 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
AIP: Adversarial Iterative Pruning Based on Knowledge Transfer for Convolutional Neural Networks
Aug 31, 2021
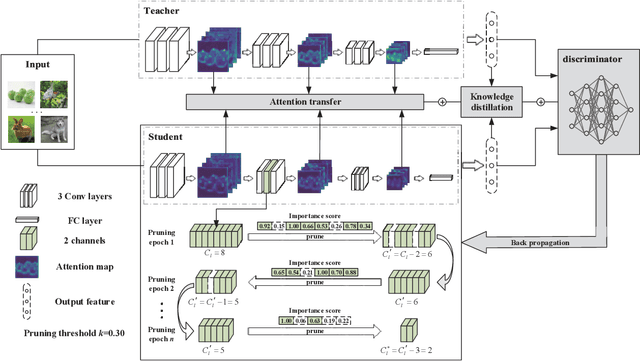
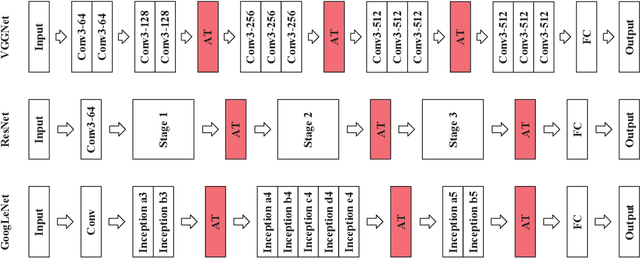
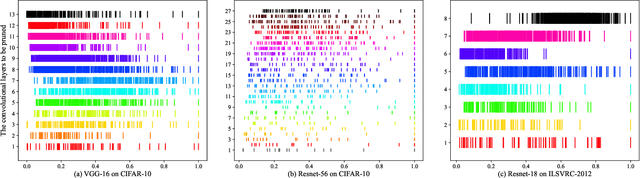
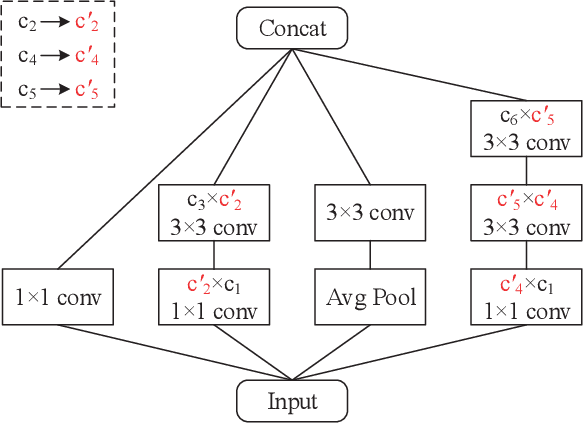
With the increase of structure complexity, convolutional neural networks (CNNs) take a fair amount of computation cost. Meanwhile, existing research reveals the salient parameter redundancy in CNNs. The current pruning methods can compress CNNs with little performance drop, but when the pruning ratio increases, the accuracy loss is more serious. Moreover, some iterative pruning methods are difficult to accurately identify and delete unimportant parameters due to the accuracy drop during pruning. We propose a novel adversarial iterative pruning method (AIP) for CNNs based on knowledge transfer. The original network is regarded as the teacher while the compressed network is the student. We apply attention maps and output features to transfer information from the teacher to the student. Then, a shallow fully-connected network is designed as the discriminator to allow the output of two networks to play an adversarial game, thereby it can quickly recover the pruned accuracy among pruning intervals. Finally, an iterative pruning scheme based on the importance of channels is proposed. We conduct extensive experiments on the image classification tasks CIFAR-10, CIFAR-100, and ILSVRC-2012 to verify our pruning method can achieve efficient compression for CNNs even without accuracy loss. On the ILSVRC-2012, when removing 36.78% parameters and 45.55% floating-point operations (FLOPs) of ResNet-18, the Top-1 accuracy drop are only 0.66%. Our method is superior to some state-of-the-art pruning schemes in terms of compressing rate and accuracy. Moreover, we further demonstrate that AIP has good generalization on the object detection task PASCAL VOC.
Topological Information-Theoretic Belief Space Planning with Optimality Guarantees
Mar 03, 2019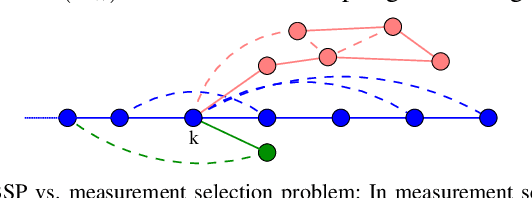
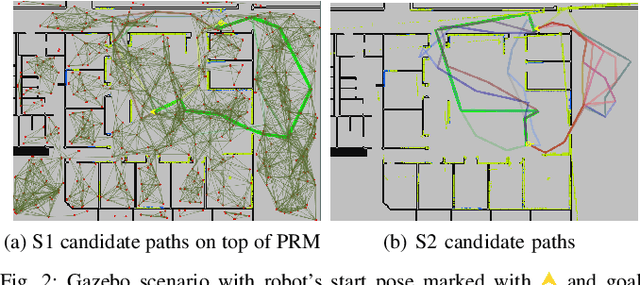
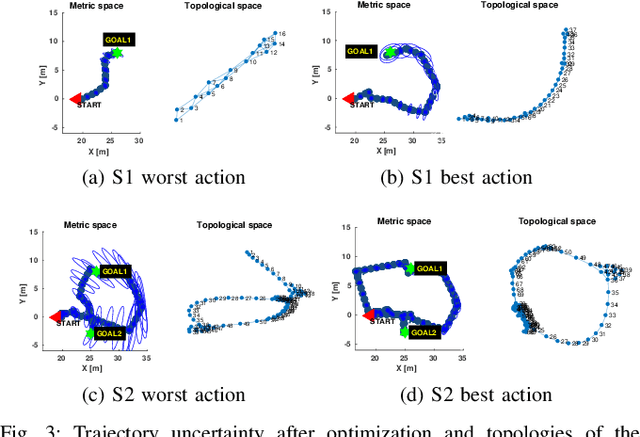
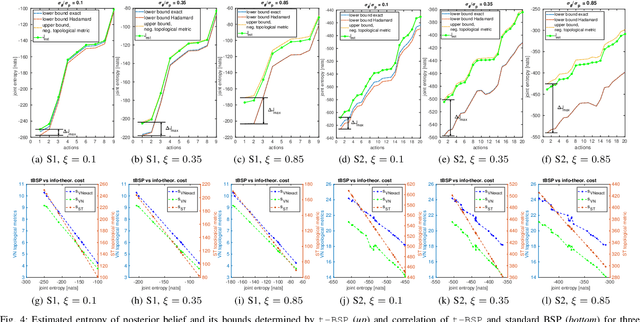
Determining a globally optimal solution of belief space planning (BSP) in high-dimensional state spaces is computationally expensive, as it involves belief propagation and objective function evaluation for each candidate action. Our recently introduced topological belief space planning t-bsp instead performs decision making considering only topologies of factor graphs that correspond to posterior future beliefs. In this paper we contribute to this body of work a novel method for efficiently determining error bounds of t-bsp, thereby providing global optimality guarantees or uncertainty margin of its solution. The bounds are given with respect to an optimal solution of information theoretic BSP considering the previously introduced topological metric which is based on the number of spanning trees. In realistic and synthetic simulations, we analyze tightness of these bounds and show empirically how this metric is closely related to another computationally more efficient t-bsp metric, an approximation of the von Neumann entropy of a graph, which can achieve online performance.
Multi-Information Source Optimization
Nov 15, 2016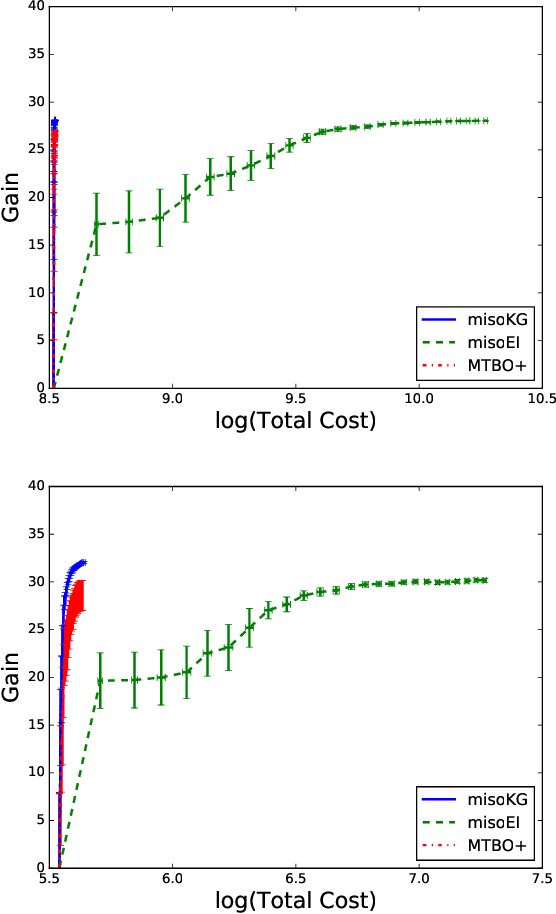

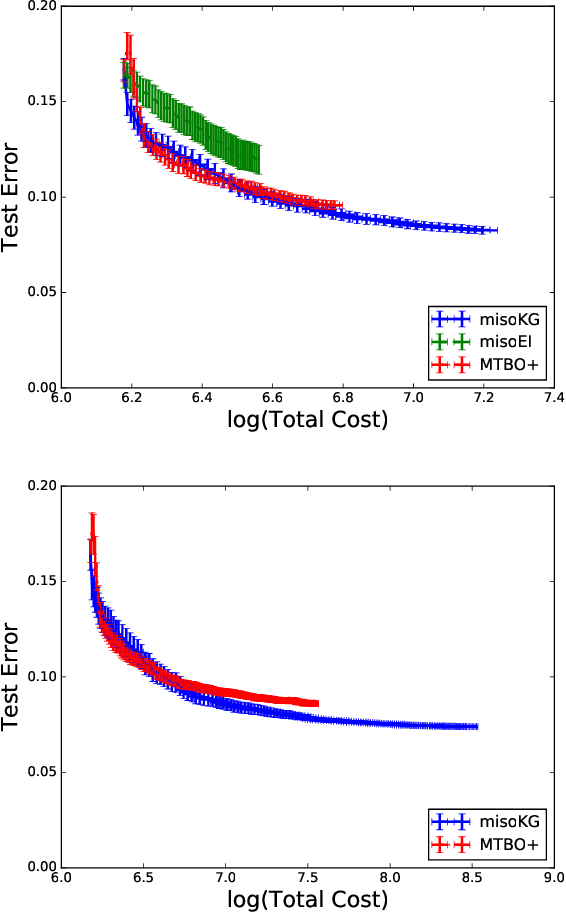
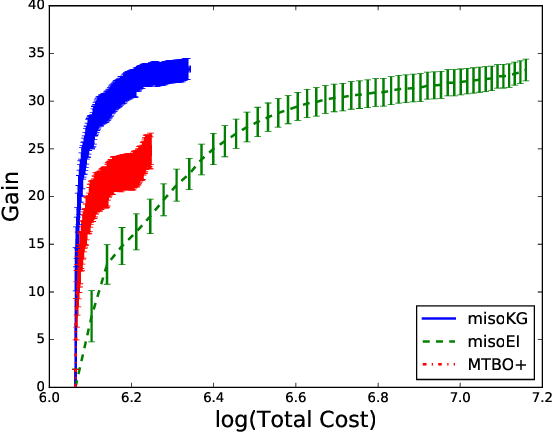
We consider Bayesian optimization of an expensive-to-evaluate black-box objective function, where we also have access to cheaper approximations of the objective. In general, such approximations arise in applications such as reinforcement learning, engineering, and the natural sciences, and are subject to an inherent, unknown bias. This model discrepancy is caused by an inadequate internal model that deviates from reality and can vary over the domain, making the utilization of these approximations a non-trivial task. We present a novel algorithm that provides a rigorous mathematical treatment of the uncertainties arising from model discrepancies and noisy observations. Its optimization decisions rely on a value of information analysis that extends the Knowledge Gradient factor to the setting of multiple information sources that vary in cost: each sampling decision maximizes the predicted benefit per unit cost. We conduct an experimental evaluation that demonstrates that the method consistently outperforms other state-of-the-art techniques: it finds designs of considerably higher objective value and additionally inflicts less cost in the exploration process.
Deep Information Propagation
Apr 04, 2017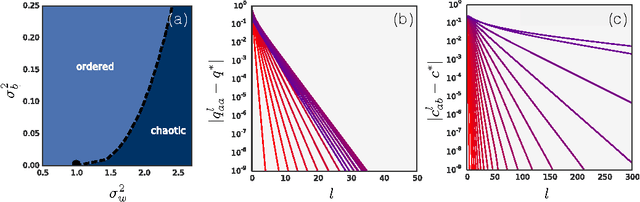
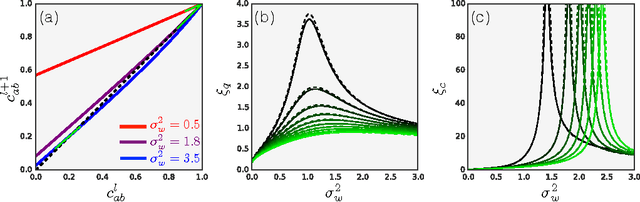
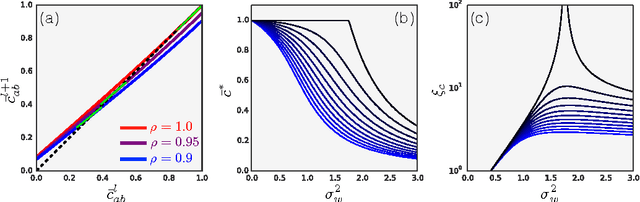
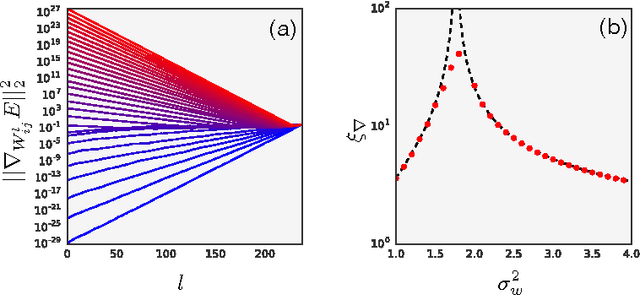
We study the behavior of untrained neural networks whose weights and biases are randomly distributed using mean field theory. We show the existence of depth scales that naturally limit the maximum depth of signal propagation through these random networks. Our main practical result is to show that random networks may be trained precisely when information can travel through them. Thus, the depth scales that we identify provide bounds on how deep a network may be trained for a specific choice of hyperparameters. As a corollary to this, we argue that in networks at the edge of chaos, one of these depth scales diverges. Thus arbitrarily deep networks may be trained only sufficiently close to criticality. We show that the presence of dropout destroys the order-to-chaos critical point and therefore strongly limits the maximum trainable depth for random networks. Finally, we develop a mean field theory for backpropagation and we show that the ordered and chaotic phases correspond to regions of vanishing and exploding gradient respectively.
Multi-Level Attention Pooling for Graph Neural Networks: Unifying Graph Representations with Multiple Localities
Mar 02, 2021


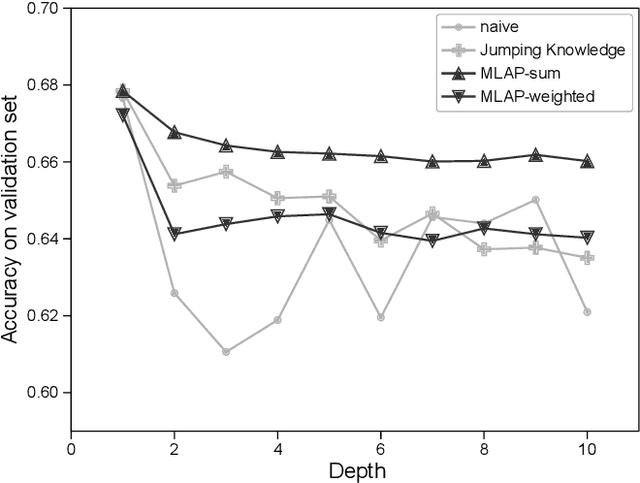
Graph neural networks (GNNs) have been widely used to learn vector representation of graph-structured data and achieved better task performance than conventional methods. The foundation of GNNs is the message passing procedure, which propagates the information in a node to its neighbors. Since this procedure proceeds one step per layer, the scope of the information propagation among nodes is small in the early layers, and it expands toward the later layers. The problem here is that the model performances degrade as the number of layers increases. A potential cause is that deep GNN models tend to lose the nodes' local information, which would be essential for good model performances, through many message passing steps. To solve this so-called oversmoothing problem, we propose a multi-level attention pooling (MLAP) architecture. It has an attention pooling layer for each message passing step and computes the final graph representation by unifying the layer-wise graph representations. The MLAP architecture allows models to utilize the structural information of graphs with multiple levels of localities because it preserves layer-wise information before losing them due to oversmoothing. Results of our experiments show that the MLAP architecture improves deeper models' performance in graph classification tasks compared to the baseline architectures. In addition, analyses on the layer-wise graph representations suggest that MLAP has the potential to learn graph representations with improved class discriminability by aggregating information with multiple levels of localities.
OSSR-PID: One-Shot Symbol Recognition in P&ID Sheets using Path Sampling and GCN
Sep 08, 2021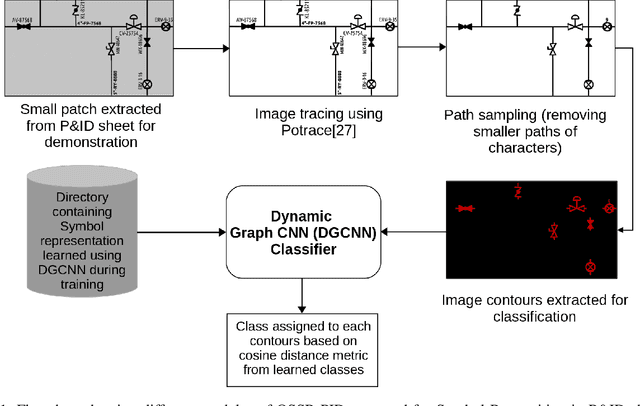
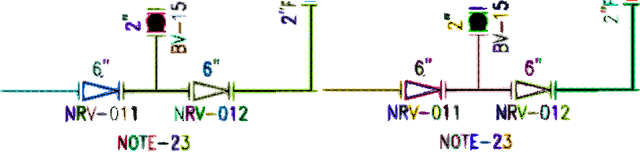

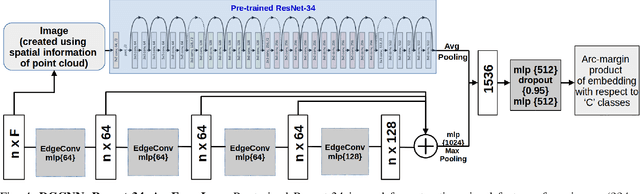
Piping and Instrumentation Diagrams (P&ID) are ubiquitous in several manufacturing, oil and gas enterprises for representing engineering schematics and equipment layout. There is an urgent need to extract and digitize information from P&IDs without the cost of annotating a varying set of symbols for each new use case. A robust one-shot learning approach for symbol recognition i.e., localization followed by classification, would therefore go a long way towards this goal. Our method works by sampling pixels sequentially along the different contour boundaries in the image. These sampled points form paths which are used in the prototypical line diagram to construct a graph that captures the structure of the contours. Subsequently, the prototypical graphs are fed into a Dynamic Graph Convolutional Neural Network (DGCNN) which is trained to classify graphs into one of the given symbol classes. Further, we append embeddings from a Resnet-34 network which is trained on symbol images containing sampled points to make the classification network more robust. Since, many symbols in P&ID are structurally very similar to each other, we utilize Arcface loss during DGCNN training which helps in maximizing symbol class separability by producing highly discriminative embeddings. The images consist of components attached on the pipeline (straight line). The sampled points segregated around the symbol regions are used for the classification task. The proposed pipeline, named OSSR-PID, is fast and gives outstanding performance for recognition of symbols on a synthetic dataset of 100 P&ID diagrams. We also compare our method against prior-work on a real-world private dataset of 12 P&ID sheets and obtain comparable/superior results. Remarkably, it is able to achieve such excellent performance using only one prototypical example per symbol.
Digitize-PID: Automatic Digitization of Piping and Instrumentation Diagrams
Sep 08, 2021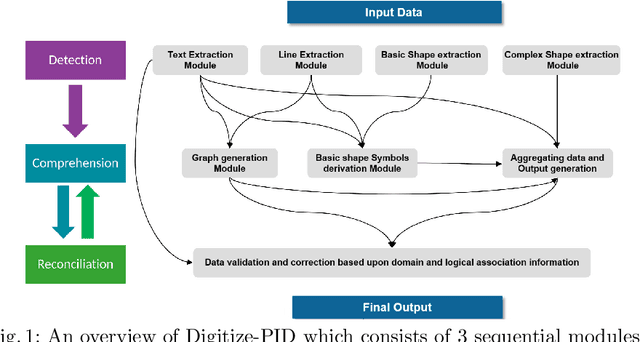
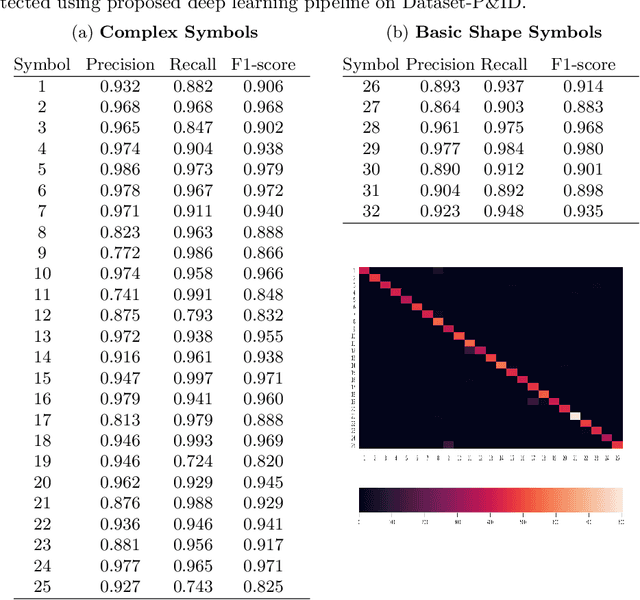
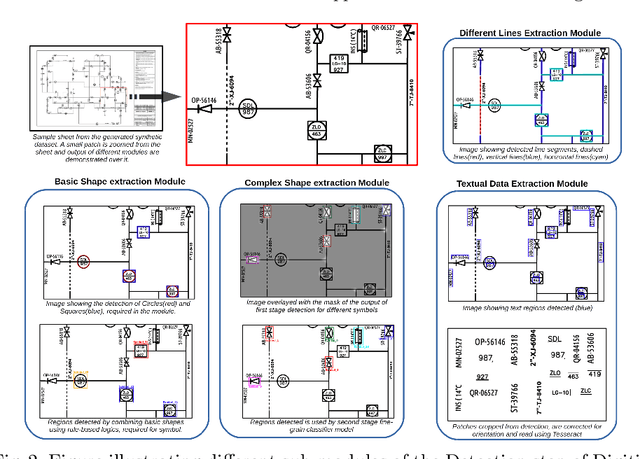
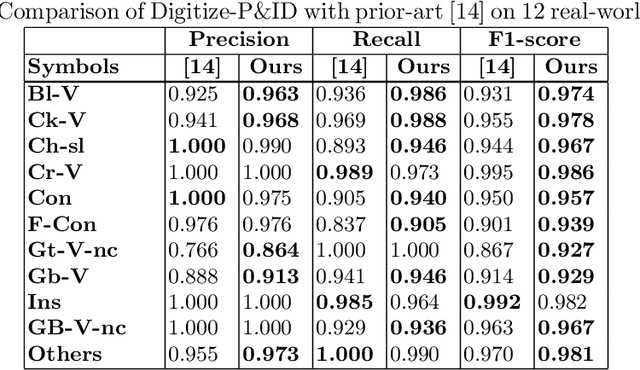
Digitization of scanned Piping and Instrumentation diagrams(P&ID), widely used in manufacturing or mechanical industries such as oil and gas over several decades, has become a critical bottleneck in dynamic inventory management and creation of smart P&IDs that are compatible with the latest CAD tools. Historically, P&ID sheets have been manually generated at the design stage, before being scanned and stored as PDFs. Current digitization initiatives involve manual processing and are consequently very time consuming, labour intensive and error-prone.Thanks to advances in image processing, machine and deep learning techniques there are emerging works on P&ID digitization. However, existing solutions face several challenges owing to the variation in the scale, size and noise in the P&IDs, sheer complexity and crowdedness within drawings, domain knowledge required to interpret the drawings. This motivates our current solution called Digitize-PID which comprises of an end-to-end pipeline for detection of core components from P&IDs like pipes, symbols and textual information, followed by their association with each other and eventually, the validation and correction of output data based on inherent domain knowledge. A novel and efficient kernel-based line detection and a two-step method for detection of complex symbols based on a fine-grained deep recognition technique is presented in the paper. In addition, we have created an annotated synthetic dataset, Dataset-P&ID, of 500 P&IDs by incorporating different types of noise and complex symbols which is made available for public use (currently there exists no public P&ID dataset). We evaluate our proposed method on this synthetic dataset and a real-world anonymized private dataset of 12 P&ID sheets. Results show that Digitize-PID outperforms the existing state-of-the-art for P&ID digitization.
* 13 pages
FIDNet: LiDAR Point Cloud Semantic Segmentation with Fully Interpolation Decoding
Sep 08, 2021

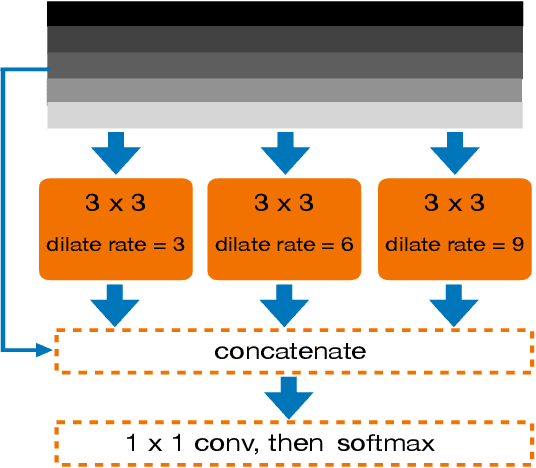

Projecting the point cloud on the 2D spherical range image transforms the LiDAR semantic segmentation to a 2D segmentation task on the range image. However, the LiDAR range image is still naturally different from the regular 2D RGB image; for example, each position on the range image encodes the unique geometry information. In this paper, we propose a new projection-based LiDAR semantic segmentation pipeline that consists of a novel network structure and an efficient post-processing step. In our network structure, we design a FID (fully interpolation decoding) module that directly upsamples the multi-resolution feature maps using bilinear interpolation. Inspired by the 3D distance interpolation used in PointNet++, we argue this FID module is a 2D version distance interpolation on $(\theta, \phi)$ space. As a parameter-free decoding module, the FID largely reduces the model complexity by maintaining good performance. Besides the network structure, we empirically find that our model predictions have clear boundaries between different semantic classes. This makes us rethink whether the widely used K-nearest-neighbor post-processing is still necessary for our pipeline. Then, we realize the many-to-one mapping causes the blurring effect that some points are mapped into the same pixel and share the same label. Therefore, we propose to process those occluded points by assigning the nearest predicted label to them. This NLA (nearest label assignment) post-processing step shows a better performance than KNN with faster inference speed in the ablation study. On the SemanticKITTI dataset, our pipeline achieves the best performance among all projection-based methods with $64 \times 2048$ resolution and all point-wise solutions. With a ResNet-34 as the backbone, both the training and testing of our model can be finished on a single RTX 2080 Ti with 11G memory. The code is released.
Continuous-Time Sequential Recommendation with Temporal Graph Collaborative Transformer
Aug 14, 2021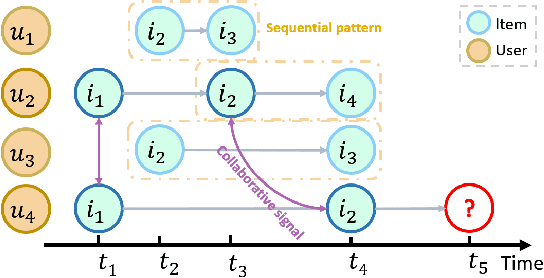
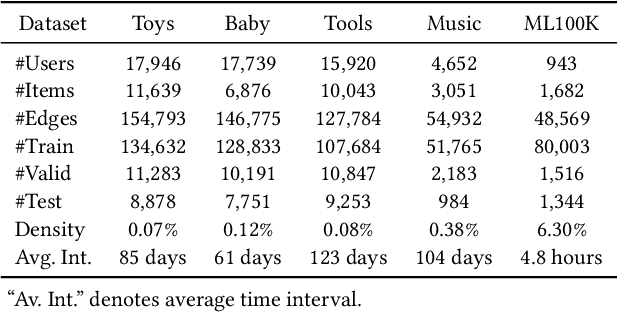
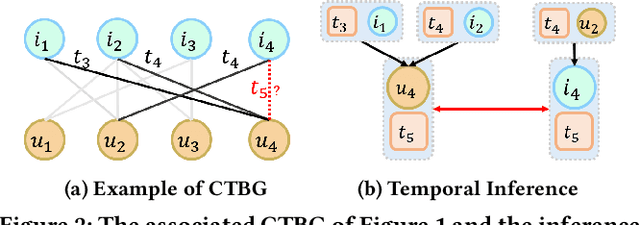
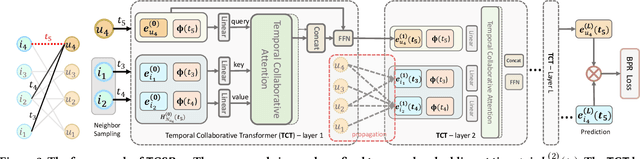
In order to model the evolution of user preference, we should learn user/item embeddings based on time-ordered item purchasing sequences, which is defined as Sequential Recommendation (SR) problem. Existing methods leverage sequential patterns to model item transitions. However, most of them ignore crucial temporal collaborative signals, which are latent in evolving user-item interactions and coexist with sequential patterns. Therefore, we propose to unify sequential patterns and temporal collaborative signals to improve the quality of recommendation, which is rather challenging. Firstly, it is hard to simultaneously encode sequential patterns and collaborative signals. Secondly, it is non-trivial to express the temporal effects of collaborative signals. Hence, we design a new framework Temporal Graph Sequential Recommender (TGSRec) upon our defined continuous-time bi-partite graph. We propose a novel Temporal Collaborative Trans-former (TCT) layer in TGSRec, which advances the self-attention mechanism by adopting a novel collaborative attention. TCT layer can simultaneously capture collaborative signals from both users and items, as well as considering temporal dynamics inside sequential patterns. We propagate the information learned fromTCTlayerover the temporal graph to unify sequential patterns and temporal collaborative signals. Empirical results on five datasets show that TGSRec significantly outperforms other baselines, in average up to 22.5% and 22.1%absolute improvements in Recall@10and MRR, respectively.
Comprehensive Studies for Arbitrary-shape Scene Text Detection
Jul 25, 2021
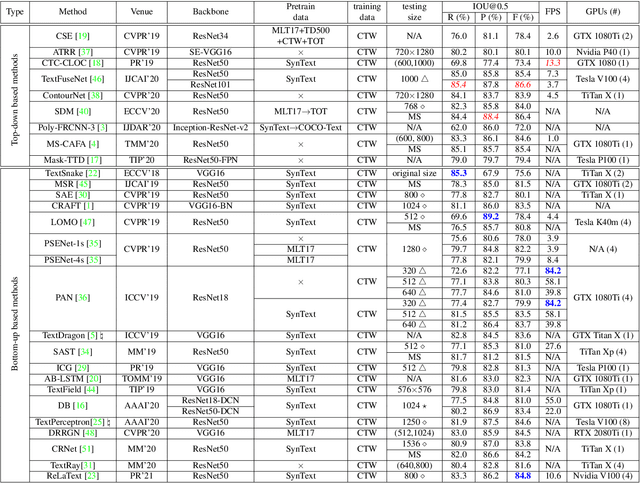
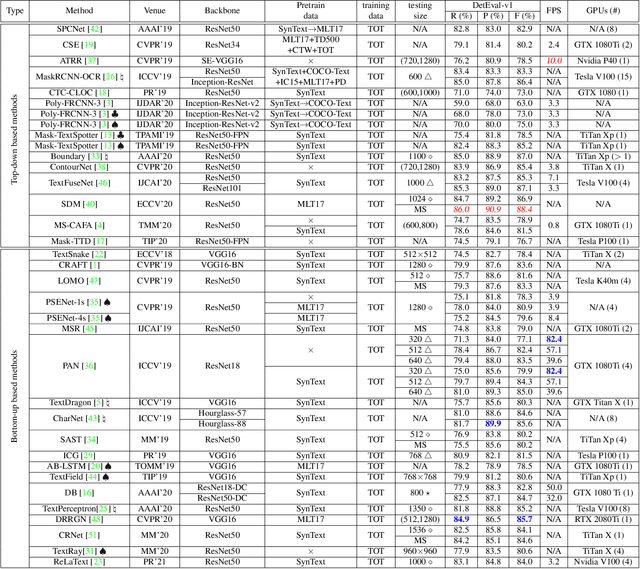

Numerous scene text detection methods have been proposed in recent years. Most of them declare they have achieved state-of-the-art performances. However, the performance comparison is unfair, due to lots of inconsistent settings (e.g., training data, backbone network, multi-scale feature fusion, evaluation protocols, etc.). These various settings would dissemble the pros and cons of the proposed core techniques. In this paper, we carefully examine and analyze the inconsistent settings, and propose a unified framework for the bottom-up based scene text detection methods. Under the unified framework, we ensure the consistent settings for non-core modules, and mainly investigate the representations of describing arbitrary-shape scene texts, e.g., regressing points on text contours, clustering pixels with predicted auxiliary information, grouping connected components with learned linkages, etc. With the comprehensive investigations and elaborate analyses, it not only cleans up the obstacle of understanding the performance differences between existing methods but also reveals the advantages and disadvantages of previous models under fair comparisons.