 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Audio Captioning Transformer
Jul 21, 2021
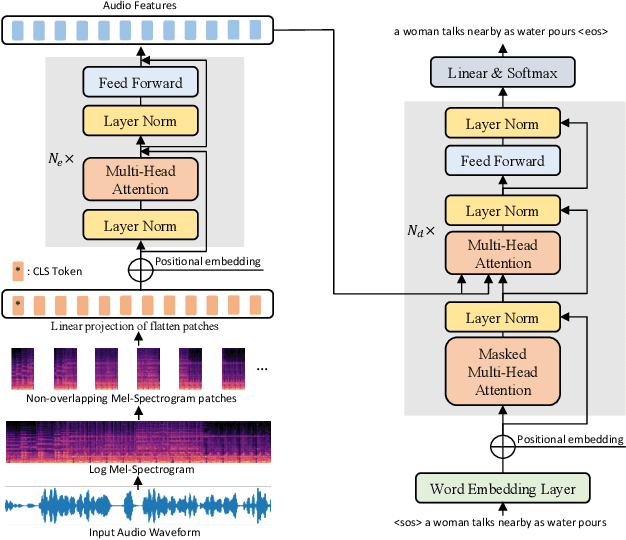

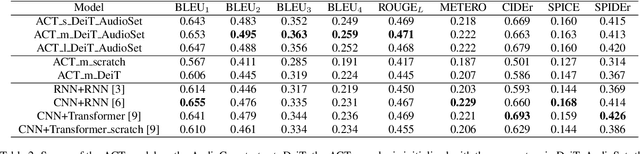
Audio captioning aims to automatically generate a natural language description of an audio clip. Most captioning models follow an encoder-decoder architecture, where the decoder predicts words based on the audio features extracted by the encoder. Convolutional neural networks (CNNs) and recurrent neural networks (RNNs) are often used as the audio encoder. However, CNNs can be limited in modelling temporal relationships among the time frames in an audio signal, while RNNs can be limited in modelling the long-range dependencies among the time frames. In this paper, we propose an Audio Captioning Transformer (ACT), which is a full Transformer network based on an encoder-decoder architecture and is totally convolution-free. The proposed method has a better ability to model the global information within an audio signal as well as capture temporal relationships between audio events. We evaluate our model on AudioCaps, which is the largest audio captioning dataset publicly available. Our model shows competitive performance compared to other state-of-the-art approaches.
Channel Compression: Rethinking Information Redundancy among Channels in CNN Architecture
Jul 02, 2020
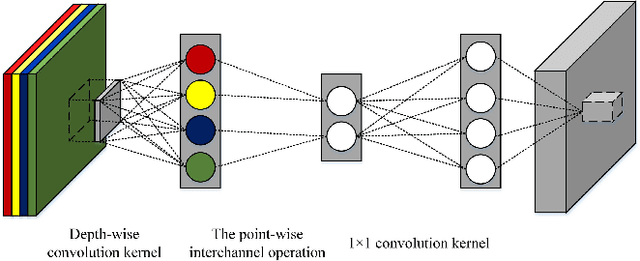
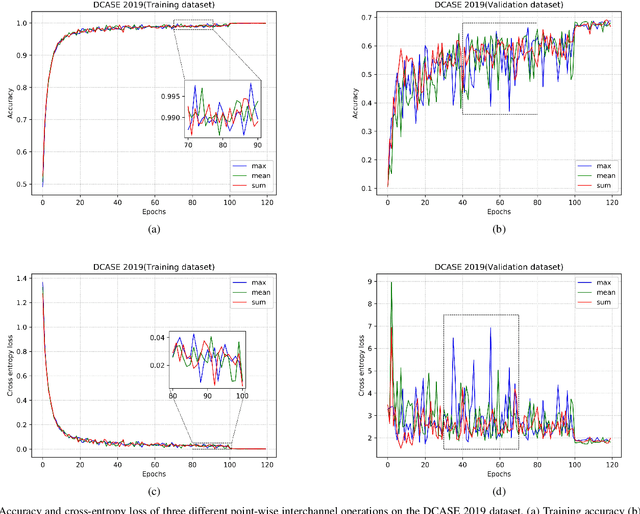
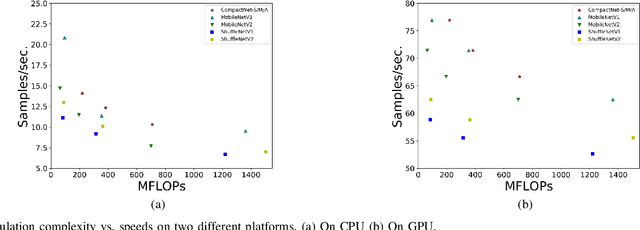
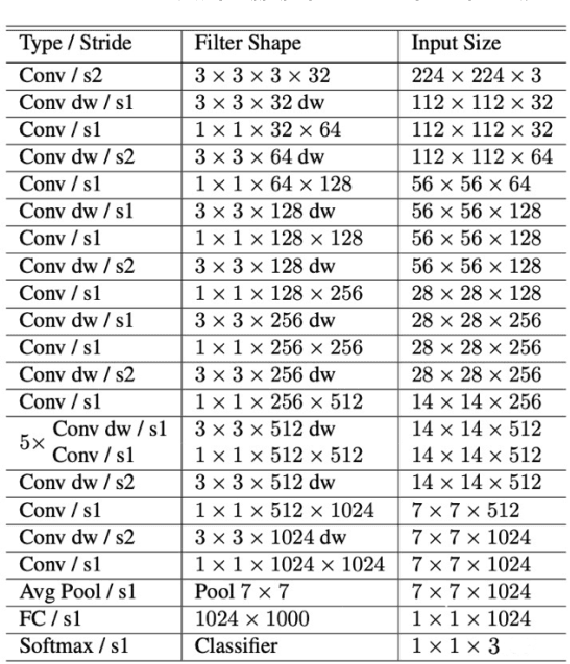
Model compression and acceleration are attracting increasing attentions due to the demand for embedded devices and mobile applications. Research on efficient convolutional neural networks (CNNs) aims at removing feature redundancy by decomposing or optimizing the convolutional calculation. In this work, feature redundancy is assumed to exist among channels in CNN architectures, which provides some leeway to boost calculation efficiency. Aiming at channel compression, a novel convolutional construction named compact convolution is proposed to embrace the progress in spatial convolution, channel grouping and pooling operation. Specifically, the depth-wise separable convolution and the point-wise interchannel operation are utilized to efficiently extract features. Different from the existing channel compression method which usually introduces considerable learnable weights, the proposed compact convolution can reduce feature redundancy with no extra parameters. With the point-wise interchannel operation, compact convolutions implicitly squeeze the channel dimension of feature maps. To explore the rules on reducing channel redundancy in neural networks, the comparison is made among different point-wise interchannel operations. Moreover, compact convolutions are extended to tackle with multiple tasks, such as acoustic scene classification, sound event detection and image classification. The extensive experiments demonstrate that our compact convolution not only exhibits high effectiveness in several multimedia tasks, but also can be efficiently implemented by benefiting from parallel computation.
Sequential Information Guided Sensing
Sep 01, 2015
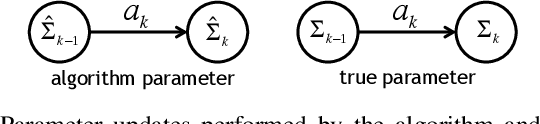
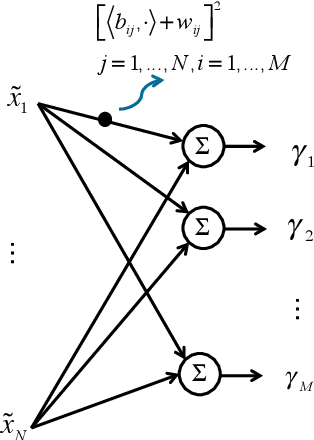
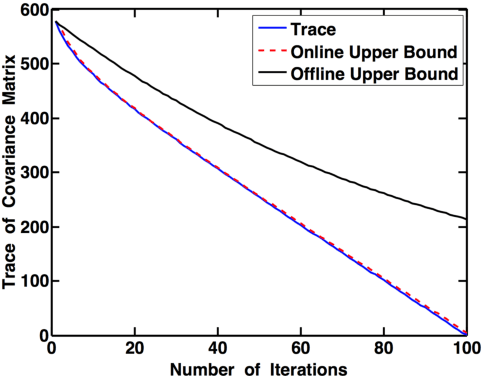
We study the value of information in sequential compressed sensing by characterizing the performance of sequential information guided sensing in practical scenarios when information is inaccurate. In particular, we assume the signal distribution is parameterized through Gaussian or Gaussian mixtures with estimated mean and covariance matrices, and we can measure compressively through a noisy linear projection or using one-sparse vectors, i.e., observing one entry of the signal each time. We establish a set of performance bounds for the bias and variance of the signal estimator via posterior mean, by capturing the conditional entropy (which is also related to the size of the uncertainty), and the additional power required due to inaccurate information to reach a desired precision. Based on this, we further study how to estimate covariance based on direct samples or covariance sketching. Numerical examples also demonstrate the superior performance of Info-Greedy Sensing algorithms compared with their random and non-adaptive counterparts.
Normalization Matters in Weakly Supervised Object Localization
Jul 28, 2021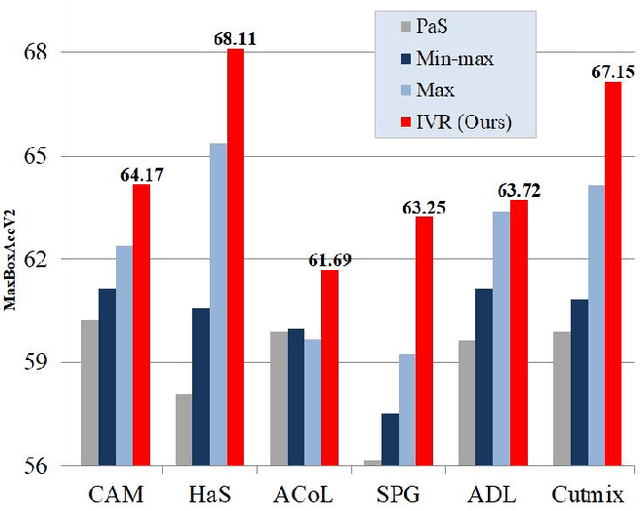
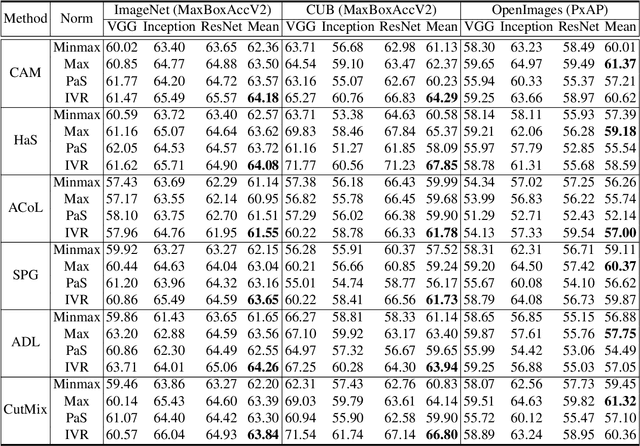
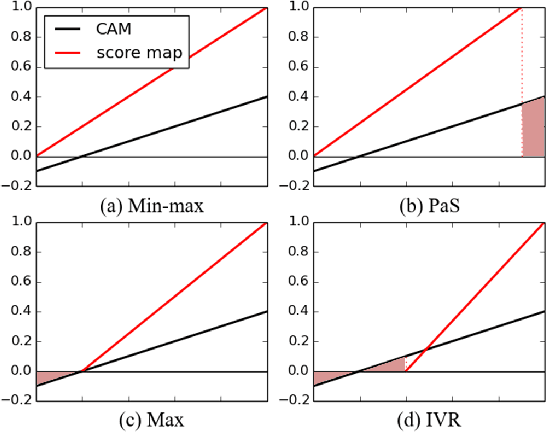
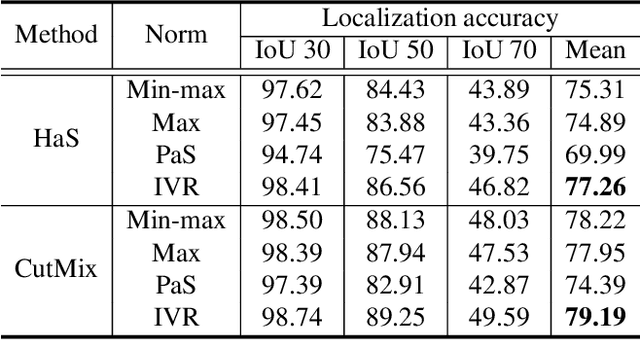
Weakly-supervised object localization (WSOL) enables finding an object using a dataset without any localization information. By simply training a classification model using only image-level annotations, the feature map of the model can be utilized as a score map for localization. In spite of many WSOL methods proposing novel strategies, there has not been any de facto standard about how to normalize the class activation map (CAM). Consequently, many WSOL methods have failed to fully exploit their own capacity because of the misuse of a normalization method. In this paper, we review many existing normalization methods and point out that they should be used according to the property of the given dataset. Additionally, we propose a new normalization method which substantially enhances the performance of any CAM-based WSOL methods. Using the proposed normalization method, we provide a comprehensive evaluation over three datasets (CUB, ImageNet and OpenImages) on three different architectures and observe significant performance gains over the conventional min-max normalization method in all the evaluated cases.
Deformation Recovery Control and Post-Impact Trajectory Replanning for Collision-Resilient Mobile Robots
Aug 04, 2021
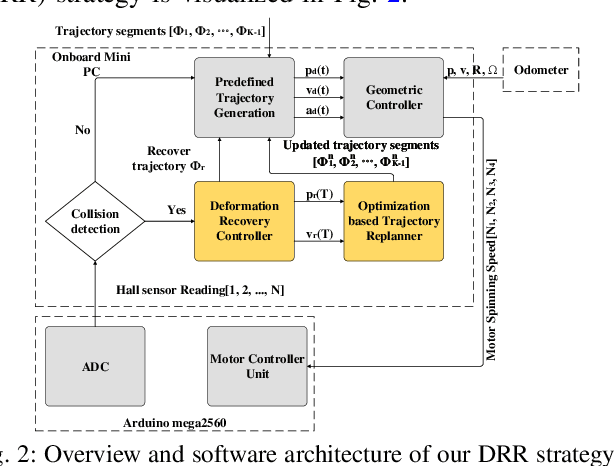

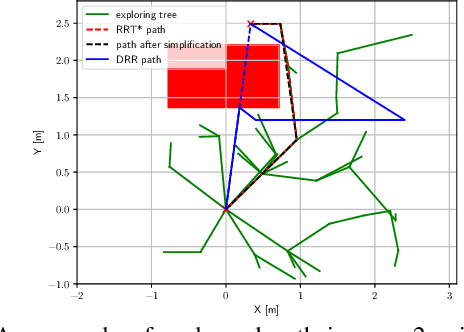
The paper focuses on collision-inclusive motion planning for impact-resilient mobile robots. We propose a new deformation recovery and replanning strategy to handle collisions that may occur at run-time. Contrary to collision avoidance methods that generate trajectories only in conservative local space or require collision checking that has high computational cost, our method directly generates (local) trajectories with imposing only waypoint constraints. If a collision occurs, our method then estimates the post-impact state and computes from there an intermediate waypoint to recover from the collision. To achieve so, we develop two novel components: 1) a deformation recovery controller that optimizes the robot's states during post-impact recovery phase, and 2) a post-impact trajectory replanner that adjusts the next waypoint with the information from the collision for the robot to pass through and generates a polynomial-based minimum effort trajectory. The proposed strategy is evaluated experimentally with an omni-directional impact-resilient wheeled robot. The robot is designed in house, and it can perceive collisions with the aid of Hall effect sensors embodied between the robot's main chassis and a surrounding deflection ring-like structure.
Deep Sensing of Urban Waterlogging
Mar 10, 2021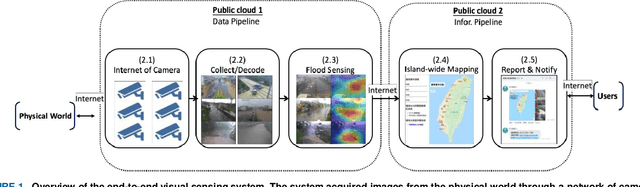
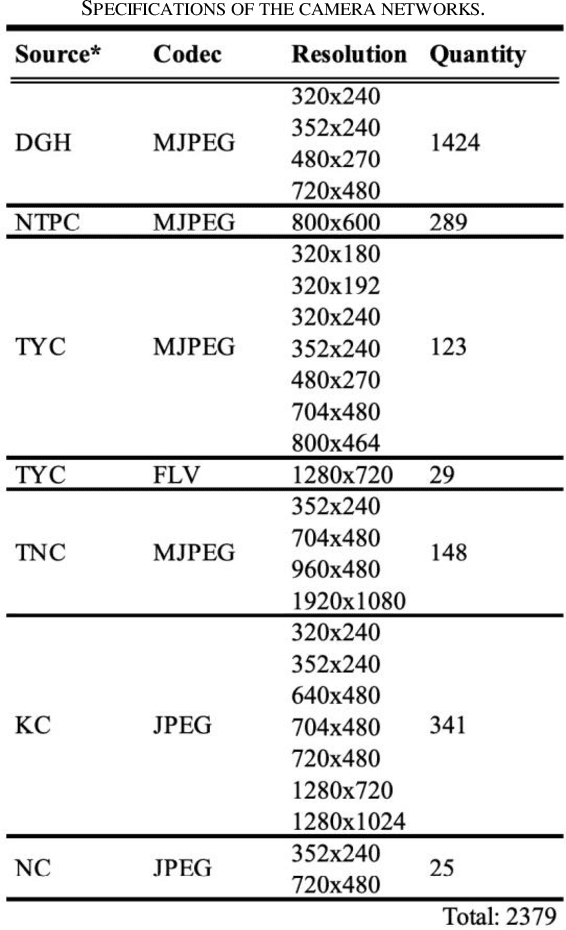
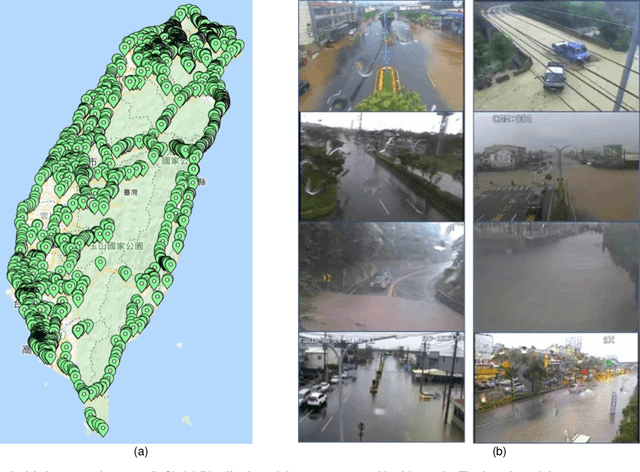
In the monsoon season, sudden flood events occur frequently in urban areas, which hamper the social and economic activities and may threaten the infrastructure and lives. The use of an efficient large-scale waterlogging sensing and information system can provide valuable real-time disaster information to facilitate disaster management and enhance awareness of the general public to alleviate losses during and after flood disasters. Therefore, in this study, a visual sensing approach driven by deep neural networks and information and communication technology was developed to provide an end-to-end mechanism to realize waterlogging sensing and event-location mapping. The use of a deep sensing system in the monsoon season in Taiwan was demonstrated, and waterlogging events were predicted on the island-wide scale. The system could sense approximately 2379 vision sources through an internet of video things framework and transmit the event-location information in 5 min. The proposed approach can sense waterlogging events at a national scale and provide an efficient and highly scalable alternative to conventional waterlogging sensing methods.
Learning-based Predictive Beamforming for Integrated Sensing and Communication in Vehicular Networks
Aug 26, 2021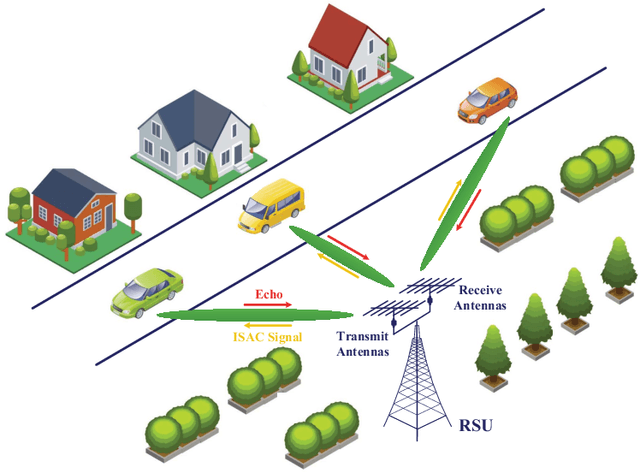
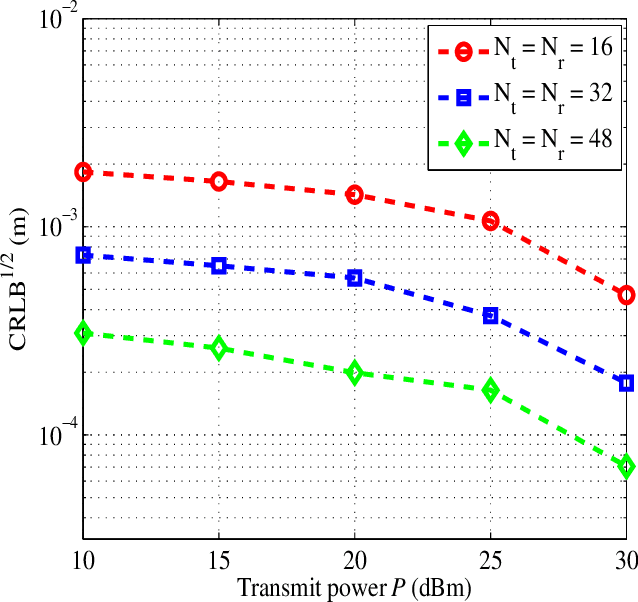
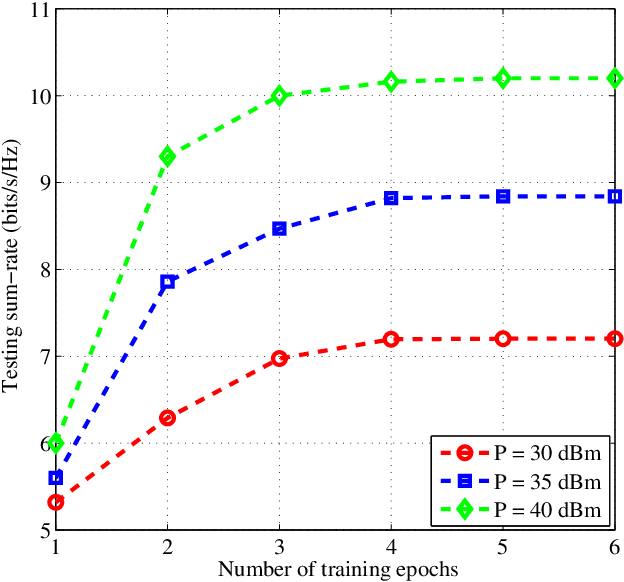
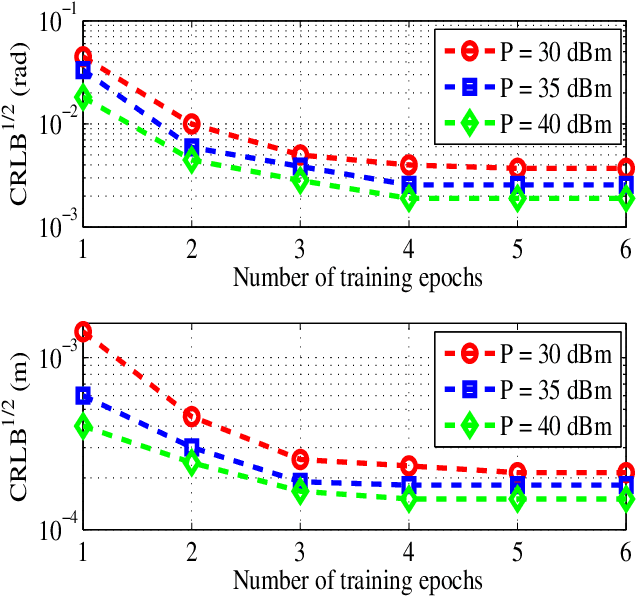
This paper investigates the integrated sensing and communication (ISAC) in vehicle-to-infrastructure (V2I) networks. To realize ISAC, an effective beamforming design is essential which however, highly depends on the availability of accurate channel tracking requiring large training overhead and computational complexity. Motivated by this, we adopt a deep learning (DL) approach to implicitly learn the features of historical channels and directly predict the beamforming matrix to be adopted for the next time slot to maximize the average achievable sum-rate of an ISAC system. The proposed method can bypass the need of explicit channel tracking process and reduce the signaling overhead significantly. To this end, a general sum-rate maximization problem with Cramer-Rao lower bounds (CRLBs)-based sensing constraints is first formulated for the considered ISAC system. Then, by exploiting the penalty method, a versatile unsupervised DL-based predictive beamforming design framework is developed to address the formulated design problem. As a realization of the developed framework, a historical channels-based convolutional long short-term memory (LSTM) network (HCL-Net) is devised for predictive beamforming in the ISAC-based V2I network. Specifically, the convolution and LSTM modules are successively adopted in the proposed HCL-Net to exploit the spatial and temporal dependencies of communication channels to further improve the learning performance. Finally, simulation results show that the proposed predictive method not only guarantees the required sensing performance, but also achieves a satisfactory sum-rate that can approach the upper bound obtained by the genie-aided scheme with the perfect instantaneous channel state information.
A Generalizable Model-and-Data Driven Approach for Open-Set RFF Authentication
Aug 10, 2021
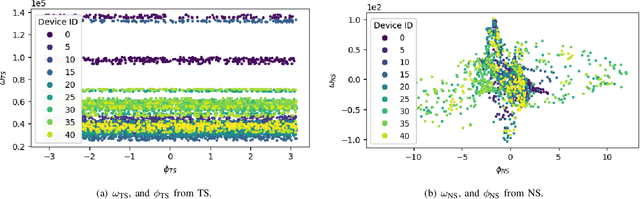

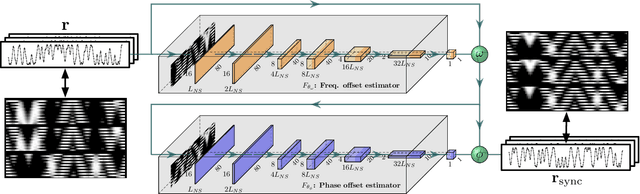
Radio-frequency fingerprints~(RFFs) are promising solutions for realizing low-cost physical layer authentication. Machine learning-based methods have been proposed for RFF extraction and discrimination. However, most existing methods are designed for the closed-set scenario where the set of devices is remains unchanged. These methods can not be generalized to the RFF discrimination of unknown devices. To enable the discrimination of RFF from both known and unknown devices, we propose a new end-to-end deep learning framework for extracting RFFs from raw received signals. The proposed framework comprises a novel preprocessing module, called neural synchronization~(NS), which incorporates the data-driven learning with signal processing priors as an inductive bias from communication-model based processing. Compared to traditional carrier synchronization techniques, which are static, this module estimates offsets by two learnable deep neural networks jointly trained by the RFF extractor. Additionally, a hypersphere representation is proposed to further improve the discrimination of RFF. Theoretical analysis shows that such a data-and-model framework can better optimize the mutual information between device identity and the RFF, which naturally leads to better performance. Experimental results verify that the proposed RFF significantly outperforms purely data-driven DNN-design and existing handcrafted RFF methods in terms of both discrimination and network generalizability.
StrucTexT: Structured Text Understanding with Multi-Modal Transformers
Aug 10, 2021
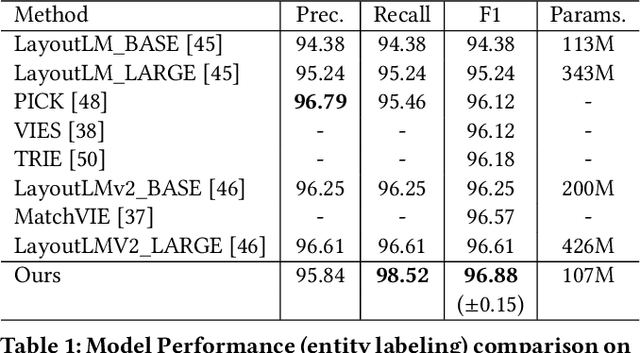
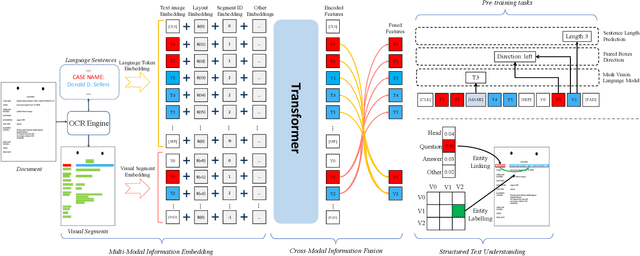
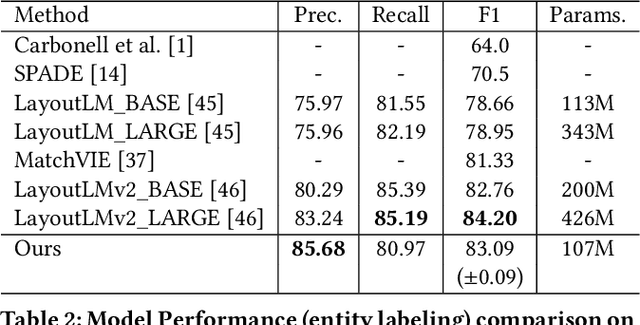
Structured text understanding on Visually Rich Documents (VRDs) is a crucial part of Document Intelligence. Due to the complexity of content and layout in VRDs, structured text understanding has been a challenging task. Most existing studies decoupled this problem into two sub-tasks: entity labeling and entity linking, which require an entire understanding of the context of documents at both token and segment levels. However, little work has been concerned with the solutions that efficiently extract the structured data from different levels. This paper proposes a unified framework named StrucTexT, which is flexible and effective for handling both sub-tasks. Specifically, based on the transformer, we introduce a segment-token aligned encoder to deal with the entity labeling and entity linking tasks at different levels of granularity. Moreover, we design a novel pre-training strategy with three self-supervised tasks to learn a richer representation. StrucTexT uses the existing Masked Visual Language Modeling task and the new Sentence Length Prediction and Paired Boxes Direction tasks to incorporate the multi-modal information across text, image, and layout. We evaluate our method for structured text understanding at segment-level and token-level and show it outperforms the state-of-the-art counterparts with significantly superior performance on the FUNSD, SROIE, and EPHOIE datasets.
SCIDA: Self-Correction Integrated Domain Adaptation from Single- to Multi-label Aerial Images
Aug 15, 2021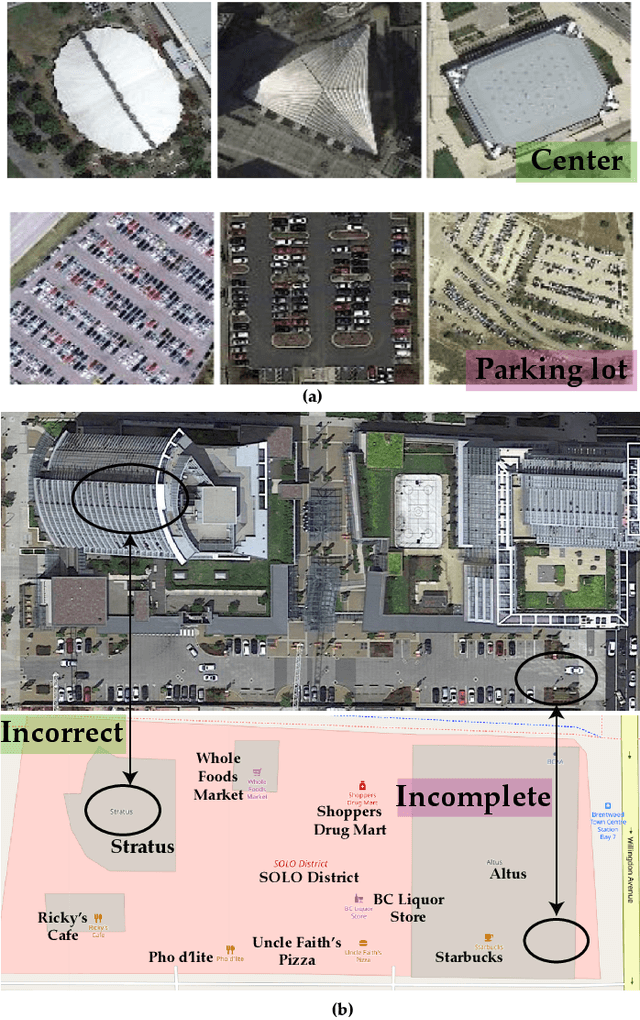
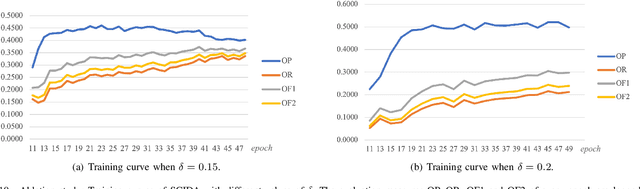
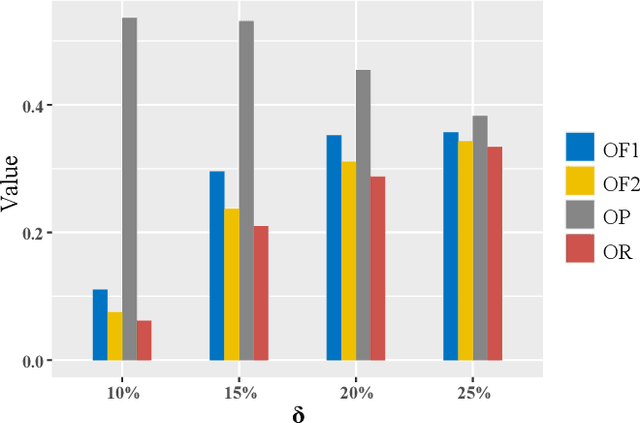
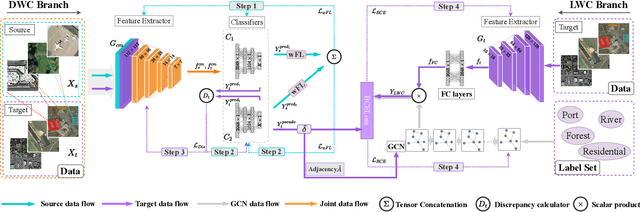
Most publicly available datasets for image classification are with single labels, while images are inherently multi-labeled in our daily life. Such an annotation gap makes many pre-trained single-label classification models fail in practical scenarios. This annotation issue is more concerned for aerial images: Aerial data collected from sensors naturally cover a relatively large land area with multiple labels, while annotated aerial datasets, which are publicly available (e.g., UCM, AID), are single-labeled. As manually annotating multi-label aerial images would be time/labor-consuming, we propose a novel self-correction integrated domain adaptation (SCIDA) method for automatic multi-label learning. SCIDA is weakly supervised, i.e., automatically learning the multi-label image classification model from using massive, publicly available single-label images. To achieve this goal, we propose a novel Label-Wise self-Correction (LWC) module to better explore underlying label correlations. This module also makes the unsupervised domain adaptation (UDA) from single- to multi-label data possible. For model training, the proposed model only uses single-label information yet requires no prior knowledge of multi-labeled data; and it predicts labels for multi-label aerial images. In our experiments, trained with single-labeled MAI-AID-s and MAI-UCM-s datasets, the proposed model is tested directly on our collected Multi-scene Aerial Image (MAI) dataset.