 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
EV-VGCNN: A Voxel Graph CNN for Event-based Object Classification
Jun 01, 2021
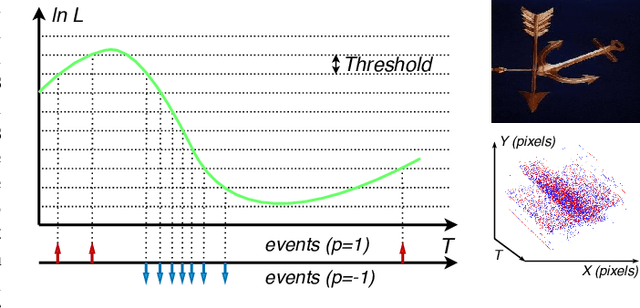
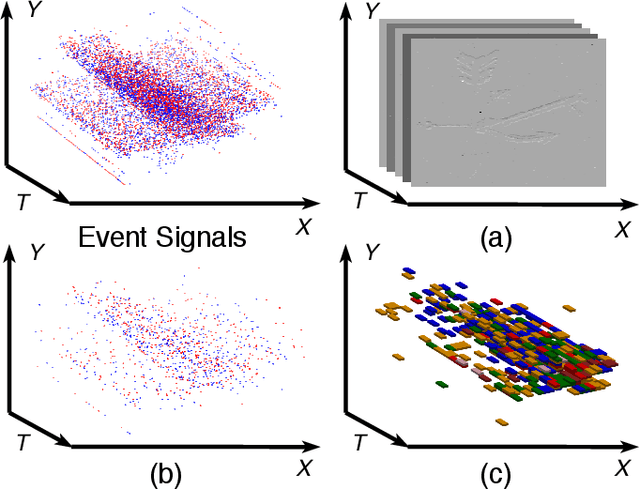
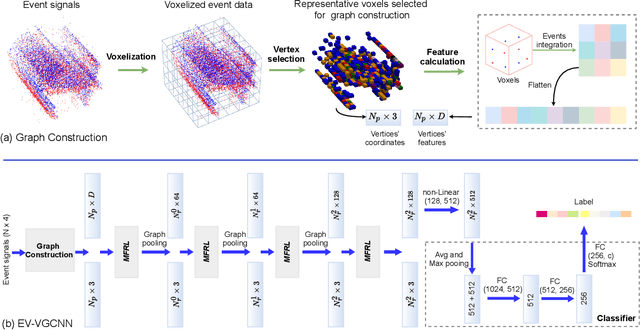
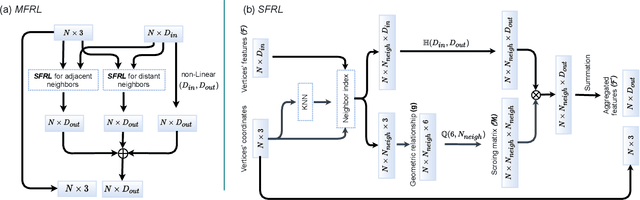
Event cameras report sparse intensity changes and hold noticeable advantages of low power consumption, high dynamic range, and high response speed for visual perception and understanding on portable devices. Event-based learning methods have recently achieved massive success on object recognition by integrating events into dense frame-based representations to apply traditional 2D learning algorithms. However, these approaches introduce much redundant information during the sparse-to-dense conversion and necessitate models with heavy-weight and large capacities, limiting the potential of event cameras on real-life applications. To address the core problem of balancing accuracy and model complexity for event-based classification models, we (1) construct graph representations for event data to utilize their sparsity nature better and design a lightweight end-to-end graph neural network (EV-VGCNN) for classification; (2) use voxel-wise vertices rather than traditional point-wise methods to incorporate the information from more points; (3) introduce a multi-scale feature relational layer (MFRL) to extract semantic and motion cues from each vertex adaptively concerning its distances to neighbors. Comprehensive experiments show that our approach advances state-of-the-art classification accuracy while achieving nearly 20 times parameter reduction (merely 0.84M parameters).
Selective Intervention Planning using RMABs: Increasing Program Engagement to Improve Maternal and Child Health Outcomes
Mar 18, 2021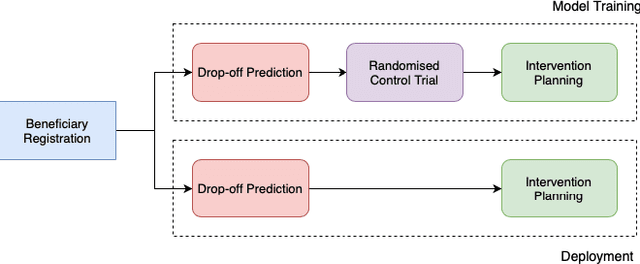
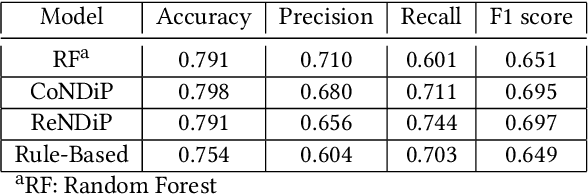
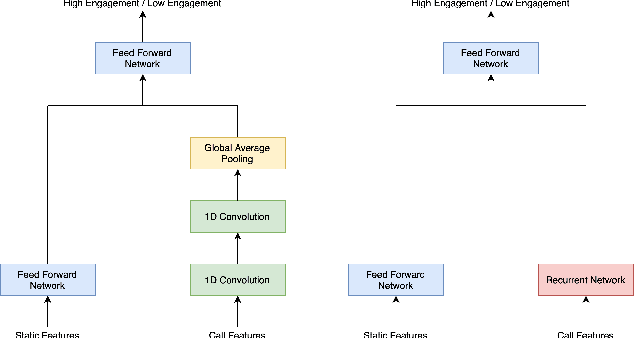
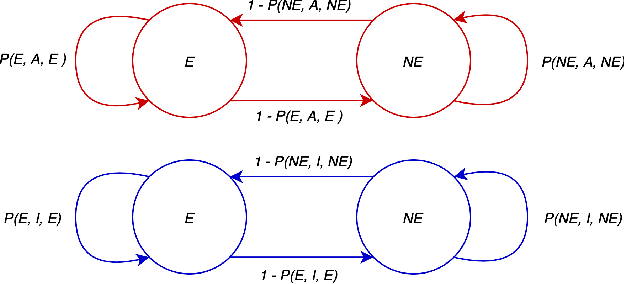
India has a maternal mortality ratio of 113 and child mortality ratio of 2830 per 100,000 live births. Lack of access to preventive care information is a major contributing factor for these deaths, especially in low-income households. We work with ARMMAN, a non-profit based in India, to further the use of call-based information programs by early-on identifying women who might not engage with these programs that are proven to affect health parameters positively. We analyzed anonymized call-records of over 300,000 women registered in an awareness program created by ARMMAN that uses cellphone calls to regularly disseminate health related information. We built machine learning based models to predict the long term engagement pattern from call logs and beneficiaries' demographic information, and discuss the applicability of this method in the real world through a pilot validation. Through a randomized controlled trial, we show that using our model's predictions to make interventions boosts engagement metrics by 14.3%. We then formulate the intervention planning problem as restless multi-armed bandits (RMABs), and present preliminary results using this approach.
Model-agnostic vs. Model-intrinsic Interpretability for Explainable Product Search
Aug 17, 2021
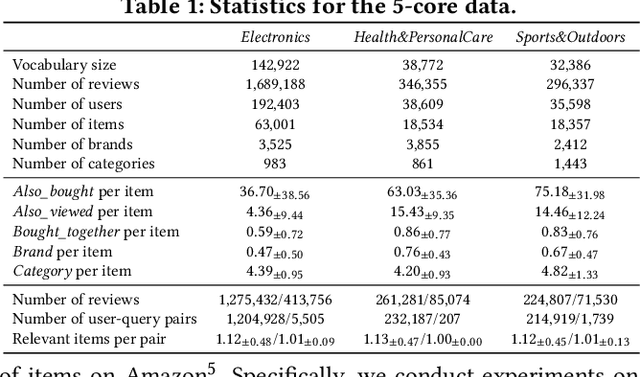
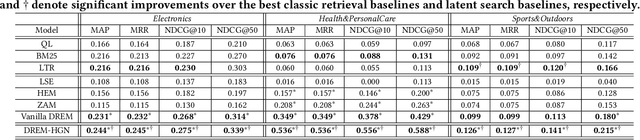

Product retrieval systems have served as the main entry for customers to discover and purchase products online. With increasing concerns on the transparency and accountability of AI systems, studies on explainable information retrieval has received more and more attention in the research community. Interestingly, in the domain of e-commerce, despite the extensive studies on explainable product recommendation, the studies of explainable product search is still in an early stage. In this paper, we study how to construct effective explainable product search by comparing model-agnostic explanation paradigms with model-intrinsic paradigms and analyzing the important factors that determine the performance of product search explanations. We propose an explainable product search model with model-intrinsic interpretability and conduct crowdsourcing to compare it with the state-of-the-art explainable product search model with model-agnostic interpretability. We observe that both paradigms have their own advantages and the effectiveness of search explanations on different properties are affected by different factors. For example, explanation fidelity is more important for user's overall satisfaction on the system while explanation novelty may be more useful in attracting user purchases. These findings could have important implications for the future studies and design of explainable product search engines.
CausalRec: Causal Inference for Visual Debiasing in Visually-Aware Recommendation
Jul 06, 2021
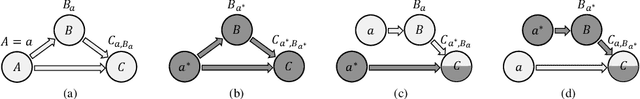
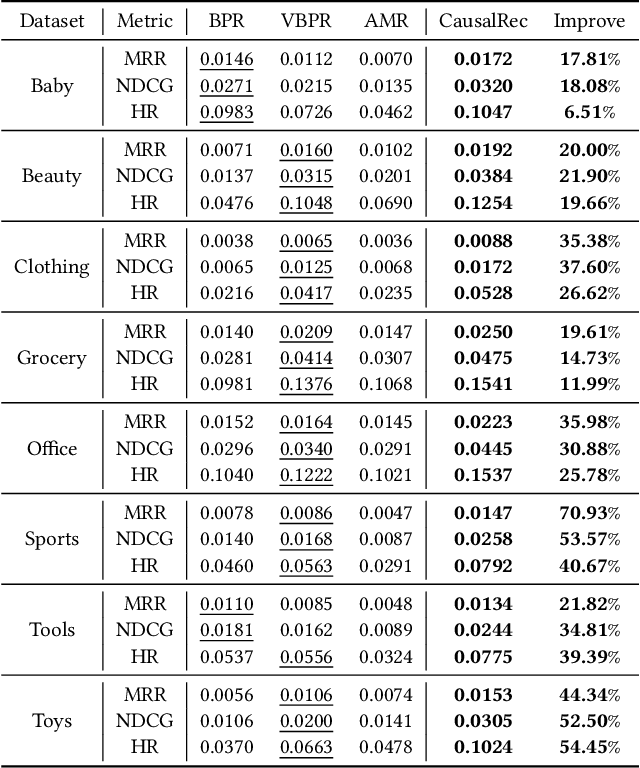
Visually-aware recommendation on E-commerce platforms aims to leverage visual information of items to predict a user's preference. It is commonly observed that user's attention to visual features does not always reflect the real preference. Although a user may click and view an item in light of a visual satisfaction of their expectations, a real purchase does not always occur due to the unsatisfaction of other essential features (e.g., brand, material, price). We refer to the reason for such a visually related interaction deviating from the real preference as a visual bias. Existing visually-aware models make use of the visual features as a separate collaborative signal similarly to other features to directly predict the user's preference without considering a potential bias, which gives rise to a visually biased recommendation. In this paper, we derive a causal graph to identify and analyze the visual bias of these existing methods. In this causal graph, the visual feature of an item acts as a mediator, which could introduce a spurious relationship between the user and the item. To eliminate this spurious relationship that misleads the prediction of the user's real preference, an intervention and a counterfactual inference are developed over the mediator. Particularly, the Total Indirect Effect is applied for a debiased prediction during the testing phase of the model. This causal inference framework is model agnostic such that it can be integrated into the existing methods. Furthermore, we propose a debiased visually-aware recommender system, denoted as CausalRec to effectively retain the supportive significance of the visual information and remove the visual bias. Extensive experiments are conducted on eight benchmark datasets, which shows the state-of-the-art performance of CausalRec and the efficacy of debiasing.
Multitask Recalibrated Aggregation Network for Medical Code Prediction
Apr 30, 2021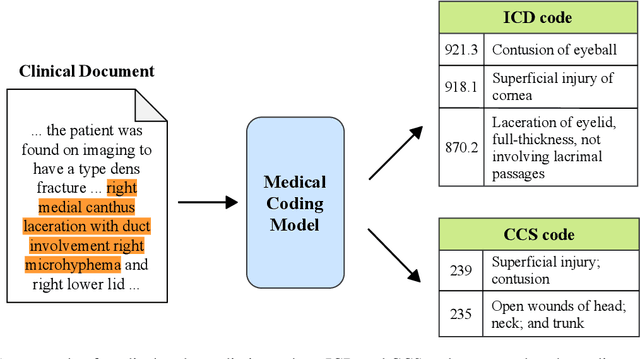
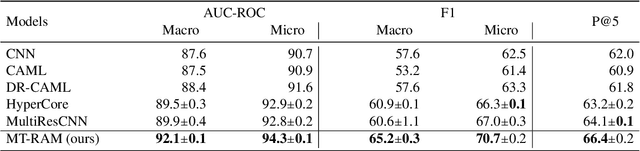
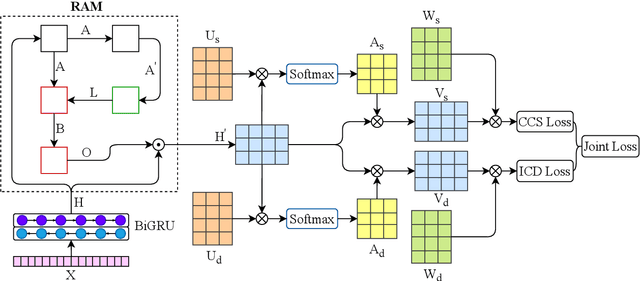
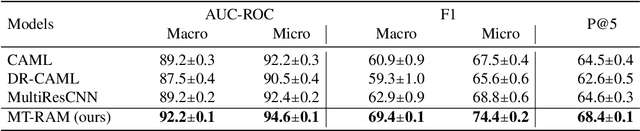
Medical coding translates professionally written medical reports into standardized codes, which is an essential part of medical information systems and health insurance reimbursement. Manual coding by trained human coders is time-consuming and error-prone. Thus, automated coding algorithms have been developed, building especially on the recent advances in machine learning and deep neural networks. To solve the challenges of encoding lengthy and noisy clinical documents and capturing code associations, we propose a multitask recalibrated aggregation network. In particular, multitask learning shares information across different coding schemes and captures the dependencies between different medical codes. Feature recalibration and aggregation in shared modules enhance representation learning for lengthy notes. Experiments with a real-world MIMIC-III dataset show significantly improved predictive performance.
TFRD: A Benchmark Dataset for Research on Temperature Field Reconstruction of Heat-Source Systems
Aug 17, 2021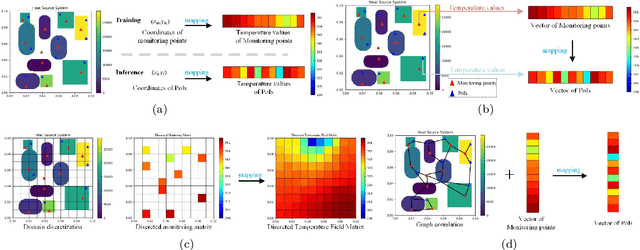
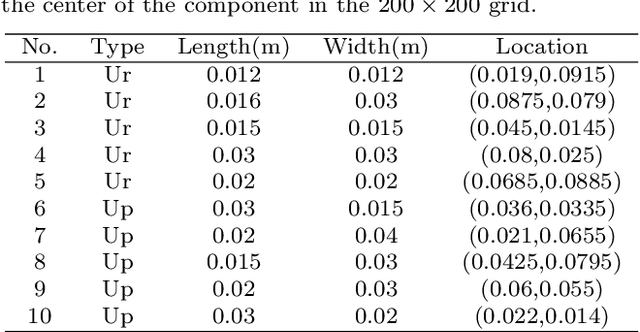
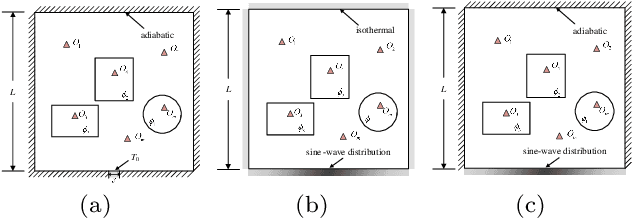
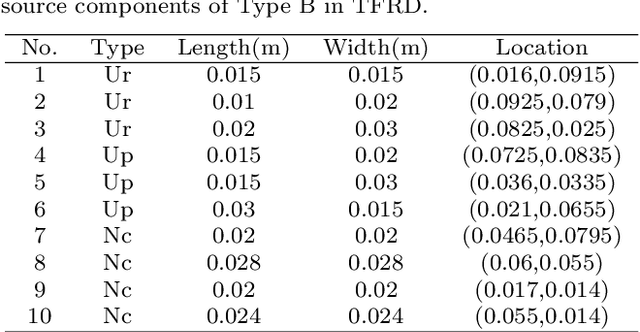
Heat management plays an important role in engineering. Temperature field reconstruction of heat source systems (TFR-HSS) with limited monitoring tensors, performs an essential role in heat management. However, prior methods with common interpolations usually cannot provide accurate reconstruction. In addition, there exists no public dataset for widely research of reconstruction methods to further boost the field reconstruction in engineering. To overcome this problem, this work construct a specific dataset, namely TFRD, for TFR-HSS task with commonly used methods, including the interpolation methods and the surrogate model based methods, as baselines to advance the research over temperature field reconstruction. First, the TFR-HSS task is mathematically modelled from real-world engineering problem and three types of numerically modellings have been constructed to transform the problem into discrete mapping forms. Besides, this work selects four typical reconstruction problem with different heat source information and boundary conditions and generate the standard samples as training and testing samples for further research. Finally, a comprehensive review of the prior methods for TFR-HSS task as well as recent widely used deep learning methods is given and we provide a performance analysis of typical methods on TFRD, which can be served as the baseline results on this benchmark.
Recovering Loss to Followup Information Using Denoising Autoencoders
Feb 12, 2018
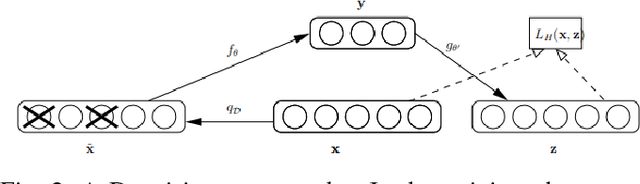
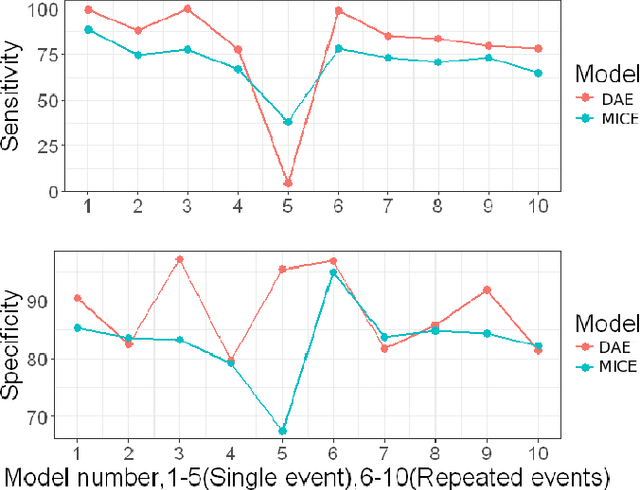
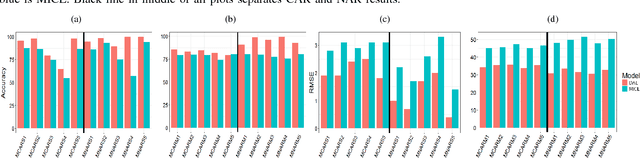
Loss to followup is a significant issue in healthcare and has serious consequences for a study's validity and cost. Methods available at present for recovering loss to followup information are restricted by their expressive capabilities and struggle to model highly non-linear relations and complex interactions. In this paper we propose a model based on overcomplete denoising autoencoders to recover loss to followup information. Designed to work with high volume data, results on various simulated and real life datasets show our model is appropriate under varying dataset and loss to followup conditions and outperforms the state-of-the-art methods by a wide margin ($\ge 20\%$ in some scenarios) while preserving the dataset utility for final analysis.
Rise of the Autonomous Machines
Jun 26, 2021
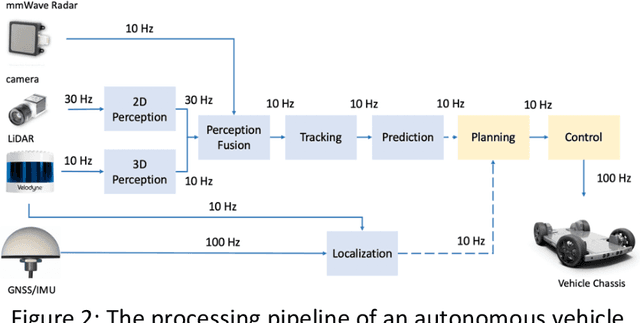
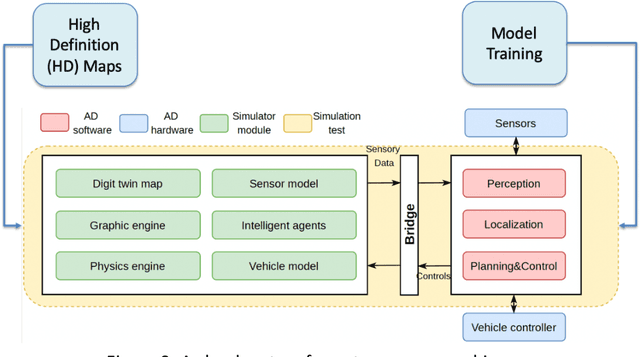
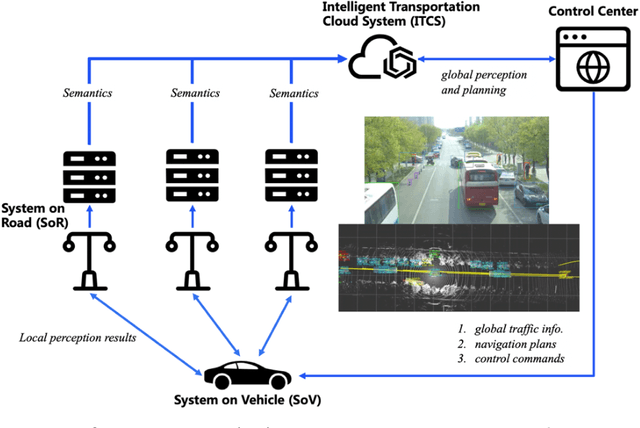
After decades of uninterrupted progress and growth, information technology has so evolved that it can be said we are entering the age of autonomous machines, but there exist many roadblocks in the way of making this a reality. In this article, we make a preliminary attempt at recognizing and categorizing the technical and non-technical challenges of autonomous machines; for each of the ten areas we have identified, we review current status, roadblocks, and potential research directions. It is hoped that this will help the community define clear, effective, and more formal development goalposts for the future.
Interactive Label Cleaning with Example-based Explanations
Jun 07, 2021


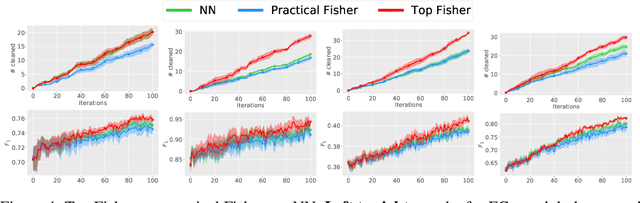
We tackle sequential learning under label noise in applications where a human supervisor can be queried to relabel suspicious examples. Existing approaches are flawed, in that they only relabel incoming examples that look ``suspicious'' to the model. As a consequence, those mislabeled examples that elude (or don't undergo) this cleaning step end up tainting the training data and the model with no further chance of being cleaned. We propose Cincer, a novel approach that cleans both new and past data by identifying pairs of mutually incompatible examples. Whenever it detects a suspicious example, Cincer identifies a counter-example in the training set that -- according to the model -- is maximally incompatible with the suspicious example, and asks the annotator to relabel either or both examples, resolving this possible inconsistency. The counter-examples are chosen to be maximally incompatible, so to serve as explanations of the model' suspicion, and highly influential, so to convey as much information as possible if relabeled. Cincer achieves this by leveraging an efficient and robust approximation of influence functions based on the Fisher information matrix (FIM). Our extensive empirical evaluation shows that clarifying the reasons behind the model's suspicions by cleaning the counter-examples helps acquiring substantially better data and models, especially when paired with our FIM approximation.
Privileged Zero-Shot AutoML
Jun 25, 2021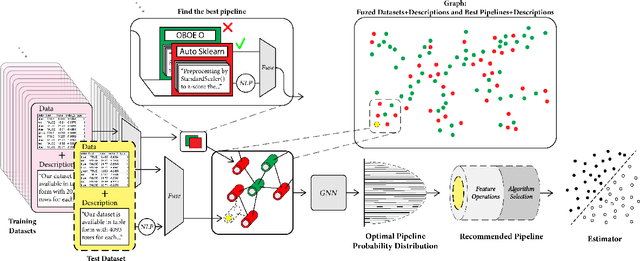
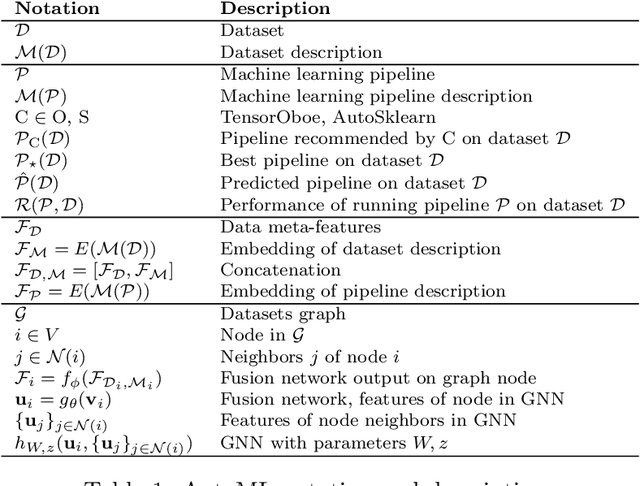
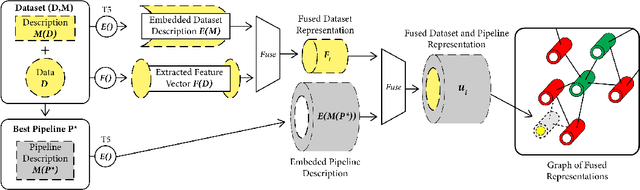
This work improves the quality of automated machine learning (AutoML) systems by using dataset and function descriptions while significantly decreasing computation time from minutes to milliseconds by using a zero-shot approach. Given a new dataset and a well-defined machine learning task, humans begin by reading a description of the dataset and documentation for the algorithms to be used. This work is the first to use these textual descriptions, which we call privileged information, for AutoML. We use a pre-trained Transformer model to process the privileged text and demonstrate that using this information improves AutoML performance. Thus, our approach leverages the progress of unsupervised representation learning in natural language processing to provide a significant boost to AutoML. We demonstrate that using only textual descriptions of the data and functions achieves reasonable classification performance, and adding textual descriptions to data meta-features improves classification across tabular datasets. To achieve zero-shot AutoML we train a graph neural network with these description embeddings and the data meta-features. Each node represents a training dataset, which we use to predict the best machine learning pipeline for a new test dataset in a zero-shot fashion. Our zero-shot approach rapidly predicts a high-quality pipeline for a supervised learning task and dataset. In contrast, most AutoML systems require tens or hundreds of pipeline evaluations. We show that zero-shot AutoML reduces running and prediction times from minutes to milliseconds, consistently across datasets. By speeding up AutoML by orders of magnitude this work demonstrates real-time AutoML.