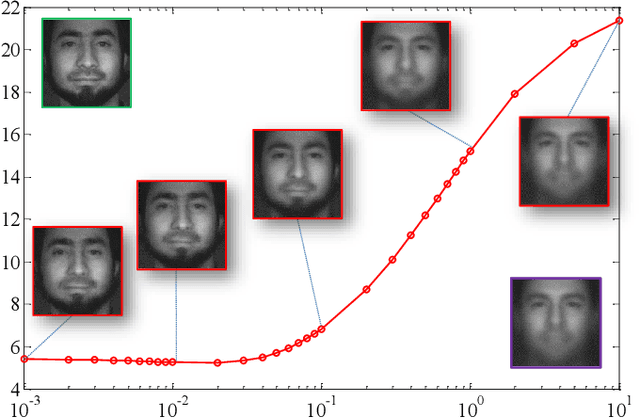
High-resolution (HR) hyperspectral face image plays an important role in face related computer vision tasks under uncontrolled conditions, such as low-light environment and spoofing attacks. However, the dense spectral bands of hyperspectral face images come at the cost of limited amount of photons reached a narrow spectral window on average, which greatly reduces the spatial resolution of hyperspectral face images. In this paper, we investigate how to adapt the deep learning techniques to hyperspectral face image super-resolution (HFSR), especially when the training samples are very limited. Benefiting from the amount of spectral bands, in which each band can be seen as an image, we present a spectral splitting and aggregation network (SSANet) for HFSR with limited training samples. In the shallow layers, we split the hyperspectral image into different spectral groups and take each of them as an individual training sample (in the sense that each group will be fed into the same network). Then, we gradually aggregate the neighbor bands at the deeper layers to exploit the spectral correlations. By this spectral splitting and aggregation strategy (SSAS), we can divide the original hyperspectral image into multiple samples to support the efficient training of the network and effectively exploit the spectral correlations among spectrum. To cope with the challenge of small training sample size (S3) problem, we propose to expand the training samples by a self-representation model and symmetry-induced augmentation. Experiments show that the introduced SSANet can well model the joint correlations of spatial and spectral information. By expanding the training samples, our proposed method can effectively alleviate the S3 problem. The comparison results demonstrate that our proposed method can outperform the state-of-the-arts.
StrucTexT: Structured Text Understanding with Multi-Modal Transformers
Aug 06, 2021
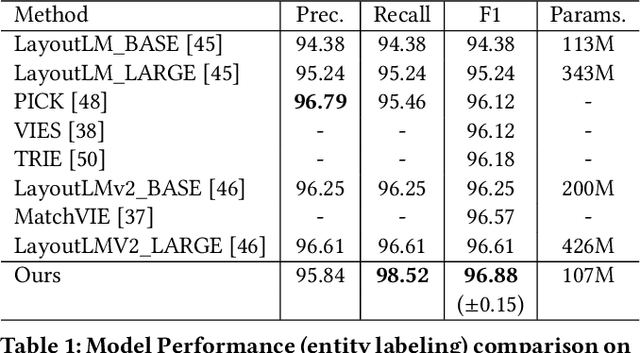
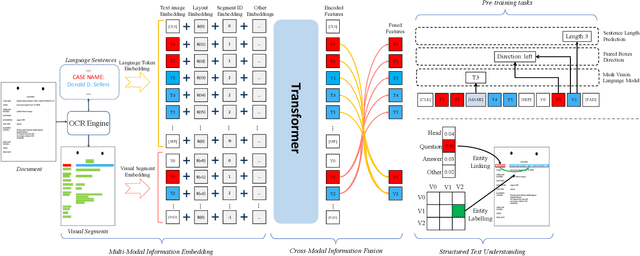
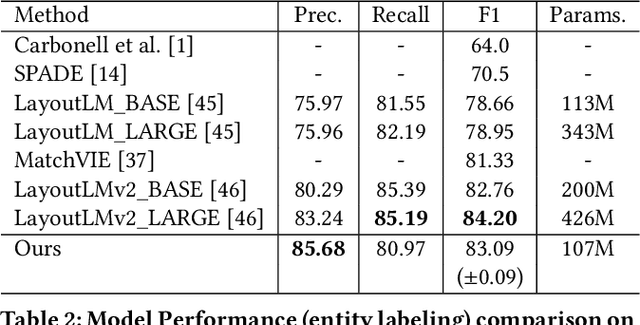
Structured text understanding on Visually Rich Documents (VRDs) is a crucial part of Document Intelligence. Due to the complexity of content and layout in VRDs, structured text understanding has been a challenging task. Most existing studies decoupled this problem into two sub-tasks: entity labeling and entity linking, which require an entire understanding of the context of documents at both token and segment levels. However, little work has been concerned with the solutions that efficiently extract the structured data from different levels. This paper proposes a unified framework named StrucTexT, which is flexible and effective for handling both sub-tasks. Specifically, based on the transformer, we introduce a segment-token aligned encoder to deal with the entity labeling and entity linking tasks at different levels of granularity. Moreover, we design a novel pre-training strategy with three self-supervised tasks to learn a richer representation. StrucTexT uses the existing Masked Visual Language Modeling task and the new Sentence Length Prediction and Paired Boxes Direction tasks to incorporate the multi-modal information across text, image, and layout. We evaluate our method for structured text understanding at segment-level and token-level and show it outperforms the state-of-the-art counterparts with significantly superior performance on the FUNSD, SROIE, and EPHOIE datasets.
Dual Side Deep Context-aware Modulation for Social Recommendation
Mar 16, 2021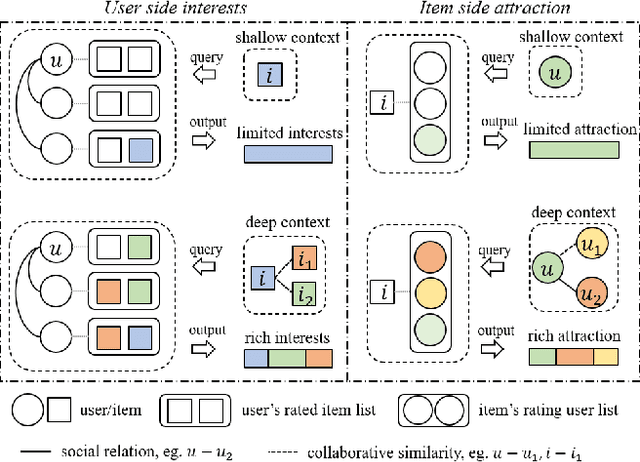

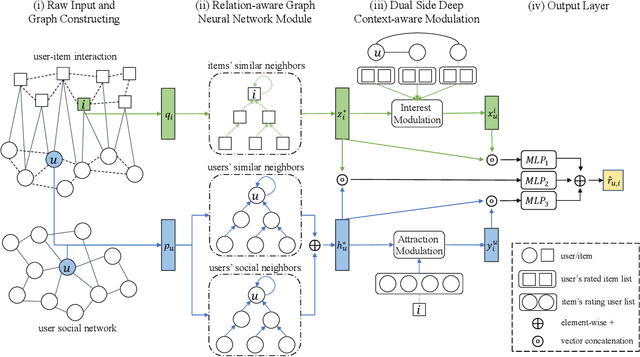
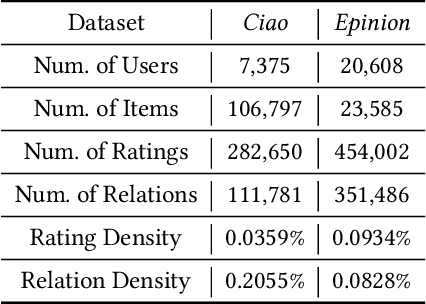
Social recommendation is effective in improving the recommendation performance by leveraging social relations from online social networking platforms. Social relations among users provide friends' information for modeling users' interest in candidate items and help items expose to potential consumers (i.e., item attraction). However, there are two issues haven't been well-studied: Firstly, for the user interests, existing methods typically aggregate friends' information contextualized on the candidate item only, and this shallow context-aware aggregation makes them suffer from the limited friends' information. Secondly, for the item attraction, if the item's past consumers are the friends of or have a similar consumption habit to the targeted user, the item may be more attractive to the targeted user, but most existing methods neglect the relation enhanced context-aware item attraction. To address the above issues, we proposed DICER (Dual Side Deep Context-aware Modulation for SocialRecommendation). Specifically, we first proposed a novel graph neural network to model the social relation and collaborative relation, and on top of high-order relations, a dual side deep context-aware modulation is introduced to capture the friends' information and item attraction. Empirical results on two real-world datasets show the effectiveness of the proposed model and further experiments are conducted to help understand how the dual context-aware modulation works.
Neural Response Interpretation through the Lens of Critical Pathways
Mar 31, 2021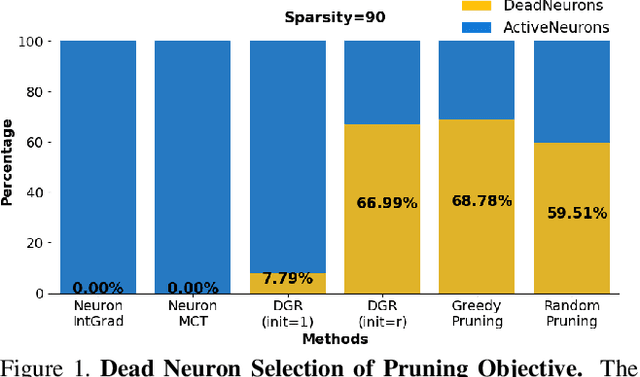
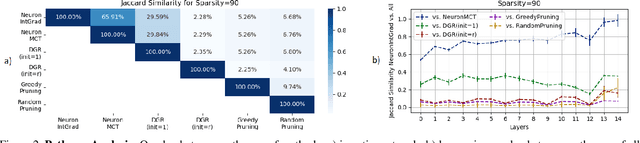
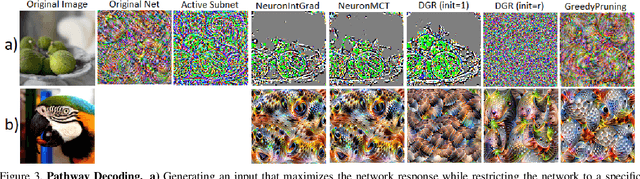

Is critical input information encoded in specific sparse pathways within the neural network? In this work, we discuss the problem of identifying these critical pathways and subsequently leverage them for interpreting the network's response to an input. The pruning objective -- selecting the smallest group of neurons for which the response remains equivalent to the original network -- has been previously proposed for identifying critical pathways. We demonstrate that sparse pathways derived from pruning do not necessarily encode critical input information. To ensure sparse pathways include critical fragments of the encoded input information, we propose pathway selection via neurons' contribution to the response. We proceed to explain how critical pathways can reveal critical input features. We prove that pathways selected via neuron contribution are locally linear (in an L2-ball), a property that we use for proposing a feature attribution method: "pathway gradient". We validate our interpretation method using mainstream evaluation experiments. The validation of pathway gradient interpretation method further confirms that selected pathways using neuron contributions correspond to critical input features. The code is publicly available.
Deep Learning Beam Optimization in Millimeter-Wave Communication Systems
Jul 16, 2021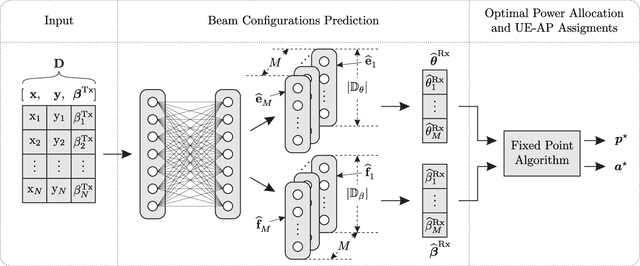
We propose a method that combines fixed point algorithms with a neural network to optimize jointly discrete and continuous variables in millimeter-wave communication systems, so that the users' rates are allocated fairly in a well-defined sense. In more detail, the discrete variables include user-access point assignments and the beam configurations, while the continuous variables refer to the power allocation. The beam configuration is predicted from user-related information using a neural network. Given the predicted beam configuration, a fixed point algorithm allocates power and assigns users to access points so that the users achieve the maximum fraction of their interference-free rates. The proposed method predicts the beam configuration in a "one-shot" manner, which significantly reduces the complexity of the beam search procedure. Moreover, even if the predicted beam configurations are not optimal, the fixed point algorithm still provides the optimal power allocation and user-access point assignments for the given beam configuration.
A guided edge-aware smoothing-sharpening filter based on patch interpolation model and generalized Gamma distribution
Jul 30, 2021



Smoothing and sharpening are two fundamental image processing operations. The latter is usually related to the former through the unsharp masking algorithm. In this paper, we develop a new type of filter which performs smoothing or sharpening via a tuning parameter. The development of the new filter is based on (1) a new Laplacian-based filter formulation which unifies the smoothing and sharpening operations, (2) a patch interpolation model similar to that used in the guided filter which provides edge-awareness capability, and (3) the generalized Gamma distribution which is used as the prior for parameter estimation. We have conducted detailed studies on the properties of two versions of the proposed filter (self-guidance and external guidance). We have also conducted experiments to demonstrate applications of the proposed filter. In the self-guidance case, we have developed adaptive smoothing and sharpening algorithms based on texture, depth and blurriness information extracted from an image. Applications include enhancing human face images, producing shallow depth of field effects, focus-based image enhancement, and seam carving. In the external guidance case, we have developed new algorithms for combining flash and no-flash images and for enhancing multi-spectral images using a panchromatic image.
* 23 pages, 16 figures
Stabilization of generative adversarial networks via noisy scale-space
May 04, 2021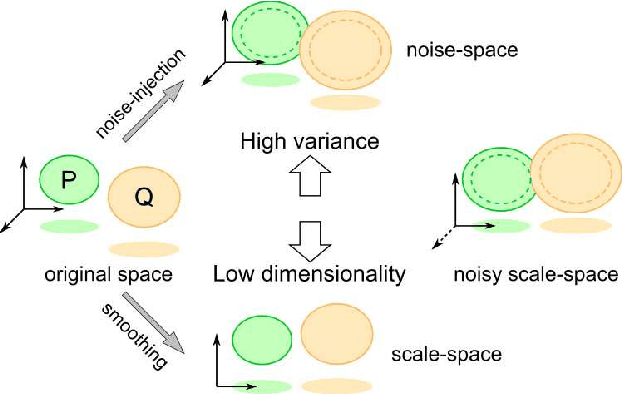
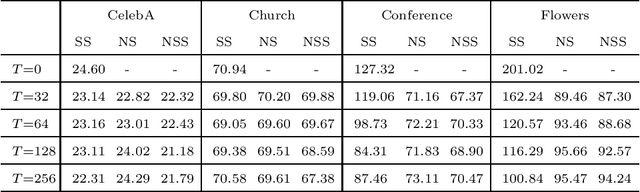

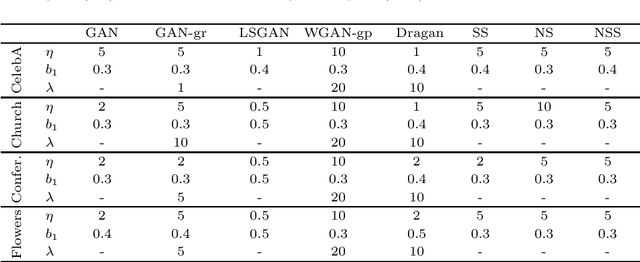
Generative adversarial networks (GAN) is a framework for generating fake data based on given reals but is unstable in the optimization. In order to stabilize GANs, the noise enlarges the overlap of the real and fake distributions at the cost of significant variance. The data smoothing may reduce the dimensionality of data but suppresses the capability of GANs to learn high-frequency information. Based on these observations, we propose a data representation for GANs, called noisy scale-space, that recursively applies the smoothing with noise to data in order to preserve the data variance while replacing high-frequency information by random data, leading to a coarse-to-fine training of GANs. We also present a synthetic data-set using the Hadamard bases that enables us to visualize the true distribution of data. We experiment with a DCGAN with the noise scale-space (NSS-GAN) using major data-sets in which NSS-GAN overtook state-of-the-arts in most cases independent of the image content.