 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
UniRE: A Unified Label Space for Entity Relation Extraction
Jul 09, 2021
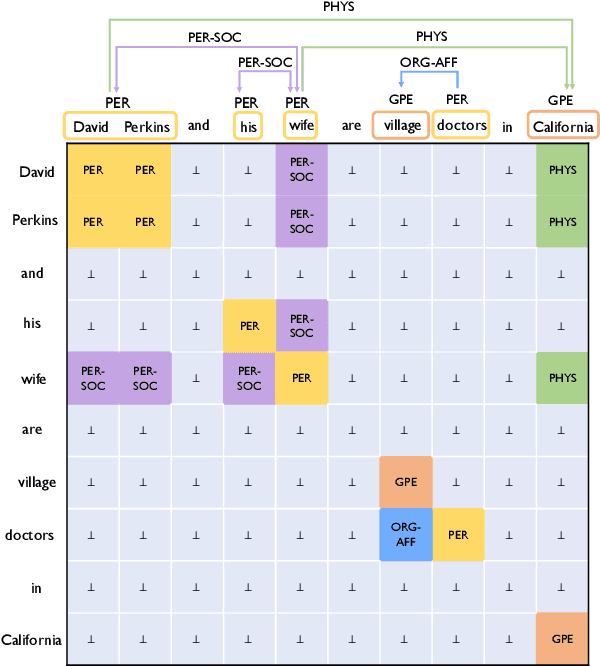
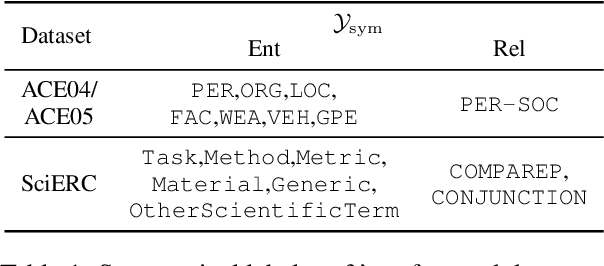
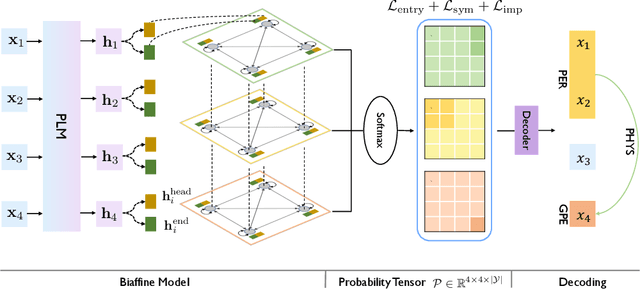
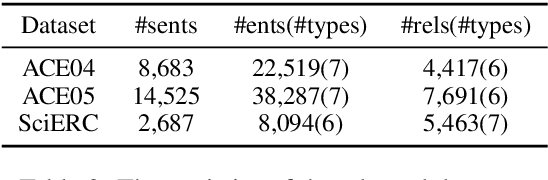
Many joint entity relation extraction models setup two separated label spaces for the two sub-tasks (i.e., entity detection and relation classification). We argue that this setting may hinder the information interaction between entities and relations. In this work, we propose to eliminate the different treatment on the two sub-tasks' label spaces. The input of our model is a table containing all word pairs from a sentence. Entities and relations are represented by squares and rectangles in the table. We apply a unified classifier to predict each cell's label, which unifies the learning of two sub-tasks. For testing, an effective (yet fast) approximate decoder is proposed for finding squares and rectangles from tables. Experiments on three benchmarks (ACE04, ACE05, SciERC) show that, using only half the number of parameters, our model achieves competitive accuracy with the best extractor, and is faster.
HDRUNet: Single Image HDR Reconstruction with Denoising and Dequantization
May 27, 2021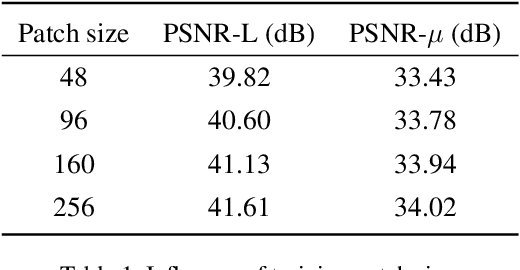
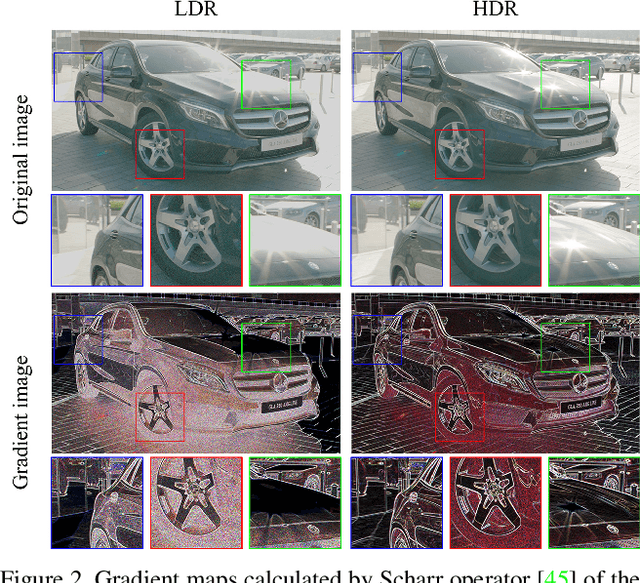
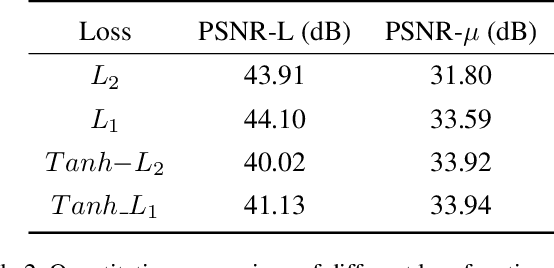
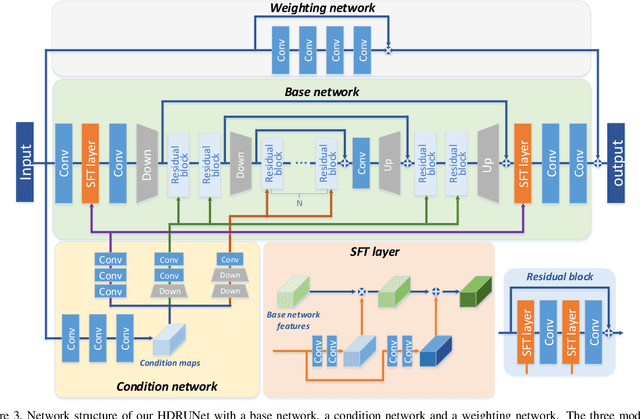
Most consumer-grade digital cameras can only capture a limited range of luminance in real-world scenes due to sensor constraints. Besides, noise and quantization errors are often introduced in the imaging process. In order to obtain high dynamic range (HDR) images with excellent visual quality, the most common solution is to combine multiple images with different exposures. However, it is not always feasible to obtain multiple images of the same scene and most HDR reconstruction methods ignore the noise and quantization loss. In this work, we propose a novel learning-based approach using a spatially dynamic encoder-decoder network, HDRUNet, to learn an end-to-end mapping for single image HDR reconstruction with denoising and dequantization. The network consists of a UNet-style base network to make full use of the hierarchical multi-scale information, a condition network to perform pattern-specific modulation and a weighting network for selectively retaining information. Moreover, we propose a Tanh_L1 loss function to balance the impact of over-exposed values and well-exposed values on the network learning. Our method achieves the state-of-the-art performance in quantitative comparisons and visual quality. The proposed HDRUNet model won the second place in the single frame track of NITRE2021 High Dynamic Range Challenge.
Deep Motion Prior for Weakly-Supervised Temporal Action Localization
Aug 12, 2021
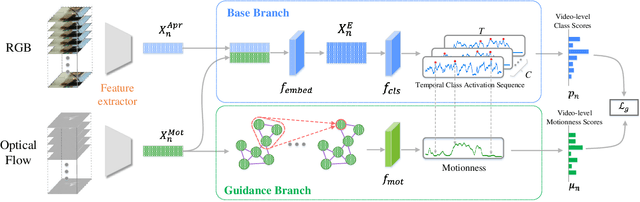
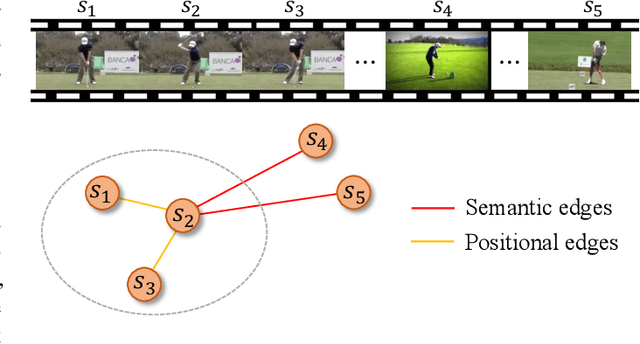
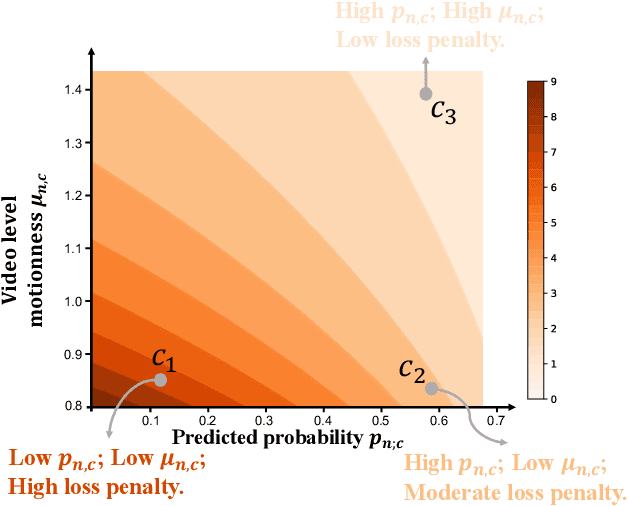
Weakly-Supervised Temporal Action Localization (WSTAL) aims to localize actions in untrimmed videos with only video-level labels. Currently, most state-of-the-art WSTAL methods follow a Multi-Instance Learning (MIL) pipeline: producing snippet-level predictions first and then aggregating to the video-level prediction. However, we argue that existing methods have overlooked two important drawbacks: 1) inadequate use of motion information and 2) the incompatibility of prevailing cross-entropy training loss. In this paper, we analyze that the motion cues behind the optical flow features are complementary informative. Inspired by this, we propose to build a context-dependent motion prior, termed as motionness. Specifically, a motion graph is introduced to model motionness based on the local motion carrier (e.g., optical flow). In addition, to highlight more informative video snippets, a motion-guided loss is proposed to modulate the network training conditioned on motionness scores. Extensive ablation studies confirm that motionness efficaciously models action-of-interest, and the motion-guided loss leads to more accurate results. Besides, our motion-guided loss is a plug-and-play loss function and is applicable with existing WSTAL methods. Without loss of generality, based on the standard MIL pipeline, our method achieves new state-of-the-art performance on three challenging benchmarks, including THUMOS'14, ActivityNet v1.2 and v1.3.
Dual-Attention Enhanced BDense-UNet for Liver Lesion Segmentation
Jul 24, 2021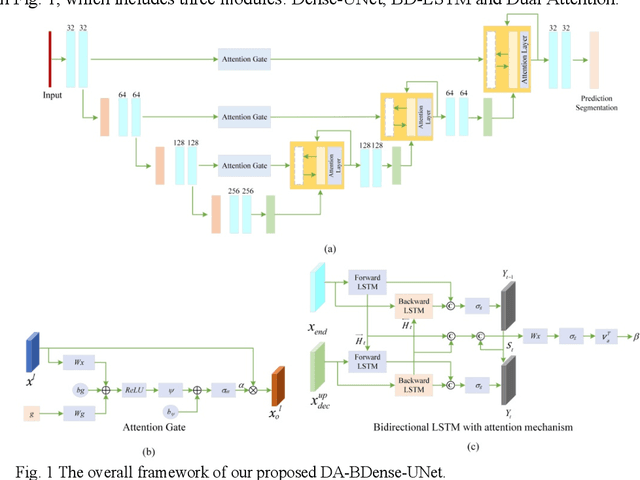
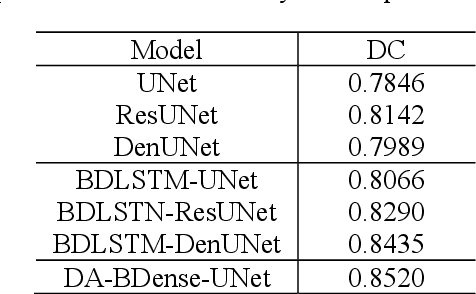
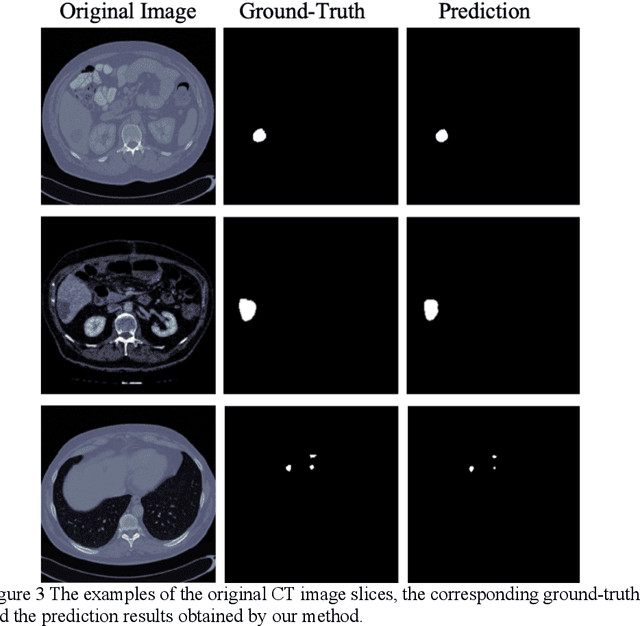
In this work, we propose a new segmentation network by integrating DenseUNet and bidirectional LSTM together with attention mechanism, termed as DA-BDense-UNet. DenseUNet allows learning enough diverse features and enhancing the representative power of networks by regulating the information flow. Bidirectional LSTM is responsible to explore the relationships between the encoded features and the up-sampled features in the encoding and decoding paths. Meanwhile, we introduce attention gates (AG) into DenseUNet to diminish responses of unrelated background regions and magnify responses of salient regions progressively. Besides, the attention in bidirectional LSTM takes into account the contribution differences of the encoded features and the up-sampled features in segmentation improvement, which can in turn adjust proper weights for these two kinds of features. We conduct experiments on liver CT image data sets collected from multiple hospitals by comparing them with state-of-the-art segmentation models. Experimental results indicate that our proposed method DA-BDense-UNet has achieved comparative performance in terms of dice coefficient, which demonstrates its effectiveness.
BackEISNN: A Deep Spiking Neural Network with Adaptive Self-Feedback and Balanced Excitatory-Inhibitory Neurons
May 27, 2021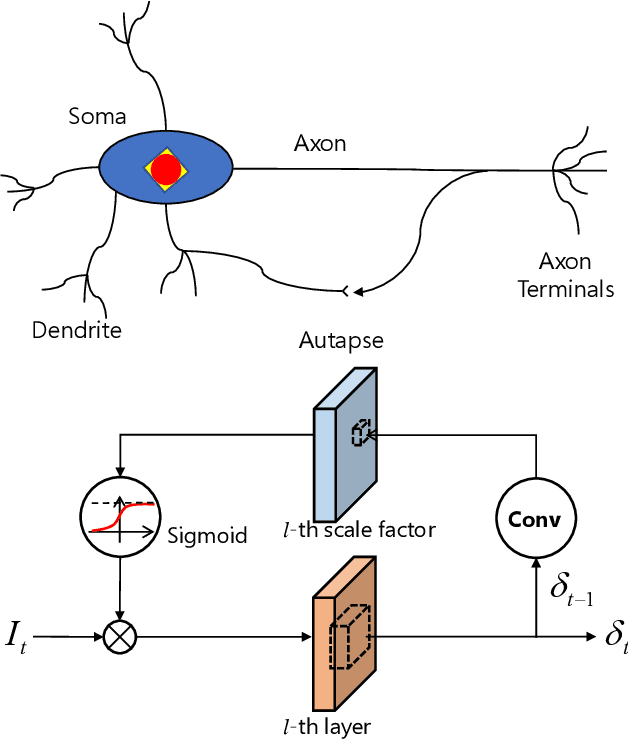
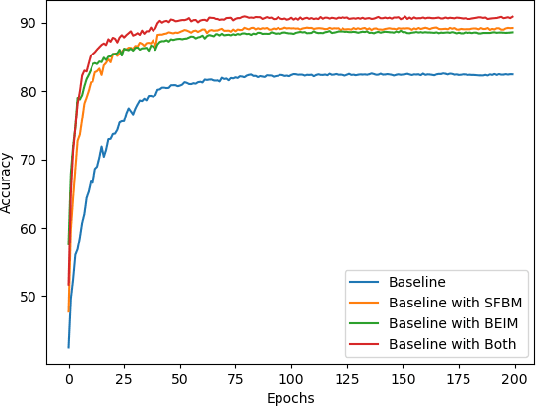
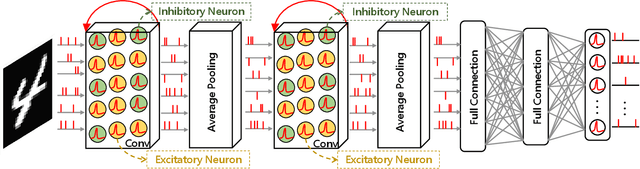
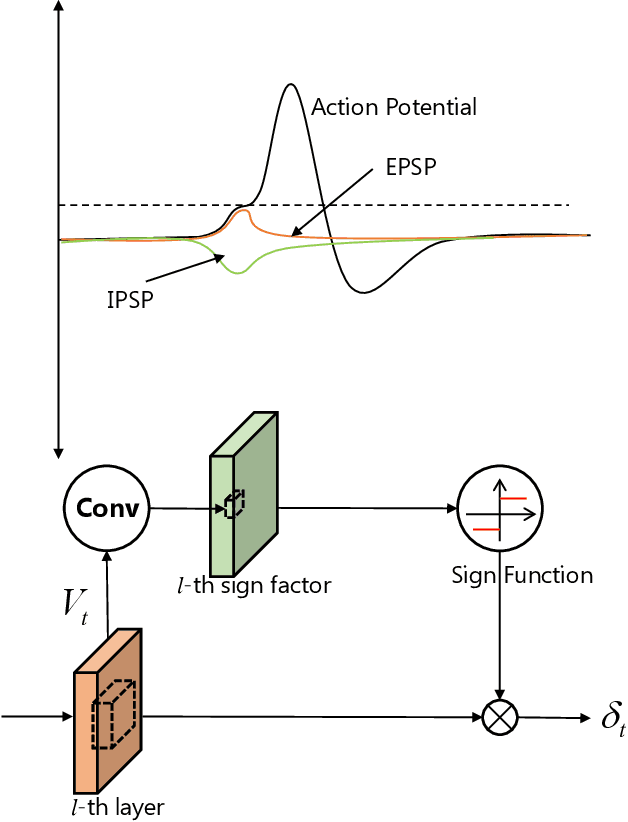
Spiking neural networks (SNNs) transmit information through discrete spikes, which performs well in processing spatial-temporal information. Due to the non-differentiable characteristic, there still exist difficulties in designing well-performed SNNs. Recently, SNNs trained with backpropagation have shown superior performance due to the proposal of the gradient approximation. However, the performance on complex tasks is still far away from the deep neural networks. Taking inspiration from the autapse in the brain which connects the spiking neurons with a self-feedback connection, we apply an adaptive time-delayed self-feedback on the membrane potential to regulate the spike precisions. As well as, we apply the balanced excitatory and inhibitory neurons mechanism to control the spiking neurons' output dynamically. With the combination of the two mechanisms, we propose a deep spiking neural network with adaptive self-feedback and balanced excitatory and inhibitory neurons (BackEISNN). The experimental results on several standard datasets have shown that the two modules not only accelerate the convergence of the network but also improve the accuracy. For the MNIST, FashionMNIST, and N-MNIST datasets, our model has achieved state-of-the-art performance. For the CIFAR10 dataset, our BackEISNN also gets remarkable performance on a relatively light structure that competes against state-of-the-art SNNs.
ST-DETR: Spatio-Temporal Object Traces Attention Detection Transformer
Jul 13, 2021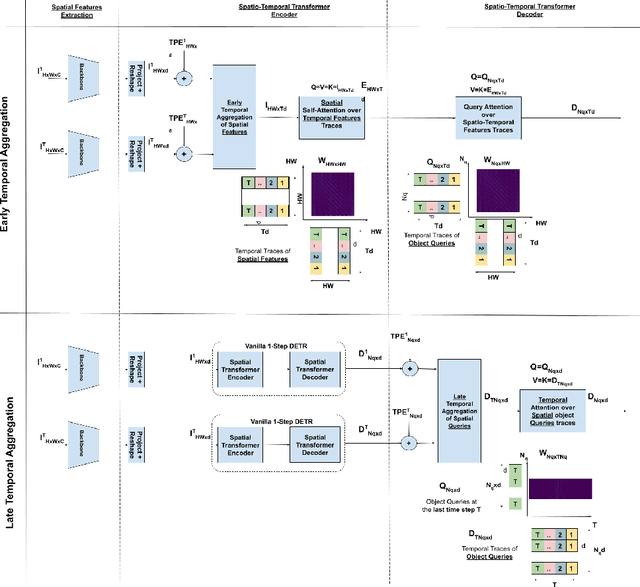

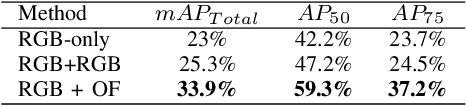

We propose ST-DETR, a Spatio-Temporal Transformer-based architecture for object detection from a sequence of temporal frames. We treat the temporal frames as sequences in both space and time and employ the full attention mechanisms to take advantage of the features correlations over both dimensions. This treatment enables us to deal with frames sequence as temporal object features traces over every location in the space. We explore two possible approaches; the early spatial features aggregation over the temporal dimension, and the late temporal aggregation of object query spatial features. Moreover, we propose a novel Temporal Positional Embedding technique to encode the time sequence information. To evaluate our approach, we choose the Moving Object Detection (MOD)task, since it is a perfect candidate to showcase the importance of the temporal dimension. Results show a significant 5% mAP improvement on the KITTI MOD dataset over the 1-step spatial baseline.
Learning Statistical Texture for Semantic Segmentation
Mar 06, 2021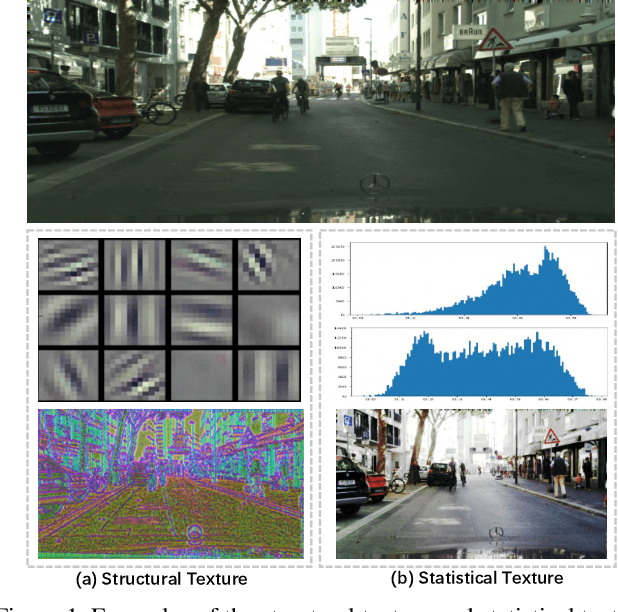
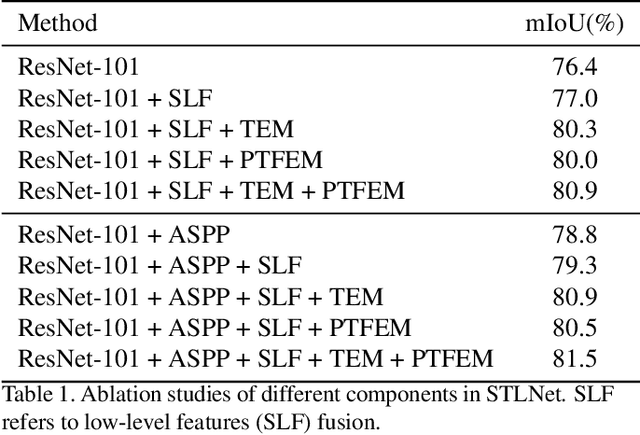
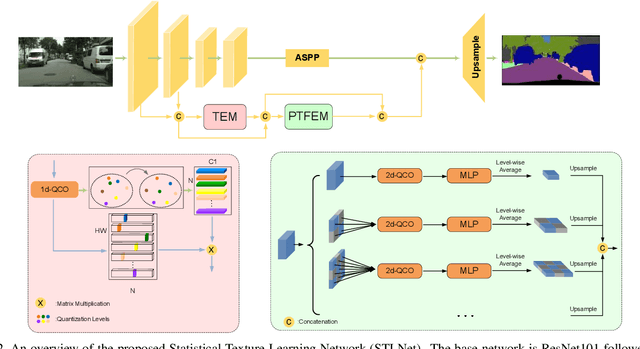

Existing semantic segmentation works mainly focus on learning the contextual information in high-level semantic features with CNNs. In order to maintain a precise boundary, low-level texture features are directly skip-connected into the deeper layers. Nevertheless, texture features are not only about local structure, but also include global statistical knowledge of the input image. In this paper, we fully take advantages of the low-level texture features and propose a novel Statistical Texture Learning Network (STLNet) for semantic segmentation. For the first time, STLNet analyzes the distribution of low level information and efficiently utilizes them for the task. Specifically, a novel Quantization and Counting Operator (QCO) is designed to describe the texture information in a statistical manner. Based on QCO, two modules are introduced: (1) Texture Enhance Module (TEM), to capture texture-related information and enhance the texture details; (2) Pyramid Texture Feature Extraction Module (PTFEM), to effectively extract the statistical texture features from multiple scales. Through extensive experiments, we show that the proposed STLNet achieves state-of-the-art performance on three semantic segmentation benchmarks: Cityscapes, PASCAL Context and ADE20K.
A Multi-task Mean Teacher for Semi-supervised Facial Affective Behavior Analysis
Jul 13, 2021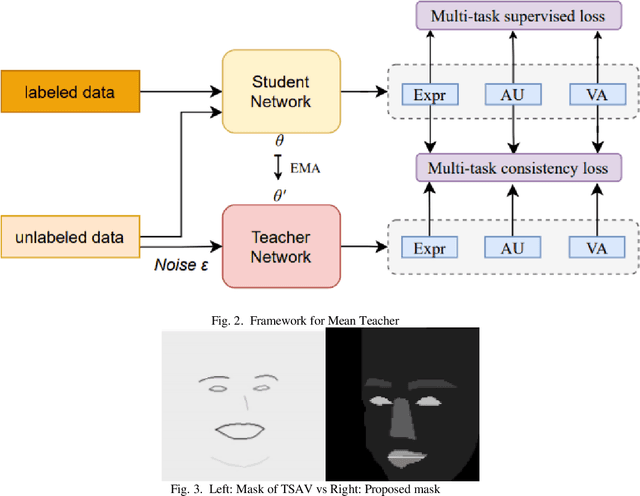
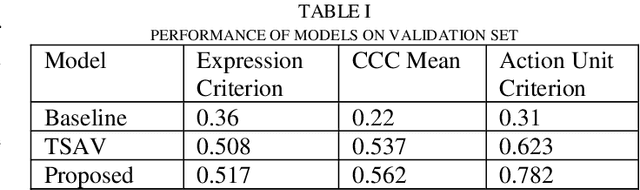
Affective Behavior Analysis is an important part in human-computer interaction. Existing successful affective behavior analysis method such as TSAV[9] suffer from challenge of incomplete labeled datasets. To boost its performance, this paper presents a multi-task mean teacher model for semi-supervised Affective Behavior Analysis to learn from missing labels and exploring the learning of multiple correlated task simultaneously. To be specific, we first utilize TSAV as baseline model to simultaneously recognize the three tasks. We have modified the preprocessing method of rendering mask to provide better semantics information. After that, we extended TSAV model to semi-supervised model using mean teacher, which allow it to be benefited from unlabeled data. Experimental results on validation datasets show that our method achieves better performance than TSAV model, which verifies that the proposed network can effectively learn additional unlabeled data to boost the affective behavior analysis performance.
CCC/Code 8.7: Applying AI in the Fight Against Modern Slavery
Jun 24, 2021On any given day, tens of millions of people find themselves trapped in instances of modern slavery. The terms "human trafficking," "trafficking in persons," and "modern slavery" are sometimes used interchangeably to refer to both sex trafficking and forced labor. Human trafficking occurs when a trafficker compels someone to provide labor or services through the use of force, fraud, and/or coercion. The wide range of stakeholders in human trafficking presents major challenges. Direct stakeholders are law enforcement, NGOs and INGOs, businesses, local/planning government authorities, and survivors. Viewed from a very high level, all stakeholders share in a rich network of interactions that produce and consume enormous amounts of information. The problems of making efficient use of such information for the purposes of fighting trafficking while at the same time adhering to community standards of privacy and ethics are formidable. At the same time they help us, technologies that increase surveillance of populations can also undermine basic human rights. In early March 2020, the Computing Community Consortium (CCC), in collaboration with the Code 8.7 Initiative, brought together over fifty members of the computing research community along with anti-slavery practitioners and survivors to lay out a research roadmap. The primary goal was to explore ways in which long-range research in artificial intelligence (AI) could be applied to the fight against human trafficking. Building on the kickoff Code 8.7 conference held at the headquarters of the United Nations in February 2019, the focus for this workshop was to link the ambitious goals outlined in the A 20-Year Community Roadmap for Artificial Intelligence Research in the US (AI Roadmap) to challenges vital in achieving the UN's Sustainable Development Goal Target 8.7, the elimination of modern slavery.
Gaze-Informed Multi-Objective Imitation Learning from Human Demonstrations
Feb 25, 2021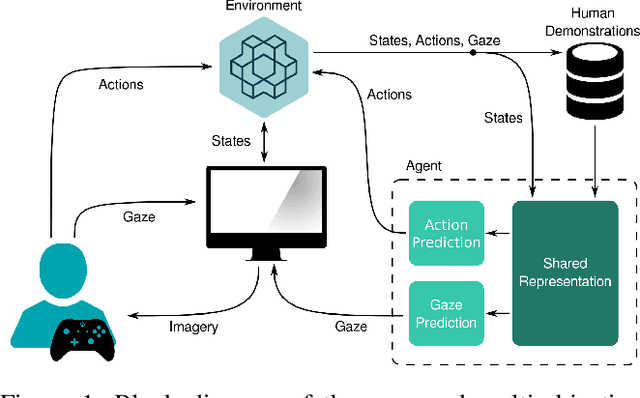
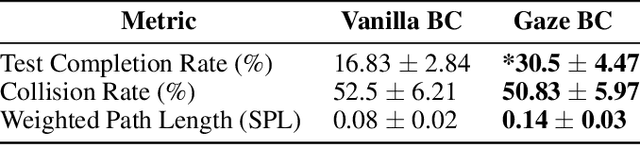
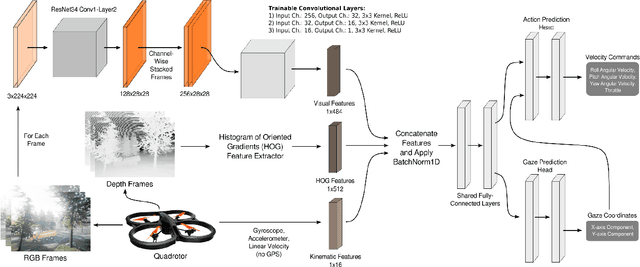

In the field of human-robot interaction, teaching learning agents from human demonstrations via supervised learning has been widely studied and successfully applied to multiple domains such as self-driving cars and robot manipulation. However, the majority of the work on learning from human demonstrations utilizes only behavioral information from the demonstrator, i.e. what actions were taken, and ignores other useful information. In particular, eye gaze information can give valuable insight towards where the demonstrator is allocating their visual attention, and leveraging such information has the potential to improve agent performance. Previous approaches have only studied the utilization of attention in simple, synchronous environments, limiting their applicability to real-world domains. This work proposes a novel imitation learning architecture to learn concurrently from human action demonstration and eye tracking data to solve tasks where human gaze information provides important context. The proposed method is applied to a visual navigation task, in which an unmanned quadrotor is trained to search for and navigate to a target vehicle in a real-world, photorealistic simulated environment. When compared to a baseline imitation learning architecture, results show that the proposed gaze augmented imitation learning model is able to learn policies that achieve significantly higher task completion rates, with more efficient paths, while simultaneously learning to predict human visual attention. This research aims to highlight the importance of multimodal learning of visual attention information from additional human input modalities and encourages the community to adopt them when training agents from human demonstrations to perform visuomotor tasks.