 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Localization Based Sequential Grouping for Continuous Speech Separation
Jul 14, 2021
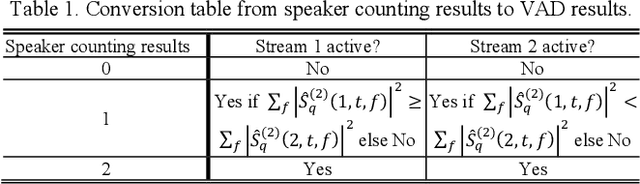
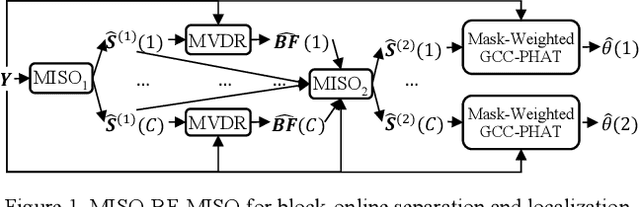
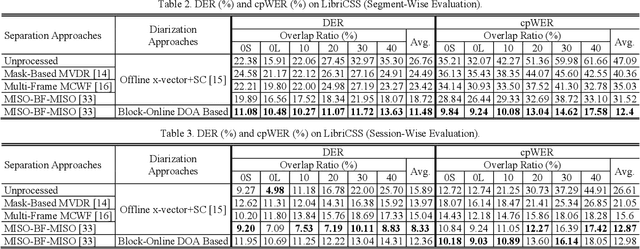
This study investigates robust speaker localization for con-tinuous speech separation and speaker diarization, where we use speaker directions to group non-contiguous segments of the same speaker. Assuming that speakers do not move and are located in different directions, the direction of arrival (DOA) information provides an informative cue for accurate sequential grouping and speaker diarization. Our system is block-online in the following sense. Given a block of frames with at most two speakers, we apply a two-speaker separa-tion model to separate (and enhance) the speakers, estimate the DOA of each separated speaker, and group the separation results across blocks based on the DOA estimates. Speaker diarization and speaker-attributed speech recognition results on the LibriCSS corpus demonstrate the effectiveness of the proposed algorithm.
A computational study on imputation methods for missing environmental data
Aug 21, 2021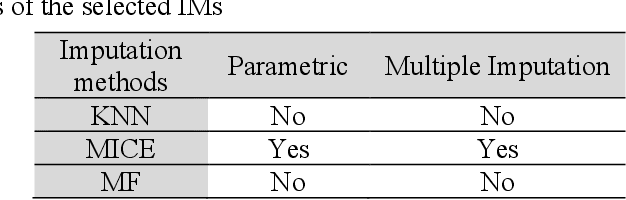

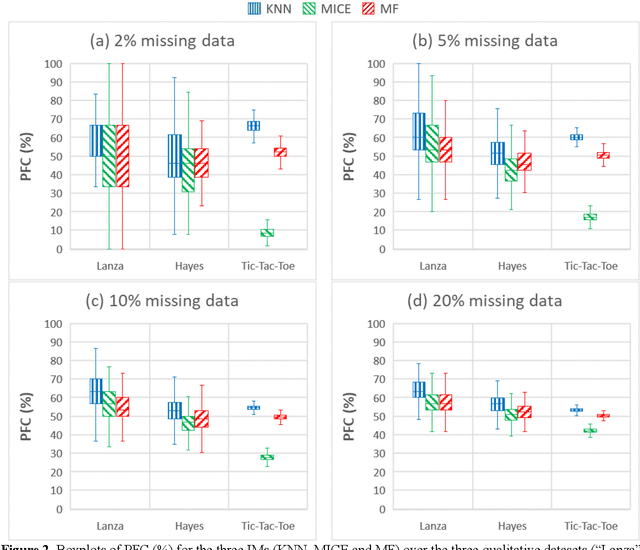
Data acquisition and recording in the form of databases are routine operations. The process of collecting data, however, may experience irregularities, resulting in databases with missing data. Missing entries might alter analysis efficiency and, consequently, the associated decision-making process. This paper focuses on databases collecting information related to the natural environment. Given the broad spectrum of recorded activities, these databases typically are of mixed nature. It is therefore relevant to evaluate the performance of missing data processing methods considering this characteristic. In this paper we investigate the performances of several missing data imputation methods and their application to the problem of missing data in environment. A computational study was performed to compare the method missForest (MF) with two other imputation methods, namely Multivariate Imputation by Chained Equations (MICE) and K-Nearest Neighbors (KNN). Tests were made on 10 pretreated datasets of various types. Results revealed that MF generally outperformed MICE and KNN in terms of imputation errors, with a more pronounced performance gap for mixed typed databases where MF reduced the imputation error up to 150%, when compared to the other methods. KNN was usually the fastest method. MF was then successfully applied to a case study on Quebec wastewater treatment plants performance monitoring. We believe that the present study demonstrates the pertinence of using MF as imputation method when dealing with missing environmental data.
Network psychometrics and cognitive network science open new ways for detecting, understanding and tackling the complexity of math anxiety: A review
Aug 31, 2021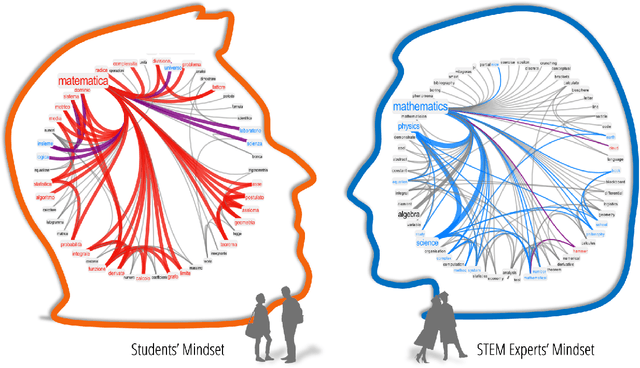
Math anxiety is a clinical pathology impairing cognitive processing in math-related contexts. Originally thought to affect only inexperienced, low-achieving students, recent investigations show how math anxiety is vastly diffused even among high-performing learners. This review of data-informed studies outlines math anxiety as a complex system that: (i) cripples well-being, self-confidence and information processing on both conscious and subconscious levels, (ii) can be transmitted by social interactions, like a pathogen, and worsened by distorted perceptions, (iii) affects roughly 20% of students in 63 out of 64 worldwide educational systems but correlates weakly with academic performance, and (iv) poses a concrete threat to students' well-being, computational literacy and career prospects in science. These patterns underline the crucial need to go beyond performance for estimating math anxiety. Recent advances with network psychometrics and cognitive network science provide ideal frameworks for detecting, interpreting and intervening upon such clinical condition. Merging education research, psychology and data science, the approaches reviewed here reconstruct psychological constructs as complex systems, represented either as multivariate correlation models (e.g. graph exploratory analysis) or as cognitive networks of semantic/emotional associations (e.g. free association networks or forma mentis networks). Not only can these interconnected networks detect otherwise hidden levels of math anxiety but - more crucially - they can unveil the specific layout of interacting factors, e.g. key sources and targets, behind math anxiety in a given cohort. As discussed here, these network approaches open concrete ways for unveiling students' perceptions, emotions and mental well-being, and can enable future powerful data-informed interventions untangling math anxiety.
Selective Intervention Planning using RMABs: Increasing Program Engagement to Improve Maternal and Child Health Outcomes
Mar 18, 2021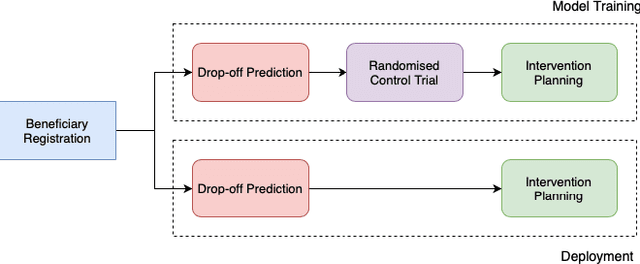
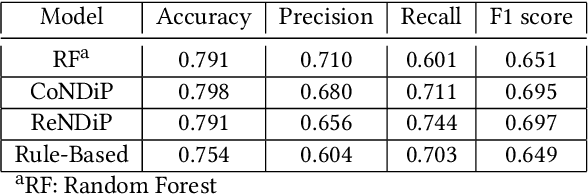
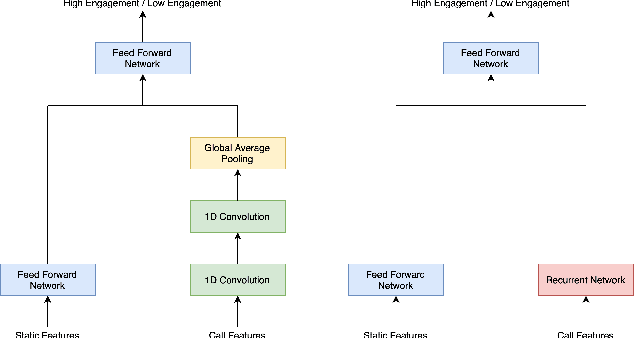
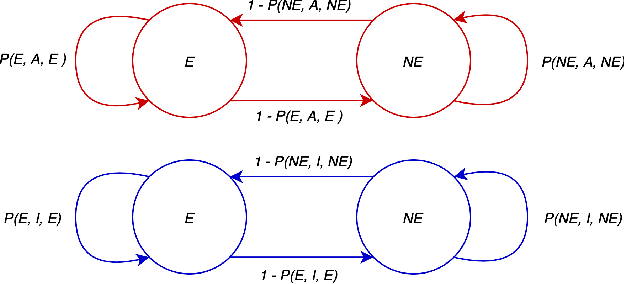
India has a maternal mortality ratio of 113 and child mortality ratio of 2830 per 100,000 live births. Lack of access to preventive care information is a major contributing factor for these deaths, especially in low-income households. We work with ARMMAN, a non-profit based in India, to further the use of call-based information programs by early-on identifying women who might not engage with these programs that are proven to affect health parameters positively. We analyzed anonymized call-records of over 300,000 women registered in an awareness program created by ARMMAN that uses cellphone calls to regularly disseminate health related information. We built machine learning based models to predict the long term engagement pattern from call logs and beneficiaries' demographic information, and discuss the applicability of this method in the real world through a pilot validation. Through a randomized controlled trial, we show that using our model's predictions to make interventions boosts engagement metrics by 14.3%. We then formulate the intervention planning problem as restless multi-armed bandits (RMABs), and present preliminary results using this approach.
Process Mining Model to Predict Mortality in Paralytic Ileus Patients
Aug 03, 2021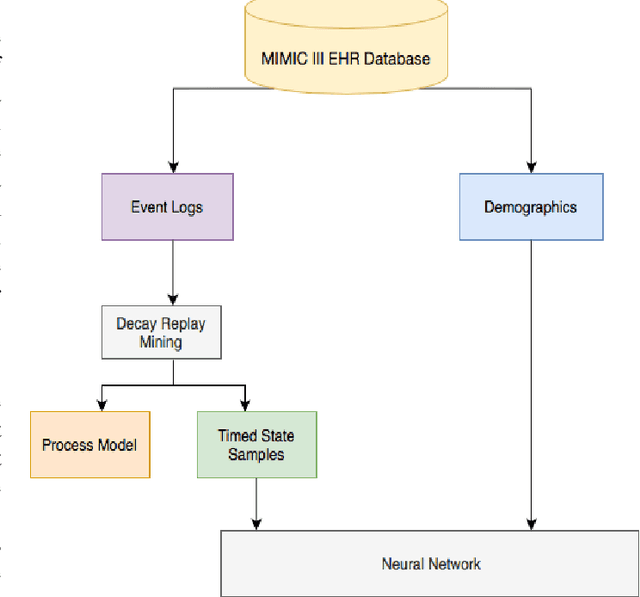
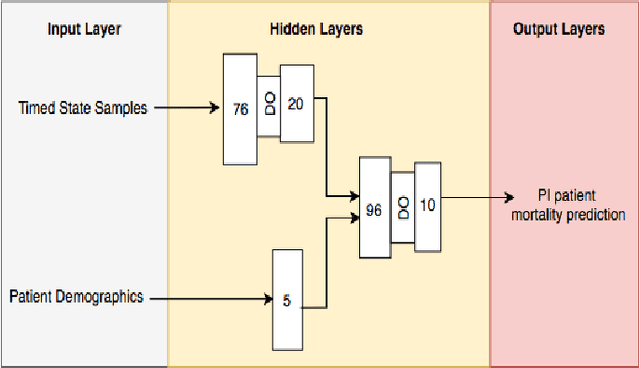
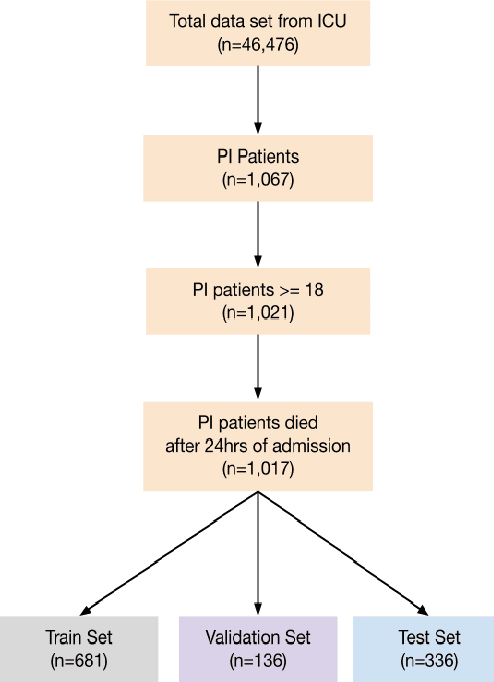
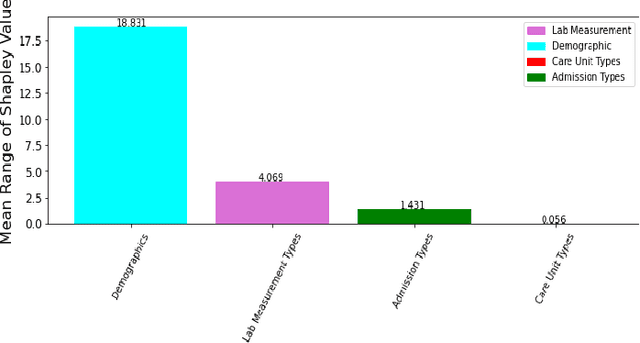
Paralytic Ileus (PI) patients are at high risk of death when admitted to the Intensive care unit (ICU), with mortality as high as 40\%. There is minimal research concerning PI patient mortality prediction. There is a need for more accurate prediction modeling for ICU patients diagnosed with PI. This paper demonstrates performance improvements in predicting the mortality of ICU patients diagnosed with PI after 24 hours of being admitted. The proposed framework, PMPI(Process Mining Model to predict mortality of PI patients), is a modification of the work used for prediction of in-hospital mortality for ICU patients with diabetes. PMPI demonstrates similar if not better performance with an Area under the ROC Curve (AUC) score of 0.82 compared to the best results of the existing literature. PMPI uses patient medical history, the time related to the events, and demographic information for prediction. The PMPI prediction framework has the potential to help medical teams in making better decisions for treatment and care for ICU patients with PI to increase their life expectancy.
More but Correct: Generating Diversified and Entity-revised Medical Response
Aug 03, 2021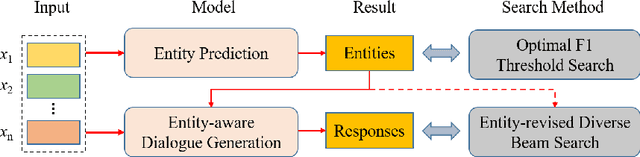
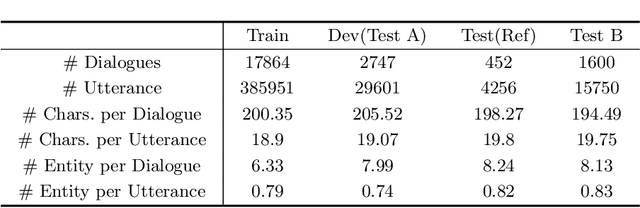
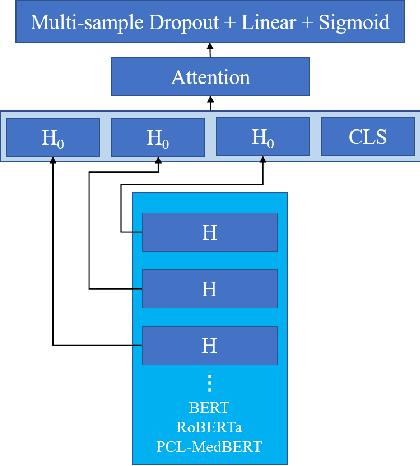
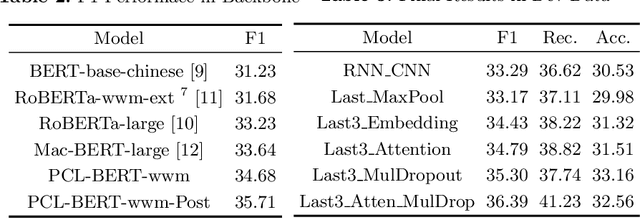
Medical Dialogue Generation (MDG) is intended to build a medical dialogue system for intelligent consultation, which can communicate with patients in real-time, thereby improving the efficiency of clinical diagnosis with broad application prospects. This paper presents our proposed framework for the Chinese MDG organized by the 2021 China conference on knowledge graph and semantic computing (CCKS) competition, which requires generating context-consistent and medically meaningful responses conditioned on the dialogue history. In our framework, we propose a pipeline system composed of entity prediction and entity-aware dialogue generation, by adding predicted entities to the dialogue model with a fusion mechanism, thereby utilizing information from different sources. At the decoding stage, we propose a new decoding mechanism named Entity-revised Diverse Beam Search (EDBS) to improve entity correctness and promote the length and quality of the final response. The proposed method wins both the CCKS and the International Conference on Learning Representations (ICLR) 2021 Workshop Machine Learning for Preventing and Combating Pandemics (MLPCP) Track 1 Entity-aware MED competitions, which demonstrate the practicality and effectiveness of our method.
Taylor saves for later: disentanglement for video prediction using Taylor representation
May 24, 2021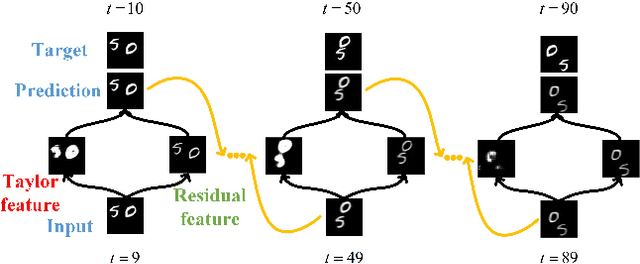
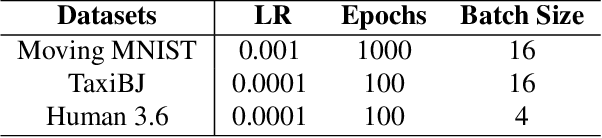
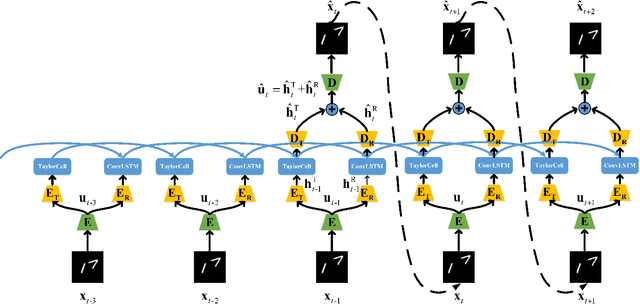
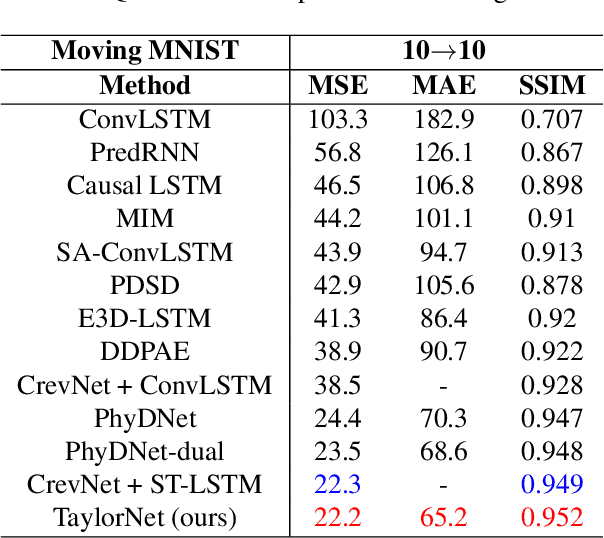
Video prediction is a challenging task with wide application prospects in meteorology and robot systems. Existing works fail to trade off short-term and long-term prediction performances and extract robust latent dynamics laws in video frames. We propose a two-branch seq-to-seq deep model to disentangle the Taylor feature and the residual feature in video frames by a novel recurrent prediction module (TaylorCell) and residual module. TaylorCell can expand the video frames' high-dimensional features into the finite Taylor series to describe the latent laws. In TaylorCell, we propose the Taylor prediction unit (TPU) and the memory correction unit (MCU). TPU employs the first input frame's derivative information to predict the future frames, avoiding error accumulation. MCU distills all past frames' information to correct the predicted Taylor feature from TPU. Correspondingly, the residual module extracts the residual feature complementary to the Taylor feature. On three generalist datasets (Moving MNIST, TaxiBJ, Human 3.6), our model outperforms or reaches state-of-the-art models, and ablation experiments demonstrate the effectiveness of our model in long-term prediction.
Modified Supervised Contrastive Learning for Detecting Anomalous Driving Behaviours
Sep 09, 2021


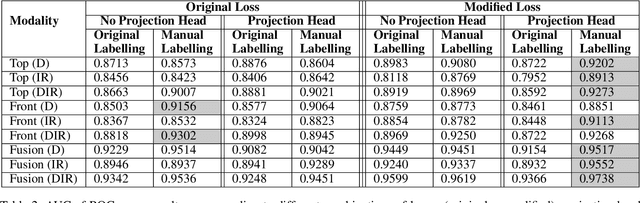
Detecting distracted driving behaviours is important to reduce millions of deaths and injuries occurring worldwide. Distracted or anomalous driving behaviours are deviations from the 'normal' driving that need to be identified correctly to alert the driver. However, these driving behaviours do not comprise of one specific type of driving style and their distribution can be different during training and testing phases of a classifier. We formulate this problem as a supervised contrastive learning approach to learn a visual representation to detect normal, and seen and unseen anomalous driving behaviours. We made a change to the standard contrastive loss function to adjust the similarity of negative pairs to aid the optimization. Normally, the (self) supervised contrastive framework contains an encoder followed by a projection head, which is omitted during testing phase as the encoding layers are considered to contain general visual representative information. However, we assert that for supervised contrastive learning task, including projection head will be beneficial. We showed our results on a Driver Anomaly Detection dataset that contains 783 minutes of video recordings of normal and anomalous driving behaviours of 31 drivers from various from top and front cameras (both depth and infrared). We also performed an extra step of fine tuning the labels in this dataset. Out of 9 video modalities combinations, our modified contrastive approach improved the ROC AUC on 7 in comparison to the baseline models (from 3.12% to 8.91% for different modalities); the remaining two models also had manual labelling. We performed statistical tests that showed evidence that our modifications perform better than the baseline contrastive models. Finally, the results showed that the fusion of depth and infrared modalities from top and front view achieved the best AUC ROC of 0.9738 and AUC PR of 0.9772.
Domain Adaptation without Model Transferring
Aug 03, 2021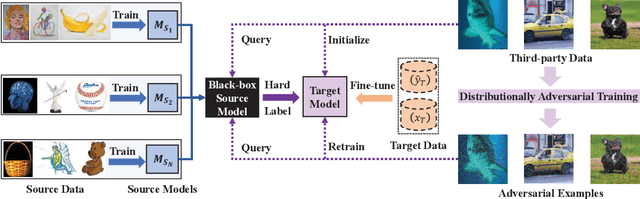
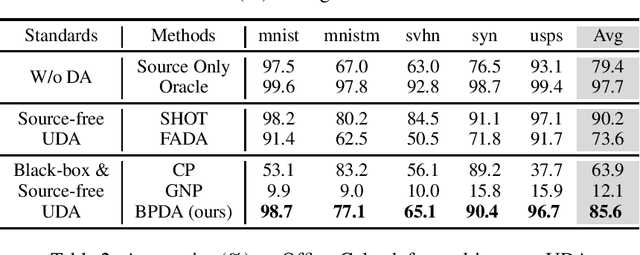
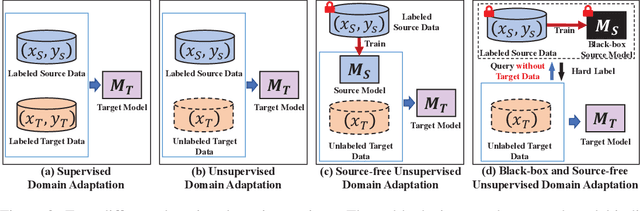
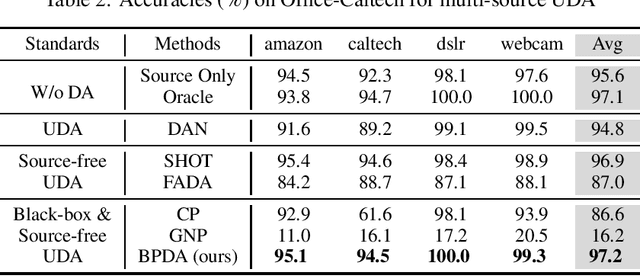
In recent years, researchers have been paying increasing attention to the threats brought by deep learning models to data security and privacy, especially in the field of domain adaptation. Existing unsupervised domain adaptation (UDA) methods can achieve promising performance without transferring data from source domain to target domain. However, UDA with representation alignment or self-supervised pseudo-labeling relies on the transferred source models. In many data-critical scenarios, methods based on model transferring may suffer from membership inference attacks and expose private data. In this paper, we aim to overcome a challenging new setting where the source models cannot be transferred to the target domain. We propose Domain Adaptation without Source Model, which refines information from source model. In order to gain more informative results, we further propose Distributionally Adversarial Training (DAT) to align the distribution of source data with that of target data. Experimental results on benchmarks of Digit-Five, Office-Caltech, Office-31, Office-Home, and DomainNet demonstrate the feasibility of our method without model transferring.
FlexParser -- the adaptive log file parser for continuous results in a changing world
Jun 06, 2021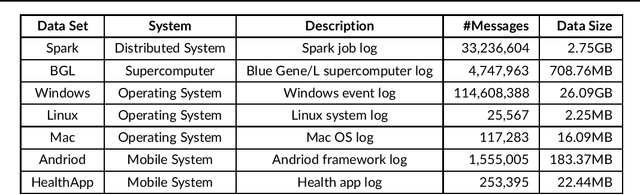
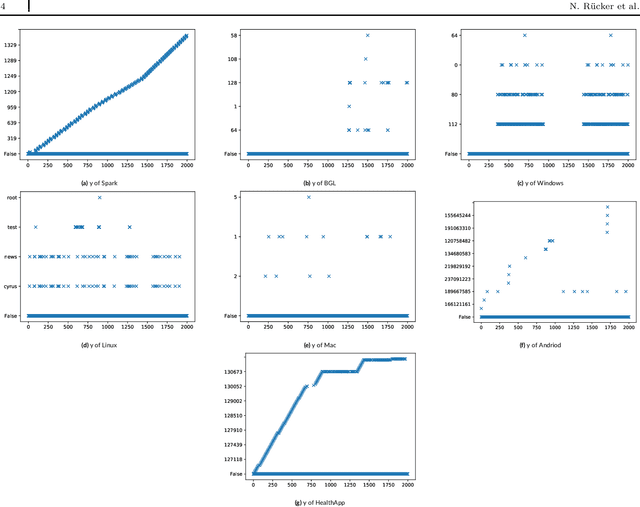
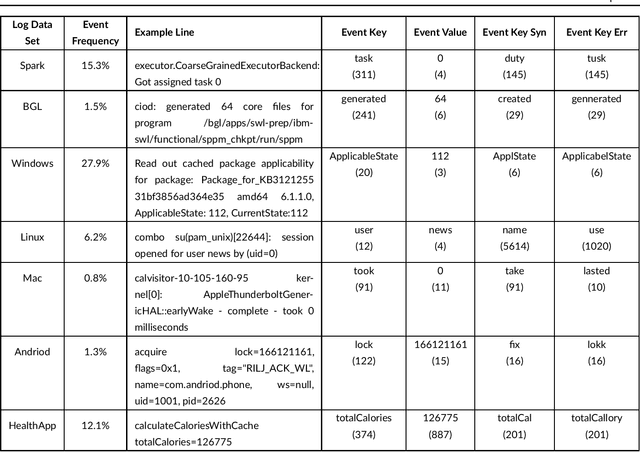
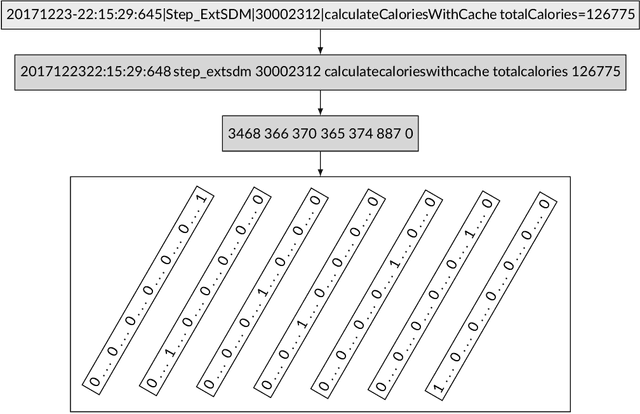
Any modern system writes events into files, called log files. Those contain crucial information which are subject to various analyses. Examples range from cybersecurity, intrusion detection over usage analyses to trouble shooting. Before data analysis is possible, desired information needs to be extracted first out of the semi-structured log messages. State of the art event parsing often assumes static log events. However, any modern system is updated consistently and with updates also log file structures can change. We call those changes 'mutations' and study parsing performance for different mutation cases. Latest research discovers mutations using anomaly detection post mortem, however, does not cover actual continuous parsing. Thus, we propose a novel, flexible parser, called FlexParser which can extract desired values despite gradual changes in the log messages. It implies basic text preprocessing followed by a supervised Deep Learning method. We train a stateful LSTM on parsing one event per data set. Statefulness enforces the model to learn log message structures across several messages. Our model was tested on seven different, publicly available log file data sets and various kinds of mutations. Exhibiting an average F1-Score of 0.98, it outperforms other Deep Learning methods as well as state-of-the-art unsupervised parsers.