 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Distilling Object Detectors via Decoupled Features
Mar 26, 2021
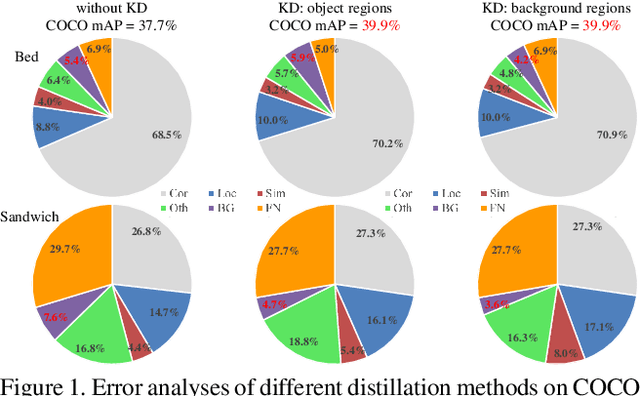
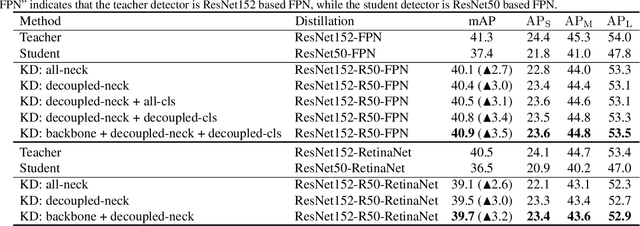

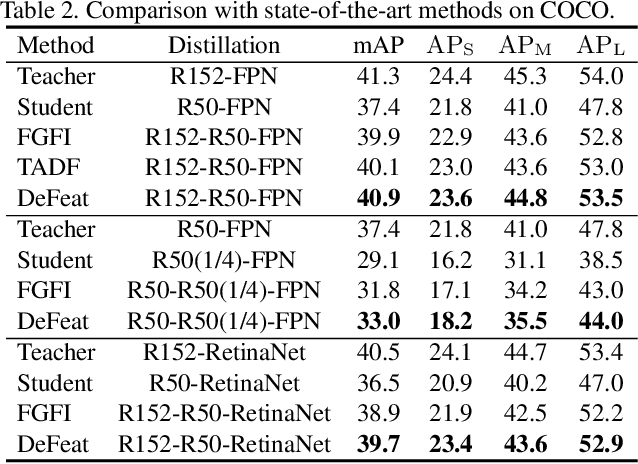
Knowledge distillation is a widely used paradigm for inheriting information from a complicated teacher network to a compact student network and maintaining the strong performance. Different from image classification, object detectors are much more sophisticated with multiple loss functions in which features that semantic information rely on are tangled. In this paper, we point out that the information of features derived from regions excluding objects are also essential for distilling the student detector, which is usually ignored in existing approaches. In addition, we elucidate that features from different regions should be assigned with different importance during distillation. To this end, we present a novel distillation algorithm via decoupled features (DeFeat) for learning a better student detector. Specifically, two levels of decoupled features will be processed for embedding useful information into the student, i.e., decoupled features from neck and decoupled proposals from classification head. Extensive experiments on various detectors with different backbones show that the proposed DeFeat is able to surpass the state-of-the-art distillation methods for object detection. For example, DeFeat improves ResNet50 based Faster R-CNN from 37.4% to 40.9% mAP, and improves ResNet50 based RetinaNet from 36.5% to 39.7% mAP on COCO benchmark. Our implementation is available at https://github.com/ggjy/DeFeat.pytorch.
Exploiting user-frequency information for mining regionalisms from Social Media texts
Jul 10, 2019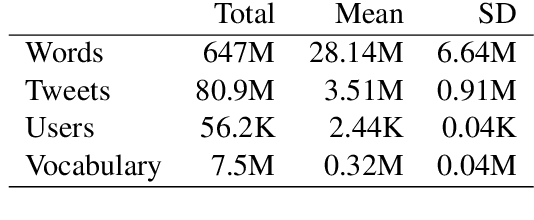
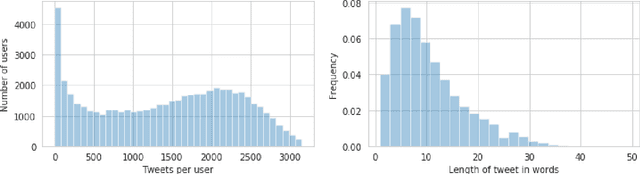

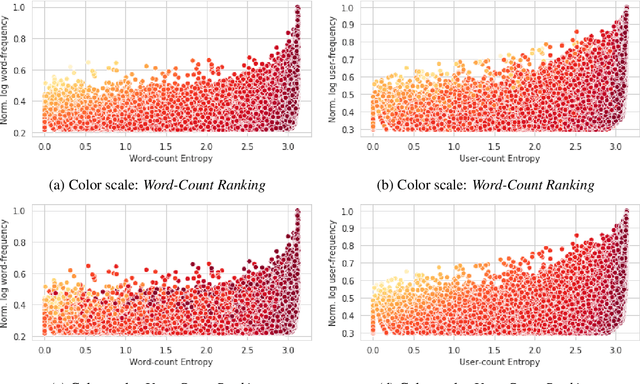
The task of detecting regionalisms (expressions or words used in certain regions) has traditionally relied on the use of questionnaires and surveys, and has also heavily depended on the expertise and intuition of the surveyor. The irruption of Social Media and its microblogging services has produced an unprecedented wealth of content, mainly informal text generated by users, opening new opportunities for linguists to extend their studies of language variation. Previous work on automatic detection of regionalisms depended mostly on word frequencies. In this work, we present a novel metric based on Information Theory that incorporates user frequency. We tested this metric on a corpus of Argentinian Spanish tweets in two ways: via manual annotation of the relevance of the retrieved terms, and also as a feature selection method for geolocation of users. In either case, our metric outperformed other techniques based solely in word frequency, suggesting that measuring the amount of users that produce a word is informative. This tool has helped lexicographers discover several unregistered words of Argentinian Spanish, as well as different meanings assigned to registered words.
Inference on Auctions with Weak Assumptions on Information
Mar 19, 2018
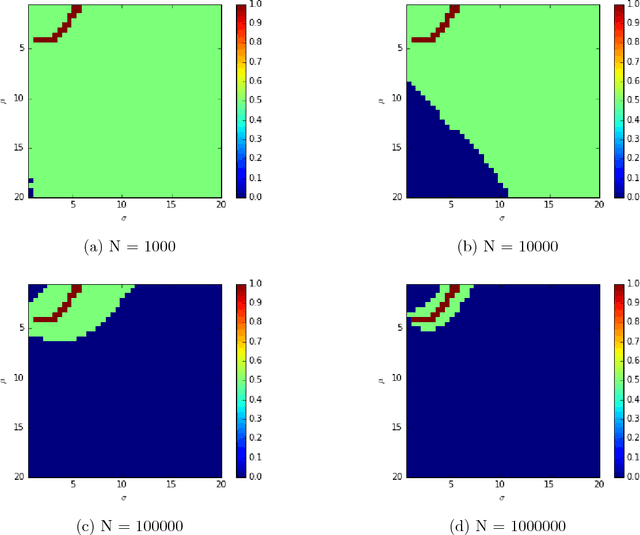
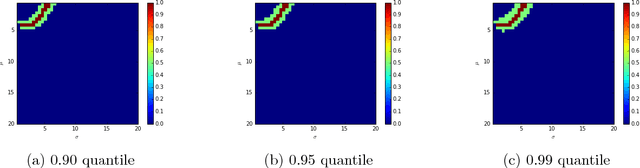
Given a sample of bids from independent auctions, this paper examines the question of inference on auction fundamentals (e.g. valuation distributions, welfare measures) under weak assumptions on information structure. The question is important as it allows us to learn about the valuation distribution in a robust way, i.e., without assuming that a particular information structure holds across observations. We leverage the recent contributions of \cite{Bergemann2013} in the robust mechanism design literature that exploit the link between Bayesian Correlated Equilibria and Bayesian Nash Equilibria in incomplete information games to construct an econometrics framework for learning about auction fundamentals using observed data on bids. We showcase our construction of identified sets in private value and common value auctions. Our approach for constructing these sets inherits the computational simplicity of solving for correlated equilibria: checking whether a particular valuation distribution belongs to the identified set is as simple as determining whether a {\it linear} program is feasible. A similar linear program can be used to construct the identified set on various welfare measures and counterfactual objects. For inference and to summarize statistical uncertainty, we propose novel finite sample methods using tail inequalities that are used to construct confidence regions on sets. We also highlight methods based on Bayesian bootstrap and subsampling. A set of Monte Carlo experiments show adequate finite sample properties of our inference procedures. We illustrate our methods using data from OCS auctions.
AnaXNet: Anatomy Aware Multi-label Finding Classification in Chest X-ray
May 20, 2021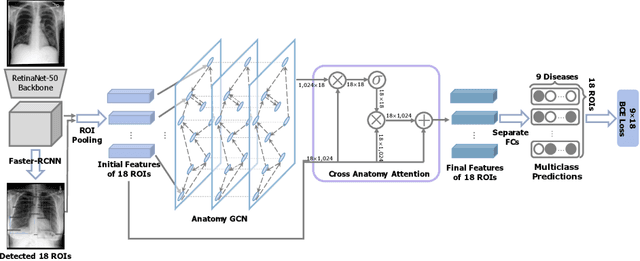
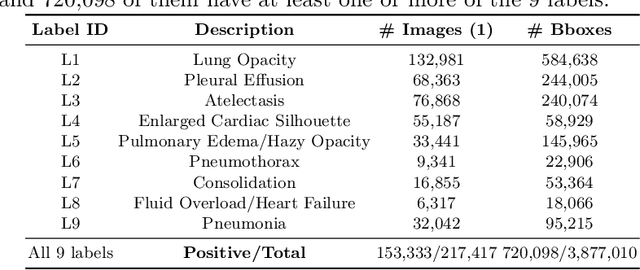
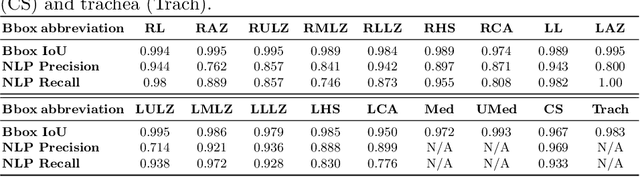
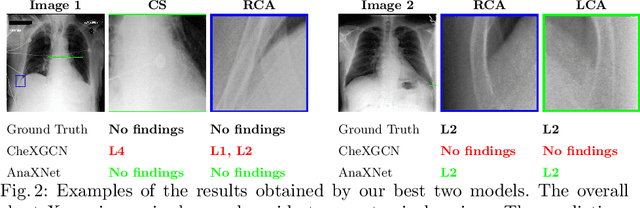
Radiologists usually observe anatomical regions of chest X-ray images as well as the overall image before making a decision. However, most existing deep learning models only look at the entire X-ray image for classification, failing to utilize important anatomical information. In this paper, we propose a novel multi-label chest X-ray classification model that accurately classifies the image finding and also localizes the findings to their correct anatomical regions. Specifically, our model consists of two modules, the detection module and the anatomical dependency module. The latter utilizes graph convolutional networks, which enable our model to learn not only the label dependency but also the relationship between the anatomical regions in the chest X-ray. We further utilize a method to efficiently create an adjacency matrix for the anatomical regions using the correlation of the label across the different regions. Detailed experiments and analysis of our results show the effectiveness of our method when compared to the current state-of-the-art multi-label chest X-ray image classification methods while also providing accurate location information.
Gait analysis with curvature maps: A simulation study
Jun 22, 2021

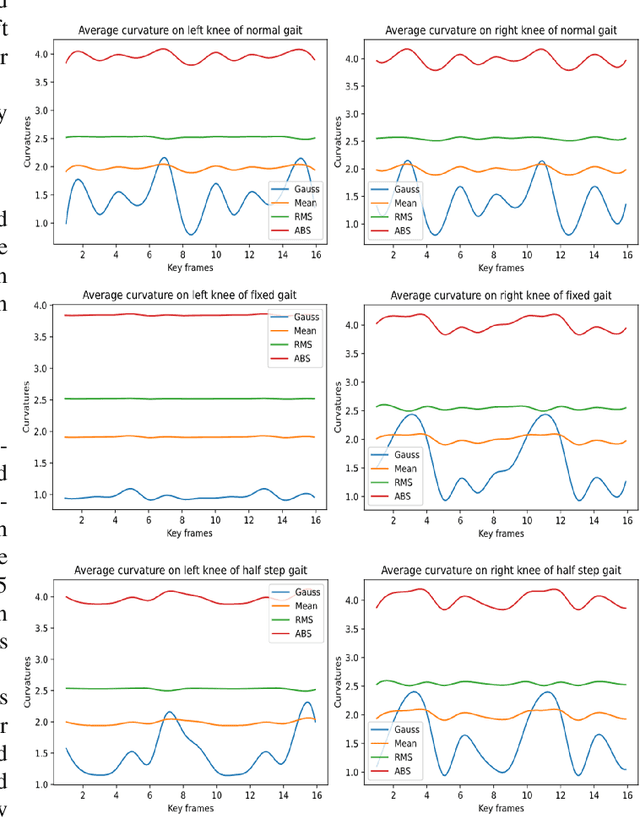
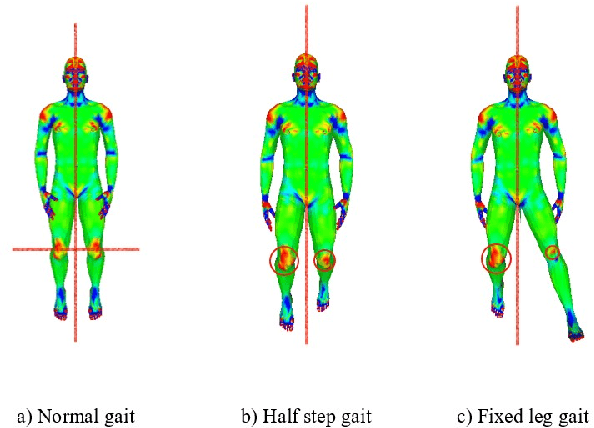
Gait analysis is an important aspect of clinical investigation for detecting neurological and musculoskeletal disorders and assessing the global health of a patient. In this paper we propose to focus our attention on extracting relevant curvature information from the body surface provided by a depth camera. We assumed that the 3D mesh was made available in a previous step and demonstrated how curvature maps could be useful to assess asymmetric anomalies with two simple simulated abnormal gaits compared with a normal one. This research set the grounds for the future development of a curvature-based gait analysis system for healthcare professionals.
A Realistic Simulation Framework for Learning with Label Noise
Jul 23, 2021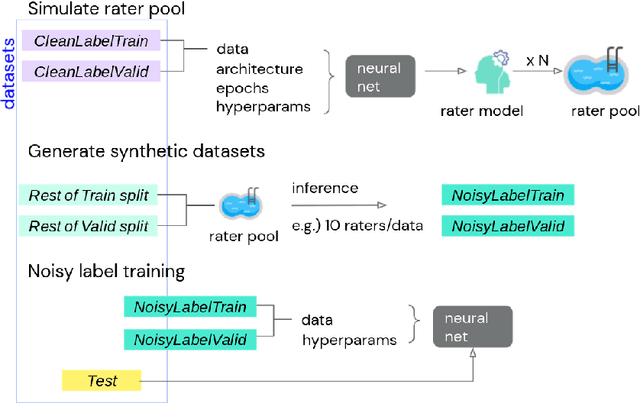
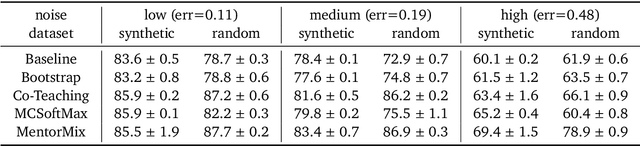
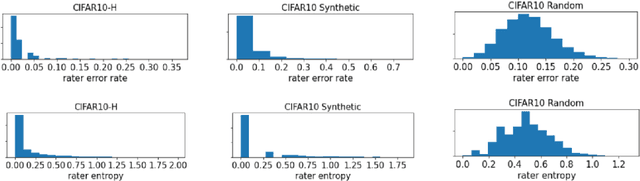
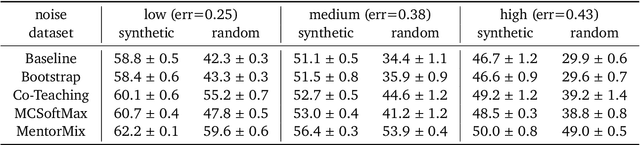
We propose a simulation framework for generating realistic instance-dependent noisy labels via a pseudo-labeling paradigm. We show that this framework generates synthetic noisy labels that exhibit important characteristics of the label noise in practical settings via comparison with the CIFAR10-H dataset. Equipped with controllable label noise, we study the negative impact of noisy labels across a few realistic settings to understand when label noise is more problematic. We also benchmark several existing algorithms for learning with noisy labels and compare their behavior on our synthetic datasets and on the datasets with independent random label noise. Additionally, with the availability of annotator information from our simulation framework, we propose a new technique, Label Quality Model (LQM), that leverages annotator features to predict and correct against noisy labels. We show that by adding LQM as a label correction step before applying existing noisy label techniques, we can further improve the models' performance.
A Generalized Space-Frequency Index Modulation Scheme for Downlink MIMO Transmissions with Improved Diversity
Aug 06, 2021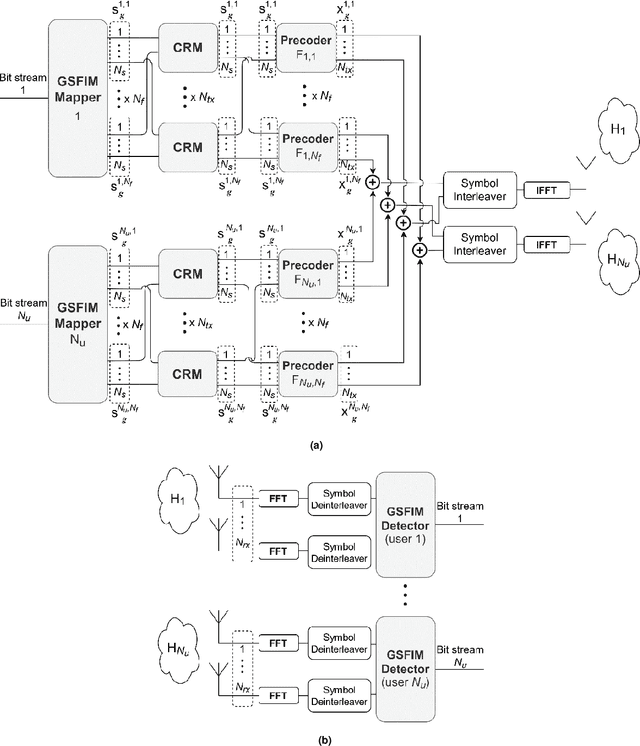
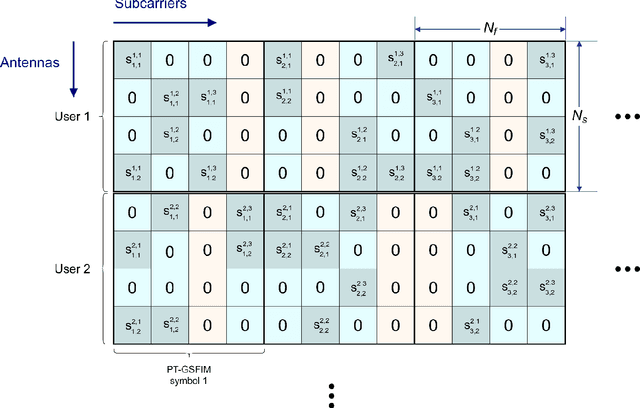
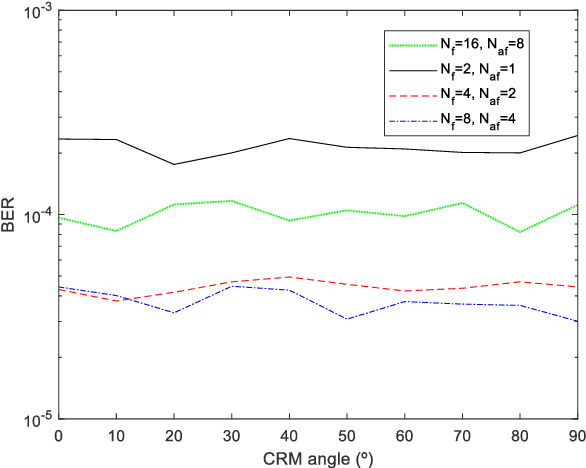
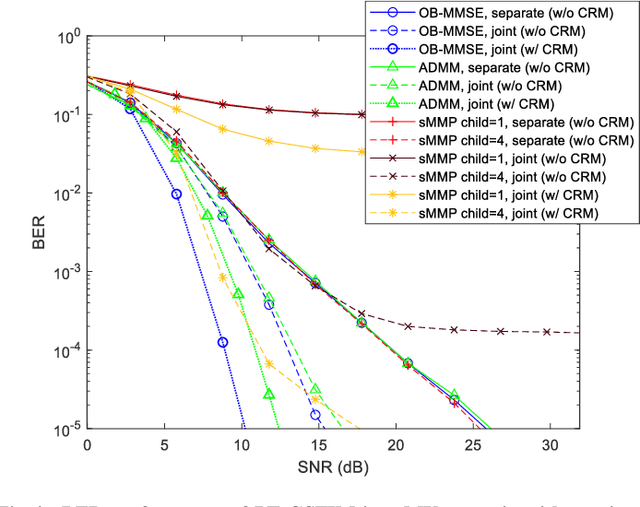
Multidimensional Index Modulations (IM) are a novel alternative to conventional modulations which can bring considerable benefits for future wireless networks. Within this scope, in this paper we present a new scheme, named as Precoding-aided Transmitter side Generalized Space-Frequency Index Modulation (PT-GSFIM), where part of the information bits select the active antennas and subcarriers which then carry amplitude and phase modulated symbols. The proposed scheme is designed for multiuser multiple-input multiple-output (MU-MIMO) scenarios and incorporates a precoder which removes multiuser interference (MUI) at the receivers. Furthermore, the proposed PT-GSFIM also integrates signal space diversity (SSD) techniques for tackling the typical poor performance of uncoded orthogonal frequency division multiplexing (OFDM) based schemes. By combining complex rotation matrices (CRM) and subcarrier-level interleaving, PT-GSFIM can exploit the inherent diversity in frequency selective channels and improve the performance without additional power or bandwidth. To support reliable detection of the multidimensional PT-GSFIM we also propose three different detection algorithms which can provide different tradeoffs between performance and complexity. Simulation results shows that proposed PT-GSFIM scheme, can provide significant gains over conventional MU-MIMO and GSM schemes.
EmoDNN: Understanding emotions from short texts through a deep neural network ensemble
Jun 03, 2021

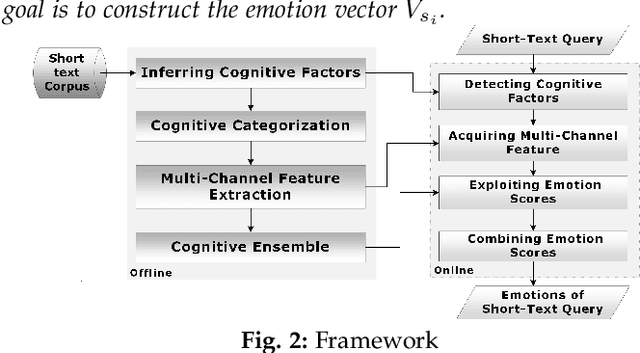
The latent knowledge in the emotions and the opinions of the individuals that are manifested via social networks are crucial to numerous applications including social management, dynamical processes, and public security. Affective computing, as an interdisciplinary research field, linking artificial intelligence to cognitive inference, is capable to exploit emotion-oriented knowledge from brief contents. The textual contents convey hidden information such as personality and cognition about corresponding authors that can determine both correlations and variations between users. Emotion recognition from brief contents should embrace the contrast between authors where the differences in personality and cognition can be traced within emotional expressions. To tackle this challenge, we devise a framework that, on the one hand, infers latent individual aspects, from brief contents and, on the other hand, presents a novel ensemble classifier equipped with dynamic dropout convnets to extract emotions from textual context. To categorize short text contents, our proposed method conjointly leverages cognitive factors and exploits hidden information. We utilize the outcome vectors in a novel embedding model to foster emotion-pertinent features that are collectively assembled by lexicon inductions. Experimental results show that compared to other competitors, our proposed model can achieve a higher performance in recognizing emotion from noisy contents.
ST-PCNN: Spatio-Temporal Physics-Coupled Neural Networks for Dynamics Forecasting
Aug 12, 2021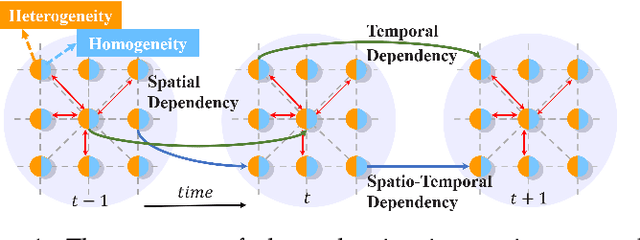

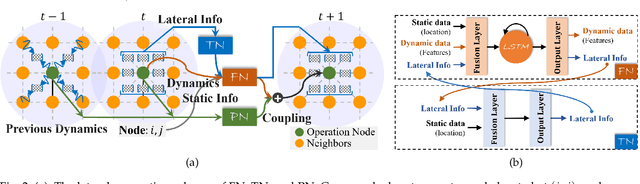
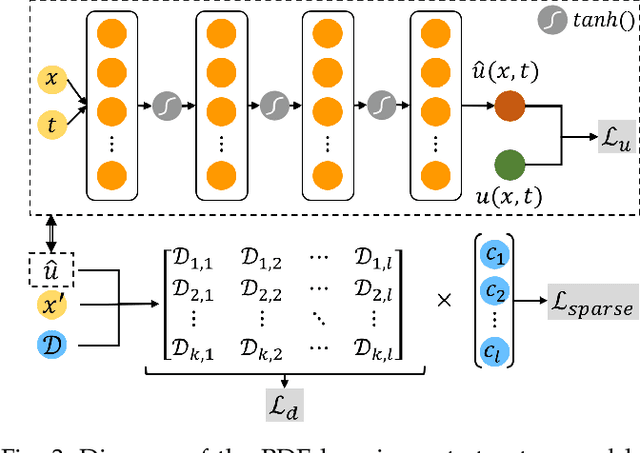
Ocean current, fluid mechanics, and many other spatio-temporal physical dynamical systems are essential components of the universe. One key characteristic of such systems is that certain physics laws -- represented as ordinary/partial differential equations (ODEs/PDEs) -- largely dominate the whole process, irrespective of time or location. Physics-informed learning has recently emerged to learn physics for accurate prediction, but they often lack a mechanism to leverage localized spatial and temporal correlation or rely on hard-coded physics parameters. In this paper, we advocate a physics-coupled neural network model to learn parameters governing the physics of the system, and further couple the learned physics to assist the learning of recurring dynamics. A spatio-temporal physics-coupled neural network (ST-PCNN) model is proposed to achieve three goals: (1) learning the underlying physics parameters, (2) transition of local information between spatio-temporal regions, and (3) forecasting future values for the dynamical system. The physics-coupled learning ensures that the proposed model can be tremendously improved by using learned physics parameters, and can achieve good long-range forecasting (e.g., more than 30-steps). Experiments, using simulated and field-collected ocean current data, validate that ST-PCNN outperforms existing physics-informed models.
Page-level Optimization of e-Commerce Item Recommendations
Aug 12, 2021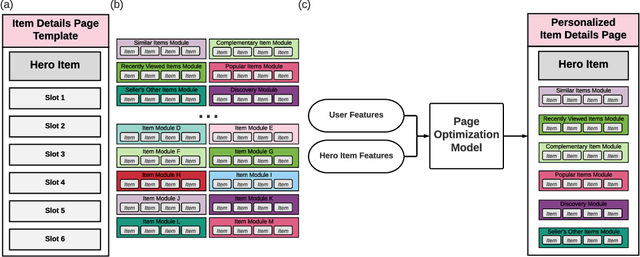

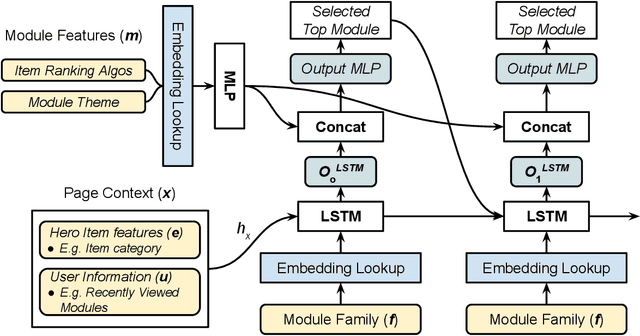

The item details page (IDP) is a web page on an e-commerce website that provides information on a specific product or item listing. Just below the details of the item on this page, the buyer can usually find recommendations for other relevant items. These are typically in the form of a series of modules or carousels, with each module containing a set of recommended items. The selection and ordering of these item recommendation modules are intended to increase discover-ability of relevant items and encourage greater user engagement, while simultaneously showcasing diversity of inventory and satisfying other business objectives. Item recommendation modules on the IDP are often curated and statically configured for all customers, ignoring opportunities for personalization. In this paper, we present a scalable end-to-end production system to optimize the personalized selection and ordering of item recommendation modules on the IDP in real-time by utilizing deep neural networks. Through extensive offline experimentation and online A/B testing, we show that our proposed system achieves significantly higher click-through and conversion rates compared to other existing methods. In our online A/B test, our framework improved click-through rate by 2.48% and purchase-through rate by 7.34% over a static configuration.