 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Emotion Recognition with Incomplete Labels Using Modified Multi-task Learning Technique
Jul 09, 2021
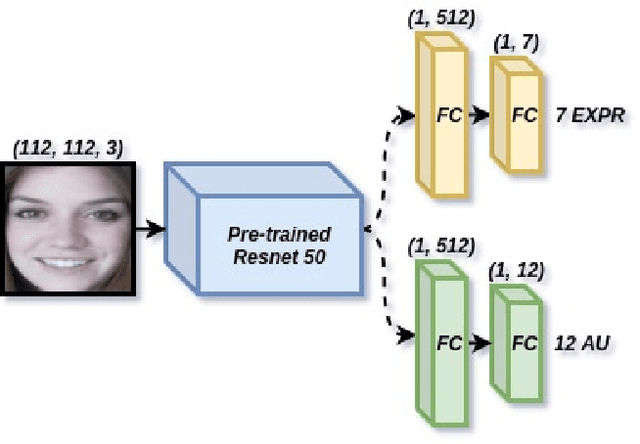
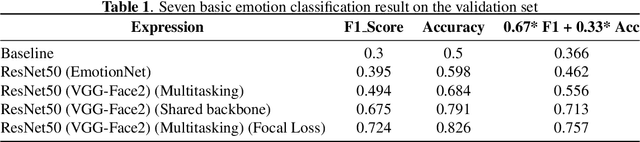
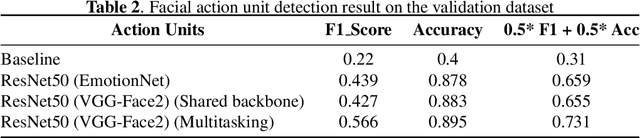
The task of predicting affective information in the wild such as seven basic emotions or action units from human faces has gradually become more interesting due to the accessibility and availability of massive annotated datasets. In this study, we propose a method that utilizes the association between seven basic emotions and twelve action units from the AffWild2 dataset. The method based on the architecture of ResNet50 involves the multi-task learning technique for the incomplete labels of the two tasks. By combining the knowledge for two correlated tasks, both performances are improved by a large margin compared to those with the model employing only one kind of label.
Argument Linking: A Survey and Forecast
Jul 18, 2021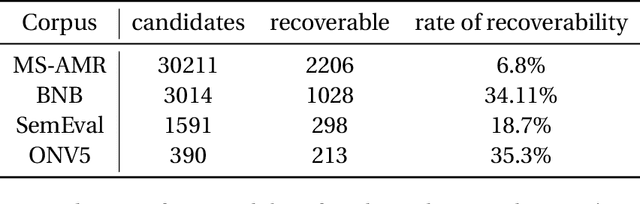

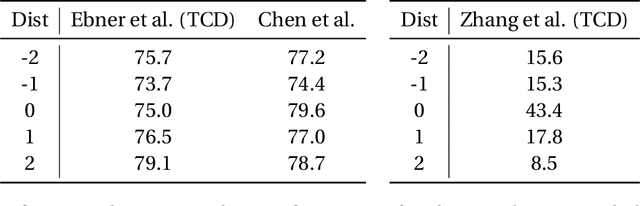

Semantic role labeling (SRL) -- identifying the semantic relationships between a predicate and other constituents in the same sentence -- is a well-studied task in natural language understanding (NLU). However, many of these relationships are evident only at the level of the document, as a role for a predicate in one sentence may often be filled by an argument in a different one. This more general task, known as implicit semantic role labeling or argument linking, has received increased attention in recent years, as researchers have recognized its centrality to information extraction and NLU. This paper surveys the literature on argument linking and identifies several notable shortcomings of existing approaches that indicate the paths along which future research effort could most profitably be spent.
Improving Compositionality of Neural Networks by Decoding Representations to Inputs
Jun 01, 2021
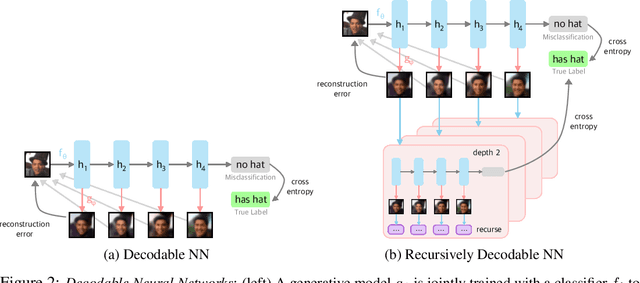
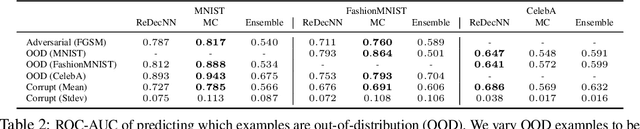

In traditional software programs, we take for granted how easy it is to debug code by tracing program logic from variables back to input, apply unit tests and assertion statements to block erroneous behavior, and compose programs together. But as the programs we write grow more complex, it becomes hard to apply traditional software to applications like computer vision or natural language. Although deep learning programs have demonstrated strong performance on these applications, they sacrifice many of the functionalities of traditional software programs. In this paper, we work towards bridging the benefits of traditional and deep learning programs by jointly training a generative model to constrain neural network activations to "decode" back to inputs. Doing so enables practitioners to probe and track information encoded in activation(s), apply assertion-like constraints on what information is encoded in an activation, and compose separate neural networks together in a plug-and-play fashion. In our experiments, we demonstrate applications of decodable representations to out-of-distribution detection, adversarial examples, calibration, and fairness -- while matching standard neural networks in accuracy.
Support-Set Based Cross-Supervision for Video Grounding
Aug 24, 2021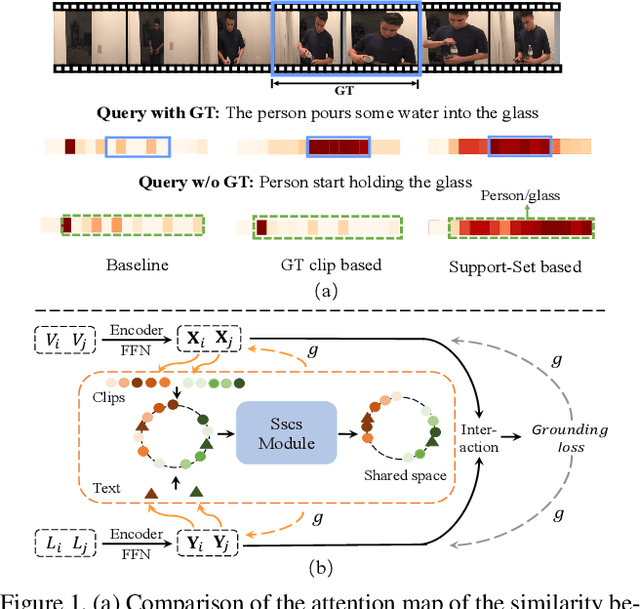
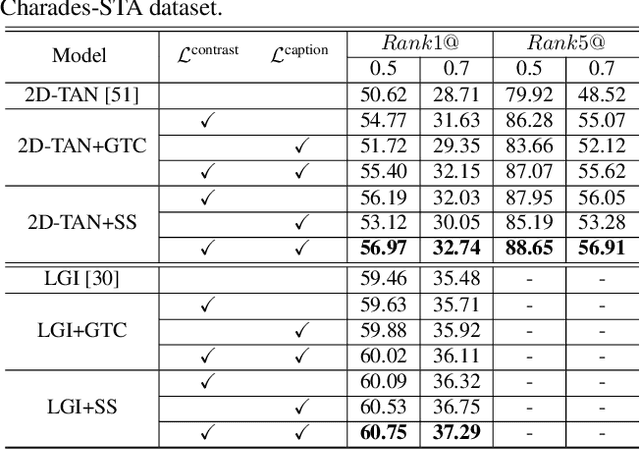

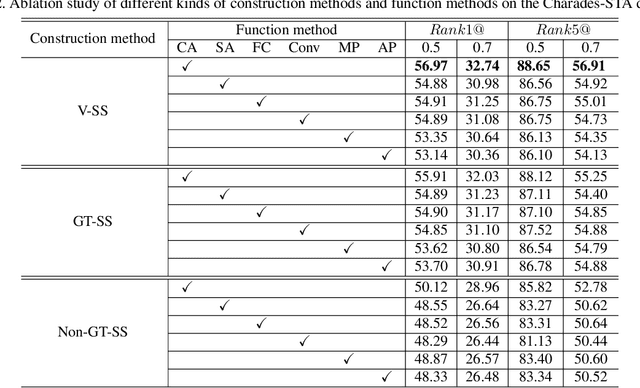
Current approaches for video grounding propose kinds of complex architectures to capture the video-text relations, and have achieved impressive improvements. However, it is hard to learn the complicated multi-modal relations by only architecture designing in fact. In this paper, we introduce a novel Support-set Based Cross-Supervision (Sscs) module which can improve existing methods during training phase without extra inference cost. The proposed Sscs module contains two main components, i.e., discriminative contrastive objective and generative caption objective. The contrastive objective aims to learn effective representations by contrastive learning, while the caption objective can train a powerful video encoder supervised by texts. Due to the co-existence of some visual entities in both ground-truth and background intervals, i.e., mutual exclusion, naively contrastive learning is unsuitable to video grounding. We address the problem by boosting the cross-supervision with the support-set concept, which collects visual information from the whole video and eliminates the mutual exclusion of entities. Combined with the original objectives, Sscs can enhance the abilities of multi-modal relation modeling for existing approaches. We extensively evaluate Sscs on three challenging datasets, and show that our method can improve current state-of-the-art methods by large margins, especially 6.35% in terms of R1@0.5 on Charades-STA.
VALUE: A Multi-Task Benchmark for Video-and-Language Understanding Evaluation
Jun 08, 2021

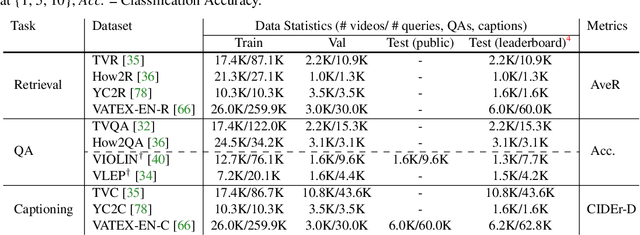
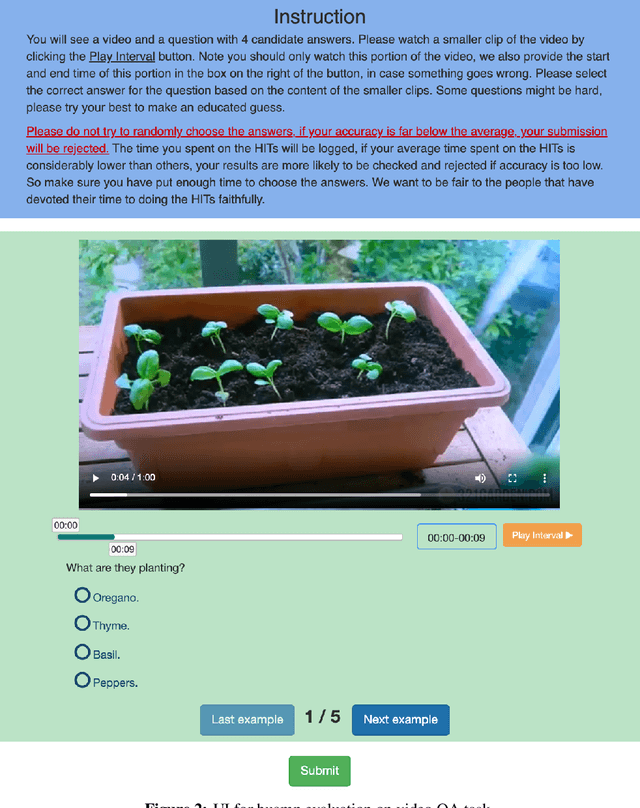
Most existing video-and-language (VidL) research focuses on a single dataset, or multiple datasets of a single task. In reality, a truly useful VidL system is expected to be easily generalizable to diverse tasks, domains, and datasets. To facilitate the evaluation of such systems, we introduce Video-And-Language Understanding Evaluation (VALUE) benchmark, an assemblage of 11 VidL datasets over 3 popular tasks: (i) text-to-video retrieval; (ii) video question answering; and (iii) video captioning. VALUE benchmark aims to cover a broad range of video genres, video lengths, data volumes, and task difficulty levels. Rather than focusing on single-channel videos with visual information only, VALUE promotes models that leverage information from both video frames and their associated subtitles, as well as models that share knowledge across multiple tasks. We evaluate various baseline methods with and without large-scale VidL pre-training, and systematically investigate the impact of video input channels, fusion methods, and different video representations. We also study the transferability between tasks, and conduct multi-task learning under different settings. The significant gap between our best model and human performance calls for future study for advanced VidL models. VALUE is available at https://value-leaderboard.github.io/.
StyleAugment: Learning Texture De-biased Representations by Style Augmentation without Pre-defined Textures
Aug 24, 2021
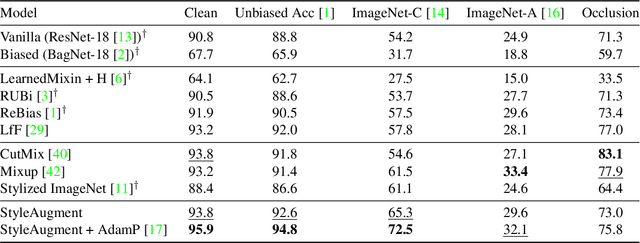


Recent powerful vision classifiers are biased towards textures, while shape information is overlooked by the models. A simple attempt by augmenting training images using the artistic style transfer method, called Stylized ImageNet, can reduce the texture bias. However, Stylized ImageNet approach has two drawbacks in fidelity and diversity. First, the generated images show low image quality due to the significant semantic gap betweeen natural images and artistic paintings. Also, Stylized ImageNet training samples are pre-computed before training, resulting in showing the lack of diversity for each sample. We propose a StyleAugment by augmenting styles from the mini-batch. StyleAugment does not rely on the pre-defined style references, but generates augmented images on-the-fly by natural images in the mini-batch for the references. Hence, StyleAugment let the model observe abundant confounding cues for each image by on-the-fly the augmentation strategy, while the augmented images are more realistic than artistic style transferred images. We validate the effectiveness of StyleAugment in the ImageNet dataset with robustness benchmarks, such as texture de-biased accuracy, corruption robustness, natural adversarial samples, and occlusion robustness. StyleAugment shows better generalization performances than previous unsupervised de-biasing methods and state-of-the-art data augmentation methods in our experiments.
Improving ClusterGAN Using Self-AugmentedInformation Maximization of Disentangling LatentSpaces
Jul 27, 2021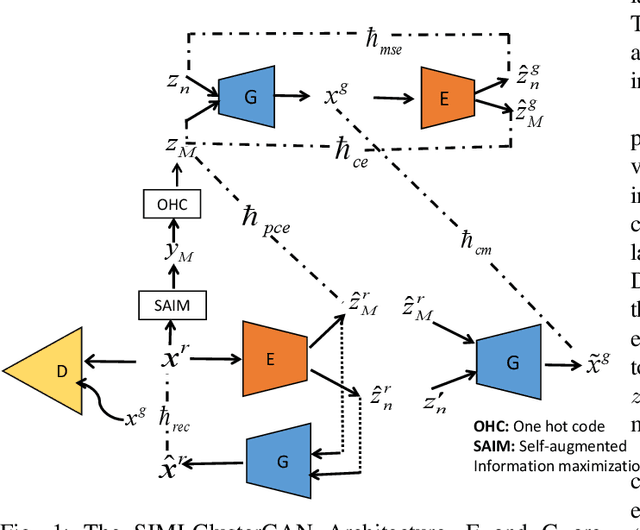



The Latent Space Clustering in Generative adversarial networks (ClusterGAN) method has been successful with high-dimensional data. However, the method assumes uniformlydistributed priors during the generation of modes, which isa restrictive assumption in real-world data and cause loss ofdiversity in the generated modes. In this paper, we proposeself-augmentation information maximization improved Clus-terGAN (SIMI-ClusterGAN) to learn the distinctive priorsfrom the data. The proposed SIMI-ClusterGAN consists offour deep neural networks: self-augmentation prior network,generator, discriminator and clustering inference autoencoder.The proposed method has been validated using seven bench-mark data sets and has shown improved performance overstate-of-the art methods. To demonstrate the superiority ofSIMI-ClusterGAN performance on imbalanced dataset, wehave discussed two imbalanced conditions on MNIST datasetswith one-class imbalance and three classes imbalanced cases.The results highlight the advantages of SIMI-ClusterGAN.
Integrated Sensing and Communication-assisted Orthogonal Time Frequency Space Transmission for Vehicular Networks
May 11, 2021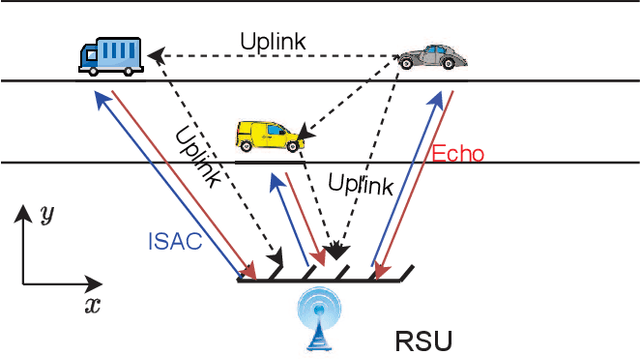
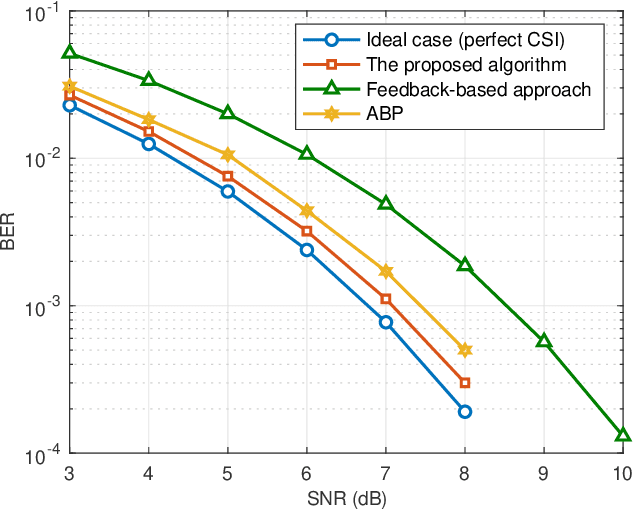
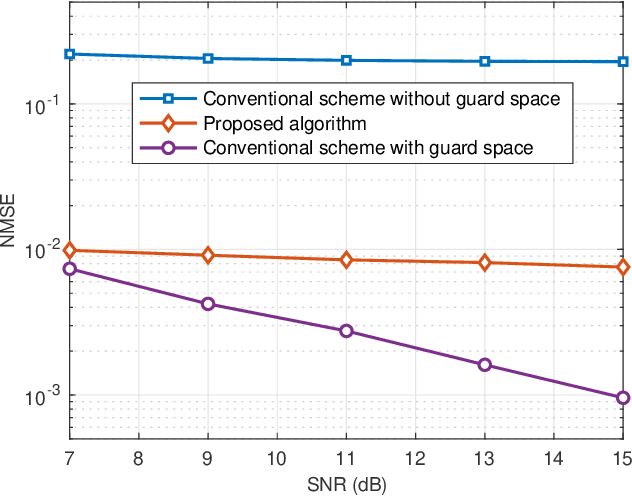
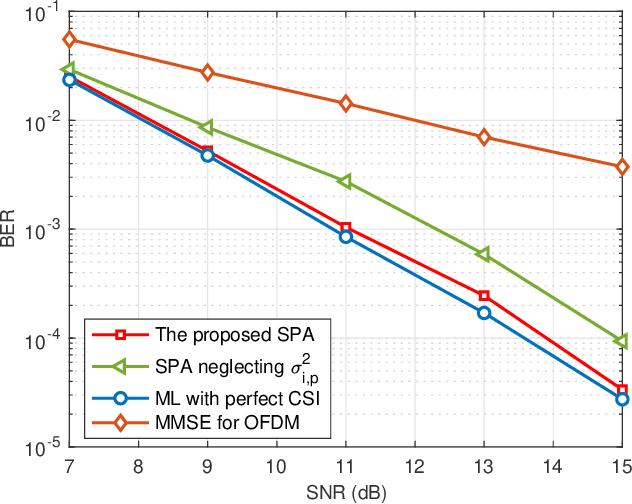
Orthogonal time frequency space (OTFS) modulation is a promising candidate for supporting reliable information transmission in high-mobility vehicular networks. In this paper, we consider the employment of the integrated (radar) sensing and communication (ISAC) technique for assisting OTFS transmission in both uplink and downlink vehicular communication systems. Benefiting from the OTFS-ISAC signals, the roadside unit (RSU) is capable of simultaneously transmitting downlink information to the vehicles and estimating the sensing parameters of vehicles, e.g., locations and speeds, based on the reflected echoes. Then, relying on the estimated kinematic parameters of vehicles, the RSU can construct the topology of the vehicular network that enables the prediction of the vehicle states in the following time instant. Consequently, the RSU can effectively formulate the transmit downlink beamformers according to the predicted parameters to counteract the channel adversity such that the vehicles can directly detect the information without the need of performing channel estimation. As for the uplink transmission, the RSU can infer the delays and Dopplers associated with different channel paths based on the aforementioned dynamic topology of the vehicular network. Thus, inserting guard space as in conventional methods are not needed for uplink channel estimation which removes the required training overhead. Finally, an efficient uplink detector is proposed by taking into account the channel estimation uncertainty. Through numerical simulations, we demonstrate the benefits of the proposed ISAC-assisted OTFS transmission scheme.
Multi-channel Opus compression for far-field automatic speech recognition with a fixed bitrate budget
Jun 15, 2021

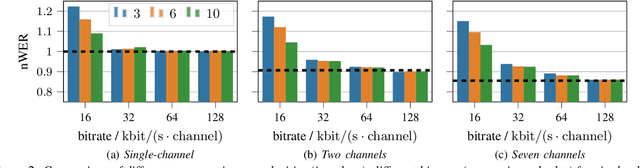
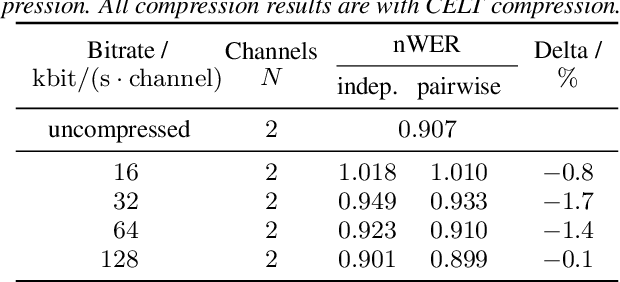
Automatic speech recognition (ASR) in the cloud allows the use of larger models and more powerful multi-channel signal processing front-ends compared to on-device processing. However, it also adds an inherent latency due to the transmission of the audio signal, especially when transmitting multiple channels of a microphone array. One way to reduce the network bandwidth requirements is client-side compression with a lossy codec such as Opus. However, this compression can have a detrimental effect especially on multi-channel ASR front-ends, due to the distortion and loss of spatial information introduced by the codec. In this publication, we propose an improved approach for the compression of microphone array signals based on Opus, using a modified joint channel coding approach and additionally introducing a multi-channel spatial decorrelating transform to reduce redundancy in the transmission. We illustrate the effect of the proposed approach on the spatial information retained in multi-channel signals after compression, and evaluate the performance on far-field ASR with a multi-channel beamforming front-end. We demonstrate that our approach can lead to a 37.5 % bitrate reduction or a 5.1 % relative word error rate reduction for a fixed bitrate budget in a seven channel setup.
An Interpretable Music Similarity Measure Based on Path Interestingness
Aug 04, 2021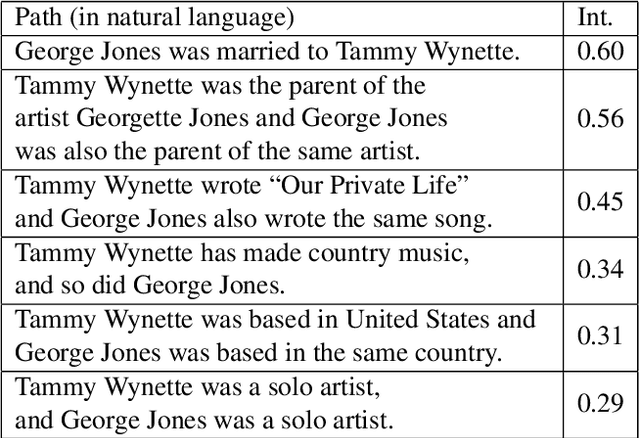

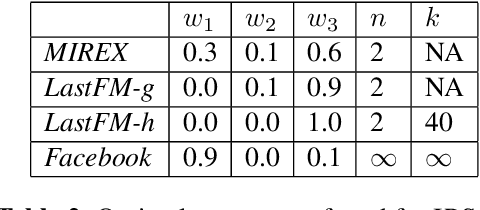
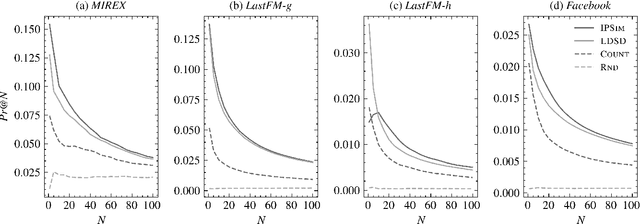
We introduce a novel and interpretable path-based music similarity measure. Our similarity measure assumes that items, such as songs and artists, and information about those items are represented in a knowledge graph. We find paths in the graph between a seed and a target item; we score those paths based on their interestingness; and we aggregate those scores to determine the similarity between the seed and the target. A distinguishing feature of our similarity measure is its interpretability. In particular, we can translate the most interesting paths into natural language, so that the causes of the similarity judgements can be readily understood by humans. We compare the accuracy of our similarity measure with other competitive path-based similarity baselines in two experimental settings and with four datasets. The results highlight the validity of our approach to music similarity, and demonstrate that path interestingness scores can be the basis of an accurate and interpretable similarity measure.