 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
SaNet: Scale-aware Neural Network for Semantic Labelling of Multiple Spatial Resolution Aerial Images
Apr 10, 2021
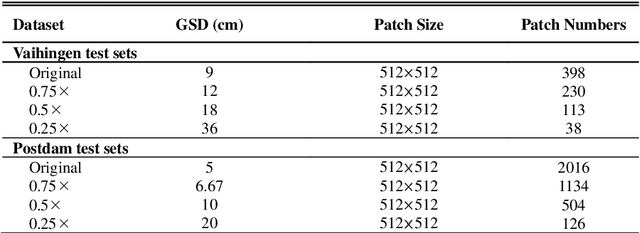


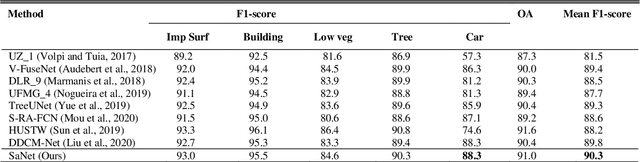
Assigning geospatial objects of aerial images with specific categories at the pixel level is a fundamental task in urban scene interpretation. Along with rapid developments in sensor technologies, aerial images can be captured at multiple spatial resolutions (MSR) with information content manifested at different scales. Extracting information from these MSR aerial images represents huge opportunities for enhanced feature representation and characterisation. However, MSR images suffer from two critical issues: 1) increased variation in the sizes of geospatial objects and 2) information and informative feature loss at coarse spatial resolutions. In this paper, we propose a novel scale-aware neural network (SaNet) for semantic labelling of MSR aerial images to address these two issues. SaNet deploys a densely connected feature network (DCFPN) module to capture high-quality multi-scale context, such as to address the scale variation issue and increase the quality of segmentation for both large and small objects simultaneously. A spatial feature recalibration (SFR) module is further incorporated into the network to learn complete semantic features with enhanced spatial relationships, where the effects of information and informative feature loss are addressed. The combination of DCFPN and SFR allows the proposed SaNet to learn scale-aware features from MSR aerial images. Extensive experiments undertaken on ISPRS semantic segmentation datasets demonstrated the outstanding accuracy of the proposed SaNet in cross-resolution segmentation, with an average OA of 83.4% on the Vaihingen dataset and an average F1 score of 80.4% on the Potsdam dataset, outperforming state-of-the-art deep learning approaches, including FPN (80.2% and 76.6%), PSPNet (79.8% and 76.2%) and Deeplabv3+ (80.8% and 76.1%) as well as DDCM-Net (81.7% and 77.6%) and EaNet (81.5% and 78.3%).
On the Importance of Domain-specific Explanations in AI-based Cybersecurity Systems (Technical Report)
Aug 02, 2021
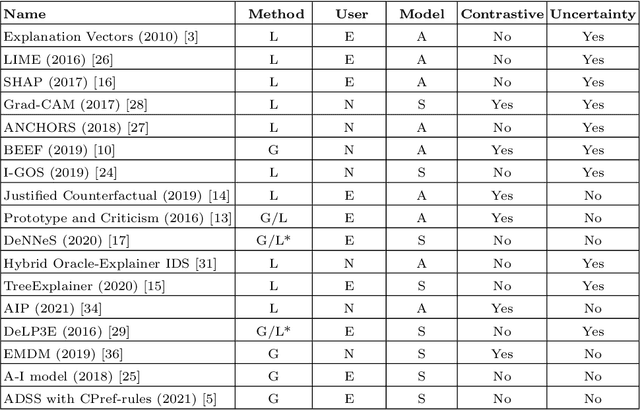
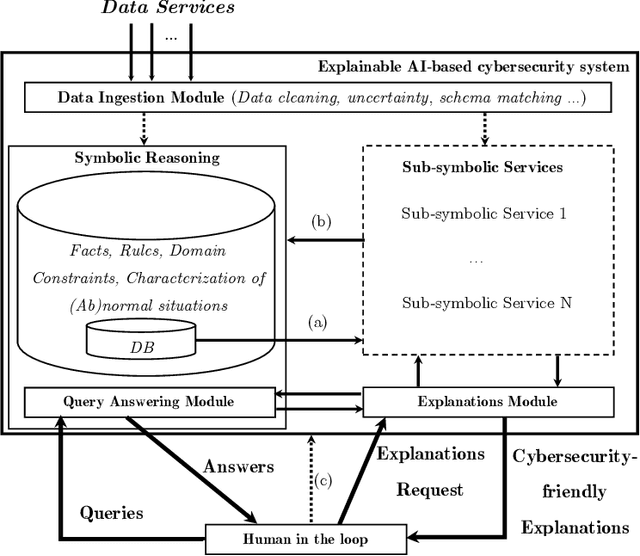
With the availability of large datasets and ever-increasing computing power, there has been a growing use of data-driven artificial intelligence systems, which have shown their potential for successful application in diverse areas. However, many of these systems are not able to provide information about the rationale behind their decisions to their users. Lack of understanding of such decisions can be a major drawback, especially in critical domains such as those related to cybersecurity. In light of this problem, in this paper we make three contributions: (i) proposal and discussion of desiderata for the explanation of outputs generated by AI-based cybersecurity systems; (ii) a comparative analysis of approaches in the literature on Explainable Artificial Intelligence (XAI) under the lens of both our desiderata and further dimensions that are typically used for examining XAI approaches; and (iii) a general architecture that can serve as a roadmap for guiding research efforts towards the development of explainable AI-based cybersecurity systems -- at its core, this roadmap proposes combinations of several research lines in a novel way towards tackling the unique challenges that arise in this context.
Latency-Constrained Highly-Reliable mmWave Communication via Multi-point Connectivity
Aug 20, 2021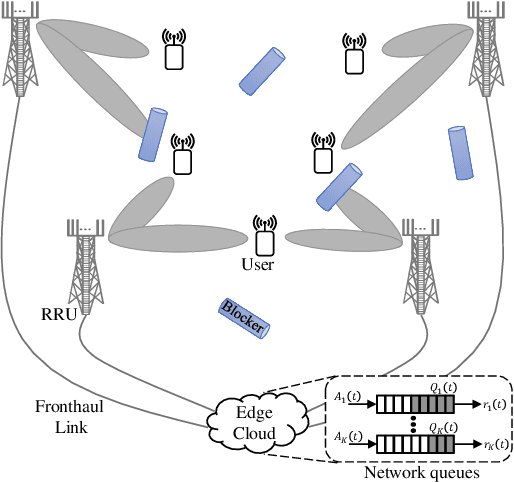
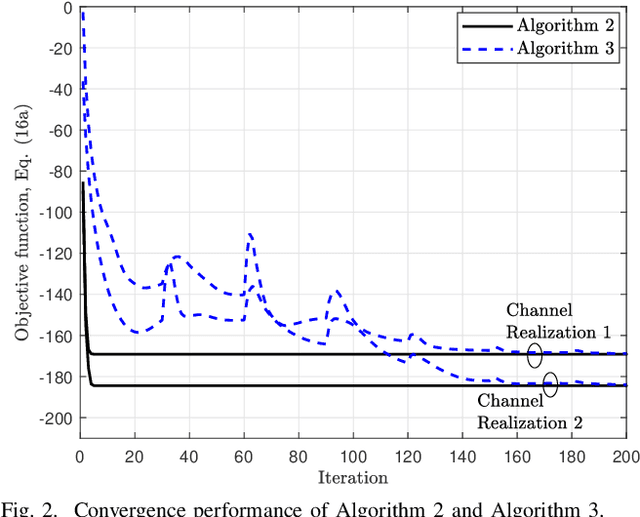
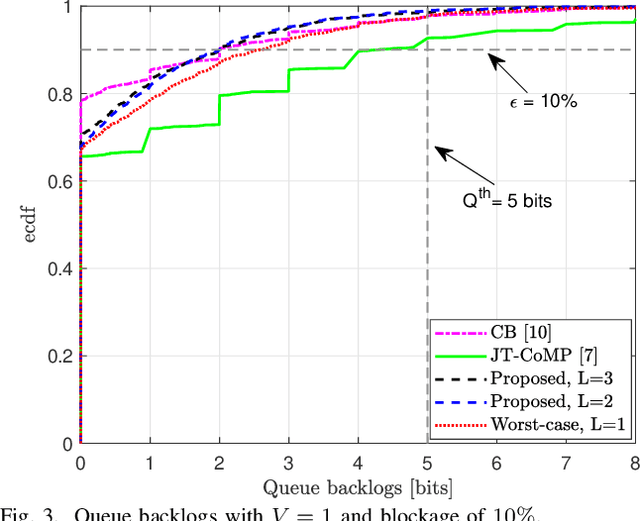
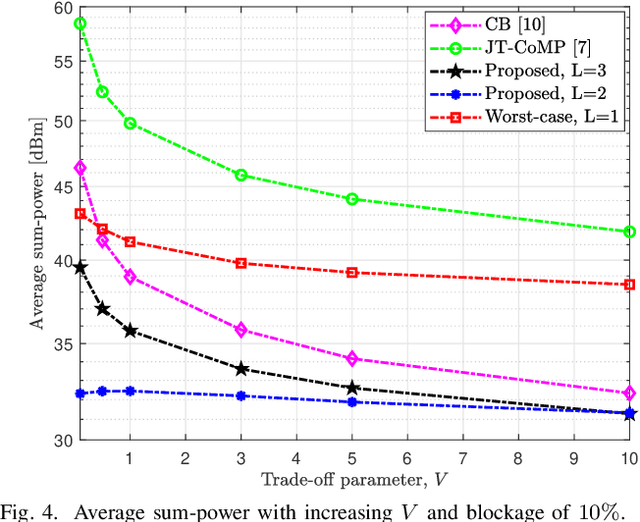
The sensitivity of millimeter-wave (mmWave) radio channel to blockage is a fundamental challenge in achieving low-latency and ultra-reliable connectivity. In this paper, we explore the viability of using coordinated multi-point (CoMP) transmission for a delay bounded and reliable mmWave communication. We propose a novel blockage-aware algorithm for the sum-power minimization problem under the user-specific latency requirements in a dynamic mobile access network. We use the Lyapunov optimization framework, and provide a dynamic control algorithm, which efficiently transforms a time-average stochastic problem into a sequence of deterministic subproblems. A robust beamformer design is then proposed by exploiting the queue backlogs and channel information, that efficiently allocates the required radio and cooperation resources, and proactively leverages the multi-antenna spatial diversity according to the instantaneous needs of the users. Further, to adapt to the uncertainties of the mmWave channel, we consider a pessimistic estimate of the rates over link blockage combinations and an adaptive selection of the CoMP serving set from the available remote radio units (RRUs). Moreover, after the relaxation of coupled and non-convex constraints via the Fractional Program (FP) techniques, a low-complexity closed-form iterative algorithm is provided by solving a system of Karush-Kuhn-Tucker (KKT) optimality conditions. The simulation results manifest that, in the presence of random blockages, the proposed methods outperform the baseline scenarios and provide power-efficient, high-reliable, and low-latency mmWave communication.
Remember What You have drawn: Semantic Image Manipulation with Memory
Jul 27, 2021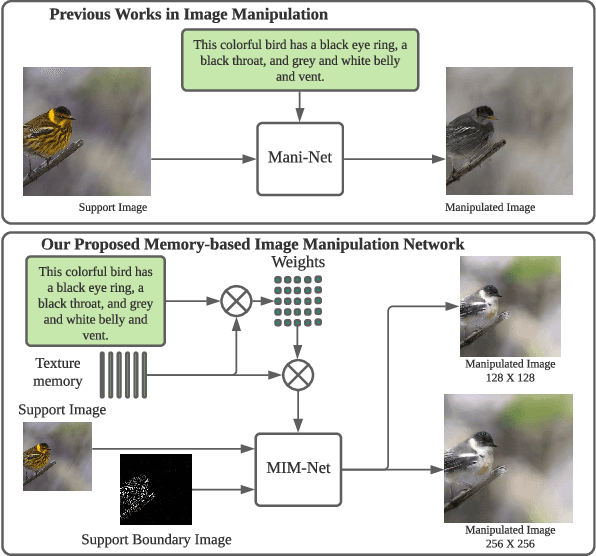
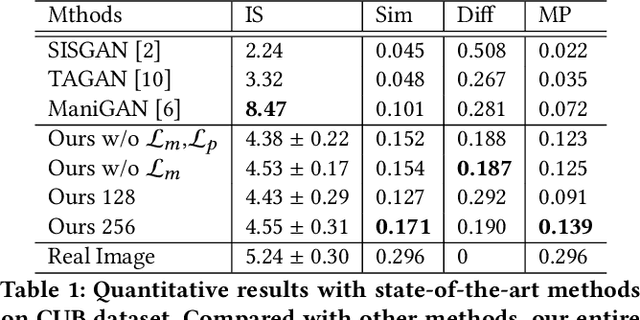


Image manipulation with natural language, which aims to manipulate images with the guidance of language descriptions, has been a challenging problem in the fields of computer vision and natural language processing (NLP). Currently, a number of efforts have been made for this task, but their performances are still distant away from generating realistic and text-conformed manipulated images. Therefore, in this paper, we propose a memory-based Image Manipulation Network (MIM-Net), where a set of memories learned from images is introduced to synthesize the texture information with the guidance of the textual description. We propose a two-stage network with an additional reconstruction stage to learn the latent memories efficiently. To avoid the unnecessary background changes, we propose a Target Localization Unit (TLU) to focus on the manipulation of the region mentioned by the text. Moreover, to learn a robust memory, we further propose a novel randomized memory training loss. Experiments on the four popular datasets show the better performance of our method compared to the existing ones.
Dual Projection Generative Adversarial Networks for Conditional Image Generation
Aug 20, 2021
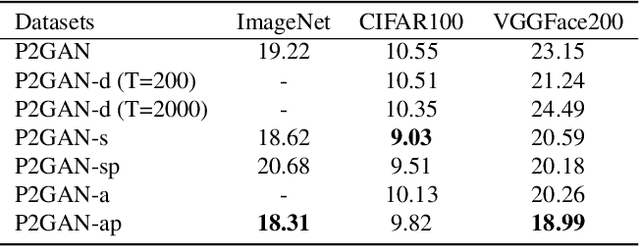
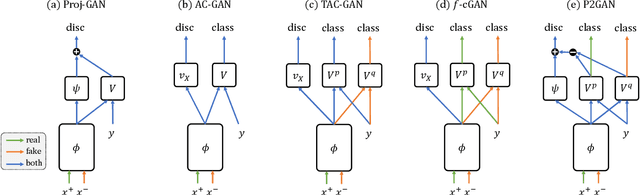

Conditional Generative Adversarial Networks (cGANs) extend the standard unconditional GAN framework to learning joint data-label distributions from samples, and have been established as powerful generative models capable of generating high-fidelity imagery. A challenge of training such a model lies in properly infusing class information into its generator and discriminator. For the discriminator, class conditioning can be achieved by either (1) directly incorporating labels as input or (2) involving labels in an auxiliary classification loss. In this paper, we show that the former directly aligns the class-conditioned fake-and-real data distributions $P(\text{image}|\text{class})$ ({\em data matching}), while the latter aligns data-conditioned class distributions $P(\text{class}|\text{image})$ ({\em label matching}). Although class separability does not directly translate to sample quality and becomes a burden if classification itself is intrinsically difficult, the discriminator cannot provide useful guidance for the generator if features of distinct classes are mapped to the same point and thus become inseparable. Motivated by this intuition, we propose a Dual Projection GAN (P2GAN) model that learns to balance between {\em data matching} and {\em label matching}. We then propose an improved cGAN model with Auxiliary Classification that directly aligns the fake and real conditionals $P(\text{class}|\text{image})$ by minimizing their $f$-divergence. Experiments on a synthetic Mixture of Gaussian (MoG) dataset and a variety of real-world datasets including CIFAR100, ImageNet, and VGGFace2 demonstrate the efficacy of our proposed models.
tFold-TR: Combining Deep Learning Enhanced Hybrid Potential Energy for Template-Based Modelling Structure Refinement
May 22, 2021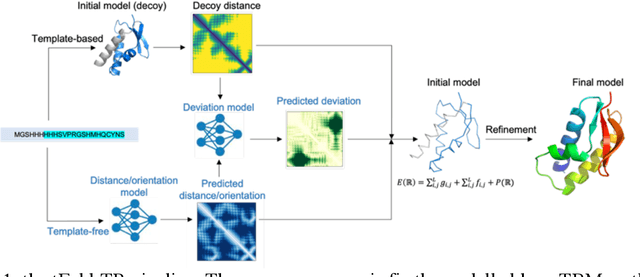


Proteins structure prediction has long been a grand challenge over the past 50 years, owing to its broad scientific and application interests. There are two major types of modelling algorithms, template-free modelling and template-based modelling. The latter one is suitable for easy prediction tasks and is widely adopted in computer-aided drug discoveries for drug design and screening. Although it has been several decades since its first edition, the current template-based modeling approach suffers from two important problems: 1) there are many missing regions in the template-query sequence alignment, and 2) the accuracy of the distance pairs from different regions of the template varies, and this information is not well introduced into the modeling. To solve the two problems, we propose a structural optimization process based on template modelling, introducing two neural network models to predict the distance information of the missing regions and the accuracy of the distance pairs of different regions in the template modeling structure. The predicted distances and residue pairwise-specific deviations are incorporated into the potential energy function for structural optimization, which significantly improves the qualities of the original template modelling decoys.
MetaLDA: a Topic Model that Efficiently Incorporates Meta information
Sep 19, 2017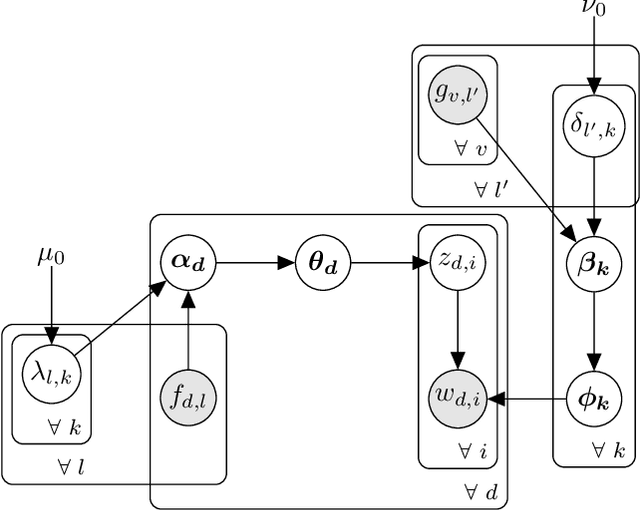
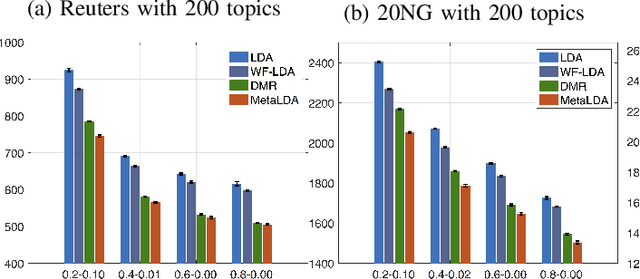

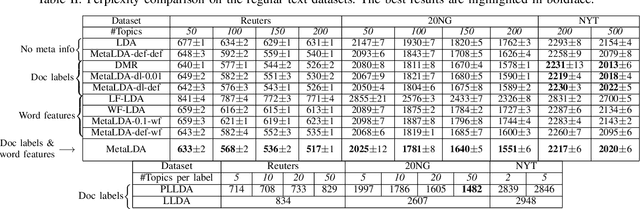
Besides the text content, documents and their associated words usually come with rich sets of meta informa- tion, such as categories of documents and semantic/syntactic features of words, like those encoded in word embeddings. Incorporating such meta information directly into the generative process of topic models can improve modelling accuracy and topic quality, especially in the case where the word-occurrence information in the training data is insufficient. In this paper, we present a topic model, called MetaLDA, which is able to leverage either document or word meta information, or both of them jointly. With two data argumentation techniques, we can derive an efficient Gibbs sampling algorithm, which benefits from the fully local conjugacy of the model. Moreover, the algorithm is favoured by the sparsity of the meta information. Extensive experiments on several real world datasets demonstrate that our model achieves comparable or improved performance in terms of both perplexity and topic quality, particularly in handling sparse texts. In addition, compared with other models using meta information, our model runs significantly faster.
Spatio-Temporal Split Learning for Privacy-Preserving Medical Platforms: Case Studies with COVID-19 CT, X-Ray, and Cholesterol Data
Aug 20, 2021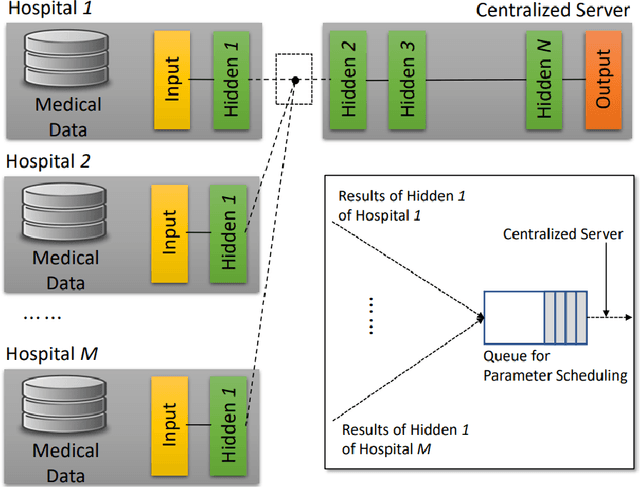

Machine learning requires a large volume of sample data, especially when it is used in high-accuracy medical applications. However, patient records are one of the most sensitive private information that is not usually shared among institutes. This paper presents spatio-temporal split learning, a distributed deep neural network framework, which is a turning point in allowing collaboration among privacy-sensitive organizations. Our spatio-temporal split learning presents how distributed machine learning can be efficiently conducted with minimal privacy concerns. The proposed split learning consists of a number of clients and a centralized server. Each client has only has one hidden layer, which acts as the privacy-preserving layer, and the centralized server comprises the other hidden layers and the output layer. Since the centralized server does not need to access the training data and trains the deep neural network with parameters received from the privacy-preserving layer, privacy of original data is guaranteed. We have coined the term, spatio-temporal split learning, as multiple clients are spatially distributed to cover diverse datasets from different participants, and we can temporally split the learning process, detaching the privacy preserving layer from the rest of the learning process to minimize privacy breaches. This paper shows how we can analyze the medical data whilst ensuring privacy using our proposed multi-site spatio-temporal split learning algorithm on Coronavirus Disease-19 (COVID-19) chest Computed Tomography (CT) scans, MUsculoskeletal RAdiographs (MURA) X-ray images, and cholesterol levels.
Hierarchical graph neural nets can capture long-range interactions
Jul 15, 2021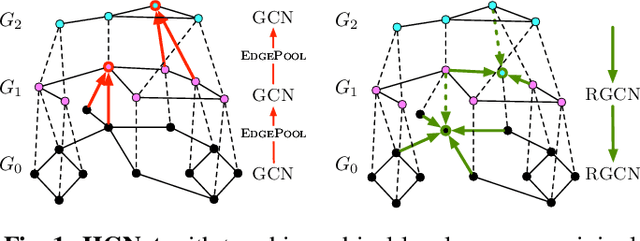
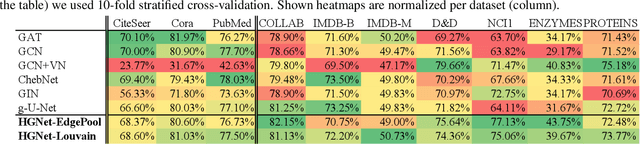
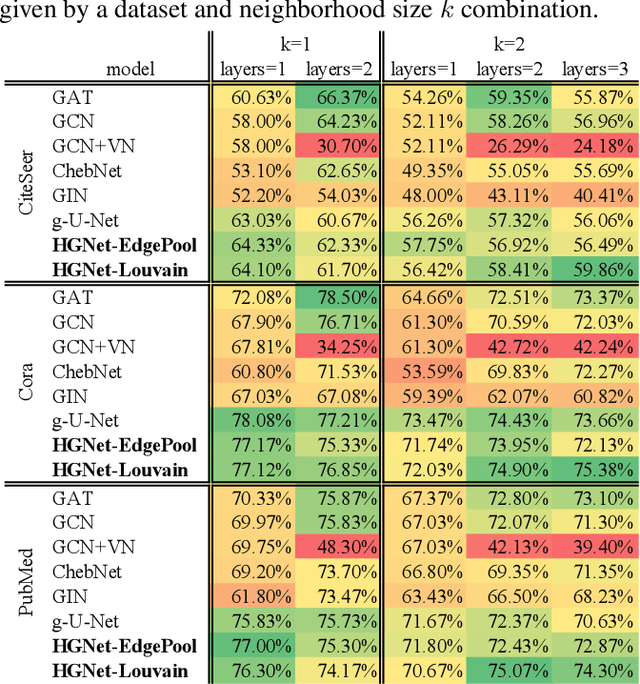
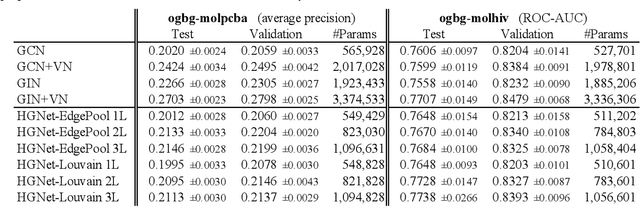
Graph neural networks (GNNs) based on message passing between neighboring nodes are known to be insufficient for capturing long-range interactions in graphs. In this project we study hierarchical message passing models that leverage a multi-resolution representation of a given graph. This facilitates learning of features that span large receptive fields without loss of local information, an aspect not studied in preceding work on hierarchical GNNs. We introduce Hierarchical Graph Net (HGNet), which for any two connected nodes guarantees existence of message-passing paths of at most logarithmic length w.r.t. the input graph size. Yet, under mild assumptions, its internal hierarchy maintains asymptotic size equivalent to that of the input graph. We observe that our HGNet outperforms conventional stacking of GCN layers particularly in molecular property prediction benchmarks. Finally, we propose two benchmarking tasks designed to elucidate capability of GNNs to leverage long-range interactions in graphs.
Encoder-Decoder Architectures for Clinically Relevant Coronary Artery Segmentation
Jun 21, 2021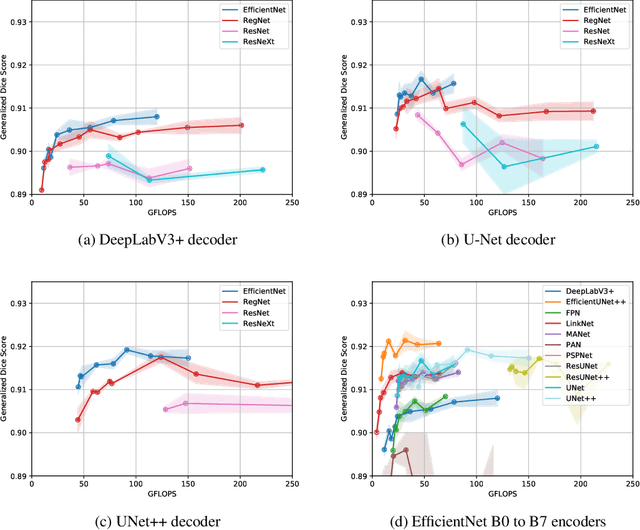
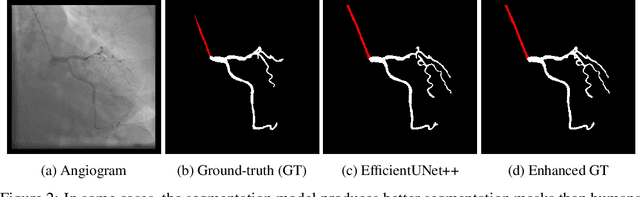

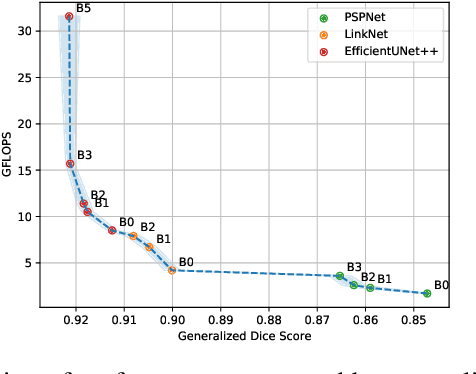
Coronary X-ray angiography is a crucial clinical procedure for the diagnosis and treatment of coronary artery disease, which accounts for roughly 16% of global deaths every year. However, the images acquired in these procedures have low resolution and poor contrast, making lesion detection and assessment challenging. Accurate coronary artery segmentation not only helps mitigate these problems, but also allows the extraction of relevant anatomical features for further analysis by quantitative methods. Although automated segmentation of coronary arteries has been proposed before, previous approaches have used non-optimal segmentation criteria, leading to less useful results. Most methods either segment only the major vessel, discarding important information from the remaining ones, or segment the whole coronary tree based mostly on contrast information, producing a noisy output that includes vessels that are not relevant for diagnosis. We adopt a better-suited clinical criterion and segment vessels according to their clinical relevance. Additionally, we simultaneously perform catheter segmentation, which may be useful for diagnosis due to the scale factor provided by the catheter's known diameter, and is a task that has not yet been performed with good results. To derive the optimal approach, we conducted an extensive comparative study of encoder-decoder architectures trained on a combination of focal loss and a variant of generalized dice loss. Based on the EfficientNet and the UNet++ architectures, we propose a line of efficient and high-performance segmentation models using a new decoder architecture, the EfficientUNet++, whose best-performing version achieved average dice scores of 0.8904 and 0.7526 for the artery and catheter classes, respectively, and an average generalized dice score of 0.9234.