 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Disentangling What and Where for 3D Object-Centric Representations Through Active Inference
Aug 26, 2021
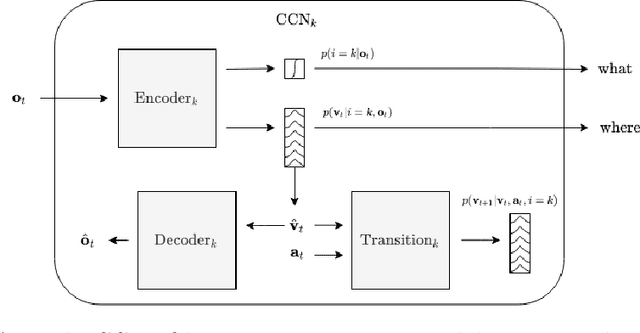
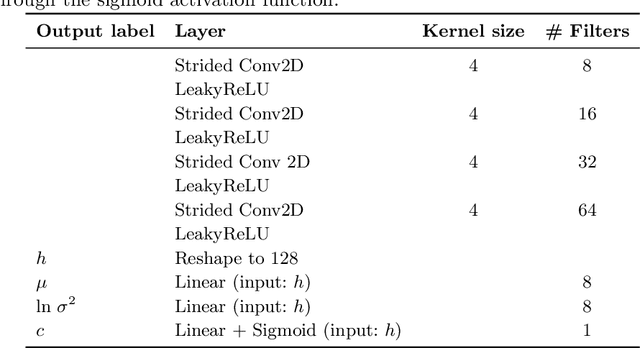
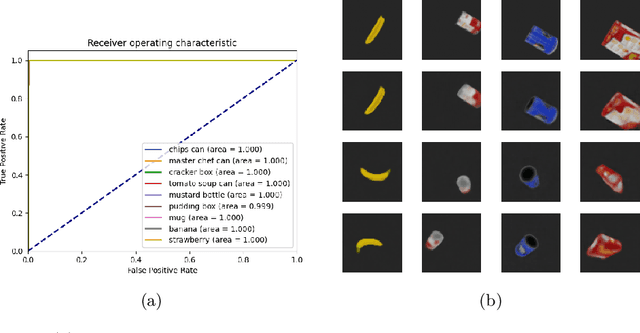
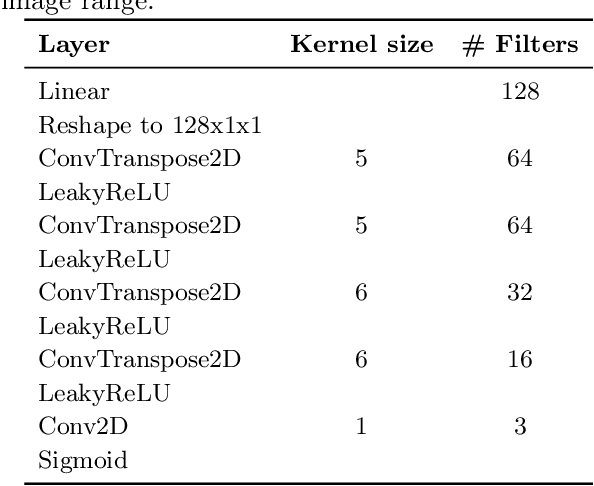
Although modern object detection and classification models achieve high accuracy, these are typically constrained in advance on a fixed train set and are therefore not flexible to deal with novel, unseen object categories. Moreover, these models most often operate on a single frame, which may yield incorrect classifications in case of ambiguous viewpoints. In this paper, we propose an active inference agent that actively gathers evidence for object classifications, and can learn novel object categories over time. Drawing inspiration from the human brain, we build object-centric generative models composed of two information streams, a what- and a where-stream. The what-stream predicts whether the observed object belongs to a specific category, while the where-stream is responsible for representing the object in its internal 3D reference frame. We show that our agent (i) is able to learn representations for many object categories in an unsupervised way, (ii) achieves state-of-the-art classification accuracies, actively resolving ambiguity when required and (iii) identifies novel object categories. Furthermore, we validate our system in an end-to-end fashion where the agent is able to search for an object at a given pose from a pixel-based rendering. We believe that this is a first step towards building modular, intelligent systems that can be used for a wide range of tasks involving three dimensional objects.
Linguistic Structures as Weak Supervision for Visual Scene Graph Generation
May 28, 2021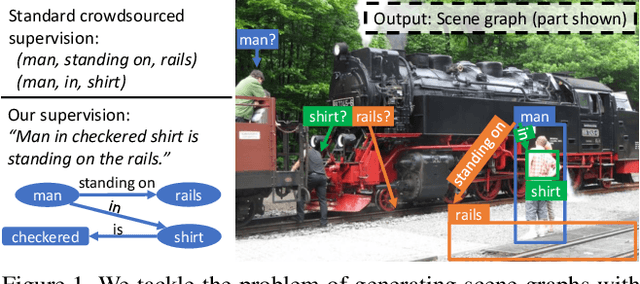

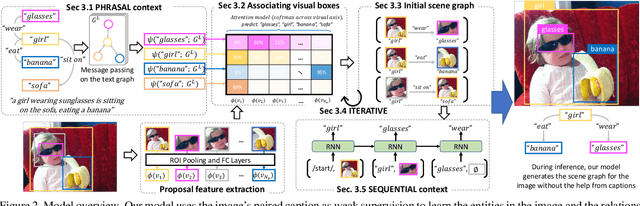
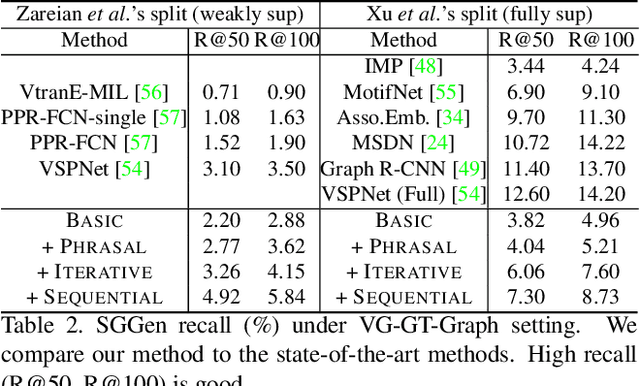
Prior work in scene graph generation requires categorical supervision at the level of triplets - subjects and objects, and predicates that relate them, either with or without bounding box information. However, scene graph generation is a holistic task: thus holistic, contextual supervision should intuitively improve performance. In this work, we explore how linguistic structures in captions can benefit scene graph generation. Our method captures the information provided in captions about relations between individual triplets, and context for subjects and objects (e.g. visual properties are mentioned). Captions are a weaker type of supervision than triplets since the alignment between the exhaustive list of human-annotated subjects and objects in triplets, and the nouns in captions, is weak. However, given the large and diverse sources of multimodal data on the web (e.g. blog posts with images and captions), linguistic supervision is more scalable than crowdsourced triplets. We show extensive experimental comparisons against prior methods which leverage instance- and image-level supervision, and ablate our method to show the impact of leveraging phrasal and sequential context, and techniques to improve localization of subjects and objects.
Effective and scalable clustering of SARS-CoV-2 sequences
Sep 10, 2021
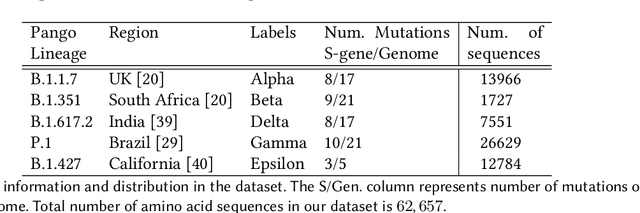
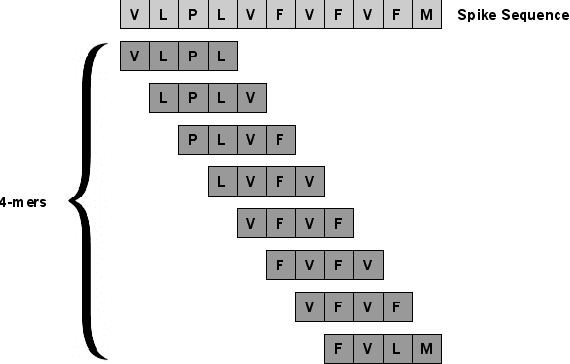
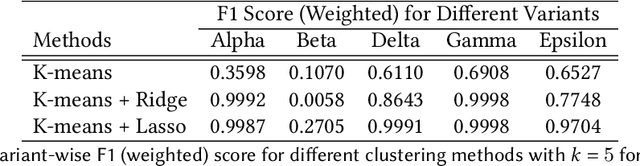
SARS-CoV-2, like any other virus, continues to mutate as it spreads, according to an evolutionary process. Unlike any other virus, the number of currently available sequences of SARS-CoV-2 in public databases such as GISAID is already several million. This amount of data has the potential to uncover the evolutionary dynamics of a virus like never before. However, a million is already several orders of magnitude beyond what can be processed by the traditional methods designed to reconstruct a virus's evolutionary history, such as those that build a phylogenetic tree. Hence, new and scalable methods will need to be devised in order to make use of the ever increasing number of viral sequences being collected. Since identifying variants is an important part of understanding the evolution of a virus, in this paper, we propose an approach based on clustering sequences to identify the current major SARS-CoV-2 variants. Using a $k$-mer based feature vector generation and efficient feature selection methods, our approach is effective in identifying variants, as well as being efficient and scalable to millions of sequences. Such a clustering method allows us to show the relative proportion of each variant over time, giving the rate of spread of each variant in different locations -- something which is important for vaccine development and distribution. We also compute the importance of each amino acid position of the spike protein in identifying a given variant in terms of information gain. Positions of high variant-specific importance tend to agree with those reported by the USA's Centers for Disease Control and Prevention (CDC), further demonstrating our approach.
Variational Information Maximization for Feature Selection
Jun 09, 2016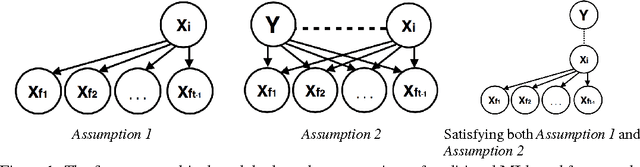


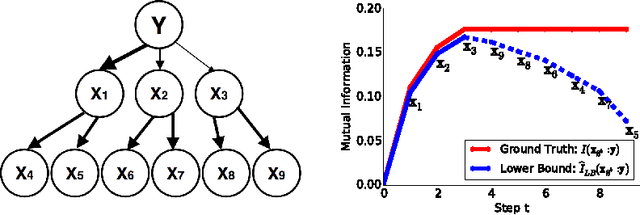
Feature selection is one of the most fundamental problems in machine learning. An extensive body of work on information-theoretic feature selection exists which is based on maximizing mutual information between subsets of features and class labels. Practical methods are forced to rely on approximations due to the difficulty of estimating mutual information. We demonstrate that approximations made by existing methods are based on unrealistic assumptions. We formulate a more flexible and general class of assumptions based on variational distributions and use them to tractably generate lower bounds for mutual information. These bounds define a novel information-theoretic framework for feature selection, which we prove to be optimal under tree graphical models with proper choice of variational distributions. Our experiments demonstrate that the proposed method strongly outperforms existing information-theoretic feature selection approaches.
CausalRec: Causal Inference for Visual Debiasing in Visually-Aware Recommendation
Jul 09, 2021
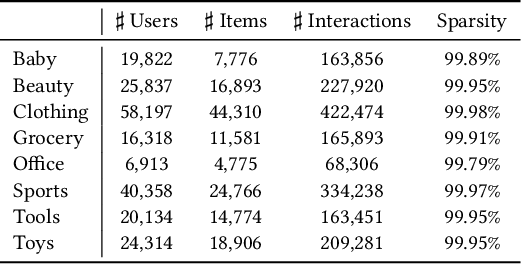
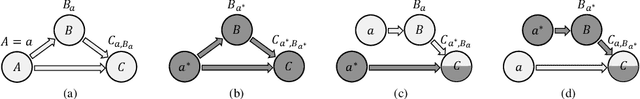
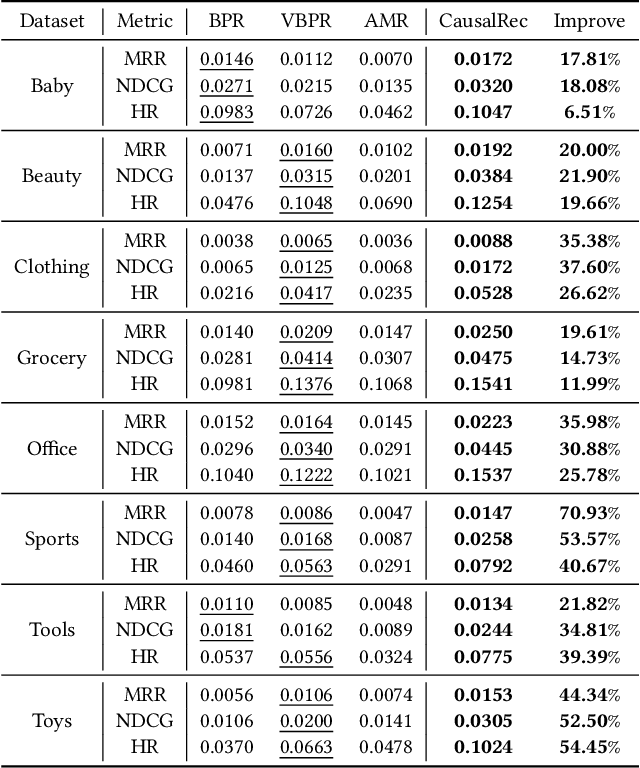
Visually-aware recommendation on E-commerce platforms aims to leverage visual information of items to predict a user's preference. It is commonly observed that user's attention to visual features does not always reflect the real preference. Although a user may click and view an item in light of a visual satisfaction of their expectations, a real purchase does not always occur due to the unsatisfaction of other essential features (e.g., brand, material, price). We refer to the reason for such a visually related interaction deviating from the real preference as a visual bias. Existing visually-aware models make use of the visual features as a separate collaborative signal similarly to other features to directly predict the user's preference without considering a potential bias, which gives rise to a visually biased recommendation. In this paper, we derive a causal graph to identify and analyze the visual bias of these existing methods. In this causal graph, the visual feature of an item acts as a mediator, which could introduce a spurious relationship between the user and the item. To eliminate this spurious relationship that misleads the prediction of the user's real preference, an intervention and a counterfactual inference are developed over the mediator. Particularly, the Total Indirect Effect is applied for a debiased prediction during the testing phase of the model. This causal inference framework is model agnostic such that it can be integrated into the existing methods. Furthermore, we propose a debiased visually-aware recommender system, denoted as CausalRec to effectively retain the supportive significance of the visual information and remove the visual bias. Extensive experiments are conducted on eight benchmark datasets, which shows the state-of-the-art performance of CausalRec and the efficacy of debiasing.
Surgical Instruction Generation with Transformers
Jul 14, 2021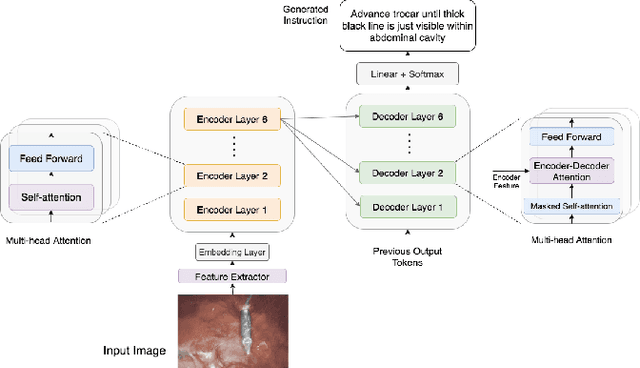
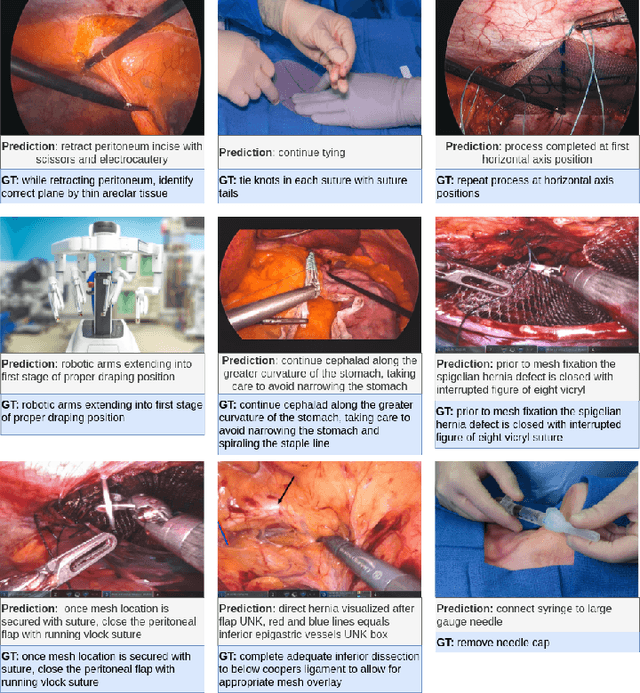
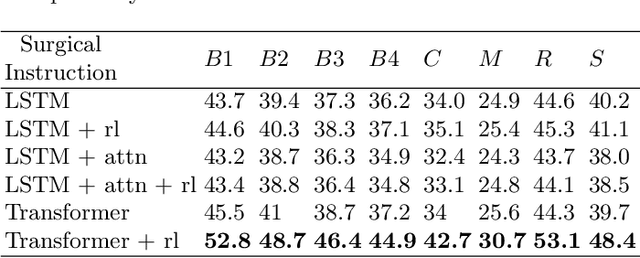
Automatic surgical instruction generation is a prerequisite towards intra-operative context-aware surgical assistance. However, generating instructions from surgical scenes is challenging, as it requires jointly understanding the surgical activity of current view and modelling relationships between visual information and textual description. Inspired by the neural machine translation and imaging captioning tasks in open domain, we introduce a transformer-backboned encoder-decoder network with self-critical reinforcement learning to generate instructions from surgical images. We evaluate the effectiveness of our method on DAISI dataset, which includes 290 procedures from various medical disciplines. Our approach outperforms the existing baseline over all caption evaluation metrics. The results demonstrate the benefits of the encoder-decoder structure backboned by transformer in handling multimodal context.
Learning to Gather Information via Imitation
Nov 13, 2016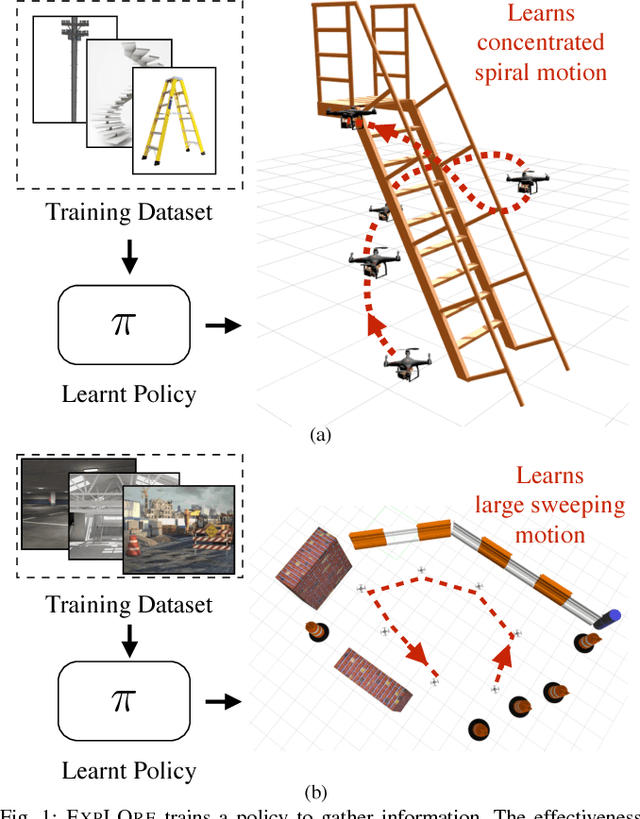
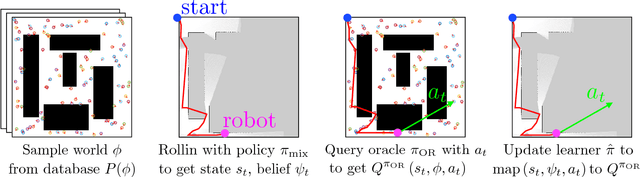
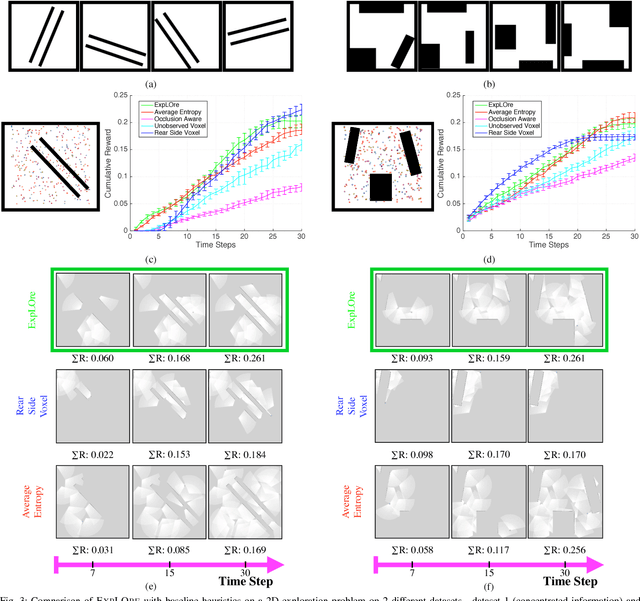
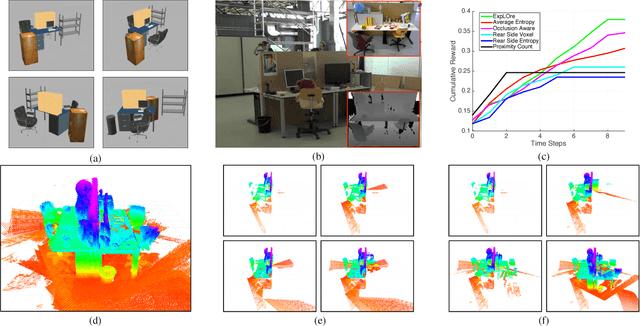
The budgeted information gathering problem - where a robot with a fixed fuel budget is required to maximize the amount of information gathered from the world - appears in practice across a wide range of applications in autonomous exploration and inspection with mobile robots. Although there is an extensive amount of prior work investigating effective approximations of the problem, these methods do not address the fact that their performance is heavily dependent on distribution of objects in the world. In this paper, we attempt to address this issue by proposing a novel data-driven imitation learning framework. We present an efficient algorithm, EXPLORE, that trains a policy on the target distribution to imitate a clairvoyant oracle - an oracle that has full information about the world and computes non-myopic solutions to maximize information gathered. We validate the approach on a spectrum of results on a number of 2D and 3D exploration problems that demonstrates the ability of EXPLORE to adapt to different object distributions. Additionally, our analysis provides theoretical insight into the behavior of EXPLORE. Our approach paves the way forward for efficiently applying data-driven methods to the domain of information gathering.
CLIP: A Dataset for Extracting Action Items for Physicians from Hospital Discharge Notes
Jun 04, 2021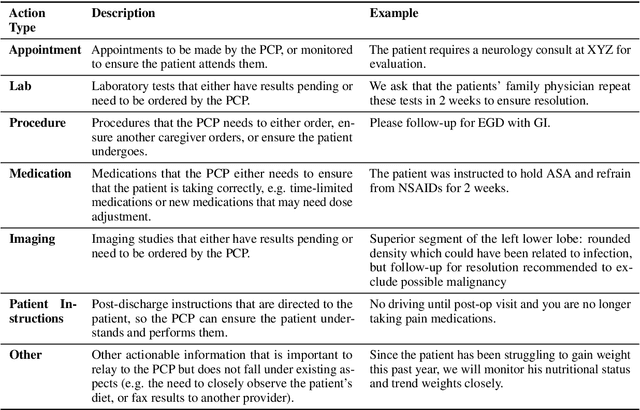

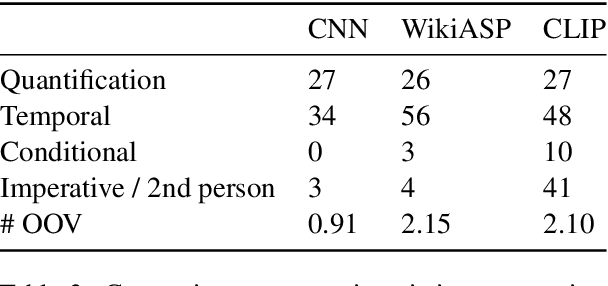
Continuity of care is crucial to ensuring positive health outcomes for patients discharged from an inpatient hospital setting, and improved information sharing can help. To share information, caregivers write discharge notes containing action items to share with patients and their future caregivers, but these action items are easily lost due to the lengthiness of the documents. In this work, we describe our creation of a dataset of clinical action items annotated over MIMIC-III, the largest publicly available dataset of real clinical notes. This dataset, which we call CLIP, is annotated by physicians and covers 718 documents representing 100K sentences. We describe the task of extracting the action items from these documents as multi-aspect extractive summarization, with each aspect representing a type of action to be taken. We evaluate several machine learning models on this task, and show that the best models exploit in-domain language model pre-training on 59K unannotated documents, and incorporate context from neighboring sentences. We also propose an approach to pre-training data selection that allows us to explore the trade-off between size and domain-specificity of pre-training datasets for this task.
Adversarial Robustness through the Lens of Causality
Jun 11, 2021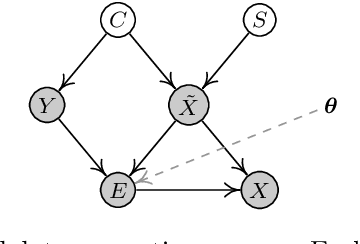
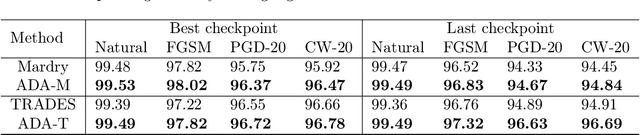
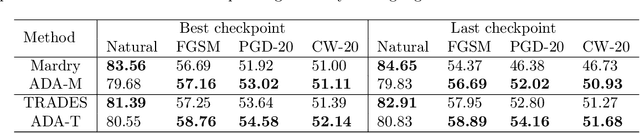
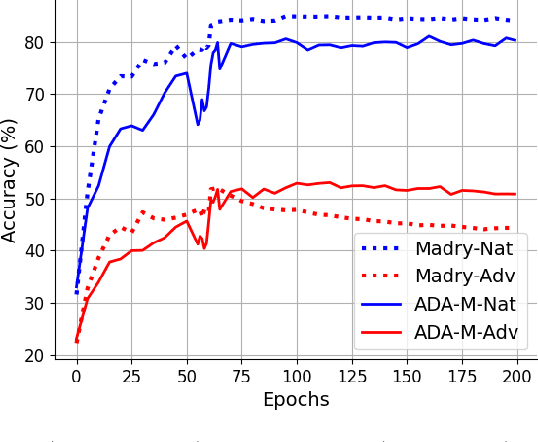
The adversarial vulnerability of deep neural networks has attracted significant attention in machine learning. From a causal viewpoint, adversarial attacks can be considered as a specific type of distribution change on natural data. As causal reasoning has an instinct for modeling distribution change, we propose to incorporate causality into mitigating adversarial vulnerability. However, causal formulations of the intuition of adversarial attack and the development of robust DNNs are still lacking in the literature. To bridge this gap, we construct a causal graph to model the generation process of adversarial examples and define the adversarial distribution to formalize the intuition of adversarial attacks. From a causal perspective, we find that the label is spuriously correlated with the style (content-independent) information when an instance is given. The spurious correlation implies that the adversarial distribution is constructed via making the statistical conditional association between style information and labels drastically different from that in natural distribution. Thus, DNNs that fit the spurious correlation are vulnerable to the adversarial distribution. Inspired by the observation, we propose the adversarial distribution alignment method to eliminate the difference between the natural distribution and the adversarial distribution. Extensive experiments demonstrate the efficacy of the proposed method. Our method can be seen as the first attempt to leverage causality for mitigating adversarial vulnerability.
Active Privacy-utility Trade-off Against a Hypothesis Testing Adversary
Feb 18, 2021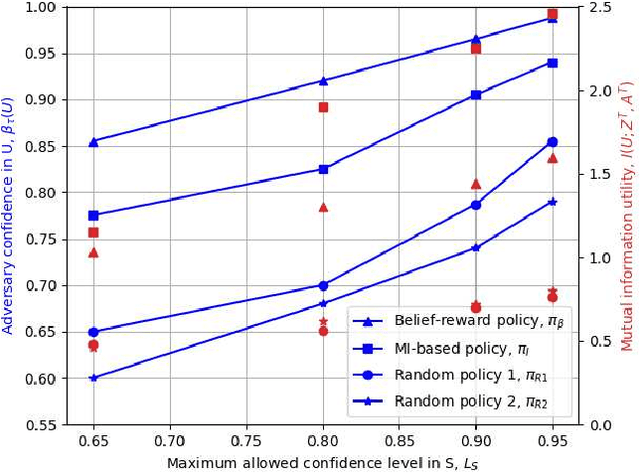
We consider a user releasing her data containing some personal information in return of a service. We model user's personal information as two correlated random variables, one of them, called the secret variable, is to be kept private, while the other, called the useful variable, is to be disclosed for utility. We consider active sequential data release, where at each time step the user chooses from among a finite set of release mechanisms, each revealing some information about the user's personal information, i.e., the true hypotheses, albeit with different statistics. The user manages data release in an online fashion such that maximum amount of information is revealed about the latent useful variable, while the confidence for the sensitive variable is kept below a predefined level. For the utility, we consider both the probability of correct detection of the useful variable and the mutual information (MI) between the useful variable and released data. We formulate both problems as a Markov decision process (MDP), and numerically solve them by advantage actor-critic (A2C) deep reinforcement learning (RL).