 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning from Matured Dumb Teacher for Fine Generalization
Aug 12, 2021
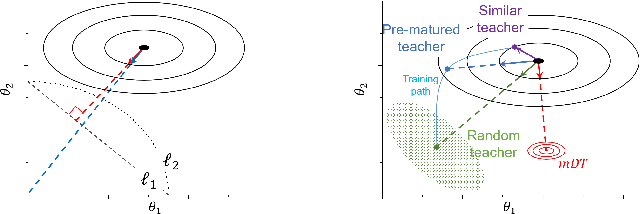
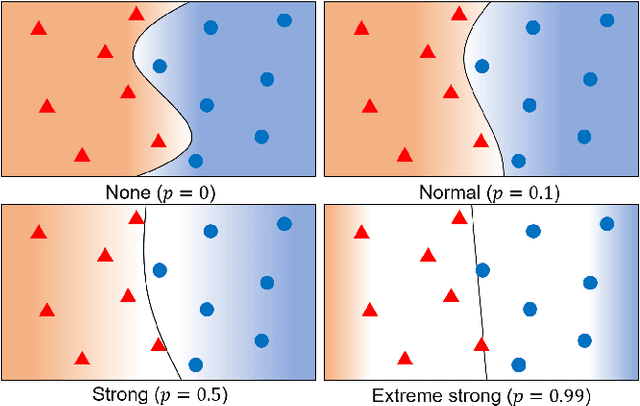
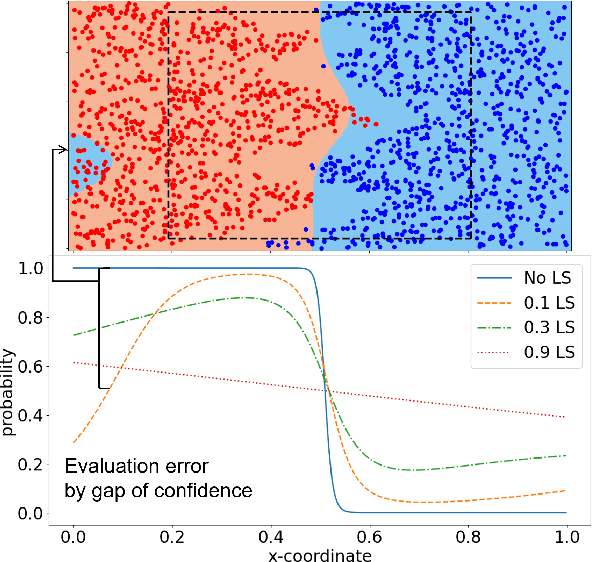
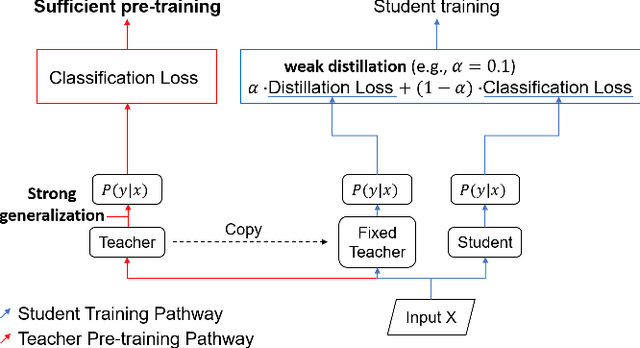
The flexibility of decision boundaries in neural networks that are unguided by training data is a well-known problem typically resolved with generalization methods. A surprising result from recent knowledge distillation (KD) literature is that random, untrained, and equally structured teacher networks can also vastly improve generalization performance. It raises the possibility of existence of undiscovered assumptions useful for generalization on an uncertain region. In this paper, we shed light on the assumptions by analyzing decision boundaries and confidence distributions of both simple and KD-based generalization methods. Assuming that a decision boundary exists to represent the most general tendency of distinction on an input sample space (i.e., the simplest hypothesis), we show the various limitations of methods when using the hypothesis. To resolve these limitations, we propose matured dumb teacher based KD, conservatively transferring the hypothesis for generalization of the student without massive destruction of trained information. In practical experiments on feed-forward and convolution neural networks for image classification tasks on MNIST, CIFAR-10, and CIFAR-100 datasets, the proposed method shows stable improvement to the best test performance in the grid search of hyperparameters. The analysis and results imply that the proposed method can provide finer generalization than existing methods.
HopfE: Knowledge Graph Representation Learning using Inverse Hopf Fibrations
Aug 12, 2021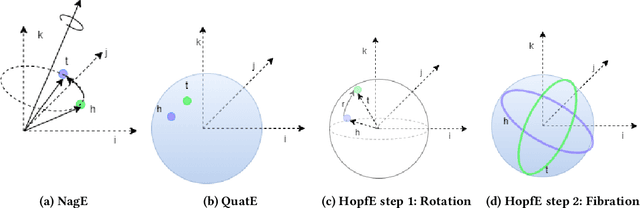

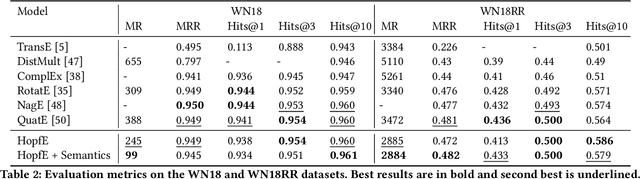
Recently, several Knowledge Graph Embedding (KGE) approaches have been devised to represent entities and relations in dense vector space and employed in downstream tasks such as link prediction. A few KGE techniques address interpretability, i.e., mapping the connectivity patterns of the relations (i.e., symmetric/asymmetric, inverse, and composition) to a geometric interpretation such as rotations. Other approaches model the representations in higher dimensional space such as four-dimensional space (4D) to enhance the ability to infer the connectivity patterns (i.e., expressiveness). However, modeling relation and entity in a 4D space often comes at the cost of interpretability. This paper proposes HopfE, a novel KGE approach aiming to achieve the interpretability of inferred relations in the four-dimensional space. We first model the structural embeddings in 3D Euclidean space and view the relation operator as an SO(3) rotation. Next, we map the entity embedding vector from a 3D space to a 4D hypersphere using the inverse Hopf Fibration, in which we embed the semantic information from the KG ontology. Thus, HopfE considers the structural and semantic properties of the entities without losing expressivity and interpretability. Our empirical results on four well-known benchmarks achieve state-of-the-art performance for the KG completion task.
Ultralow complexity long short-term memory network for fiber nonlinearity mitigation in coherent optical communication systems
Aug 12, 2021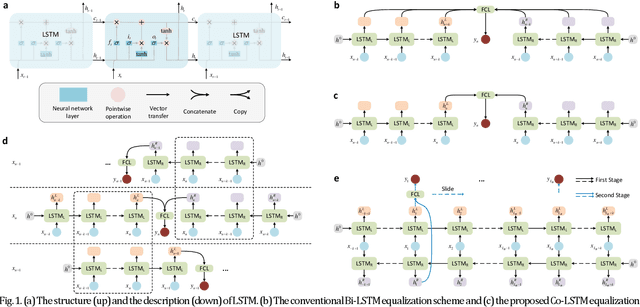
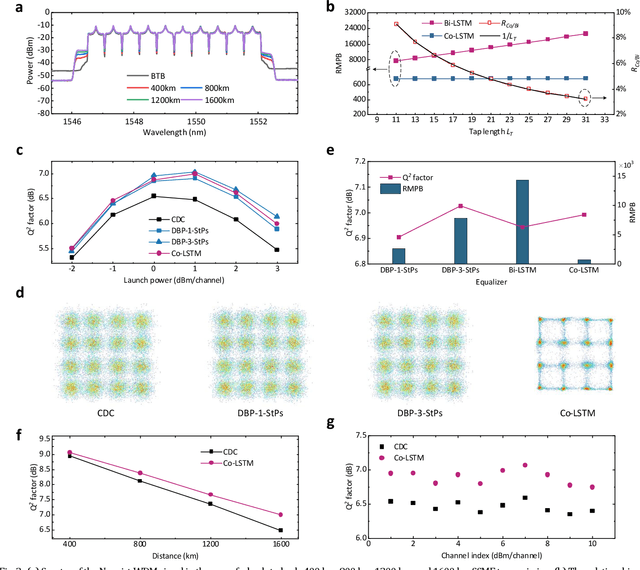
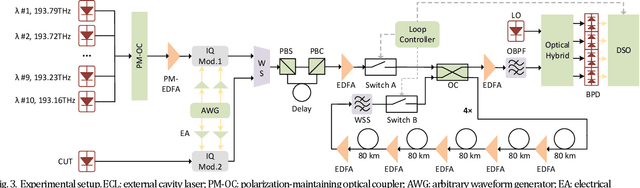
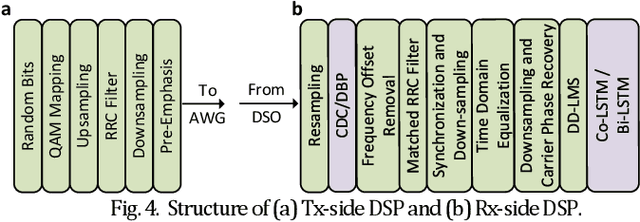
Fiber Kerr nonlinearity is a fundamental limitation to the achievable capacity of long-distance optical fiber communication. Digital back-propagation (DBP) is a primary methodology to mitigate both linear and nonlinear impairments by solving the inverse-propagating nonlinear Schr\"odinger equation (NLSE), which requires detailed link information. Recently, the paradigms based on neural network (NN) were proposed to mitigate nonlinear transmission impairments in optical communication systems. However, almost all neural network-based equalization schemes yield high computation complexity, which prevents the practical implementation in commercial transmission systems. In this paper, we propose a center-oriented long short-term memory network (Co-LSTM) incorporating a simplified mode with a recycling mechanism in the equalization operation, which can mitigate fiber nonlinearity in coherent optical communication systems with ultralow complexity. To validate the proposed methodology, we carry out an experiment of ten-channel wavelength division multiplexing (WDM) transmission with 64 Gbaud polarization-division-multiplexed 16-ary quadrature amplitude modulation (16-QAM) signals. Co-LSTM and DBP achieve a comparable performance of nonlinear mitigation. However, the complexity of Co-LSTM with a simplified mode is almost independent of the transmission distance, which is much lower than that of the DBP. The proposed Co-LSTM methodology presents an attractive approach for low complexity nonlinearity mitigation with neural networks.
A Unified Framework for Cross-Domain and Cross-System Recommendations
Aug 18, 2021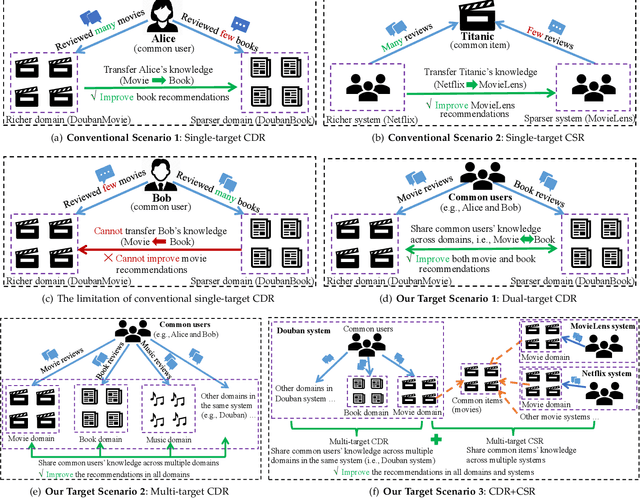

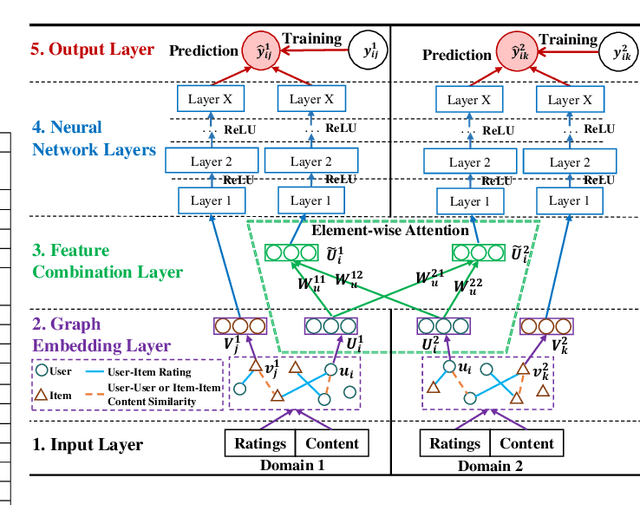
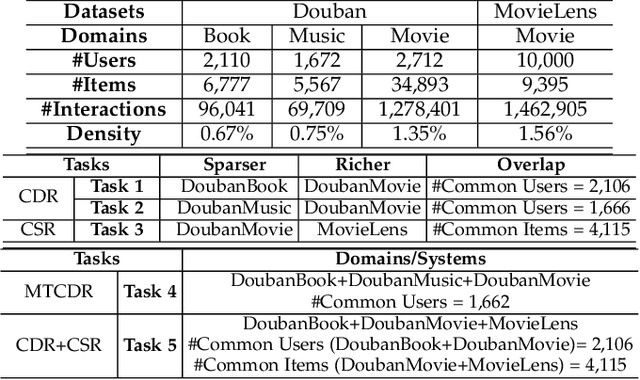
Cross-Domain Recommendation (CDR) and Cross-System Recommendation (CSR) have been proposed to improve the recommendation accuracy in a target dataset (domain/system) with the help of a source one with relatively richer information. However, most existing CDR and CSR approaches are single-target, namely, there is a single target dataset, which can only help the target dataset and thus cannot benefit the source dataset. In this paper, we focus on three new scenarios, i.e., Dual-Target CDR (DTCDR), Multi-Target CDR (MTCDR), and CDR+CSR, and aim to improve the recommendation accuracy in all datasets simultaneously for all scenarios. To do this, we propose a unified framework, called GA (based on Graph embedding and Attention techniques), for all three scenarios. In GA, we first construct separate heterogeneous graphs to generate more representative user and item embeddings. Then, we propose an element-wise attention mechanism to effectively combine the embeddings of common entities (users/items) learned from different datasets. Moreover, to avoid negative transfer, we further propose a Personalized training strategy to minimize the embedding difference of common entities between a richer dataset and a sparser dataset, deriving three new models, i.e., GA-DTCDR-P, GA-MTCDR-P, and GA-CDR+CSR-P, for the three scenarios respectively. Extensive experiments conducted on four real-world datasets demonstrate that our proposed GA models significantly outperform the state-of-the-art approaches.
Identifiable Energy-based Representations: An Application to Estimating Heterogeneous Causal Effects
Aug 06, 2021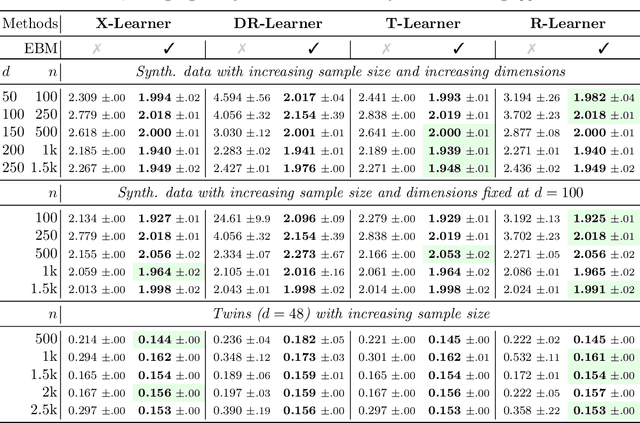
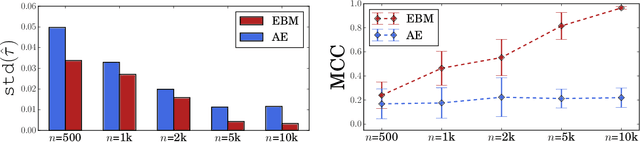
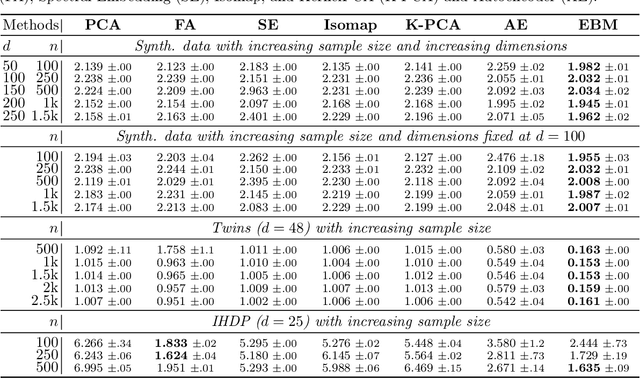
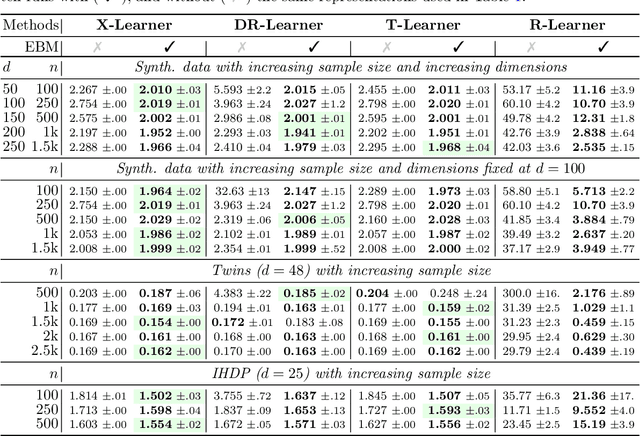
Conditional average treatment effects (CATEs) allow us to understand the effect heterogeneity across a large population of individuals. However, typical CATE learners assume all confounding variables are measured in order for the CATE to be identifiable. Often, this requirement is satisfied by simply collecting many variables, at the expense of increased sample complexity for estimating CATEs. To combat this, we propose an energy-based model (EBM) that learns a low-dimensional representation of the variables by employing a noise contrastive loss function. With our EBM we introduce a preprocessing step that alleviates the dimensionality curse for any existing model and learner developed for estimating CATE. We prove that our EBM keeps the representations partially identifiable up to some universal constant, as well as having universal approximation capability to avoid excessive information loss from model misspecification; these properties combined with our loss function, enable the representations to converge and keep the CATE estimation consistent. Experiments demonstrate the convergence of the representations, as well as show that estimating CATEs on our representations performs better than on the variables or the representations obtained via various benchmark dimensionality reduction methods.
Training Group Orthogonal Neural Networks with Privileged Information
Aug 18, 2017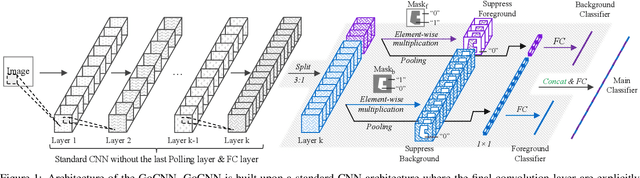


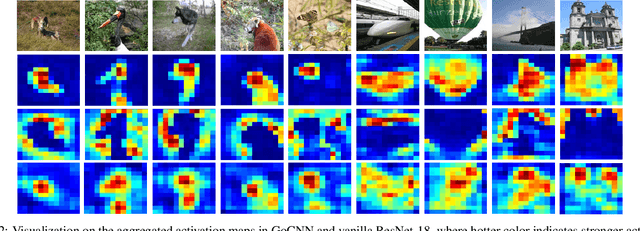
Learning rich and diverse representations is critical for the performance of deep convolutional neural networks (CNNs). In this paper, we consider how to use privileged information to promote inherent diversity of a single CNN model such that the model can learn better representations and offer stronger generalization ability. To this end, we propose a novel group orthogonal convolutional neural network (GoCNN) that learns untangled representations within each layer by exploiting provided privileged information and enhances representation diversity effectively. We take image classification as an example where image segmentation annotations are used as privileged information during the training process. Experiments on two benchmark datasets -- ImageNet and PASCAL VOC -- clearly demonstrate the strong generalization ability of our proposed GoCNN model. On the ImageNet dataset, GoCNN improves the performance of state-of-the-art ResNet-152 model by absolute value of 1.2% while only uses privileged information of 10% of the training images, confirming effectiveness of GoCNN on utilizing available privileged knowledge to train better CNNs.
Autonomous Cooperative Multi-Vehicle System for Interception of Aerial and Stationary Targets in Unknown Environments
Sep 01, 2021This paper presents the design, development, and testing of hardware-software systems by the IISc-TCS team for Challenge 1 of the Mohammed Bin Zayed International Robotics Challenge 2020. The goal of Challenge 1 was to grab a ball suspended from a moving and maneuvering UAV and pop balloons anchored to the ground, using suitable manipulators. The important tasks carried out to address this challenge include the design and development of a hardware system with efficient grabbing and popping mechanisms, considering the restrictions in volume and payload, design of accurate target interception algorithms using visual information suitable for outdoor environments, and development of a software architecture for dynamic multi-agent aerial systems performing complex dynamic missions. In this paper, a single degree of freedom manipulator attached with an end-effector is designed for grabbing and popping, and robust algorithms are developed for the interception of targets in an uncertain environment. Vision-based guidance and tracking laws are proposed based on the concept of pursuit engagement and artificial potential function. The software architecture presented in this work proposes an Operation Management System (OMS) architecture that allocates static and dynamic tasks collaboratively among multiple UAVs to perform any given mission. An important aspect of this work is that all the systems developed were designed to operate in completely autonomous mode. A detailed description of the architecture along with simulations of complete challenge in the Gazebo environment and field experiment results are also included in this work. The proposed hardware-software system is particularly useful for counter-UAV systems and can also be modified in order to cater to several other applications.
Introducing: DeepHead, Wide-band Electromagnetic Imaging Paradigm
Jul 23, 2021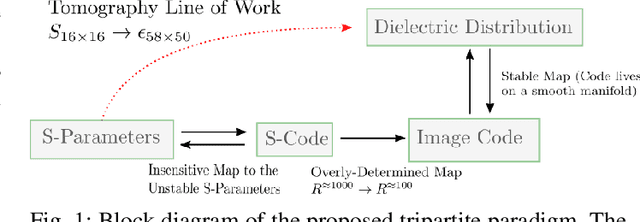
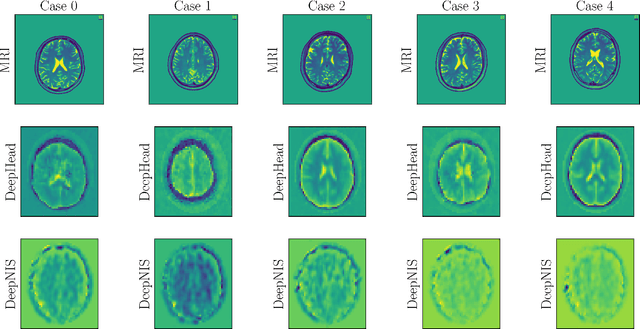

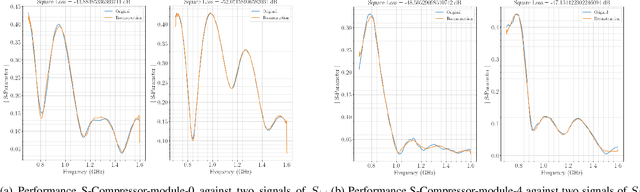
Electromagnetic medical imaging in the microwave regime is a hard problem notorious for 1) instability 2) under-determinism. This two-pronged problem is tackled with a two-pronged solution that uses double compression to maximally utilizing the cheap unlabelled data to a) provide a priori information required to ease under-determinism and b) reduce sensitivity of inference to the input. The result is a stable solver with a high resolution output. DeepHead is a fully data-driven implementation of the paradigm proposed in the context of microwave brain imaging. It infers the dielectric distribution of the brain at a desired single frequency while making use of an input that spreads over a wide band of frequencies. The performance of the model is evaluated with both simulations and human volunteers experiments. The inference made is juxtaposed with ground-truth dielectric distribution in simulation case, and the golden MRI / CT imaging modalities of the volunteers in real-world case.
* Under review, major revision
Computational complexity of Inexact Proximal Point Algorithm for Convex Optimization under Holderian Growth
Aug 12, 2021
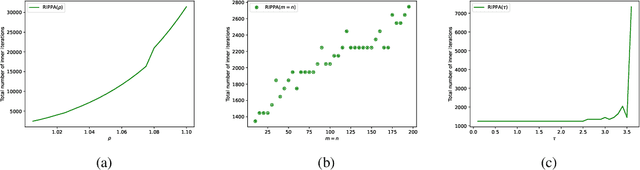
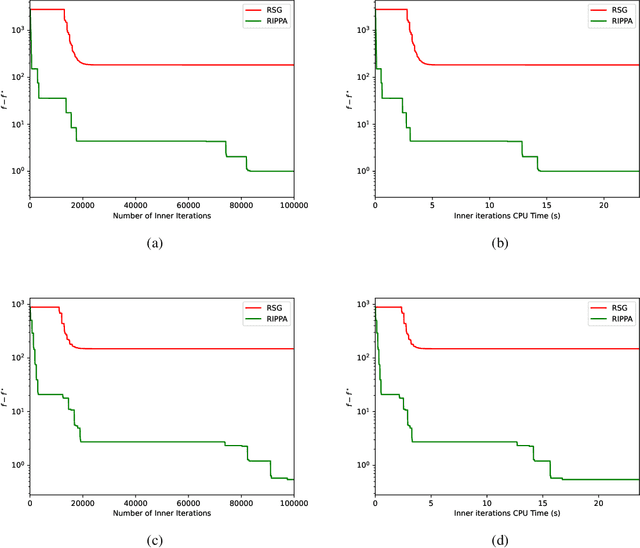
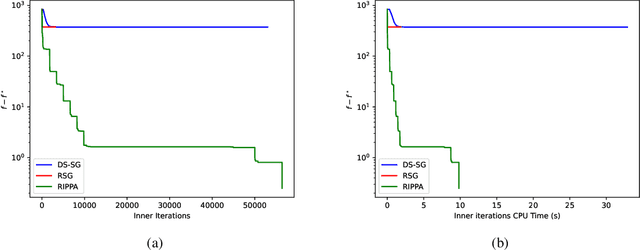
\noindent Several decades ago the Proximal Point Algorithm (PPA) stated to gain a long-lasting attraction for both abstract operator theory and numerical optimization communities. Even in modern applications, researchers still use proximal minimization theory to design scalable algorithms that overcome nonsmoothness. Remarkable works as \cite{Fer:91,Ber:82constrained,Ber:89parallel,Tom:11} established tight relations between the convergence behaviour of PPA and the regularity of the objective function. In this manuscript we derive nonasymptotic iteration complexity of exact and inexact PPA to minimize convex functions under $\gamma-$Holderian growth: $\BigO{\log(1/\epsilon)}$ (for $\gamma \in [1,2]$) and $\BigO{1/\epsilon^{\gamma - 2}}$ (for $\gamma > 2$). In particular, we recover well-known results on PPA: finite convergence for sharp minima and linear convergence for quadratic growth, even under presence of inexactness. However, without taking into account the concrete computational effort paid for computing each PPA iteration, any iteration complexity remains abstract and purely informative. Therefore, using an inner (proximal) gradient/subgradient method subroutine that computes inexact PPA iteration, we secondly show novel computational complexity bounds on a restarted inexact PPA, available when no information on the growth of the objective function is known. In the numerical experiments we confirm the practical performance and implementability of our framework.
SSAN: Separable Self-Attention Network for Video Representation Learning
May 27, 2021
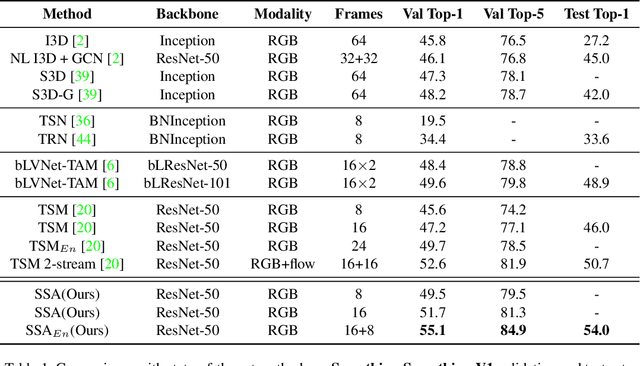
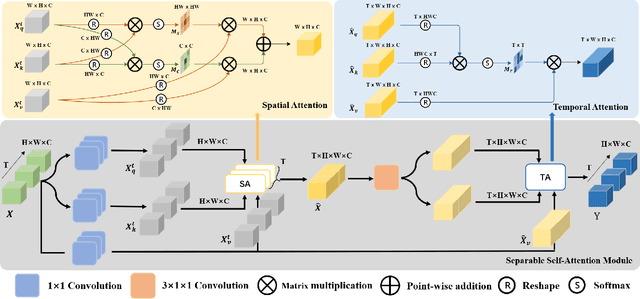
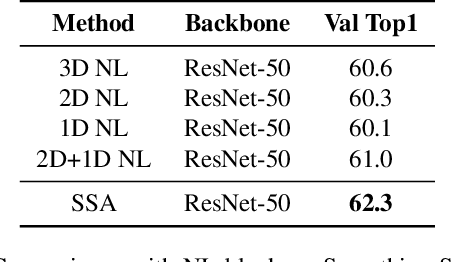
Self-attention has been successfully applied to video representation learning due to the effectiveness of modeling long range dependencies. Existing approaches build the dependencies merely by computing the pairwise correlations along spatial and temporal dimensions simultaneously. However, spatial correlations and temporal correlations represent different contextual information of scenes and temporal reasoning. Intuitively, learning spatial contextual information first will benefit temporal modeling. In this paper, we propose a separable self-attention (SSA) module, which models spatial and temporal correlations sequentially, so that spatial contexts can be efficiently used in temporal modeling. By adding SSA module into 2D CNN, we build a SSA network (SSAN) for video representation learning. On the task of video action recognition, our approach outperforms state-of-the-art methods on Something-Something and Kinetics-400 datasets. Our models often outperform counterparts with shallower network and fewer modalities. We further verify the semantic learning ability of our method in visual-language task of video retrieval, which showcases the homogeneity of video representations and text embeddings. On MSR-VTT and Youcook2 datasets, video representations learnt by SSA significantly improve the state-of-the-art performance.