 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards Sample-Optimal Compressive Phase Retrieval with Sparse and Generative Priors
Jun 29, 2021
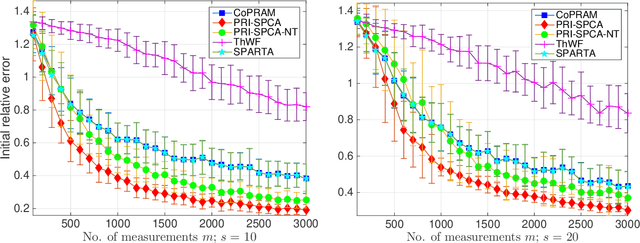
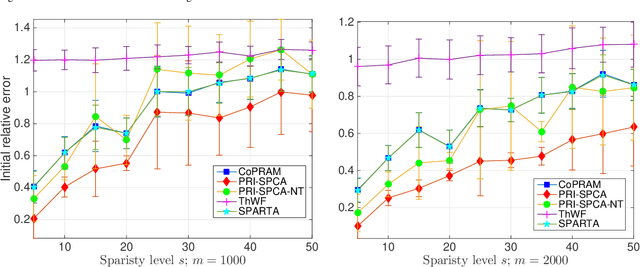
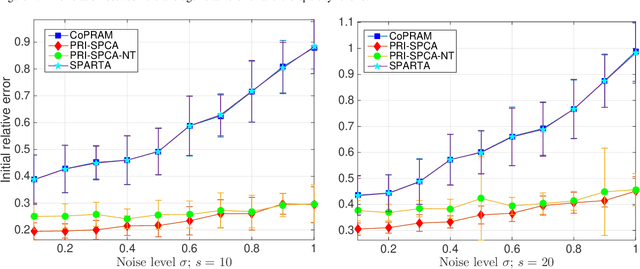
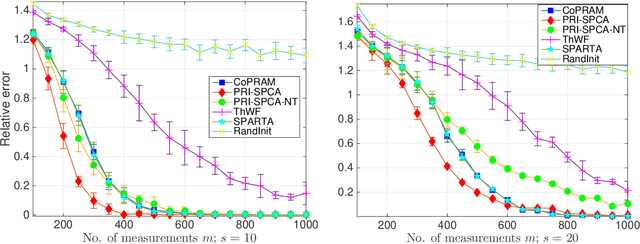
Compressive phase retrieval is a popular variant of the standard compressive sensing problem, in which the measurements only contain magnitude information. In this paper, motivated by recent advances in deep generative models, we provide recovery guarantees with order-optimal sample complexity bounds for phase retrieval with generative priors. We first show that when using i.i.d. Gaussian measurements and an $L$-Lipschitz continuous generative model with bounded $k$-dimensional inputs, roughly $O(k \log L)$ samples suffice to guarantee that the signal is close to any vector that minimizes an amplitude-based empirical loss function. Attaining this sample complexity with a practical algorithm remains a difficult challenge, and a popular spectral initialization method has been observed to pose a major bottleneck. To partially address this, we further show that roughly $O(k \log L)$ samples ensure sufficient closeness between the signal and any {\em globally optimal} solution to an optimization problem designed for spectral initialization (though finding such a solution may still be challenging). We adapt this result to sparse phase retrieval, and show that $O(s \log n)$ samples are sufficient for a similar guarantee when the underlying signal is $s$-sparse and $n$-dimensional, matching an information-theoretic lower bound. While our guarantees do not directly correspond to a practical algorithm, we propose a practical spectral initialization method motivated by our findings, and experimentally observe significant performance gains over various existing spectral initialization methods of sparse phase retrieval.
Multi-agent deep reinforcement learning (MADRL) meets multi-user MIMO systems
Sep 10, 2021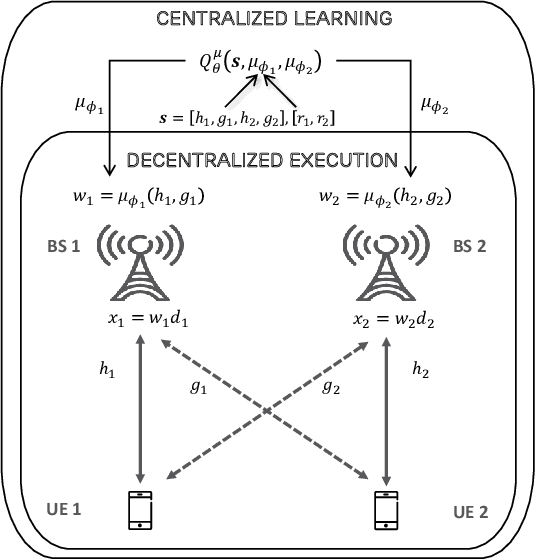
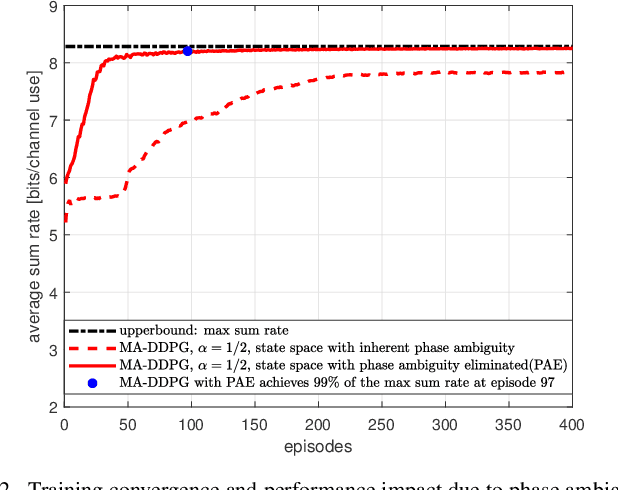
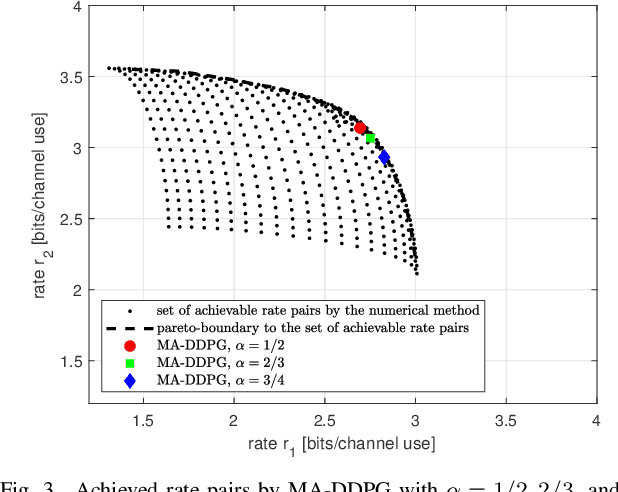
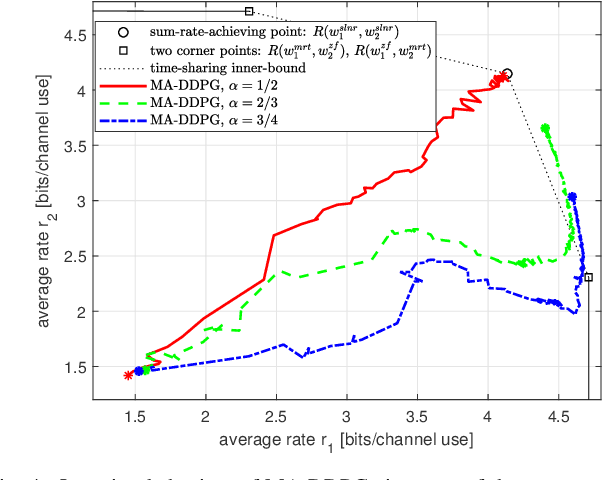
A multi-agent deep reinforcement learning (MADRL) is a promising approach to challenging problems in wireless environments involving multiple decision-makers (or actors) with high-dimensional continuous action space. In this paper, we present a MADRL-based approach that can jointly optimize precoders to achieve the outer-boundary, called pareto-boundary, of the achievable rate region for a multiple-input single-output (MISO) interference channel (IFC). In order to address two main challenges, namely, multiple actors (or agents) with partial observability and multi-dimensional continuous action space in MISO IFC setup, we adopt a multi-agent deep deterministic policy gradient (MA-DDPG) framework in which decentralized actors with partial observability can learn a multi-dimensional continuous policy in a centralized manner with the aid of shared critic with global information. Meanwhile, we will also address a phase ambiguity issue with the conventional complex baseband representation of signals widely used in radio communications. In order to mitigate the impact of phase ambiguity on training performance, we propose a training method, called phase ambiguity elimination (PAE), that leads to faster learning and better performance of MA-DDPG in wireless communication systems. The simulation results exhibit that MA-DDPG is capable of learning a near-optimal precoding strategy in a MISO IFC environment. To the best of our knowledge, this is the first work to demonstrate that the MA-DDPG framework can jointly optimize precoders to achieve the pareto-boundary of achievable rate region in a multi-cell multi-user multi-antenna system.
Topic, Sentiment and Impact Analysis: COVID19 Information Seeking on Social Media
Aug 28, 2020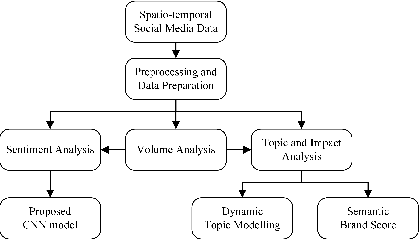
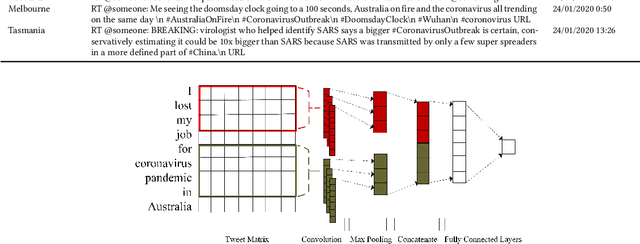
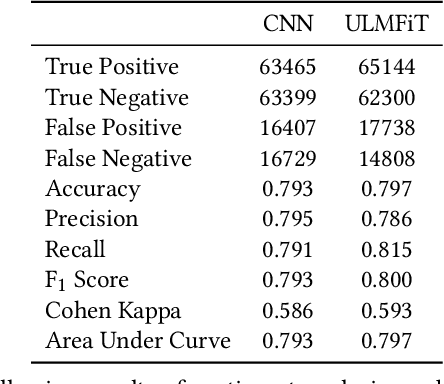

When people notice something unusual, they discuss it on social media. They leave traces of their emotions via text expressions. A systematic collection, analysis, and interpretation of social media data across time and space can give insights on local outbreaks, mental health, and social issues. Such timely insights can help in developing strategies and resources with an appropriate and efficient response. This study analysed a large Spatio-temporal tweet dataset of the Australian sphere related to COVID19. The methodology included a volume analysis, dynamic topic modelling, sentiment detection, and semantic brand score to obtain an insight on the COVID19 pandemic outbreak and public discussion in different states and cities of Australia over time. The obtained insights are compared with independently observed phenomena such as government reported instances.
Detailed Avatar Recovery from Single Image
Aug 06, 2021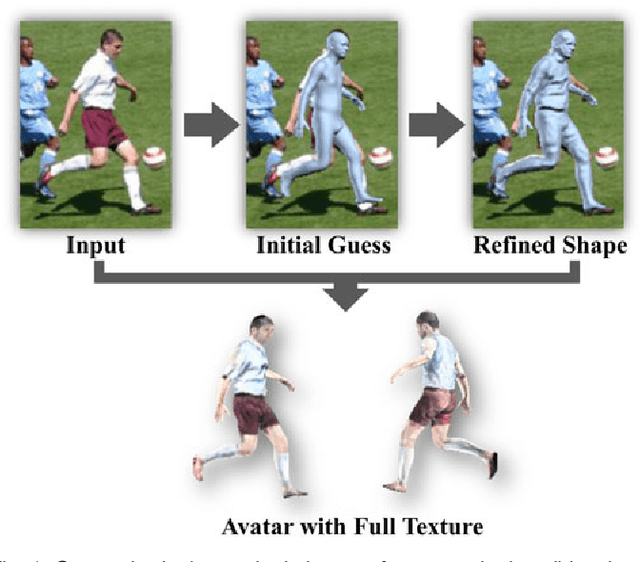
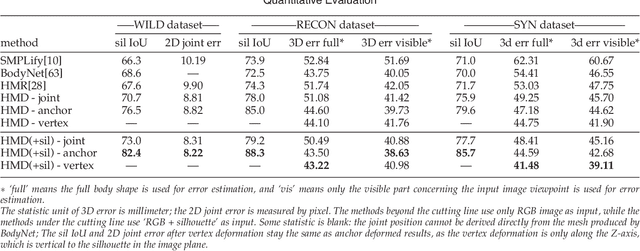
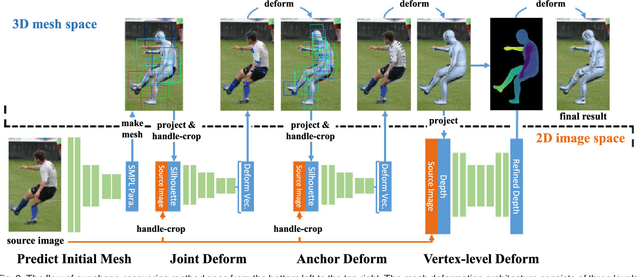
This paper presents a novel framework to recover \emph{detailed} avatar from a single image. It is a challenging task due to factors such as variations in human shapes, body poses, texture, and viewpoints. Prior methods typically attempt to recover the human body shape using a parametric-based template that lacks the surface details. As such resulting body shape appears to be without clothing. In this paper, we propose a novel learning-based framework that combines the robustness of the parametric model with the flexibility of free-form 3D deformation. We use the deep neural networks to refine the 3D shape in a Hierarchical Mesh Deformation (HMD) framework, utilizing the constraints from body joints, silhouettes, and per-pixel shading information. Our method can restore detailed human body shapes with complete textures beyond skinned models. Experiments demonstrate that our method has outperformed previous state-of-the-art approaches, achieving better accuracy in terms of both 2D IoU number and 3D metric distance.
Distilling EEG Representations via Capsules for Affective Computing
Apr 30, 2021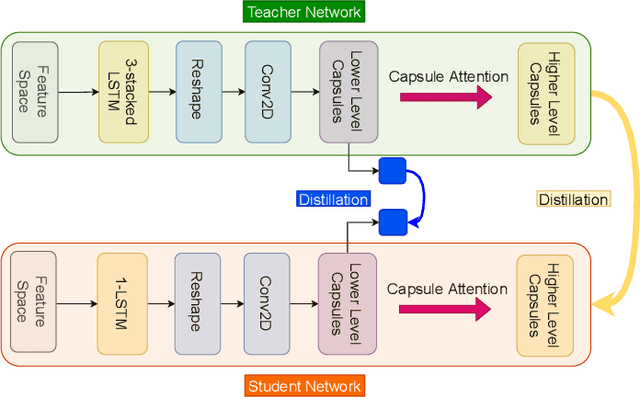
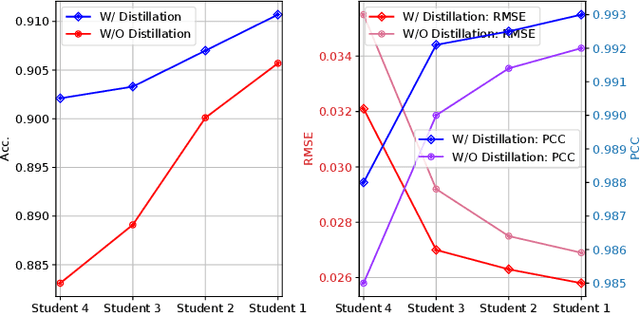
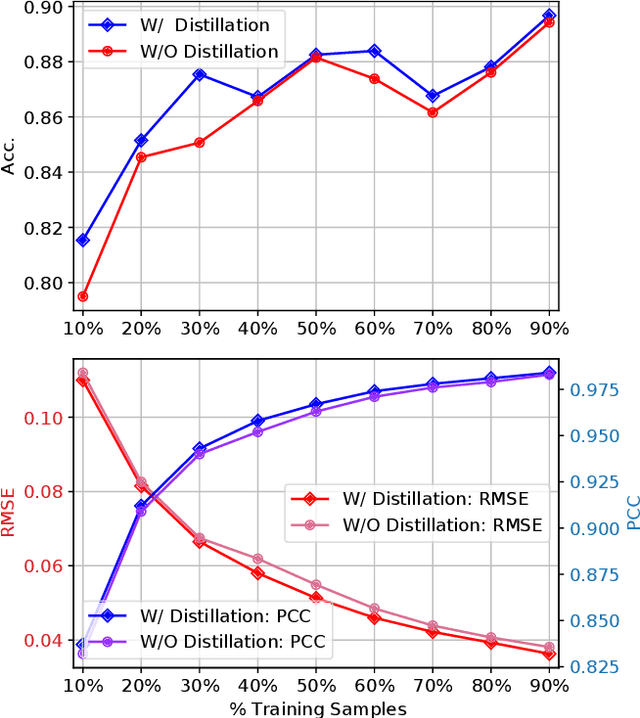
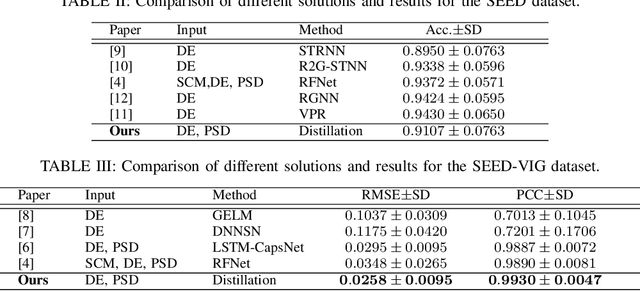
Affective computing with Electroencephalogram (EEG) is a challenging task that requires cumbersome models to effectively learn the information contained in large-scale EEG signals, causing difficulties for real-time smart-device deployment. In this paper, we propose a novel knowledge distillation pipeline to distill EEG representations via capsule-based architectures for both classification and regression tasks. Our goal is to distill information from a heavy model to a lightweight model for subject-specific tasks. To this end, we first pre-train a large model (teacher network) on large number of training samples. Then, we employ the teacher network to learn the discriminative features embedded in capsules by adopting a lightweight model (student network) to mimic the teacher using the privileged knowledge. Such privileged information learned by the teacher contain similarities among capsules and are only available during the training stage of the student network. We evaluate the proposed architecture on two large-scale public EEG datasets, showing that our framework consistently enables student networks with different compression ratios to effectively learn from the teacher, even when provided with limited training samples. Lastly, our method achieves state-of-the-art results on one of the two datasets.
Blind Modulo Analog-to-Digital Conversion
Aug 19, 2021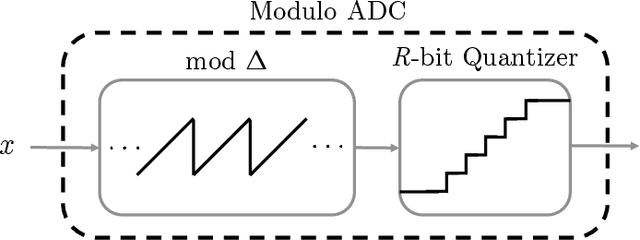
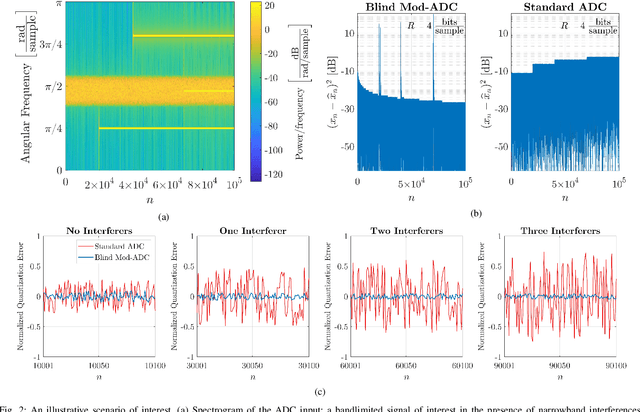
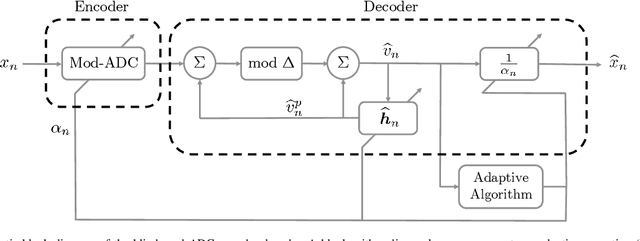
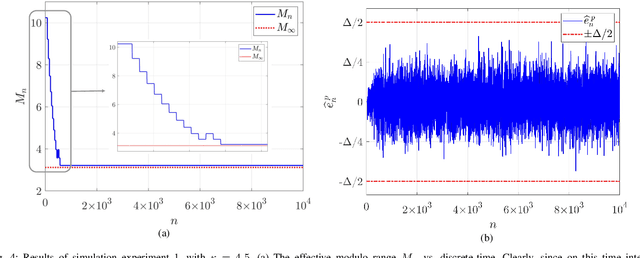
In a growing number of applications, there is a need to digitize signals whose spectral characteristics are challenging for traditional Analog-to-Digital Converters (ADCs). Examples, among others, include systems where the ADC must acquire at once a very wide but sparsely and dynamically occupied bandwidth supporting diverse services, as well as systems where the signal of interest is subject to strong narrowband co-channel interference. In such scenarios, the resolution requirements can be prohibitively high. As an alternative, the recently proposed modulo-ADC architecture can in principle require dramatically fewer bits in the conversation to obtain the target fidelity, but requires that information about the spectrum be known and explicitly taken into account by the analog and digital processing in the converter, which is frequently impractical. To address this limitation, we develop a blind version of the architecture that requires no such knowledge in the converter, without sacrificing performance. In particular, it features an automatic modulo-level adjustment and a fully adaptive modulo unwrapping mechanism, allowing it to asymptotically match the characteristics of the unknown input signal. In addition to detailed analysis, simulations demonstrate the attractive performance characteristics in representative settings.
Depth Completion using Plane-Residual Representation
Apr 15, 2021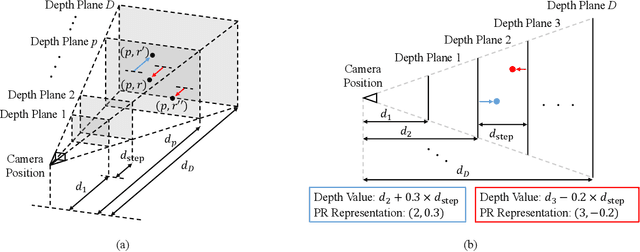
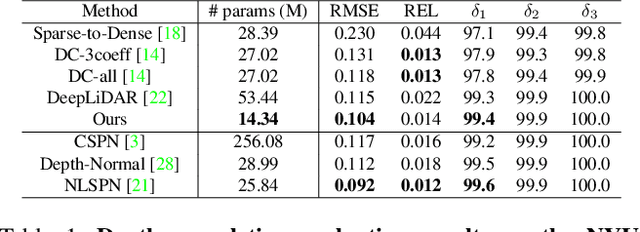
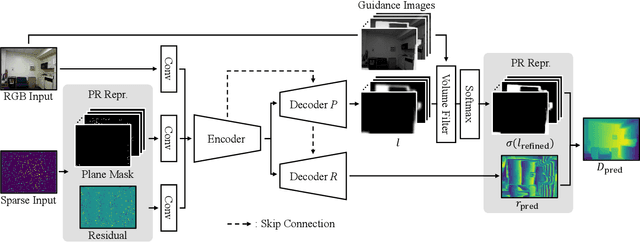
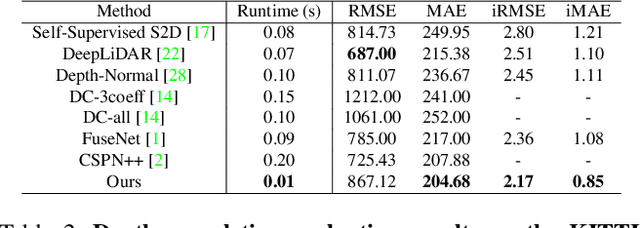
The basic framework of depth completion is to predict a pixel-wise dense depth map using very sparse input data. In this paper, we try to solve this problem in a more effective way, by reformulating the regression-based depth estimation problem into a combination of depth plane classification and residual regression. Our proposed approach is to initially densify sparse depth information by figuring out which plane a pixel should lie among a number of discretized depth planes, and then calculate the final depth value by predicting the distance from the specified plane. This will help the network to lessen the burden of directly regressing the absolute depth information from none, and to effectively obtain more accurate depth prediction result with less computation power and inference time. To do so, we firstly introduce a novel way of interpreting depth information with the closest depth plane label $p$ and a residual value $r$, as we call it, Plane-Residual (PR) representation. We also propose a depth completion network utilizing PR representation consisting of a shared encoder and two decoders, where one classifies the pixel's depth plane label, while the other one regresses the normalized distance from the classified depth plane. By interpreting depth information in PR representation and using our corresponding depth completion network, we were able to acquire improved depth completion performance with faster computation, compared to previous approaches.
Large-vocabulary Audio-visual Speech Recognition in Noisy Environments
Sep 10, 2021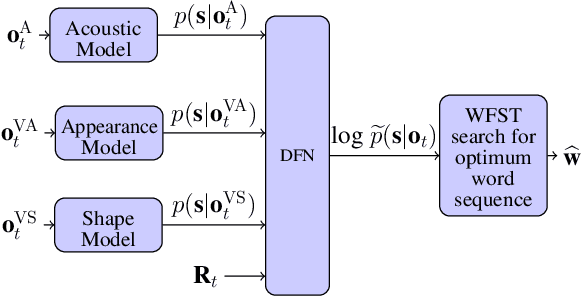
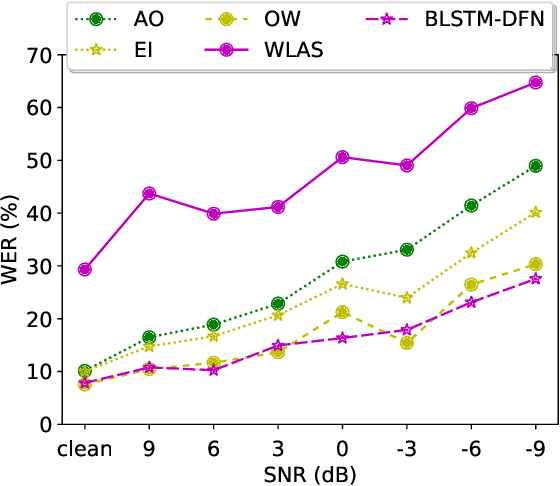

Audio-visual speech recognition (AVSR) can effectively and significantly improve the recognition rates of small-vocabulary systems, compared to their audio-only counterparts. For large-vocabulary systems, however, there are still many difficulties, such as unsatisfactory video recognition accuracies, that make it hard to improve over audio-only baselines. In this paper, we specifically consider such scenarios, focusing on the large-vocabulary task of the LRS2 database, where audio-only performance is far superior to video-only accuracies, making this an interesting and challenging setup for multi-modal integration. To address the inherent difficulties, we propose a new fusion strategy: a recurrent integration network is trained to fuse the state posteriors of multiple single-modality models, guided by a set of model-based and signal-based stream reliability measures. During decoding, this network is used for stream integration within a hybrid recognizer, where it can thus cope with the time-variant reliability and information content of its multiple feature inputs. We compare the results with end-to-end AVSR systems as well as with competitive hybrid baseline models, finding that the new fusion strategy shows superior results, on average even outperforming oracle dynamic stream weighting, which has so far marked the -- realistically unachievable -- upper bound for standard stream weighting. Even though the pure lipreading performance is low, audio-visual integration is helpful under all -- clean, noisy, and reverberant -- conditions. On average, the new system achieves a relative word error rate reduction of 42.18\% compared to the audio-only model, pointing at a high effectiveness of the proposed integration approach.
Unifying Nonlocal Blocks for Neural Networks
Aug 13, 2021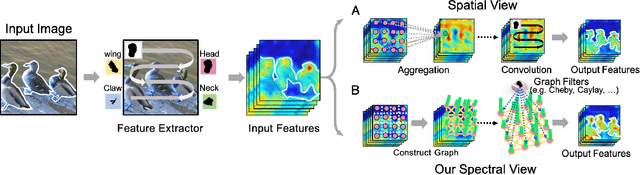

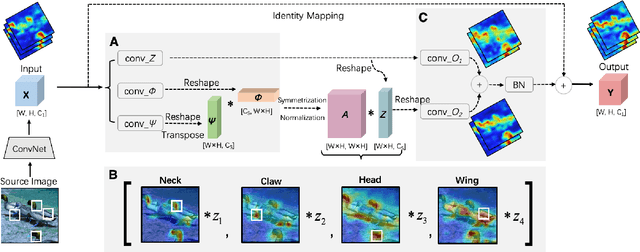
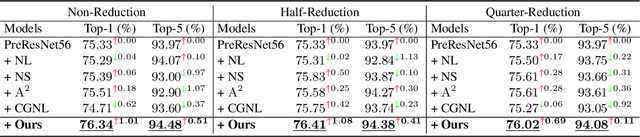
The nonlocal-based blocks are designed for capturing long-range spatial-temporal dependencies in computer vision tasks. Although having shown excellent performance, they still lack the mechanism to encode the rich, structured information among elements in an image or video. In this paper, to theoretically analyze the property of these nonlocal-based blocks, we provide a new perspective to interpret them, where we view them as a set of graph filters generated on a fully-connected graph. Specifically, when choosing the Chebyshev graph filter, a unified formulation can be derived for explaining and analyzing the existing nonlocal-based blocks (e.g., nonlocal block, nonlocal stage, double attention block). Furthermore, by concerning the property of spectral, we propose an efficient and robust spectral nonlocal block, which can be more robust and flexible to catch long-range dependencies when inserted into deep neural networks than the existing nonlocal blocks. Experimental results demonstrate the clear-cut improvements and practical applicabilities of our method on image classification, action recognition, semantic segmentation, and person re-identification tasks.
Neural Enhanced Belief Propagation for Cooperative Localization
May 27, 2021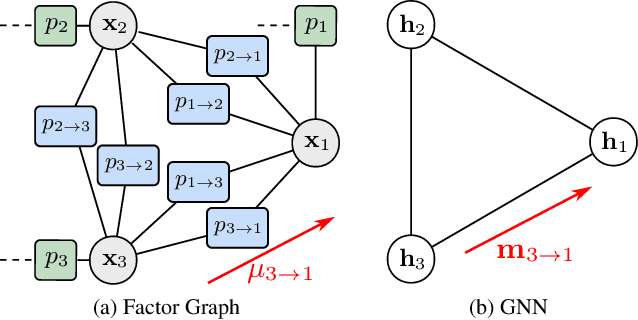
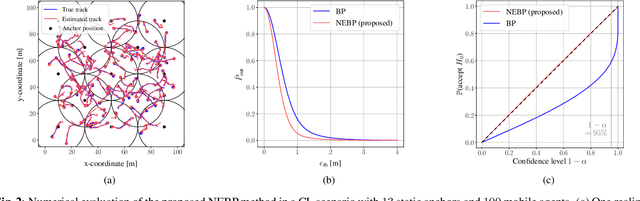
Location-aware networks will introduce innovative services and applications for modern convenience, applied ocean sciences, and public safety. In this paper, we establish a hybrid method for model-based and data-driven inference. We consider a cooperative localization (CL) scenario where the mobile agents in a wireless network aim to localize themselves by performing pairwise observations with other agents and by exchanging location information. A traditional method for distributed CL in large agent networks is belief propagation (BP) which is completely model-based and is known to suffer from providing inconsistent (overconfident) estimates. The proposed approach addresses these limitations by complementing BP with learned information provided by a graph neural network (GNN). We demonstrate numerically that our method can improve estimation accuracy and avoid overconfident beliefs, while its computational complexity remains comparable to BP. Notably, more consistent beliefs are obtained by not explicitly addressing overconfidence in the loss function used for training of the GNN.