 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
A Comprehensive Exploration of Pre-training Language Models
Jun 22, 2021
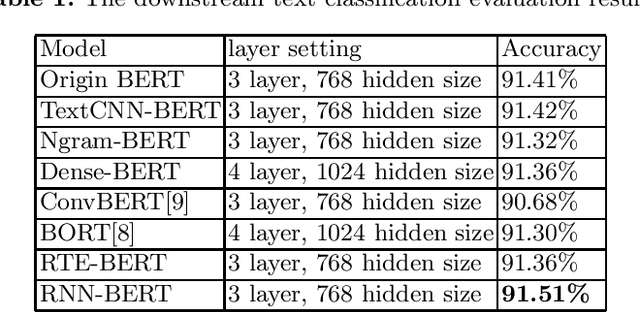
Recently, the development of pre-trained language models has brought natural language processing (NLP) tasks to the new state-of-the-art. In this paper we explore the efficiency of various pre-trained language models. We pre-train a list of transformer-based models with the same amount of text and the same training steps. The experimental results shows that the most improvement upon the origin BERT is adding the RNN-layer to capture more contextual information for the transformer-encoder layers.
M-ar-K-Fast Independent Component Analysis
Aug 17, 2021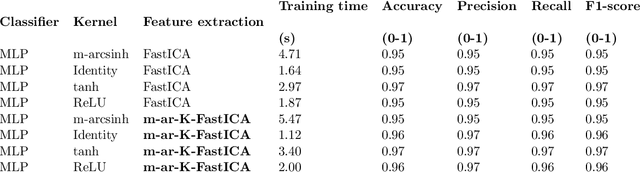
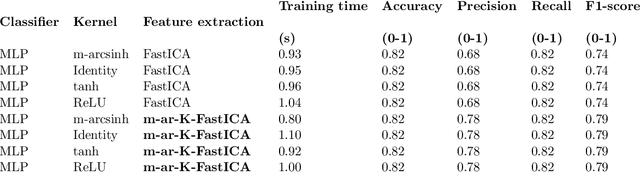
This study presents the m-arcsinh Kernel ('m-ar-K') Fast Independent Component Analysis ('FastICA') method ('m-ar-K-FastICA') for feature extraction. The kernel trick has enabled dimensionality reduction techniques to capture a higher extent of non-linearity in the data; however, reproducible, open-source kernels to aid with feature extraction are still limited and may not be reliable when projecting features from entropic data. The m-ar-K function, freely available in Python and compatible with its open-source library 'scikit-learn', is hereby coupled with FastICA to achieve more reliable feature extraction in presence of a high extent of randomness in the data, reducing the need for pre-whitening. Different classification tasks were considered, as related to five (N = 5) open access datasets of various degrees of information entropy, available from scikit-learn and the University California Irvine (UCI) Machine Learning repository. Experimental results demonstrate improvements in the classification performance brought by the proposed feature extraction. The novel m-ar-K-FastICA dimensionality reduction approach is compared to the 'FastICA' gold standard method, supporting its higher reliability and computational efficiency, regardless of the underlying uncertainty in the data.
BanditMF: Multi-Armed Bandit Based Matrix Factorization Recommender System
Jun 21, 2021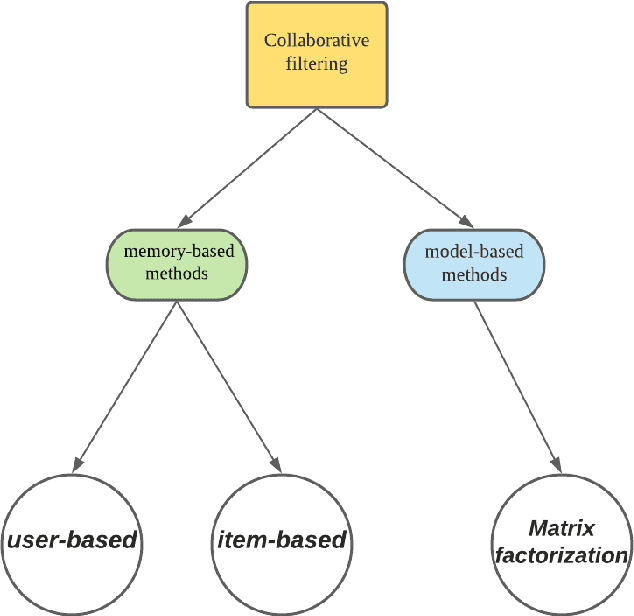
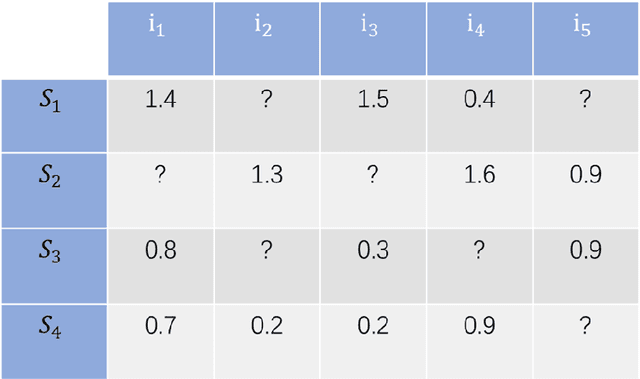
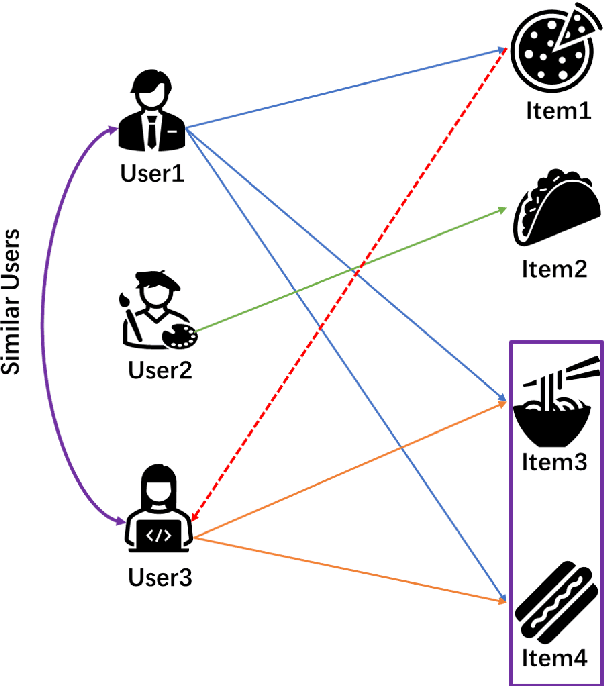
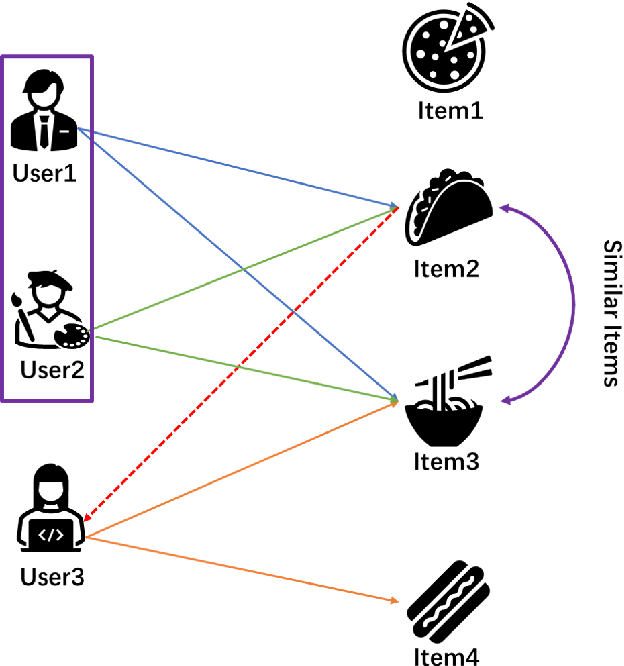
Multi-armed bandits (MAB) provide a principled online learning approach to attain the balance between exploration and exploitation.Due to the superior performance and low feedback learning without the learning to act in multiple situations, Multi-armed Bandits drawing widespread attention in applications ranging such as recommender systems. Likewise, within the recommender system, collaborative filtering (CF) is arguably the earliest and most influential method in the recommender system. Crucially, new users and an ever-changing pool of recommended items are the challenges that recommender systems need to address. For collaborative filtering, the classical method is training the model offline, then perform the online testing, but this approach can no longer handle the dynamic changes in user preferences which is the so-called \textit{cold start}. So how to effectively recommend items to users in the absence of effective information? To address the aforementioned problems, a multi-armed bandit based collaborative filtering recommender system has been proposed, named BanditMF. BanditMF is designed to address two challenges in the multi-armed bandits algorithm and collaborative filtering: (1) how to solve the cold start problem for collaborative filtering under the condition of scarcity of valid information, (2) how to solve the sub-optimal problem of bandit algorithms in strong social relations domains caused by independently estimating unknown parameters associated with each user and ignoring correlations between users.
CausalRec: Causal Inference for Visual Debiasing in Visually-Aware Recommendation
Jul 13, 2021
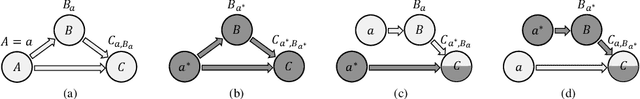
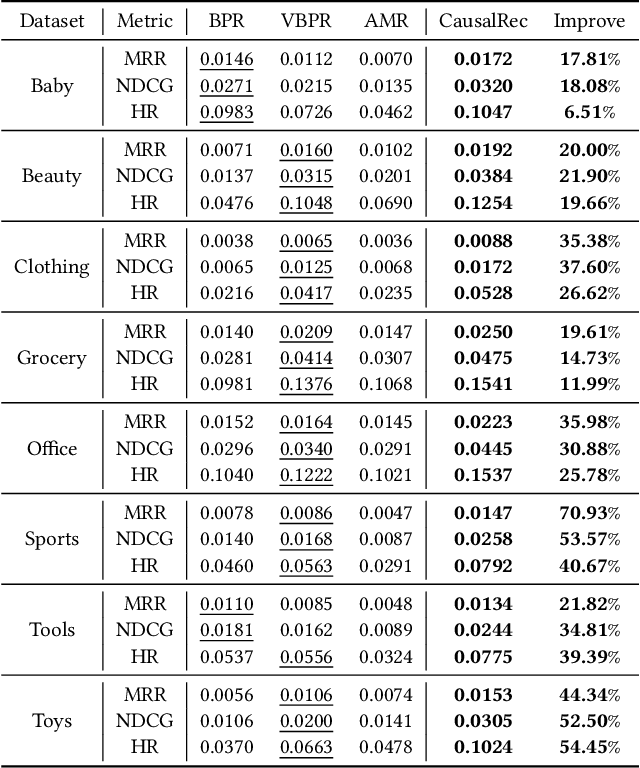
Visually-aware recommendation on E-commerce platforms aims to leverage visual information of items to predict a user's preference. It is commonly observed that user's attention to visual features does not always reflect the real preference. Although a user may click and view an item in light of a visual satisfaction of their expectations, a real purchase does not always occur due to the unsatisfaction of other essential features (e.g., brand, material, price). We refer to the reason for such a visually related interaction deviating from the real preference as a visual bias. Existing visually-aware models make use of the visual features as a separate collaborative signal similarly to other features to directly predict the user's preference without considering a potential bias, which gives rise to a visually biased recommendation. In this paper, we derive a causal graph to identify and analyze the visual bias of these existing methods. In this causal graph, the visual feature of an item acts as a mediator, which could introduce a spurious relationship between the user and the item. To eliminate this spurious relationship that misleads the prediction of the user's real preference, an intervention and a counterfactual inference are developed over the mediator. Particularly, the Total Indirect Effect is applied for a debiased prediction during the testing phase of the model. This causal inference framework is model agnostic such that it can be integrated into the existing methods. Furthermore, we propose a debiased visually-aware recommender system, denoted as CausalRec to effectively retain the supportive significance of the visual information and remove the visual bias. Extensive experiments are conducted on eight benchmark datasets, which shows the state-of-the-art performance of CausalRec and the efficacy of debiasing.
MTNet: A Multi-Task Neural Network for On-Field Calibration of Low-Cost Air Monitoring Sensors
May 10, 2021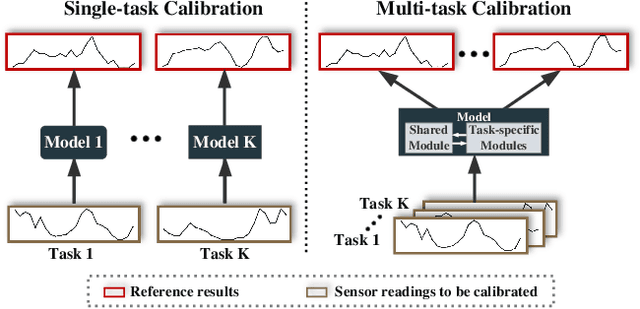
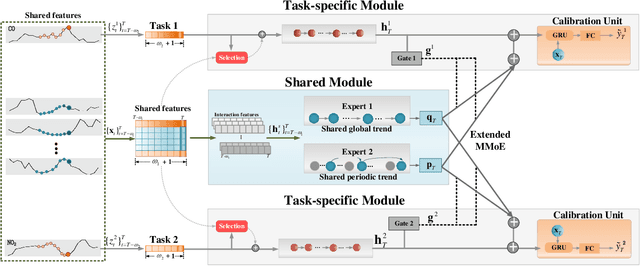
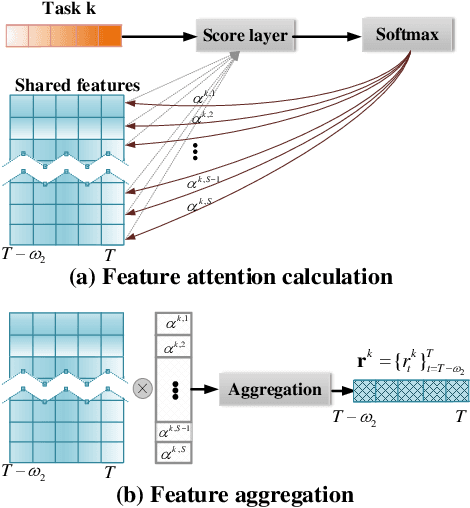
The advances of sensor technology enable people to monitor air quality through widely distributed low-cost sensors. However, measurements from these sensors usually encounter high biases and require a calibration step to reach an acceptable performance in down-streaming analytical tasks. Most existing calibration methods calibrate one type of sensor at a time, which we call single-task calibration. Despite the popularity of this single-task schema, it may neglect interactions among calibration tasks of different sensors, which encompass underlying information to promote calibration performance. In this paper, we propose a multi-task calibration network (MTNet) to calibrate multiple sensors (e.g., carbon monoxide and nitrogen oxide sensors) simultaneously, modeling the interactions among tasks. MTNet consists of a single shared module, and several task-specific modules. Specifically, in the shared module, we extend the multi-gate mixture-of-experts structure to harmonize the task conflicts and correlations among different tasks; in each task-specific module, we introduce a feature selection strategy to customize the input for the specific task. These improvements allow MTNet to learn interaction information shared across different tasks, and task-specific information for each calibration task as well. We evaluate MTNet on three real-world datasets and compare it with several established baselines. The experimental results demonstrate that MTNet achieves the state-of-the-art performance.
Long-Term, in-the-Wild Study of Feedback about Speech Intelligibility for K-12 Students Attending Class via a Telepresence Robot
Aug 24, 2021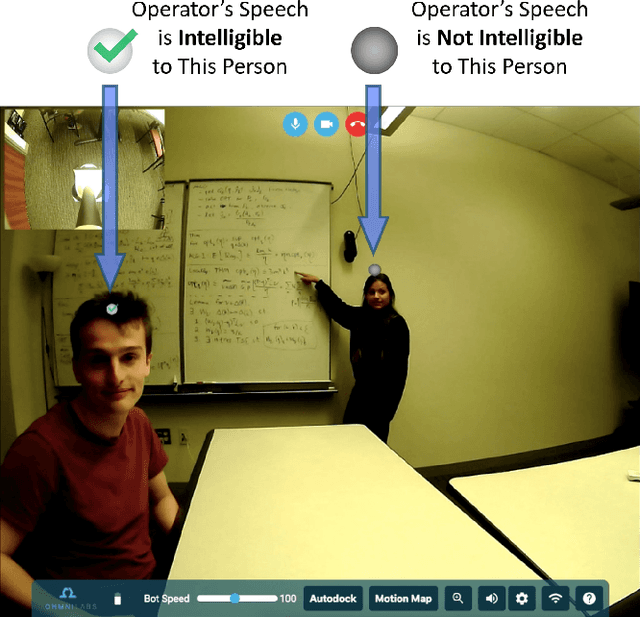

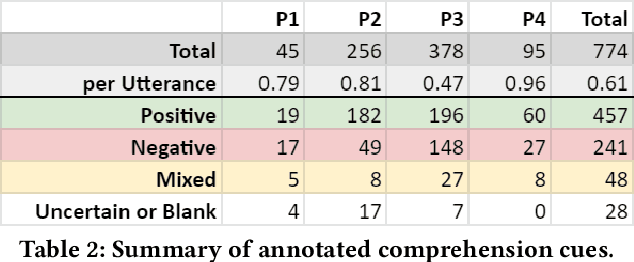
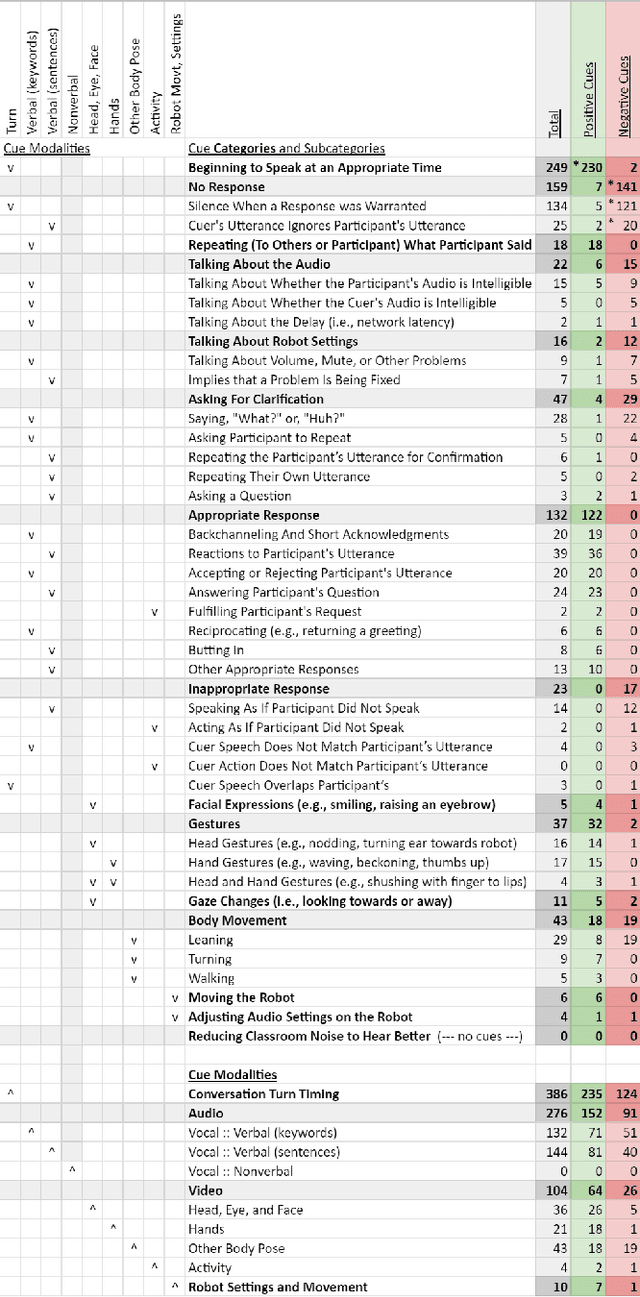
Telepresence robots offer presence, embodiment, and mobility to remote users, making them promising options for homebound K-12 students. It is difficult, however, for robot operators to know how well they are being heard in remote and noisy classroom environments. One solution is to estimate the operator's speech intelligibility to their listeners in order to provide feedback about it to the operator. This work contributes the first evaluation of a speech intelligibility feedback system for homebound K-12 students attending class remotely. In our four long-term, in-the-wild deployments we found that students speak at different volumes instead of adjusting the robot's volume, and that detailed audio calibration and network latency feedback are needed. We also contribute the first findings about the types and frequencies of multimodal comprehension cues given to homebound students by listeners in the classroom. By annotating and categorizing over 700 cues, we found that the most common cue modalities were conversation turn timing and verbal content. Conversation turn timing cues occurred more frequently overall, whereas verbal content cues contained more information and might be the most frequent modality for negative cues. Our work provides recommendations for telepresence systems that could intervene to ensure that remote users are being heard.
ICDAR 2021 Competition on Scientific Literature Parsing
Jun 08, 2021
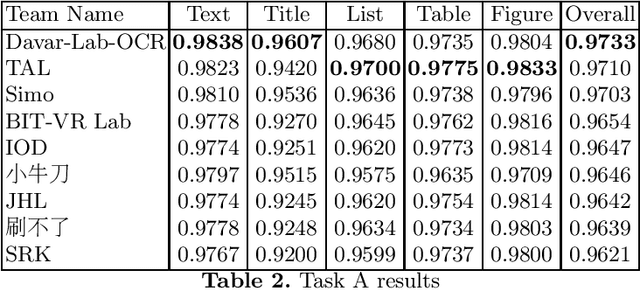
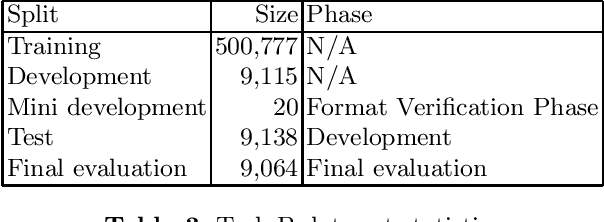
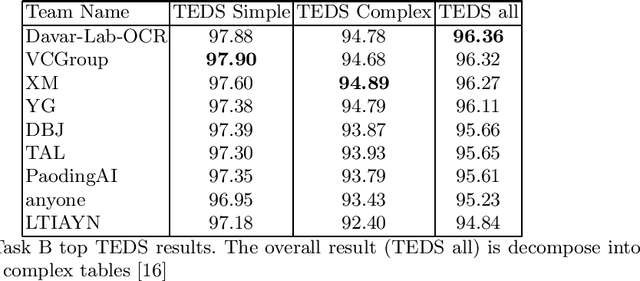
Scientific literature contain important information related to cutting-edge innovations in diverse domains. Advances in natural language processing have been driving the fast development in automated information extraction from scientific literature. However, scientific literature is often available in unstructured PDF format. While PDF is great for preserving basic visual elements, such as characters, lines, shapes, etc., on a canvas for presentation to humans, automatic processing of the PDF format by machines presents many challenges. With over 2.5 trillion PDF documents in existence, these issues are prevalent in many other important application domains as well. Our ICDAR 2021 Scientific Literature Parsing Competition (ICDAR2021-SLP) aims to drive the advances specifically in document understanding. ICDAR2021-SLP leverages the PubLayNet and PubTabNet datasets, which provide hundreds of thousands of training and evaluation examples. In Task A, Document Layout Recognition, submissions with the highest performance combine object detection and specialised solutions for the different categories. In Task B, Table Recognition, top submissions rely on methods to identify table components and post-processing methods to generate the table structure and content. Results from both tasks show an impressive performance and opens the possibility for high performance practical applications.
Enriched Music Representations with Multiple Cross-modal Contrastive Learning
Apr 01, 2021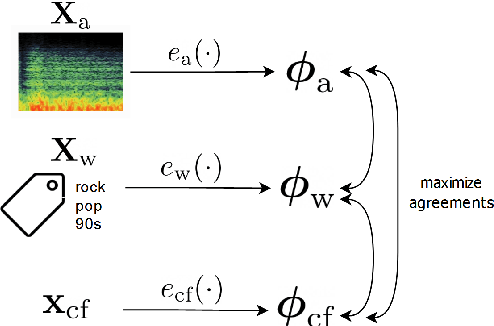
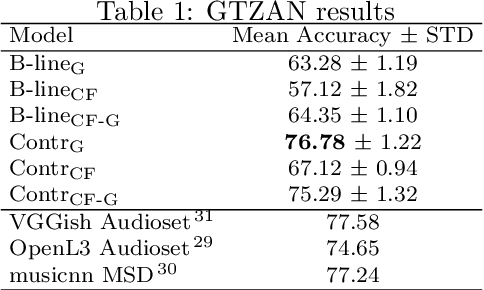
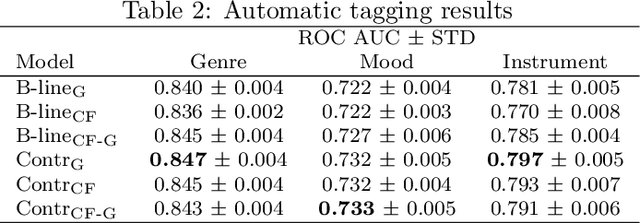
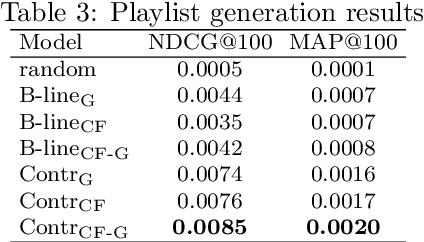
Modeling various aspects that make a music piece unique is a challenging task, requiring the combination of multiple sources of information. Deep learning is commonly used to obtain representations using various sources of information, such as the audio, interactions between users and songs, or associated genre metadata. Recently, contrastive learning has led to representations that generalize better compared to traditional supervised methods. In this paper, we present a novel approach that combines multiple types of information related to music using cross-modal contrastive learning, allowing us to learn an audio feature from heterogeneous data simultaneously. We align the latent representations obtained from playlists-track interactions, genre metadata, and the tracks' audio, by maximizing the agreement between these modality representations using a contrastive loss. We evaluate our approach in three tasks, namely, genre classification, playlist continuation and automatic tagging. We compare the performances with a baseline audio-based CNN trained to predict these modalities. We also study the importance of including multiple sources of information when training our embedding model. The results suggest that the proposed method outperforms the baseline in all the three downstream tasks and achieves comparable performance to the state-of-the-art.
Evaluating Fairness in Argument Retrieval
Aug 23, 2021
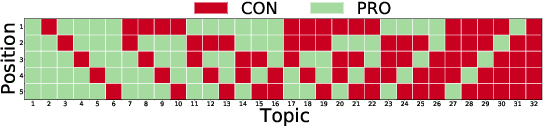
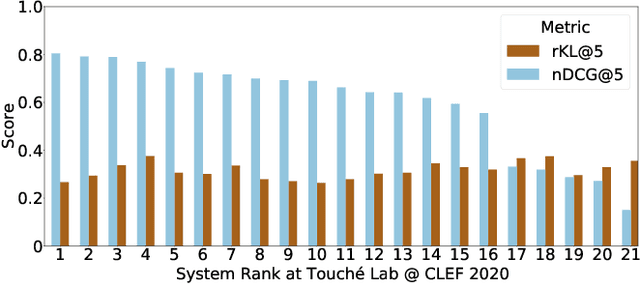

Existing commercial search engines often struggle to represent different perspectives of a search query. Argument retrieval systems address this limitation of search engines and provide both positive (PRO) and negative (CON) perspectives about a user's information need on a controversial topic (e.g., climate change). The effectiveness of such argument retrieval systems is typically evaluated based on topical relevance and argument quality, without taking into account the often differing number of documents shown for the argument stances (PRO or CON). Therefore, systems may retrieve relevant passages, but with a biased exposure of arguments. In this work, we analyze a range of non-stochastic fairness-aware ranking and diversity metrics to evaluate the extent to which argument stances are fairly exposed in argument retrieval systems. Using the official runs of the argument retrieval task Touch\'e at CLEF 2020, as well as synthetic data to control the amount and order of argument stances in the rankings, we show that systems with the best effectiveness in terms of topical relevance are not necessarily the most fair or the most diverse in terms of argument stance. The relationships we found between (un)fairness and diversity metrics shed light on how to evaluate group fairness -- in addition to topical relevance -- in argument retrieval settings.
COMBO: a new module for EUD parsing
Jul 08, 2021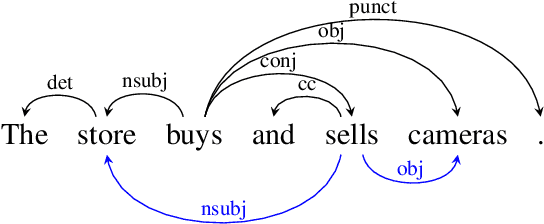

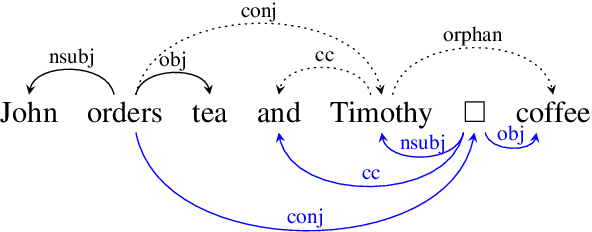
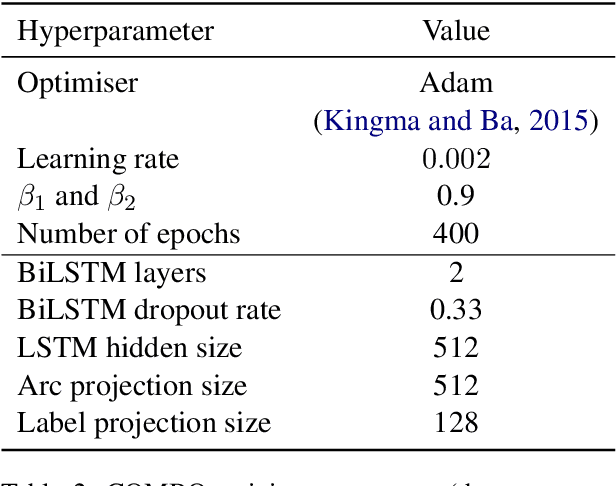
We introduce the COMBO-based approach for EUD parsing and its implementation, which took part in the IWPT 2021 EUD shared task. The goal of this task is to parse raw texts in 17 languages into Enhanced Universal Dependencies (EUD). The proposed approach uses COMBO to predict UD trees and EUD graphs. These structures are then merged into the final EUD graphs. Some EUD edge labels are extended with case information using a single language-independent expansion rule. In the official evaluation, the solution ranked fourth, achieving an average ELAS of 83.79%. The source code is available at https://gitlab.clarin-pl.eu/syntactic-tools/combo.