 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Combining Local and Global Viewpoint Planning for Fruit Coverage
Aug 18, 2021
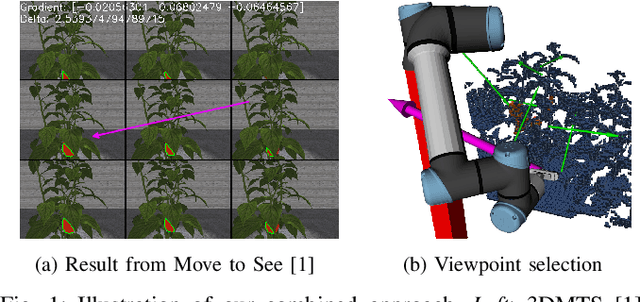
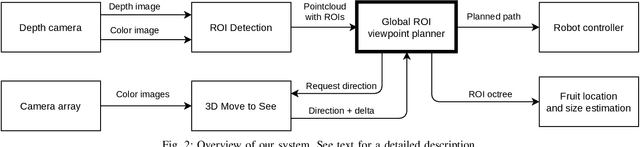
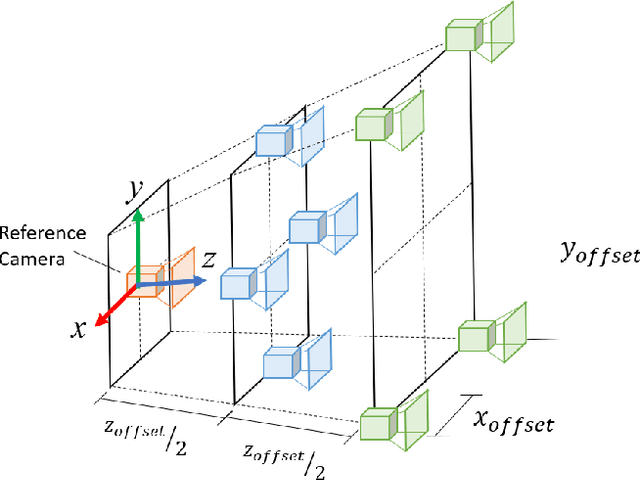

Obtaining 3D sensor data of complete plants or plant parts (e.g., the crop or fruit) is difficult due to their complex structure and a high degree of occlusion. However, especially for the estimation of the position and size of fruits, it is necessary to avoid occlusions as much as possible and acquire sensor information of the relevant parts. Global viewpoint planners exist that suggest a series of viewpoints to cover the regions of interest up to a certain degree, but they usually prioritize global coverage and do not emphasize the avoidance of local occlusions. On the other hand, there are approaches that aim at avoiding local occlusions, but they cannot be used in larger environments since they only reach a local maximum of coverage. In this paper, we therefore propose to combine a local, gradient-based method with global viewpoint planning to enable local occlusion avoidance while still being able to cover large areas. Our simulated experiments with a robotic arm equipped with a camera array as well as an RGB-D camera show that this combination leads to a significantly increased coverage of the regions of interest compared to just applying global coverage planning.
Learning Dynamic Interpolation for Extremely Sparse Light Fields with Wide Baselines
Aug 18, 2021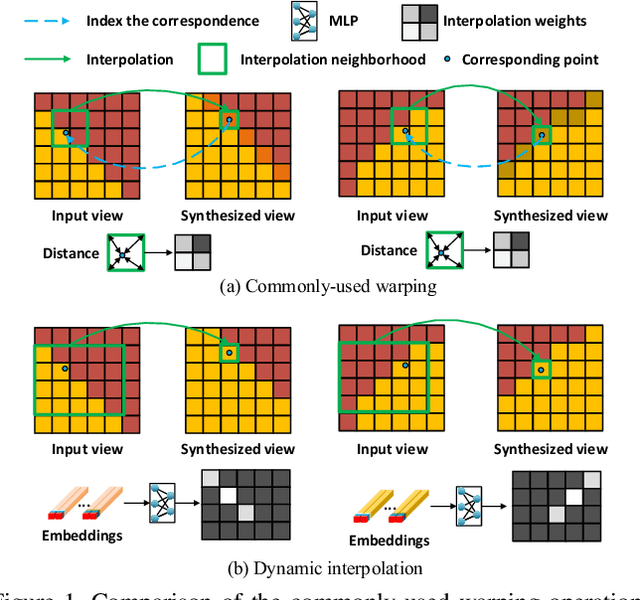
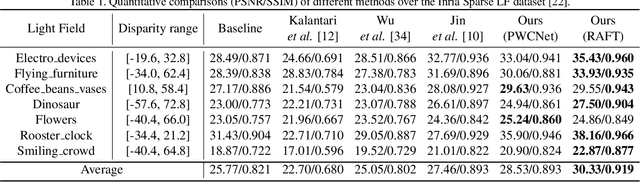
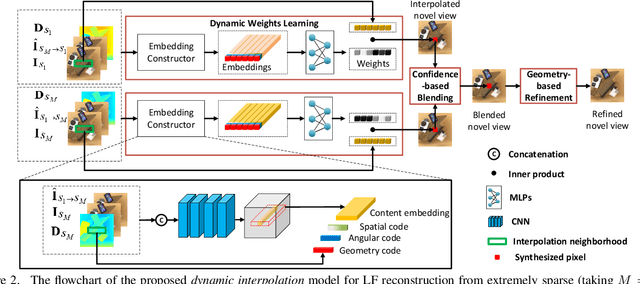
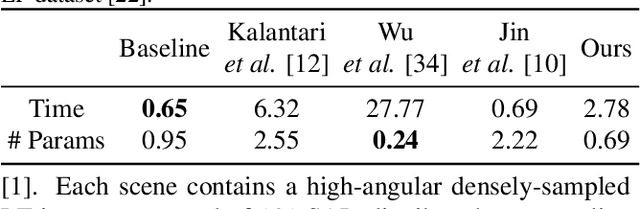
In this paper, we tackle the problem of dense light field (LF) reconstruction from sparsely-sampled ones with wide baselines and propose a learnable model, namely dynamic interpolation, to replace the commonly-used geometry warping operation. Specifically, with the estimated geometric relation between input views, we first construct a lightweight neural network to dynamically learn weights for interpolating neighbouring pixels from input views to synthesize each pixel of novel views independently. In contrast to the fixed and content-independent weights employed in the geometry warping operation, the learned interpolation weights implicitly incorporate the correspondences between the source and novel views and adapt to different image content information. Then, we recover the spatial correlation between the independently synthesized pixels of each novel view by referring to that of input views using a geometry-based spatial refinement module. We also constrain the angular correlation between the novel views through a disparity-oriented LF structure loss. Experimental results on LF datasets with wide baselines show that the reconstructed LFs achieve much higher PSNR/SSIM and preserve the LF parallax structure better than state-of-the-art methods. The source code is publicly available at https://github.com/MantangGuo/DI4SLF.
Measuring the Impact of Blockchain and Smart Contract on Construction Supply Chain Visibility
Apr 15, 2021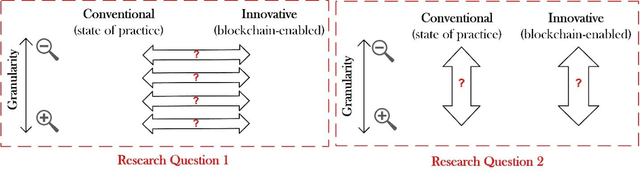

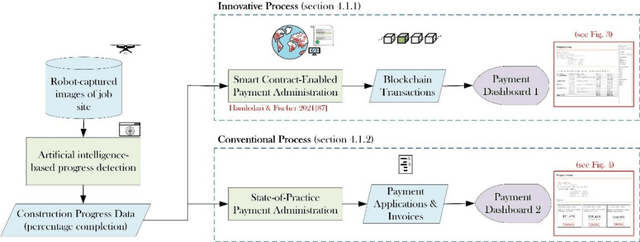

This work assesses the impact of blockchain and smart contract on the visibility of construction supply chain and in the context of payments (intersection of cash and product flows). It uses comparative empirical experiments (Charrette Test Method) to draw comparisons between the visibility of state-of-practice and blockchain-enabled payment systems in a commercial construction project. Comparisons were drawn across four levels of granularity. The findings are twofold: 1) blockchain improved information completeness and information accuracy respectively by an average 216% and 261% compared with the digital state-of-practice solution. The improvements were significantly more pronounced for inquiries that had higher product, trade, and temporal granularity; 2) blockchain-enabled solution was robust in the face of increased granularity, while the conventional solution experienced 50% and 66.7% decline respectively in completeness and accuracy of information. The paper concludes with a discussion of mechanisms contributing to visibility and technology adoption based on business objectives.
Self-Supervised Graph Learning with Hyperbolic Embedding for Temporal Health Event Prediction
Jun 09, 2021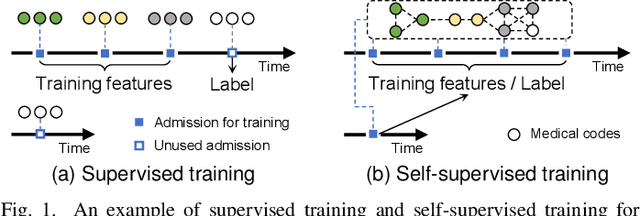
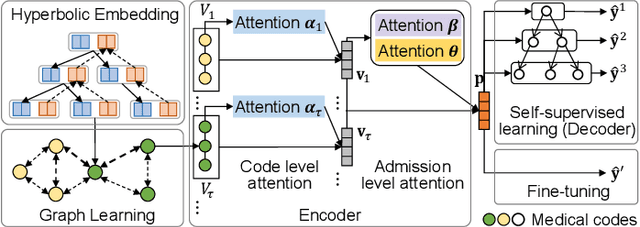
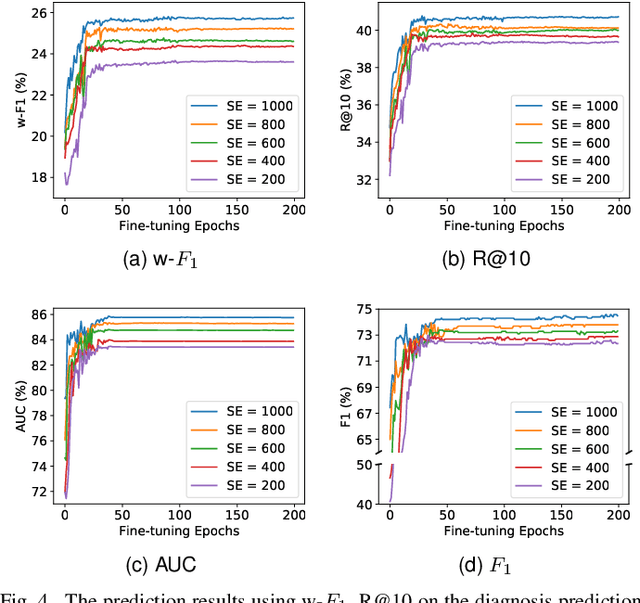
Electronic Health Records (EHR) have been heavily used in modern healthcare systems for recording patients' admission information to hospitals. Many data-driven approaches employ temporal features in EHR for predicting specific diseases, readmission times, or diagnoses of patients. However, most existing predictive models cannot fully utilize EHR data, due to an inherent lack of labels in supervised training for some temporal events. Moreover, it is hard for existing works to simultaneously provide generic and personalized interpretability. To address these challenges, we first propose a hyperbolic embedding method with information flow to pre-train medical code representations in a hierarchical structure. We incorporate these pre-trained representations into a graph neural network to detect disease complications, and design a multi-level attention method to compute the contributions of particular diseases and admissions, thus enhancing personalized interpretability. We present a new hierarchy-enhanced historical prediction proxy task in our self-supervised learning framework to fully utilize EHR data and exploit medical domain knowledge. We conduct a comprehensive set of experiments and case studies on widely used publicly available EHR datasets to verify the effectiveness of our model. The results demonstrate our model's strengths in both predictive tasks and interpretable abilities.
MODETR: Moving Object Detection with Transformers
Jun 21, 2021
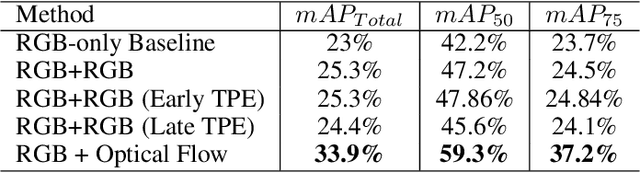

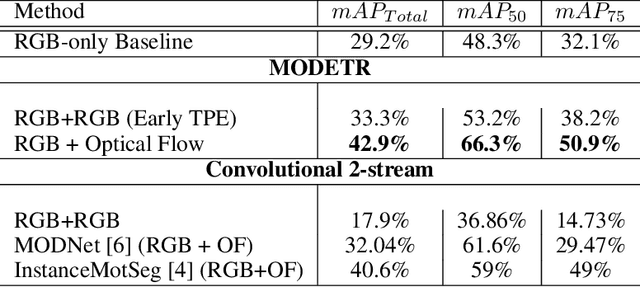
Moving Object Detection (MOD) is a crucial task for the Autonomous Driving pipeline. MOD is usually handled via 2-stream convolutional architectures that incorporates both appearance and motion cues, without considering the inter-relations between the spatial or motion features. In this paper, we tackle this problem through multi-head attention mechanisms, both across the spatial and motion streams. We propose MODETR; a Moving Object DEtection TRansformer network, comprised of multi-stream transformer encoders for both spatial and motion modalities, and an object transformer decoder that produces the moving objects bounding boxes using set predictions. The whole architecture is trained end-to-end using bi-partite loss. Several methods of incorporating motion cues with the Transformer model are explored, including two-stream RGB and Optical Flow (OF) methods, and multi-stream architectures that take advantage of sequence information. To incorporate the temporal information, we propose a new Temporal Positional Encoding (TPE) approach to extend the Spatial Positional Encoding(SPE) in DETR. We explore two architectural choices for that, balancing between speed and time. To evaluate the our network, we perform the MOD task on the KITTI MOD [6] data set. Results show significant 5% mAP of the Transformer network for MOD over the state-of-the art methods. Moreover, the proposed TPE encoding provides 10% mAP improvement over the SPE baseline.
Dropout Regularization for Self-Supervised Learning of Transformer Encoder Speech Representation
Jul 09, 2021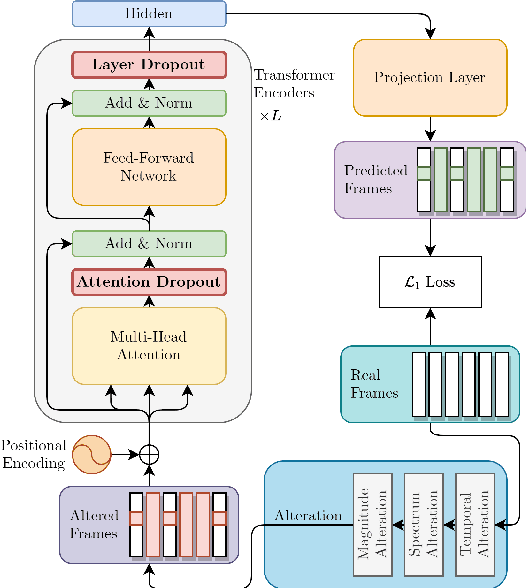
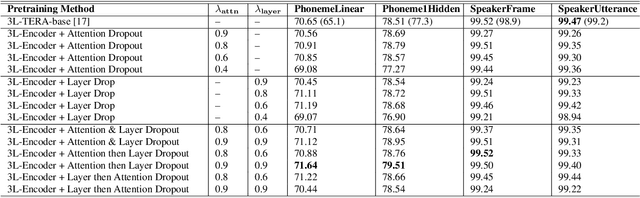

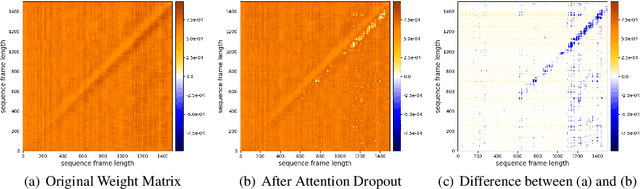
Predicting the altered acoustic frames is an effective way of self-supervised learning for speech representation. However, it is challenging to prevent the pretrained model from overfitting. In this paper, we proposed to introduce two dropout regularization methods into the pretraining of transformer encoder: (1) attention dropout, (2) layer dropout. Both of the two dropout methods encourage the model to utilize global speech information, and avoid just copying local spectrum features when reconstructing the masked frames. We evaluated the proposed methods on phoneme classification and speaker recognition tasks. The experiments demonstrate that our dropout approaches achieve competitive results, and improve the performance of classification accuracy on downstream tasks.
Extreme Face Inpainting with Sketch-Guided Conditional GAN
May 13, 2021
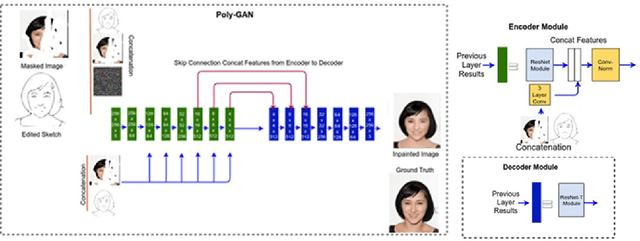
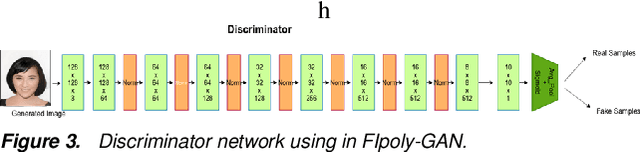

Recovering badly damaged face images is a useful yet challenging task, especially in extreme cases where the masked or damaged region is very large. One of the major challenges is the ability of the system to generalize on faces outside the training dataset. We propose to tackle this extreme inpainting task with a conditional Generative Adversarial Network (GAN) that utilizes structural information, such as edges, as a prior condition. Edge information can be obtained from the partially masked image and a structurally similar image or a hand drawing. In our proposed conditional GAN, we pass the conditional input in every layer of the encoder while maintaining consistency in the distributions between the learned weights and the incoming conditional input. We demonstrate the effectiveness of our method with badly damaged face examples.
Operational Learning-based Boundary Estimation in Electromagnetic Medical Imaging
Aug 04, 2021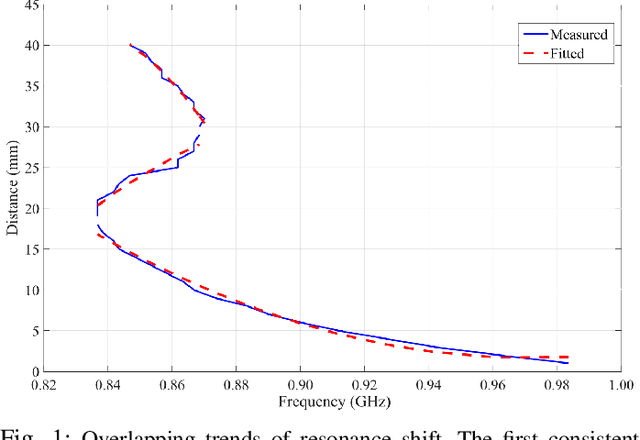
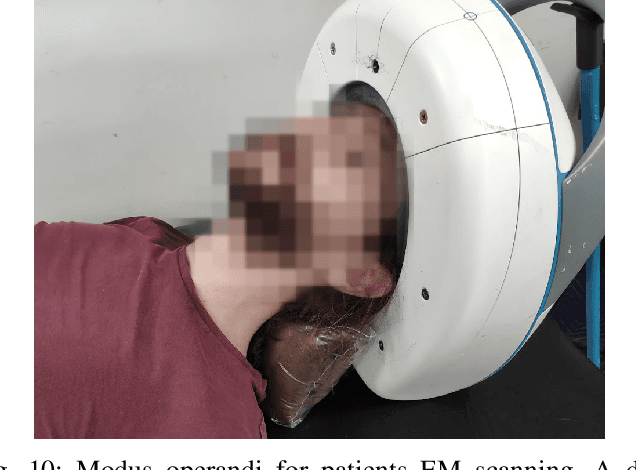
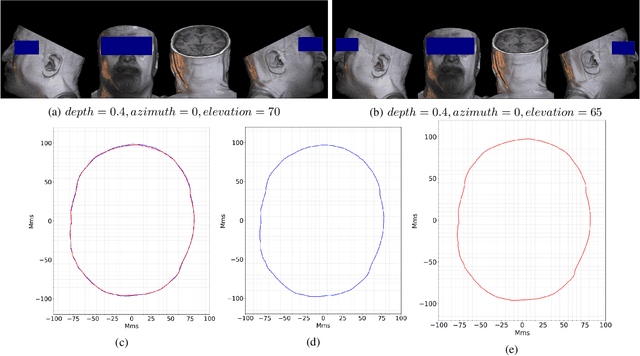
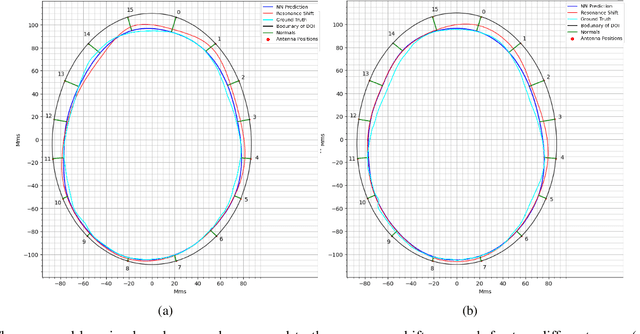
Incorporating boundaries of the imaging object as a priori information to imaging algorithms can significantly improve the performance of electromagnetic medical imaging systems. To avoid overly complicating the system by using different sensors and the adverse effect of the subject's movement, a learning-based method is proposed to estimate the boundary (external contour) of the imaged object using the same electromagnetic imaging data. While imaging techniques may discard the reflection coefficients for being dominant and uninformative for imaging, these parameters are made use of for boundary detection. The learned model is verified through independent clinical human trials by using a head imaging system with a 16-element antenna array that works across the band 0.7-1.6 GHz. The evaluation demonstrated that the model achieves average dissimilarity of 0.012 in Hu-moment while detecting head boundary. The model enables fast scan and image creation while eliminating the need for additional devices for accurate boundary estimation.
* Under Review
Emotion Recognition with Incomplete Labels Using Modified Multi-task Learning Technique
Jul 09, 2021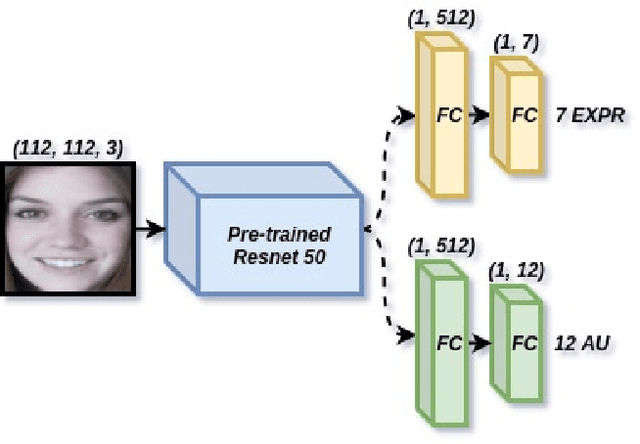
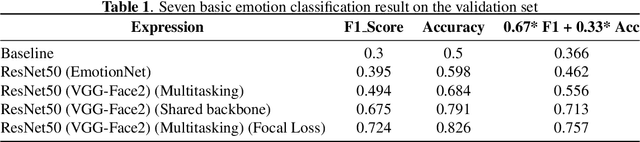
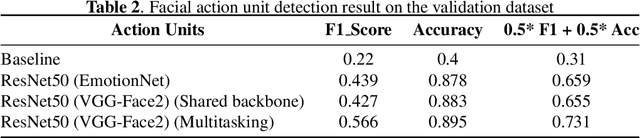
The task of predicting affective information in the wild such as seven basic emotions or action units from human faces has gradually become more interesting due to the accessibility and availability of massive annotated datasets. In this study, we propose a method that utilizes the association between seven basic emotions and twelve action units from the AffWild2 dataset. The method based on the architecture of ResNet50 involves the multi-task learning technique for the incomplete labels of the two tasks. By combining the knowledge for two correlated tasks, both performances are improved by a large margin compared to those with the model employing only one kind of label.
Large-Scale Modeling of Mobile User Click Behaviors Using Deep Learning
Aug 11, 2021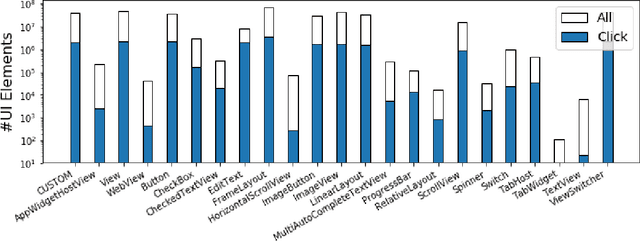
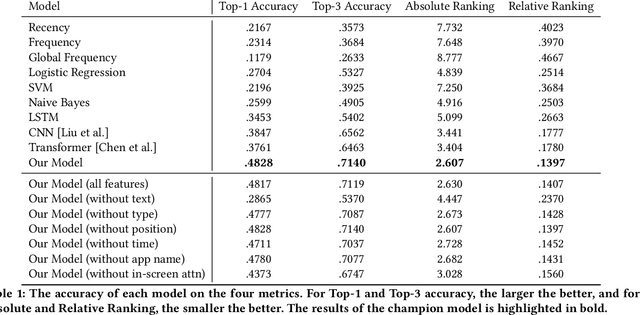
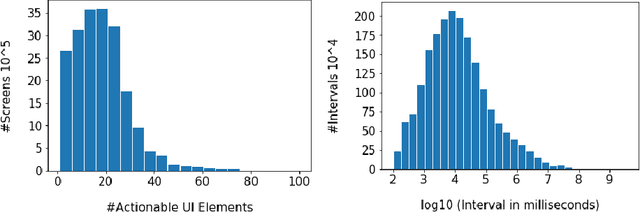
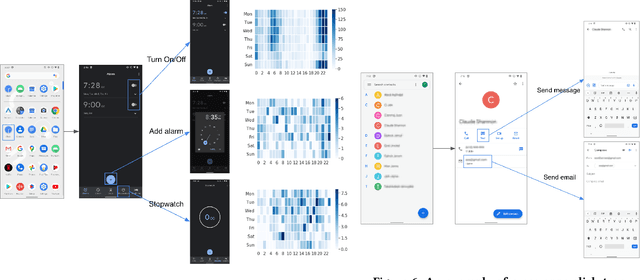
Modeling tap or click sequences of users on a mobile device can improve our understandings of interaction behavior and offers opportunities for UI optimization by recommending next element the user might want to click on. We analyzed a large-scale dataset of over 20 million clicks from more than 4,000 mobile users who opted in. We then designed a deep learning model that predicts the next element that the user clicks given the user's click history, the structural information of the UI screen, and the current context such as the time of the day. We thoroughly investigated the deep model by comparing it with a set of baseline methods based on the dataset. The experiments show that our model achieves 48% and 71% accuracy (top-1 and top-3) for predicting next clicks based on a held-out dataset of test users, which significantly outperformed all the baseline methods with a large margin. We discussed a few scenarios for integrating the model in mobile interaction and how users can potentially benefit from the model.