 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Privileged Zero-Shot AutoML
Jun 25, 2021
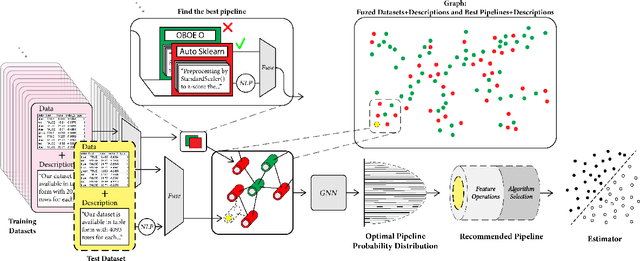
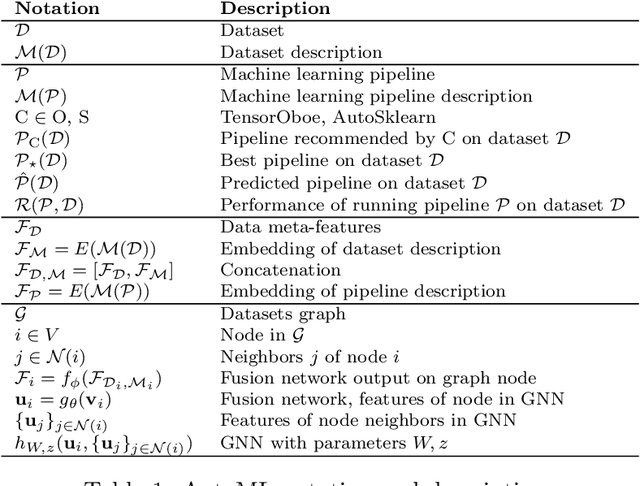
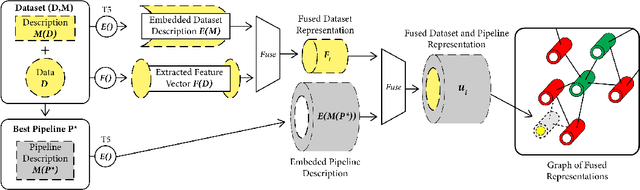
This work improves the quality of automated machine learning (AutoML) systems by using dataset and function descriptions while significantly decreasing computation time from minutes to milliseconds by using a zero-shot approach. Given a new dataset and a well-defined machine learning task, humans begin by reading a description of the dataset and documentation for the algorithms to be used. This work is the first to use these textual descriptions, which we call privileged information, for AutoML. We use a pre-trained Transformer model to process the privileged text and demonstrate that using this information improves AutoML performance. Thus, our approach leverages the progress of unsupervised representation learning in natural language processing to provide a significant boost to AutoML. We demonstrate that using only textual descriptions of the data and functions achieves reasonable classification performance, and adding textual descriptions to data meta-features improves classification across tabular datasets. To achieve zero-shot AutoML we train a graph neural network with these description embeddings and the data meta-features. Each node represents a training dataset, which we use to predict the best machine learning pipeline for a new test dataset in a zero-shot fashion. Our zero-shot approach rapidly predicts a high-quality pipeline for a supervised learning task and dataset. In contrast, most AutoML systems require tens or hundreds of pipeline evaluations. We show that zero-shot AutoML reduces running and prediction times from minutes to milliseconds, consistently across datasets. By speeding up AutoML by orders of magnitude this work demonstrates real-time AutoML.
Weakly Supervised Object Detection with Pointwise Mutual Information
Jan 26, 2018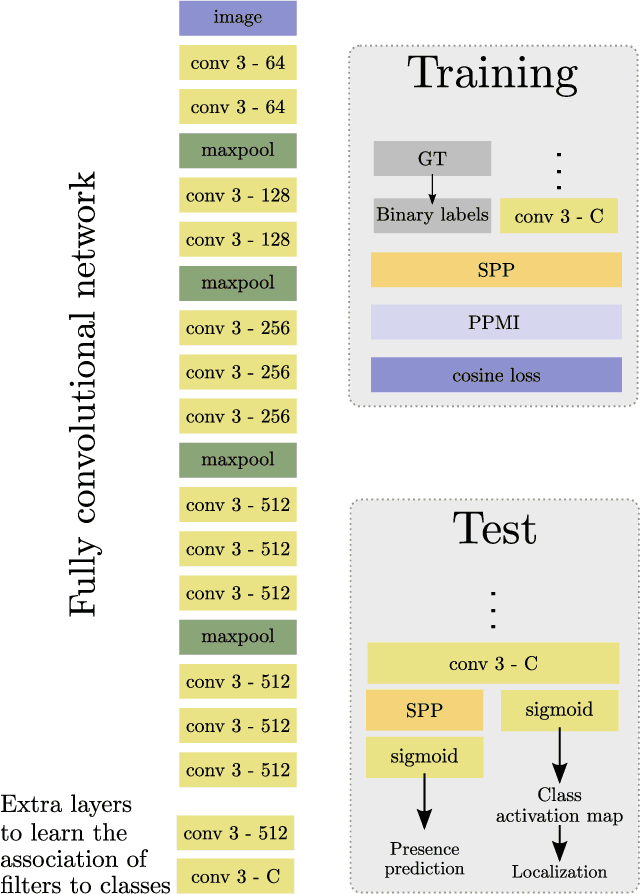


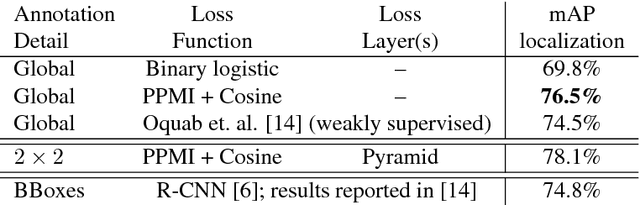
In this work a novel approach for weakly supervised object detection that incorporates pointwise mutual information is presented. A fully convolutional neural network architecture is applied in which the network learns one filter per object class. The resulting feature map indicates the location of objects in an image, yielding an intuitive representation of a class activation map. While traditionally such networks are learned by a softmax or binary logistic regression (sigmoid cross-entropy loss), a learning approach based on a cosine loss is introduced. A pointwise mutual information layer is incorporated in the network in order to project predictions and ground truth presence labels in a non-categorical embedding space. Thus, the cosine loss can be employed in this non-categorical representation. Besides integrating image level annotations, it is shown how to integrate point-wise annotations using a Spatial Pyramid Pooling layer. The approach is evaluated on the VOC2012 dataset for classification, point localization and weakly supervised bounding box localization. It is shown that the combination of pointwise mutual information and a cosine loss eases the learning process and thus improves the accuracy. The integration of coarse point-wise localizations further improves the results at minimal annotation costs.
Differentiable Particle Filters through Conditional Normalizing Flow
Jul 01, 2021
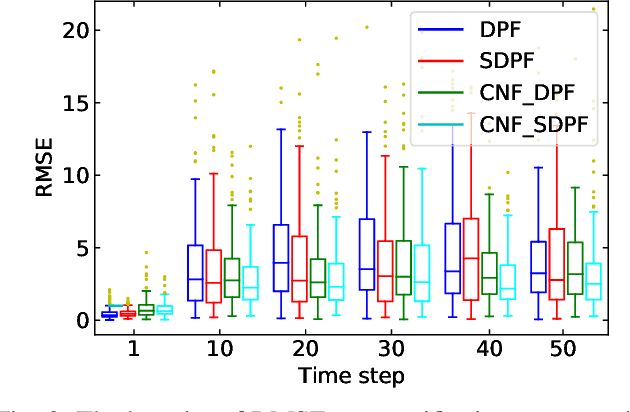
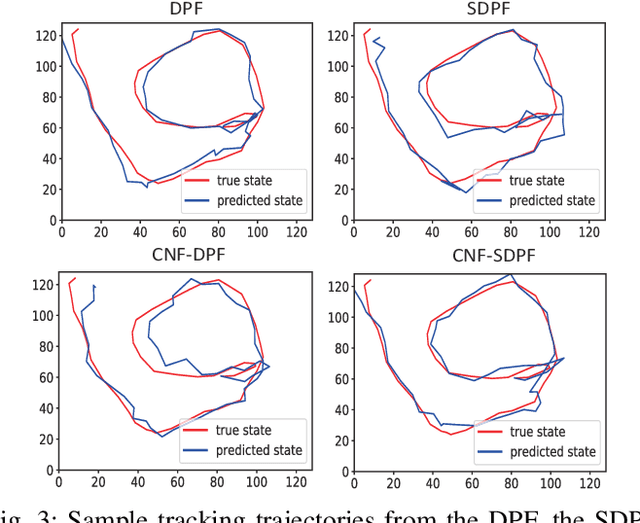
Differentiable particle filters provide a flexible mechanism to adaptively train dynamic and measurement models by learning from observed data. However, most existing differentiable particle filters are within the bootstrap particle filtering framework and fail to incorporate the information from latest observations to construct better proposals. In this paper, we utilize conditional normalizing flows to construct proposal distributions for differentiable particle filters, enriching the distribution families that the proposal distributions can represent. In addition, normalizing flows are incorporated in the construction of the dynamic model, resulting in a more expressive dynamic model. We demonstrate the performance of the proposed conditional normalizing flow-based differentiable particle filters in a visual tracking task.
A Fast Graph Kernel Based Classification Method for Wireless Link Scheduling on Riemannian Manifold
Jun 25, 2021
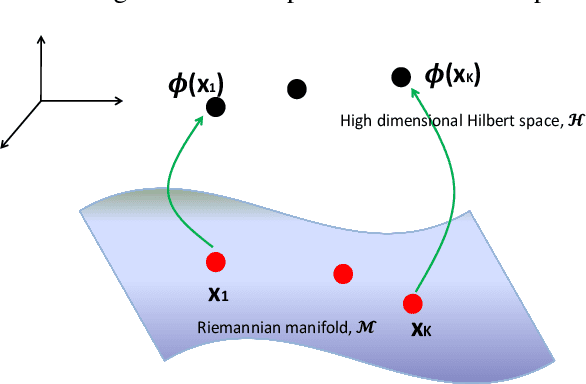
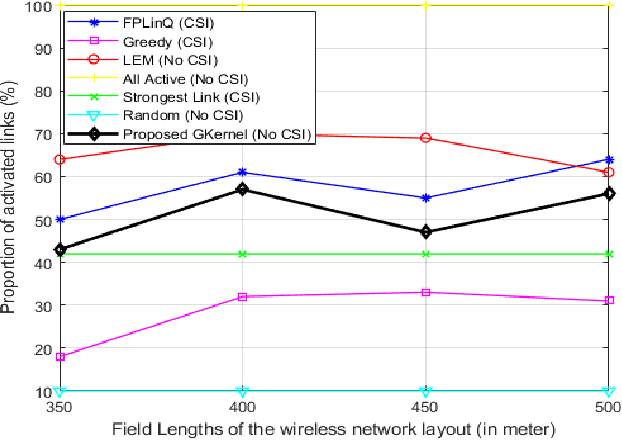
In this paper, we propose a novel graph kernel method for the wireless link scheduling problem in device-to-device (D2D) networks on Riemannian manifold. The link scheduling problem can be considered as a binary classification problem since each D2D pair can only hold the state active or inactive. Our goal is to learn a novel metric that facilitates the design of an efficient but less computationally demanding machine learning (ML) solution for the binary classification task of link scheduling problem that requires no channel state information (CSI) and a fewer number of training samples as opposed to other benchmark ML algorithms. To this aim, we first represent the wireless D2D network as a graph and model the features of each D2D pair, including its communication and interference links, as regularized (i.e., positively-shifted) Laplacian matrices which are symmetric positive definite (SPD) one. By doing so, we represent the feature information of each D2D pair as a point on the SPD manifold, and we analyze the topology through Riemannian geometry. We compute the Riemannian metric, e.g., Log-Euclidean metric (LEM), which are suitable distance measures between the regularized Laplacian matrices. The LEM is then utilized to define a positive definite graph kernel for the binary classification of the link scheduling decisions. Simulation results demonstrate that the proposed graph Kernel-based method is computationally less demanding and achieves a sum rate of more than 95% of benchmark algorithm FPLinQ [1] for 10 D2D pairs without using CSI and less than a hundred training network layouts.
Learning from Matured Dumb Teacher for Fine Generalization
Aug 17, 2021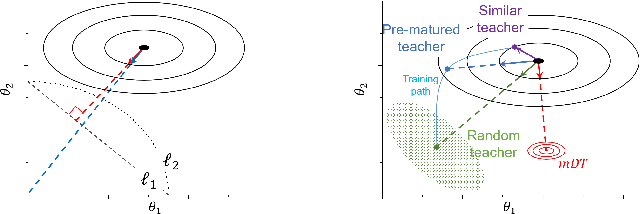
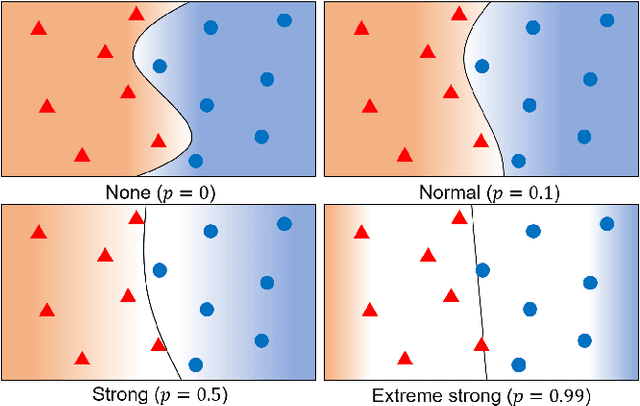
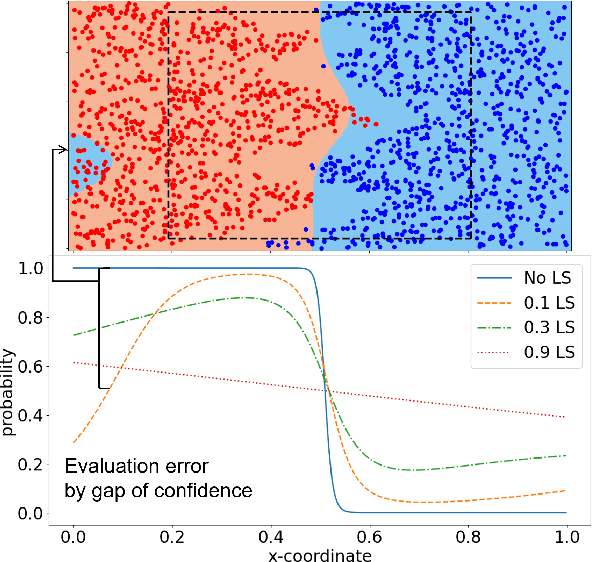
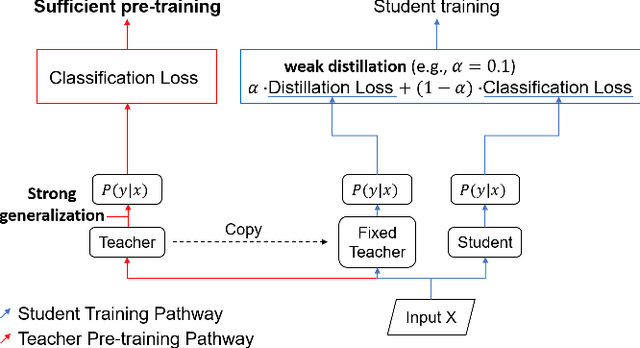
The flexibility of decision boundaries in neural networks that are unguided by training data is a well-known problem typically resolved with generalization methods. A surprising result from recent knowledge distillation (KD) literature is that random, untrained, and equally structured teacher networks can also vastly improve generalization performance. It raises the possibility of existence of undiscovered assumptions useful for generalization on an uncertain region. In this paper, we shed light on the assumptions by analyzing decision boundaries and confidence distributions of both simple and KD-based generalization methods. Assuming that a decision boundary exists to represent the most general tendency of distinction on an input sample space (i.e., the simplest hypothesis), we show the various limitations of methods when using the hypothesis. To resolve these limitations, we propose matured dumb teacher based KD, conservatively transferring the hypothesis for generalization of the student without massive destruction of trained information. In practical experiments on feed-forward and convolution neural networks for image classification tasks on MNIST, CIFAR-10, and CIFAR-100 datasets, the proposed method shows stable improvement to the best test performance in the grid search of hyperparameters. The analysis and results imply that the proposed method can provide finer generalization than existing methods.
Label Design-based ELM Network for Timing Synchronization in OFDM Systems with Nonlinear Distortion
Jul 28, 2021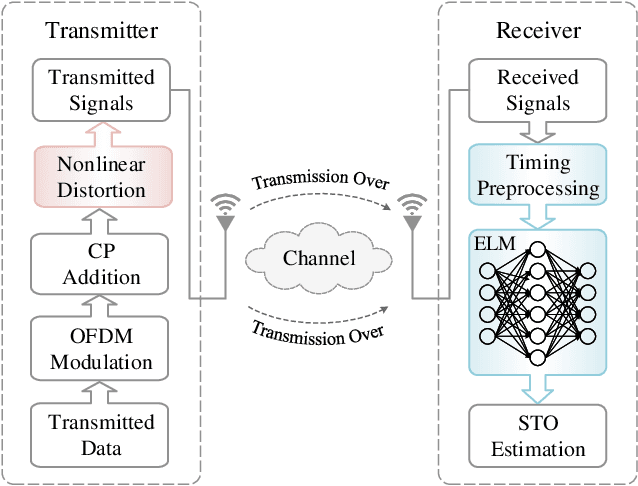
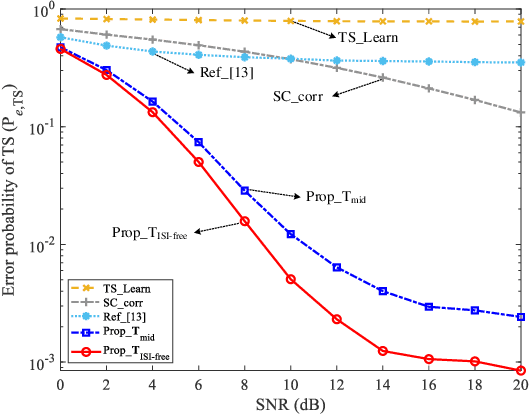
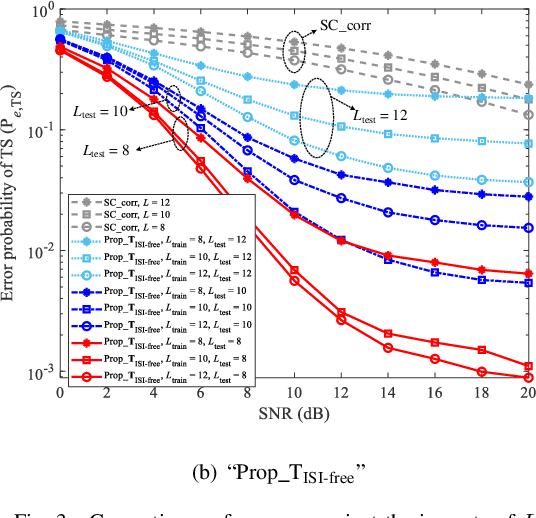
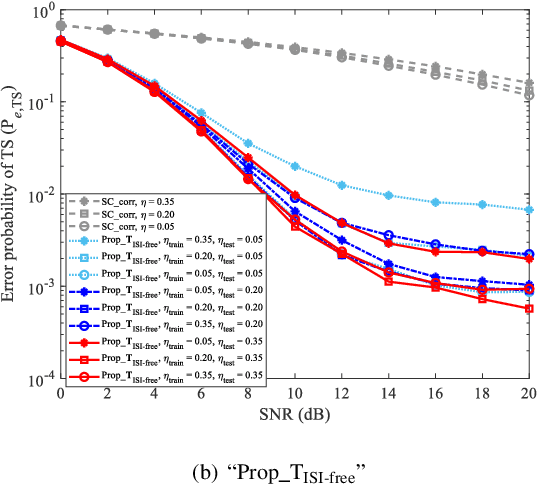
Due to the nonlinear distortion in Orthogonal frequency division multiplexing (OFDM) systems, the timing synchronization (TS) performance is inevitably degraded at the receiver. To relieve this issue, an extreme learning machine (ELM)-based network with a novel learning label is proposed to the TS of OFDM system in our work and increases the possibility of symbol timing offset (STO) estimation residing in inter-symbol interference (ISI)-free region. Especially, by exploiting the prior information of the ISI-free region, two types of learning labels are developed to facilitate the ELM-based TS network. With designed learning labels, a timing-processing by classic TS scheme is first executed to capture the coarse timing metric (TM) and then followed by an ELM network to refine the TM. According to experiments and analysis, our scheme shows its effectiveness in the improvement of TS performance and reveals its generalization performance in different training and testing channel scenarios.
Unsupervised Geodesic-preserved Generative Adversarial Networks for Unconstrained 3D Pose Transfer
Aug 17, 2021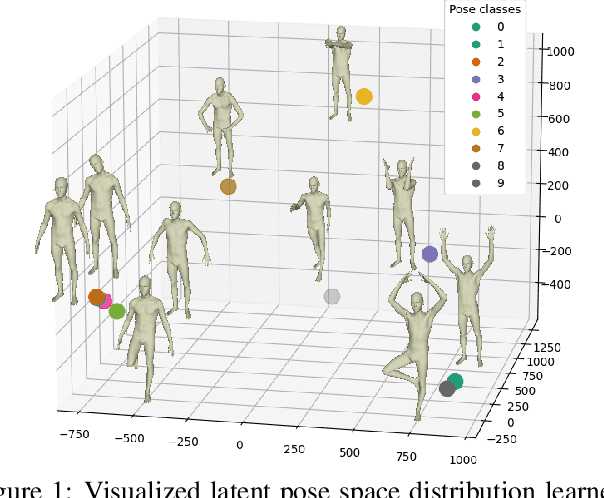

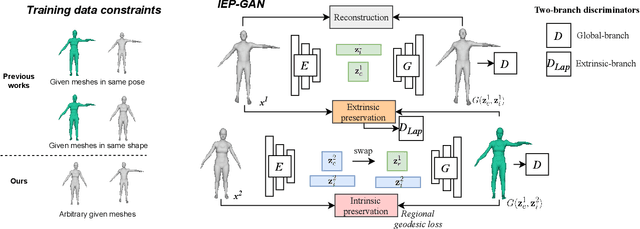
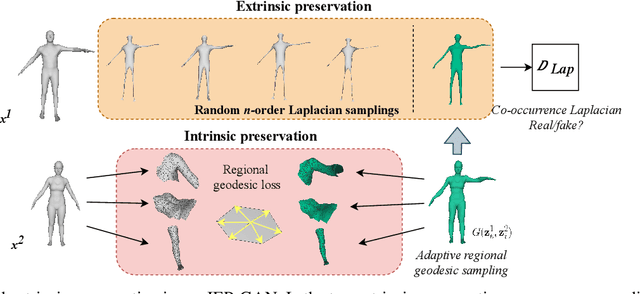
With the strength of deep generative models, 3D pose transfer regains intensive research interests in recent years. Existing methods mainly rely on a variety of constraints to achieve the pose transfer over 3D meshes, e.g., the need for the manually encoding for shape and pose disentanglement. In this paper, we present an unsupervised approach to conduct the pose transfer between any arbitrate given 3D meshes. Specifically, a novel Intrinsic-Extrinsic Preserved Generative Adversarial Network (IEP-GAN) is presented for both intrinsic (i.e., shape) and extrinsic (i.e., pose) information preservation. Extrinsically, we propose a co-occurrence discriminator to capture the structural/pose invariance from distinct Laplacians of the mesh. Meanwhile, intrinsically, a local intrinsic-preserved loss is introduced to preserve the geodesic priors while avoiding the heavy computations. At last, we show the possibility of using IEP-GAN to manipulate 3D human meshes in various ways, including pose transfer, identity swapping and pose interpolation with latent code vector arithmetic. The extensive experiments on various 3D datasets of humans, animals and hands qualitatively and quantitatively demonstrate the generality of our approach. Our proposed model produces better results and is substantially more efficient compared to recent state-of-the-art methods. Code is available: https://github.com/mikecheninoulu/Unsupervised_IEPGAN.
Globally Convergent Multilevel Training of Deep Residual Networks
Jul 15, 2021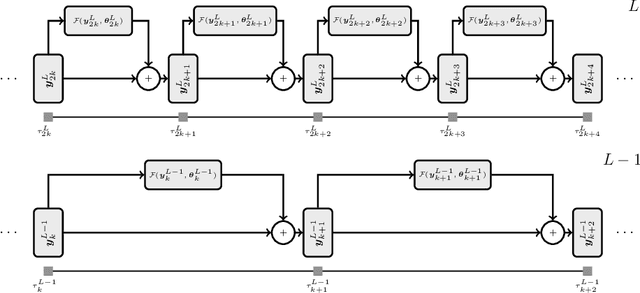

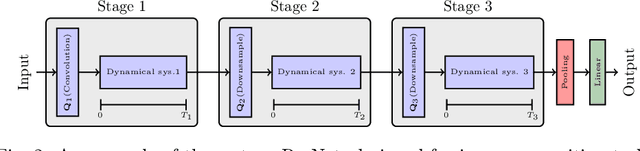

We propose a globally convergent multilevel training method for deep residual networks (ResNets). The devised method can be seen as a novel variant of the recursive multilevel trust-region (RMTR) method, which operates in hybrid (stochastic-deterministic) settings by adaptively adjusting mini-batch sizes during the training. The multilevel hierarchy and the transfer operators are constructed by exploiting a dynamical system's viewpoint, which interprets forward propagation through the ResNet as a forward Euler discretization of an initial value problem. In contrast to traditional training approaches, our novel RMTR method also incorporates curvature information on all levels of the multilevel hierarchy by means of the limited-memory SR1 method. The overall performance and the convergence properties of our multilevel training method are numerically investigated using examples from the field of classification and regression.
With One Voice: Composing a Travel Voice Assistant from Re-purposed Models
Aug 04, 2021
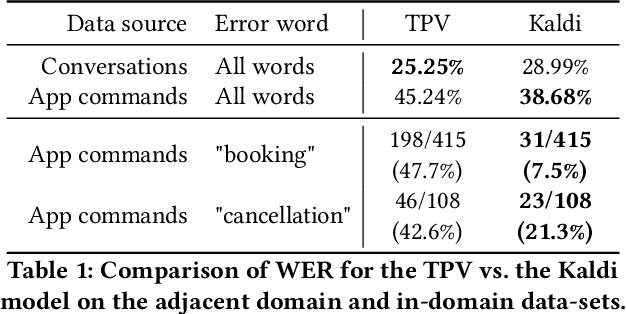
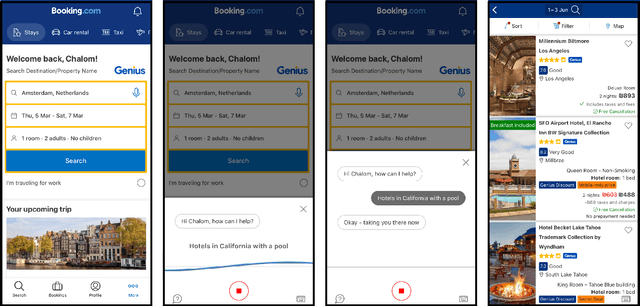

Voice assistants provide users a new way of interacting with digital products, allowing them to retrieve information and complete tasks with an increased sense of control and flexibility. Such products are comprised of several machine learning models, like Speech-to-Text transcription, Named Entity Recognition and Resolution, and Text Classification. Building a voice assistant from scratch takes the prolonged efforts of several teams constructing numerous models and orchestrating between components. Alternatives such as using third-party vendors or re-purposing existing models may be considered to shorten time-to-market and development costs. However, each option has its benefits and drawbacks. We present key insights from building a voice search assistant for Booking.com search and recommendation system. Our paper compares the achieved performance and development efforts in dedicated tailor-made solutions against existing re-purposed models. We share and discuss our data-driven decisions about implementation trade-offs and their estimated outcomes in hindsight, showing that a fully functional machine learning product can be built from existing models.
* 2nd International Workshop on Industrial Recommendation Systems @ KDD 2021
DP-NormFedAvg: Normalizing Client Updates for Privacy-Preserving Federated Learning
Jun 13, 2021
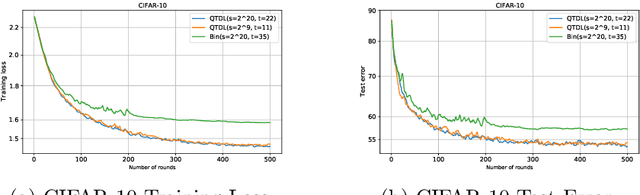

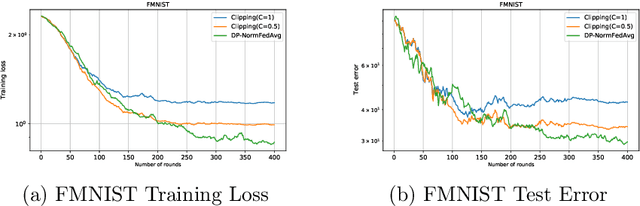
In this paper, we focus on facilitating differentially private quantized communication between the clients and server in federated learning (FL). Towards this end, we propose to have the clients send a \textit{private quantized} version of only the \textit{unit vector} along the change in their local parameters to the server, \textit{completely throwing away the magnitude information}. We call this algorithm \texttt{DP-NormFedAvg} and show that it has the same order-wise convergence rate as \texttt{FedAvg} on smooth quasar-convex functions (an important class of non-convex functions for modeling optimization of deep neural networks), thereby establishing that discarding the magnitude information is not detrimental from an optimization point of view. We also introduce QTDL, a new differentially private quantization mechanism for unit-norm vectors, which we use in \texttt{DP-NormFedAvg}. QTDL employs \textit{discrete} noise having a Laplacian-like distribution on a \textit{finite support} to provide privacy. We show that under a growth-condition assumption on the per-sample client losses, the extra per-coordinate communication cost in each round incurred due to privacy by our method is $\mathcal{O}(1)$ with respect to the model dimension, which is an improvement over prior work. Finally, we show the efficacy of our proposed method with experiments on fully-connected neural networks trained on CIFAR-10 and Fashion-MNIST.