 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Orthogonal Time Frequency Space Modulation: A Discrete Zak Transform Approach
Jun 24, 2021
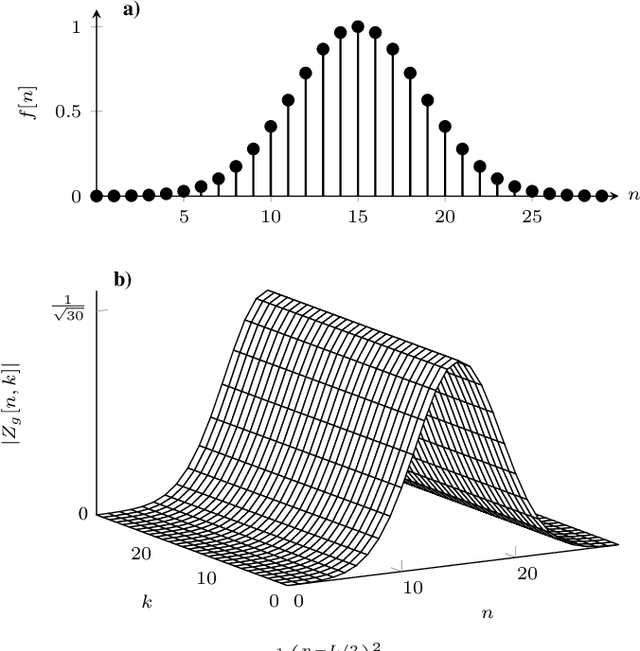
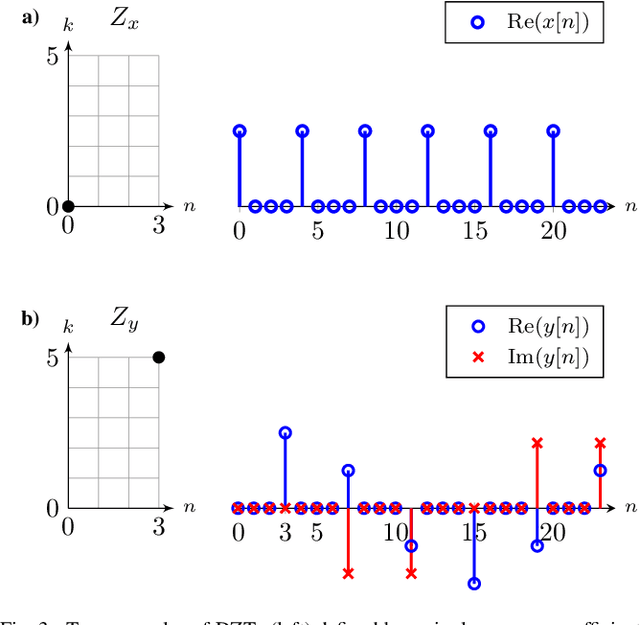
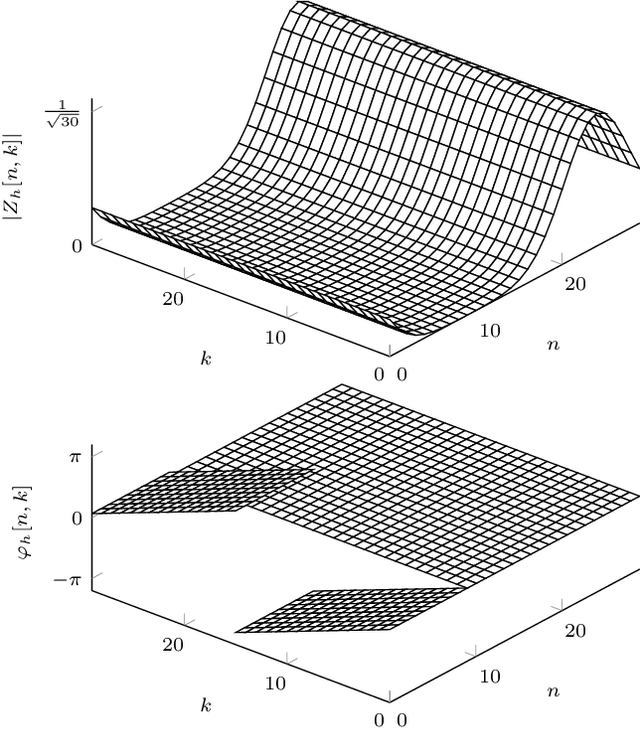
In orthogonal time frequency space (OTFS) modulation, information-carrying symbols reside in the delay-Doppler (DD) domain. By operating in the DD domain, an appealing property for communication arises: time-frequency (TF) dispersive channels encountered in high mobility environments become time-invariant. The time-invariance of the channel in the DD domain enables efficient equalizers for time-frequency dispersive channels. In this paper, we propose an OTFS system based on the discrete Zak transform. The presented formulation not only allows an efficient implementation of OTFS but also simplifies the derivation and analysis of the input-output relation of TF dispersive channel in the DD domain.
Non-local Channel Aggregation Network for Single Image Rain Removal
Mar 03, 2021



Rain streaks showing in images or videos would severely degrade the performance of computer vision applications. Thus, it is of vital importance to remove rain streaks and facilitate our vision systems. While recent convolutinal neural network based methods have shown promising results in single image rain removal (SIRR), they fail to effectively capture long-range location dependencies or aggregate convolutional channel information simultaneously. However, as SIRR is a highly illposed problem, these spatial and channel information are very important clues to solve SIRR. First, spatial information could help our model to understand the image context by gathering long-range dependency location information hidden in the image. Second, aggregating channels could help our model to concentrate on channels more related to image background instead of rain streaks. In this paper, we propose a non-local channel aggregation network (NCANet) to address the SIRR problem. NCANet models 2D rainy images as sequences of vectors in three directions, namely vertical direction, transverse direction and channel direction. Recurrently aggregating information from all three directions enables our model to capture the long-range dependencies in both channels and spaitials locations. Extensive experiments on both heavy and light rain image data sets demonstrate the effectiveness of the proposed NCANet model.
Explainable AI and susceptibility to adversarial attacks: a case study in classification of breast ultrasound images
Aug 09, 2021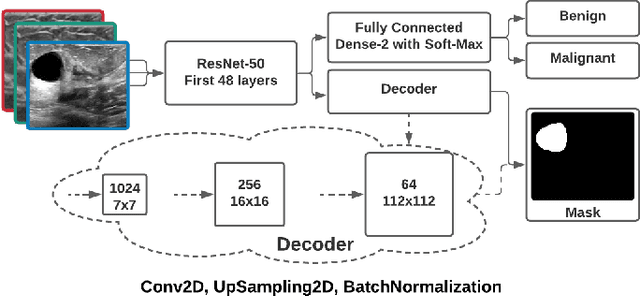
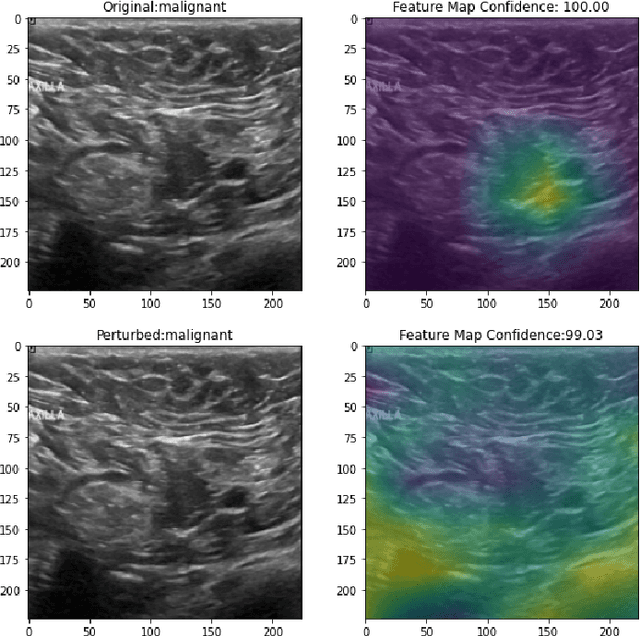
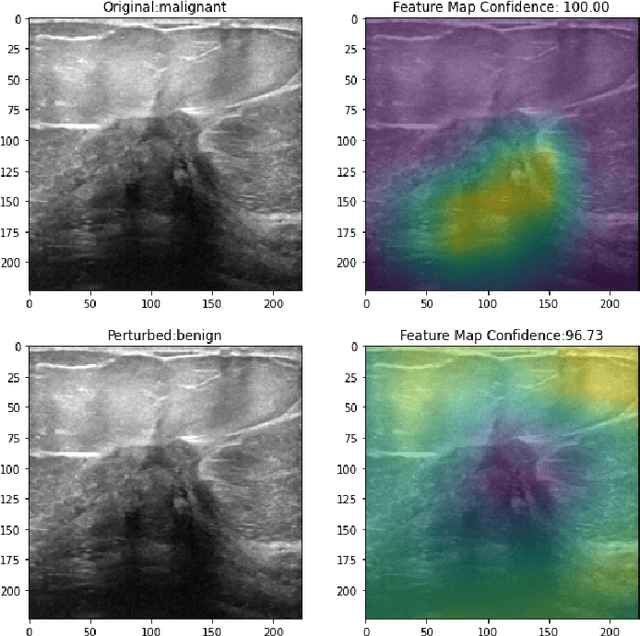
Ultrasound is a non-invasive imaging modality that can be conveniently used to classify suspicious breast nodules and potentially detect the onset of breast cancer. Recently, Convolutional Neural Networks (CNN) techniques have shown promising results in classifying ultrasound images of the breast into benign or malignant. However, CNN inference acts as a black-box model, and as such, its decision-making is not interpretable. Therefore, increasing effort has been dedicated to explaining this process, most notably through GRAD-CAM and other techniques that provide visual explanations into inner workings of CNNs. In addition to interpretation, these methods provide clinically important information, such as identifying the location for biopsy or treatment. In this work, we analyze how adversarial assaults that are practically undetectable may be devised to alter these importance maps dramatically. Furthermore, we will show that this change in the importance maps can come with or without altering the classification result, rendering them even harder to detect. As such, care must be taken when using these importance maps to shed light on the inner workings of deep learning. Finally, we utilize Multi-Task Learning (MTL) and propose a new network based on ResNet-50 to improve the classification accuracies. Our sensitivity and specificity is comparable to the state of the art results.
Fully Autonomous Real-World Reinforcement Learning for Mobile Manipulation
Aug 03, 2021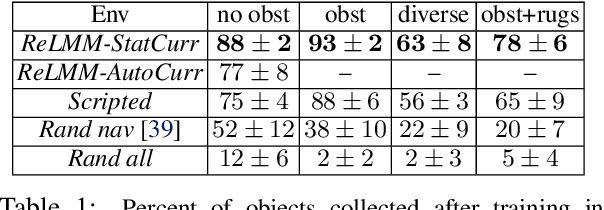
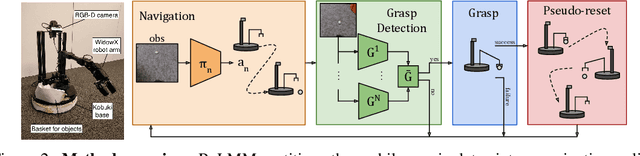

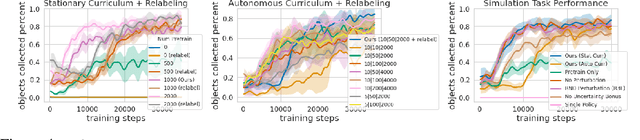
We study how robots can autonomously learn skills that require a combination of navigation and grasping. While reinforcement learning in principle provides for automated robotic skill learning, in practice reinforcement learning in the real world is challenging and often requires extensive instrumentation and supervision. Our aim is to devise a robotic reinforcement learning system for learning navigation and manipulation together, in an autonomous way without human intervention, enabling continual learning under realistic assumptions. Our proposed system, ReLMM, can learn continuously on a real-world platform without any environment instrumentation, without human intervention, and without access to privileged information, such as maps, objects positions, or a global view of the environment. Our method employs a modularized policy with components for manipulation and navigation, where manipulation policy uncertainty drives exploration for the navigation controller, and the manipulation module provides rewards for navigation. We evaluate our method on a room cleanup task, where the robot must navigate to and pick up items scattered on the floor. After a grasp curriculum training phase, ReLMM can learn navigation and grasping together fully automatically, in around 40 hours of autonomous real-world training.
A Comparison of Methods for OOV-word Recognition on a New Public Dataset
Jul 16, 2021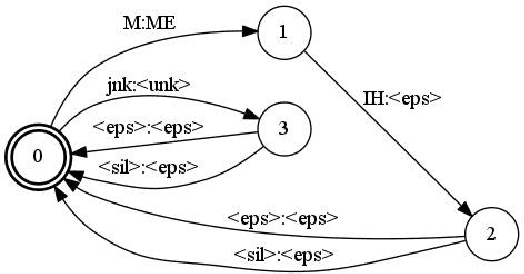
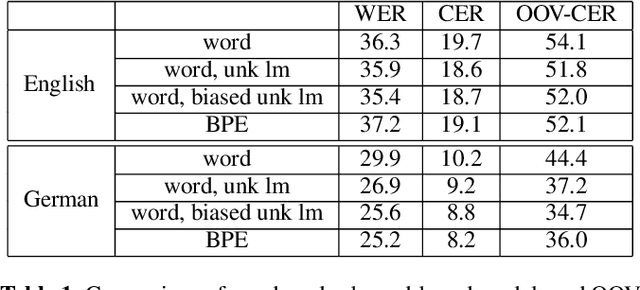
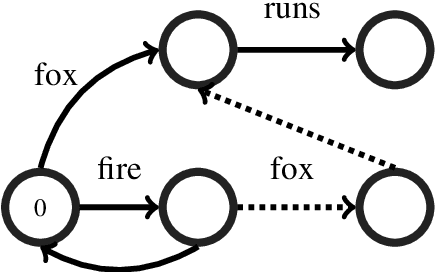
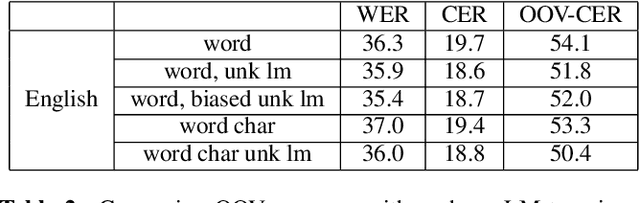
A common problem for automatic speech recognition systems is how to recognize words that they did not see during training. Currently there is no established method of evaluating different techniques for tackling this problem. We propose using the CommonVoice dataset to create test sets for multiple languages which have a high out-of-vocabulary (OOV) ratio relative to a training set and release a new tool for calculating relevant performance metrics. We then evaluate, within the context of a hybrid ASR system, how much better subword models are at recognizing OOVs, and how much benefit one can get from incorporating OOV-word information into an existing system by modifying WFSTs. Additionally, we propose a new method for modifying a subword-based language model so as to better recognize OOV-words. We showcase very large improvements in OOV-word recognition and make both the data and code available.
Privacy-Preserving Image Acquisition Using Trainable Optical Kernel
Jun 28, 2021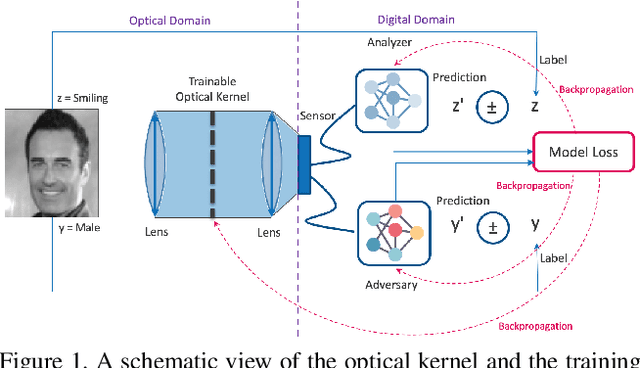
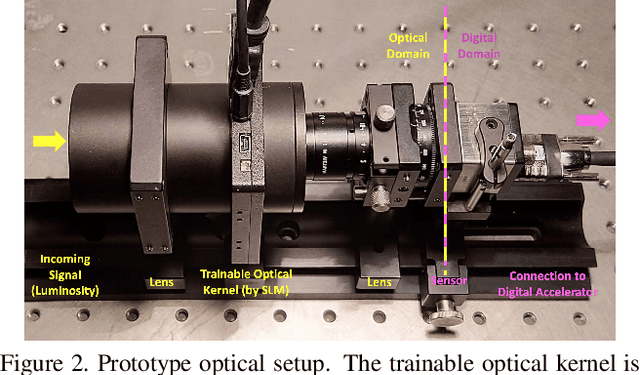
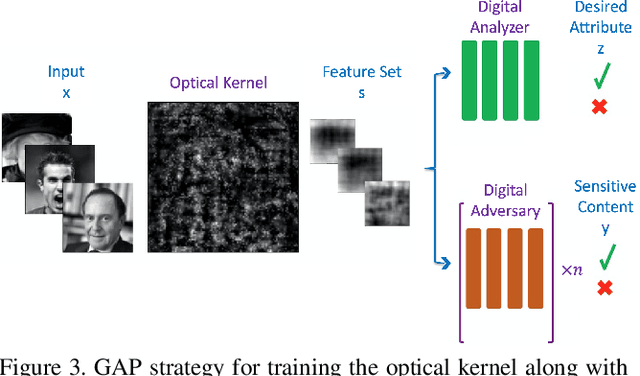

Preserving privacy is a growing concern in our society where sensors and cameras are ubiquitous. In this work, for the first time, we propose a trainable image acquisition method that removes the sensitive identity revealing information in the optical domain before it reaches the image sensor. The method benefits from a trainable optical convolution kernel which transmits the desired information while filters out the sensitive content. As the sensitive content is suppressed before it reaches the image sensor, it does not enter the digital domain therefore is unretrievable by any sort of privacy attack. This is in contrast with the current digital privacy-preserving methods that are all vulnerable to direct access attack. Also, in contrast with the previous optical privacy-preserving methods that cannot be trained, our method is data-driven and optimized for the specific application at hand. Moreover, there is no additional computation, memory, or power burden on the acquisition system since this processing happens passively in the optical domain and can even be used together and on top of the fully digital privacy-preserving systems. The proposed approach is adaptable to different digital neural networks and content. We demonstrate it for several scenarios such as smile detection as the desired attribute while the gender is filtered out as the sensitive content. We trained the optical kernel in conjunction with two adversarial neural networks where the analysis network tries to detect the desired attribute and the adversarial network tries to detect the sensitive content. We show that this method can reduce 65.1% of sensitive content when it is selected to be the gender and it only loses 7.3% of the desired content. Moreover, we reconstruct the original faces using the deep reconstruction method that confirms the ineffectiveness of reconstruction attacks to obtain the sensitive content.
Partially-Observed Decoupled Data-based Control (POD2C) for Complex Robotic Systems
Jul 16, 2021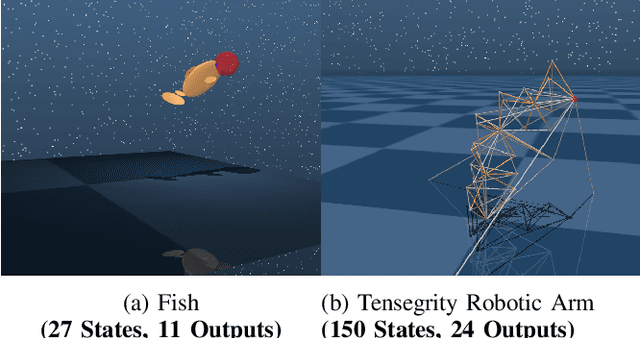
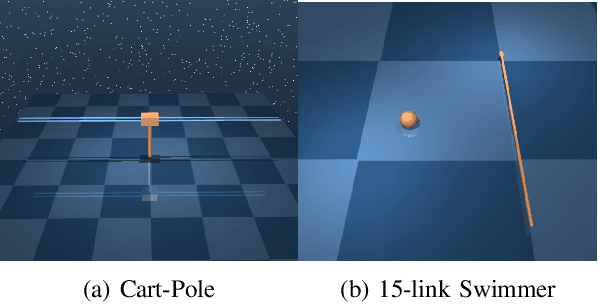
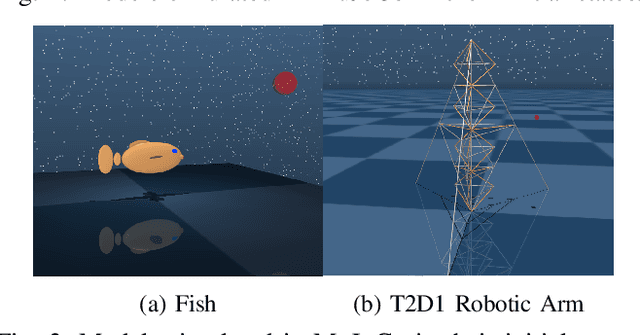
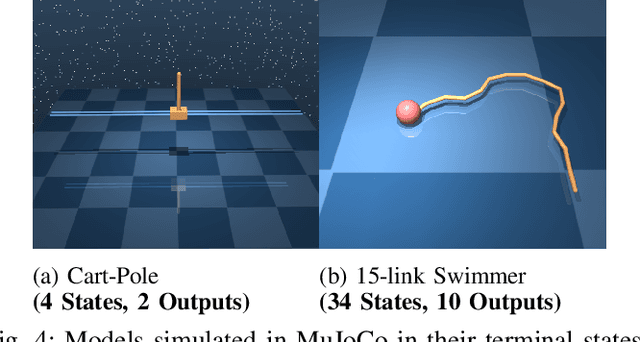
This paper develops a systematic data-based approach to the closed-loop feedback control of high-dimensional robotic systems using only partial state observation. We first develop a model-free generalization of the iterative Linear Quadratic Regulator (iLQR) to partially-observed systems using an Autoregressive Moving Average (ARMA) model, that is generated using only the input-output data. The ARMA model results in an information state, which has dimension less than or equal to the underlying actual state dimension. This open-loop trajectory optimization solution is then used to design a local feedback control law, and the composite law then provides a solution to the partially observed feedback design problem. The efficacy of the developed method is shown by controlling complex high dimensional nonlinear robotic systems in the presence of model and sensing uncertainty and for which analytical models are either unavailable or inaccurate.
PlaneTR: Structure-Guided Transformers for 3D Plane Recovery
Jul 27, 2021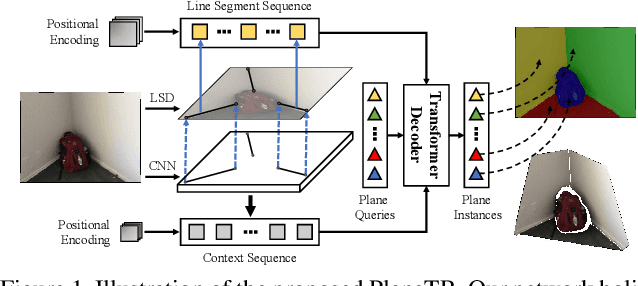
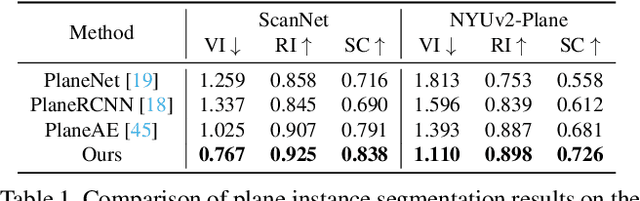
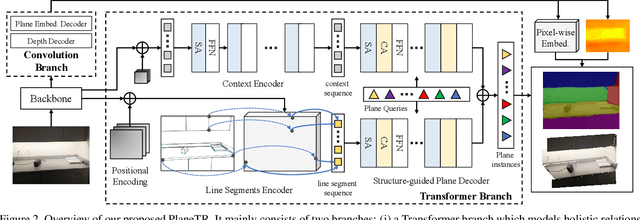
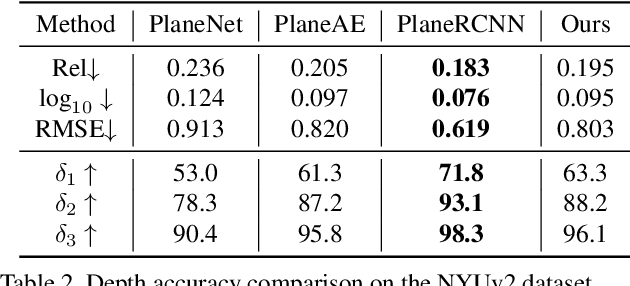
This paper presents a neural network built upon Transformers, namely PlaneTR, to simultaneously detect and reconstruct planes from a single image. Different from previous methods, PlaneTR jointly leverages the context information and the geometric structures in a sequence-to-sequence way to holistically detect plane instances in one forward pass. Specifically, we represent the geometric structures as line segments and conduct the network with three main components: (i) context and line segments encoders, (ii) a structure-guided plane decoder, (iii) a pixel-wise plane embedding decoder. Given an image and its detected line segments, PlaneTR generates the context and line segment sequences via two specially designed encoders and then feeds them into a Transformers-based decoder to directly predict a sequence of plane instances by simultaneously considering the context and global structure cues. Finally, the pixel-wise embeddings are computed to assign each pixel to one predicted plane instance which is nearest to it in embedding space. Comprehensive experiments demonstrate that PlaneTR achieves a state-of-the-art performance on the ScanNet and NYUv2 datasets.
Discriminative Region-based Multi-Label Zero-Shot Learning
Aug 20, 2021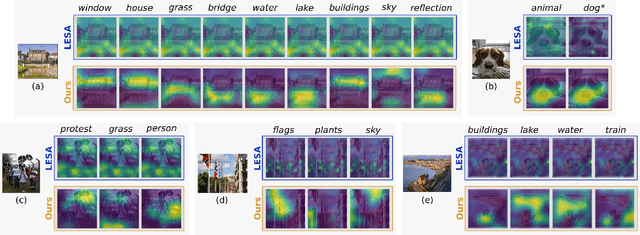
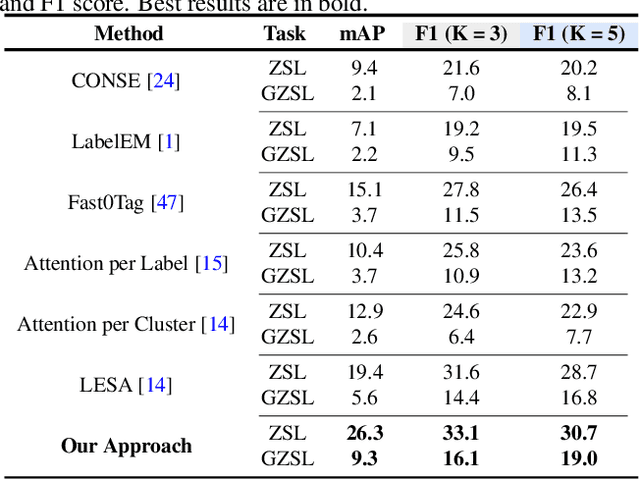
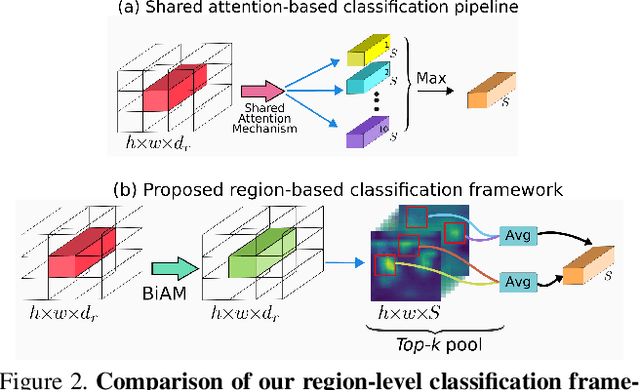
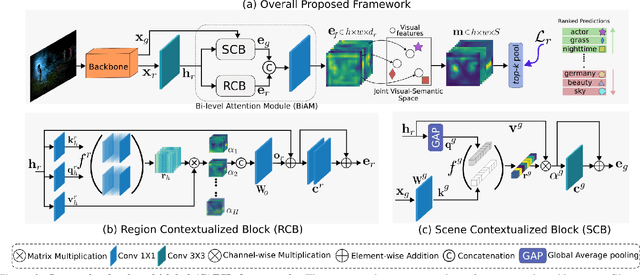
Multi-label zero-shot learning (ZSL) is a more realistic counter-part of standard single-label ZSL since several objects can co-exist in a natural image. However, the occurrence of multiple objects complicates the reasoning and requires region-specific processing of visual features to preserve their contextual cues. We note that the best existing multi-label ZSL method takes a shared approach towards attending to region features with a common set of attention maps for all the classes. Such shared maps lead to diffused attention, which does not discriminatively focus on relevant locations when the number of classes are large. Moreover, mapping spatially-pooled visual features to the class semantics leads to inter-class feature entanglement, thus hampering the classification. Here, we propose an alternate approach towards region-based discriminability-preserving multi-label zero-shot classification. Our approach maintains the spatial resolution to preserve region-level characteristics and utilizes a bi-level attention module (BiAM) to enrich the features by incorporating both region and scene context information. The enriched region-level features are then mapped to the class semantics and only their class predictions are spatially pooled to obtain image-level predictions, thereby keeping the multi-class features disentangled. Our approach sets a new state of the art on two large-scale multi-label zero-shot benchmarks: NUS-WIDE and Open Images. On NUS-WIDE, our approach achieves an absolute gain of 6.9% mAP for ZSL, compared to the best published results.
Recognising Biomedical Names: Challenges and Solutions
Jun 23, 2021

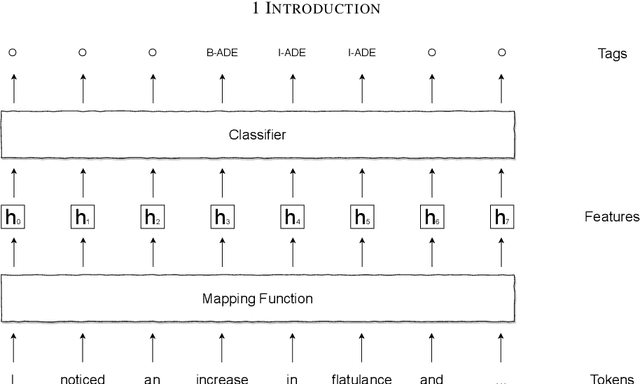
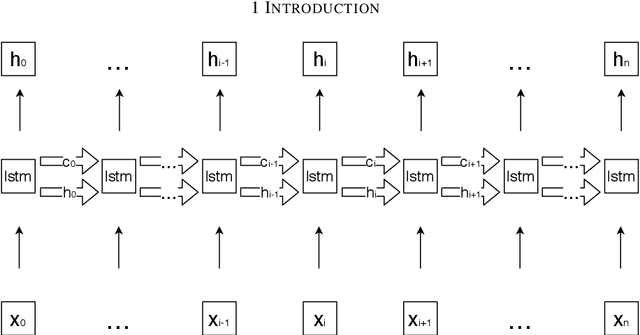
The growth rate in the amount of biomedical documents is staggering. Unlocking information trapped in these documents can enable researchers and practitioners to operate confidently in the information world. Biomedical NER, the task of recognising biomedical names, is usually employed as the first step of the NLP pipeline. Standard NER models, based on sequence tagging technique, are good at recognising short entity mentions in the generic domain. However, there are several open challenges of applying these models to recognise biomedical names: 1) Biomedical names may contain complex inner structure (discontinuity and overlapping) which cannot be recognised using standard sequence tagging technique; 2) The training of NER models usually requires large amount of labelled data, which are difficult to obtain in the biomedical domain; and, 3) Commonly used language representation models are pre-trained on generic data; a domain shift therefore exists between these models and target biomedical data. To deal with these challenges, we explore several research directions and make the following contributions: 1) we propose a transition-based NER model which can recognise discontinuous mentions; 2) We develop a cost-effective approach that nominates the suitable pre-training data; and, 3) We design several data augmentation methods for NER. Our contributions have obvious practical implications, especially when new biomedical applications are needed. Our proposed data augmentation methods can help the NER model achieve decent performance, requiring only a small amount of labelled data. Our investigation regarding selecting pre-training data can improve the model by incorporating language representation models, which are pre-trained using in-domain data. Finally, our proposed transition-based NER model can further improve the performance by recognising discontinuous mentions.