 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Dynamic Prediction Model for NOx Emission of SCR System Based on Hybrid Data-driven Algorithms
Aug 03, 2021
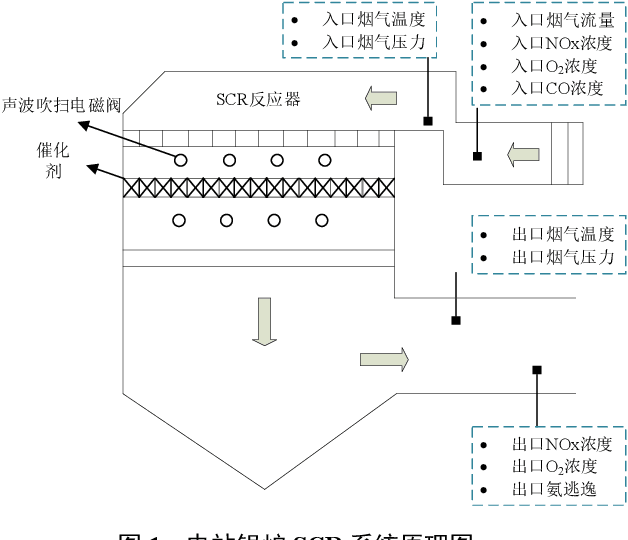
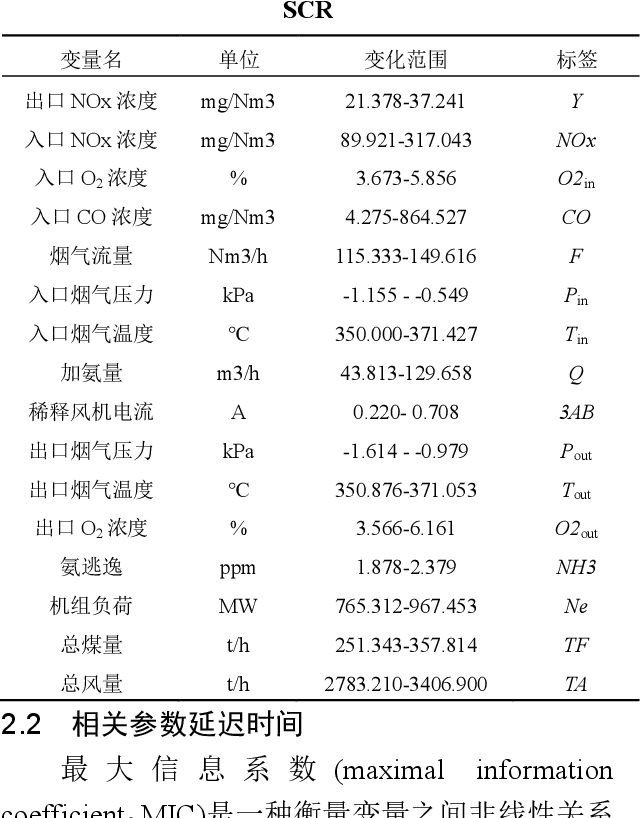
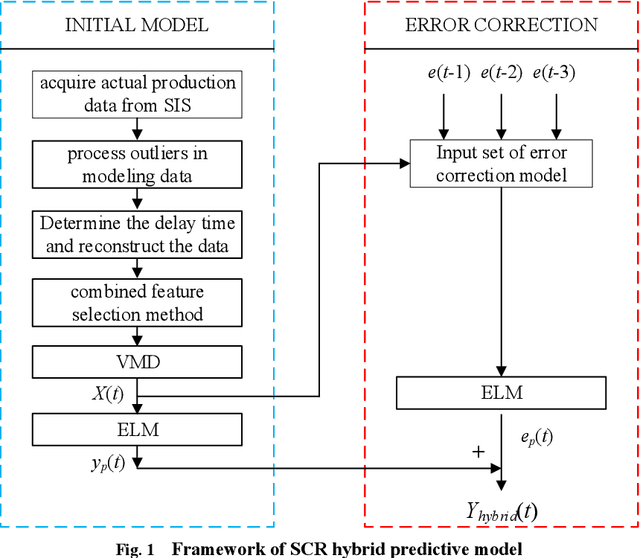
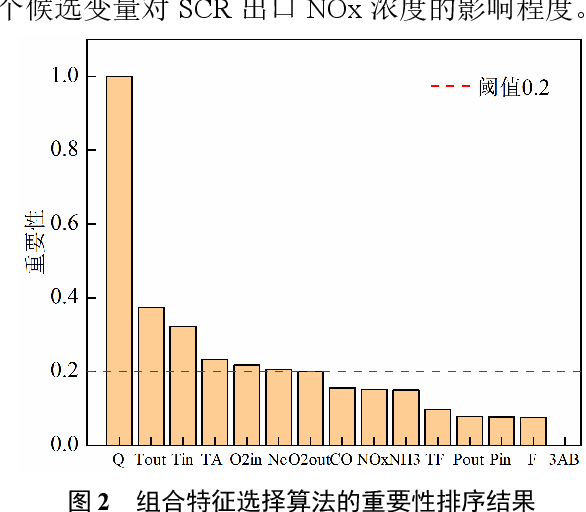
Aiming at the problem that delay time is difficult to determine and prediction accuracy is low in building prediction model of SCR system, a dynamic modeling scheme based on a hybrid of multiple data-driven algorithms was proposed. First, processed abnormal values and normalized the data. To improve the relevance of the input data, used MIC to estimate delay time and reconstructed production data. Then used combined feature selection method to determine input variables. To further mine data information, VMD was used to decompose input time series. Finally, established NOx emission prediction model combining ELM and EC model. Experimental results based on actual historical operating data show that the MAPE of predicted results is 2.61%. Model sensitivity analysis shows that besides the amount of ammonia injection, the inlet oxygen concentration and the flue gas temperature have a significant impact on NOx emission, which should be considered in SCR process control and optimization.
Depth-Guided Camouflaged Object Detection
Jun 26, 2021
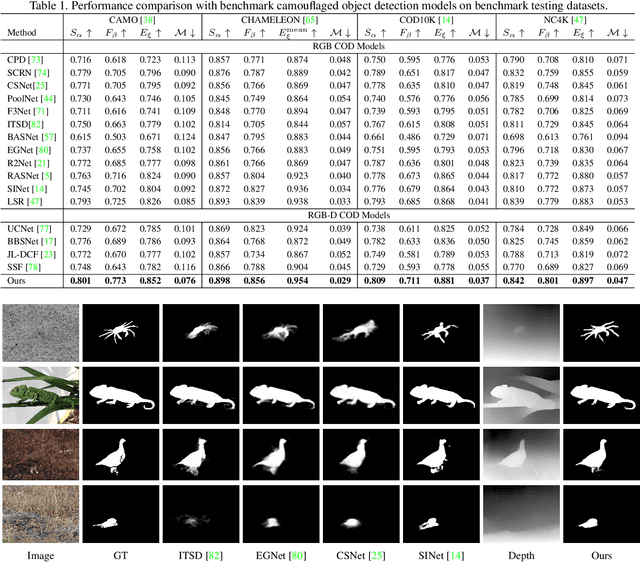
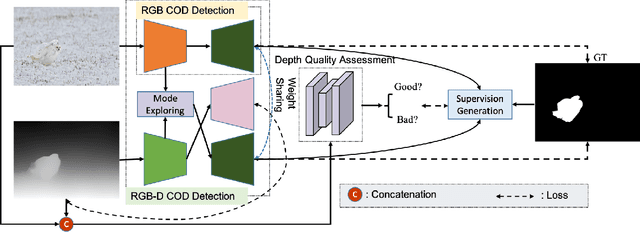

Camouflaged object detection (COD) aims to segment camouflaged objects hiding in the environment, which is challenging due to the similar appearance of camouflaged objects and their surroundings. Research in biology suggests that depth can provide useful object localization cues for camouflaged object discovery, as all the animals have 3D perception ability. However, the depth information has not been exploited for camouflaged object detection. To explore the contribution of depth for camouflage detection, we present a depth-guided camouflaged object detection network with pre-computed depth maps from existing monocular depth estimation methods. Due to the domain gap between the depth estimation dataset and our camouflaged object detection dataset, the generated depth may not be accurate enough to be directly used in our framework. We then introduce a depth quality assessment module to evaluate the quality of depth based on the model prediction from both RGB COD branch and RGB-D COD branch. During training, only high-quality depth is used to update the modal interaction module for multi-modal learning. During testing, our depth quality assessment module can effectively determine the contribution of depth and select the RGB branch or RGB-D branch for camouflage prediction. Extensive experiments on various camouflaged object detection datasets prove the effectiveness of our solution in exploring the depth information for camouflaged object detection. Our code and data is publicly available at: \url{https://github.com/JingZhang617/RGBD-COD}.
Trajectory Synthesis for Fisher Information Maximization
Sep 11, 2017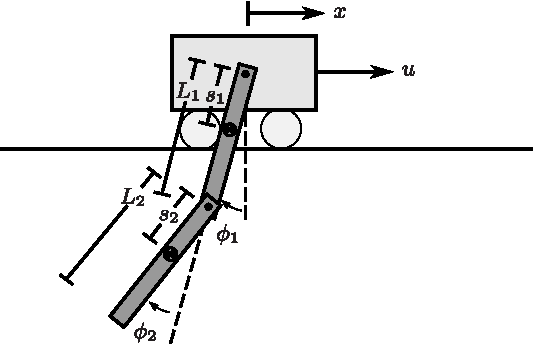
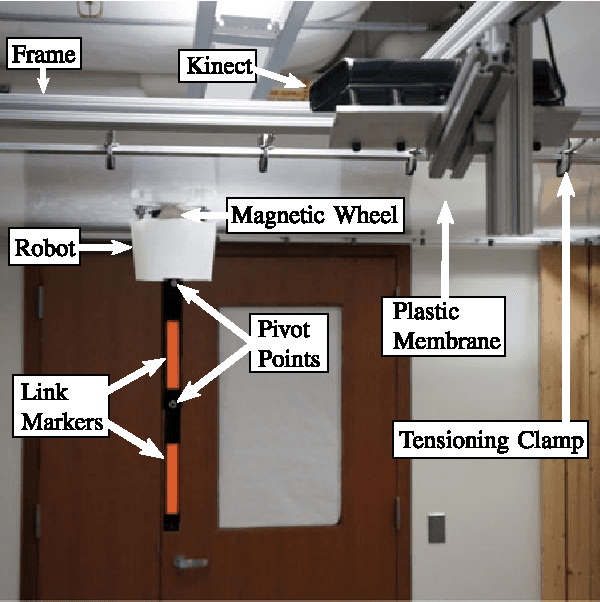

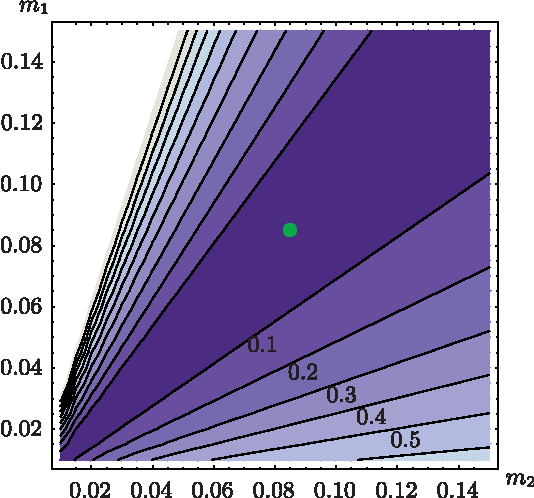
Estimation of model parameters in a dynamic system can be significantly improved with the choice of experimental trajectory. For general, nonlinear dynamic systems, finding globally "best" trajectories is typically not feasible; however, given an initial estimate of the model parameters and an initial trajectory, we present a continuous-time optimization method that produces a locally optimal trajectory for parameter estimation in the presence of measurement noise. The optimization algorithm is formulated to find system trajectories that improve a norm on the Fisher information matrix. A double-pendulum cart apparatus is used to numerically and experimentally validate this technique. In simulation, the optimized trajectory increases the minimum eigenvalue of the Fisher information matrix by three orders of magnitude compared to the initial trajectory. Experimental results show that this optimized trajectory translates to an order of magnitude improvement in the parameter estimate error in practice.
* 12 pages
COVID19-HPSMP: COVID-19 Adopted Hybrid and Parallel Deep Information Fusion Framework for Stock Price Movement Prediction
Jan 02, 2021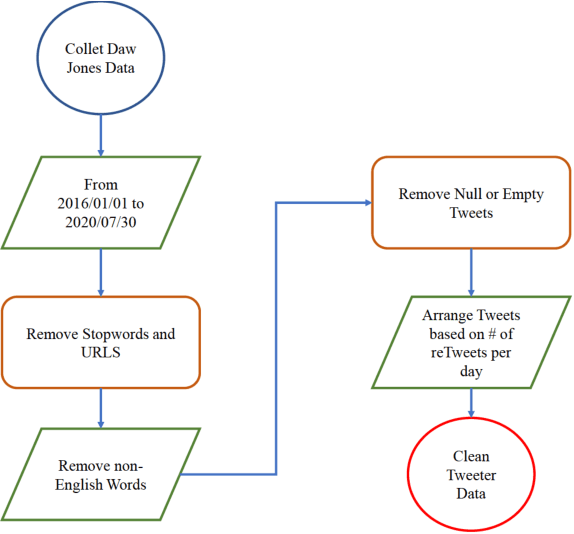

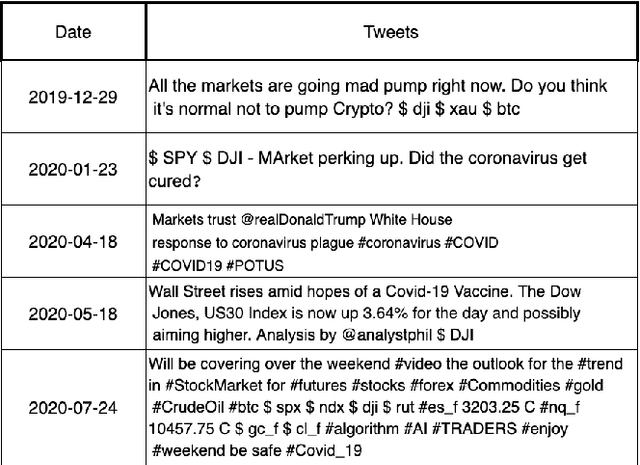
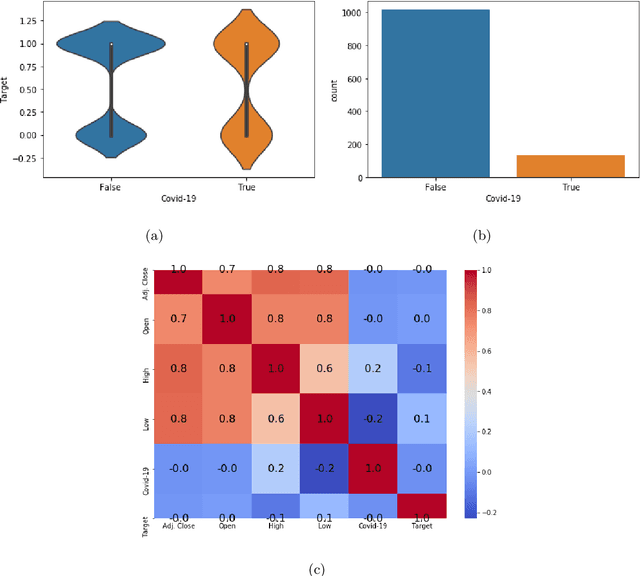
The novel of coronavirus (COVID-19) has suddenly and abruptly changed the world as we knew at the start of the 3rd decade of the 21st century. Particularly, COVID-19 pandemic has negatively affected financial econometrics and stock markets across the globe. Artificial Intelligence (AI) and Machine Learning (ML)-based prediction models, especially Deep Neural Network (DNN) architectures, have the potential to act as a key enabling factor to reduce the adverse effects of the COVID-19 pandemic and future possible ones on financial markets. In this regard, first, a unique COVID-19 related PRIce MOvement prediction (COVID19 PRIMO) dataset is introduced in this paper, which incorporates effects of social media trends related to COVID-19 on stock market price movements. Afterwards, a novel hybrid and parallel DNN-based framework is proposed that integrates different and diversified learning architectures. Referred to as the COVID-19 adopted Hybrid and Parallel deep fusion framework for Stock price Movement Prediction (COVID19-HPSMP), innovative fusion strategies are used to combine scattered social media news related to COVID-19 with historical mark data. The proposed COVID19-HPSMP consists of two parallel paths (hence hybrid), one based on Convolutional Neural Network (CNN) with Local/Global Attention modules, and one integrated CNN and Bi-directional Long Short term Memory (BLSTM) path. The two parallel paths are followed by a multilayer fusion layer acting as a fusion centre that combines localized features. Performance evaluations are performed based on the introduced COVID19 PRIMO dataset illustrating superior performance of the proposed framework.
Pseudo-Relevance Feedback for Multiple Representation Dense Retrieval
Jul 01, 2021
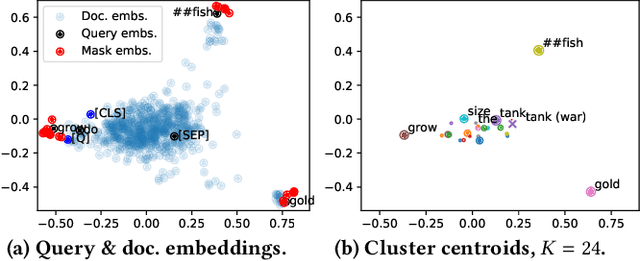
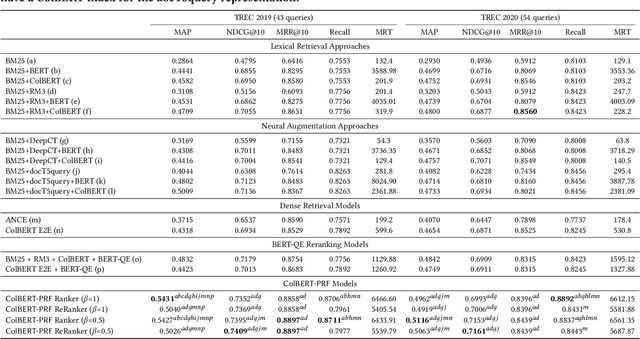
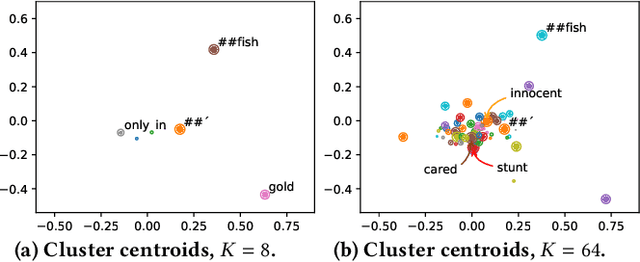
Pseudo-relevance feedback mechanisms, from Rocchio to the relevance models, have shown the usefulness of expanding and reweighting the users' initial queries using information occurring in an initial set of retrieved documents, known as the pseudo-relevant set. Recently, dense retrieval -- through the use of neural contextual language models such as BERT for analysing the documents' and queries' contents and computing their relevance scores -- has shown a promising performance on several information retrieval tasks still relying on the traditional inverted index for identifying documents relevant to a query. Two different dense retrieval families have emerged: the use of single embedded representations for each passage and query (e.g. using BERT's [CLS] token), or via multiple representations (e.g. using an embedding for each token of the query and document). In this work, we conduct the first study into the potential for multiple representation dense retrieval to be enhanced using pseudo-relevance feedback. In particular, based on the pseudo-relevant set of documents identified using a first-pass dense retrieval, we extract representative feedback embeddings (using KMeans clustering) -- while ensuring that these embeddings discriminate among passages (based on IDF) -- which are then added to the query representation. These additional feedback embeddings are shown to both enhance the effectiveness of a reranking as well as an additional dense retrieval operation. Indeed, experiments on the MSMARCO passage ranking dataset show that MAP can be improved by upto 26% on the TREC 2019 query set and 10% on the TREC 2020 query set by the application of our proposed ColBERT-PRF method on a ColBERT dense retrieval approach.
* 10 pages
Semantic and Syntactic Enhanced Aspect Sentiment Triplet Extraction
Jun 07, 2021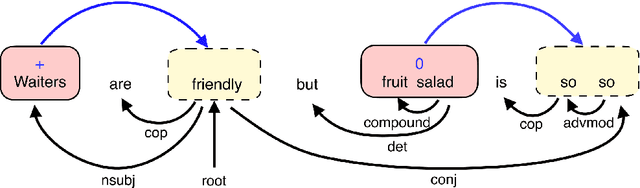

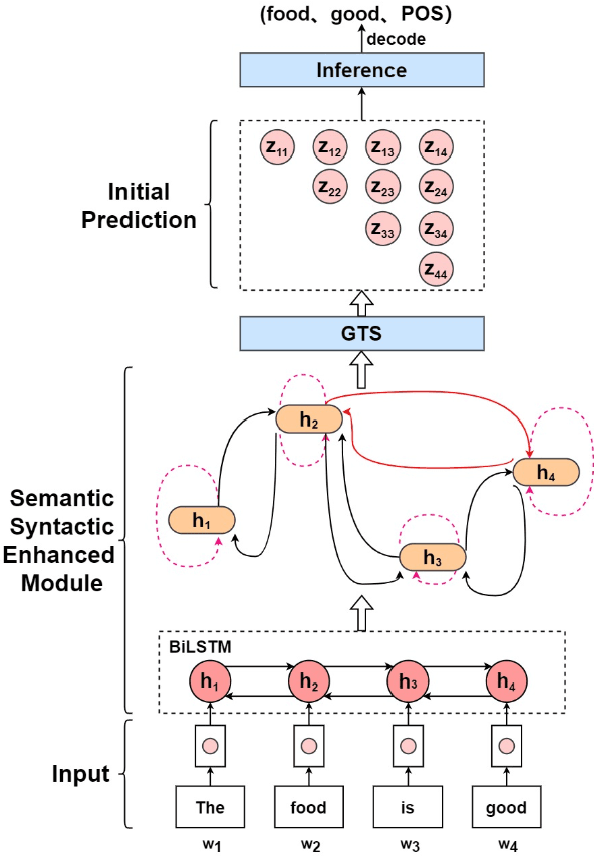
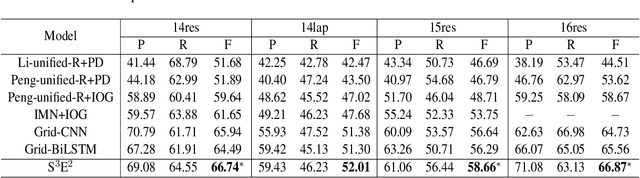
Aspect Sentiment Triplet Extraction (ASTE) aims to extract triplets from sentences, where each triplet includes an entity, its associated sentiment, and the opinion span explaining the reason for the sentiment. Most existing research addresses this problem in a multi-stage pipeline manner, which neglects the mutual information between such three elements and has the problem of error propagation. In this paper, we propose a Semantic and Syntactic Enhanced aspect Sentiment triplet Extraction model (S3E2) to fully exploit the syntactic and semantic relationships between the triplet elements and jointly extract them. Specifically, we design a Graph-Sequence duel representation and modeling paradigm for the task of ASTE: we represent the semantic and syntactic relationships between word pairs in a sentence by graph and encode it by Graph Neural Networks (GNNs), as well as modeling the original sentence by LSTM to preserve the sequential information. Under this setting, we further apply a more efficient inference strategy for the extraction of triplets. Extensive evaluations on four benchmark datasets show that S3E2 significantly outperforms existing approaches, which proves our S3E2's superiority and flexibility in an end-to-end fashion.
Learning Language-Conditioned Robot Behavior from Offline Data and Crowd-Sourced Annotation
Sep 02, 2021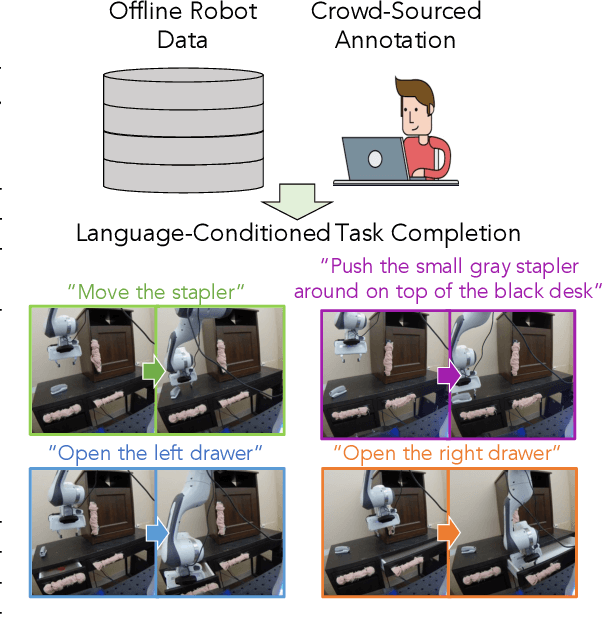
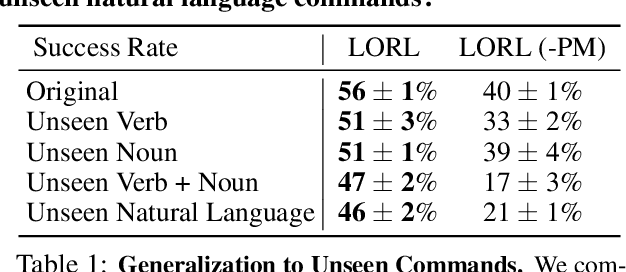
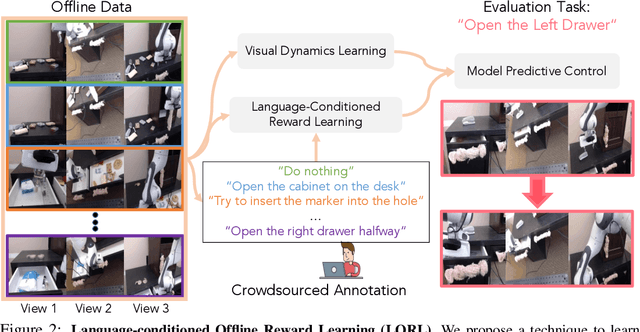

We study the problem of learning a range of vision-based manipulation tasks from a large offline dataset of robot interaction. In order to accomplish this, humans need easy and effective ways of specifying tasks to the robot. Goal images are one popular form of task specification, as they are already grounded in the robot's observation space. However, goal images also have a number of drawbacks: they are inconvenient for humans to provide, they can over-specify the desired behavior leading to a sparse reward signal, or under-specify task information in the case of non-goal reaching tasks. Natural language provides a convenient and flexible alternative for task specification, but comes with the challenge of grounding language in the robot's observation space. To scalably learn this grounding we propose to leverage offline robot datasets (including highly sub-optimal, autonomously collected data) with crowd-sourced natural language labels. With this data, we learn a simple classifier which predicts if a change in state completes a language instruction. This provides a language-conditioned reward function that can then be used for offline multi-task RL. In our experiments, we find that on language-conditioned manipulation tasks our approach outperforms both goal-image specifications and language conditioned imitation techniques by more than 25%, and is able to perform visuomotor tasks from natural language, such as "open the right drawer" and "move the stapler", on a Franka Emika Panda robot.
FT-TDR: Frequency-guided Transformer and Top-Down Refinement Network for Blind Face Inpainting
Aug 10, 2021
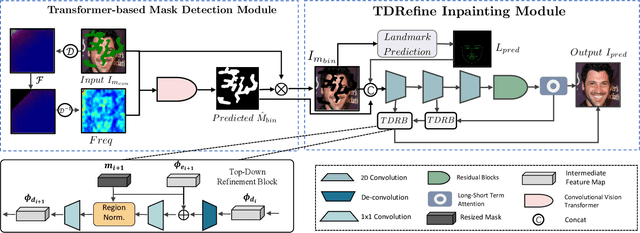
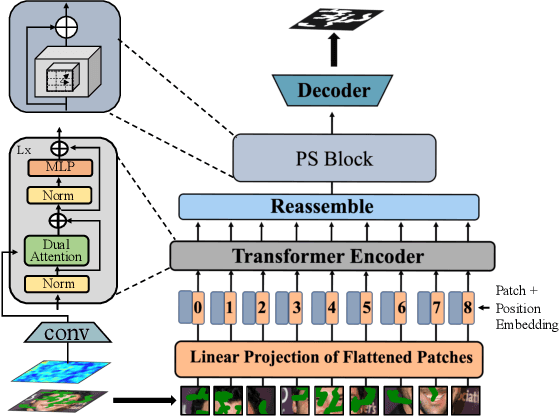

Blind face inpainting refers to the task of reconstructing visual contents without explicitly indicating the corrupted regions in a face image. Inherently, this task faces two challenges: (1) how to detect various mask patterns of different shapes and contents; (2) how to restore visually plausible and pleasing contents in the masked regions. In this paper, we propose a novel two-stage blind face inpainting method named Frequency-guided Transformer and Top-Down Refinement Network (FT-TDR) to tackle these challenges. Specifically, we first use a transformer-based network to detect the corrupted regions to be inpainted as masks by modeling the relation among different patches. We also exploit the frequency modality as complementary information for improved detection results and capture the local contextual incoherence to enhance boundary consistency. Then a top-down refinement network is proposed to hierarchically restore features at different levels and generate contents that are semantically consistent with the unmasked face regions. Extensive experiments demonstrate that our method outperforms current state-of-the-art blind and non-blind face inpainting methods qualitatively and quantitatively.
Deep Learning Radio Frequency Signal Classification with Hybrid Images
May 19, 2021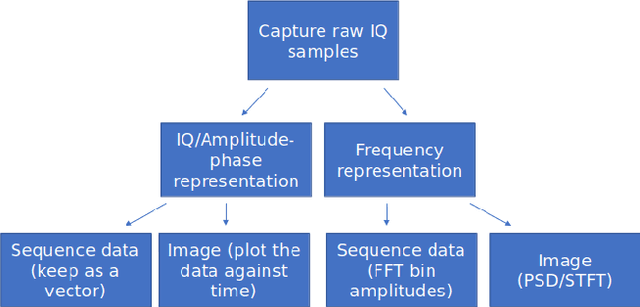
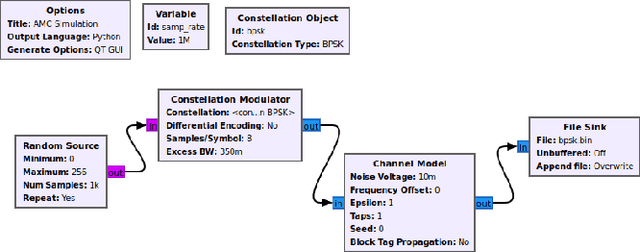
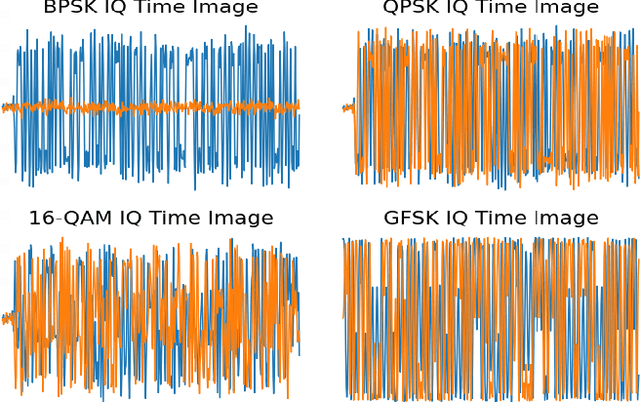
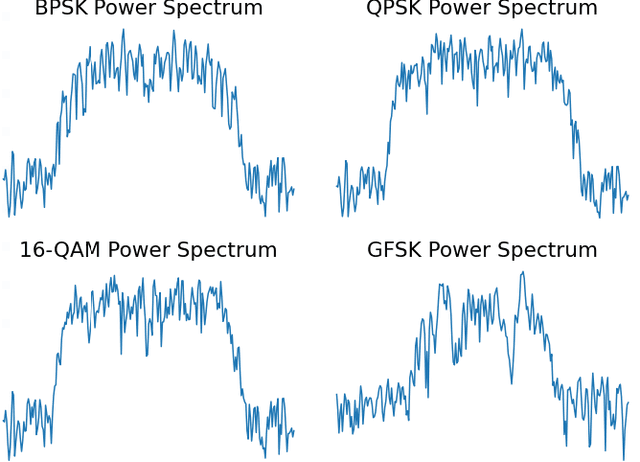
In recent years, Deep Learning (DL) has been successfully applied to detect and classify Radio Frequency (RF) Signals. A DL approach is especially useful since it identifies the presence of a signal without needing full protocol information, and can also detect and/or classify non-communication waveforms, such as radar signals. In this work, we focus on the different pre-processing steps that can be used on the input training data, and test the results on a fixed DL architecture. While previous works have mostly focused exclusively on either time-domain or frequency domain approaches, we propose a hybrid image that takes advantage of both time and frequency domain information, and tackles the classification as a Computer Vision problem. Our initial results point out limitations to classical pre-processing approaches while also showing that it's possible to build a classifier that can leverage the strengths of multiple signal representations.
Multi-Server Private Linear Transformation with Joint Privacy
Aug 22, 2021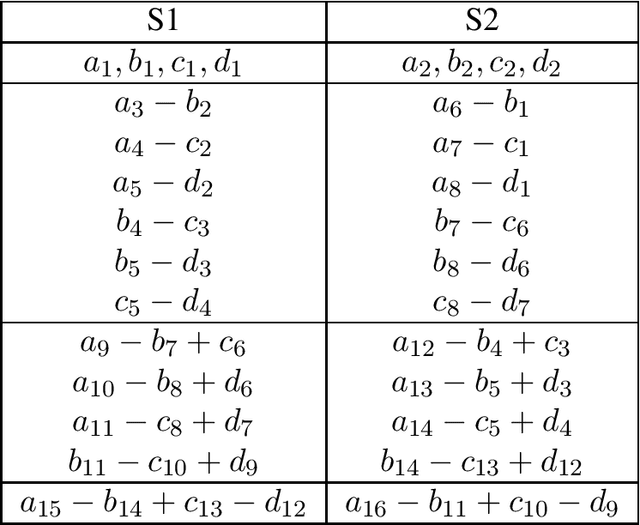
This paper focuses on the Private Linear Transformation (PLT) problem in the multi-server scenario. In this problem, there are $N$ servers, each of which stores an identical copy of a database consisting of $K$ independent messages, and there is a user who wishes to compute $L$ independent linear combinations of a subset of $D$ messages in the database while leaking no information to the servers about the identity of the entire set of these $D$ messages required for the computation. We focus on the setting in which the coefficient matrix of the desired $L$ linear combinations generates a Maximum Distance Separable (MDS) code. We characterize the capacity of the PLT problem, defined as the supremum of all achievable download rates, for all parameters $N, K, D \geq 1$ and $L=1$, i.e., when the user wishes to compute one linear combination of $D$ messages. Moreover, we establish an upper bound on the capacity of PLT problem for all parameters $N, K, D, L \geq 1$, and leveraging some known capacity results, we show the tightness of this bound in the following regimes: (i) the case when there is a single server (i.e., $N=1$), (ii) the case when $L=1$, and (iii) the case when $L=D$.