 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Comparison of Methods for OOV-word Recognition on a New Public Dataset
Jul 16, 2021
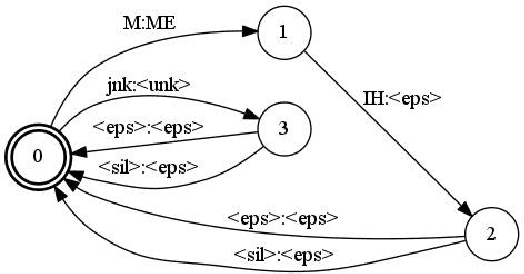
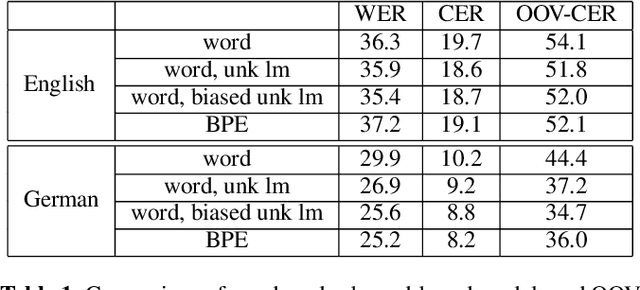
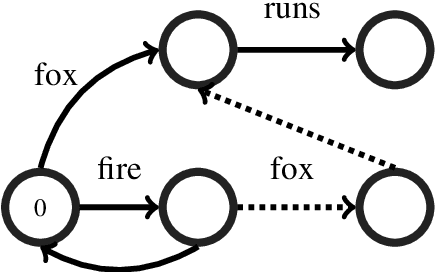
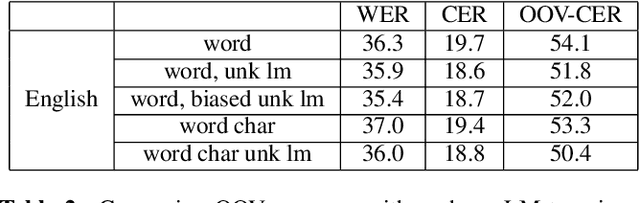
A common problem for automatic speech recognition systems is how to recognize words that they did not see during training. Currently there is no established method of evaluating different techniques for tackling this problem. We propose using the CommonVoice dataset to create test sets for multiple languages which have a high out-of-vocabulary (OOV) ratio relative to a training set and release a new tool for calculating relevant performance metrics. We then evaluate, within the context of a hybrid ASR system, how much better subword models are at recognizing OOVs, and how much benefit one can get from incorporating OOV-word information into an existing system by modifying WFSTs. Additionally, we propose a new method for modifying a subword-based language model so as to better recognize OOV-words. We showcase very large improvements in OOV-word recognition and make both the data and code available.
Assessing the Knowledge State of Online Students -- New Data, New Approaches, Improved Accuracy
Sep 04, 2021
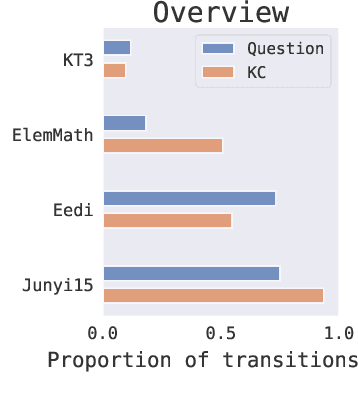
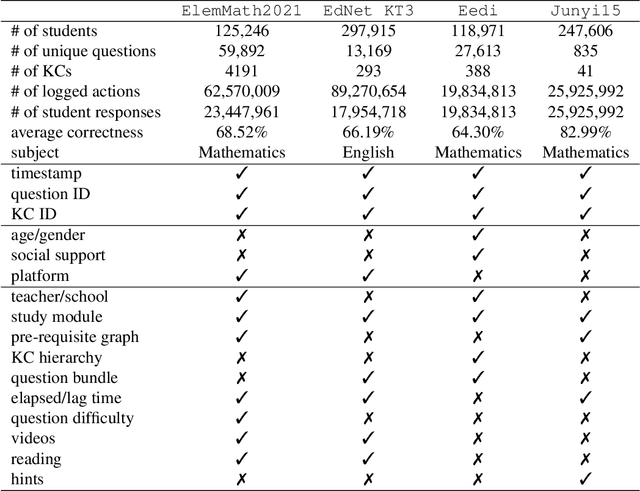
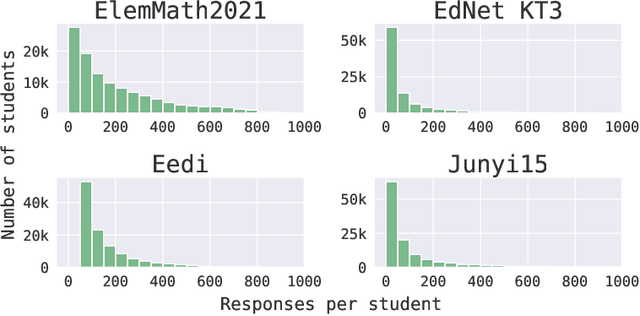
We consider the problem of assessing the changing knowledge state of individual students as they go through online courses. This student performance (SP) modeling problem, also known as knowledge tracing, is a critical step for building adaptive online teaching systems. Specifically, we conduct a study of how to utilize various types and large amounts of students log data to train accurate machine learning models that predict the knowledge state of future students. This study is the first to use four very large datasets made available recently from four distinct intelligent tutoring systems. Our results include a new machine learning approach that defines a new state of the art for SP modeling, improving over earlier methods in several ways: First, we achieve improved accuracy by introducing new features that can be easily computed from conventional question-response logs (e.g., the pattern in the student's most recent answers). Second, we take advantage of features of the student history that go beyond question-response pairs (e.g., which video segments the student watched, or skipped) as well as information about prerequisite structure in the curriculum. Third, we train multiple specialized modeling models for different aspects of the curriculum (e.g., specializing in early versus later segments of the student history), then combine these specialized models to create a group prediction of student knowledge. Taken together, these innovations yield an average AUC score across these four datasets of 0.807 compared to the previous best logistic regression approach score of 0.766, and also outperforming state-of-the-art deep neural net approaches. Importantly, we observe consistent improvements from each of our three methodological innovations, in each dataset, suggesting that our methods are of general utility and likely to produce improvements for other online tutoring systems as well.
Partially-Observed Decoupled Data-based Control (POD2C) for Complex Robotic Systems
Jul 16, 2021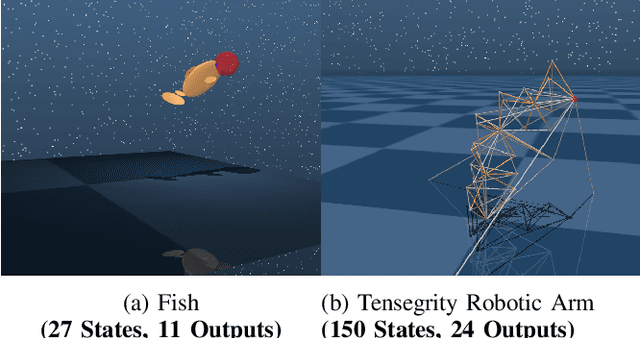
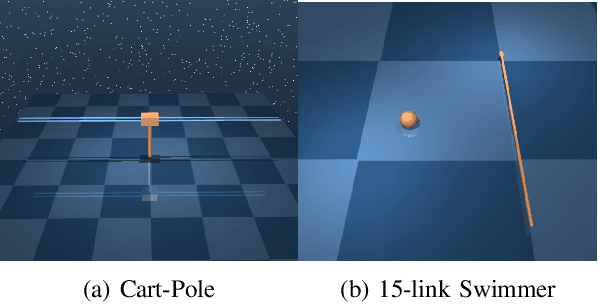
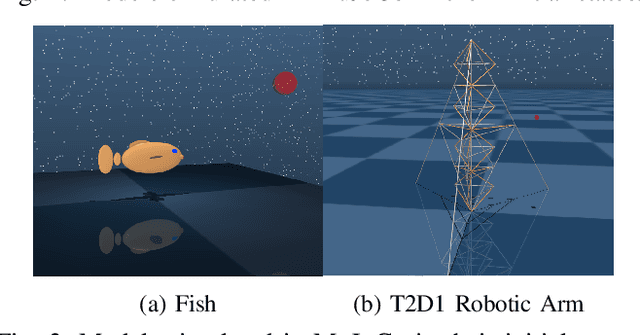
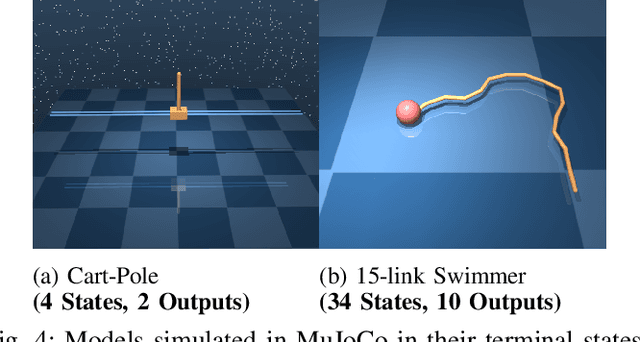
This paper develops a systematic data-based approach to the closed-loop feedback control of high-dimensional robotic systems using only partial state observation. We first develop a model-free generalization of the iterative Linear Quadratic Regulator (iLQR) to partially-observed systems using an Autoregressive Moving Average (ARMA) model, that is generated using only the input-output data. The ARMA model results in an information state, which has dimension less than or equal to the underlying actual state dimension. This open-loop trajectory optimization solution is then used to design a local feedback control law, and the composite law then provides a solution to the partially observed feedback design problem. The efficacy of the developed method is shown by controlling complex high dimensional nonlinear robotic systems in the presence of model and sensing uncertainty and for which analytical models are either unavailable or inaccurate.
A Generalizable Model-and-Data Driven Approach for Open-Set RFF Authentication
Aug 10, 2021
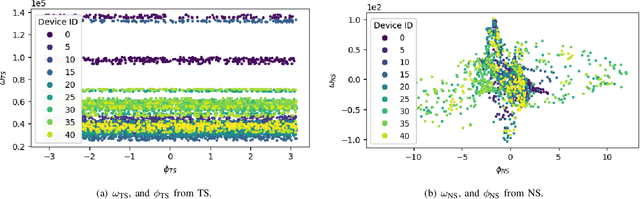

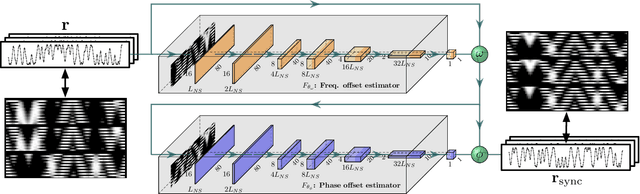
Radio-frequency fingerprints~(RFFs) are promising solutions for realizing low-cost physical layer authentication. Machine learning-based methods have been proposed for RFF extraction and discrimination. However, most existing methods are designed for the closed-set scenario where the set of devices is remains unchanged. These methods can not be generalized to the RFF discrimination of unknown devices. To enable the discrimination of RFF from both known and unknown devices, we propose a new end-to-end deep learning framework for extracting RFFs from raw received signals. The proposed framework comprises a novel preprocessing module, called neural synchronization~(NS), which incorporates the data-driven learning with signal processing priors as an inductive bias from communication-model based processing. Compared to traditional carrier synchronization techniques, which are static, this module estimates offsets by two learnable deep neural networks jointly trained by the RFF extractor. Additionally, a hypersphere representation is proposed to further improve the discrimination of RFF. Theoretical analysis shows that such a data-and-model framework can better optimize the mutual information between device identity and the RFF, which naturally leads to better performance. Experimental results verify that the proposed RFF significantly outperforms purely data-driven DNN-design and existing handcrafted RFF methods in terms of both discrimination and network generalizability.
StrucTexT: Structured Text Understanding with Multi-Modal Transformers
Aug 10, 2021
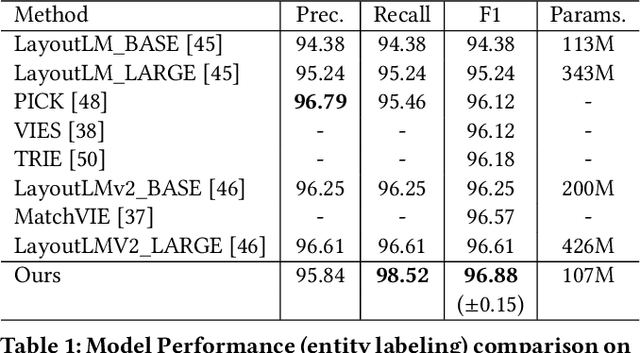
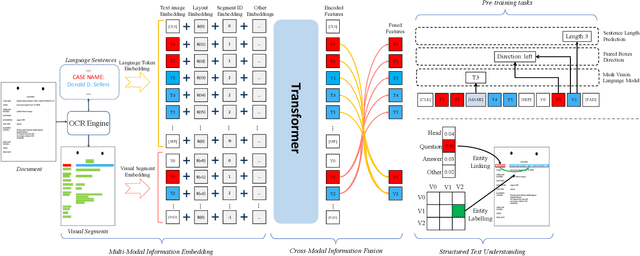
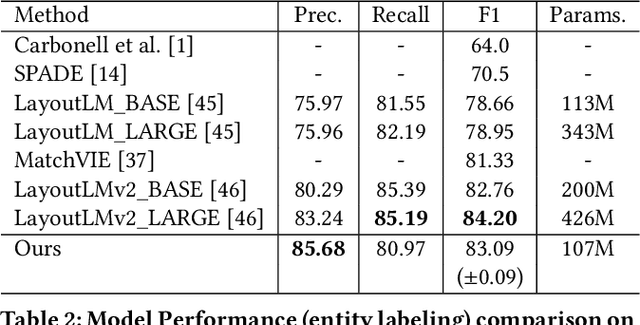
Structured text understanding on Visually Rich Documents (VRDs) is a crucial part of Document Intelligence. Due to the complexity of content and layout in VRDs, structured text understanding has been a challenging task. Most existing studies decoupled this problem into two sub-tasks: entity labeling and entity linking, which require an entire understanding of the context of documents at both token and segment levels. However, little work has been concerned with the solutions that efficiently extract the structured data from different levels. This paper proposes a unified framework named StrucTexT, which is flexible and effective for handling both sub-tasks. Specifically, based on the transformer, we introduce a segment-token aligned encoder to deal with the entity labeling and entity linking tasks at different levels of granularity. Moreover, we design a novel pre-training strategy with three self-supervised tasks to learn a richer representation. StrucTexT uses the existing Masked Visual Language Modeling task and the new Sentence Length Prediction and Paired Boxes Direction tasks to incorporate the multi-modal information across text, image, and layout. We evaluate our method for structured text understanding at segment-level and token-level and show it outperforms the state-of-the-art counterparts with significantly superior performance on the FUNSD, SROIE, and EPHOIE datasets.
SCIDA: Self-Correction Integrated Domain Adaptation from Single- to Multi-label Aerial Images
Aug 15, 2021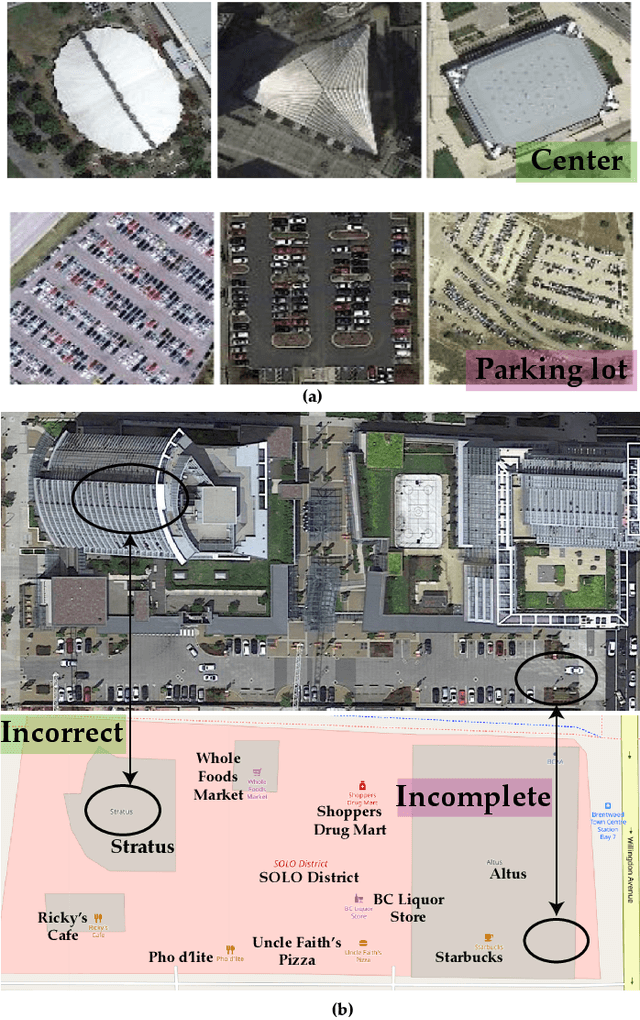
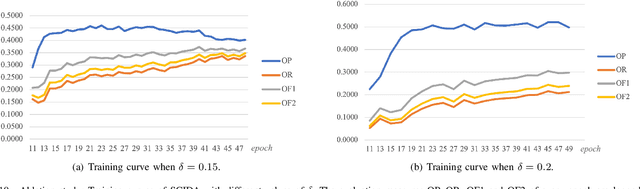
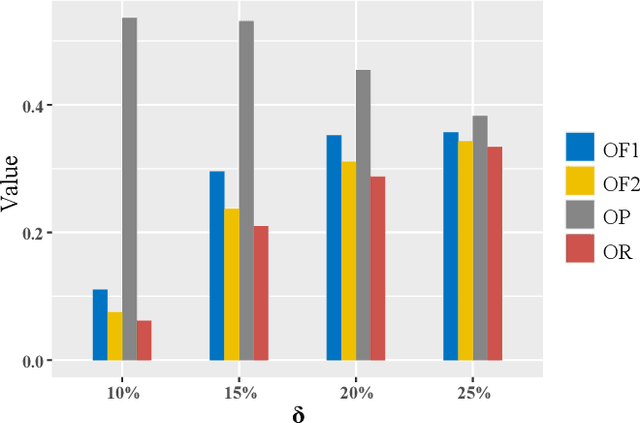
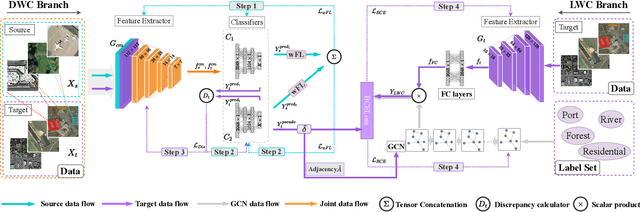
Most publicly available datasets for image classification are with single labels, while images are inherently multi-labeled in our daily life. Such an annotation gap makes many pre-trained single-label classification models fail in practical scenarios. This annotation issue is more concerned for aerial images: Aerial data collected from sensors naturally cover a relatively large land area with multiple labels, while annotated aerial datasets, which are publicly available (e.g., UCM, AID), are single-labeled. As manually annotating multi-label aerial images would be time/labor-consuming, we propose a novel self-correction integrated domain adaptation (SCIDA) method for automatic multi-label learning. SCIDA is weakly supervised, i.e., automatically learning the multi-label image classification model from using massive, publicly available single-label images. To achieve this goal, we propose a novel Label-Wise self-Correction (LWC) module to better explore underlying label correlations. This module also makes the unsupervised domain adaptation (UDA) from single- to multi-label data possible. For model training, the proposed model only uses single-label information yet requires no prior knowledge of multi-labeled data; and it predicts labels for multi-label aerial images. In our experiments, trained with single-labeled MAI-AID-s and MAI-UCM-s datasets, the proposed model is tested directly on our collected Multi-scene Aerial Image (MAI) dataset.
Learning-based Predictive Beamforming for Integrated Sensing and Communication in Vehicular Networks
Aug 26, 2021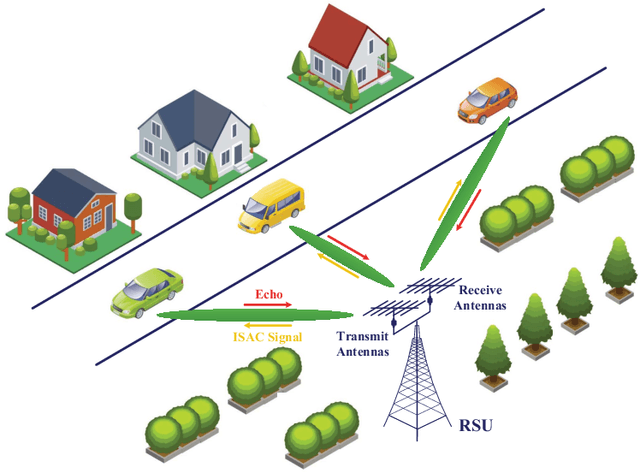
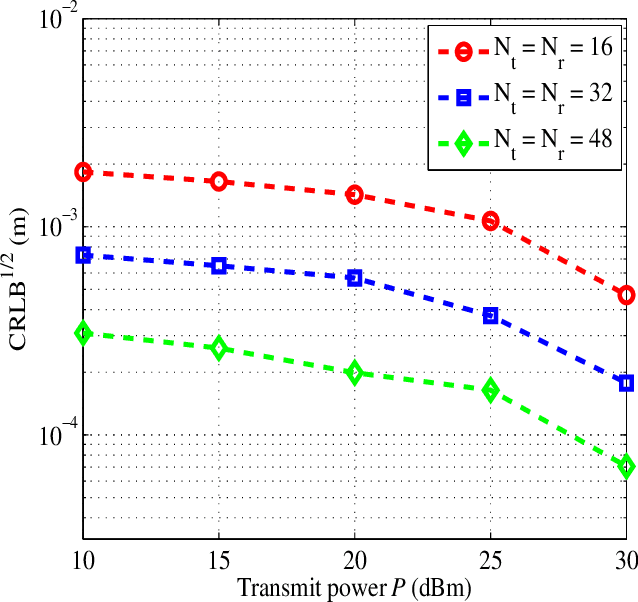
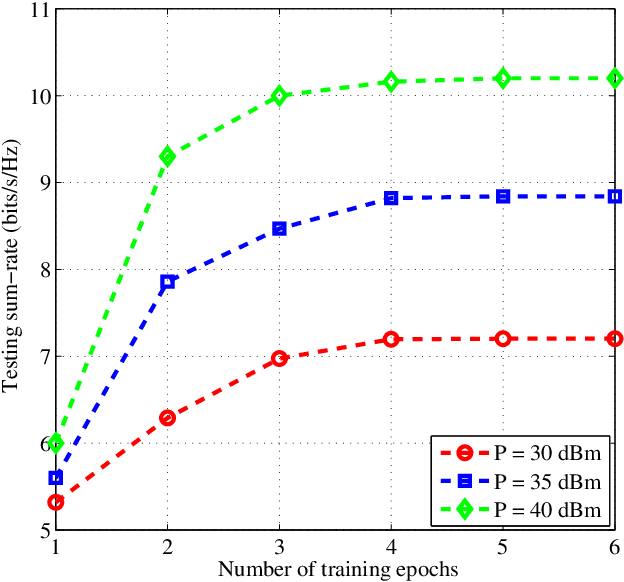
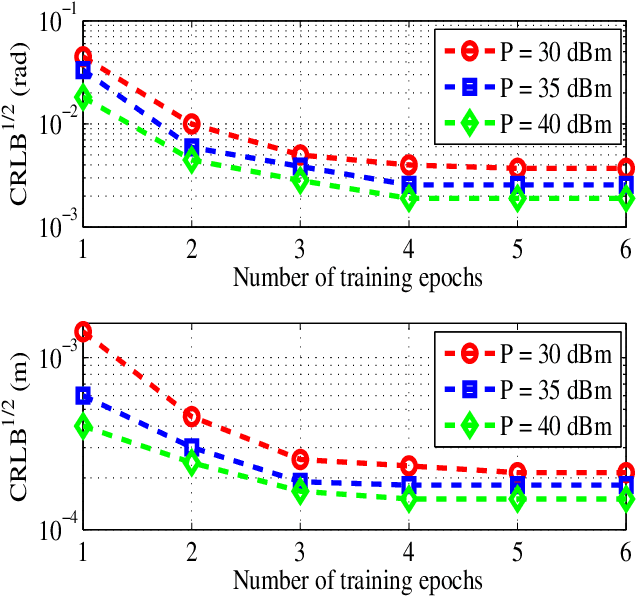
This paper investigates the integrated sensing and communication (ISAC) in vehicle-to-infrastructure (V2I) networks. To realize ISAC, an effective beamforming design is essential which however, highly depends on the availability of accurate channel tracking requiring large training overhead and computational complexity. Motivated by this, we adopt a deep learning (DL) approach to implicitly learn the features of historical channels and directly predict the beamforming matrix to be adopted for the next time slot to maximize the average achievable sum-rate of an ISAC system. The proposed method can bypass the need of explicit channel tracking process and reduce the signaling overhead significantly. To this end, a general sum-rate maximization problem with Cramer-Rao lower bounds (CRLBs)-based sensing constraints is first formulated for the considered ISAC system. Then, by exploiting the penalty method, a versatile unsupervised DL-based predictive beamforming design framework is developed to address the formulated design problem. As a realization of the developed framework, a historical channels-based convolutional long short-term memory (LSTM) network (HCL-Net) is devised for predictive beamforming in the ISAC-based V2I network. Specifically, the convolution and LSTM modules are successively adopted in the proposed HCL-Net to exploit the spatial and temporal dependencies of communication channels to further improve the learning performance. Finally, simulation results show that the proposed predictive method not only guarantees the required sensing performance, but also achieves a satisfactory sum-rate that can approach the upper bound obtained by the genie-aided scheme with the perfect instantaneous channel state information.
Exploring the Properties and Evolution of Neural Network Eigenspaces during Training
Jun 18, 2021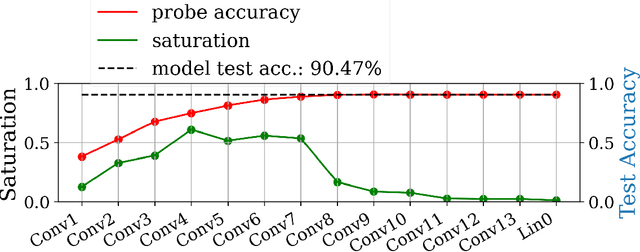
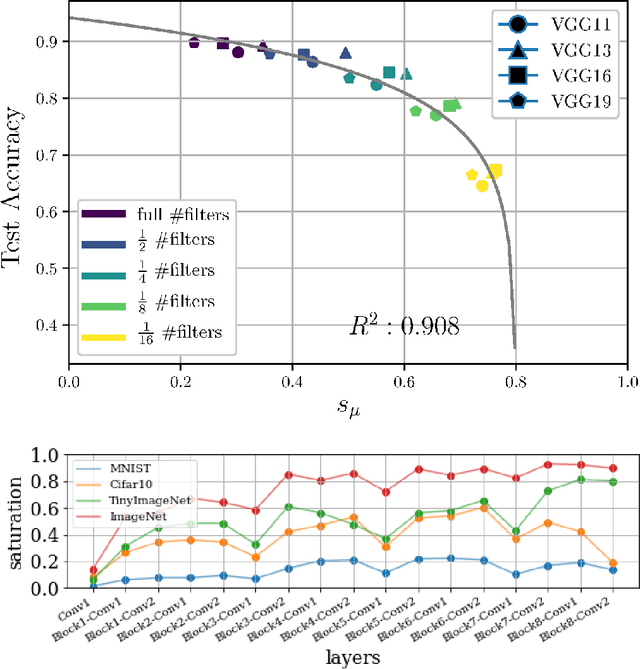
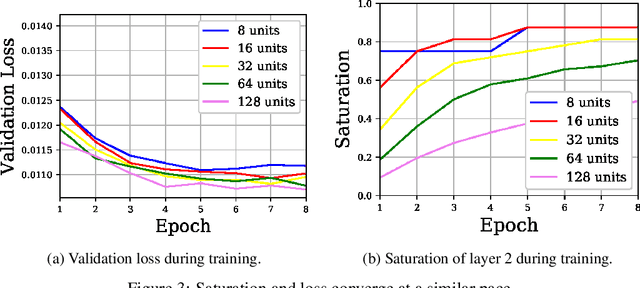
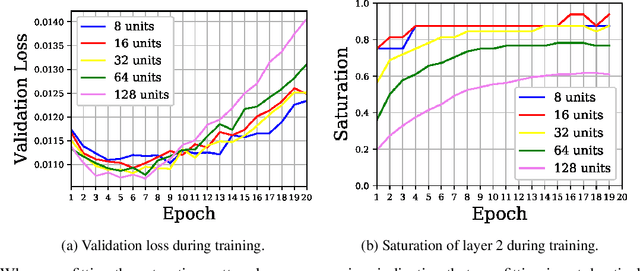
In this work we explore the information processing inside neural networks using logistic regression probes \cite{probes} and the saturation metric \cite{featurespace_saturation}. We show that problem difficulty and neural network capacity affect the predictive performance in an antagonistic manner, opening the possibility of detecting over- and under-parameterization of neural networks for a given task. We further show that the observed effects are independent from previously reported pathological patterns like the ``tail pattern'' described in \cite{featurespace_saturation}. Finally we are able to show that saturation patterns converge early during training, allowing for a quicker cycle time during analysis
Deep Position-wise Interaction Network for CTR Prediction
Jun 17, 2021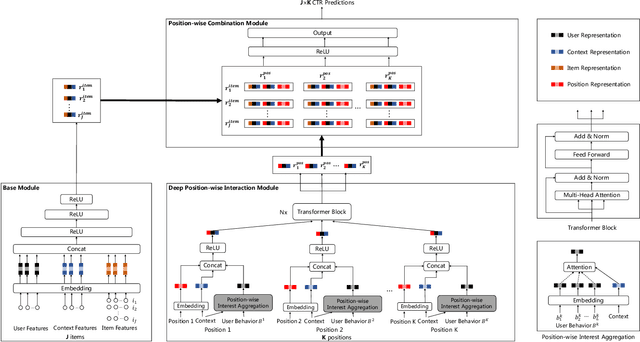
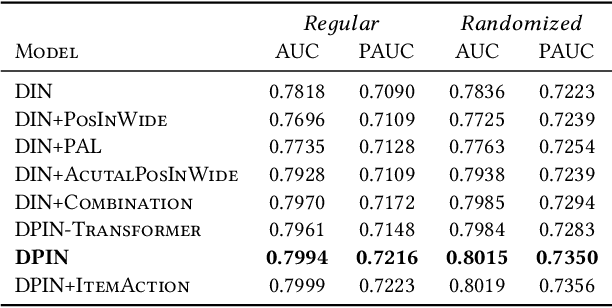
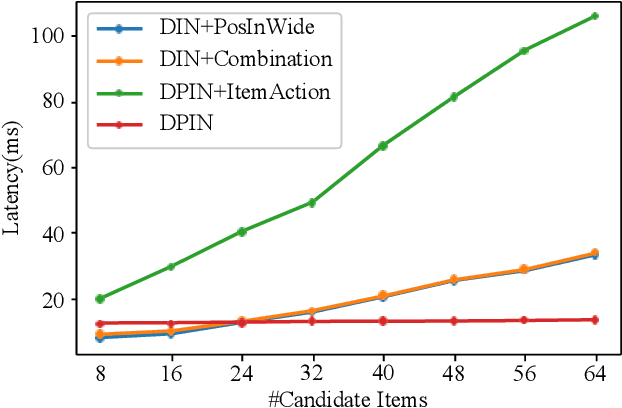
Click-through rate (CTR) prediction plays an important role in online advertising and recommender systems. In practice, the training of CTR models depends on click data which is intrinsically biased towards higher positions since higher position has higher CTR by nature. Existing methods such as actual position training with fixed position inference and inverse propensity weighted training with no position inference alleviate the bias problem to some extend. However, the different treatment of position information between training and inference will inevitably lead to inconsistency and sub-optimal online performance. Meanwhile, the basic assumption of these methods, i.e., the click probability is the product of examination probability and relevance probability, is oversimplified and insufficient to model the rich interaction between position and other information. In this paper, we propose a Deep Position-wise Interaction Network (DPIN) to efficiently combine all candidate items and positions for estimating CTR at each position, achieving consistency between offline and online as well as modeling the deep non-linear interaction among position, user, context and item under the limit of serving performance. Following our new treatment to the position bias in CTR prediction, we propose a new evaluation metrics named PAUC (position-wise AUC) that is suitable for measuring the ranking quality at a given position. Through extensive experiments on a real world dataset, we show empirically that our method is both effective and efficient in solving position bias problem. We have also deployed our method in production and observed statistically significant improvement over a highly optimized baseline in a rigorous A/B test.
PlaneTR: Structure-Guided Transformers for 3D Plane Recovery
Jul 27, 2021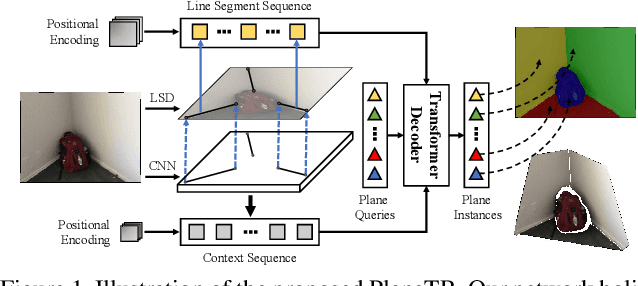
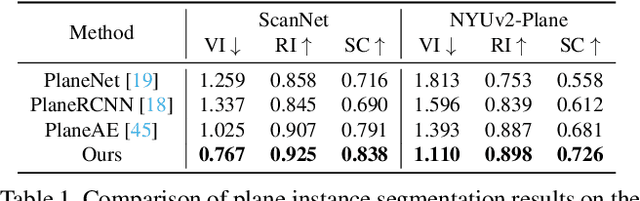
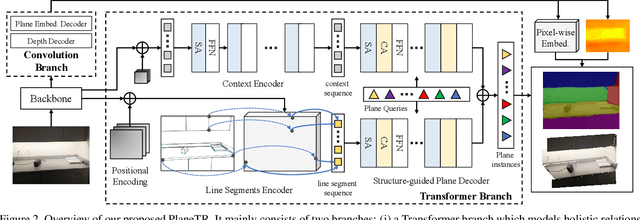
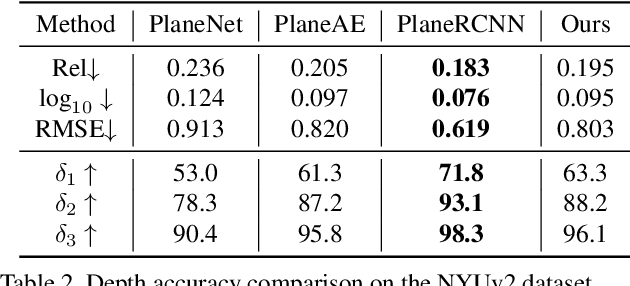
This paper presents a neural network built upon Transformers, namely PlaneTR, to simultaneously detect and reconstruct planes from a single image. Different from previous methods, PlaneTR jointly leverages the context information and the geometric structures in a sequence-to-sequence way to holistically detect plane instances in one forward pass. Specifically, we represent the geometric structures as line segments and conduct the network with three main components: (i) context and line segments encoders, (ii) a structure-guided plane decoder, (iii) a pixel-wise plane embedding decoder. Given an image and its detected line segments, PlaneTR generates the context and line segment sequences via two specially designed encoders and then feeds them into a Transformers-based decoder to directly predict a sequence of plane instances by simultaneously considering the context and global structure cues. Finally, the pixel-wise embeddings are computed to assign each pixel to one predicted plane instance which is nearest to it in embedding space. Comprehensive experiments demonstrate that PlaneTR achieves a state-of-the-art performance on the ScanNet and NYUv2 datasets.