 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Machine Learning for Naval Architecture, Ocean and Marine Engineering
Sep 01, 2021
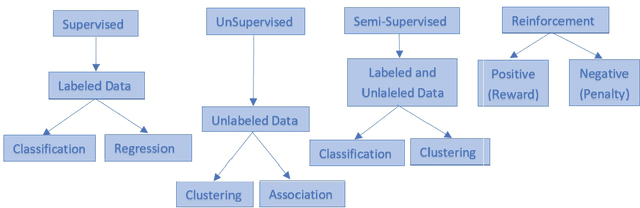
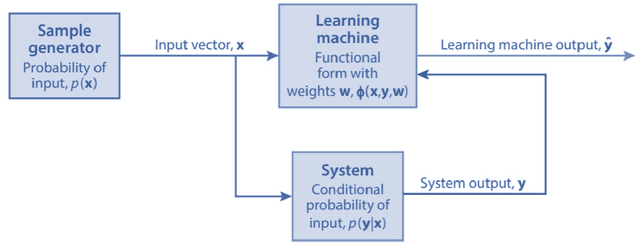
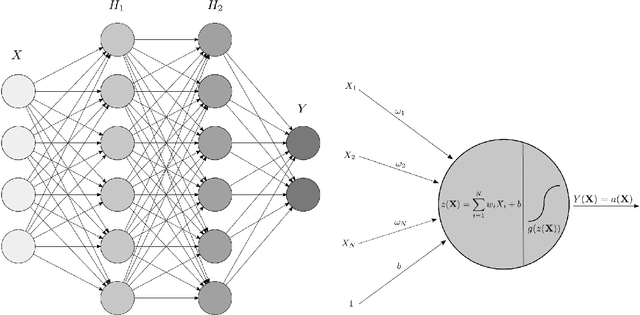
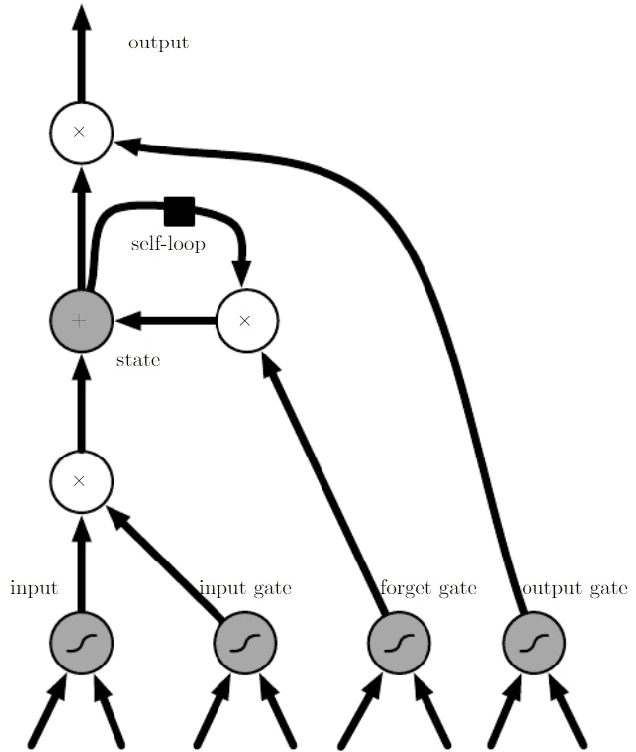
Machine Learning (ML) based algorithms have found significant impact in many fields of engineering and sciences, where datasets are available from experiments and high fidelity numerical simulations. Those datasets are generally utilized in a machine learning model to extract information about the underlying physics and derive functional relationships mapping input variables to target quantities of interest. Commonplace machine learning algorithms utilized in Scientific Machine Learning (SciML) include neural networks, regression trees, random forests, support vector machines, etc. The focus of this article is to review the applications of ML in naval architecture, ocean, and marine engineering problems; and identify priority directions of research. We discuss the applications of machine learning algorithms for different problems such as wave height prediction, calculation of wind loads on ships, damage detection of offshore platforms, calculation of ship added resistance, and various other applications in coastal and marine environments. The details of the data sets including the source of data-sets utilized in the ML model development are included. The features used as the inputs to the ML models are presented in detail and finally, the methods employed in optimization of the ML models were also discussed. Based on this comprehensive analysis we point out future directions of research that may be fruitful for the application of ML to the ocean and marine engineering problems.
CN-LBP: Complex Networks-based Local Binary Patterns for Texture Classification
Jun 04, 2021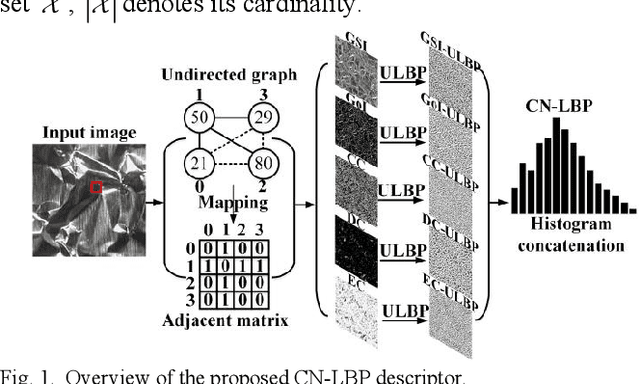
To effectively overcome the limitations of local binary patterns (LBP), this letter proposes a new texture descriptor aided by complex networks (CN) and uniform LBP (ULBP), namely, CN-LBP. Specifically, we first abstract a gray-scale image (GSI) as an undirected graph with the help of pixel distance and intensity, and gradient of image (GoI). Second, three variants of CN-based feature measurements (clustering coefficient, degree centrality, and eigenvector centrality) are proposed to decipher the image spatial-relationship, energy, and entropy, respectively, thus generating three feature maps, which can retain the image information as much as possible. Third, given the generated feature maps, we apply ULBP on feature maps, GSI, and GoI, and obtain the discriminative representation of the texture image. Finally, CN-LBP is obtained by jointly calculating and concatenating the spatial histograms. In contrast to original LBP, the proposed texture descriptor contains more detailed image information and shows certain resistance to noise. Experiment results show that the proposed approach significantly improves the texture classification accuracy compared with state-of-the-art LBP-based variants and deep learning-based approaches.
Ranking labs-of-origin for genetically engineered DNA using Metric Learning
Jul 16, 2021
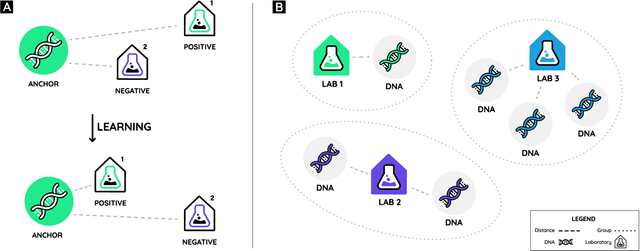
With the constant advancements of genetic engineering, a common concern is to be able to identify the lab-of-origin of genetically engineered DNA sequences. For that reason, AltLabs has hosted the genetic Engineering Attribution Challenge to gather many teams to propose new tools to solve this problem. Here we show our proposed method to rank the most likely labs-of-origin and generate embeddings for DNA sequences and labs. These embeddings can also perform various other tasks, like clustering both DNA sequences and labs and using them as features for Machine Learning models applied to solve other problems. This work demonstrates that our method outperforms the classic training method for this task while generating other helpful information.
Conditional Generation of Synthetic Geospatial Images from Pixel-level and Feature-level Inputs
Sep 11, 2021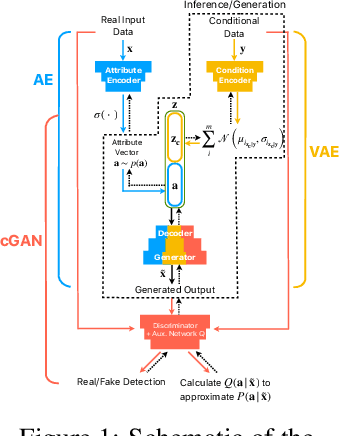
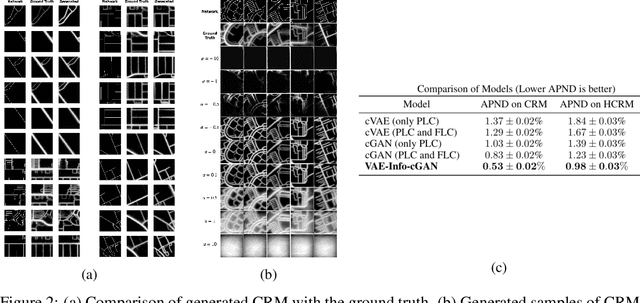
Training robust supervised deep learning models for many geospatial applications of computer vision is difficult due to dearth of class-balanced and diverse training data. Conversely, obtaining enough training data for many applications is financially prohibitive or may be infeasible, especially when the application involves modeling rare or extreme events. Synthetically generating data (and labels) using a generative model that can sample from a target distribution and exploit the multi-scale nature of images can be an inexpensive solution to address scarcity of labeled data. Towards this goal, we present a deep conditional generative model, called VAE-Info-cGAN, that combines a Variational Autoencoder (VAE) with a conditional Information Maximizing Generative Adversarial Network (InfoGAN), for synthesizing semantically rich images simultaneously conditioned on a pixel-level condition (PLC) and a macroscopic feature-level condition (FLC). Dimensionally, the PLC can only vary in the channel dimension from the synthesized image and is meant to be a task-specific input. The FLC is modeled as an attribute vector in the latent space of the generated image which controls the contributions of various characteristic attributes germane to the target distribution. Experiments on a GPS trajectories dataset show that the proposed model can accurately generate various forms of spatiotemporal aggregates across different geographic locations while conditioned only on a raster representation of the road network. The primary intended application of the VAE-Info-cGAN is synthetic data (and label) generation for targeted data augmentation for computer vision-based modeling of problems relevant to geospatial analysis and remote sensing.
Exploration in Deep Reinforcement Learning: A Comprehensive Survey
Sep 15, 2021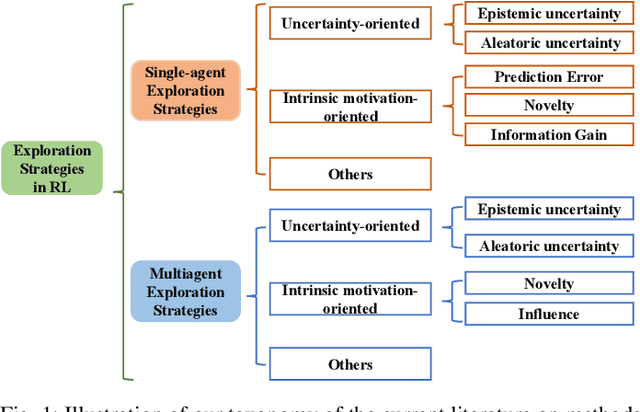
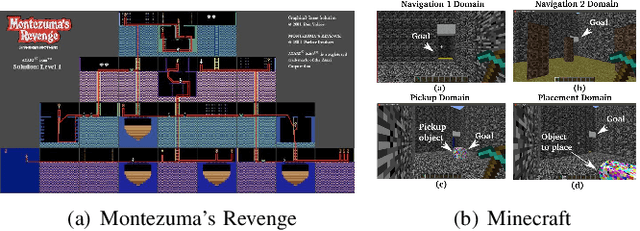

Deep Reinforcement Learning (DRL) and Deep Multi-agent Reinforcement Learning (MARL) have achieved significant success across a wide range of domains, such as game AI, autonomous vehicles, robotics and finance. However, DRL and deep MARL agents are widely known to be sample-inefficient and millions of interactions are usually needed even for relatively simple game settings, thus preventing the wide application in real-industry scenarios. One bottleneck challenge behind is the well-known exploration problem, i.e., how to efficiently explore the unknown environments and collect informative experiences that could benefit the policy learning most. In this paper, we conduct a comprehensive survey on existing exploration methods in DRL and deep MARL for the purpose of providing understandings and insights on the critical problems and solutions. We first identify several key challenges to achieve efficient exploration, which most of the exploration methods aim at addressing. Then we provide a systematic survey of existing approaches by classifying them into two major categories: uncertainty-oriented exploration and intrinsic motivation-oriented exploration. The essence of uncertainty-oriented exploration is to leverage the quantification of the epistemic and aleatoric uncertainty to derive efficient exploration. By contrast, intrinsic motivation-oriented exploration methods usually incorporate different reward agnostic information for intrinsic exploration guidance. Beyond the above two main branches, we also conclude other exploration methods which adopt sophisticated techniques but are difficult to be classified into the above two categories. In addition, we provide a comprehensive empirical comparison of exploration methods for DRL on a set of commonly used benchmarks. Finally, we summarize the open problems of exploration in DRL and deep MARL and point out a few future directions.
Visual Recognition with Deep Learning from Biased Image Datasets
Sep 06, 2021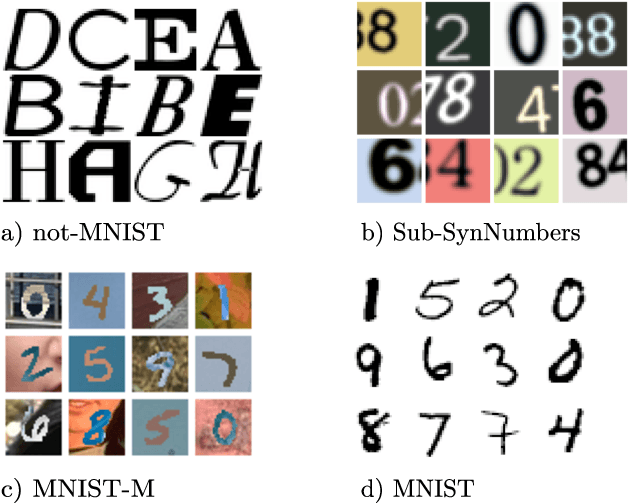
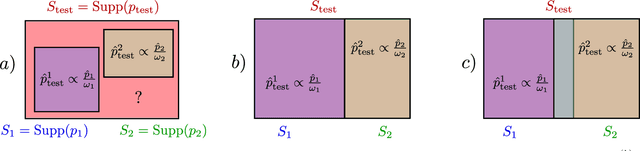
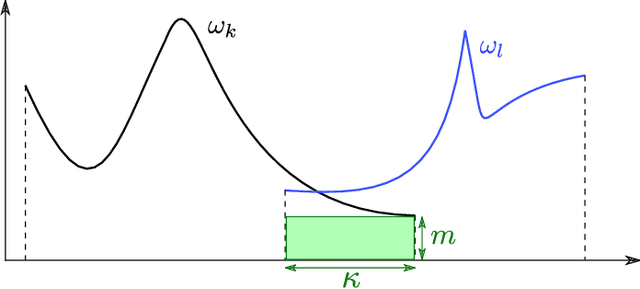
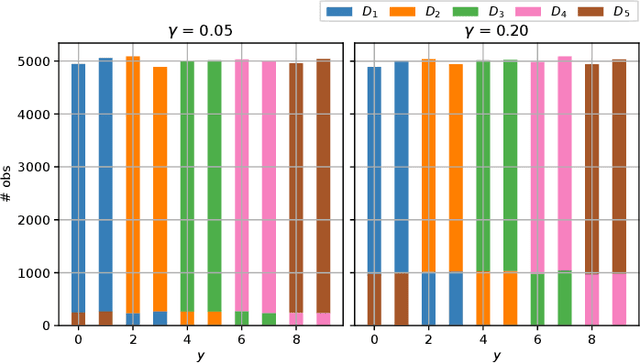
In practice, and more especially when training deep neural networks, visual recognition rules are often learned based on various sources of information. On the other hand, the recent deployment of facial recognition systems with uneven predictive performances on different population segments highlights the representativeness issues possibly induced by a naive aggregation of image datasets. Indeed, sampling bias does not vanish simply by considering larger datasets, and ignoring its impact may completely jeopardize the generalization capacity of the learned prediction rules. In this paper, we show how biasing models, originally introduced for nonparametric estimation in (Gill et al., 1988), and recently revisited from the perspective of statistical learning theory in (Laforgue and Cl\'emen\c{c}on, 2019), can be applied to remedy these problems in the context of visual recognition. Based on the (approximate) knowledge of the biasing mechanisms at work, our approach consists in reweighting the observations, so as to form a nearly debiased estimator of the target distribution. One key condition for our method to be theoretically valid is that the supports of the distributions generating the biased datasets at disposal must overlap, and cover the support of the target distribution. In order to meet this requirement in practice, we propose to use a low dimensional image representation, shared across the image databases. Finally, we provide numerical experiments highlighting the relevance of our approach whenever the biasing functions are appropriately chosen.
Is Pseudo-Lidar needed for Monocular 3D Object detection?
Aug 13, 2021
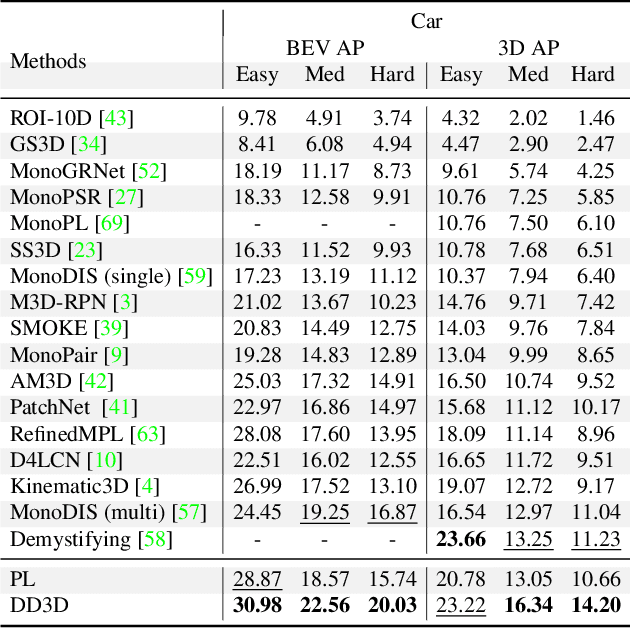
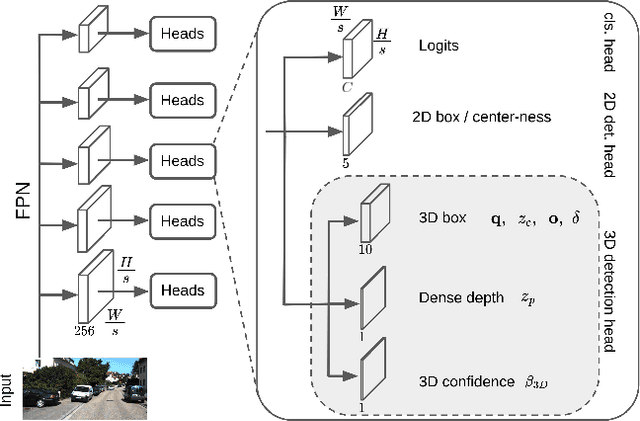
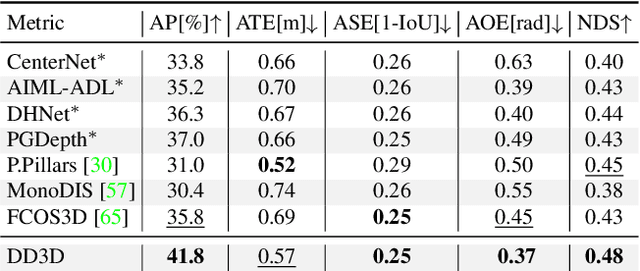
Recent progress in 3D object detection from single images leverages monocular depth estimation as a way to produce 3D pointclouds, turning cameras into pseudo-lidar sensors. These two-stage detectors improve with the accuracy of the intermediate depth estimation network, which can itself be improved without manual labels via large-scale self-supervised learning. However, they tend to suffer from overfitting more than end-to-end methods, are more complex, and the gap with similar lidar-based detectors remains significant. In this work, we propose an end-to-end, single stage, monocular 3D object detector, DD3D, that can benefit from depth pre-training like pseudo-lidar methods, but without their limitations. Our architecture is designed for effective information transfer between depth estimation and 3D detection, allowing us to scale with the amount of unlabeled pre-training data. Our method achieves state-of-the-art results on two challenging benchmarks, with 16.34% and 9.28% AP for Cars and Pedestrians (respectively) on the KITTI-3D benchmark, and 41.5% mAP on NuScenes.
Curvature Graph Neural Network
Jun 30, 2021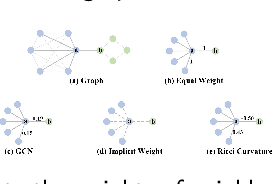

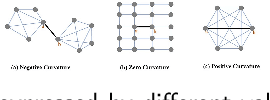
Graph neural networks (GNNs) have achieved great success in many graph-based tasks. Much work is dedicated to empowering GNNs with the adaptive locality ability, which enables measuring the importance of neighboring nodes to the target node by a node-specific mechanism. However, the current node-specific mechanisms are deficient in distinguishing the importance of nodes in the topology structure. We believe that the structural importance of neighboring nodes is closely related to their importance in aggregation. In this paper, we introduce discrete graph curvature (the Ricci curvature) to quantify the strength of structural connection of pairwise nodes. And we propose Curvature Graph Neural Network (CGNN), which effectively improves the adaptive locality ability of GNNs by leveraging the structural property of graph curvature. To improve the adaptability of curvature to various datasets, we explicitly transform curvature into the weights of neighboring nodes by the necessary Negative Curvature Processing Module and Curvature Normalization Module. Then, we conduct numerous experiments on various synthetic datasets and real-world datasets. The experimental results on synthetic datasets show that CGNN effectively exploits the topology structure information, and the performance is improved significantly. CGNN outperforms the baselines on 5 dense node classification benchmark datasets. This study deepens the understanding of how to utilize advanced topology information and assign the importance of neighboring nodes from the perspective of graph curvature and encourages us to bridge the gap between graph theory and neural networks.
Information-Theoretic Bounds and Approximations in Neural Population Coding
Nov 07, 2017While Shannon's mutual information has widespread applications in many disciplines, for practical applications it is often difficult to calculate its value accurately for high-dimensional variables because of the curse of dimensionality. This paper is focused on effective approximation methods for evaluating mutual information in the context of neural population coding. For large but finite neural populations, we derive several information-theoretic asymptotic bounds and approximation formulas that remain valid in high-dimensional spaces. We prove that optimizing the population density distribution based on these approximation formulas is a convex optimization problem which allows efficient numerical solutions. Numerical simulation results confirmed that our asymptotic formulas were highly accurate for approximating mutual information for large neural populations. In special cases, the approximation formulas are exactly equal to the true mutual information. We also discuss techniques of variable transformation and dimensionality reduction to facilitate computation of the approximations.
Entropic alternatives to initialization
Jul 16, 2021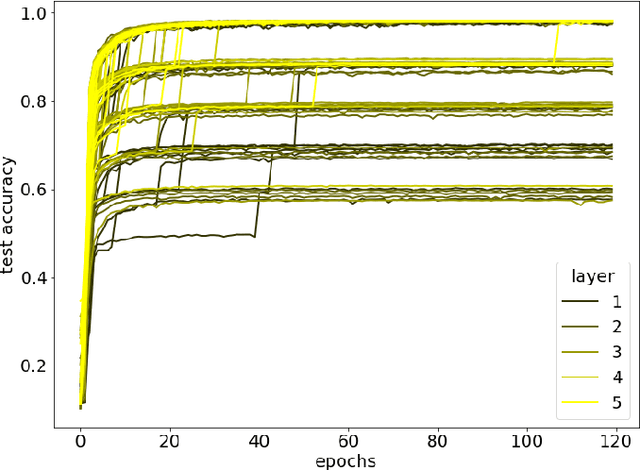
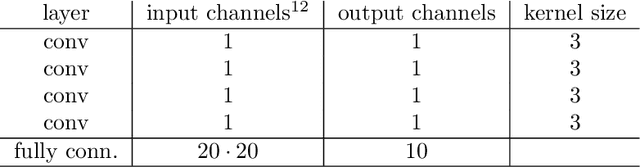
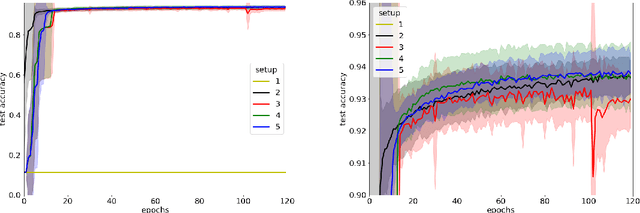
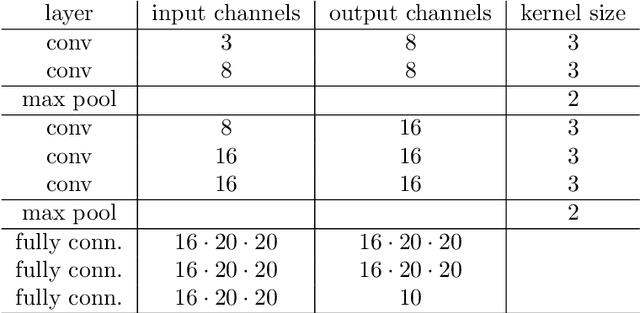
Local entropic loss functions provide a versatile framework to define architecture-aware regularization procedures. Besides the possibility of being anisotropic in the synaptic space, the local entropic smoothening of the loss function can vary during training, thus yielding a tunable model complexity. A scoping protocol where the regularization is strong in the early-stage of the training and then fades progressively away constitutes an alternative to standard initialization procedures for deep convolutional neural networks, nonetheless, it has wider applicability. We analyze anisotropic, local entropic smoothenings in the language of statistical physics and information theory, providing insight into both their interpretation and workings. We comment some aspects related to the physics of renormalization and the spacetime structure of convolutional networks.