 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
LeafMask: Towards Greater Accuracy on Leaf Segmentation
Aug 08, 2021

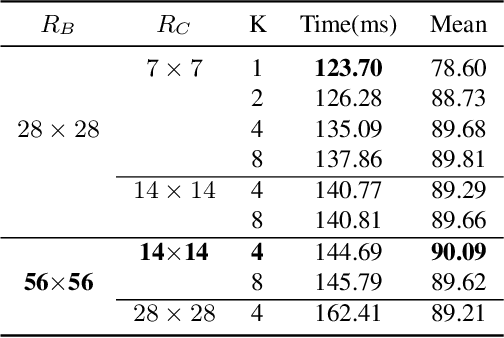
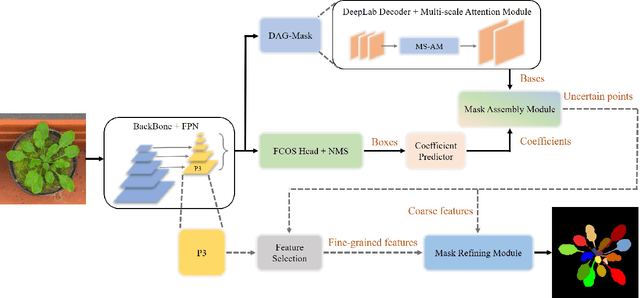
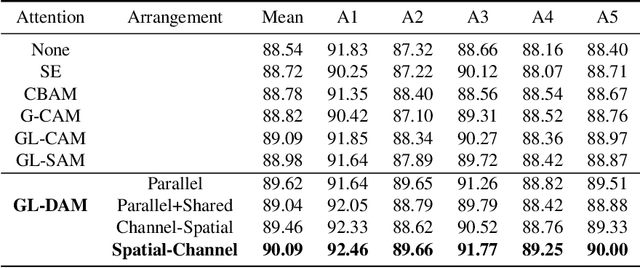
Leaf segmentation is the most direct and effective way for high-throughput plant phenotype data analysis and quantitative researches of complex traits. Currently, the primary goal of plant phenotyping is to raise the accuracy of the autonomous phenotypic measurement. In this work, we present the LeafMask neural network, a new end-to-end model to delineate each leaf region and count the number of leaves, with two main components: 1) the mask assembly module merging position-sensitive bases of each predicted box after non-maximum suppression (NMS) and corresponding coefficients to generate original masks; 2) the mask refining module elaborating leaf boundaries from the mask assembly module by the point selection strategy and predictor. In addition, we also design a novel and flexible multi-scale attention module for the dual attention-guided mask (DAG-Mask) branch to effectively enhance information expression and produce more accurate bases. Our main contribution is to generate the final improved masks by combining the mask assembly module with the mask refining module under the anchor-free instance segmentation paradigm. We validate our LeafMask through extensive experiments on Leaf Segmentation Challenge (LSC) dataset. Our proposed model achieves the 90.09% BestDice score outperforming other state-of-the-art approaches.
Spatial Correlation Aware Compressed Sensing for User Activity Detection and Channel Estimation in Massive MTC
Apr 17, 2021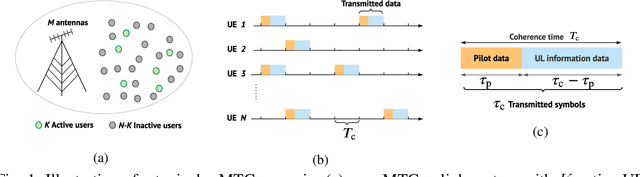
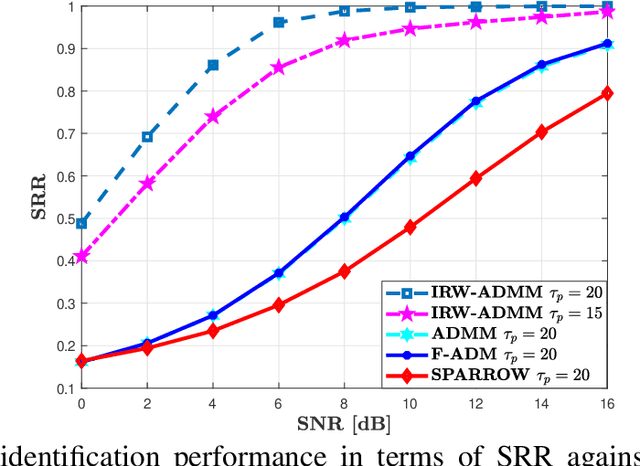
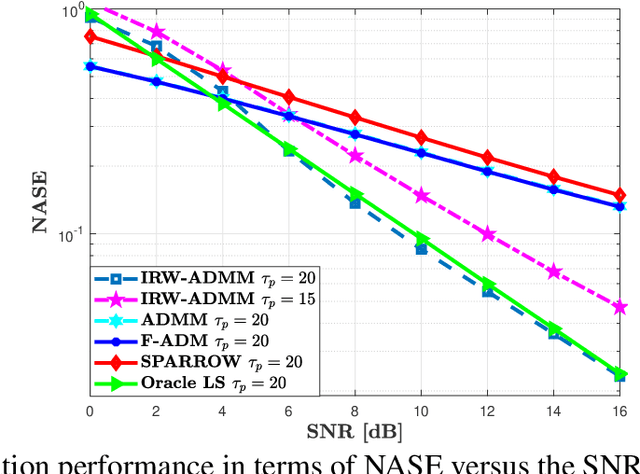
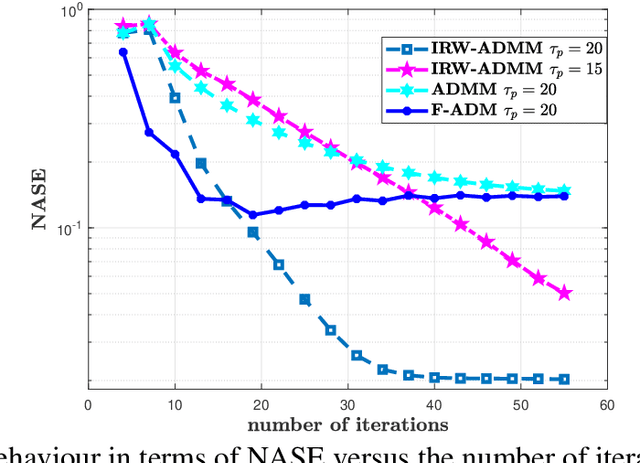
Grant-free access is considered as a key enabler to massive machine-type communications (mMTC) as it promotes energy-efficiency and small signalling overhead. Due to the sporadic user activity in mMTC, joint user identification and channel estimation (JUICE) is a main challenge. This paper addresses the JUICE in single-cell mMTC with single-antenna users and a multi-antenna base station (BS) under spatially correlated fading channels. In particular, by leveraging the sporadic user activity, we solve the JUICE in a multi measurement vector compressed sensing (CS) framework under two different cases, with and without the knowledge of prior channel distribution information (CDI) at the BS. First, for the case without prior information, we formulate the JUICE as an iterative reweighted $\ell_{2,1}$-norm minimization problem. Second, when the CDI is known to the BS, we exploit the available information and formulate the JUICE from a Bayesian estimation perspective as a maximum \emph{a posteriori} probability (MAP) estimation problem. For both JUICE formulations, we derive efficient iterative solutions based on the alternating direction method of multipliers (ADMM). The numerical experiments show that the proposed solutions achieve higher channel estimation quality and activity detection accuracy with shorter pilot sequences compared to existing algorithms.
Attention! Stay Focus!
Apr 16, 2021

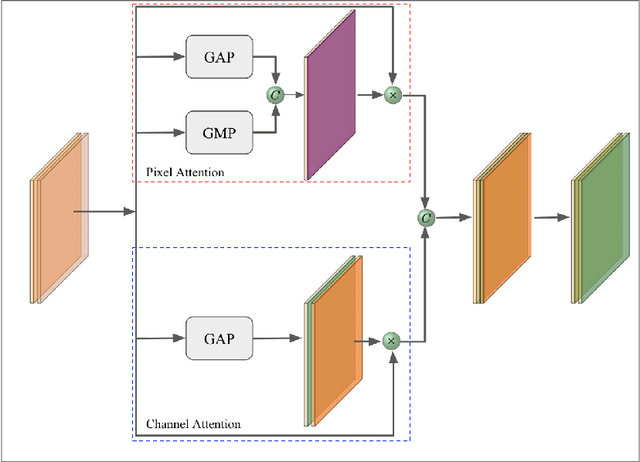
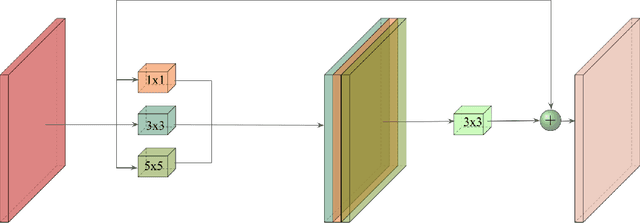
We develop a deep convolutional neural networks(CNNs) to deal with the blurry artifacts caused by the defocus of the camera using dual-pixel images. Specifically, we develop a double attention network which consists of attentional encoders, triple locals and global local modules to effectively extract useful information from each image in the dual-pixels and select the useful information from each image and synthesize the final output image. We demonstrate the effectiveness of the proposed deblurring algorithm in terms of both qualitative and quantitative aspects by evaluating on the test set in the NTIRE 2021 Defocus Deblurring using Dual-pixel Images Challenge. The code, and trained models are available at https://github.com/tuvovan/ATTSF.
HRegNet: A Hierarchical Network for Large-scale Outdoor LiDAR Point Cloud Registration
Jul 26, 2021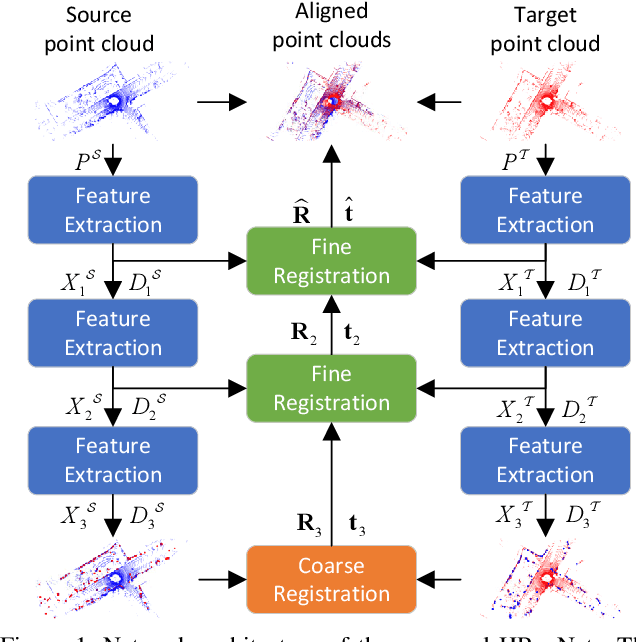
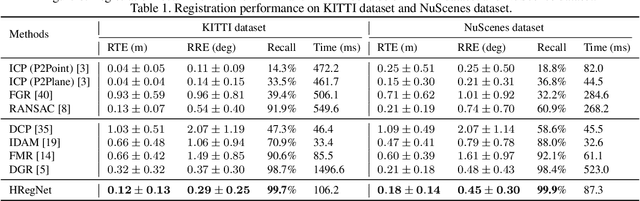
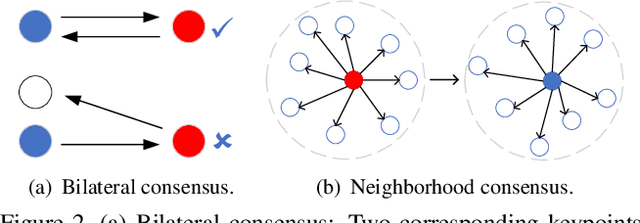
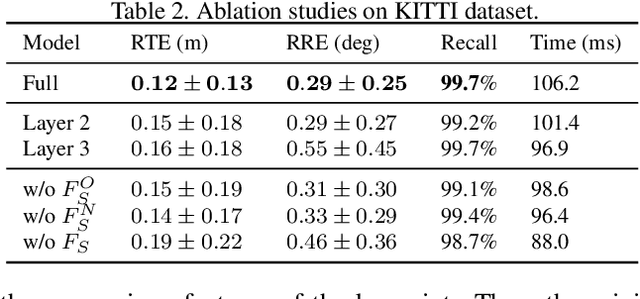
Point cloud registration is a fundamental problem in 3D computer vision. Outdoor LiDAR point clouds are typically large-scale and complexly distributed, which makes the registration challenging. In this paper, we propose an efficient hierarchical network named HRegNet for large-scale outdoor LiDAR point cloud registration. Instead of using all points in the point clouds, HRegNet performs registration on hierarchically extracted keypoints and descriptors. The overall framework combines the reliable features in deeper layer and the precise position information in shallower layers to achieve robust and precise registration. We present a correspondence network to generate correct and accurate keypoints correspondences. Moreover, bilateral consensus and neighborhood consensus are introduced for keypoints matching and novel similarity features are designed to incorporate them into the correspondence network, which significantly improves the registration performance. Besides, the whole network is also highly efficient since only a small number of keypoints are used for registration. Extensive experiments are conducted on two large-scale outdoor LiDAR point cloud datasets to demonstrate the high accuracy and efficiency of the proposed HRegNet. The project website is https://ispc-group.github.io/hregnet.
Self-Attentive Ensemble Transformer: Representing Ensemble Interactions in Neural Networks for Earth System Models
Jul 10, 2021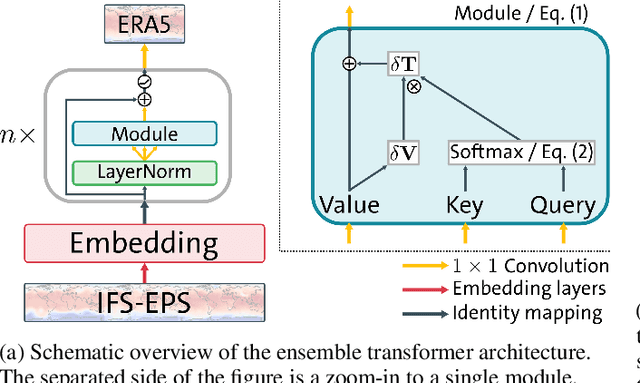
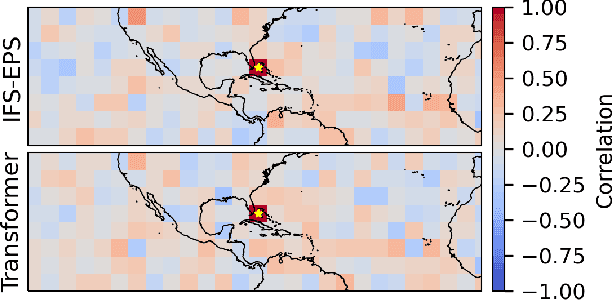
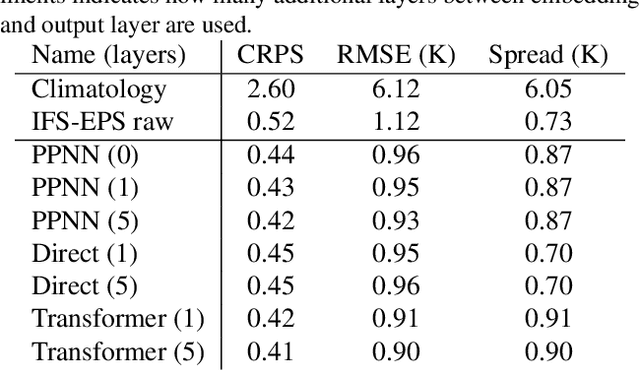

Ensemble data from Earth system models has to be calibrated and post-processed. I propose a novel member-by-member post-processing approach with neural networks. I bridge ideas from ensemble data assimilation with self-attention, resulting into the self-attentive ensemble transformer. Here, interactions between ensemble members are represented as additive and dynamic self-attentive part. As proof-of-concept, I regress global ECMWF ensemble forecasts to 2-metre-temperature fields from the ERA5 reanalysis. I demonstrate that the ensemble transformer can calibrate the ensemble spread and extract additional information from the ensemble. As it is a member-by-member approach, the ensemble transformer directly outputs multivariate and spatially-coherent ensemble members. Therefore, self-attention and the transformer technique can be a missing piece for a non-parametric post-processing of ensemble data with neural networks.
Structuring and presenting data for testing of automotive electronics to reduce effort during decision making
Apr 23, 2021
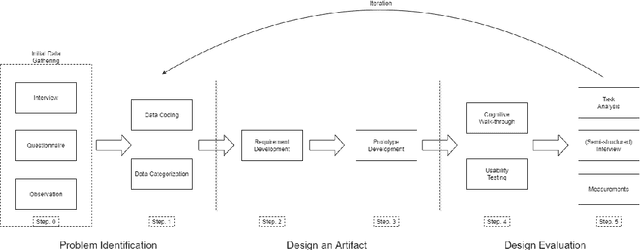


Automotive engineering is recognized as a combination of software and mechanical engineering due to the ever-increasing number of software-based components in vehicles. Since vehicles have become more sophisticated than before to ensure robustness, testing of automotive electronics is performed in high volume, producing immense test-related data. This study investigates how unstructured and decentralized test-related data from testing of automotive electronics creates issues in decision making during the testing and analysis process of test artifacts by performing an exploratory case-study at one of the leading automotive companies, Volvo Cars. From the findings of the exploratory study, a prototype was designed to improve the data and information structure and presentation for test analysis and diagnostics for automotive electronics. The prototype's results showed that providing better data and information structure significantly increases the efficiency and reduces the workload for testers when conducting test analysis and diagnostics. Testers showed a decrease in task load for tasks related to testing due to better information structure, presentation, correctness and accessibility. Hence, the improvements aided the testers to arrive at decisions regarding root cause analysis of failed tests efficiently. The findings of this study can assist automotive companies in systematically investigating and improving the testing process of automotive electronics in regards to managing and structuring test-related data. Keywords: Testing, Automotive Electronics, Electronic Control Unit, ECU, Unstructured Data.
Sparse-to-dense Feature Matching: Intra and Inter domain Cross-modal Learning in Domain Adaptation for 3D Semantic Segmentation
Aug 08, 2021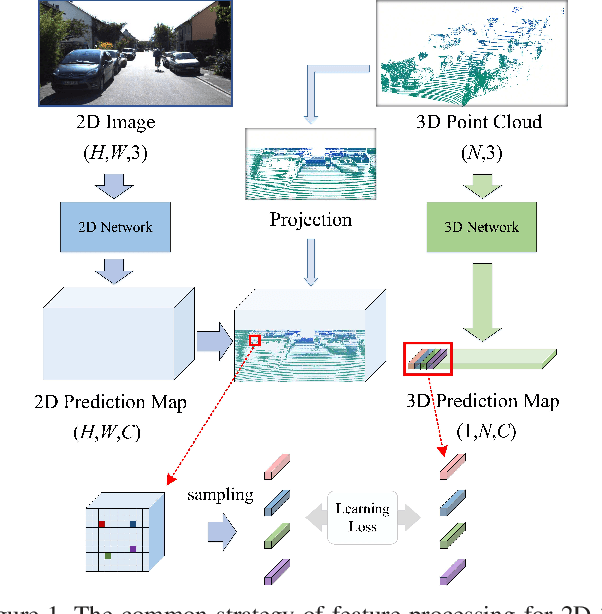
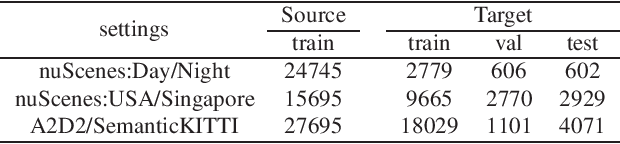
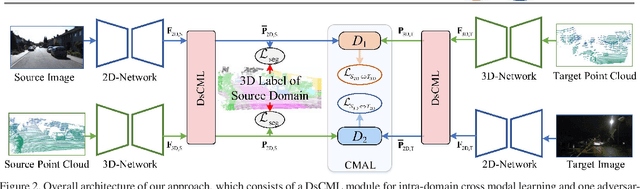
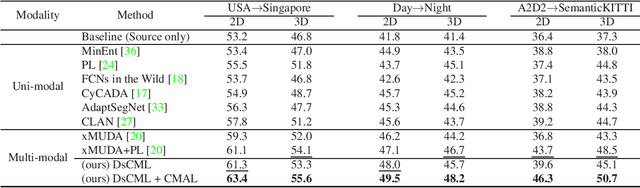
Domain adaptation is critical for success when confronting with the lack of annotations in a new domain. As the huge time consumption of labeling process on 3D point cloud, domain adaptation for 3D semantic segmentation is of great expectation. With the rise of multi-modal datasets, large amount of 2D images are accessible besides 3D point clouds. In light of this, we propose to further leverage 2D data for 3D domain adaptation by intra and inter domain cross modal learning. As for intra-domain cross modal learning, most existing works sample the dense 2D pixel-wise features into the same size with sparse 3D point-wise features, resulting in the abandon of numerous useful 2D features. To address this problem, we propose Dynamic sparse-to-dense Cross Modal Learning (DsCML) to increase the sufficiency of multi-modality information interaction for domain adaptation. For inter-domain cross modal learning, we further advance Cross Modal Adversarial Learning (CMAL) on 2D and 3D data which contains different semantic content aiming to promote high-level modal complementarity. We evaluate our model under various multi-modality domain adaptation settings including day-to-night, country-to-country and dataset-to-dataset, brings large improvements over both uni-modal and multi-modal domain adaptation methods on all settings.
MST: Masked Self-Supervised Transformer for Visual Representation
Jun 10, 2021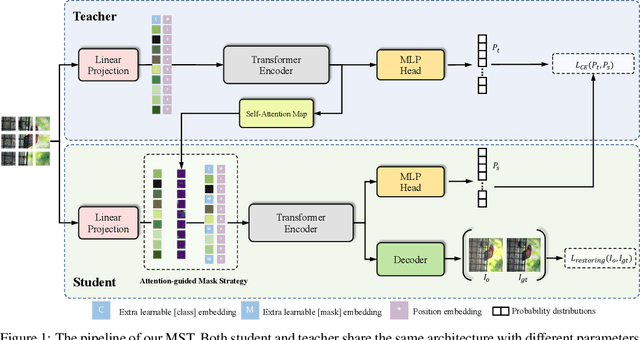
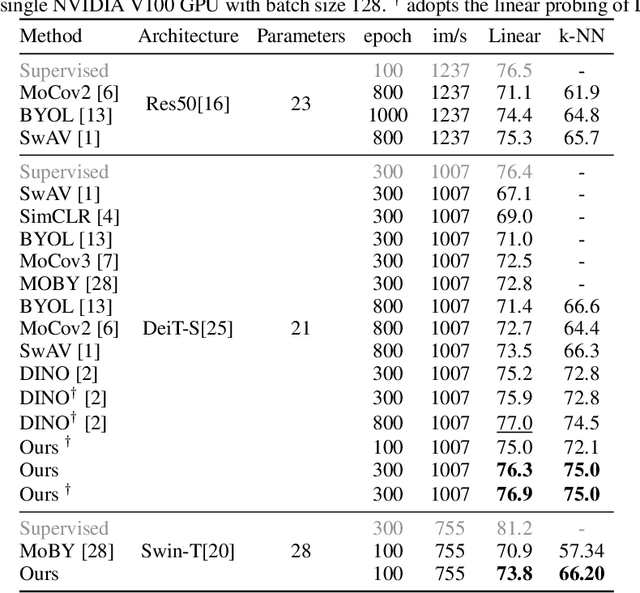

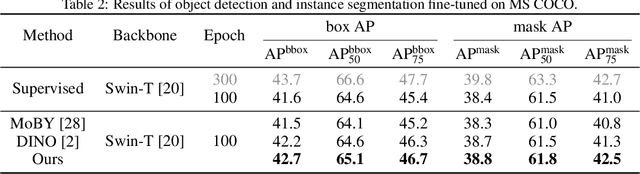
Transformer has been widely used for self-supervised pre-training in Natural Language Processing (NLP) and achieved great success. However, it has not been fully explored in visual self-supervised learning. Meanwhile, previous methods only consider the high-level feature and learning representation from a global perspective, which may fail to transfer to the downstream dense prediction tasks focusing on local features. In this paper, we present a novel Masked Self-supervised Transformer approach named MST, which can explicitly capture the local context of an image while preserving the global semantic information. Specifically, inspired by the Masked Language Modeling (MLM) in NLP, we propose a masked token strategy based on the multi-head self-attention map, which dynamically masks some tokens of local patches without damaging the crucial structure for self-supervised learning. More importantly, the masked tokens together with the remaining tokens are further recovered by a global image decoder, which preserves the spatial information of the image and is more friendly to the downstream dense prediction tasks. The experiments on multiple datasets demonstrate the effectiveness and generality of the proposed method. For instance, MST achieves Top-1 accuracy of 76.9% with DeiT-S only using 300-epoch pre-training by linear evaluation, which outperforms supervised methods with the same epoch by 0.4% and its comparable variant DINO by 1.0\%. For dense prediction tasks, MST also achieves 42.7% mAP on MS COCO object detection and 74.04% mIoU on Cityscapes segmentation only with 100-epoch pre-training.
Enhancing Multi-Robot Perception via Learned Data Association
Jul 01, 2021
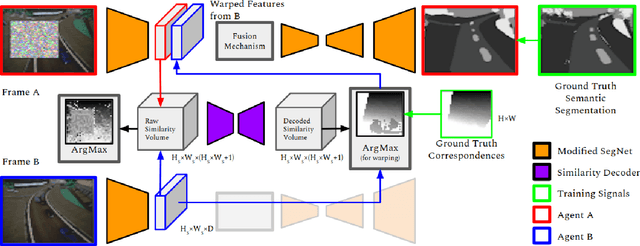
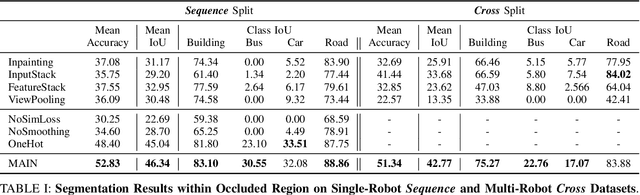
In this paper, we address the multi-robot collaborative perception problem, specifically in the context of multi-view infilling for distributed semantic segmentation. This setting entails several real-world challenges, especially those relating to unregistered multi-agent image data. Solutions must effectively leverage multiple, non-static, and intermittently-overlapping RGB perspectives. To this end, we propose the Multi-Agent Infilling Network: an extensible neural architecture that can be deployed (in a distributed manner) to each agent in a robotic swarm. Specifically, each robot is in charge of locally encoding and decoding visual information, and an extensible neural mechanism allows for an uncertainty-aware and context-based exchange of intermediate features. We demonstrate improved performance on a realistic multi-robot AirSim dataset.
A Deep Local and Global Scene-Graph Matching for Image-Text Retrieval
Jun 04, 2021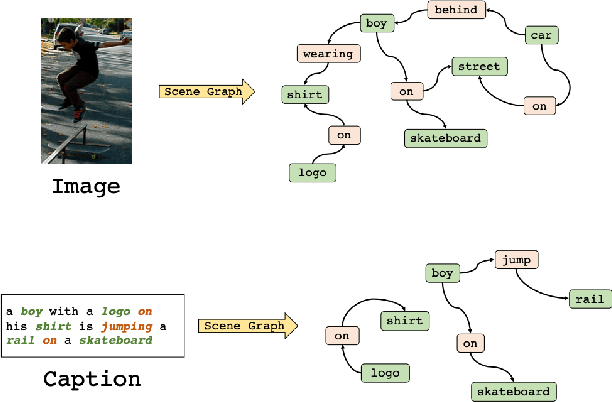
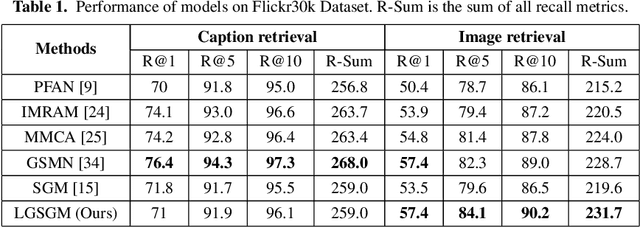
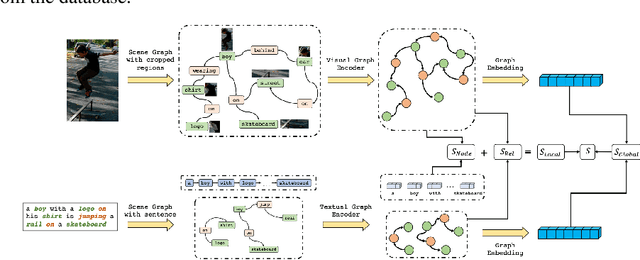
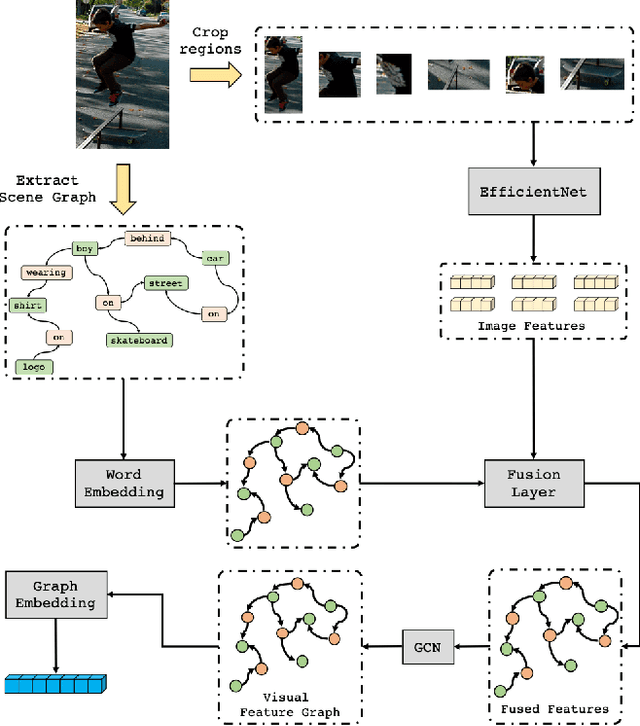
Conventional approaches to image-text retrieval mainly focus on indexing visual objects appearing in pictures but ignore the interactions between these objects. Such objects occurrences and interactions are equivalently useful and important in this field as they are usually mentioned in the text. Scene graph presentation is a suitable method for the image-text matching challenge and obtained good results due to its ability to capture the inter-relationship information. Both images and text are represented in scene graph levels and formulate the retrieval challenge as a scene graph matching challenge. In this paper, we introduce the Local and Global Scene Graph Matching (LGSGM) model that enhances the state-of-the-art method by integrating an extra graph convolution network to capture the general information of a graph. Specifically, for a pair of scene graphs of an image and its caption, two separate models are used to learn the features of each graph's nodes and edges. Then a Siamese-structure graph convolution model is employed to embed graphs into vector forms. We finally combine the graph-level and the vector-level to calculate the similarity of this image-text pair. The empirical experiments show that our enhancement with the combination of levels can improve the performance of the baseline method by increasing the recall by more than 10% on the Flickr30k dataset.