 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
CTNet: Context-based Tandem Network for Semantic Segmentation
Apr 20, 2021

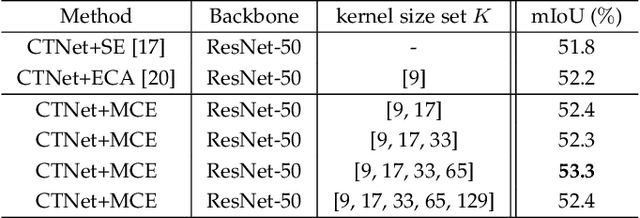
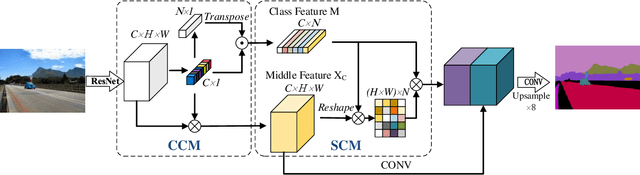
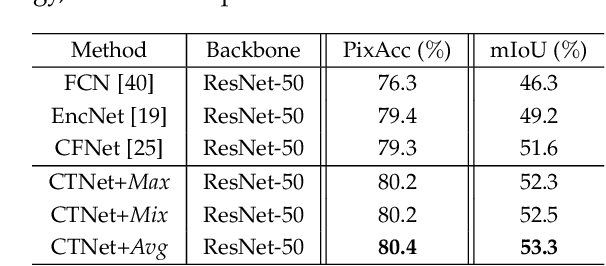
Contextual information has been shown to be powerful for semantic segmentation. This work proposes a novel Context-based Tandem Network (CTNet) by interactively exploring the spatial contextual information and the channel contextual information, which can discover the semantic context for semantic segmentation. Specifically, the Spatial Contextual Module (SCM) is leveraged to uncover the spatial contextual dependency between pixels by exploring the correlation between pixels and categories. Meanwhile, the Channel Contextual Module (CCM) is introduced to learn the semantic features including the semantic feature maps and class-specific features by modeling the long-term semantic dependence between channels. The learned semantic features are utilized as the prior knowledge to guide the learning of SCM, which can make SCM obtain more accurate long-range spatial dependency. Finally, to further improve the performance of the learned representations for semantic segmentation, the results of the two context modules are adaptively integrated to achieve better results. Extensive experiments are conducted on three widely-used datasets, i.e., PASCAL-Context, ADE20K and PASCAL VOC2012. The results demonstrate the superior performance of the proposed CTNet by comparison with several state-of-the-art methods.
With One Voice: Composing a Travel Voice Assistant from Re-purposed Models
Aug 04, 2021
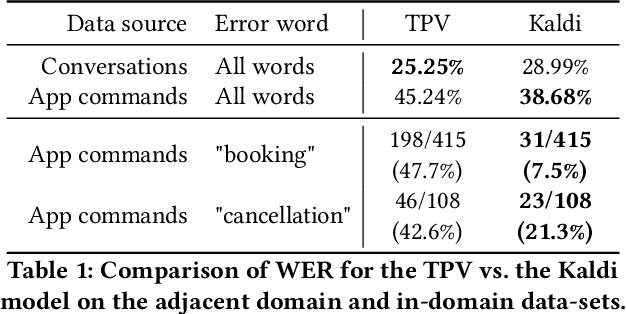
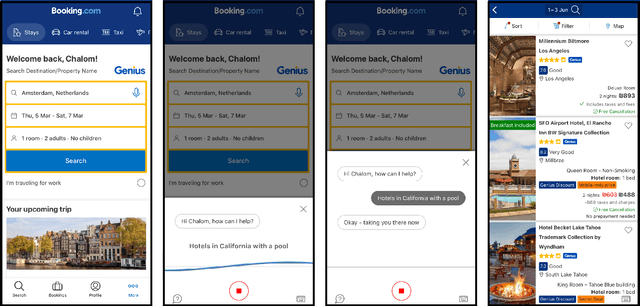

Voice assistants provide users a new way of interacting with digital products, allowing them to retrieve information and complete tasks with an increased sense of control and flexibility. Such products are comprised of several machine learning models, like Speech-to-Text transcription, Named Entity Recognition and Resolution, and Text Classification. Building a voice assistant from scratch takes the prolonged efforts of several teams constructing numerous models and orchestrating between components. Alternatives such as using third-party vendors or re-purposing existing models may be considered to shorten time-to-market and development costs. However, each option has its benefits and drawbacks. We present key insights from building a voice search assistant for Booking.com search and recommendation system. Our paper compares the achieved performance and development efforts in dedicated tailor-made solutions against existing re-purposed models. We share and discuss our data-driven decisions about implementation trade-offs and their estimated outcomes in hindsight, showing that a fully functional machine learning product can be built from existing models.
* 2nd International Workshop on Industrial Recommendation Systems @ KDD 2021
A Transformer-based Math Language Model for Handwritten Math Expression Recognition
Aug 11, 2021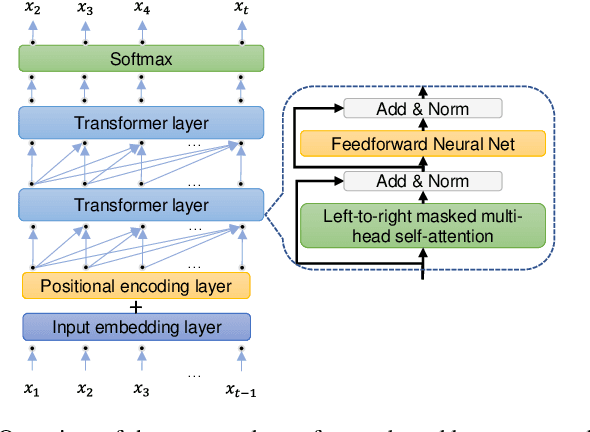
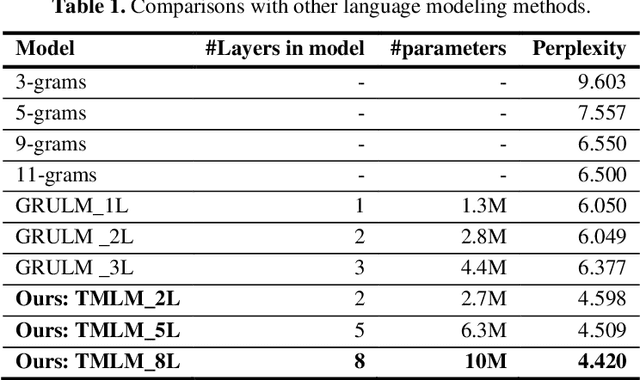
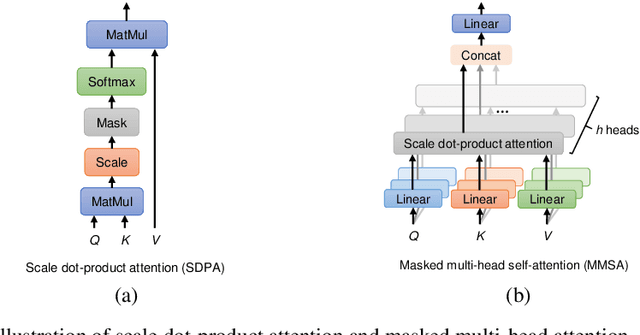

Handwritten mathematical expressions (HMEs) contain ambiguities in their interpretations, even for humans sometimes. Several math symbols are very similar in the writing style, such as dot and comma or 0, O, and o, which is a challenge for HME recognition systems to handle without using contextual information. To address this problem, this paper presents a Transformer-based Math Language Model (TMLM). Based on the self-attention mechanism, the high-level representation of an input token in a sequence of tokens is computed by how it is related to the previous tokens. Thus, TMLM can capture long dependencies and correlations among symbols and relations in a mathematical expression (ME). We trained the proposed language model using a corpus of approximately 70,000 LaTeX sequences provided in CROHME 2016. TMLM achieved the perplexity of 4.42, which outperformed the previous math language models, i.e., the N-gram and recurrent neural network-based language models. In addition, we combine TMLM into a stochastic context-free grammar-based HME recognition system using a weighting parameter to re-rank the top-10 best candidates. The expression rates on the testing sets of CROHME 2016 and CROHME 2019 were improved by 2.97 and 0.83 percentage points, respectively.
RadArnomaly: Protecting Radar Systems from Data Manipulation Attacks
Jun 13, 2021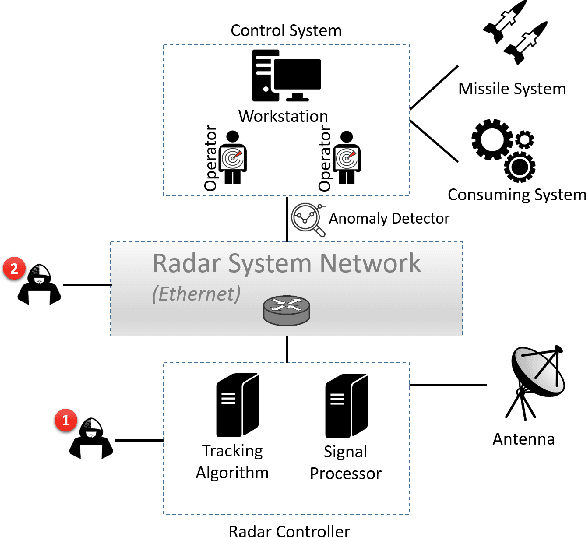
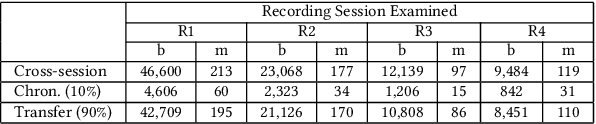
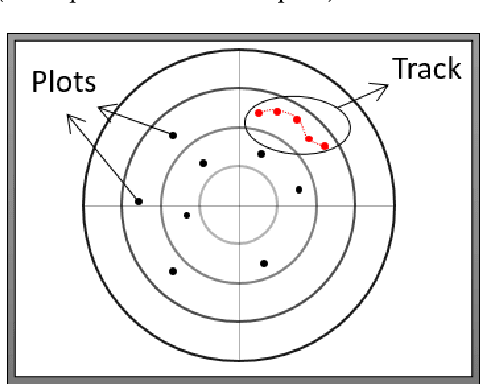
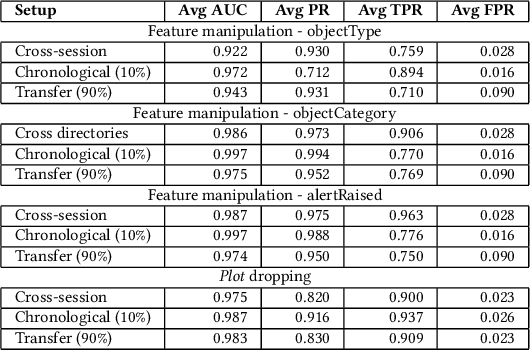
Radar systems are mainly used for tracking aircraft, missiles, satellites, and watercraft. In many cases, information regarding the objects detected by the radar system is sent to, and used by, a peripheral consuming system, such as a missile system or a graphical user interface used by an operator. Those systems process the data stream and make real-time, operational decisions based on the data received. Given this, the reliability and availability of information provided by radar systems has grown in importance. Although the field of cyber security has been continuously evolving, no prior research has focused on anomaly detection in radar systems. In this paper, we present a deep learning-based method for detecting anomalies in radar system data streams. We propose a novel technique which learns the correlation between numerical features and an embedding representation of categorical features in an unsupervised manner. The proposed technique, which allows the detection of malicious manipulation of critical fields in the data stream, is complemented by a timing-interval anomaly detection mechanism proposed for the detection of message dropping attempts. Real radar system data is used to evaluate the proposed method. Our experiments demonstrate the method's high detection accuracy on a variety of data stream manipulation attacks (average detection rate of 88% with 1.59% false alarms) and message dropping attacks (average detection rate of 92% with 2.2% false alarms).
Learning Site-Specific Probing Beams for Fast mmWave Beam Alignment
Jul 28, 2021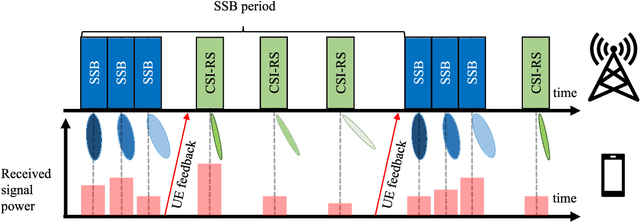
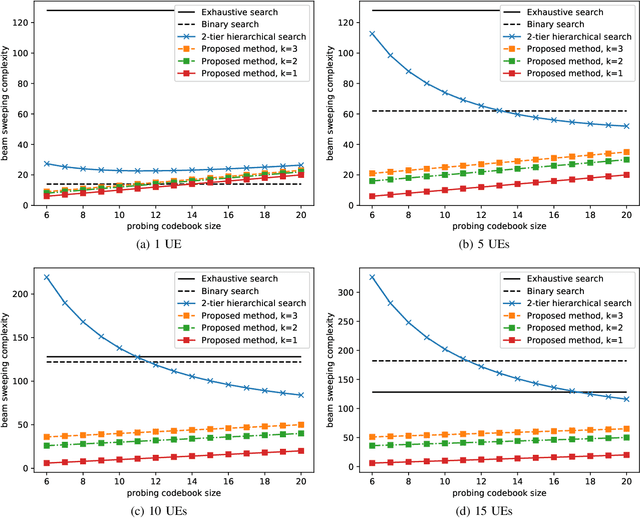
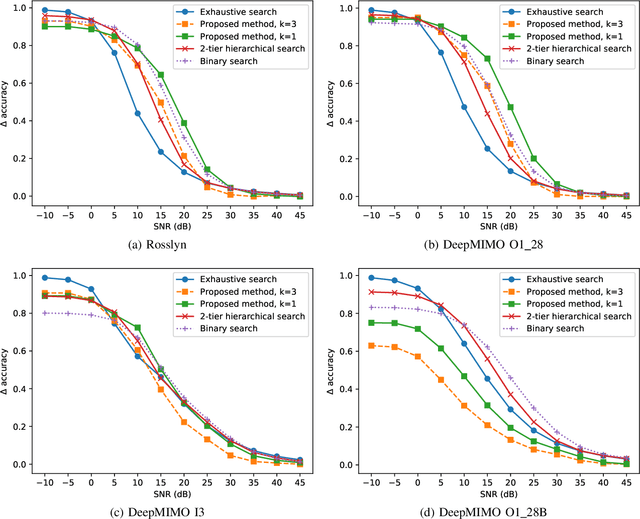
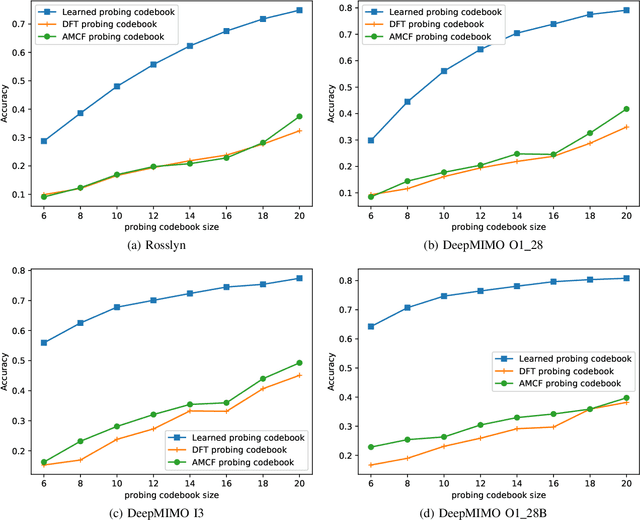
Beam alignment - the process of finding an optimal directional beam pair - is a challenging procedure crucial to millimeter wave (mmWave) communication systems. We propose a novel beam alignment method that learns a site-specific probing codebook and uses the probing codebook measurements to predict the optimal narrow beam. An end-to-end neural network (NN) architecture is designed to jointly learn the probing codebook and the beam predictor. The learned codebook consists of site-specific probing beams that can capture particular characteristics of the propagation environment. The proposed method relies on beam sweeping of the learned probing codebook, does not require additional context information, and is compatible with the beam sweeping-based beam alignment framework in 5G. Using realistic ray-tracing datasets, we demonstrate that the proposed method can achieve high beam alignment accuracy and signal-to-noise ratio (SNR) while significantly - by roughly a factor of 3 in our setting - reducing the beam sweeping complexity and latency.
AdaRNN: Adaptive Learning and Forecasting of Time Series
Aug 11, 2021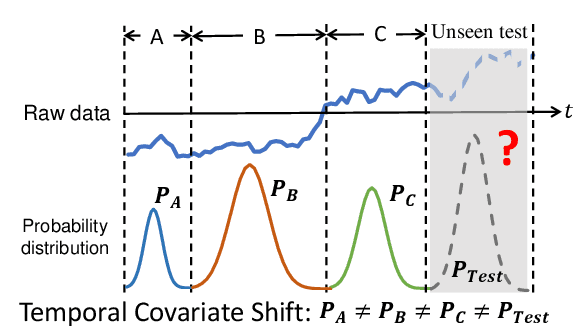
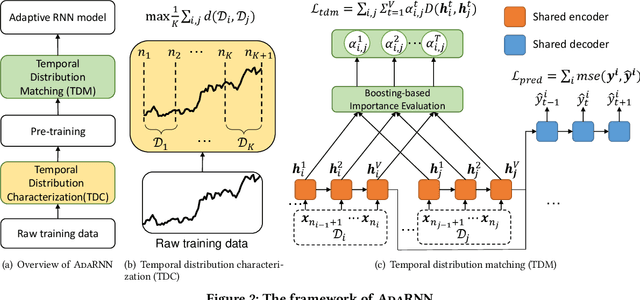
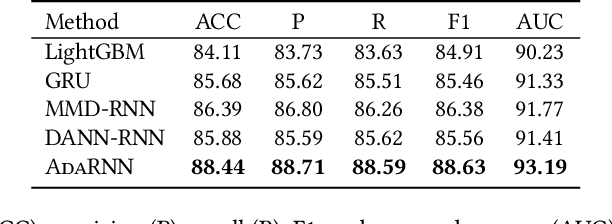
Time series has wide applications in the real world and is known to be difficult to forecast. Since its statistical properties change over time, its distribution also changes temporally, which will cause severe distribution shift problem to existing methods. However, it remains unexplored to model the time series in the distribution perspective. In this paper, we term this as Temporal Covariate Shift (TCS). This paper proposes Adaptive RNNs (AdaRNN) to tackle the TCS problem by building an adaptive model that generalizes well on the unseen test data. AdaRNN is sequentially composed of two novel algorithms. First, we propose Temporal Distribution Characterization to better characterize the distribution information in the TS. Second, we propose Temporal Distribution Matching to reduce the distribution mismatch in TS to learn the adaptive TS model. AdaRNN is a general framework with flexible distribution distances integrated. Experiments on human activity recognition, air quality prediction, and financial analysis show that AdaRNN outperforms the latest methods by a classification accuracy of 2.6% and significantly reduces the RMSE by 9.0%. We also show that the temporal distribution matching algorithm can be extended in Transformer structure to boost its performance.
Alias-Free Generative Adversarial Networks
Jul 15, 2021
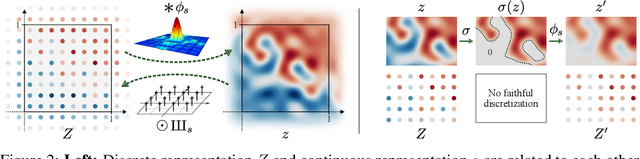
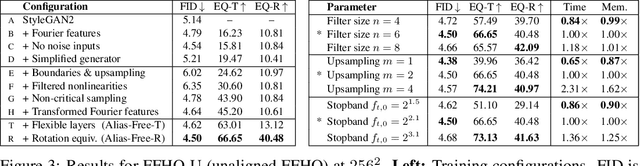
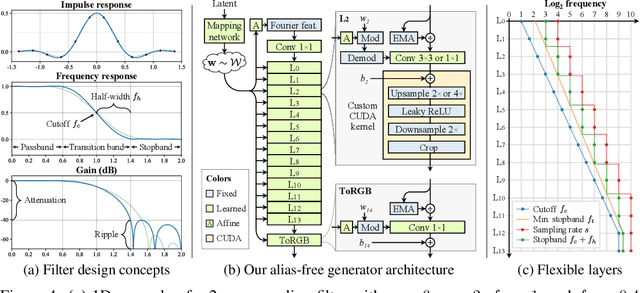
We observe that despite their hierarchical convolutional nature, the synthesis process of typical generative adversarial networks depends on absolute pixel coordinates in an unhealthy manner. This manifests itself as, e.g., detail appearing to be glued to image coordinates instead of the surfaces of depicted objects. We trace the root cause to careless signal processing that causes aliasing in the generator network. Interpreting all signals in the network as continuous, we derive generally applicable, small architectural changes that guarantee that unwanted information cannot leak into the hierarchical synthesis process. The resulting networks match the FID of StyleGAN2 but differ dramatically in their internal representations, and they are fully equivariant to translation and rotation even at subpixel scales. Our results pave the way for generative models better suited for video and animation.
A Tale Of Two Long Tails
Jul 27, 2021As machine learning models are increasingly employed to assist human decision-makers, it becomes critical to communicate the uncertainty associated with these model predictions. However, the majority of work on uncertainty has focused on traditional probabilistic or ranking approaches - where the model assigns low probabilities or scores to uncertain examples. While this captures what examples are challenging for the model, it does not capture the underlying source of the uncertainty. In this work, we seek to identify examples the model is uncertain about and characterize the source of said uncertainty. We explore the benefits of designing a targeted intervention - targeted data augmentation of the examples where the model is uncertain over the course of training. We investigate whether the rate of learning in the presence of additional information differs between atypical and noisy examples? Our results show that this is indeed the case, suggesting that well-designed interventions over the course of training can be an effective way to characterize and distinguish between different sources of uncertainty.
Modeling the Sequential Dependence among Audience Multi-step Conversions with Multi-task Learning in Targeted Display Advertising
May 24, 2021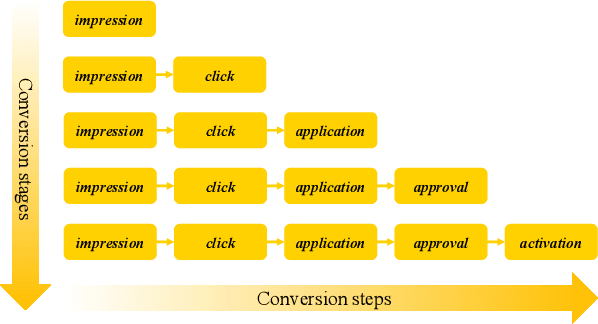

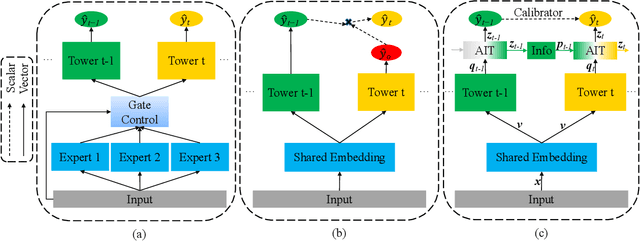
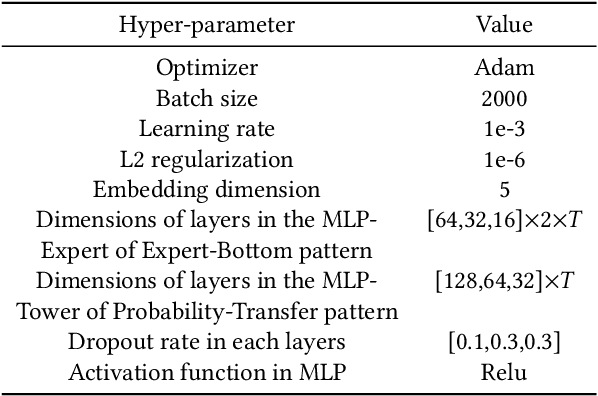
In most real-world large-scale online applications (e.g., e-commerce or finance), customer acquisition is usually a multi-step conversion process of audiences. For example, an impression->click->purchase process is usually performed of audiences for e-commerce platforms. However, it is more difficult to acquire customers in financial advertising (e.g., credit card advertising) than in traditional advertising. On the one hand, the audience multi-step conversion path is longer. On the other hand, the positive feedback is sparser (class imbalance) step by step, and it is difficult to obtain the final positive feedback due to the delayed feedback of activation. Multi-task learning is a typical solution in this direction. While considerable multi-task efforts have been made in this direction, a long-standing challenge is how to explicitly model the long-path sequential dependence among audience multi-step conversions for improving the end-to-end conversion. In this paper, we propose an Adaptive Information Transfer Multi-task (AITM) framework, which models the sequential dependence among audience multi-step conversions via the Adaptive Information Transfer (AIT) module. The AIT module can adaptively learn what and how much information to transfer for different conversion stages. Besides, by combining the Behavioral Expectation Calibrator in the loss function, the AITM framework can yield more accurate end-to-end conversion identification. The proposed framework is deployed in Meituan app, which utilizes it to real-timely show a banner to the audience with a high end-to-end conversion rate for Meituan Co-Branded Credit Cards. Offline experimental results on both industrial and public real-world datasets clearly demonstrate that the proposed framework achieves significantly better performance compared with state-of-the-art baselines.
Online Recognition of Actions Involving Objects
Apr 13, 2021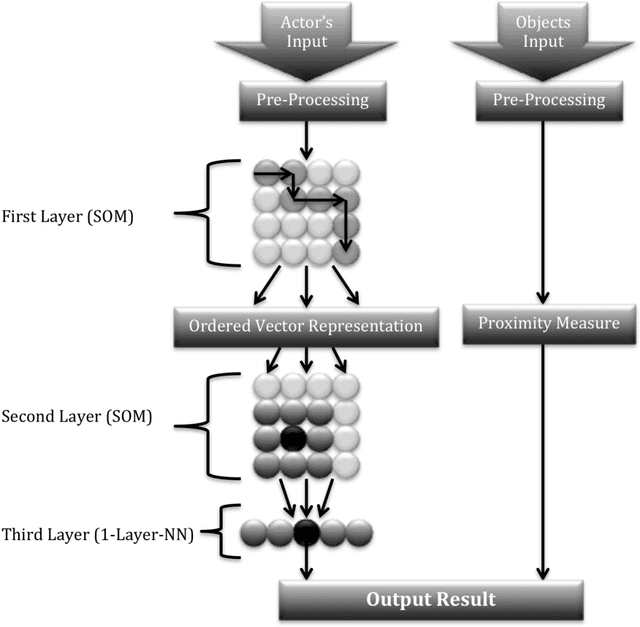
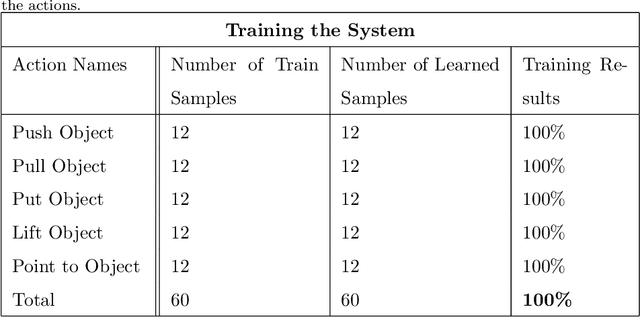
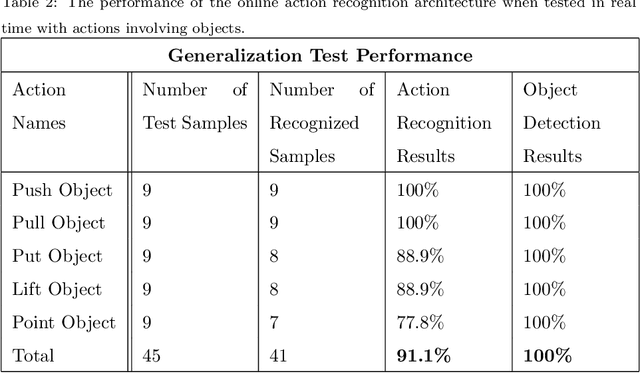
We present an online system for real time recognition of actions involving objects working in online mode. The system merges two streams of information processing running in parallel. One is carried out by a hierarchical self-organizing map (SOM) system that recognizes the performed actions by analysing the spatial trajectories of the agent's movements. It consists of two layers of SOMs and a custom made supervised neural network. The activation sequences in the first layer SOM represent the sequences of significant postures of the agent during the performance of actions. These activation sequences are subsequently recoded and clustered in the second layer SOM, and then labeled by the activity in the third layer custom made supervised neural network. The second information processing stream is carried out by a second system that determines which object among several in the agent's vicinity the action is applied to. This is achieved by applying a proximity measure. The presented method combines the two information processing streams to determine what action the agent performed and on what object. The action recognition system has been tested with excellent performance.