 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
DL-Traff: Survey and Benchmark of Deep Learning Models for Urban Traffic Prediction
Aug 20, 2021
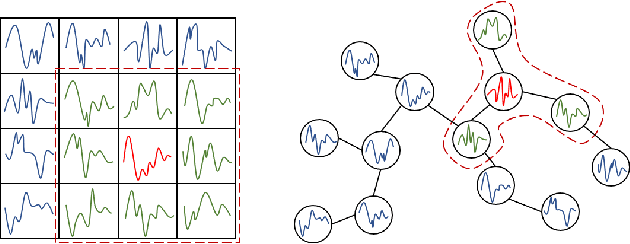
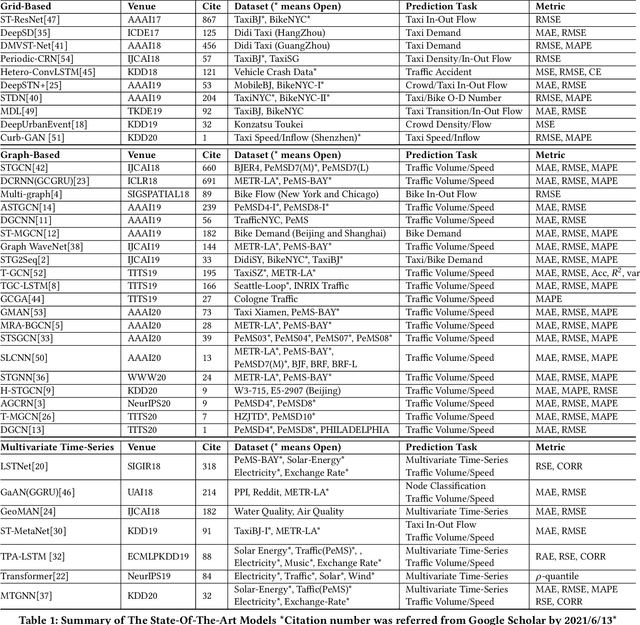
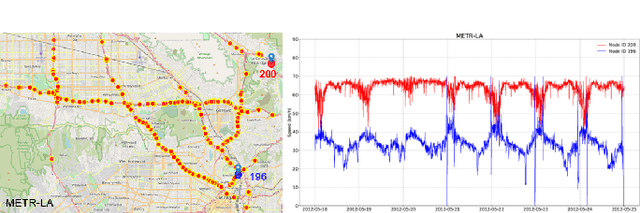
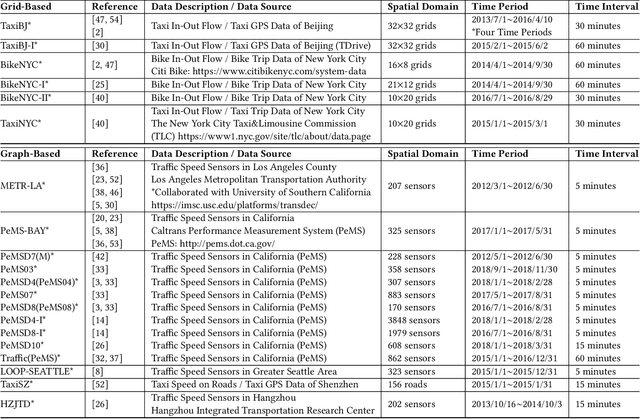
Nowadays, with the rapid development of IoT (Internet of Things) and CPS (Cyber-Physical Systems) technologies, big spatiotemporal data are being generated from mobile phones, car navigation systems, and traffic sensors. By leveraging state-of-the-art deep learning technologies on such data, urban traffic prediction has drawn a lot of attention in AI and Intelligent Transportation System community. The problem can be uniformly modeled with a 3D tensor (T, N, C), where T denotes the total time steps, N denotes the size of the spatial domain (i.e., mesh-grids or graph-nodes), and C denotes the channels of information. According to the specific modeling strategy, the state-of-the-art deep learning models can be divided into three categories: grid-based, graph-based, and multivariate time-series models. In this study, we first synthetically review the deep traffic models as well as the widely used datasets, then build a standard benchmark to comprehensively evaluate their performances with the same settings and metrics. Our study named DL-Traff is implemented with two most popular deep learning frameworks, i.e., TensorFlow and PyTorch, which is already publicly available as two GitHub repositories https://github.com/deepkashiwa20/DL-Traff-Grid and https://github.com/deepkashiwa20/DL-Traff-Graph. With DL-Traff, we hope to deliver a useful resource to researchers who are interested in spatiotemporal data analysis.
Machine Learning Characterization of Cancer Patients-Derived Extracellular Vesicles using Vibrational Spectroscopies
Aug 25, 2021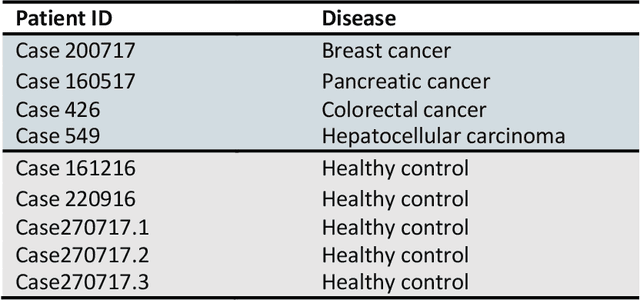
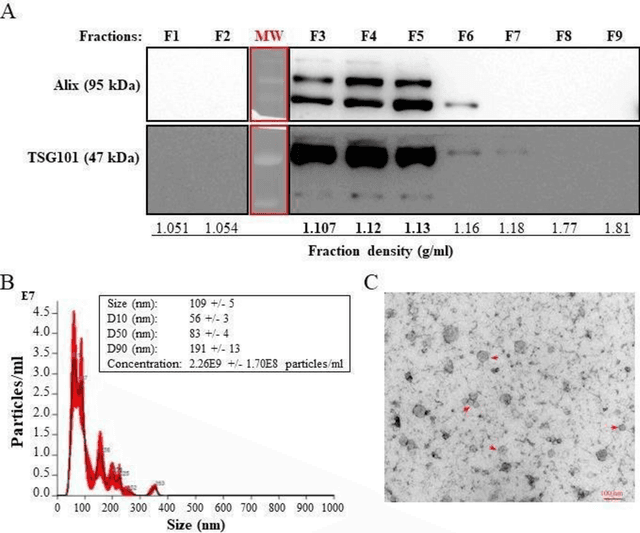
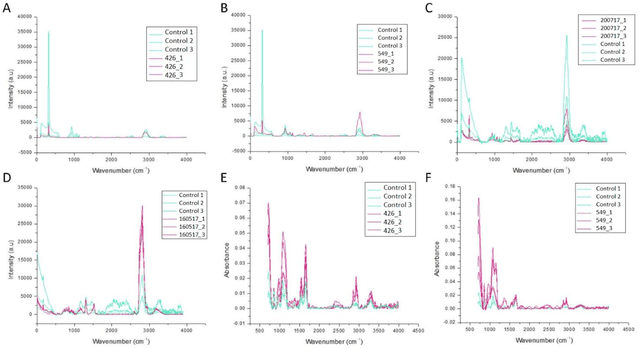
The early detection of cancer is a challenging problem in medicine. The blood sera of cancer patients are enriched with heterogeneous secretory lipid bound extracellular vesicles (EVs), which present a complex repertoire of information and biomarkers, representing their cell of origin, that are being currently studied in the field of liquid biopsy and cancer screening. Vibrational spectroscopies provide non-invasive approaches for the assessment of structural and biophysical properties in complex biological samples. In this study, multiple Raman spectroscopy measurements were performed on the EVs extracted from the blood sera of 9 patients consisting of four different cancer subtypes (colorectal cancer, hepatocellular carcinoma, breast cancer and pancreatic cancer) and five healthy patients (controls). FTIR(Fourier Transform Infrared) spectroscopy measurements were performed as a complementary approach to Raman analysis, on two of the four cancer subtypes. The AdaBoost Random Forest Classifier, Decision Trees, and Support Vector Machines (SVM) distinguished the baseline corrected Raman spectra of cancer EVs from those of healthy controls (18 spectra) with a classification accuracy of greater than 90% when reduced to a spectral frequency range of 1800 to 1940 inverse cm, and subjected to a 0.5 training/testing split. FTIR classification accuracy on 14 spectra showed an 80% classification accuracy. Our findings demonstrate that basic machine learning algorithms are powerful tools to distinguish the complex vibrational spectra of cancer patient EVs from those of healthy patients. These experimental methods hold promise as valid and efficient liquid biopsy for machine intelligence-assisted early cancer screening.
Channel Estimation for RIS-Aided Multiuser Millimeter-Wave Massive MIMO Systems
Jun 28, 2021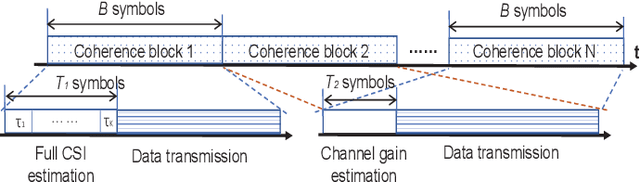
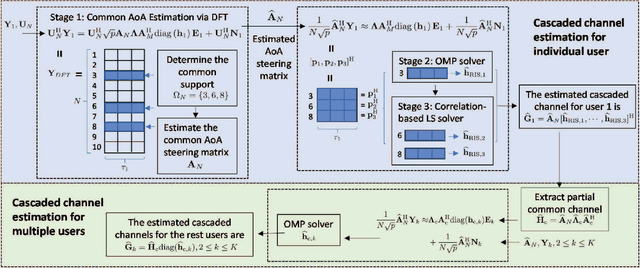
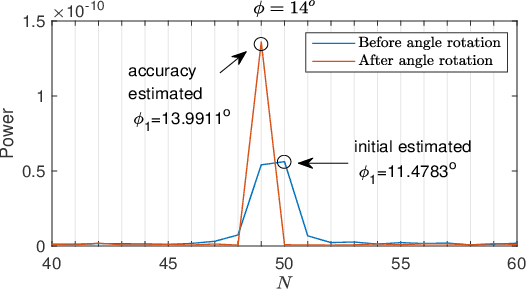
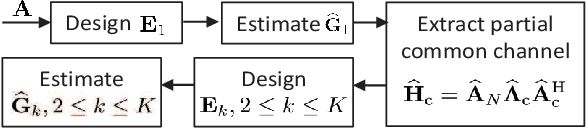
Channel estimation in the RIS-aided massive multiuser multiple-input single-output (MU-MISO) wireless communication systems is challenging due to the passive feature of RIS and the large number of reflecting elements that incur high channel estimation overhead. To address this issue, we propose a novel cascaded channel estimation strategy with low pilot overhead by exploiting the sparsity and the correlation of multiuser cascaded channels in millimeter-wave massive MISO systems. Based on the fact that the phsical positions of the BS, the RIS and users may not change in several or even tens of consecutive channel coherence blocks, we first estimate the full channel state information (CSI) including all the angle and gain information in the first coherence block, and then only re-estimate the channel gains in the remaining coherence blocks with much less pilot overhead. In the first coherence block, we propose a two-phase channel estimation method, in which the cascaded channel of one typical user is estimated in Phase I based on the linear correlation among cascaded paths, while the cascaded channels of other users are estimated in Phase II by utilizing the partial CSI of the common base station (BS)-RIS channel obtained in Phase I. The total theoretical minimum pilot overhead in the first coherence block is $8J-2+(K-1)\left\lceil (8J-2)/L\right\rceil $, where $K$, $L$ and $J$ denote the numbers of users, paths in the BS-RIS channel and paths in the RIS-user channel, respectively. In each of the remaining coherence blocks, the minimum pilot overhead is $JK$. Moreover, the training phase shift matrices at the RIS are optimized to improve the estimation performance.
A Self-Distillation Embedded Supervised Affinity Attention Model for Few-Shot Segmentation
Aug 14, 2021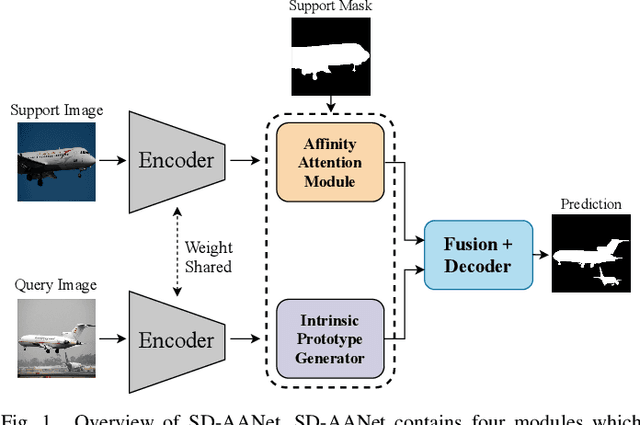


Few-shot semantic segmentation is a challenging task of predicting object categories in pixel-wise with only few annotated samples. However, existing approaches still face two main challenges. First, huge feature distinction between support and query images causes knowledge transferring barrier, which harms the segmentation performance. Second, few support samples cause unrepresentative of support features, hardly to guide high-quality query segmentation. To deal with the above two issues, we propose self-distillation embedded supervised affinity attention model (SD-AANet) to improve the performance of few-shot segmentation task. Specifically, the self-distillation guided prototype module (SDPM) extracts intrinsic prototype by self-distillation between support and query to capture representative features. The supervised affinity attention module (SAAM) adopts support ground truth to guide the production of high quality query attention map, which can learn affinity information to focus on whole area of query target. Extensive experiments prove that our SD-AANet significantly improves the performance comparing with existing methods. Comprehensive ablation experiments and visualization studies also show the significant effect of SDPM and SAAM for few-shot segmentation task. On benchmark datasets, PASCAL-5i and COCO-20i, our proposed SD-AANet both achieve state-of-the-art results. Our code will be publicly available soon.
Scale-Consistent Fusion: from Heterogeneous Local Sampling to Global Immersive Rendering
Jun 17, 2021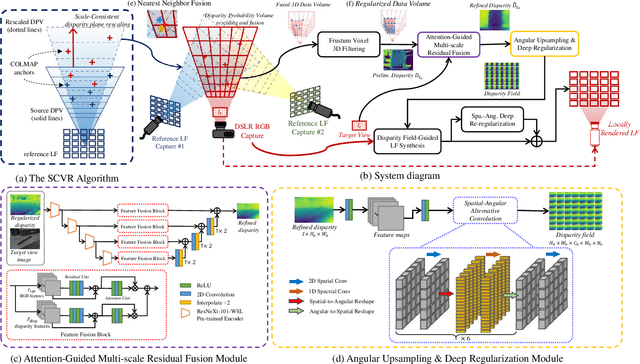



Image-based geometric modeling and novel view synthesis based on sparse, large-baseline samplings are challenging but important tasks for emerging multimedia applications such as virtual reality and immersive telepresence. Existing methods fail to produce satisfactory results due to the limitation on inferring reliable depth information over such challenging reference conditions. With the popularization of commercial light field (LF) cameras, capturing LF images (LFIs) is as convenient as taking regular photos, and geometry information can be reliably inferred. This inspires us to use a sparse set of LF captures to render high-quality novel views globally. However, fusion of LF captures from multiple angles is challenging due to the scale inconsistency caused by various capture settings. To overcome this challenge, we propose a novel scale-consistent volume rescaling algorithm that robustly aligns the disparity probability volumes (DPV) among different captures for scale-consistent global geometry fusion. Based on the fused DPV projected to the target camera frustum, novel learning-based modules have been proposed (i.e., the attention-guided multi-scale residual fusion module, and the disparity field guided deep re-regularization module) which comprehensively regularize noisy observations from heterogeneous captures for high-quality rendering of novel LFIs. Both quantitative and qualitative experiments over the Stanford Lytro Multi-view LF dataset show that the proposed method outperforms state-of-the-art methods significantly under different experiment settings for disparity inference and LF synthesis.
A Large-Scale Rich Context Query and Recommendation Dataset in Online Knowledge-Sharing
Jun 11, 2021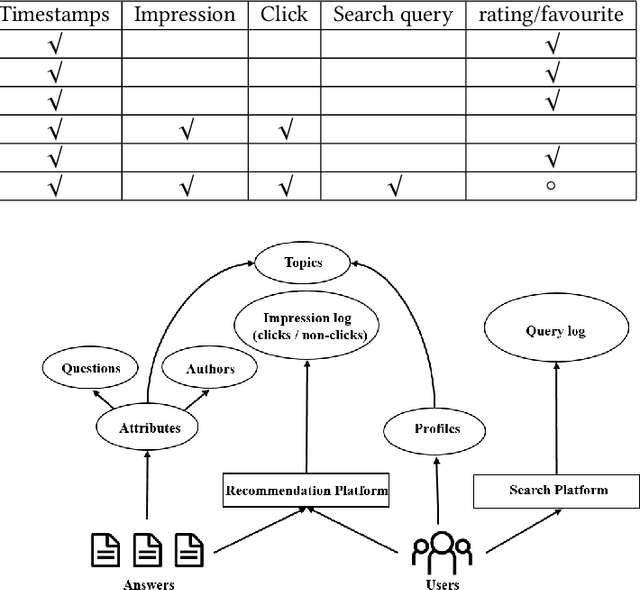
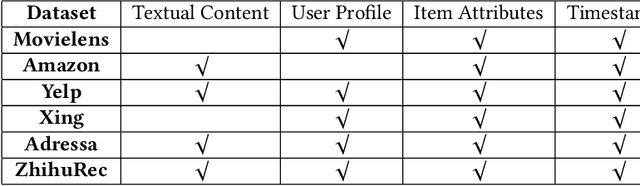

Data plays a vital role in machine learning studies. In the research of recommendation, both user behaviors and side information are helpful to model users. So, large-scale real scenario datasets with abundant user behaviors will contribute a lot. However, it is not easy to get such datasets as most of them are only hold and protected by companies. In this paper, a new large-scale dataset collected from a knowledge-sharing platform is presented, which is composed of around 100M interactions collected within 10 days, 798K users, 165K questions, 554K answers, 240K authors, 70K topics, and more than 501K user query keywords. There are also descriptions of users, answers, questions, authors, and topics, which are anonymous. Note that each user's latest query keywords have not been included in previous open datasets, which reveal users' explicit information needs. We characterize the dataset and demonstrate its potential applications for recommendation study. Multiple experiments show the dataset can be used to evaluate algorithms in general top-N recommendation, sequential recommendation, and context-aware recommendation. This dataset can also be used to integrate search and recommendation and recommendation with negative feedback. Besides, tasks beyond recommendation, such as user gender prediction, most valuable answerer identification, and high-quality answer recognition, can also use this dataset. To the best of our knowledge, this is the largest real-world interaction dataset for personalized recommendation.
Comprehensive Studies for Arbitrary-shape Scene Text Detection
Jul 25, 2021
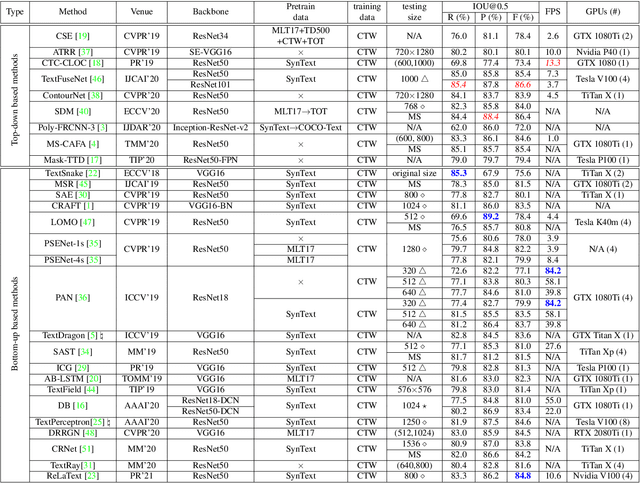
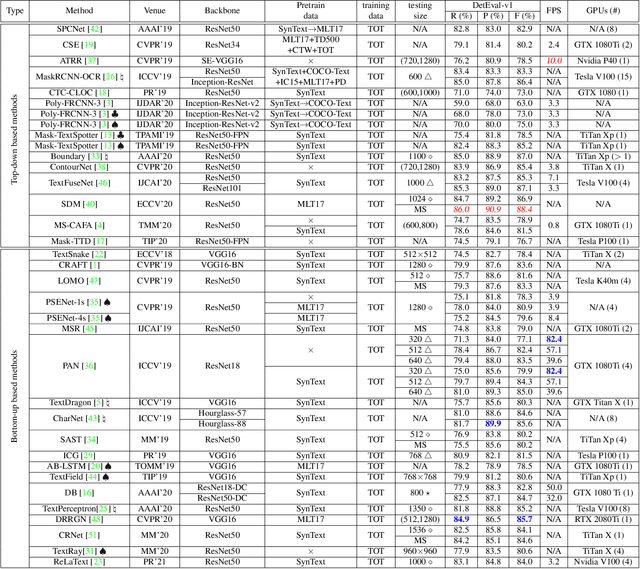

Numerous scene text detection methods have been proposed in recent years. Most of them declare they have achieved state-of-the-art performances. However, the performance comparison is unfair, due to lots of inconsistent settings (e.g., training data, backbone network, multi-scale feature fusion, evaluation protocols, etc.). These various settings would dissemble the pros and cons of the proposed core techniques. In this paper, we carefully examine and analyze the inconsistent settings, and propose a unified framework for the bottom-up based scene text detection methods. Under the unified framework, we ensure the consistent settings for non-core modules, and mainly investigate the representations of describing arbitrary-shape scene texts, e.g., regressing points on text contours, clustering pixels with predicted auxiliary information, grouping connected components with learned linkages, etc. With the comprehensive investigations and elaborate analyses, it not only cleans up the obstacle of understanding the performance differences between existing methods but also reveals the advantages and disadvantages of previous models under fair comparisons.
Water from Two Rocks: Maximizing the Mutual Information
May 22, 2018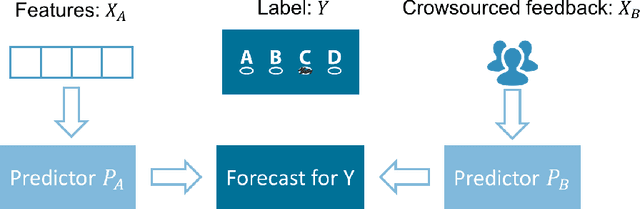
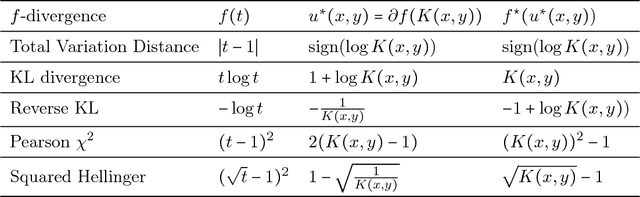
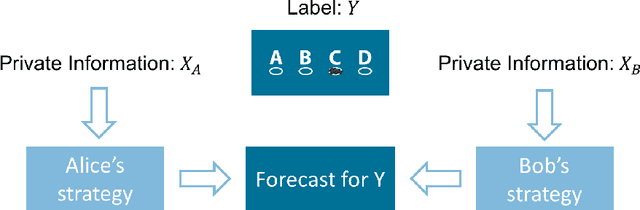
We build a natural connection between the learning problem, co-training, and forecast elicitation without verification (related to peer-prediction) and address them simultaneously using the same information theoretic approach. In co-training/multiview learning, the goal is to aggregate two views of data into a prediction for a latent label. We show how to optimally combine two views of data by reducing the problem to an optimization problem. Our work gives a unified and rigorous approach to the general setting. In forecast elicitation without verification we seek to design a mechanism that elicits high quality forecasts from agents in the setting where the mechanism does not have access to the ground truth. By assuming the agents' information is independent conditioning on the outcome, we propose mechanisms where truth-telling is a strict equilibrium for both the single-task and multi-task settings. Our multi-task mechanism additionally has the property that the truth-telling equilibrium pays better than any other strategy profile and strictly better than any other "non-permutation" strategy profile when the prior satisfies some mild conditions.
Multi-Objective Resource Allocation for IRS-Aided SWIPT
Mar 10, 2021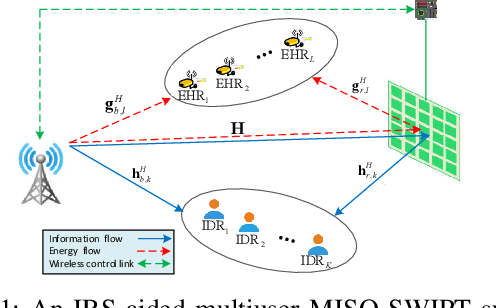
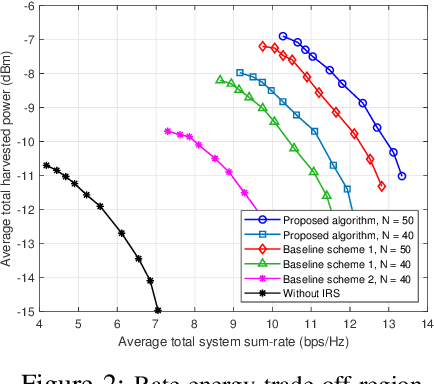
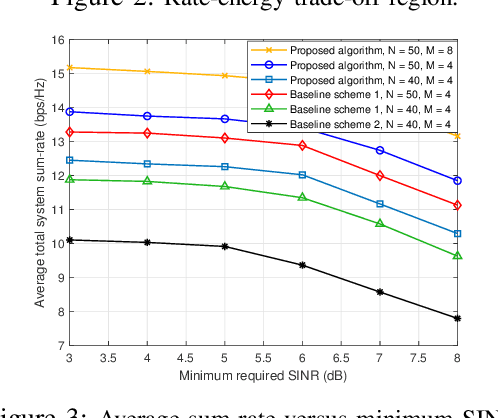
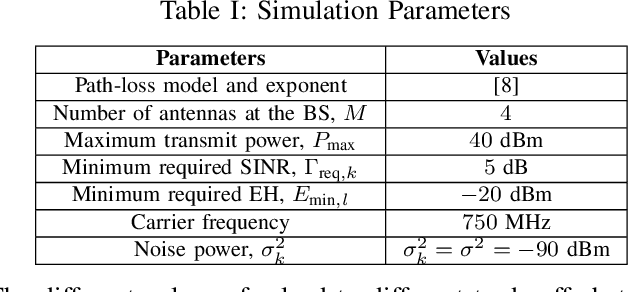
In this letter, we study the resource allocation for a multiuser intelligent reflecting surface (IRS)-aided simultaneous wireless information and power transfer (SWIPT) system. Specifically, a multi-antenna base station (BS) transmits energy and information signals simultaneously to multiple energy harvesting receivers (EHRs) and information decoding receivers (IDRs) assisted by an IRS. Under this setup, we introduce a multi-objective optimization (MOOP) framework to investigate the fundamental trade-off between the data sum-rate maximization and the total harvested energy maximization, by jointly optimizing the energy/information beamforming vectors at the BS and the phase shifts at the IRS. This MOOP problem is first converted to a single-objective optimization problem (SOOP) via the $\epsilon$-constraint method and then solved by majorization minimization (MM) and inner approximation (IA) techniques. Simulation results unveil a non-trivial trade-off between the considered competing objectives, as well as the superior performance of the proposed scheme as compared to various baseline schemes.
Approximating Pandora's Box with Correlations
Aug 30, 2021
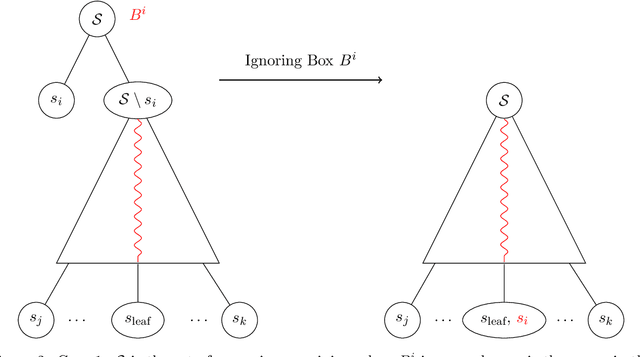
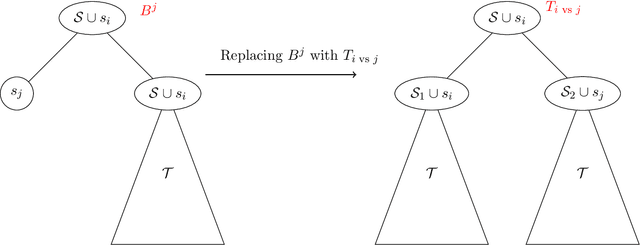
The Pandora's Box problem asks to find a search strategy over $n$ alternatives given stochastic information about their values, aiming to minimize the sum of the search cost and the value of the chosen alternative. Even though the case of independently distributed values is well understood, our algorithmic understanding of the problem is very limited once the independence assumption is dropped. Our work aims to characterize the complexity of approximating the Pandora's Box problem under correlated value distributions. To that end, we present a general reduction to a simpler version of Pandora's Box, that only asks to find a value below a certain threshold, and eliminates the need to reason about future values that will arise during the search. Using this general tool, we study two cases of correlation; the case of explicitly given distributions of support $m$ and the case of mixtures of $m$ product distributions. $\bullet$ In the first case, we connect Pandora's Box to the well studied problem of Optimal Decision Tree, obtaining an $O(\log m)$ approximation but also showing that the problem is strictly easier as it is equivalent (up to constant factors) to the Uniform Decision Tree problem. $\bullet$ In the case of mixtures of product distributions, the problem is again related to the noisy variant of Optimal Decision Tree which is significantly more challenging. We give a constant-factor approximation that runs in time $n^{ \tilde O( m^2/\varepsilon^2 ) }$ for $m$ mixture components whose marginals on every alternative are either identical or separated in TV distance by $\varepsilon$.