 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Multi-Information Source Optimization
Nov 15, 2016
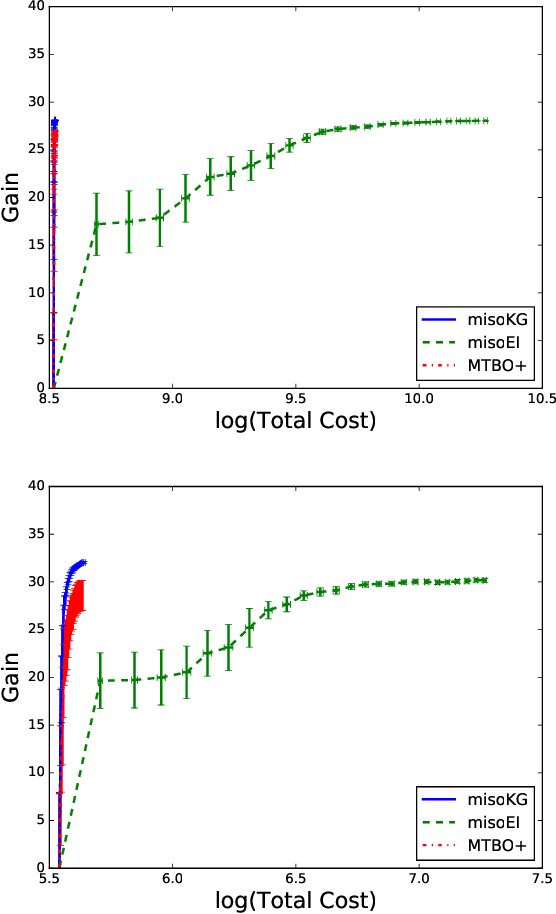

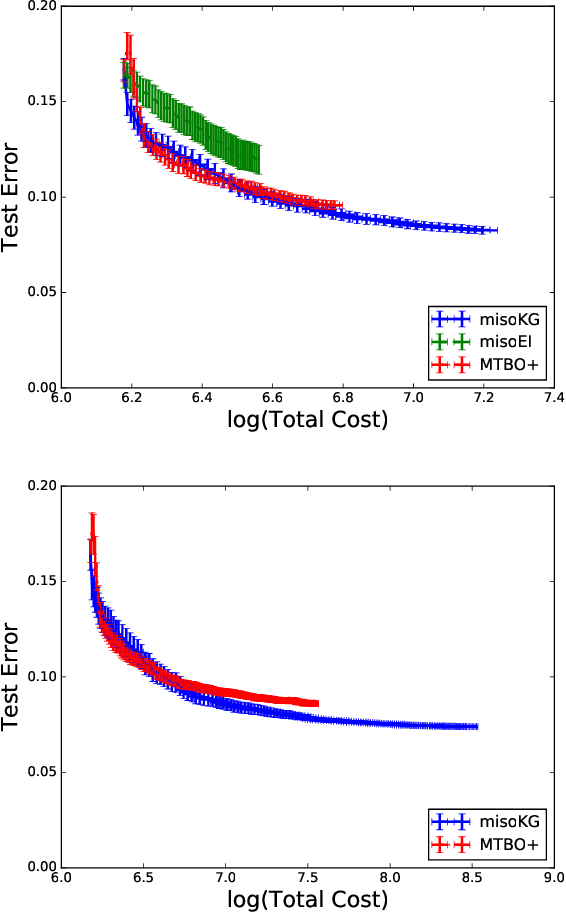
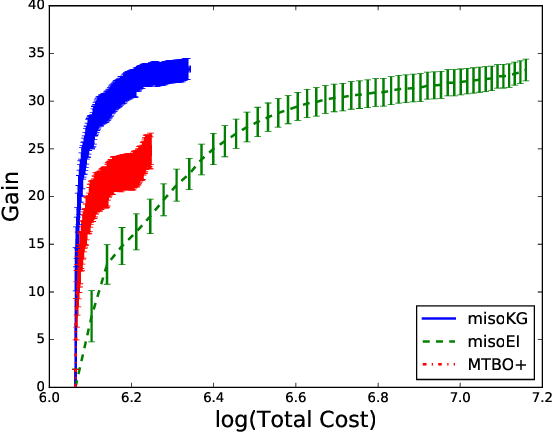
We consider Bayesian optimization of an expensive-to-evaluate black-box objective function, where we also have access to cheaper approximations of the objective. In general, such approximations arise in applications such as reinforcement learning, engineering, and the natural sciences, and are subject to an inherent, unknown bias. This model discrepancy is caused by an inadequate internal model that deviates from reality and can vary over the domain, making the utilization of these approximations a non-trivial task. We present a novel algorithm that provides a rigorous mathematical treatment of the uncertainties arising from model discrepancies and noisy observations. Its optimization decisions rely on a value of information analysis that extends the Knowledge Gradient factor to the setting of multiple information sources that vary in cost: each sampling decision maximizes the predicted benefit per unit cost. We conduct an experimental evaluation that demonstrates that the method consistently outperforms other state-of-the-art techniques: it finds designs of considerably higher objective value and additionally inflicts less cost in the exploration process.
Modified Supervised Contrastive Learning for Detecting Anomalous Driving Behaviours
Sep 09, 2021


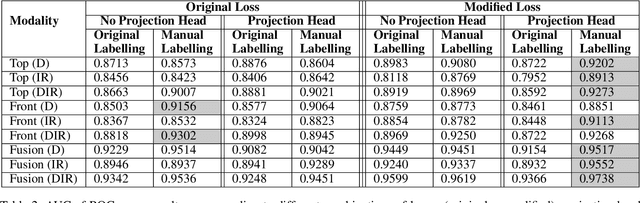
Detecting distracted driving behaviours is important to reduce millions of deaths and injuries occurring worldwide. Distracted or anomalous driving behaviours are deviations from the 'normal' driving that need to be identified correctly to alert the driver. However, these driving behaviours do not comprise of one specific type of driving style and their distribution can be different during training and testing phases of a classifier. We formulate this problem as a supervised contrastive learning approach to learn a visual representation to detect normal, and seen and unseen anomalous driving behaviours. We made a change to the standard contrastive loss function to adjust the similarity of negative pairs to aid the optimization. Normally, the (self) supervised contrastive framework contains an encoder followed by a projection head, which is omitted during testing phase as the encoding layers are considered to contain general visual representative information. However, we assert that for supervised contrastive learning task, including projection head will be beneficial. We showed our results on a Driver Anomaly Detection dataset that contains 783 minutes of video recordings of normal and anomalous driving behaviours of 31 drivers from various from top and front cameras (both depth and infrared). We also performed an extra step of fine tuning the labels in this dataset. Out of 9 video modalities combinations, our modified contrastive approach improved the ROC AUC on 7 in comparison to the baseline models (from 3.12% to 8.91% for different modalities); the remaining two models also had manual labelling. We performed statistical tests that showed evidence that our modifications perform better than the baseline contrastive models. Finally, the results showed that the fusion of depth and infrared modalities from top and front view achieved the best AUC ROC of 0.9738 and AUC PR of 0.9772.
Topological Information-Theoretic Belief Space Planning with Optimality Guarantees
Mar 03, 2019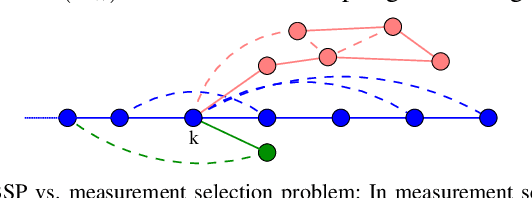
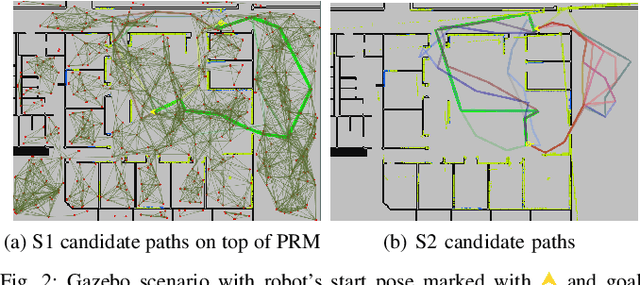
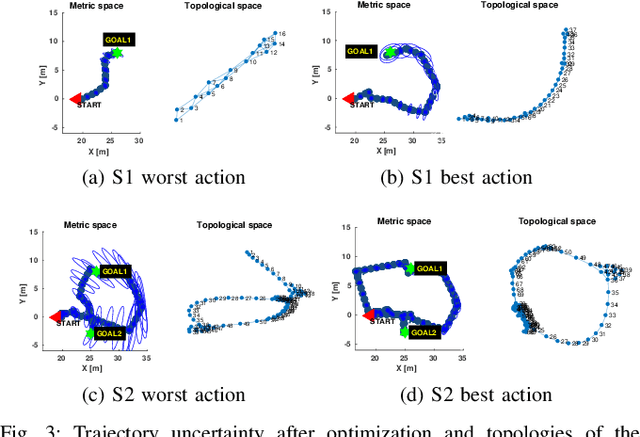
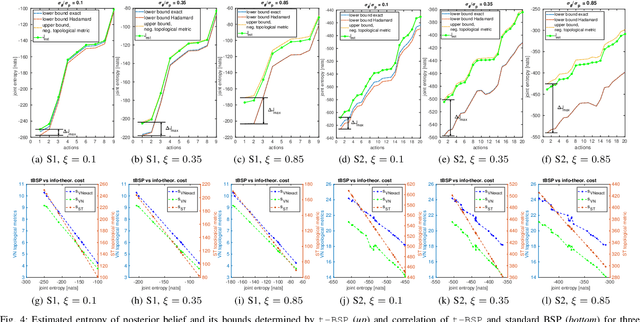
Determining a globally optimal solution of belief space planning (BSP) in high-dimensional state spaces is computationally expensive, as it involves belief propagation and objective function evaluation for each candidate action. Our recently introduced topological belief space planning t-bsp instead performs decision making considering only topologies of factor graphs that correspond to posterior future beliefs. In this paper we contribute to this body of work a novel method for efficiently determining error bounds of t-bsp, thereby providing global optimality guarantees or uncertainty margin of its solution. The bounds are given with respect to an optimal solution of information theoretic BSP considering the previously introduced topological metric which is based on the number of spanning trees. In realistic and synthetic simulations, we analyze tightness of these bounds and show empirically how this metric is closely related to another computationally more efficient t-bsp metric, an approximation of the von Neumann entropy of a graph, which can achieve online performance.
PoissonSeg: Semi-Supervised Few-Shot Medical Image Segmentation via Poisson Learning
Aug 26, 2021
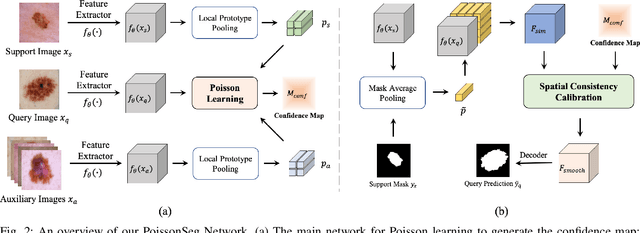
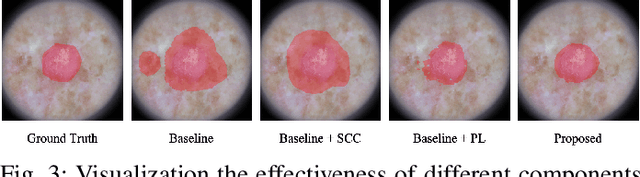
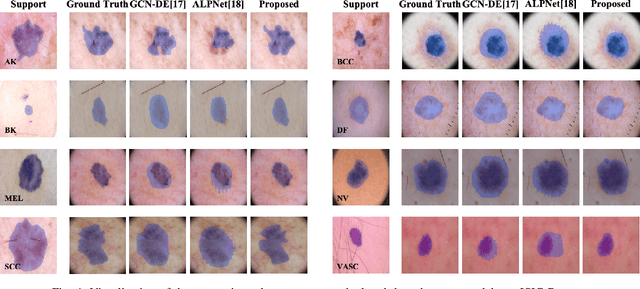
The application of deep learning to medical image segmentation has been hampered due to the lack of abundant pixel-level annotated data. Few-shot Semantic Segmentation (FSS) is a promising strategy for breaking the deadlock. However, a high-performing FSS model still requires sufficient pixel-level annotated classes for training to avoid overfitting, which leads to its performance bottleneck in medical image segmentation due to the unmet need for annotations. Thus, semi-supervised FSS for medical images is accordingly proposed to utilize unlabeled data for further performance improvement. Nevertheless, existing semi-supervised FSS methods has two obvious defects: (1) neglecting the relationship between the labeled and unlabeled data; (2) using unlabeled data directly for end-to-end training leads to degenerated representation learning. To address these problems, we propose a novel semi-supervised FSS framework for medical image segmentation. The proposed framework employs Poisson learning for modeling data relationship and propagating supervision signals, and Spatial Consistency Calibration for encouraging the model to learn more coherent representations. In this process, unlabeled samples do not involve in end-to-end training, but provide supervisory information for query image segmentation through graph-based learning. We conduct extensive experiments on three medical image segmentation datasets (i.e. ISIC skin lesion segmentation, abdominal organs segmentation for MRI and abdominal organs segmentation for CT) to demonstrate the state-of-the-art performance and broad applicability of the proposed framework.
Deep Information Propagation
Apr 04, 2017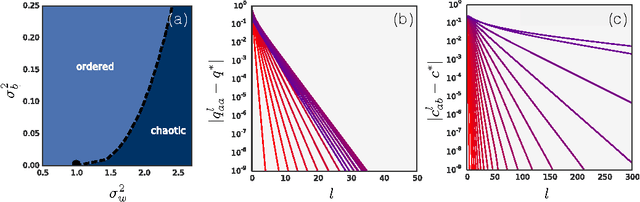
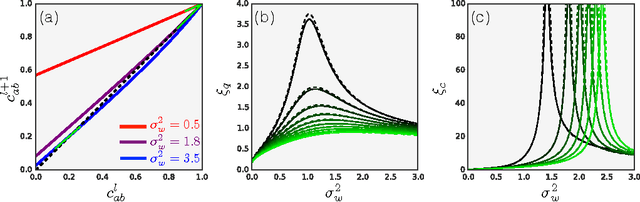
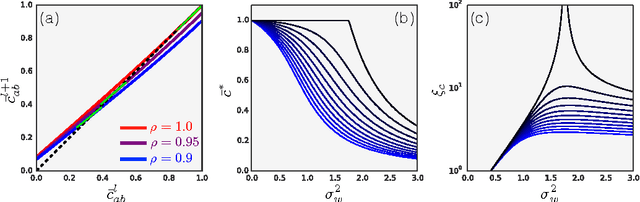
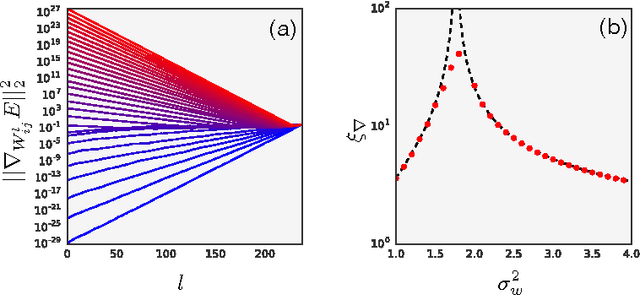
We study the behavior of untrained neural networks whose weights and biases are randomly distributed using mean field theory. We show the existence of depth scales that naturally limit the maximum depth of signal propagation through these random networks. Our main practical result is to show that random networks may be trained precisely when information can travel through them. Thus, the depth scales that we identify provide bounds on how deep a network may be trained for a specific choice of hyperparameters. As a corollary to this, we argue that in networks at the edge of chaos, one of these depth scales diverges. Thus arbitrarily deep networks may be trained only sufficiently close to criticality. We show that the presence of dropout destroys the order-to-chaos critical point and therefore strongly limits the maximum trainable depth for random networks. Finally, we develop a mean field theory for backpropagation and we show that the ordered and chaotic phases correspond to regions of vanishing and exploding gradient respectively.
PoseDet: Fast Multi-Person Pose Estimation Using Pose Embedding
Jul 22, 2021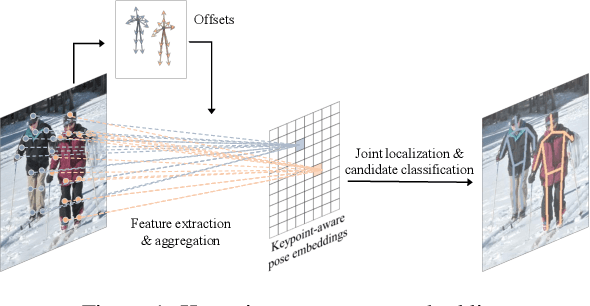
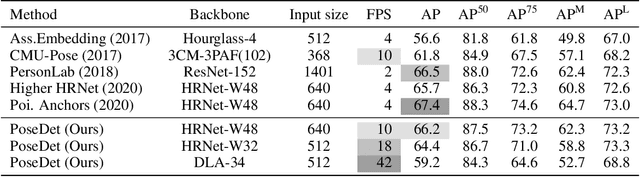
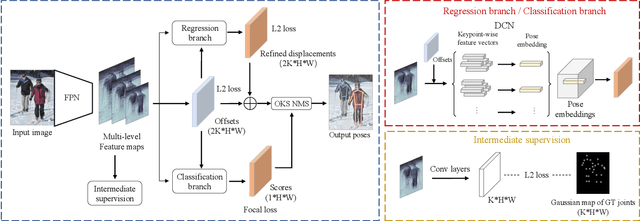
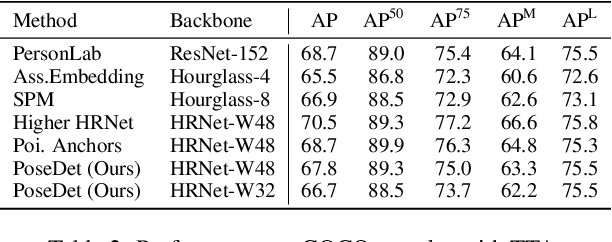
Current methods of multi-person pose estimation typically treat the localization and the association of body joints separately. It is convenient but inefficient, leading to additional computation and a waste of time. This paper, however, presents a novel framework PoseDet (Estimating Pose by Detection) to localize and associate body joints simultaneously at higher inference speed. Moreover, we propose the keypoint-aware pose embedding to represent an object in terms of the locations of its keypoints. The proposed pose embedding contains semantic and geometric information, allowing us to access discriminative and informative features efficiently. It is utilized for candidate classification and body joint localization in PoseDet, leading to robust predictions of various poses. This simple framework achieves an unprecedented speed and a competitive accuracy on the COCO benchmark compared with state-of-the-art methods. Extensive experiments on the CrowdPose benchmark show the robustness in the crowd scenes. Source code is available.
User-Generated Text Corpus for Evaluating Japanese Morphological Analysis and Lexical Normalization
Apr 08, 2021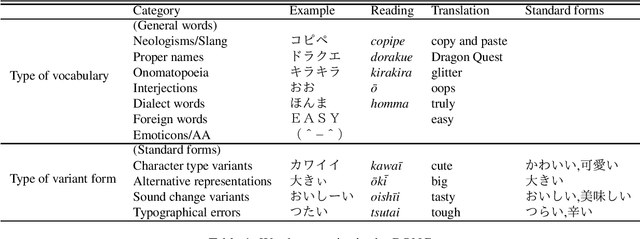
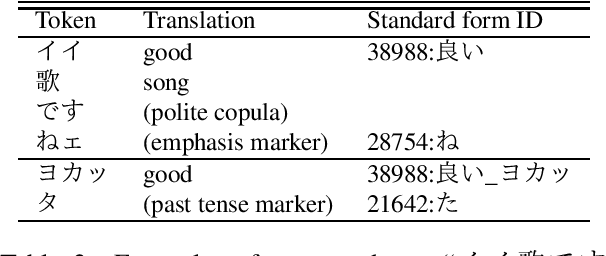

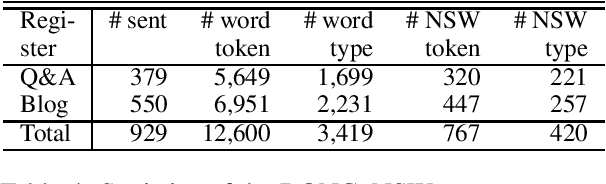
Morphological analysis (MA) and lexical normalization (LN) are both important tasks for Japanese user-generated text (UGT). To evaluate and compare different MA/LN systems, we have constructed a publicly available Japanese UGT corpus. Our corpus comprises 929 sentences annotated with morphological and normalization information, along with category information we classified for frequent UGT-specific phenomena. Experiments on the corpus demonstrated the low performance of existing MA/LN methods for non-general words and non-standard forms, indicating that the corpus would be a challenging benchmark for further research on UGT.
Whittle Index for A Class of Restless Bandits with Imperfect Observations
Aug 09, 2021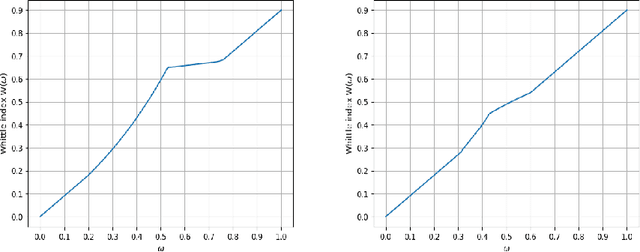
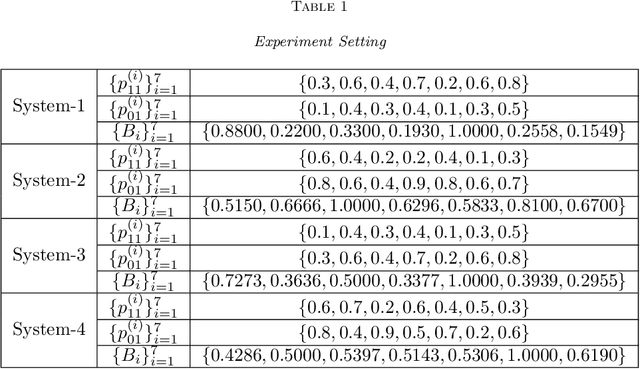
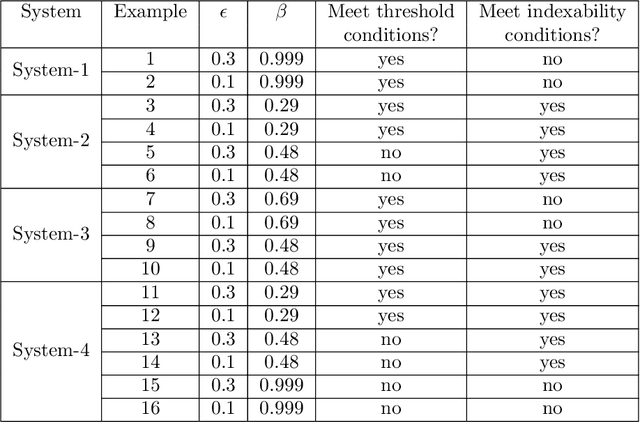
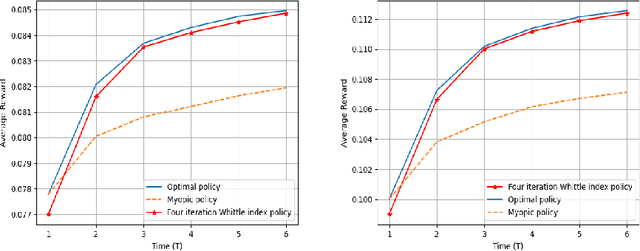
We consider a class of restless bandit problems that finds a broad application area in stochastic optimization, reinforcement learning and operations research. In our model, there are $N$ independent $2$-state Markov processes that may be observed and accessed for accruing rewards. The observation is error-prone, i.e., both false alarm and miss detection may happen. Furthermore, the user can only choose a subset of $M~(M<N)$ processes to observe at each discrete time. If a process in state~$1$ is correctly observed, then it will offer some reward. Due to the partial and imperfect observation model, the system is formulated as a restless multi-armed bandit problem with an information state space of uncountable cardinality. Restless bandit problems with finite state spaces are PSPACE-HARD in general. In this paper, we establish a low-complexity algorithm that achieves a strong performance for this class of restless bandits. Under certain conditions, we theoretically prove the existence (indexability) of Whittle index and its equivalence to our algorithm. When those conditions do not hold, we show by numerical experiments the near-optimal performance of our algorithm in general.
A Large-Scale Rich Context Query and Recommendation Dataset in Online Knowledge-Sharing
Jun 11, 2021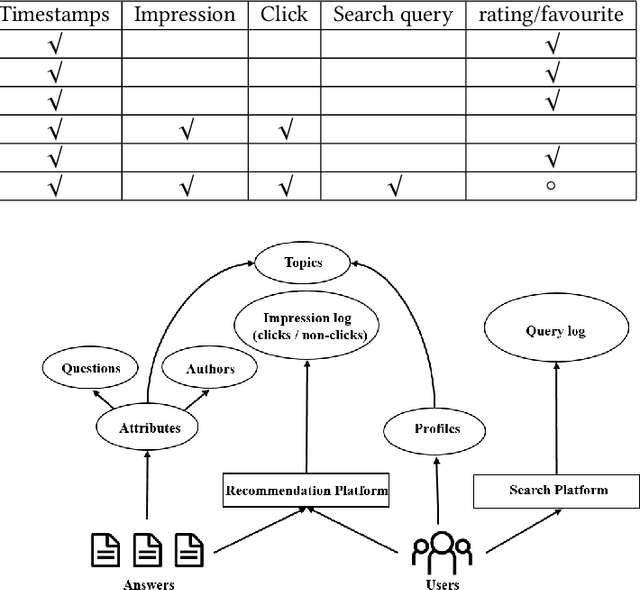
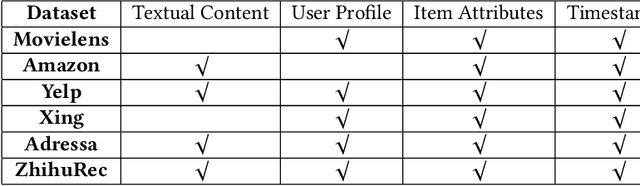

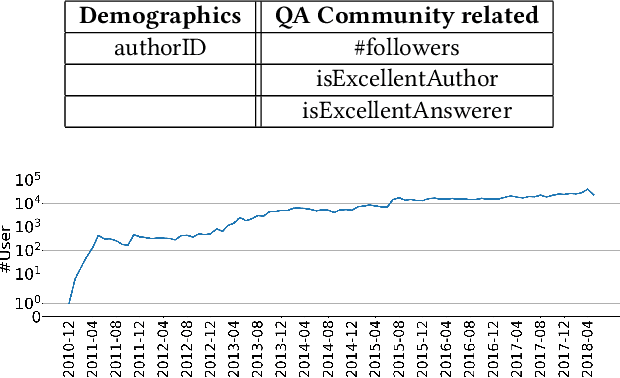
Data plays a vital role in machine learning studies. In the research of recommendation, both user behaviors and side information are helpful to model users. So, large-scale real scenario datasets with abundant user behaviors will contribute a lot. However, it is not easy to get such datasets as most of them are only hold and protected by companies. In this paper, a new large-scale dataset collected from a knowledge-sharing platform is presented, which is composed of around 100M interactions collected within 10 days, 798K users, 165K questions, 554K answers, 240K authors, 70K topics, and more than 501K user query keywords. There are also descriptions of users, answers, questions, authors, and topics, which are anonymous. Note that each user's latest query keywords have not been included in previous open datasets, which reveal users' explicit information needs. We characterize the dataset and demonstrate its potential applications for recommendation study. Multiple experiments show the dataset can be used to evaluate algorithms in general top-N recommendation, sequential recommendation, and context-aware recommendation. This dataset can also be used to integrate search and recommendation and recommendation with negative feedback. Besides, tasks beyond recommendation, such as user gender prediction, most valuable answerer identification, and high-quality answer recognition, can also use this dataset. To the best of our knowledge, this is the largest real-world interaction dataset for personalized recommendation.
Learning Robust Latent Representations for Controllable Speech Synthesis
May 10, 2021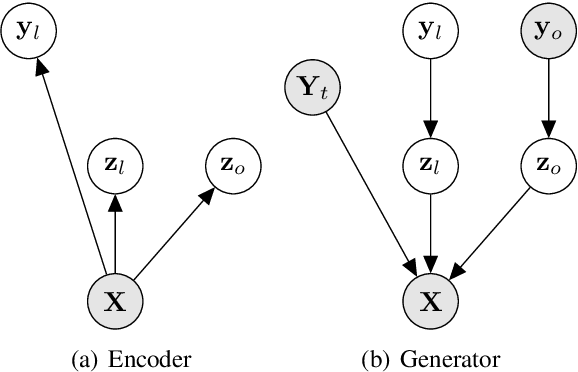
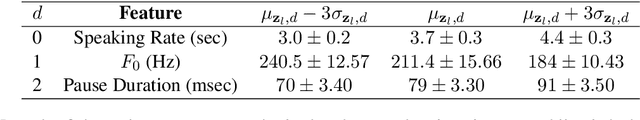
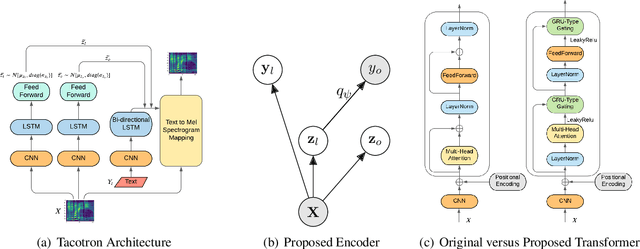

State-of-the-art Variational Auto-Encoders (VAEs) for learning disentangled latent representations give impressive results in discovering features like pitch, pause duration, and accent in speech data, leading to highly controllable text-to-speech (TTS) synthesis. However, these LSTM-based VAEs fail to learn latent clusters of speaker attributes when trained on either limited or noisy datasets. Further, different latent variables start encoding the same features, limiting the control and expressiveness during speech synthesis. To resolve these issues, we propose RTI-VAE (Reordered Transformer with Information reduction VAE) where we minimize the mutual information between different latent variables and devise a modified Transformer architecture with layer reordering to learn controllable latent representations in speech data. We show that RTI-VAE reduces the cluster overlap of speaker attributes by at least 30\% over LSTM-VAE and by at least 7\% over vanilla Transformer-VAE.