 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Exploiting Multimodal Reinforcement Learning for Simultaneous Machine Translation
Feb 22, 2021

This paper addresses the problem of simultaneous machine translation (SiMT) by exploring two main concepts: (a) adaptive policies to learn a good trade-off between high translation quality and low latency; and (b) visual information to support this process by providing additional (visual) contextual information which may be available before the textual input is produced. For that, we propose a multimodal approach to simultaneous machine translation using reinforcement learning, with strategies to integrate visual and textual information in both the agent and the environment. We provide an exploration on how different types of visual information and integration strategies affect the quality and latency of simultaneous translation models, and demonstrate that visual cues lead to higher quality while keeping the latency low.
Auxiliary Class Based Multiple Choice Learning
Aug 06, 2021
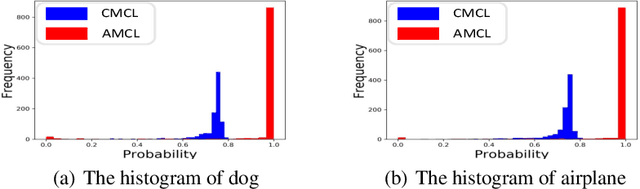


The merit of ensemble learning lies in having different outputs from many individual models on a single input, i.e., the diversity of the base models. The high quality of diversity can be achieved when each model is specialized to different subsets of the whole dataset. Moreover, when each model explicitly knows to which subsets it is specialized, more opportunities arise to improve diversity. In this paper, we propose an advanced ensemble method, called Auxiliary class based Multiple Choice Learning (AMCL), to ultimately specialize each model under the framework of multiple choice learning (MCL). The advancement of AMCL is originated from three novel techniques which control the framework from different directions: 1) the concept of auxiliary class to provide more distinct information through the labels, 2) the strategy, named memory-based assignment, to determine the association between the inputs and the models, and 3) the feature fusion module to achieve generalized features. To demonstrate the performance of our method compared to all variants of MCL methods, we conduct extensive experiments on the image classification and segmentation tasks. Overall, the performance of AMCL exceeds all others in most of the public datasets trained with various networks as members of the ensembles.
Structured Covariance Matrix Estimation with Missing-Data for Radar Applications via Expectation-Maximization
May 08, 2021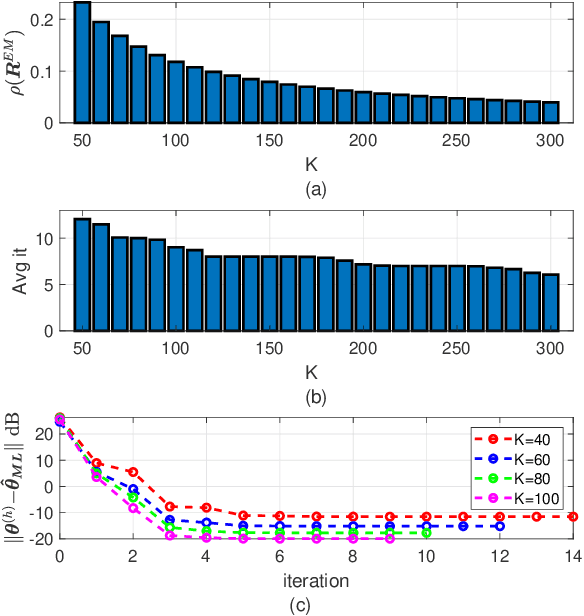
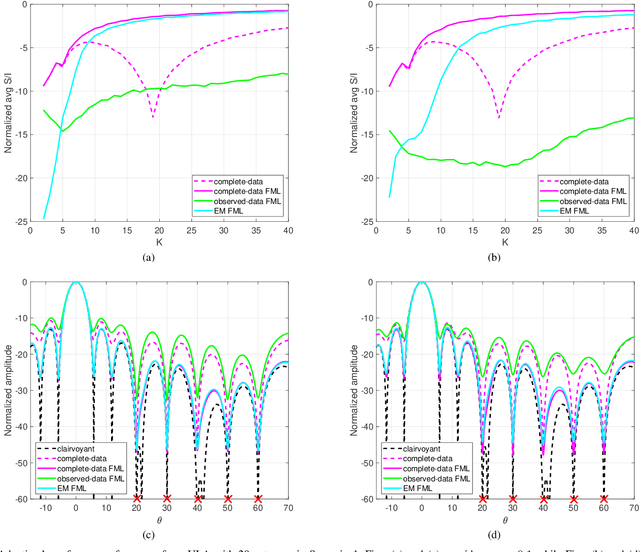
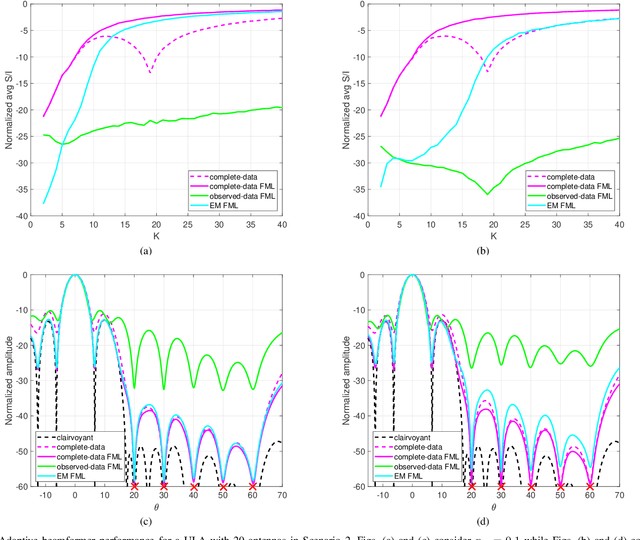
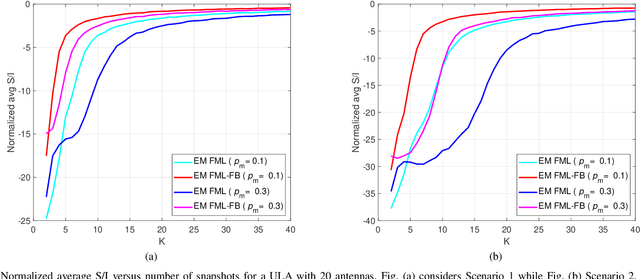
Structured covariance matrix estimation in the presence of missing data is addressed in this paper with emphasis on radar signal processing applications. After a motivation of the study, the array model is specified and the problem of computing the maximum likelihood estimate of a structured covariance matrix is formulated. A general procedure to optimize the observed-data likelihood function is developed resorting to the expectation-maximization algorithm. The corresponding convergence properties are thoroughly established and the rate of convergence is analyzed. The estimation technique is contextualized for two practically relevant radar problems: beamforming and detection of the number of sources. In the former case an adaptive beamformer leveraging the EM-based estimator is presented; in the latter, detection techniques generalizing the classic Akaike information criterion, minimum description length, and Hannan-Quinn information criterion, are introduced. Numerical results are finally presented to corroborate the theoretical study.
Transductive image segmentation: Self-training and effect of uncertainty estimation
Jul 30, 2021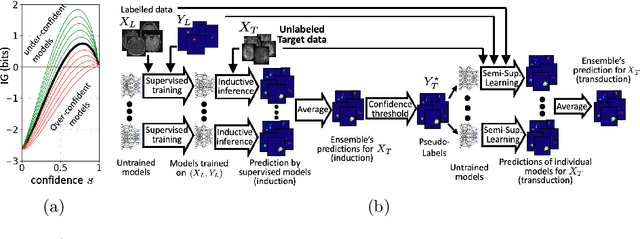

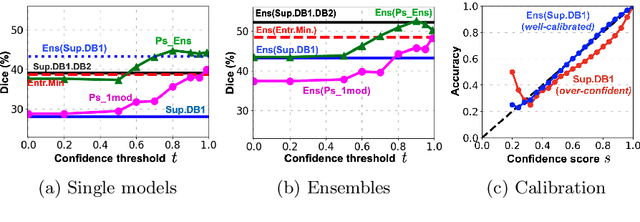
Semi-supervised learning (SSL) uses unlabeled data during training to learn better models. Previous studies on SSL for medical image segmentation focused mostly on improving model generalization to unseen data. In some applications, however, our primary interest is not generalization but to obtain optimal predictions on a specific unlabeled database that is fully available during model development. Examples include population studies for extracting imaging phenotypes. This work investigates an often overlooked aspect of SSL, transduction. It focuses on the quality of predictions made on the unlabeled data of interest when they are included for optimization during training, rather than improving generalization. We focus on the self-training framework and explore its potential for transduction. We analyze it through the lens of Information Gain and reveal that learning benefits from the use of calibrated or under-confident models. Our extensive experiments on a large MRI database for multi-class segmentation of traumatic brain lesions shows promising results when comparing transductive with inductive predictions. We believe this study will inspire further research on transductive learning, a well-suited paradigm for medical image analysis.
Attention-Gated Graph Convolutions for Extracting Drug Interaction Information from Drug Labels
Nov 04, 2019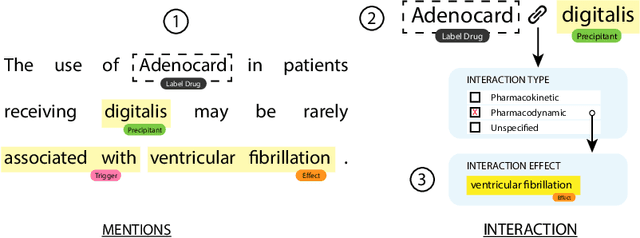
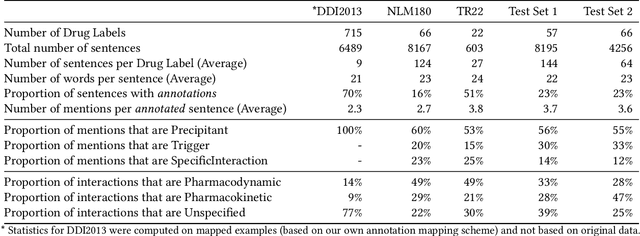

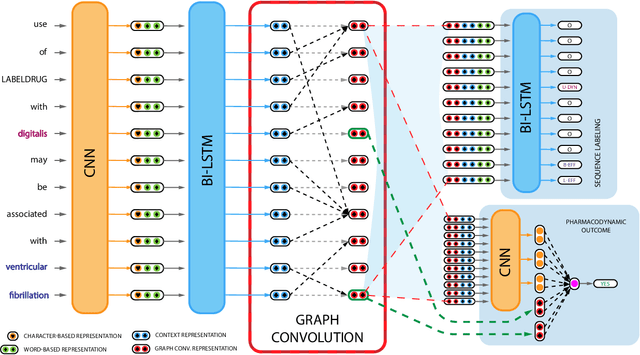
Preventable adverse events as a result of medical errors present a growing concern in the healthcare system. As drug-drug interactions (DDIs) may lead to preventable adverse events, being able to extract DDIs from drug labels into a machine-processable form is an important step toward effective dissemination of drug safety information. In this study, we tackle the problem of jointly extracting drugs and their interactions, including interaction outcome, from drug labels. Our deep learning approach entails composing various intermediate representations including sequence and graph based context, where the latter is derived using graph convolutions (GC) with a novel attention-based gating mechanism (holistically called GCA). These representations are then composed in meaningful ways to handle all subtasks jointly. To overcome scarcity in training data, we additionally propose transfer learning by pre-training on related DDI data. Our model is trained and evaluated on the 2018 TAC DDI corpus. Our GCA model in conjunction with transfer learning performs at 39.20% F1 and 26.09% F1 on entity recognition (ER) and relation extraction (RE) respectively on the first official test set and at 45.30% F1 and 27.87% F1 on ER and RE respectively on the second official test set corresponding to an improvement over our prior best results by up to 6 absolute F1 points. After controlling for available training data, our model exhibits state-of-the-art performance by improving over the next comparable best outcome by roughly three F1 points in ER and 1.5 F1 points in RE evaluation across two official test sets.
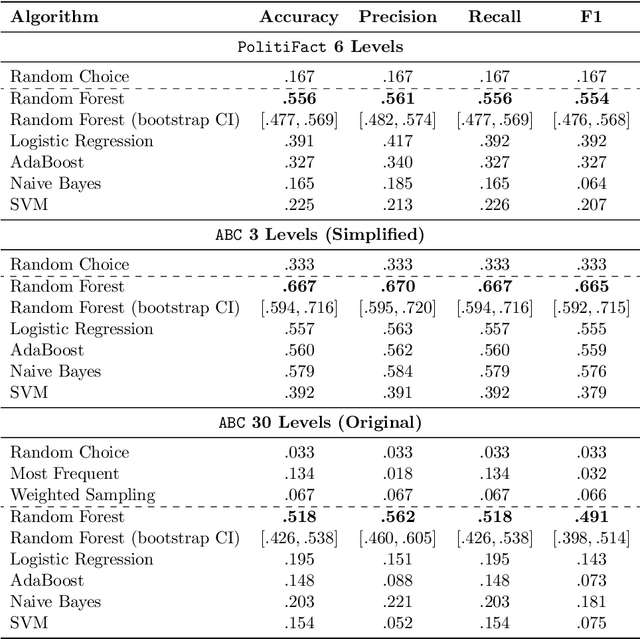
The Many Dimensions of Truthfulness: Crowdsourcing Misinformation Assessments on a Multidimensional Scale
Aug 23, 2021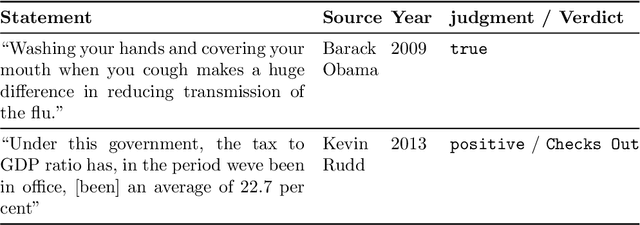
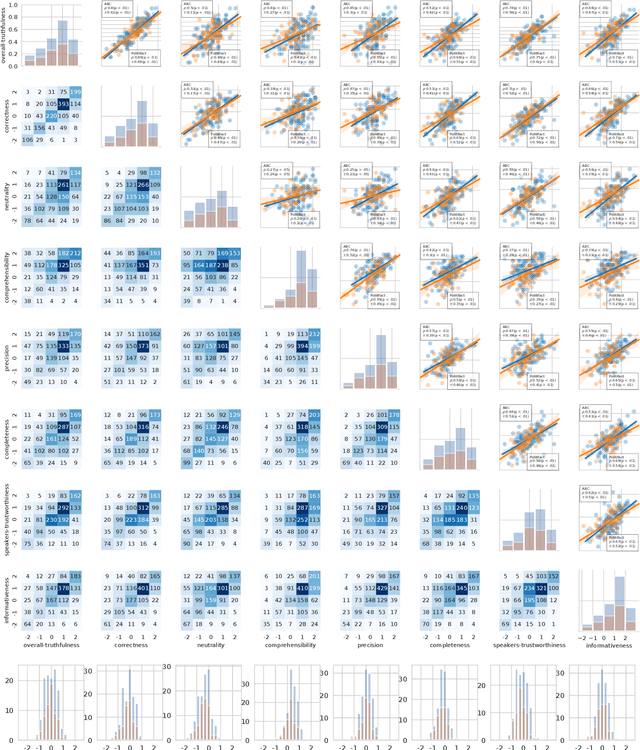
Recent work has demonstrated the viability of using crowdsourcing as a tool for evaluating the truthfulness of public statements. Under certain conditions such as: (1) having a balanced set of workers with different backgrounds and cognitive abilities; (2) using an adequate set of mechanisms to control the quality of the collected data; and (3) using a coarse grained assessment scale, the crowd can provide reliable identification of fake news. However, fake news are a subtle matter: statements can be just biased ("cherrypicked"), imprecise, wrong, etc. and the unidimensional truth scale used in existing work cannot account for such differences. In this paper we propose a multidimensional notion of truthfulness and we ask the crowd workers to assess seven different dimensions of truthfulness selected based on existing literature: Correctness, Neutrality, Comprehensibility, Precision, Completeness, Speaker's Trustworthiness, and Informativeness. We deploy a set of quality control mechanisms to ensure that the thousands of assessments collected on 180 publicly available fact-checked statements distributed over two datasets are of adequate quality, including a custom search engine used by the crowd workers to find web pages supporting their truthfulness assessments. A comprehensive analysis of crowdsourced judgments shows that: (1) the crowdsourced assessments are reliable when compared to an expert-provided gold standard; (2) the proposed dimensions of truthfulness capture independent pieces of information; (3) the crowdsourcing task can be easily learned by the workers; and (4) the resulting assessments provide a useful basis for a more complete estimation of statement truthfulness.
* 33 pages; Paper accepted at Information Processing & Management on July 28, 2021; IP&M Special Issue on Dis/Misinformation Mining from Social Media
Compression phase is not necessary for generalization in representation learning
Feb 15, 2021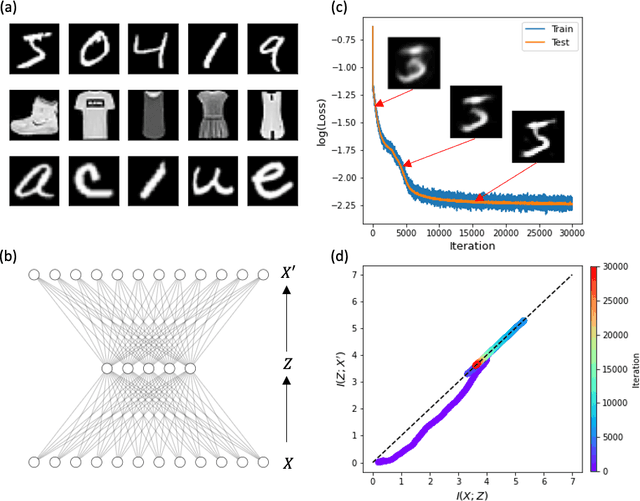
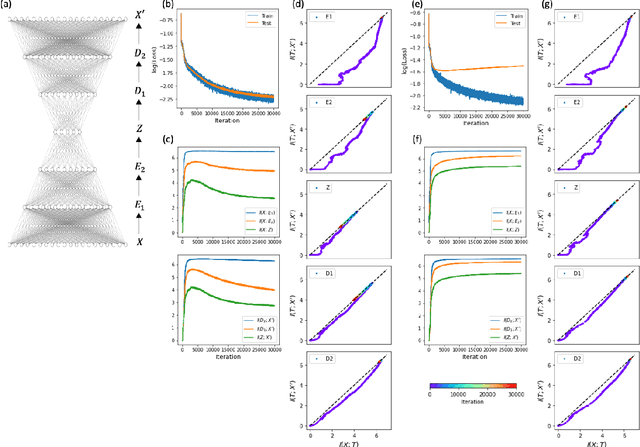
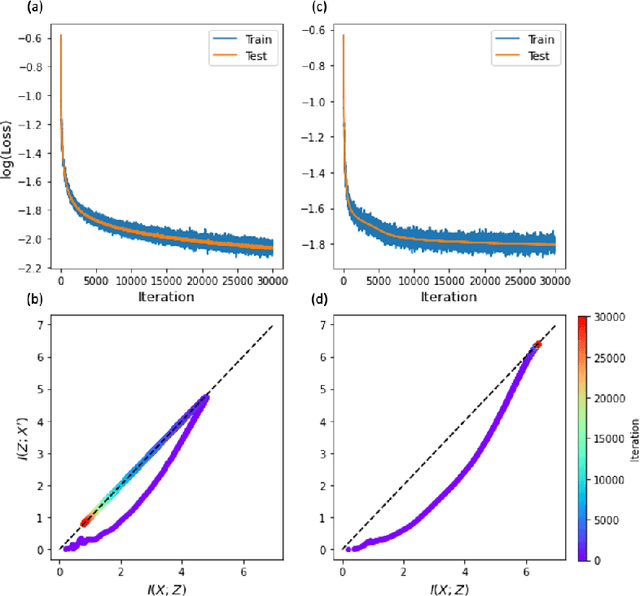
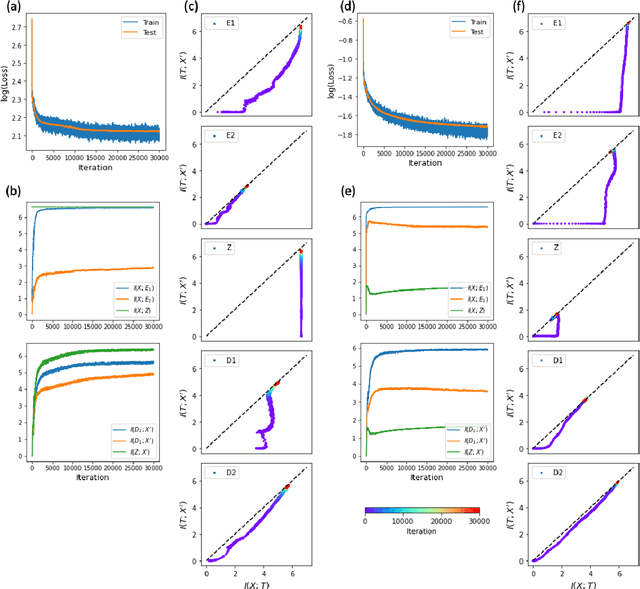
The outstanding performance of deep learning in various fields has been a fundamental query, which can be potentially examined using information theory that interprets the learning process as the transmission and compression of information. Information plane analyses of the mutual information between the input-hidden-output layers demonstrated two distinct learning phases of fitting and compression. It is debatable if the compression phase is necessary to generalize the input-output relations extracted from training data. In this study, we investigated this through experiments with various species of autoencoders and evaluated their information processing phase with an accurate kernel-based estimator of mutual information. Given sufficient training data, vanilla autoencoders demonstrated the compression phase, which was amplified after imposing sparsity regularization for hidden activities. However, we found that the compression phase is not universally observed in different species of autoencoders, including variational autoencoders, that have special constraints on network weights or manifold of hidden space. These types of autoencoders exhibited perfect generalization ability for test data without requiring the compression phase. Thus, we conclude that the compression phase is not necessary for generalization in representation learning.
Drone-based AI and 3D Reconstruction for Digital Twin Augmentation
May 20, 2021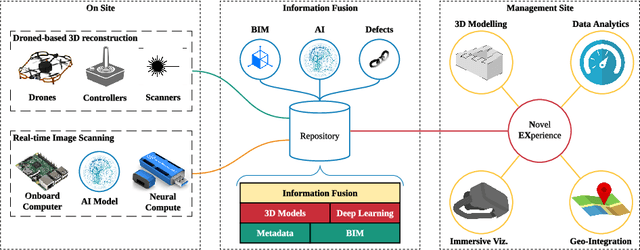
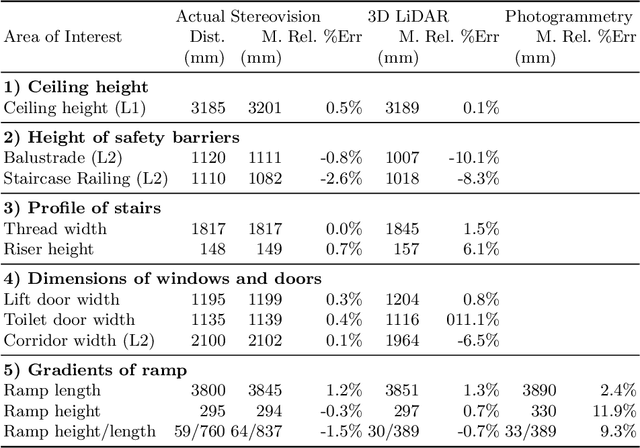


Digital Twin is an emerging technology at the forefront of Industry 4.0, with the ultimate goal of combining the physical space and the virtual space. To date, the Digital Twin concept has been applied in many engineering fields, providing useful insights in the areas of engineering design, manufacturing, automation, and construction industry. While the nexus of various technologies opens up new opportunities with Digital Twin, the technology requires a framework to integrate the different technologies, such as the Building Information Model used in the Building and Construction industry. In this work, an Information Fusion framework is proposed to seamlessly fuse heterogeneous components in a Digital Twin framework from the variety of technologies involved. This study aims to augment Digital Twin in buildings with the use of AI and 3D reconstruction empowered by unmanned aviation vehicles. We proposed a drone-based Digital Twin augmentation framework with reusable and customisable components. A proof of concept is also developed, and extensive evaluation is conducted for 3D reconstruction and applications of AI for defect detection.
Iterative, Deep, and Unsupervised Synthetic Aperture Sonar Image Segmentation
Jul 30, 2021
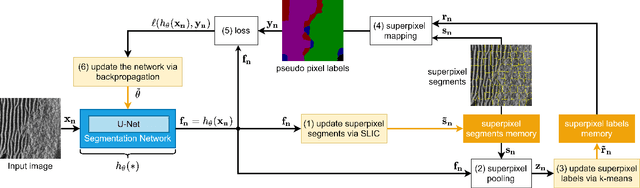
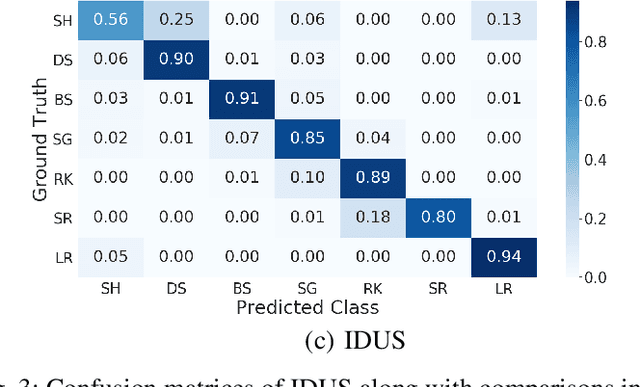
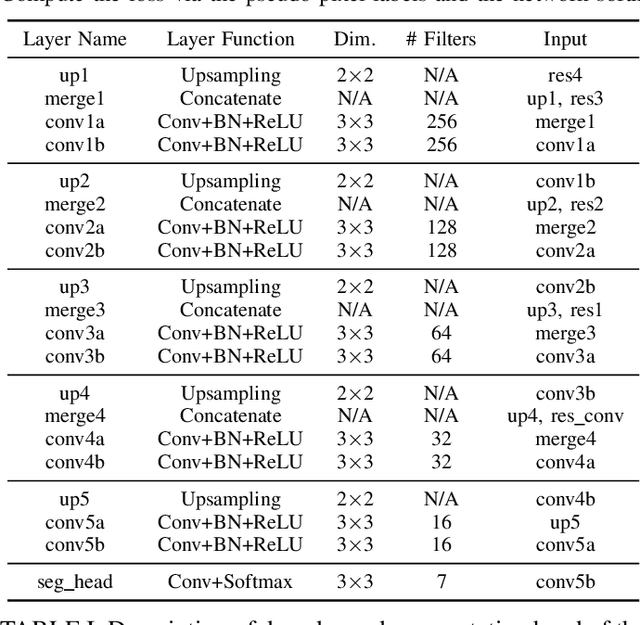
Deep learning has not been routinely employed for semantic segmentation of seabed environment for synthetic aperture sonar (SAS) imagery due to the implicit need of abundant training data such methods necessitate. Abundant training data, specifically pixel-level labels for all images, is usually not available for SAS imagery due to the complex logistics (e.g., diver survey, chase boat, precision position information) needed for obtaining accurate ground-truth. Many hand-crafted feature based algorithms have been proposed to segment SAS in an unsupervised fashion. However, there is still room for improvement as the feature extraction step of these methods is fixed. In this work, we present a new iterative unsupervised algorithm for learning deep features for SAS image segmentation. Our proposed algorithm alternates between clustering superpixels and updating the parameters of a convolutional neural network (CNN) so that the feature extraction for image segmentation can be optimized. We demonstrate the efficacy of our method on a realistic benchmark dataset. Our results show that the performance of our proposed method is considerably better than current state-of-the-art methods in SAS image segmentation.
Graph Trend Networks for Recommendations
Aug 12, 2021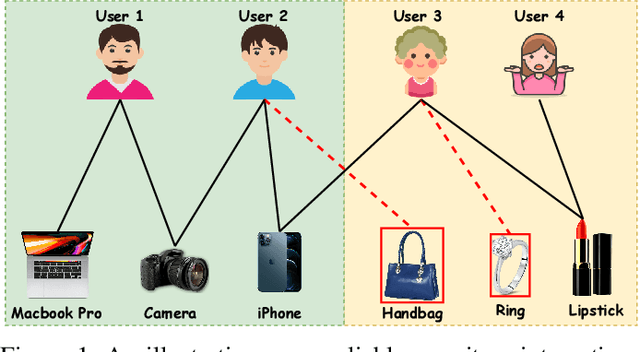
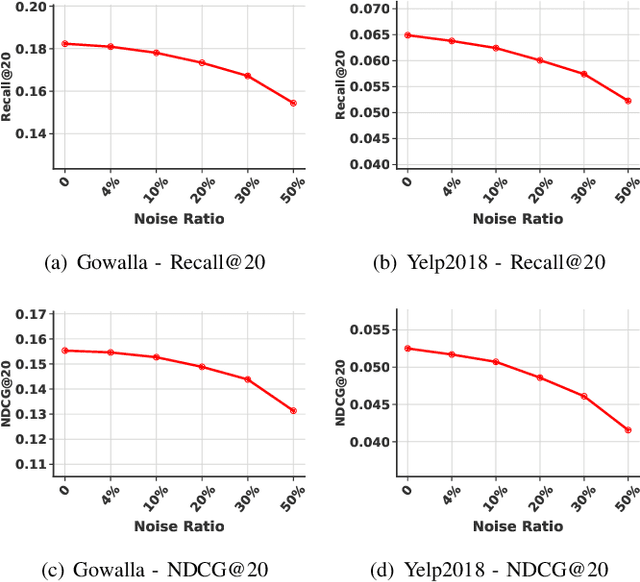
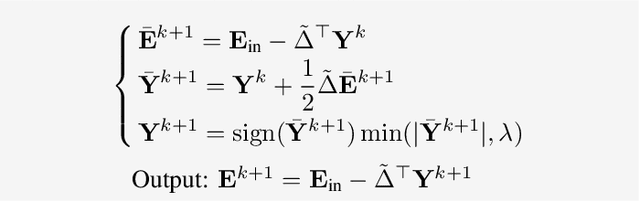
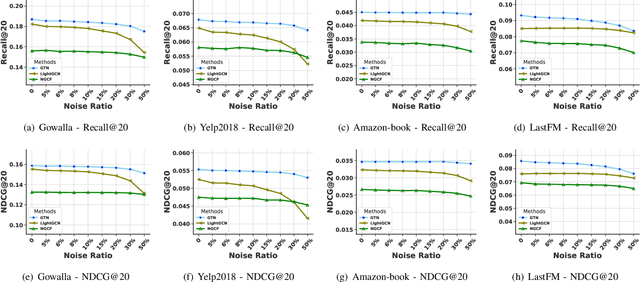
Recommender systems aim to provide personalized services to users and are playing an increasingly important role in our daily lives. The key of recommender systems is to predict how likely users will interact with items based on their historical online behaviors, e.g., clicks, add-to-cart, purchases, etc. To exploit these user-item interactions, there are increasing efforts on considering the user-item interactions as a user-item bipartite graph and then performing information propagation in the graph via Graph Neural Networks (GNNs). Given the power of GNNs in graph representation learning, these GNN-based recommendation methods have remarkably boosted the recommendation performance. Despite their success, most existing GNN-based recommender systems overlook the existence of interactions caused by unreliable behaviors (e.g., random/bait clicks) and uniformly treat all the interactions, which can lead to sub-optimal and unstable performance. In this paper, we investigate the drawbacks (e.g., non-adaptive propagation and non-robustness) of existing GNN-based recommendation methods. To address these drawbacks, we propose the Graph Trend Networks for recommendations (GTN) with principled designs that can capture the adaptive reliability of the interactions. Comprehensive experiments and ablation studies are presented to verify and understand the effectiveness of the proposed framework. Our implementation and datasets can be released after publication.