 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
EqGNN: Equalized Node Opportunity in Graphs
Aug 19, 2021
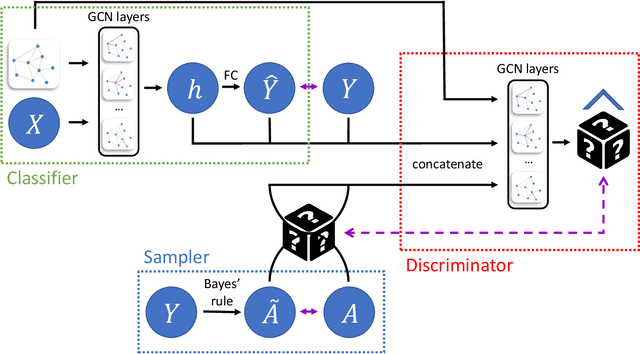
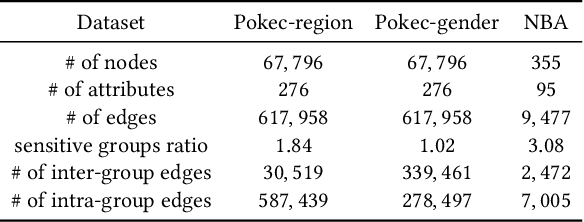
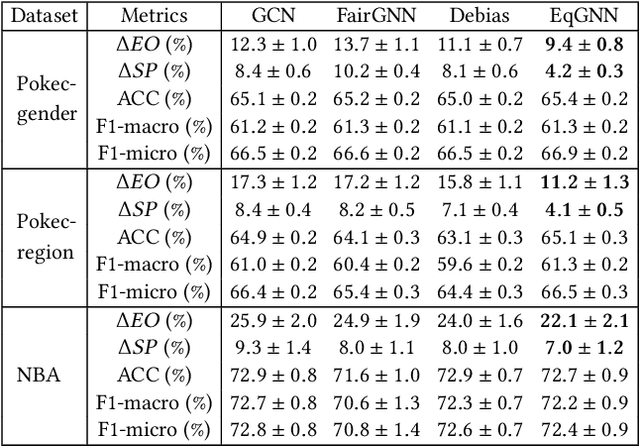
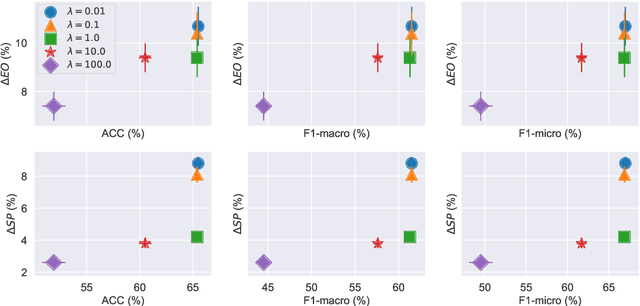
Graph neural networks (GNNs), has been widely used for supervised learning tasks in graphs reaching state-of-the-art results. However, little work was dedicated to creating unbiased GNNs, i.e., where the classification is uncorrelated with sensitive attributes, such as race or gender. Some ignore the sensitive attributes or optimize for the criteria of statistical parity for fairness. However, it has been shown that neither approaches ensure fairness, but rather cripple the utility of the prediction task. In this work, we present a GNN framework that allows optimizing representations for the notion of Equalized Odds fairness criteria. The architecture is composed of three components: (1) a GNN classifier predicting the utility class, (2) a sampler learning the distribution of the sensitive attributes of the nodes given their labels. It generates samples fed into a (3) discriminator that discriminates between true and sampled sensitive attributes using a novel "permutation loss" function. Using these components, we train a model to neglect information regarding the sensitive attribute only with respect to its label. To the best of our knowledge, we are the first to optimize GNNs for the equalized odds criteria. We evaluate our classifier over several graph datasets and sensitive attributes and show our algorithm reaches state-of-the-art results.
TransFER: Learning Relation-aware Facial Expression Representations with Transformers
Aug 25, 2021
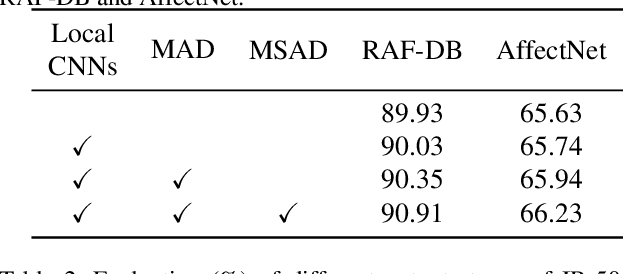
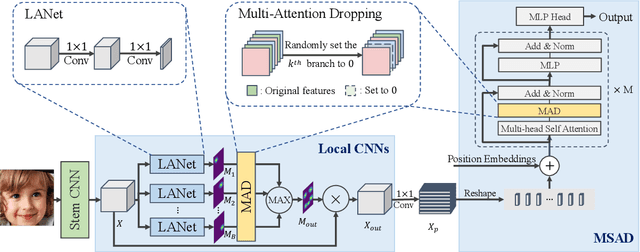

Facial expression recognition (FER) has received increasing interest in computer vision. We propose the TransFER model which can learn rich relation-aware local representations. It mainly consists of three components: Multi-Attention Dropping (MAD), ViT-FER, and Multi-head Self-Attention Dropping (MSAD). First, local patches play an important role in distinguishing various expressions, however, few existing works can locate discriminative and diverse local patches. This can cause serious problems when some patches are invisible due to pose variations or viewpoint changes. To address this issue, the MAD is proposed to randomly drop an attention map. Consequently, models are pushed to explore diverse local patches adaptively. Second, to build rich relations between different local patches, the Vision Transformers (ViT) are used in FER, called ViT-FER. Since the global scope is used to reinforce each local patch, a better representation is obtained to boost the FER performance. Thirdly, the multi-head self-attention allows ViT to jointly attend to features from different information subspaces at different positions. Given no explicit guidance, however, multiple self-attentions may extract similar relations. To address this, the MSAD is proposed to randomly drop one self-attention module. As a result, models are forced to learn rich relations among diverse local patches. Our proposed TransFER model outperforms the state-of-the-art methods on several FER benchmarks, showing its effectiveness and usefulness.
Semi-Supervised Clustering with Inaccurate Pairwise Annotations
Apr 05, 2021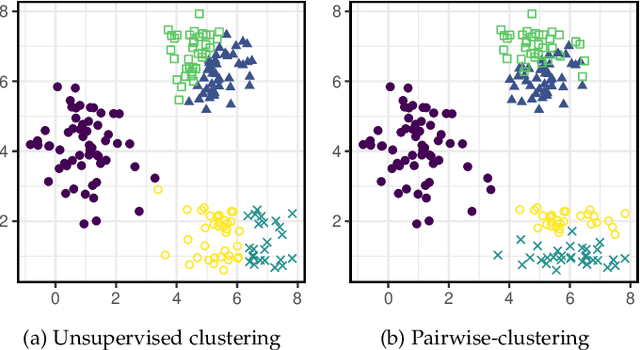
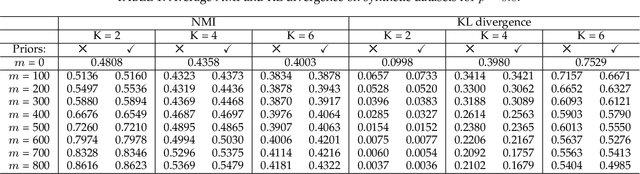
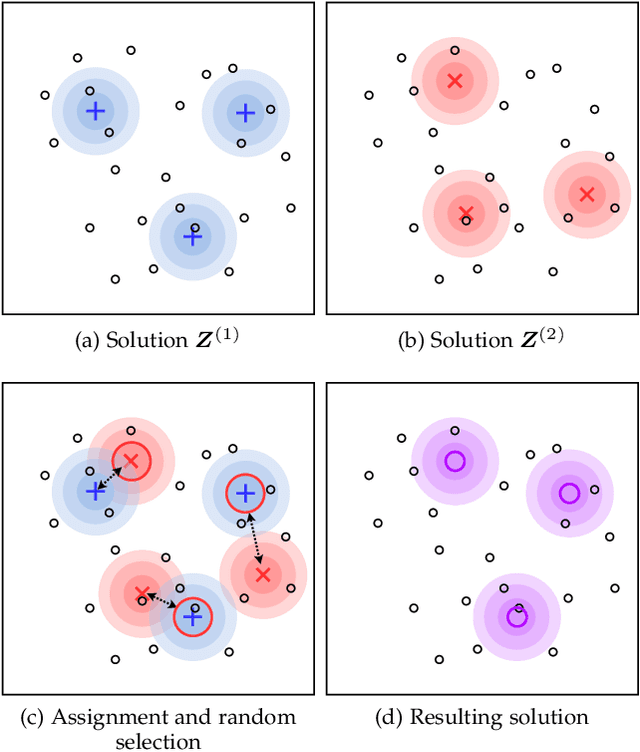
Pairwise relational information is a useful way of providing partial supervision in domains where class labels are difficult to acquire. This work presents a clustering model that incorporates pairwise annotations in the form of must-link and cannot-link relations and considers possible annotation inaccuracies (i.e., a common setting when experts provide pairwise supervision). We propose a generative model that assumes Gaussian-distributed data samples along with must-link and cannot-link relations generated by stochastic block models. We adopt a maximum-likelihood approach and demonstrate that, even when supervision is weak and inaccurate, accounting for relational information significantly improves clustering performance. Relational information also helps to detect meaningful groups in real-world datasets that do not fit the original data-distribution assumptions. Additionally, we extend the model to integrate prior knowledge of experts' accuracy and discuss circumstances in which the use of this knowledge is beneficial.
Learning Languages in the Limit from Positive Information with Finitely Many Memory Changes
Oct 09, 2020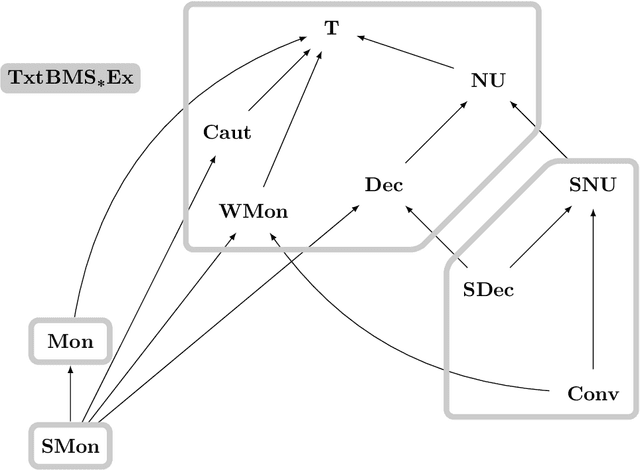
We investigate learning collections of languages from texts by an inductive inference machine with access to the current datum and its memory in form of states. The bounded memory states (BMS) learner is considered successful in case it eventually settles on a correct hypothesis while exploiting only finitely many different states. We give the complete map of all pairwise relations for an established collection of learning success restrictions. Most prominently, we show that non-U-shapedness is not restrictive, while conservativeness and (strong) monotonicity are. Some results carry over from iterative learning by a general lemma showing that, for a wealth of restrictions (the \emph{semantic} restrictions), iterative and bounded memory states learning are equivalent. We also give an example of a non-semantic restriction (strongly non-U-shapedness) where the two settings differ.
Lymph Node Graph Neural Networks for Cancer Metastasis Prediction
Jun 03, 2021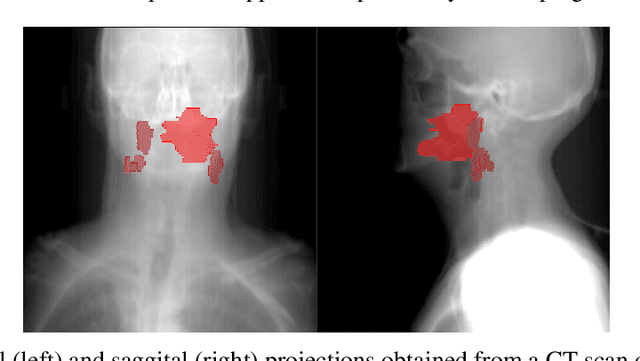
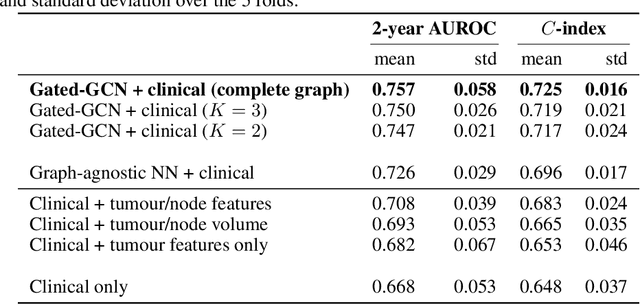
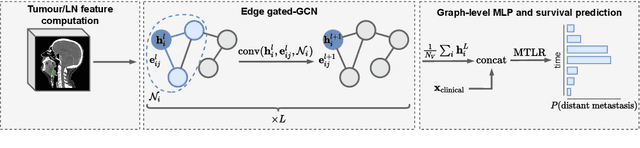

Predicting outcomes, such as survival or metastasis for individual cancer patients is a crucial component of precision oncology. Machine learning (ML) offers a promising way to exploit rich multi-modal data, including clinical information and imaging to learn predictors of disease trajectory and help inform clinical decision making. In this paper, we present a novel graph-based approach to incorporate imaging characteristics of existing cancer spread to local lymph nodes (LNs) as well as their connectivity patterns in a prognostic ML model. We trained an edge-gated Graph Convolutional Network (Gated-GCN) to accurately predict the risk of distant metastasis (DM) by propagating information across the LN graph with the aid of soft edge attention mechanism. In a cohort of 1570 head and neck cancer patients, the Gated-GCN achieves AUROC of 0.757 for 2-year DM classification and $C$-index of 0.725 for lifetime DM risk prediction, outperforming current prognostic factors as well as previous approaches based on aggregated LN features. We also explored the importance of graph structure and individual lymph nodes through ablation experiments and interpretability studies, highlighting the importance of considering individual LN characteristics as well as the relationships between regions of cancer spread.
Learning the Physics of Particle Transport via Transformers
Sep 08, 2021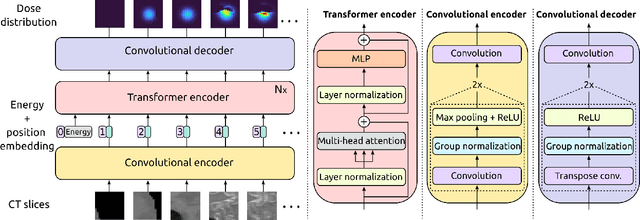
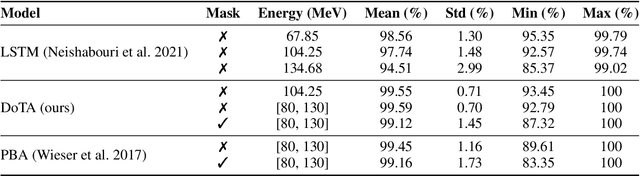
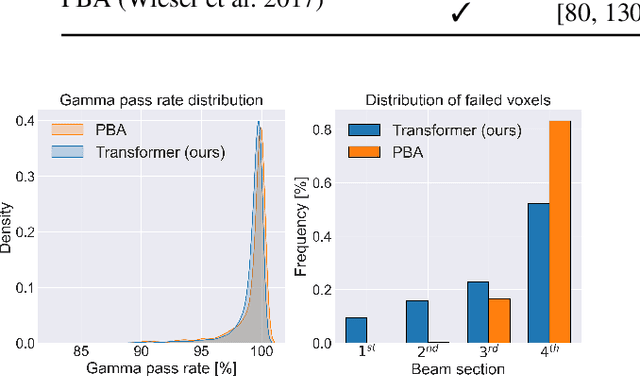
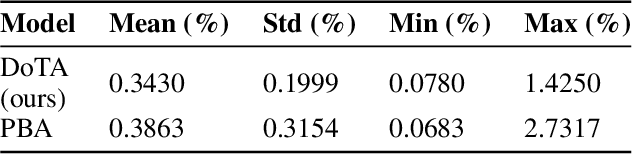
Particle physics simulations are the cornerstone of nuclear engineering applications. Among them radiotherapy (RT) is crucial for society, with 50% of cancer patients receiving radiation treatments. For the most precise targeting of tumors, next generation RT treatments aim for real-time correction during radiation delivery, necessitating particle transport algorithms that yield precise dose distributions in sub-second times even in highly heterogeneous patient geometries. This is infeasible with currently available, purely physics based simulations. In this study, we present a data-driven dose calculation algorithm predicting the dose deposited by mono-energetic proton beams for arbitrary energies and patient geometries. Our approach frames particle transport as sequence modeling, where convolutional layers extract important spatial features into tokens and the transformer self-attention mechanism routes information between such tokens in the sequence and a beam energy token. We train our network and evaluate prediction accuracy using computationally expensive but accurate Monte Carlo (MC) simulations, considered the gold standard in particle physics. Our proposed model is 33 times faster than current clinical analytic pencil beam algorithms, improving upon their accuracy in the most heterogeneous and challenging geometries. With a relative error of 0.34% and very high gamma pass rate of 99.59% (1%, 3 mm), it also greatly outperforms the only published similar data-driven proton dose algorithm, even at a finer grid resolution. Offering MC precision 400 times faster, our model could overcome a major obstacle that has so far prohibited real-time adaptive proton treatments and significantly increase cancer treatment efficacy. Its potential to model physics interactions of other particles could also boost heavy ion treatment planning procedures limited by the speed of traditional methods.
A Model-Agnostic Method for PMU Data Recovery Using Optimal Singular Value Thresholding
Aug 06, 2021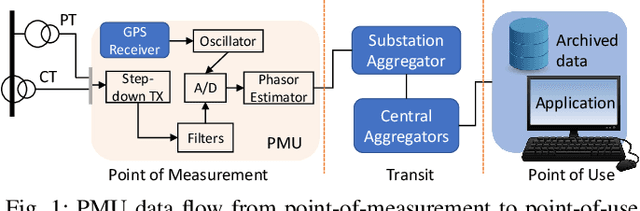


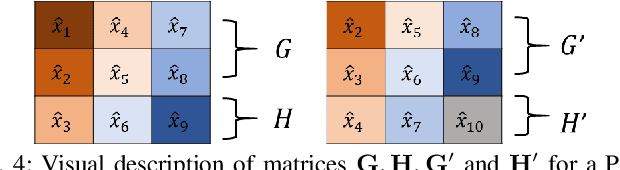
This paper presents a fast model-agnostic method for recovering noisy Phasor Measurement Unit (PMU) datastreams with missing entries. The measurements are first transformed into a Page matrix, and the original signals are reconstructed using low-rank matrix estimation based on optimal singular value thresholding. Two variations of the recovery algorithm are shown- a) an offline block-processing method for imputing past measurements, and b) an online method for predicting future measurements. Information within a PMU channel (temporal correlation) as well as from different PMUchannels in a network (spatial correlation) are utilized to recover degraded data. The proposed method is fast and needs no explicit knowledge of the underlying system model or measurement noise distribution. The performance of the recovery algorithms is illustrated using simulated measurements from the IEEE 39-bus test system as well as real measurements from an anonymized U.S. electric utility. Extensive numeric tests show that the original signals can be accurately recovered in the presence of additive noise, consecutive data drop as well as simultaneous data erasure across multiple PMU channels.
Full-Duplex Strategy for Video Object Segmentation
Aug 06, 2021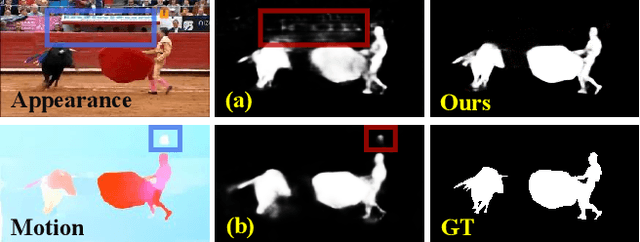

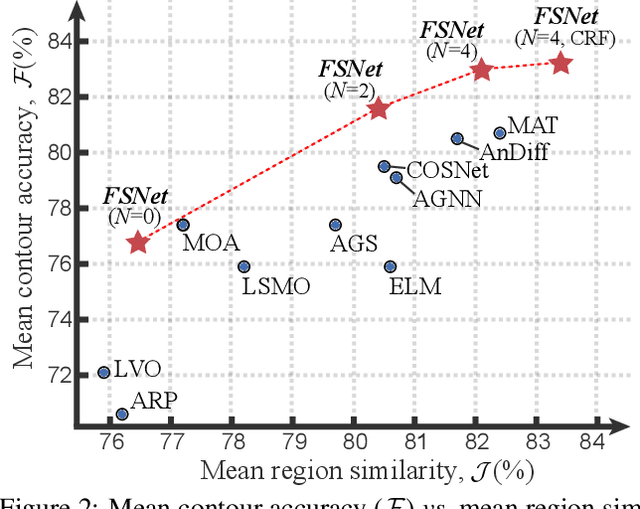
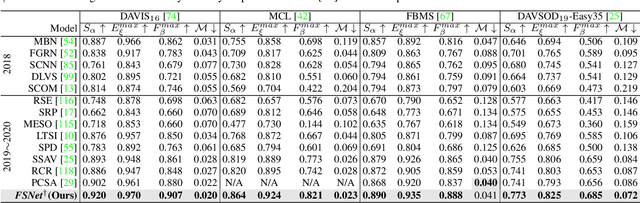
Appearance and motion are two important sources of information in video object segmentation (VOS). Previous methods mainly focus on using simplex solutions, lowering the upper bound of feature collaboration among and across these two cues. In this paper, we study a novel framework, termed the FSNet (Full-duplex Strategy Network), which designs a relational cross-attention module (RCAM) to achieve the bidirectional message propagation across embedding subspaces. Furthermore, the bidirectional purification module (BPM) is introduced to update the inconsistent features between the spatial-temporal embeddings, effectively improving the model robustness. By considering the mutual restraint within the full-duplex strategy, our FSNet performs the cross-modal feature-passing (i.e., transmission and receiving) simultaneously before the fusion and decoding stage, making it robust to various challenging scenarios (e.g., motion blur, occlusion) in VOS. Extensive experiments on five popular benchmarks (i.e., DAVIS$_{16}$, FBMS, MCL, SegTrack-V2, and DAVSOD$_{19}$) show that our FSNet outperforms other state-of-the-arts for both the VOS and video salient object detection tasks.
Synth-by-Reg (SbR): Contrastive learning for synthesis-based registration of paired images
Jul 30, 2021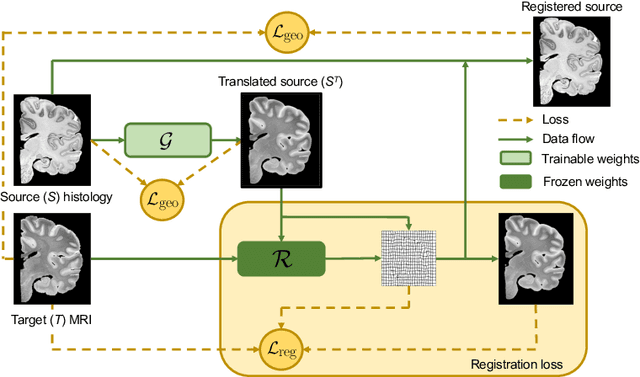
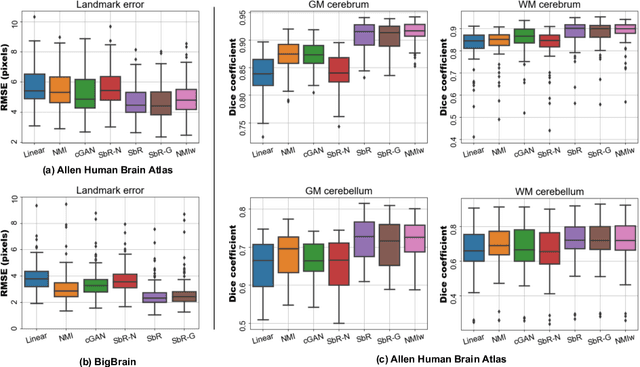
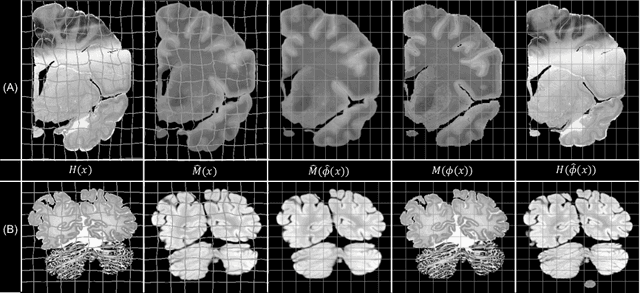
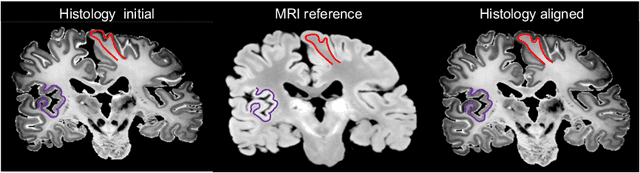
Nonlinear inter-modality registration is often challenging due to the lack of objective functions that are good proxies for alignment. Here we propose a synthesis-by-registration method to convert this problem into an easier intra-modality task. We introduce a registration loss for weakly supervised image translation between domains that does not require perfectly aligned training data. This loss capitalises on a registration U-Net with frozen weights, to drive a synthesis CNN towards the desired translation. We complement this loss with a structure preserving constraint based on contrastive learning, which prevents blurring and content shifts due to overfitting. We apply this method to the registration of histological sections to MRI slices, a key step in 3D histology reconstruction. Results on two different public datasets show improvements over registration based on mutual information (13% reduction in landmark error) and synthesis-based algorithms such as CycleGAN (11% reduction), and are comparable to a registration CNN with label supervision.
Learning from Partially Overlapping Labels: Image Segmentation under Annotation Shift
Jul 13, 2021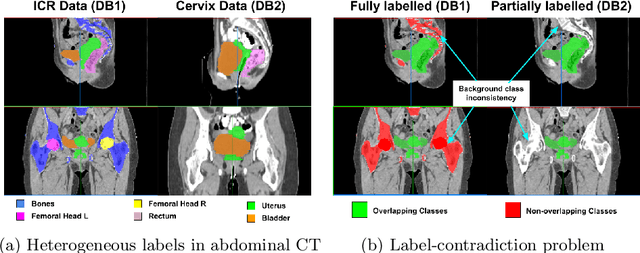
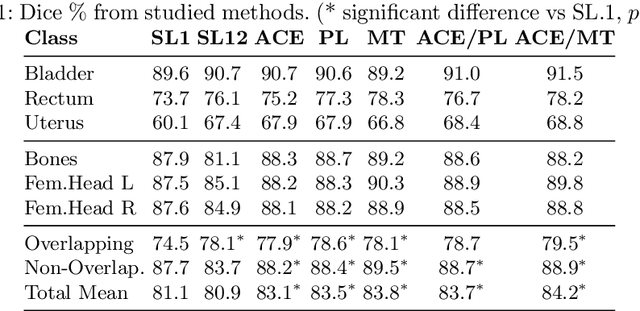
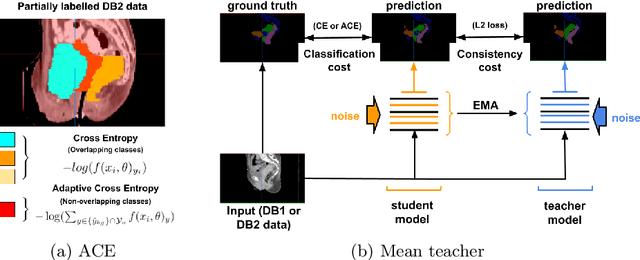
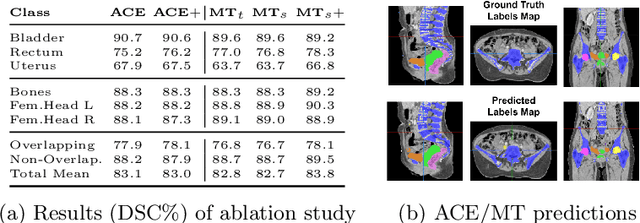
Scarcity of high quality annotated images remains a limiting factor for training accurate image segmentation models. While more and more annotated datasets become publicly available, the number of samples in each individual database is often small. Combining different databases to create larger amounts of training data is appealing yet challenging due to the heterogeneity as a result of differences in data acquisition and annotation processes, often yielding incompatible or even conflicting information. In this paper, we investigate and propose several strategies for learning from partially overlapping labels in the context of abdominal organ segmentation. We find that combining a semi-supervised approach with an adaptive cross entropy loss can successfully exploit heterogeneously annotated data and substantially improve segmentation accuracy compared to baseline and alternative approaches.