 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
The Many Dimensions of Truthfulness: Crowdsourcing Misinformation Assessments on a Multidimensional Scale
Aug 23, 2021
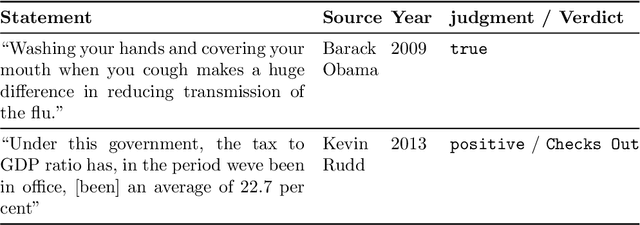
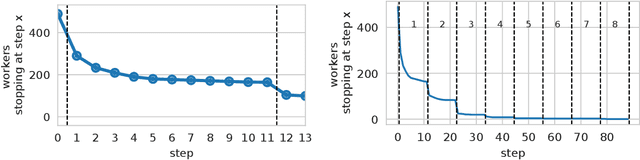
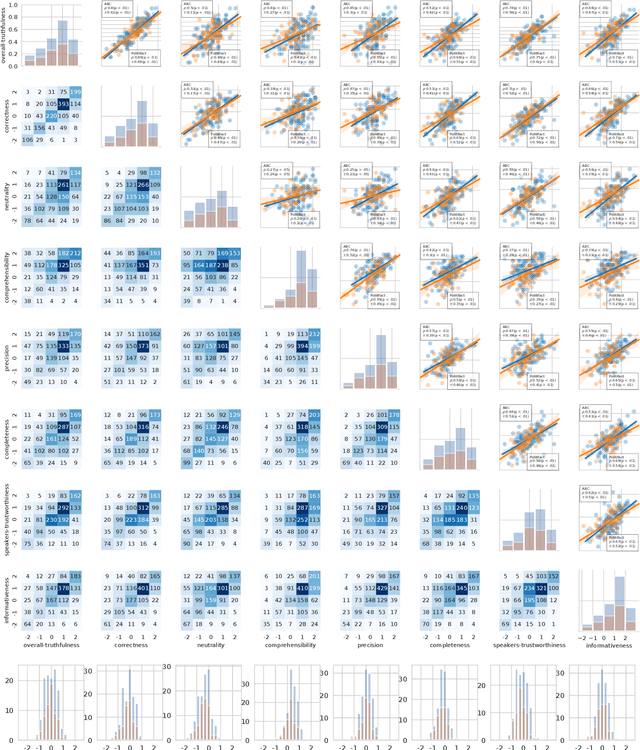
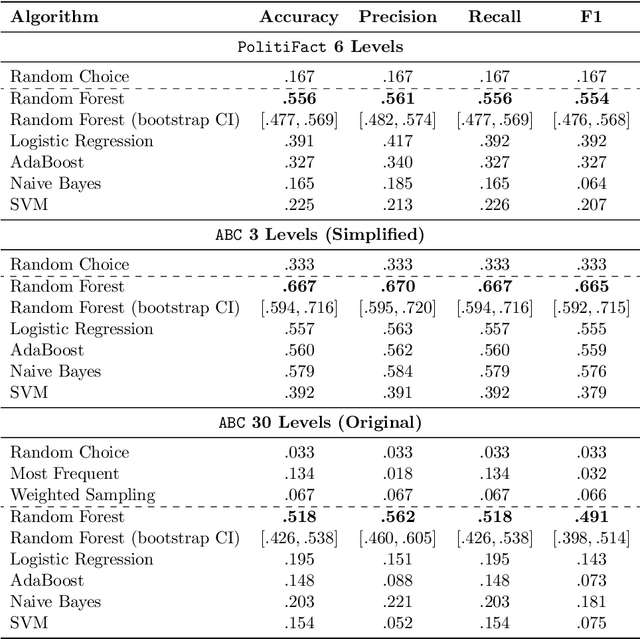
Recent work has demonstrated the viability of using crowdsourcing as a tool for evaluating the truthfulness of public statements. Under certain conditions such as: (1) having a balanced set of workers with different backgrounds and cognitive abilities; (2) using an adequate set of mechanisms to control the quality of the collected data; and (3) using a coarse grained assessment scale, the crowd can provide reliable identification of fake news. However, fake news are a subtle matter: statements can be just biased ("cherrypicked"), imprecise, wrong, etc. and the unidimensional truth scale used in existing work cannot account for such differences. In this paper we propose a multidimensional notion of truthfulness and we ask the crowd workers to assess seven different dimensions of truthfulness selected based on existing literature: Correctness, Neutrality, Comprehensibility, Precision, Completeness, Speaker's Trustworthiness, and Informativeness. We deploy a set of quality control mechanisms to ensure that the thousands of assessments collected on 180 publicly available fact-checked statements distributed over two datasets are of adequate quality, including a custom search engine used by the crowd workers to find web pages supporting their truthfulness assessments. A comprehensive analysis of crowdsourced judgments shows that: (1) the crowdsourced assessments are reliable when compared to an expert-provided gold standard; (2) the proposed dimensions of truthfulness capture independent pieces of information; (3) the crowdsourcing task can be easily learned by the workers; and (4) the resulting assessments provide a useful basis for a more complete estimation of statement truthfulness.
* 33 pages; Paper accepted at Information Processing & Management on July 28, 2021; IP&M Special Issue on Dis/Misinformation Mining from Social Media
Iterative, Deep, and Unsupervised Synthetic Aperture Sonar Image Segmentation
Jul 30, 2021
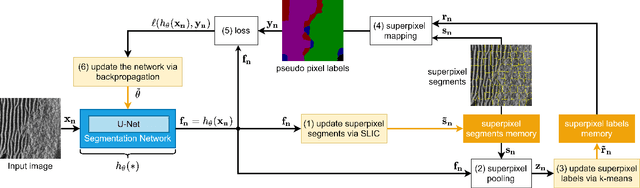
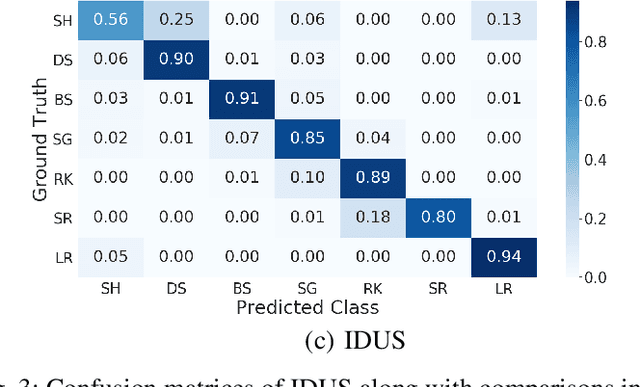
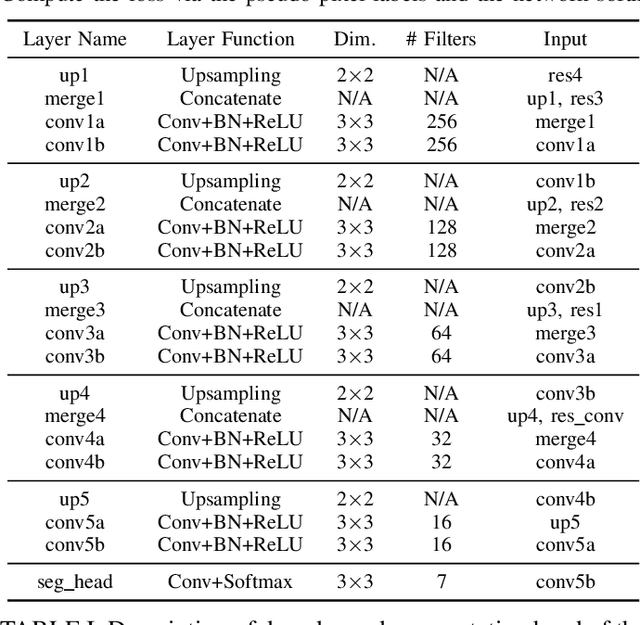
Deep learning has not been routinely employed for semantic segmentation of seabed environment for synthetic aperture sonar (SAS) imagery due to the implicit need of abundant training data such methods necessitate. Abundant training data, specifically pixel-level labels for all images, is usually not available for SAS imagery due to the complex logistics (e.g., diver survey, chase boat, precision position information) needed for obtaining accurate ground-truth. Many hand-crafted feature based algorithms have been proposed to segment SAS in an unsupervised fashion. However, there is still room for improvement as the feature extraction step of these methods is fixed. In this work, we present a new iterative unsupervised algorithm for learning deep features for SAS image segmentation. Our proposed algorithm alternates between clustering superpixels and updating the parameters of a convolutional neural network (CNN) so that the feature extraction for image segmentation can be optimized. We demonstrate the efficacy of our method on a realistic benchmark dataset. Our results show that the performance of our proposed method is considerably better than current state-of-the-art methods in SAS image segmentation.
Principal component analysis for Gaussian process posteriors
Jul 15, 2021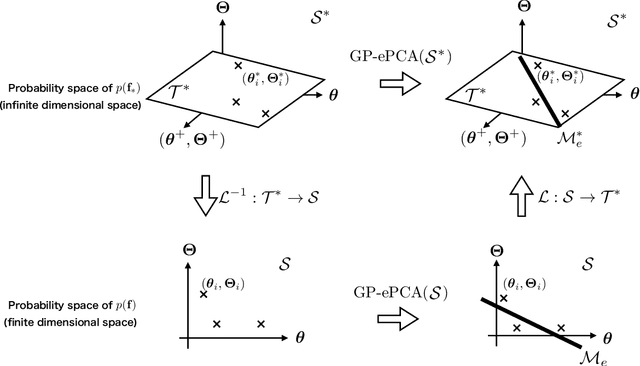
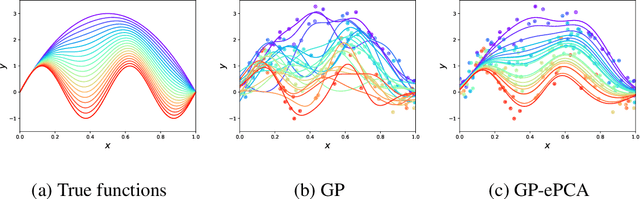
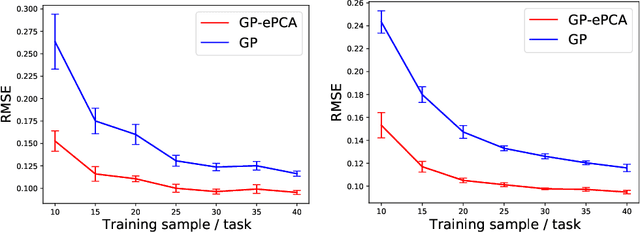
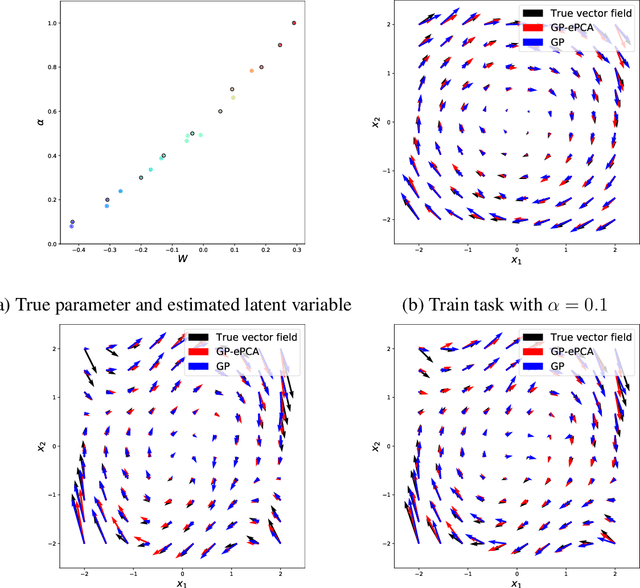
This paper proposes an extension of principal component analysis for Gaussian process posteriors denoted by GP-PCA. Since GP-PCA estimates a low-dimensional space of GP posteriors, it can be used for meta-learning, which is a framework for improving the precision of a new task by estimating a structure of a set of tasks. The issue is how to define a structure of a set of GPs with an infinite-dimensional parameter, such as coordinate system and a divergence. In this study, we reduce the infiniteness of GP to the finite-dimensional case under the information geometrical framework by considering a space of GP posteriors that has the same prior. In addition, we propose an approximation method of GP-PCA based on variational inference and demonstrate the effectiveness of GP-PCA as meta-learning through experiments.
Graph Trend Networks for Recommendations
Aug 12, 2021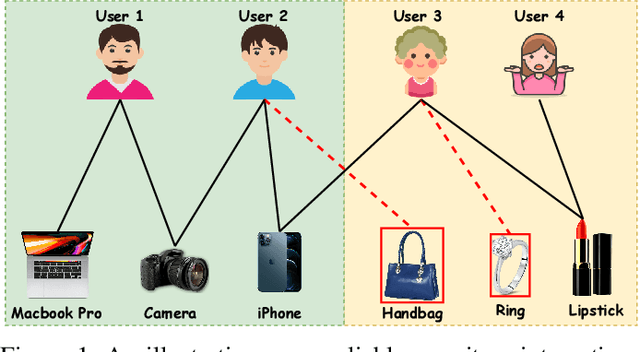
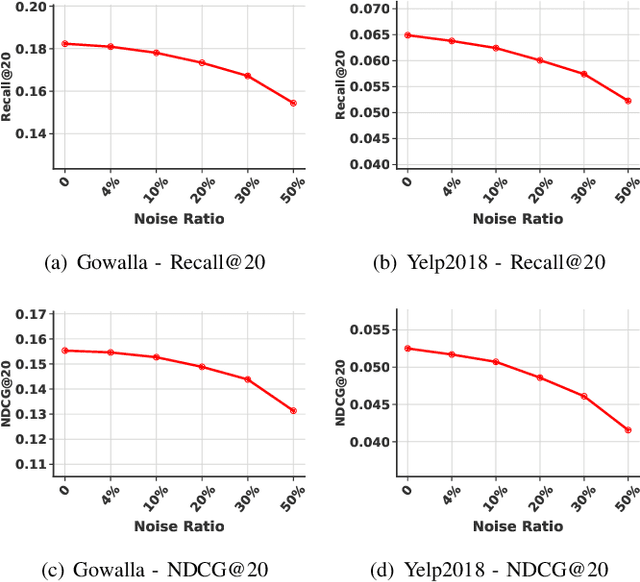
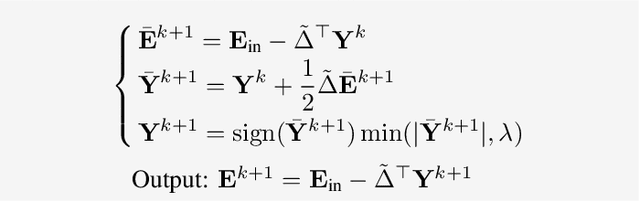
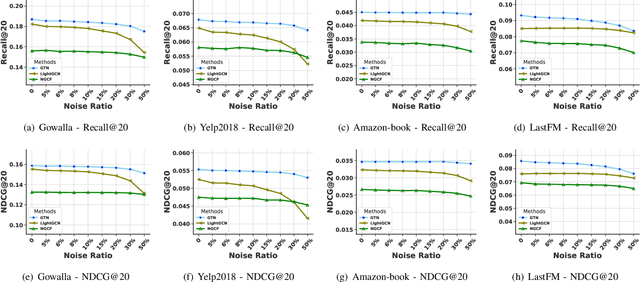
Recommender systems aim to provide personalized services to users and are playing an increasingly important role in our daily lives. The key of recommender systems is to predict how likely users will interact with items based on their historical online behaviors, e.g., clicks, add-to-cart, purchases, etc. To exploit these user-item interactions, there are increasing efforts on considering the user-item interactions as a user-item bipartite graph and then performing information propagation in the graph via Graph Neural Networks (GNNs). Given the power of GNNs in graph representation learning, these GNN-based recommendation methods have remarkably boosted the recommendation performance. Despite their success, most existing GNN-based recommender systems overlook the existence of interactions caused by unreliable behaviors (e.g., random/bait clicks) and uniformly treat all the interactions, which can lead to sub-optimal and unstable performance. In this paper, we investigate the drawbacks (e.g., non-adaptive propagation and non-robustness) of existing GNN-based recommendation methods. To address these drawbacks, we propose the Graph Trend Networks for recommendations (GTN) with principled designs that can capture the adaptive reliability of the interactions. Comprehensive experiments and ablation studies are presented to verify and understand the effectiveness of the proposed framework. Our implementation and datasets can be released after publication.
Improving Information Retrieval Results for Persian Documents using FarsNet
Nov 01, 2018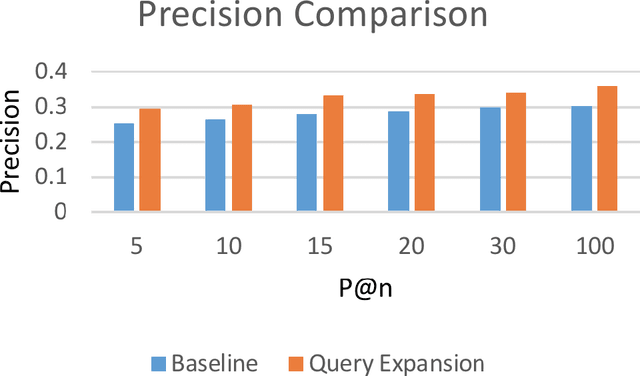
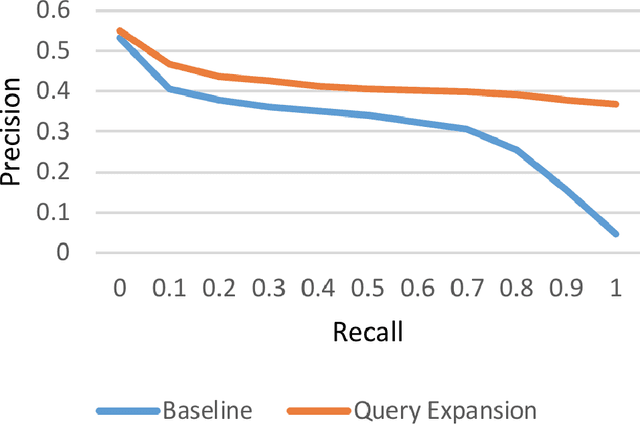
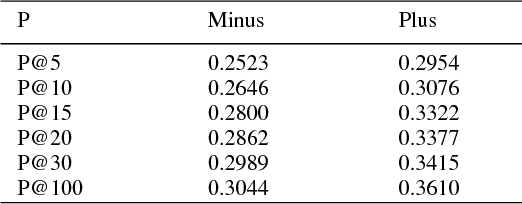
In this paper, we propose a new method for query expansion, which uses FarsNet (Persian WordNet) to find similar tokens related to the query and expand the semantic meaning of the query. For this purpose, we use synonymy relations in FarsNet and extract the related synonyms to query words. This algorithm is used to enhance information retrieval systems and improve search results. The overall evaluation of this system in comparison to the baseline method (without using query expansion) shows an improvement of about 9 percent in Mean Average Precision (MAP).
PP-Rec: News Recommendation with Personalized User Interest and Time-aware News Popularity
Jun 02, 2021
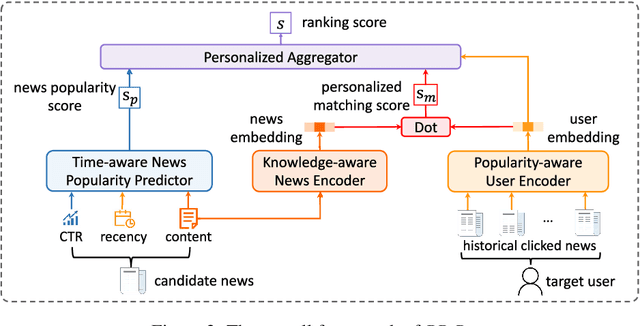
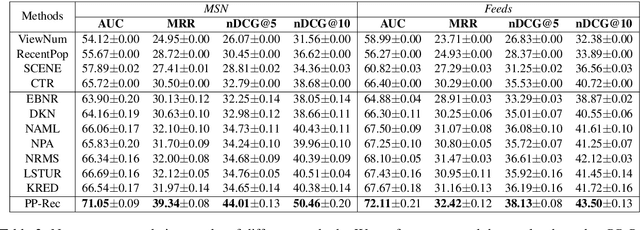
Personalized news recommendation methods are widely used in online news services. These methods usually recommend news based on the matching between news content and user interest inferred from historical behaviors. However, these methods usually have difficulties in making accurate recommendations to cold-start users, and tend to recommend similar news with those users have read. In general, popular news usually contain important information and can attract users with different interests. Besides, they are usually diverse in content and topic. Thus, in this paper we propose to incorporate news popularity information to alleviate the cold-start and diversity problems for personalized news recommendation. In our method, the ranking score for recommending a candidate news to a target user is the combination of a personalized matching score and a news popularity score. The former is used to capture the personalized user interest in news. The latter is used to measure time-aware popularity of candidate news, which is predicted based on news content, recency, and real-time CTR using a unified framework. Besides, we propose a popularity-aware user encoder to eliminate the popularity bias in user behaviors for accurate interest modeling. Experiments on two real-world datasets show our method can effectively improve the accuracy and diversity for news recommendation.
Separation of Powers in Federated Learning
May 19, 2021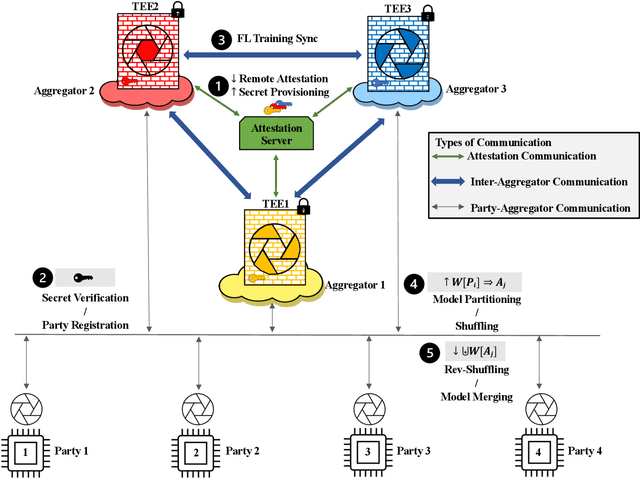
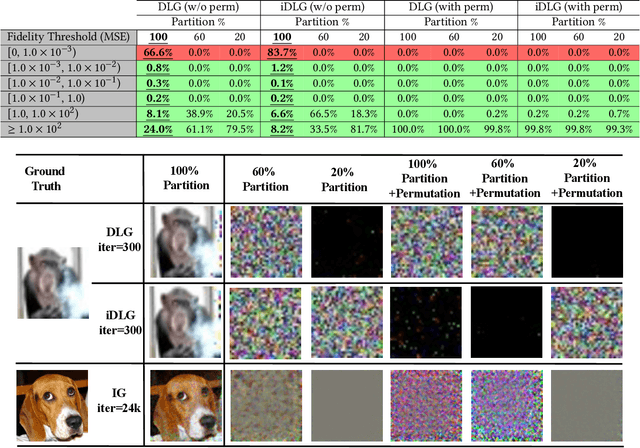
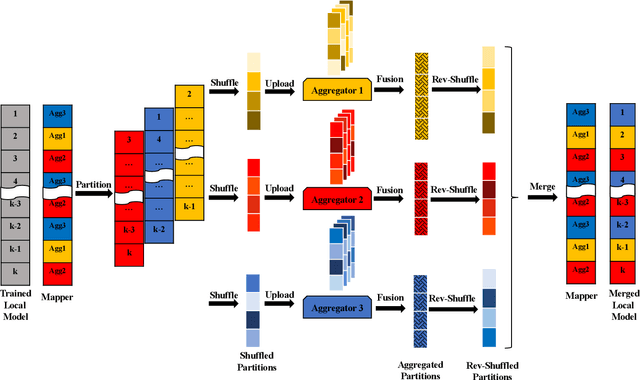

Federated Learning (FL) enables collaborative training among mutually distrusting parties. Model updates, rather than training data, are concentrated and fused in a central aggregation server. A key security challenge in FL is that an untrustworthy or compromised aggregation process might lead to unforeseeable information leakage. This challenge is especially acute due to recently demonstrated attacks that have reconstructed large fractions of training data from ostensibly "sanitized" model updates. In this paper, we introduce TRUDA, a new cross-silo FL system, employing a trustworthy and decentralized aggregation architecture to break down information concentration with regard to a single aggregator. Based on the unique computational properties of model-fusion algorithms, all exchanged model updates in TRUDA are disassembled at the parameter-granularity and re-stitched to random partitions designated for multiple TEE-protected aggregators. Thus, each aggregator only has a fragmentary and shuffled view of model updates and is oblivious to the model architecture. Our new security mechanisms can fundamentally mitigate training reconstruction attacks, while still preserving the final accuracy of trained models and keeping performance overheads low.
A Hybrid Recommender System for Recommending Smartphones to Prospective Customers
May 26, 2021



Recommender Systems are a subclass of machine learning systems that employ sophisticated information filtering strategies to reduce the search time and suggest the most relevant items to any particular user. Hybrid recommender systems combine multiple recommendation strategies in different ways to benefit from their complementary advantages. Some hybrid recommender systems have combined collaborative filtering and content-based approaches to build systems that are more robust. In this paper, we propose a hybrid recommender system, which combines Alternative Least Squares (ALS) based collaborative filtering with deep learning to enhance recommendation performance as well as overcome the limitations associated with the collaborative filtering approach, especially concerning its cold start problem. In essence, we use the outputs from ALS (collaborative filtering) to influence the recommendations from a Deep Neural Network (DNN), which combines characteristic, contextual, structural and sequential information, in a big data processing framework. We have conducted several experiments in testing the efficacy of the proposed hybrid architecture in recommending smartphones to prospective customers and compared its performance with other open-source recommenders. The results have shown that the proposed system has outperformed several existing hybrid recommender systems.
Augmented KRnet for density estimation and approximation
May 26, 2021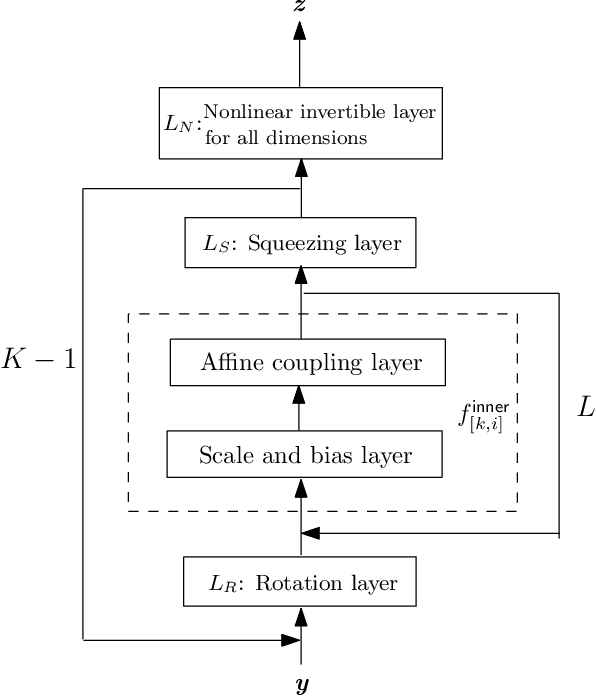
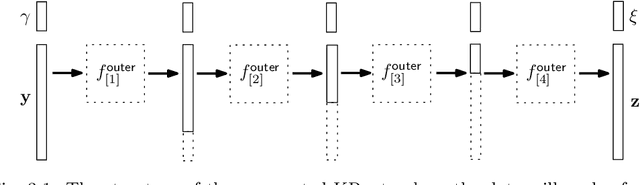
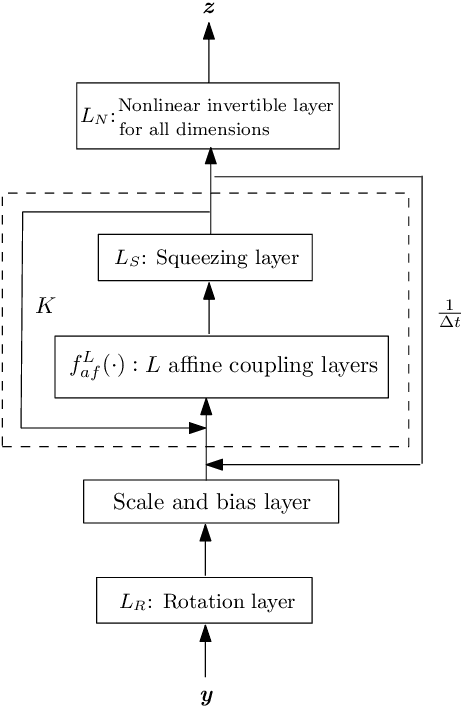
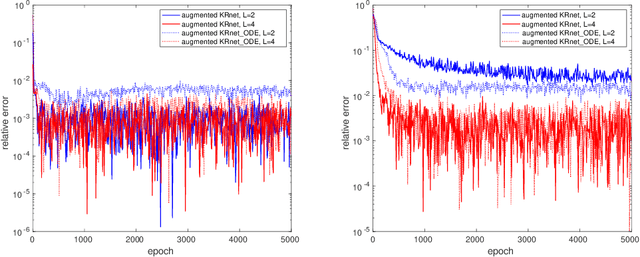
In this work, we have proposed augmented KRnets including both discrete and continuous models. One difficulty in flow-based generative modeling is to maintain the invertibility of the transport map, which is often a trade-off between effectiveness and robustness. The exact invertibility has been achieved in the real NVP using a specific pattern to exchange information between two separated groups of dimensions. KRnet has been developed to enhance the information exchange among data dimensions by incorporating the Knothe-Rosenblatt rearrangement into the structure of the transport map. Due to the maintenance of exact invertibility, a full nonlinear update of all data dimensions needs three iterations in KRnet. To alleviate this issue, we will add augmented dimensions that act as a channel for communications among the data dimensions. In the augmented KRnet, a fully nonlinear update is achieved in two iterations. We also show that the augmented KRnet can be reformulated as the discretization of a neural ODE, where the exact invertibility is kept such that the adjoint method can be formulated with respect to the discretized ODE to obtain the exact gradient. Numerical experiments have been implemented to demonstrate the effectiveness of our models.
High-Efficiency Resonant Beam Charging and Communication
Jul 30, 2021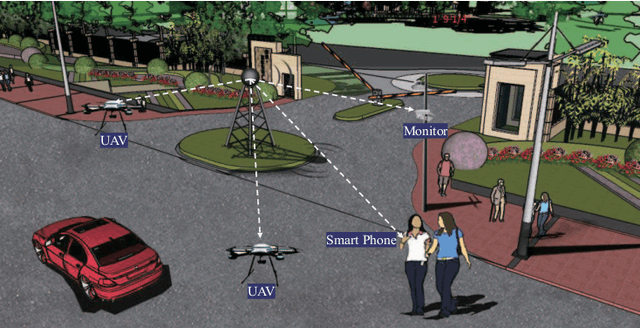
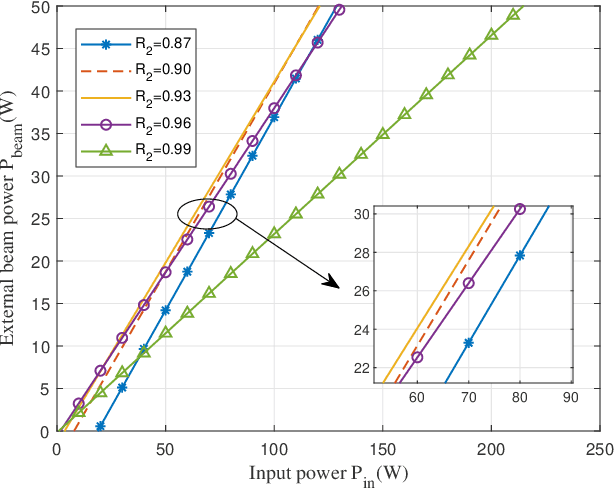
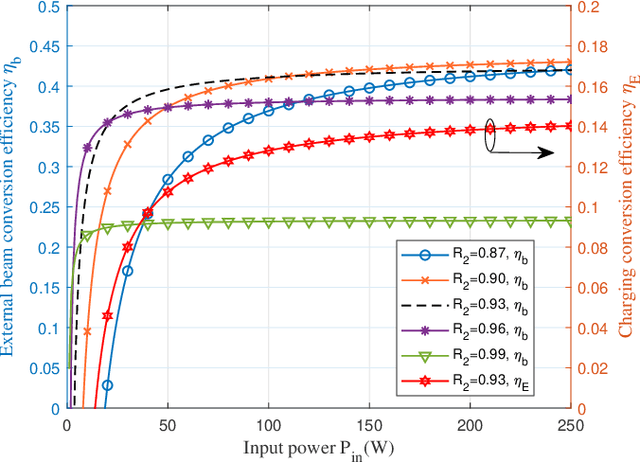
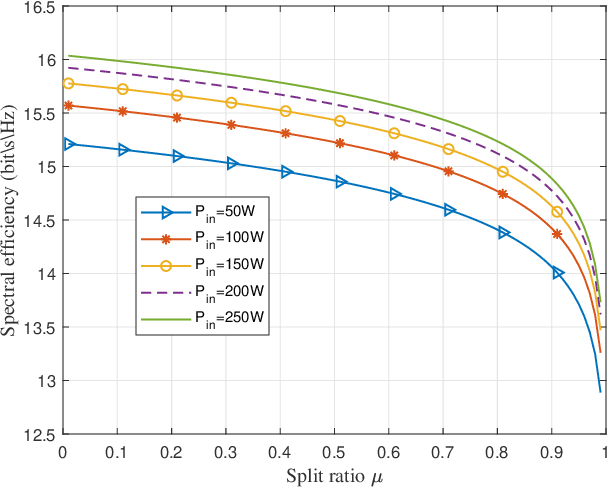
Simultaneous wireless information and power transfer (SWIPT) has been envisioned as an enabling technology for future 6G by providing high-efficiency power transfer and high-rate data transmissions concurrently. In this paper, we propose a resonant beam charging and communication (RBCC) system utilizing the telescope internal modulator (TIM) and the semiconductor gain medium. TIM can concentrate the diverged beam into a small-size gain module, thus the propagation loss is reduced and the transmission efficiency is enhanced. Since the semiconductor gain medium has better energy absorption capacity compared with the traditional solid-state one, the overall energy conversion efficiency can be improved. We establish an analytical model of this RBCC system for SWIPT and evaluate its stability, output energy, and spectral efficiency. Numerical analysis shows that the proposed RBCC system can realize stable SWIPT over 10 meters, whose energy conversion efficiency is increased by 14 times compared with the traditional system using the solid-state gain medium without TIM, and the spectrum efficiency can be above 15 bit/s/Hz.