 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Selective Intervention Planning using RMABs: Increasing Program Engagement to Improve Maternal and Child Health Outcomes
Mar 18, 2021
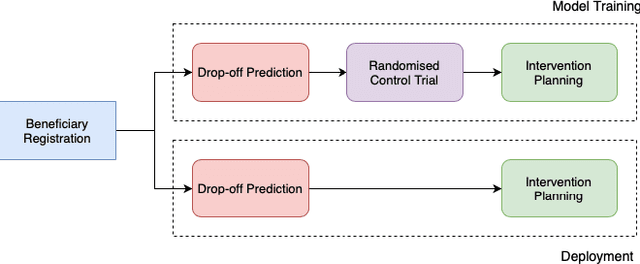
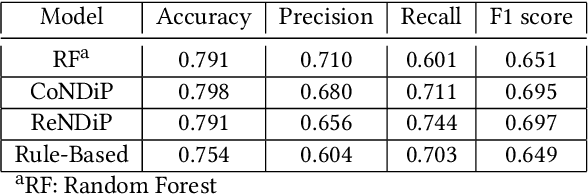
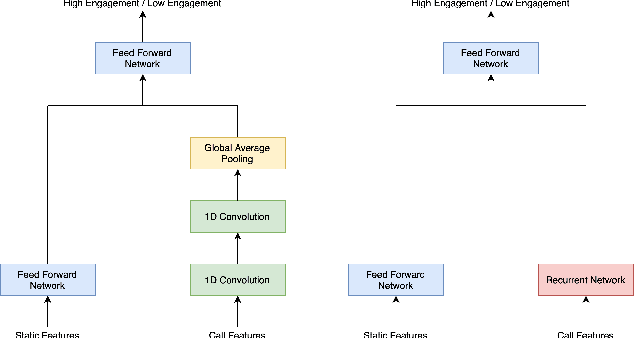
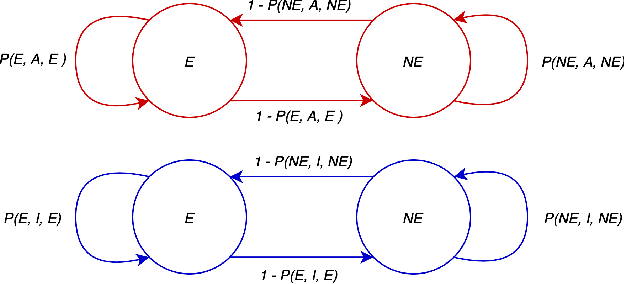
India has a maternal mortality ratio of 113 and child mortality ratio of 2830 per 100,000 live births. Lack of access to preventive care information is a major contributing factor for these deaths, especially in low-income households. We work with ARMMAN, a non-profit based in India, to further the use of call-based information programs by early-on identifying women who might not engage with these programs that are proven to affect health parameters positively. We analyzed anonymized call-records of over 300,000 women registered in an awareness program created by ARMMAN that uses cellphone calls to regularly disseminate health related information. We built machine learning based models to predict the long term engagement pattern from call logs and beneficiaries' demographic information, and discuss the applicability of this method in the real world through a pilot validation. Through a randomized controlled trial, we show that using our model's predictions to make interventions boosts engagement metrics by 14.3%. We then formulate the intervention planning problem as restless multi-armed bandits (RMABs), and present preliminary results using this approach.
Feature Importance-aware Transferable Adversarial Attacks
Aug 22, 2021
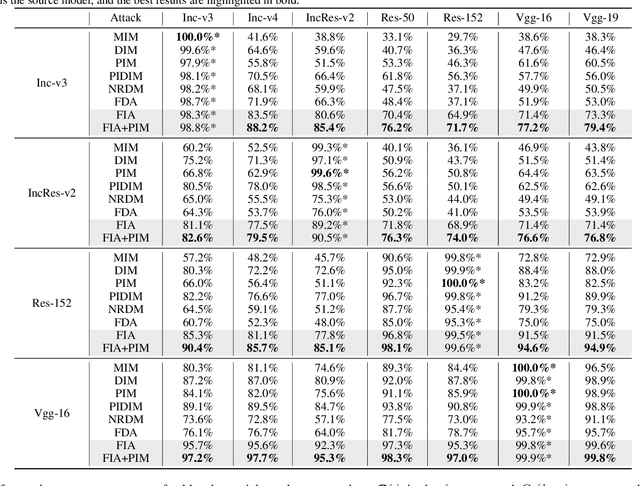
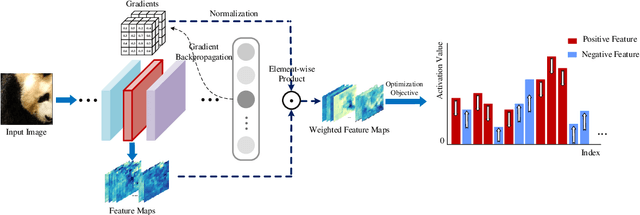
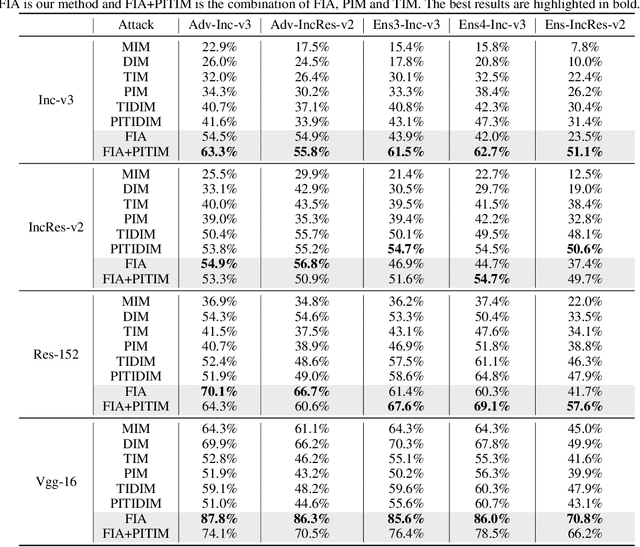
Transferability of adversarial examples is of central importance for attacking an unknown model, which facilitates adversarial attacks in more practical scenarios, e.g., black-box attacks. Existing transferable attacks tend to craft adversarial examples by indiscriminately distorting features to degrade prediction accuracy in a source model without aware of intrinsic features of objects in the images. We argue that such brute-force degradation would introduce model-specific local optimum into adversarial examples, thus limiting the transferability. By contrast, we propose the Feature Importance-aware Attack (FIA), which disrupts important object-aware features that dominate model decisions consistently. More specifically, we obtain feature importance by introducing the aggregate gradient, which averages the gradients with respect to feature maps of the source model, computed on a batch of random transforms of the original clean image. The gradients will be highly correlated to objects of interest, and such correlation presents invariance across different models. Besides, the random transforms will preserve intrinsic features of objects and suppress model-specific information. Finally, the feature importance guides to search for adversarial examples towards disrupting critical features, achieving stronger transferability. Extensive experimental evaluation demonstrates the effectiveness and superior performance of the proposed FIA, i.e., improving the success rate by 9.5% against normally trained models and 12.8% against defense models as compared to the state-of-the-art transferable attacks. Code is available at: https://github.com/hcguoO0/FIA
Modeling the Sequential Dependence among Audience Multi-step Conversions with Multi-task Learning in Targeted Display Advertising
May 24, 2021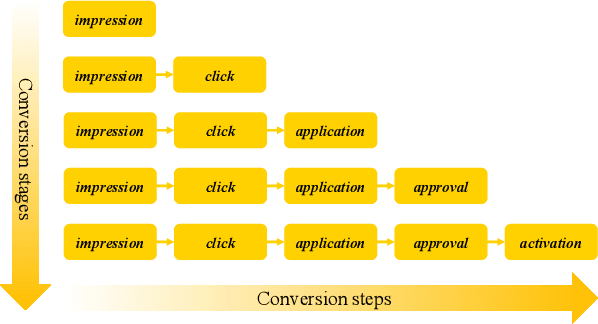

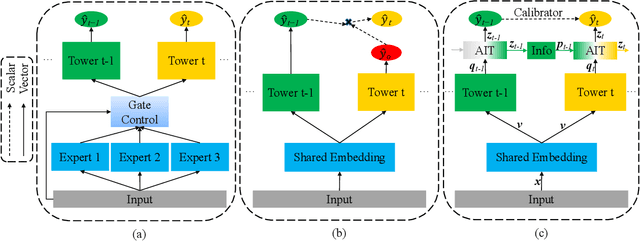
In most real-world large-scale online applications (e.g., e-commerce or finance), customer acquisition is usually a multi-step conversion process of audiences. For example, an impression->click->purchase process is usually performed of audiences for e-commerce platforms. However, it is more difficult to acquire customers in financial advertising (e.g., credit card advertising) than in traditional advertising. On the one hand, the audience multi-step conversion path is longer. On the other hand, the positive feedback is sparser (class imbalance) step by step, and it is difficult to obtain the final positive feedback due to the delayed feedback of activation. Multi-task learning is a typical solution in this direction. While considerable multi-task efforts have been made in this direction, a long-standing challenge is how to explicitly model the long-path sequential dependence among audience multi-step conversions for improving the end-to-end conversion. In this paper, we propose an Adaptive Information Transfer Multi-task (AITM) framework, which models the sequential dependence among audience multi-step conversions via the Adaptive Information Transfer (AIT) module. The AIT module can adaptively learn what and how much information to transfer for different conversion stages. Besides, by combining the Behavioral Expectation Calibrator in the loss function, the AITM framework can yield more accurate end-to-end conversion identification. The proposed framework is deployed in Meituan app, which utilizes it to real-timely show a banner to the audience with a high end-to-end conversion rate for Meituan Co-Branded Credit Cards. Offline experimental results on both industrial and public real-world datasets clearly demonstrate that the proposed framework achieves significantly better performance compared with state-of-the-art baselines.
Domain Generalization via Gradient Surgery
Aug 03, 2021
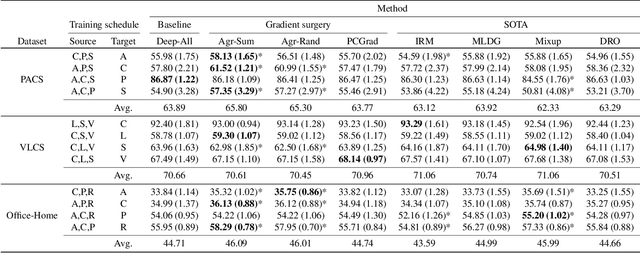
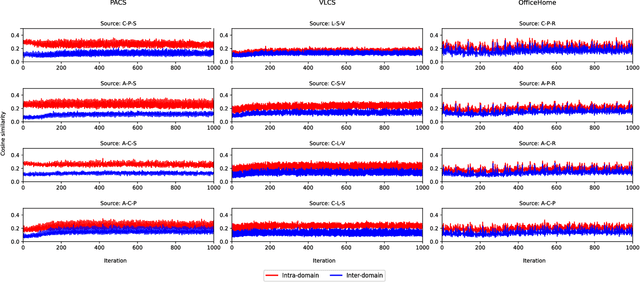
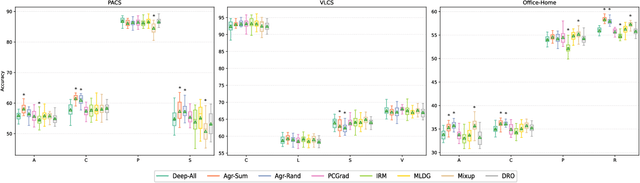
In real-life applications, machine learning models often face scenarios where there is a change in data distribution between training and test domains. When the aim is to make predictions on distributions different from those seen at training, we incur in a domain generalization problem. Methods to address this issue learn a model using data from multiple source domains, and then apply this model to the unseen target domain. Our hypothesis is that when training with multiple domains, conflicting gradients within each mini-batch contain information specific to the individual domains which is irrelevant to the others, including the test domain. If left untouched, such disagreement may degrade generalization performance. In this work, we characterize the conflicting gradients emerging in domain shift scenarios and devise novel gradient agreement strategies based on gradient surgery to alleviate their effect. We validate our approach in image classification tasks with three multi-domain datasets, showing the value of the proposed agreement strategy in enhancing the generalization capability of deep learning models in domain shift scenarios.
CTNet: Context-based Tandem Network for Semantic Segmentation
Apr 20, 2021
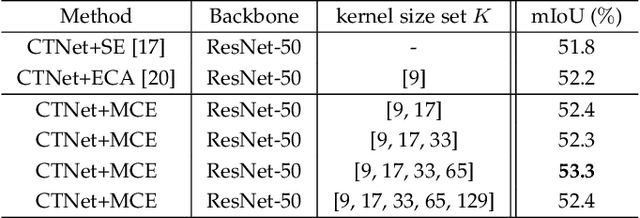
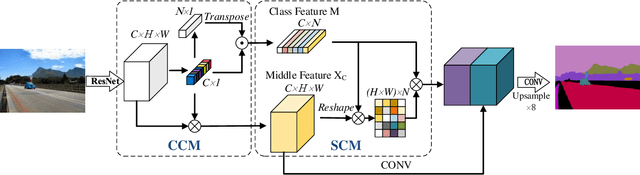
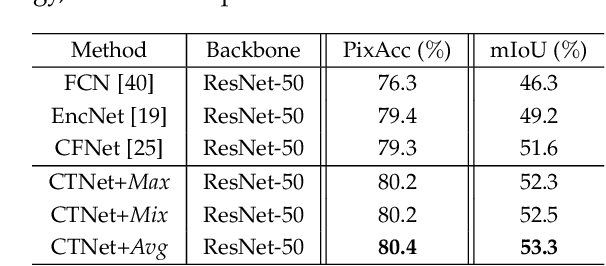
Contextual information has been shown to be powerful for semantic segmentation. This work proposes a novel Context-based Tandem Network (CTNet) by interactively exploring the spatial contextual information and the channel contextual information, which can discover the semantic context for semantic segmentation. Specifically, the Spatial Contextual Module (SCM) is leveraged to uncover the spatial contextual dependency between pixels by exploring the correlation between pixels and categories. Meanwhile, the Channel Contextual Module (CCM) is introduced to learn the semantic features including the semantic feature maps and class-specific features by modeling the long-term semantic dependence between channels. The learned semantic features are utilized as the prior knowledge to guide the learning of SCM, which can make SCM obtain more accurate long-range spatial dependency. Finally, to further improve the performance of the learned representations for semantic segmentation, the results of the two context modules are adaptively integrated to achieve better results. Extensive experiments are conducted on three widely-used datasets, i.e., PASCAL-Context, ADE20K and PASCAL VOC2012. The results demonstrate the superior performance of the proposed CTNet by comparison with several state-of-the-art methods.
Robust and Interpretable Temporal Convolution Network for Event Detection in Lung Sound Recordings
Jun 30, 2021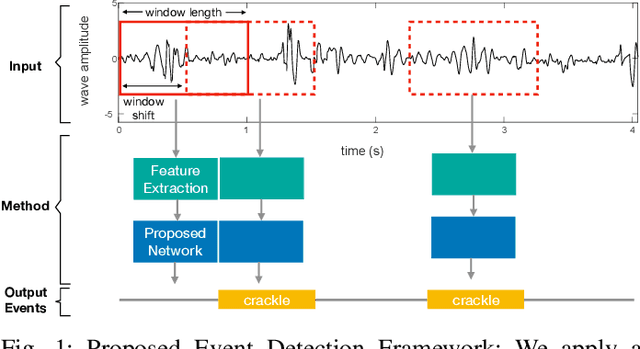
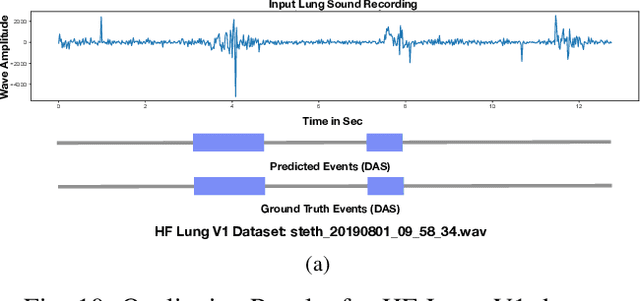
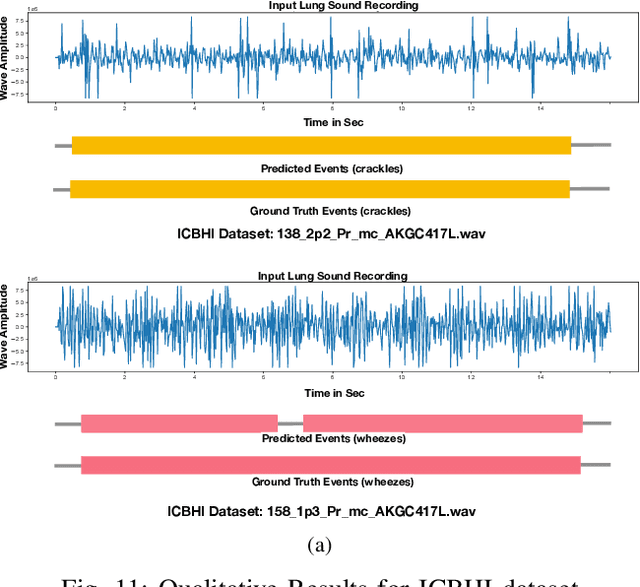
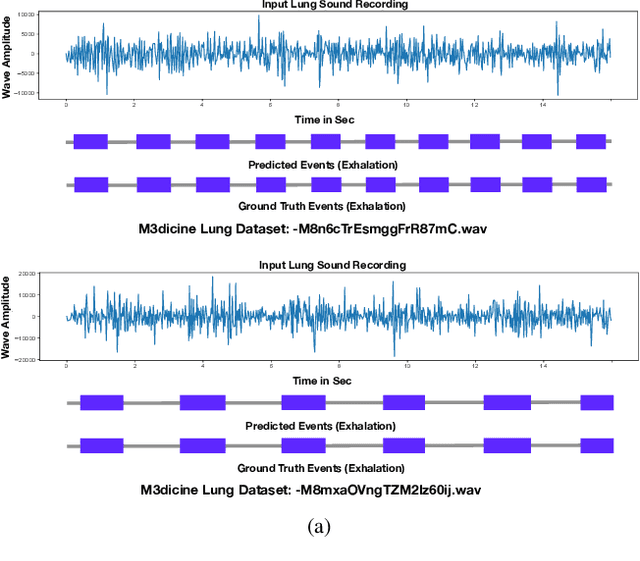
This paper proposes a novel framework for lung sound event detection, segmenting continuous lung sound recordings into discrete events and performing recognition on each event. Exploiting the lightweight nature of Temporal Convolution Networks (TCNs) and their superior results compared to their recurrent counterparts, we propose a lightweight, yet robust, and completely interpretable framework for lung sound event detection. We propose the use of a multi-branch TCN architecture and exploit a novel fusion strategy to combine the resultant features from these branches. This not only allows the network to retain the most salient information across different temporal granularities and disregards irrelevant information, but also allows our network to process recordings of arbitrary length. Results: The proposed method is evaluated on multiple public and in-house benchmarks of irregular and noisy recordings of the respiratory auscultation process for the identification of numerous auscultation events including inhalation, exhalation, crackles, wheeze, stridor, and rhonchi. We exceed the state-of-the-art results in all evaluations. Furthermore, we empirically analyse the effect of the proposed multi-branch TCN architecture and the feature fusion strategy and provide quantitative and qualitative evaluations to illustrate their efficiency. Moreover, we provide an end-to-end model interpretation pipeline that interprets the operations of all the components of the proposed framework. Our analysis of different feature fusion strategies shows that the proposed feature concatenation method leads to better suppression of non-informative features, which drastically reduces the classifier overhead resulting in a robust lightweight network.The lightweight nature of our model allows it to be deployed in end-user devices such as smartphones, and it has the ability to generate predictions in real-time.
Joint Pilot Design and Channel Estimation using Deep Residual Learning for Multi-Cell Massive MIMO under Hardware Impairments
Aug 10, 2021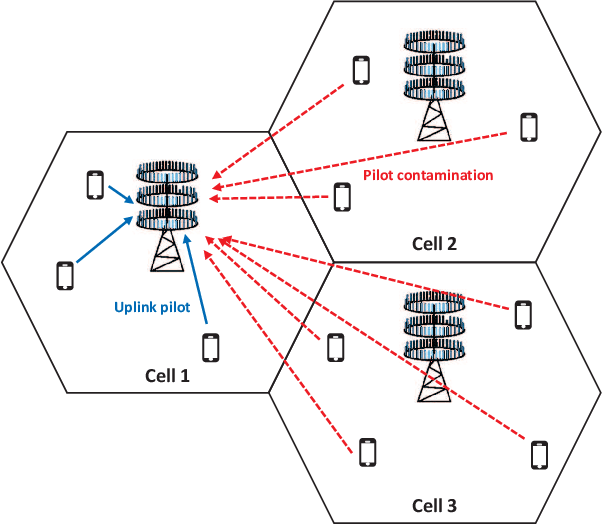
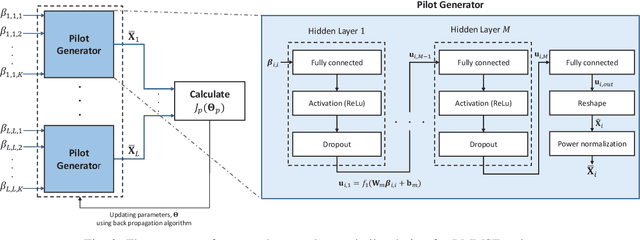
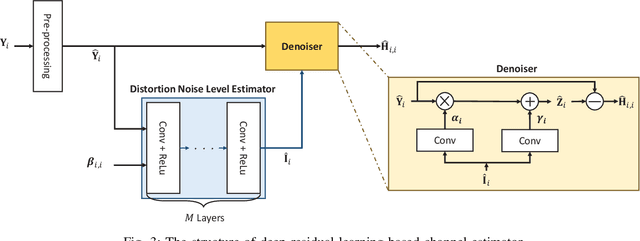
In multi-cell massive MIMO systems, channel estimation is deteriorated by pilot contamination and the effects of pilot contamination become more severe due to hardware impairments. In this paper, we propose a joint pilot design and channel estimation based on deep residual learning in order to mitigate the effects of pilot contamination under the consideration of hardware impairments. We first investigate a conventional linear minimum mean square error (LMMSE) based channel estimator to suppress the interference caused by pilot contamination. After that, a deep learning based pilot design is proposed to minimize the mean square error (MSE) of LMMSE channel estimation, which is utilized to the joint pilot design and channel estimator for transfer learning approach. For the channel estimator, we use a deep residual learning which extracts the features of interference caused by pilot contamination and eliminates them to estimate the channel information. Simulation results demonstrate that the proposed joint pilot design and channel estimator outperforms the conventional approach in multi-cell massive MIMO scenarios. Furthermore, the joint pilot design and channel estimator using transfer learning enhances the estimation performance by reducing the effects of pilot contamination when the prior knowledge of pilot contamination cannot be exploited.
Jointly Optimizing Query Encoder and Product Quantization to Improve Retrieval Performance
Aug 22, 2021
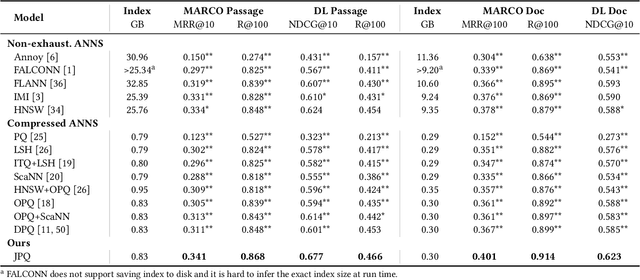
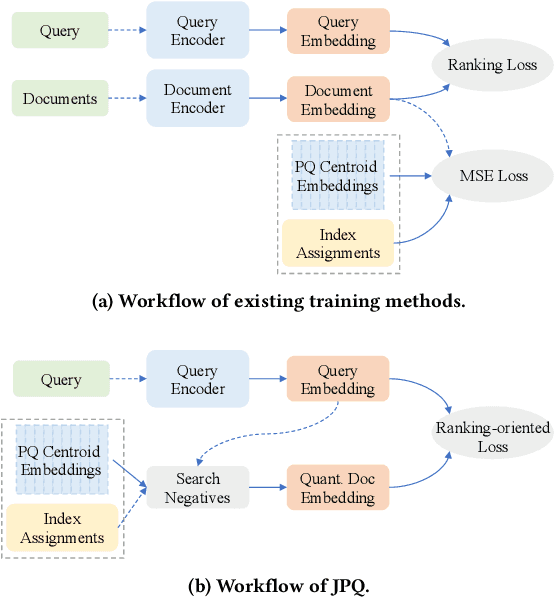
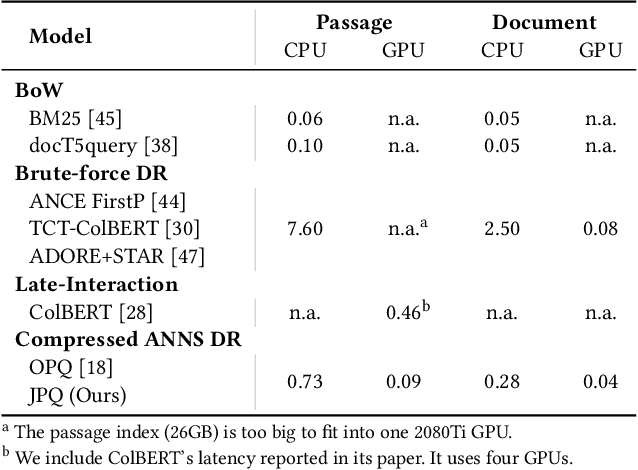
Recently, Information Retrieval community has witnessed fast-paced advances in Dense Retrieval (DR), which performs first-stage retrieval with embedding-based search. Despite the impressive ranking performance, previous studies usually adopt brute-force search to acquire candidates, which is prohibitive in practical Web search scenarios due to its tremendous memory usage and time cost. To overcome these problems, vector compression methods have been adopted in many practical embedding-based retrieval applications. One of the most popular methods is Product Quantization (PQ). However, although existing vector compression methods including PQ can help improve the efficiency of DR, they incur severely decayed retrieval performance due to the separation between encoding and compression. To tackle this problem, we present JPQ, which stands for Joint optimization of query encoding and Product Quantization. It trains the query encoder and PQ index jointly in an end-to-end manner based on three optimization strategies, namely ranking-oriented loss, PQ centroid optimization, and end-to-end negative sampling. We evaluate JPQ on two publicly available retrieval benchmarks. Experimental results show that JPQ significantly outperforms popular vector compression methods. Compared with previous DR models that use brute-force search, JPQ almost matches the best retrieval performance with 30x compression on index size. The compressed index further brings 10x speedup on CPU and 2x speedup on GPU in query latency.
Stein ICP for Uncertainty Estimation in Point Cloud Matching
Jun 07, 2021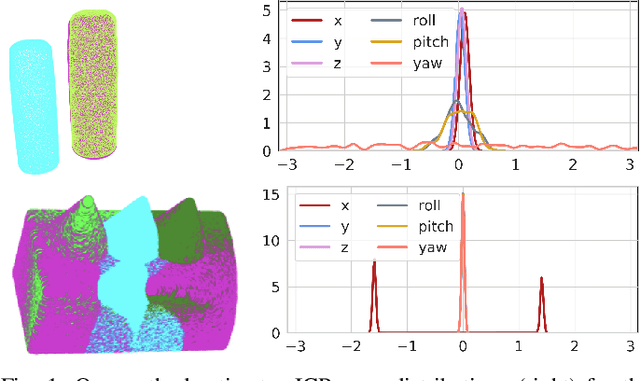

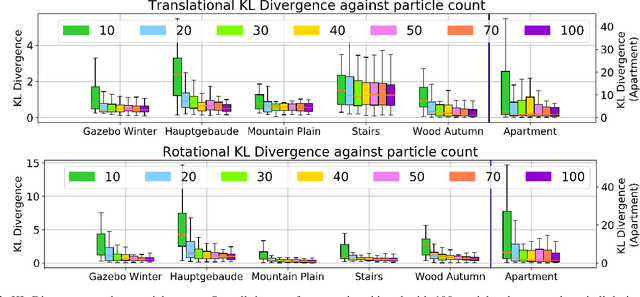

Quantification of uncertainty in point cloud matching is critical in many tasks such as pose estimation, sensor fusion, and grasping. Iterative closest point (ICP) is a commonly used pose estimation algorithm which provides a point estimate of the transformation between two point clouds. There are many sources of uncertainty in this process that may arise due to sensor noise, ambiguous environment, and occlusion. However, for safety critical problems such as autonomous driving, a point estimate of the pose transformation is not sufficient as it does not provide information about the multiple solutions. Current probabilistic ICP methods usually do not capture all sources of uncertainty and may provide unreliable transformation estimates which can have a detrimental effect in state estimation or decision making tasks that use this information. In this work we propose a new algorithm to align two point clouds that can precisely estimate the uncertainty of ICP's transformation parameters. We develop a Stein variational inference framework with gradient based optimization of ICP's cost function. The method provides a non-parametric estimate of the transformation, can model complex multi-modal distributions, and can be effectively parallelized on a GPU. Experiments using 3D kinect data as well as sparse indoor/outdoor LiDAR data show that our method is capable of efficiently producing accurate pose uncertainty estimates.
Invariant Information Distillation for Unsupervised Image Segmentation and Clustering
Jul 21, 2018
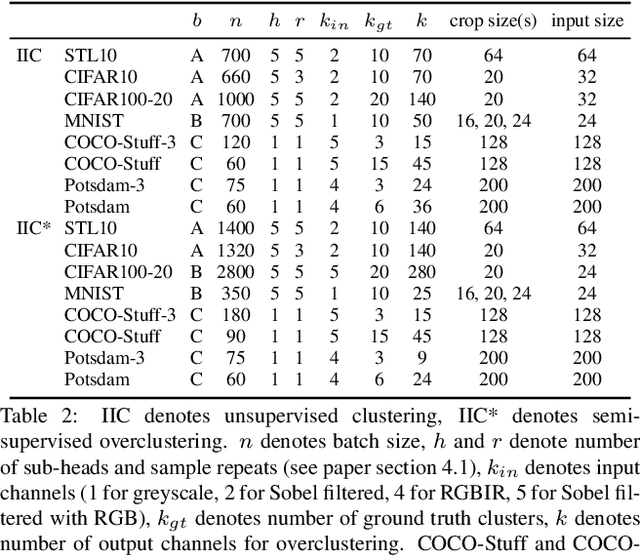

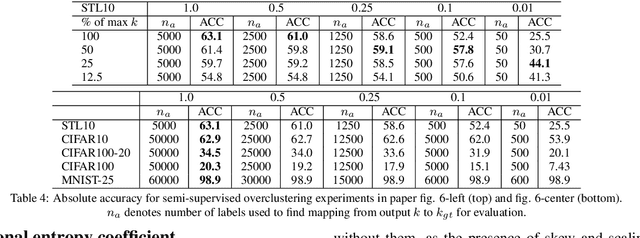
We present a new method that learns to segment and cluster images without labels of any kind. A simple loss based on information theory is used to extract meaningful representations directly from raw images. This is achieved by maximising mutual information of images known to be related by spatial proximity or randomized transformations, which distills their shared abstract content. Unlike much of the work in unsupervised deep learning, our learned function outputs segmentation heatmaps and discrete classifications labels directly, rather than embeddings that need further processing to be usable. The loss can be formulated as a convolution, making it the first end-to-end unsupervised learning method that learns densely and efficiently for semantic segmentation. Implemented using realistic settings on generic deep neural network architectures, our method attains superior performance on COCO-Stuff and ISPRS-Potsdam for segmentation and STL for clustering, beating state-of-the-art baselines.