 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Personalized News Recommendation: A Survey
Jun 16, 2021
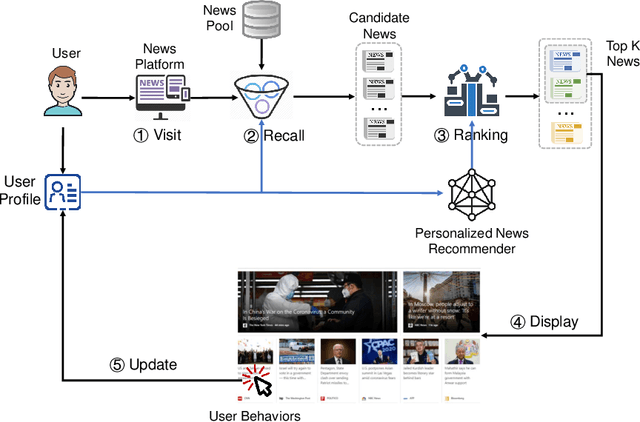

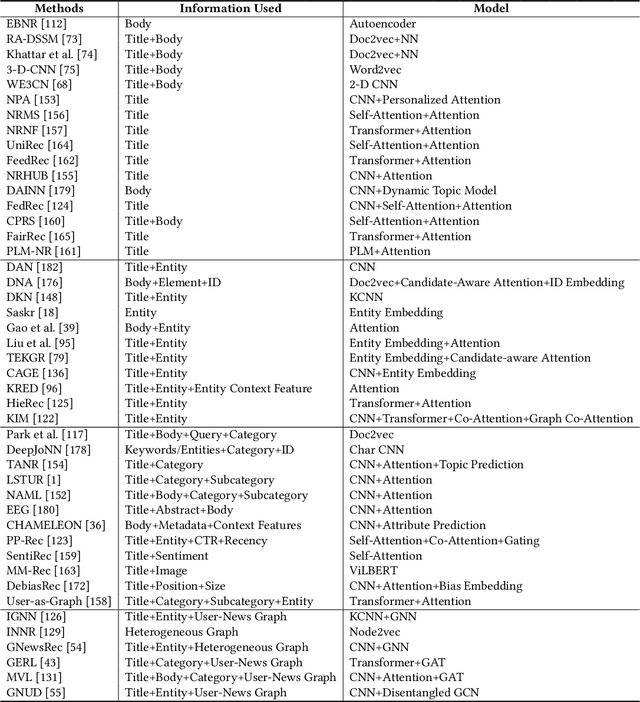
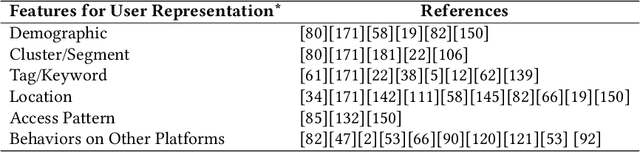
Personalized news recommendation is an important technique to help users find their interested news information and alleviate their information overload. It has been extensively studied over decades and has achieved notable success in improving users' news reading experience. However, there are still many unsolved problems and challenges that need to be further studied. To help researchers master the advances in personalized news recommendation over the past years, in this paper we present a comprehensive overview of personalized news recommendation. Instead of following the conventional taxonomy of news recommendation methods, in this paper we propose a novel perspective to understand personalized news recommendation based on its core problems and the associated techniques and challenges. We first review the techniques for tackling each core problem in a personalized news recommender system and the challenges they face. Next, we introduce the public datasets and evaluation metrics used for personalized news recommendation. We then discuss the key points on improving the responsibility of personalized news recommender systems. Finally, we raise several research directions that are worth investigating in future. This paper can provide up-to-date and comprehensive views to help readers understand the personalized news recommendation field. We hope this paper can facilitate research on personalized news recommendation and as well as related fields in natural language processing and data mining.
Should Answer Immediately or Wait for Further Information? A Novel Wait-or-Answer Task and Its Predictive Approach
May 27, 2020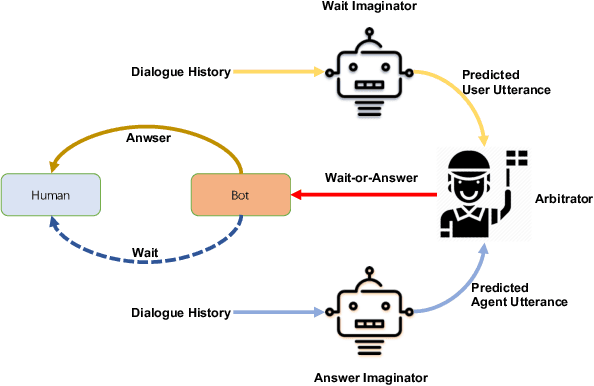
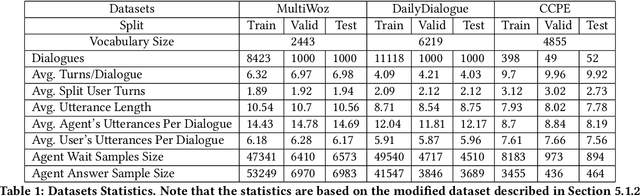
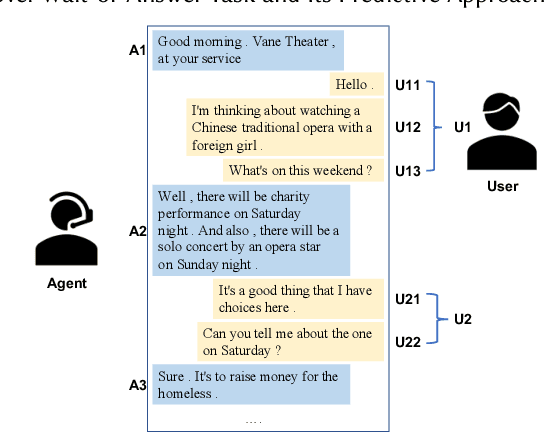
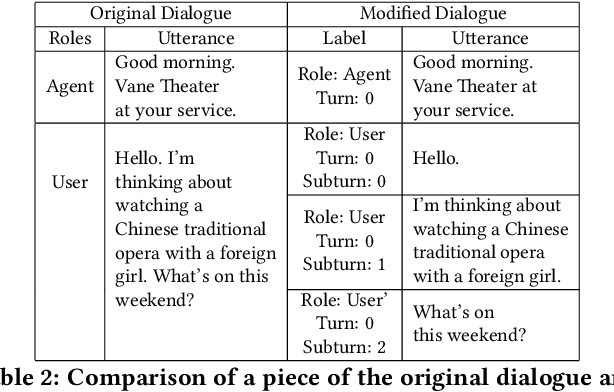
Different people have different habits of describing their intents in conversations. Some people may tend to deliberate their full intents in several successive utterances, i.e., they use several consistent messages for readability instead of a long sentence to express their question. This creates a predicament faced by dialogue systems' application, especially in real-world industrial scenarios, in which the dialogue system is unsure that whether it should answer the user's query immediately or wait for users' further supplementary input. Motivated by such interesting quandary, we define a novel task: Wait-or-Answer to better tackle this dilemma faced by dialogue systems. We shed light on a new research topic about how the dialogue system can be more competent to behave in this Wait-or-Answer quandary. Further, we propose a predictive approach dubbed Imagine-then-Arbitrate (ITA) to resolve this Wait-or-Answer task. More specifically, we take advantage of an arbitrator model to help the dialogue system decide to wait or answer. The arbitrator's decision is made with the assistance of two ancillary imaginator models: a wait imaginator and an answer imaginator. The wait imaginator tries to predict what the user would supplement and use its prediction to persuade the arbitrator that the user has some information to add, so the dialogue system should wait. The answer imaginator, nevertheless, struggles to predict the answer of the dialogue system and convince the arbitrator that it's a superior choice to answer the users' query immediately. To our best knowledge, our paper is the first work to explicitly define the Wait-or-Answer task in the dialogue system. Additionally, our proposed ITA approach significantly outperforms the existing models in solving this Wait-or-Answer problem.
PP-Rec: News Recommendation with Personalized User Interest and Time-aware News Popularity
Jun 10, 2021
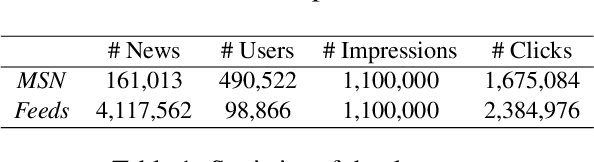
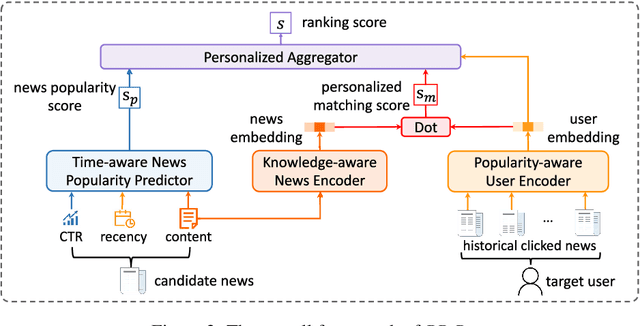
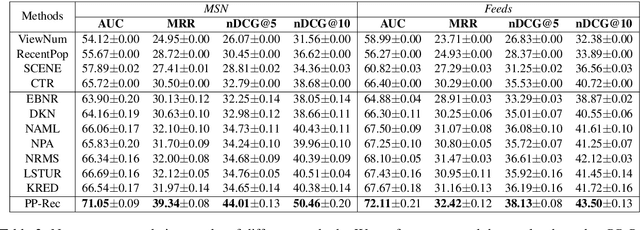
Personalized news recommendation methods are widely used in online news services. These methods usually recommend news based on the matching between news content and user interest inferred from historical behaviors. However, these methods usually have difficulties in making accurate recommendations to cold-start users, and tend to recommend similar news with those users have read. In general, popular news usually contain important information and can attract users with different interests. Besides, they are usually diverse in content and topic. Thus, in this paper we propose to incorporate news popularity information to alleviate the cold-start and diversity problems for personalized news recommendation. In our method, the ranking score for recommending a candidate news to a target user is the combination of a personalized matching score and a news popularity score. The former is used to capture the personalized user interest in news. The latter is used to measure time-aware popularity of candidate news, which is predicted based on news content, recency, and real-time CTR using a unified framework. Besides, we propose a popularity-aware user encoder to eliminate the popularity bias in user behaviors for accurate interest modeling. Experiments on two real-world datasets show our method can effectively improve the accuracy and diversity for news recommendation.
Invariant Information Distillation for Unsupervised Image Segmentation and Clustering
Jul 21, 2018
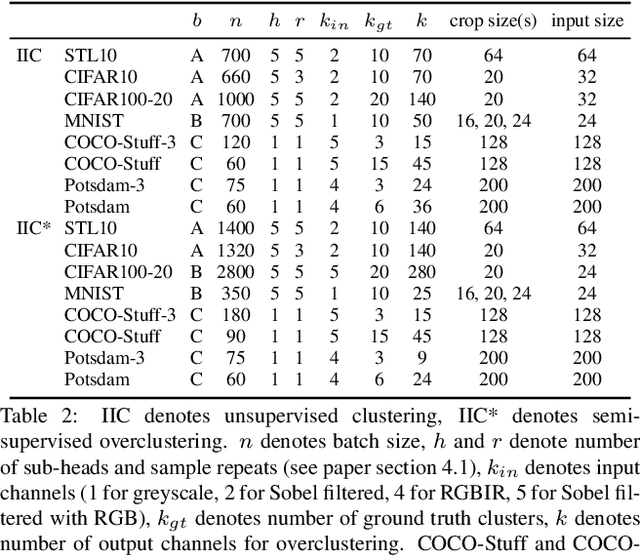

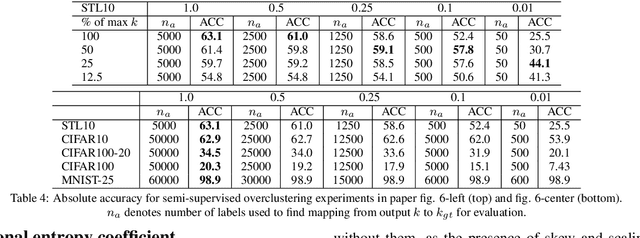
We present a new method that learns to segment and cluster images without labels of any kind. A simple loss based on information theory is used to extract meaningful representations directly from raw images. This is achieved by maximising mutual information of images known to be related by spatial proximity or randomized transformations, which distills their shared abstract content. Unlike much of the work in unsupervised deep learning, our learned function outputs segmentation heatmaps and discrete classifications labels directly, rather than embeddings that need further processing to be usable. The loss can be formulated as a convolution, making it the first end-to-end unsupervised learning method that learns densely and efficiently for semantic segmentation. Implemented using realistic settings on generic deep neural network architectures, our method attains superior performance on COCO-Stuff and ISPRS-Potsdam for segmentation and STL for clustering, beating state-of-the-art baselines.
AvaTr: One-Shot Speaker Extraction with Transformers
May 03, 2021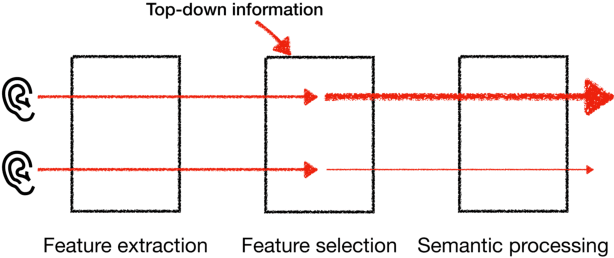

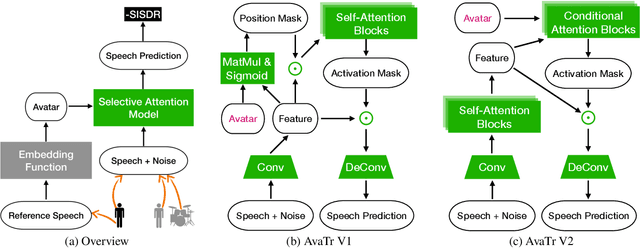
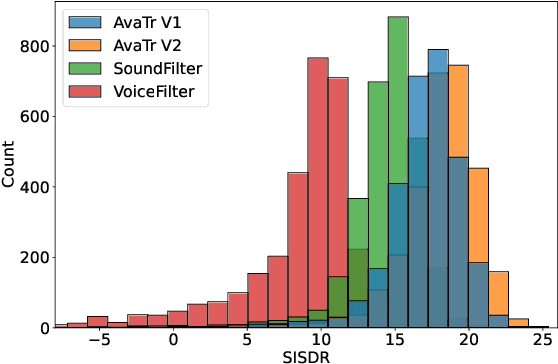
To extract the voice of a target speaker when mixed with a variety of other sounds, such as white and ambient noises or the voices of interfering speakers, we extend the Transformer network to attend the most relevant information with respect to the target speaker given the characteristics of his or her voices as a form of contextual information. The idea has a natural interpretation in terms of the selective attention theory. Specifically, we propose two models to incorporate the voice characteristics in Transformer based on different insights of where the feature selection should take place. Both models yield excellent performance, on par or better than published state-of-the-art models on the speaker extraction task, including separating speech of novel speakers not seen during training.
A Multi-modal and Multi-task Learning Method for Action Unit and Expression Recognition
Jul 09, 2021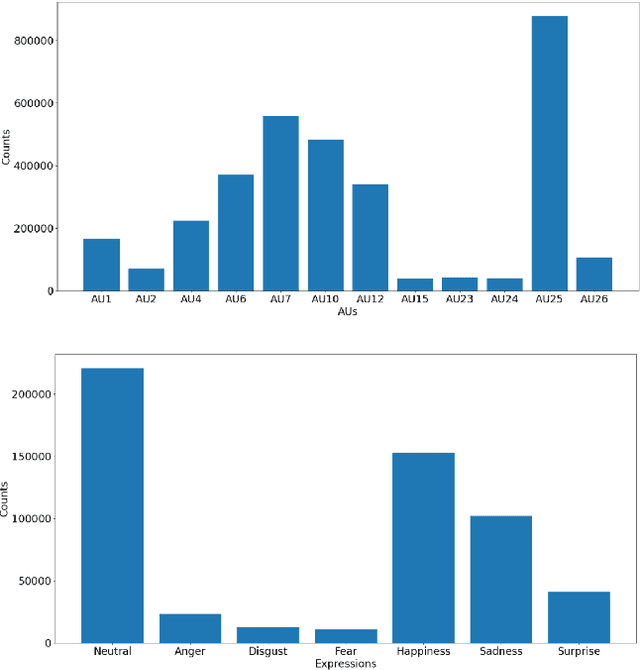

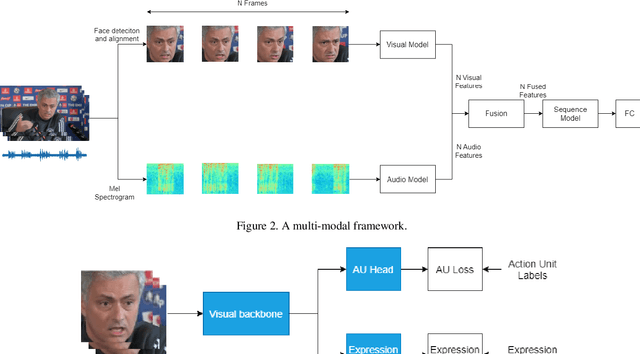
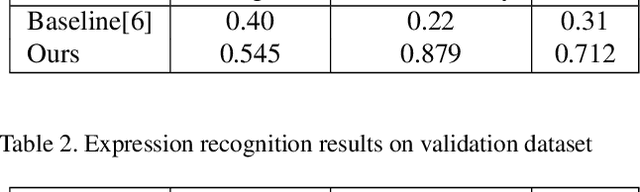
Analyzing human affect is vital for human-computer interaction systems. Most methods are developed in restricted scenarios which are not practical for in-the-wild settings. The Affective Behavior Analysis in-the-wild (ABAW) 2021 Contest provides a benchmark for this in-the-wild problem. In this paper, we introduce a multi-modal and multi-task learning method by using both visual and audio information. We use both AU and expression annotations to train the model and apply a sequence model to further extract associations between video frames. We achieve an AU score of 0.712 and an expression score of 0.477 on the validation set. These results demonstrate the effectiveness of our approach in improving model performance.
Towards Zero-shot Language Modeling
Aug 06, 2021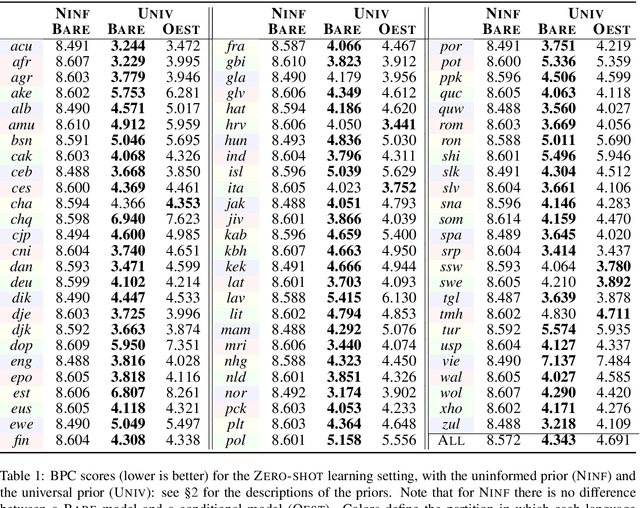
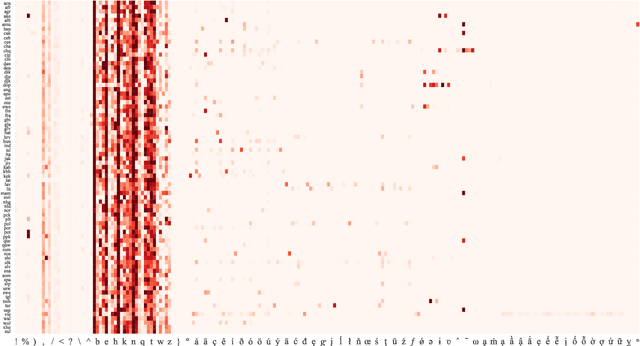
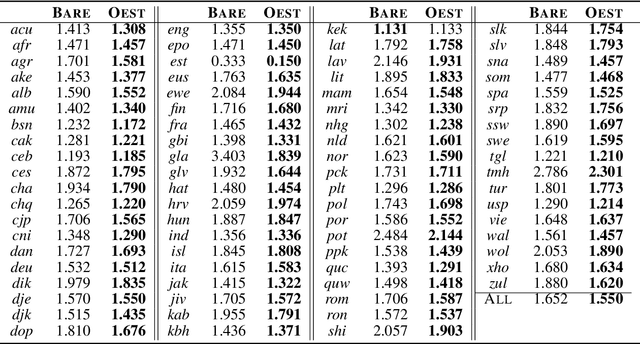
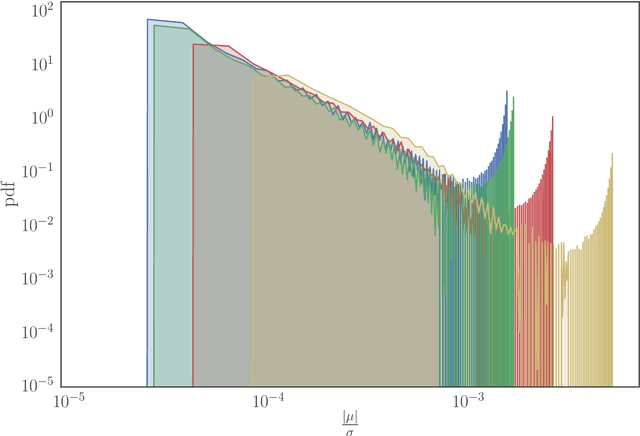
Can we construct a neural model that is inductively biased towards learning human languages? Motivated by this question, we aim at constructing an informative prior over neural weights, in order to adapt quickly to held-out languages in the task of character-level language modeling. We infer this distribution from a sample of typologically diverse training languages via Laplace approximation. The use of such a prior outperforms baseline models with an uninformative prior (so-called "fine-tuning") in both zero-shot and few-shot settings. This shows that the prior is imbued with universal phonological knowledge. Moreover, we harness additional language-specific side information as distant supervision for held-out languages. Specifically, we condition language models on features from typological databases, by concatenating them to hidden states or generating weights with hyper-networks. These features appear beneficial in the few-shot setting, but not in the zero-shot setting. Since the paucity of digital texts affects the majority of the world's languages, we hope that these findings will help broaden the scope of applications for language technology.
Improved Representation Learning for Session-based Recommendation
Jul 04, 2021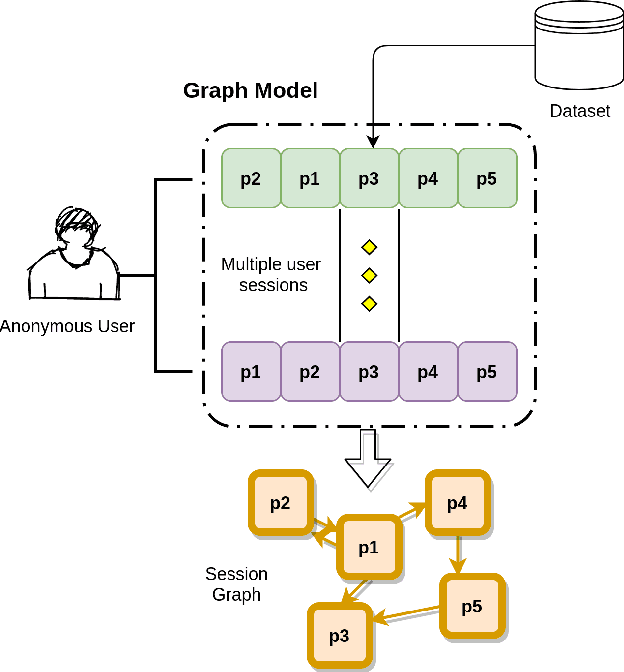

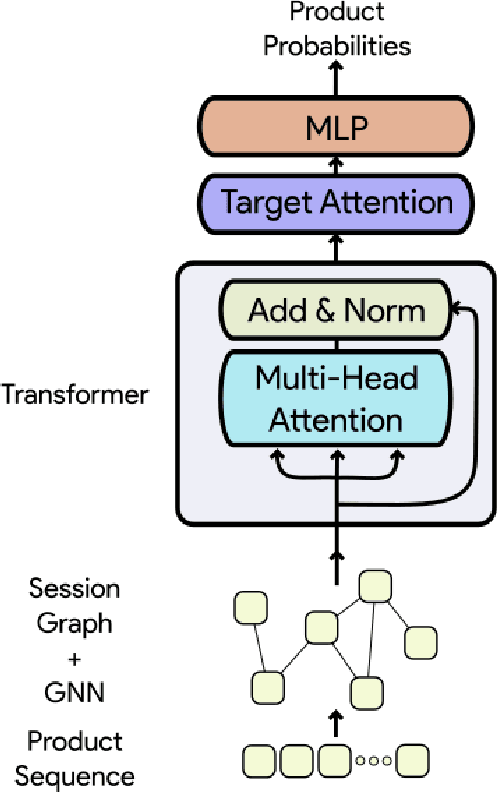
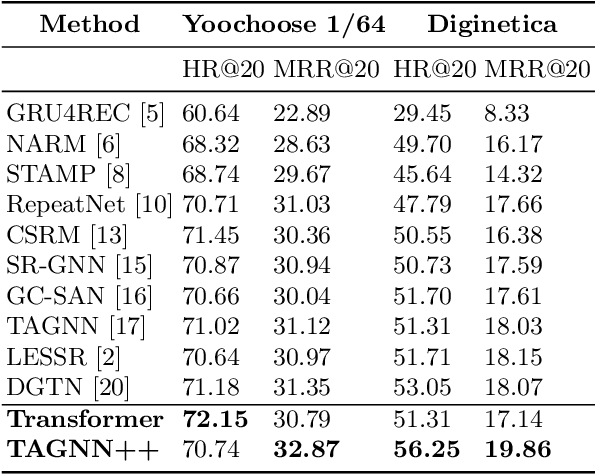
Session-based recommendation systems suggest relevant items to users by modeling user behavior and preferences using short-term anonymous sessions. Existing methods leverage Graph Neural Networks (GNNs) that propagate and aggregate information from neighboring nodes i.e., local message passing. Such graph-based architectures have representational limits, as a single sub-graph is susceptible to overfit the sequential dependencies instead of accounting for complex transitions between items in different sessions. We propose using a Transformer in combination with a target attentive GNN, which allows richer Representation Learning. Our experimental results and ablation show that our proposed method outperforms the existing methods on real-world benchmark datasets.
EqGNN: Equalized Node Opportunity in Graphs
Aug 19, 2021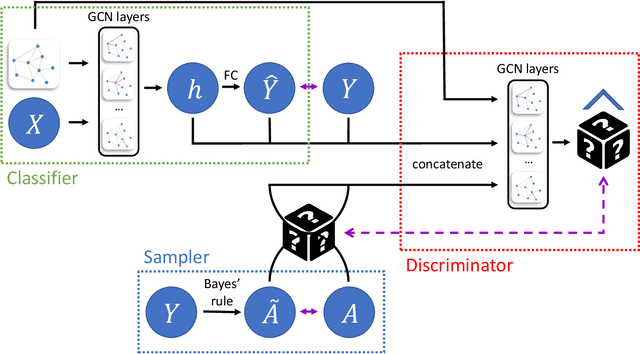
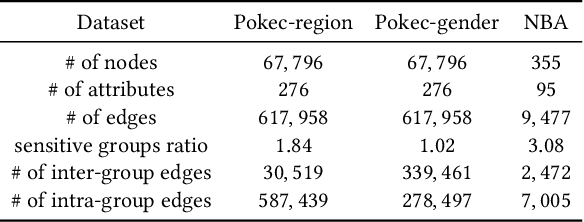
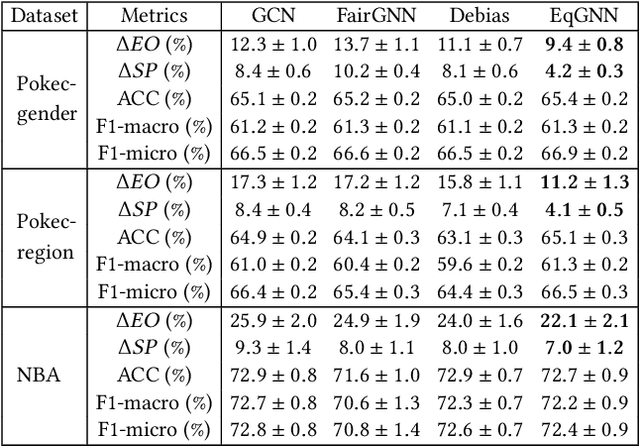
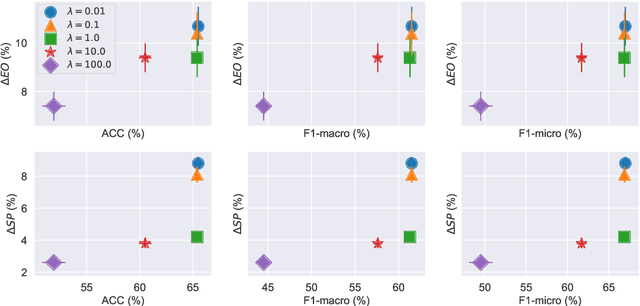
Graph neural networks (GNNs), has been widely used for supervised learning tasks in graphs reaching state-of-the-art results. However, little work was dedicated to creating unbiased GNNs, i.e., where the classification is uncorrelated with sensitive attributes, such as race or gender. Some ignore the sensitive attributes or optimize for the criteria of statistical parity for fairness. However, it has been shown that neither approaches ensure fairness, but rather cripple the utility of the prediction task. In this work, we present a GNN framework that allows optimizing representations for the notion of Equalized Odds fairness criteria. The architecture is composed of three components: (1) a GNN classifier predicting the utility class, (2) a sampler learning the distribution of the sensitive attributes of the nodes given their labels. It generates samples fed into a (3) discriminator that discriminates between true and sampled sensitive attributes using a novel "permutation loss" function. Using these components, we train a model to neglect information regarding the sensitive attribute only with respect to its label. To the best of our knowledge, we are the first to optimize GNNs for the equalized odds criteria. We evaluate our classifier over several graph datasets and sensitive attributes and show our algorithm reaches state-of-the-art results.
TransFER: Learning Relation-aware Facial Expression Representations with Transformers
Aug 25, 2021
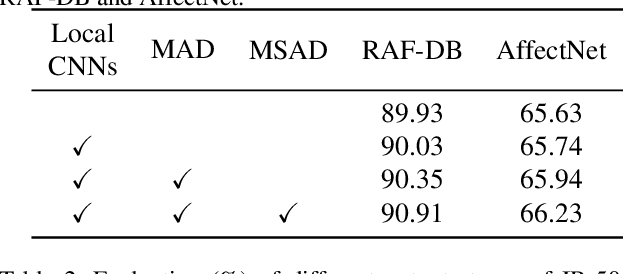
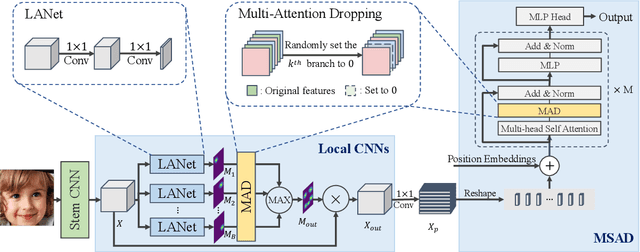

Facial expression recognition (FER) has received increasing interest in computer vision. We propose the TransFER model which can learn rich relation-aware local representations. It mainly consists of three components: Multi-Attention Dropping (MAD), ViT-FER, and Multi-head Self-Attention Dropping (MSAD). First, local patches play an important role in distinguishing various expressions, however, few existing works can locate discriminative and diverse local patches. This can cause serious problems when some patches are invisible due to pose variations or viewpoint changes. To address this issue, the MAD is proposed to randomly drop an attention map. Consequently, models are pushed to explore diverse local patches adaptively. Second, to build rich relations between different local patches, the Vision Transformers (ViT) are used in FER, called ViT-FER. Since the global scope is used to reinforce each local patch, a better representation is obtained to boost the FER performance. Thirdly, the multi-head self-attention allows ViT to jointly attend to features from different information subspaces at different positions. Given no explicit guidance, however, multiple self-attentions may extract similar relations. To address this, the MSAD is proposed to randomly drop one self-attention module. As a result, models are forced to learn rich relations among diverse local patches. Our proposed TransFER model outperforms the state-of-the-art methods on several FER benchmarks, showing its effectiveness and usefulness.