 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Graph Feature Gating Networks
May 10, 2021
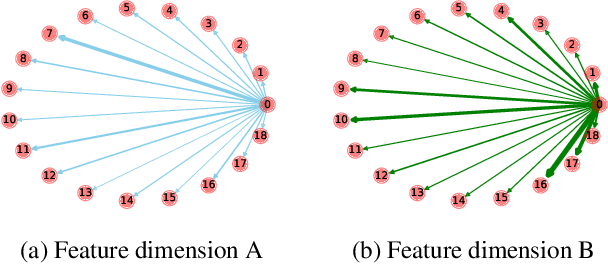
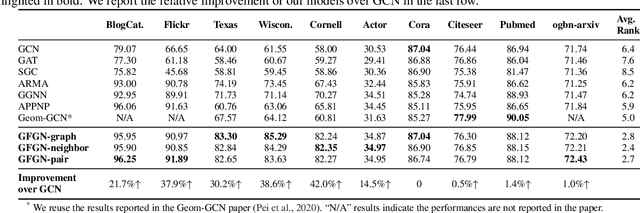
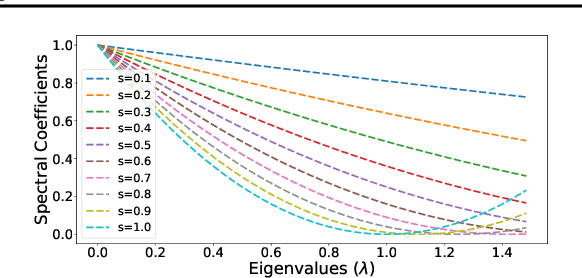
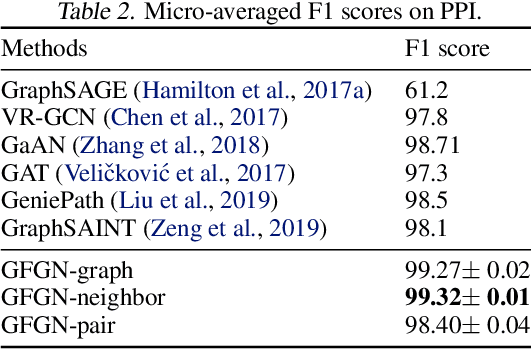
Graph neural networks (GNNs) have received tremendous attention due to their power in learning effective representations for graphs. Most GNNs follow a message-passing scheme where the node representations are updated by aggregating and transforming the information from the neighborhood. Meanwhile, they adopt the same strategy in aggregating the information from different feature dimensions. However, suggested by social dimension theory and spectral embedding, there are potential benefits to treat the dimensions differently during the aggregation process. In this work, we investigate to enable heterogeneous contributions of feature dimensions in GNNs. In particular, we propose a general graph feature gating network (GFGN) based on the graph signal denoising problem and then correspondingly introduce three graph filters under GFGN to allow different levels of contributions from feature dimensions. Extensive experiments on various real-world datasets demonstrate the effectiveness and robustness of the proposed frameworks.
Learning data association without data association: An EM approach to neural assignment prediction
May 02, 2021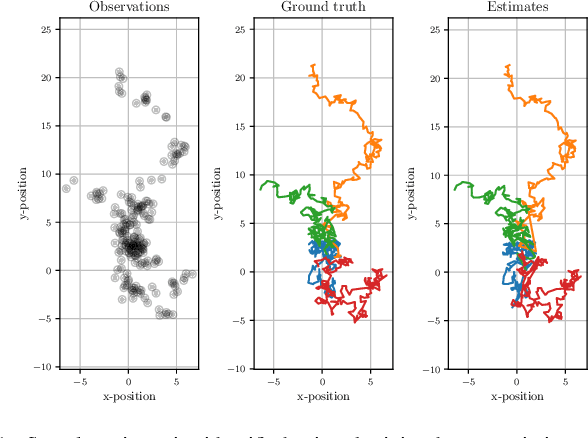
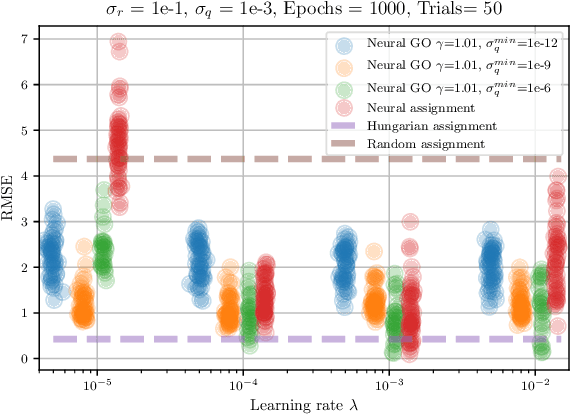
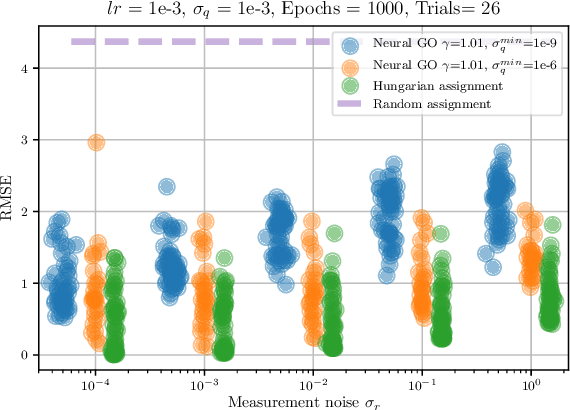
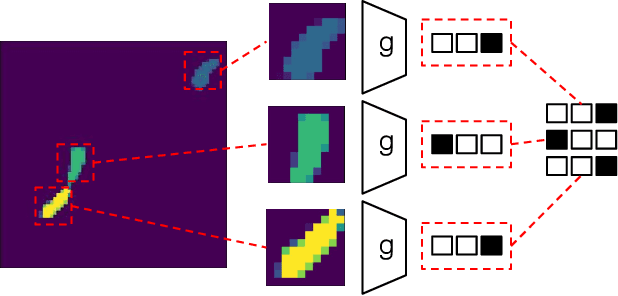
Data association is a fundamental component of effective multi-object tracking. Current approaches to data-association tend to frame this as an assignment problem relying on gating and distance-based cost matrices, or offset the challenge of data association to a problem of tracking by detection. The latter is typically formulated as a supervised learning problem, and requires labelling information about tracked object identities to train a model for object recognition. This paper introduces an expectation maximisation approach to train neural models for data association, which does not require labelling information. Here, a Sinkhorn network is trained to predict assignment matrices that maximise the marginal likelihood of trajectory observations. Importantly, networks trained using the proposed approach can be re-used in downstream tracking applications.
NRGNN: Learning a Label Noise-Resistant Graph Neural Network on Sparsely and Noisily Labeled Graphs
Jun 08, 2021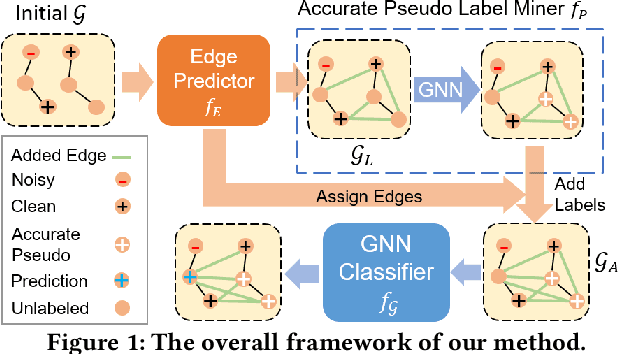
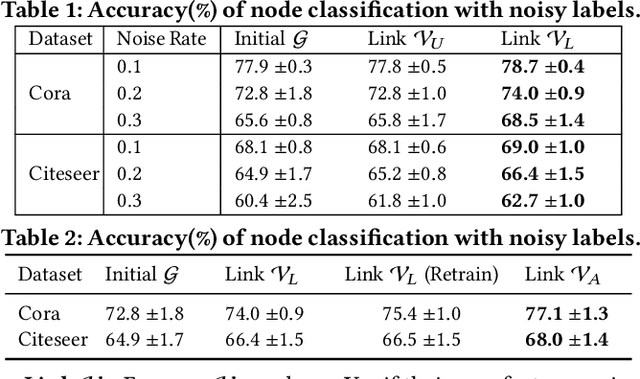
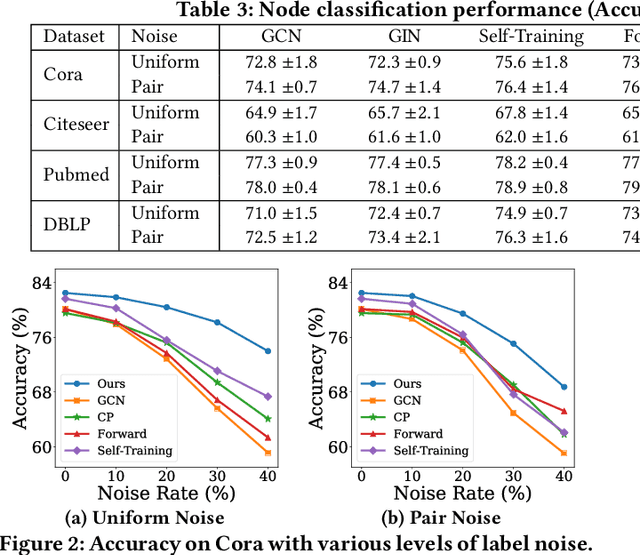
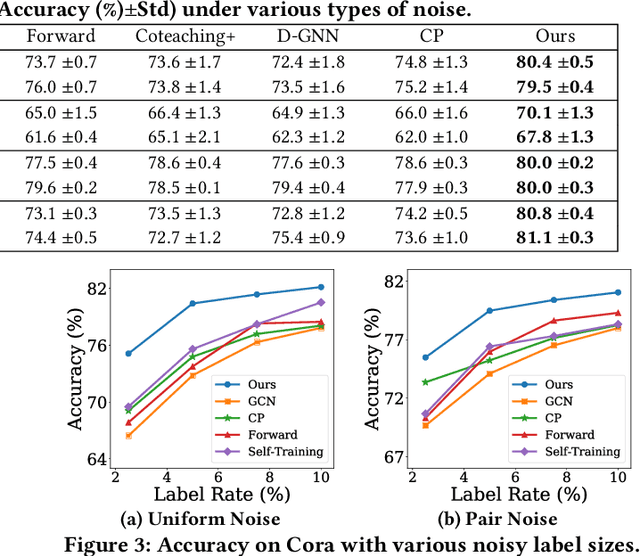
Graph Neural Networks (GNNs) have achieved promising results for semi-supervised learning tasks on graphs such as node classification. Despite the great success of GNNs, many real-world graphs are often sparsely and noisily labeled, which could significantly degrade the performance of GNNs, as the noisy information could propagate to unlabeled nodes via graph structure. Thus, it is important to develop a label noise-resistant GNN for semi-supervised node classification. Though extensive studies have been conducted to learn neural networks with noisy labels, they mostly focus on independent and identically distributed data and assume a large number of noisy labels are available, which are not directly applicable for GNNs. Thus, we investigate a novel problem of learning a robust GNN with noisy and limited labels. To alleviate the negative effects of label noise, we propose to link the unlabeled nodes with labeled nodes of high feature similarity to bring more clean label information. Furthermore, accurate pseudo labels could be obtained by this strategy to provide more supervision and further reduce the effects of label noise. Our theoretical and empirical analysis verify the effectiveness of these two strategies under mild conditions. Extensive experiments on real-world datasets demonstrate the effectiveness of the proposed method in learning a robust GNN with noisy and limited labels.
Deep PET/CT fusion with Dempster-Shafer theory for lymphoma segmentation
Aug 11, 2021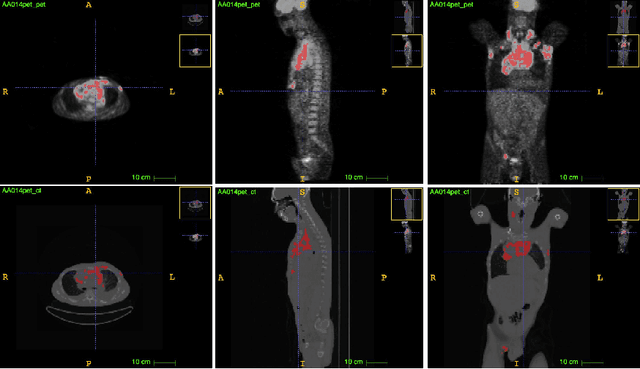
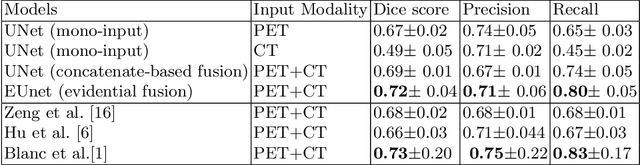
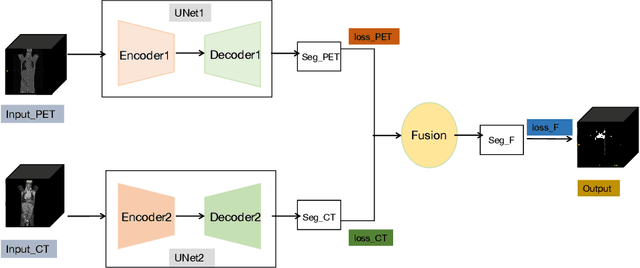
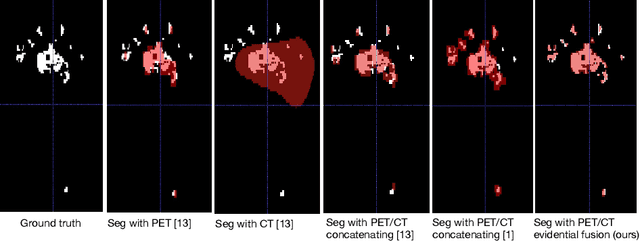
Lymphoma detection and segmentation from whole-body Positron Emission Tomography/Computed Tomography (PET/CT) volumes are crucial for surgical indication and radiotherapy. Designing automatic segmentation methods capable of effectively exploiting the information from PET and CT as well as resolving their uncertainty remain a challenge. In this paper, we propose an lymphoma segmentation model using an UNet with an evidential PET/CT fusion layer. Single-modality volumes are trained separately to get initial segmentation maps and an evidential fusion layer is proposed to fuse the two pieces of evidence using Dempster-Shafer theory (DST). Moreover, a multi-task loss function is proposed: in addition to the use of the Dice loss for PET and CT segmentation, a loss function based on the concordance between the two segmentation is added to constrain the final segmentation. We evaluate our proposal on a database of polycentric PET/CT volumes of patients treated for lymphoma, delineated by the experts. Our method get accurate segmentation results with Dice score of 0.726, without any user interaction. Quantitative results show that our method is superior to the state-of-the-art methods.
Assessing putative bias in prediction of anti-microbial resistance from real-world genotyping data under explicit causal assumptions
Jul 06, 2021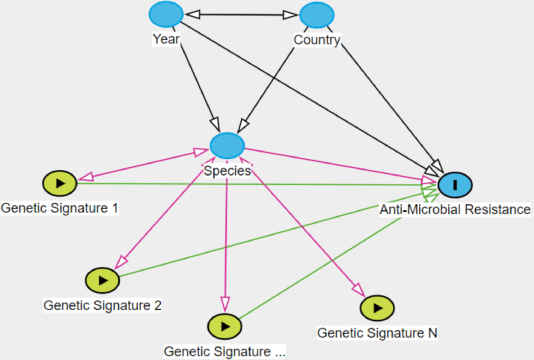
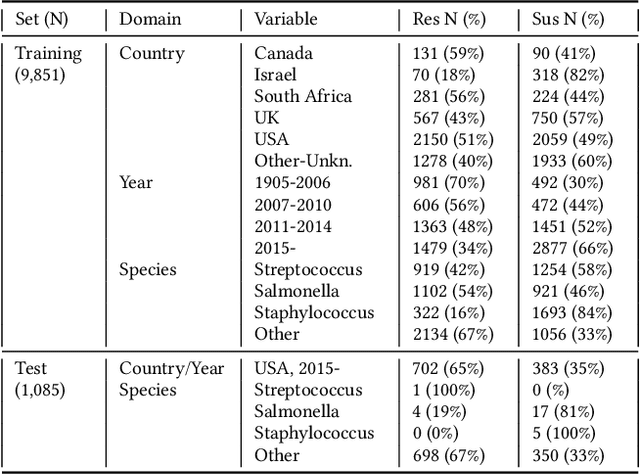
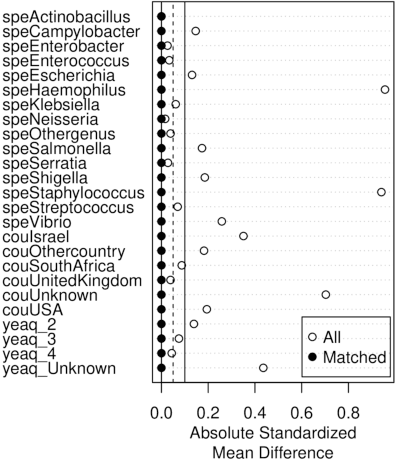
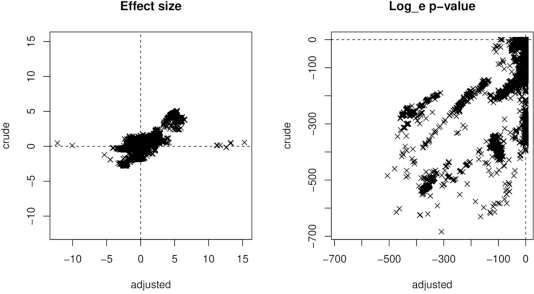
Whole genome sequencing (WGS) is quickly becoming the customary means for identification of antimicrobial resistance (AMR) due to its ability to obtain high resolution information about the genes and mechanisms that are causing resistance and driving pathogen mobility. By contrast, traditional phenotypic (antibiogram) testing cannot easily elucidate such information. Yet development of AMR prediction tools from genotype-phenotype data can be biased, since sampling is non-randomized. Sample provenience, period of collection, and species representation can confound the association of genetic traits with AMR. Thus, prediction models can perform poorly on new data with sampling distribution shifts. In this work -- under an explicit set of causal assumptions -- we evaluate the effectiveness of propensity-based rebalancing and confounding adjustment on AMR prediction using genotype-phenotype AMR data from the Pathosystems Resource Integration Center (PATRIC). We select bacterial genotypes (encoded as k-mer signatures, i.e. DNA fragments of length k), country, year, species, and AMR phenotypes for the tetracycline drug class, preparing test data with recent genomes coming from a single country. We test boosted logistic regression (BLR) and random forests (RF) with/without bias-handling. On 10,936 instances, we find evidence of species, location and year imbalance with respect to the AMR phenotype. The crude versus bias-adjusted change in effect of genetic signatures on AMR varies but only moderately (selecting the top 20,000 out of 40+ million k-mers). The area under the receiver operating characteristic (AUROC) of the RF (0.95) is comparable to that of BLR (0.94) on both out-of-bag samples from bootstrap and the external test (n=1,085), where AUROCs do not decrease. We observe a 1%-5% gain in AUROC with bias-handling compared to the sole use of genetic signatures. ...
MM-Rec: Multimodal News Recommendation
Apr 15, 2021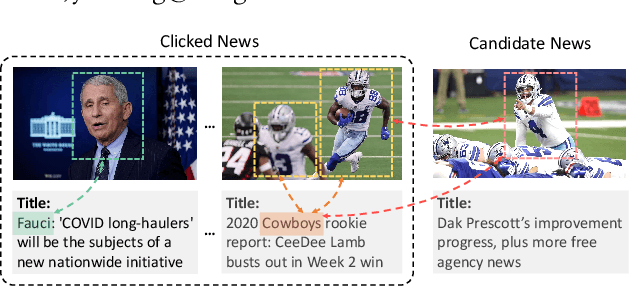

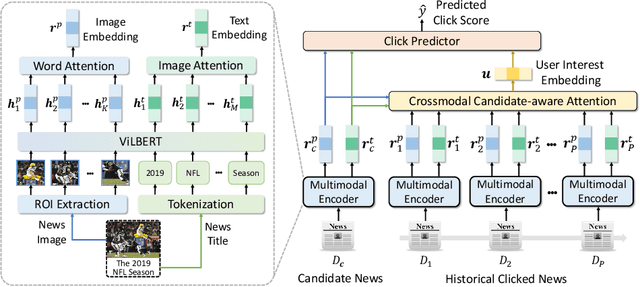
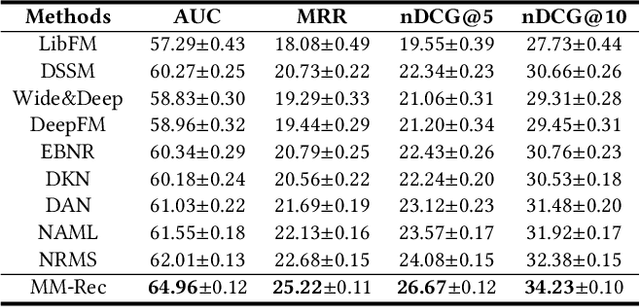
Accurate news representation is critical for news recommendation. Most of existing news representation methods learn news representations only from news texts while ignore the visual information in news like images. In fact, users may click news not only because of the interest in news titles but also due to the attraction of news images. Thus, images are useful for representing news and predicting user behaviors. In this paper, we propose a multimodal news recommendation method, which can incorporate both textual and visual information of news to learn multimodal news representations. We first extract region-of-interests (ROIs) from news images via objective detection. Then we use a pre-trained visiolinguistic model to encode both news texts and news image ROIs and model their inherent relatedness using co-attentional Transformers. In addition, we propose a crossmodal candidate-aware attention network to select relevant historical clicked news for accurate user modeling by measuring the crossmodal relatedness between clicked news and candidate news. Experiments validate that incorporating multimodal news information can effectively improve news recommendation.
Spatial and Temporal Networks for Facial Expression Recognition in the Wild Videos
Jul 12, 2021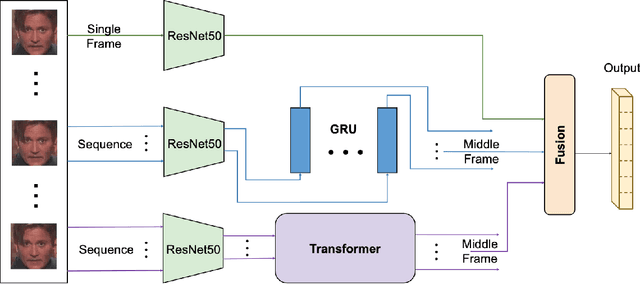
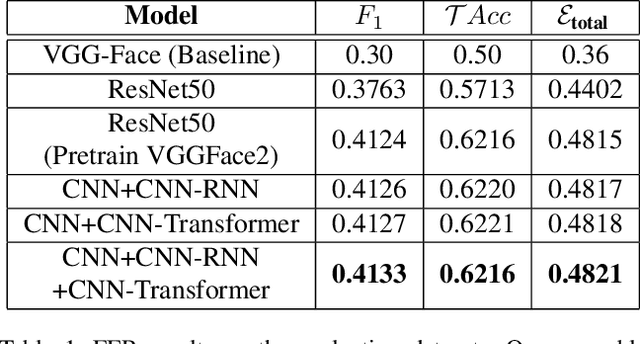
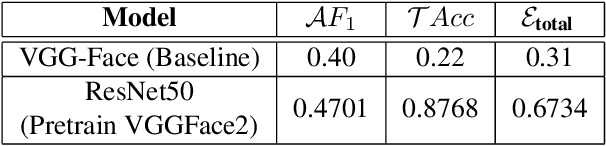
The paper describes our proposed methodology for the seven basic expression classification track of Affective Behavior Analysis in-the-wild (ABAW) Competition 2021. In this task, facial expression recognition (FER) methods aim to classify the correct expression category from a diverse background, but there are several challenges. First, to adapt the model to in-the-wild scenarios, we use the knowledge from pre-trained large-scale face recognition data. Second, we propose an ensemble model with a convolution neural network (CNN), a CNN-recurrent neural network (CNN-RNN), and a CNN-Transformer (CNN-Transformer), to incorporate both spatial and temporal information. Our ensemble model achieved F1 as 0.4133, accuracy as 0.6216 and final metric as 0.4821 on the validation set.
Compressing gradients by exploiting temporal correlation in momentum-SGD
Aug 17, 2021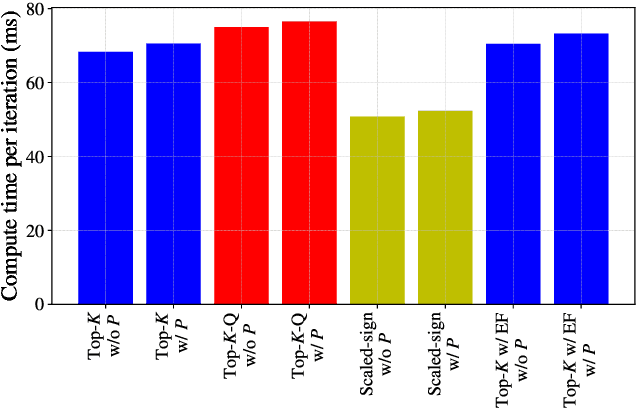
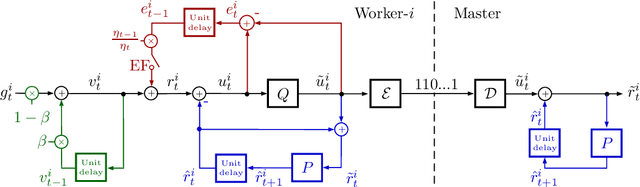
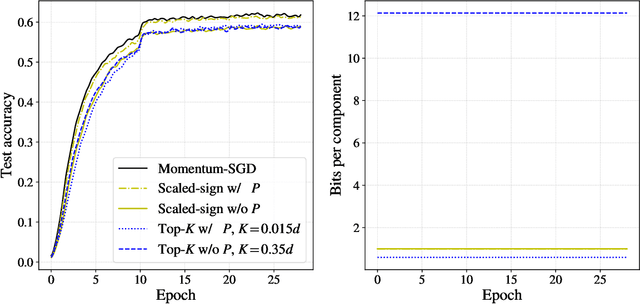
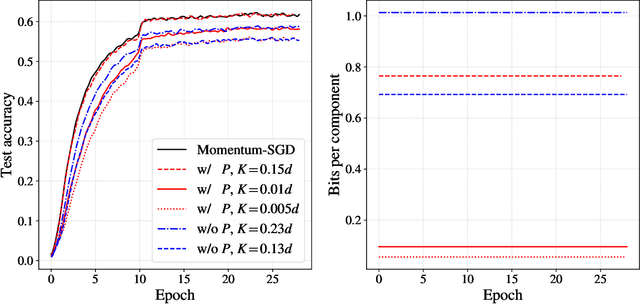
An increasing bottleneck in decentralized optimization is communication. Bigger models and growing datasets mean that decentralization of computation is important and that the amount of information exchanged is quickly growing. While compression techniques have been introduced to cope with the latter, none has considered leveraging the temporal correlations that exist in consecutive vector updates. An important example is distributed momentum-SGD where temporal correlation is enhanced by the low-pass-filtering effect of applying momentum. In this paper we design and analyze compression methods that exploit temporal correlation in systems both with and without error-feedback. Experiments with the ImageNet dataset demonstrate that our proposed methods offer significant reduction in the rate of communication at only a negligible increase in computation complexity. We further analyze the convergence of SGD when compression is applied with error-feedback. In the literature, convergence guarantees are developed only for compressors that provide error-bounds point-wise, i.e., for each input to the compressor. In contrast, many important codes (e.g. rate-distortion codes) provide error-bounds only in expectation and thus provide a more general guarantee. In this paper we prove the convergence of SGD under an expected error assumption by establishing a bound for the minimum gradient norm.
* This paper was presented in part at the 11th International Symposium on Topics in Coding (ISTC), Montreal, QC, Canada, August 2021, and the paper has been accepted for publication in the IEEE Journal on Selected Areas in Information Theory (JSAIT) Volume 2, Issue 3 (2021), https://ieeexplore.ieee.org/document/9511618
Few-Shot Learning Through an Information Retrieval Lens
Nov 14, 2017
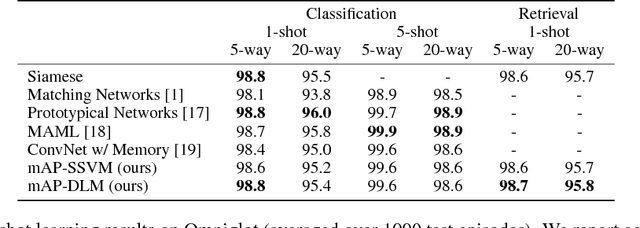
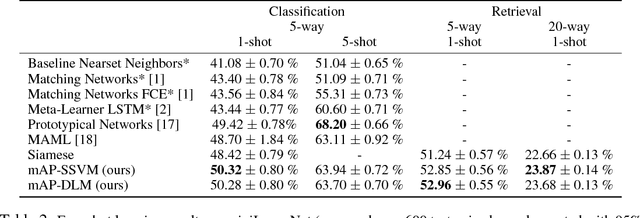
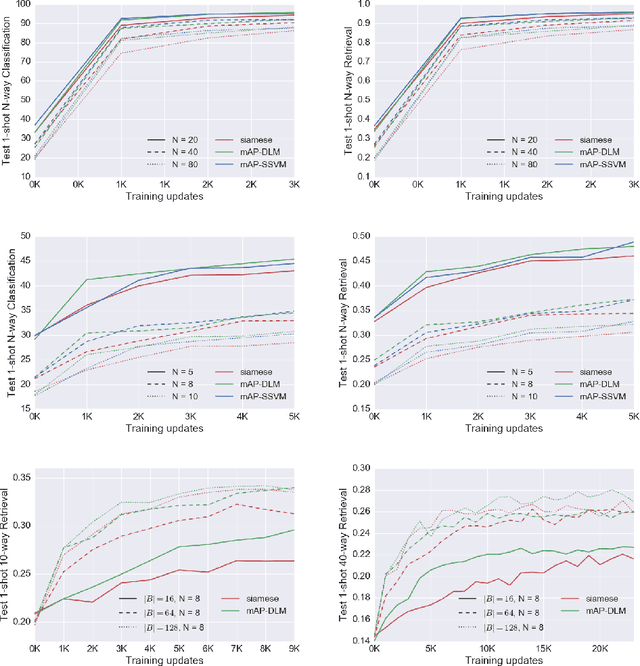
Few-shot learning refers to understanding new concepts from only a few examples. We propose an information retrieval-inspired approach for this problem that is motivated by the increased importance of maximally leveraging all the available information in this low-data regime. We define a training objective that aims to extract as much information as possible from each training batch by effectively optimizing over all relative orderings of the batch points simultaneously. In particular, we view each batch point as a `query' that ranks the remaining ones based on its predicted relevance to them and we define a model within the framework of structured prediction to optimize mean Average Precision over these rankings. Our method achieves impressive results on the standard few-shot classification benchmarks while is also capable of few-shot retrieval.
OKSP: A Novel Deep Learning Automatic Event Detection Pipeline for Seismic Monitoringin Costa Rica
Sep 06, 2021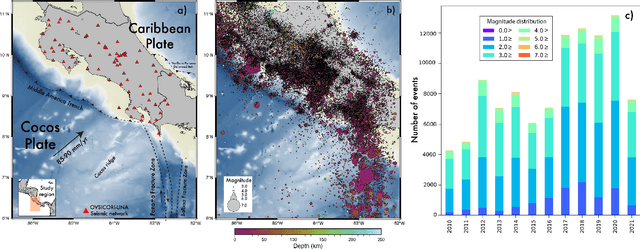
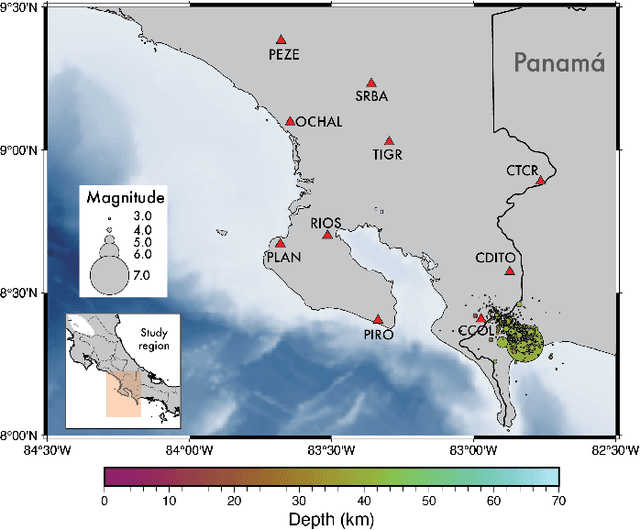
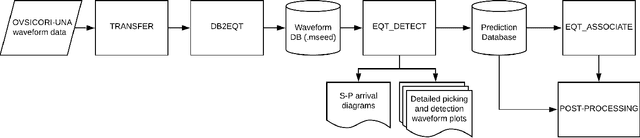
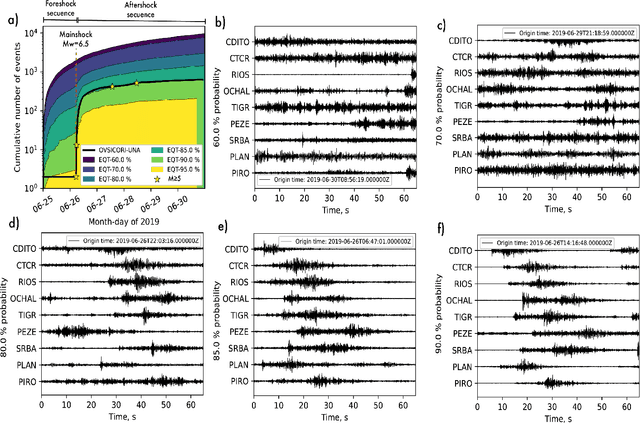
Small magnitude earthquakes are the most abundant but the most difficult to locate robustly and well due to their low amplitudes and high frequencies usually obscured by heterogeneous noise sources. They highlight crucial information about the stress state and the spatio-temporal behavior of fault systems during the earthquake cycle, therefore, its full characterization is then crucial for improving earthquake hazard assessment. Modern DL algorithms along with the increasing computational power are exploiting the continuously growing seismological databases, allowing scientists to improve the completeness for earthquake catalogs, systematically detecting smaller magnitude earthquakes and reducing the errors introduced mainly by human intervention. In this work, we introduce OKSP, a novel automatic earthquake detection pipeline for seismic monitoring in Costa Rica. Using Kabre supercomputer from the Costa Rica High Technology Center, we applied OKSP to the day before and the first 5 days following the Puerto Armuelles, M6.5, earthquake that occurred on 26 June, 2019, along the Costa Rica-Panama border and found 1100 more earthquakes previously unidentified by the Volcanological and Seismological Observatory of Costa Rica. From these events, a total of 23 earthquakes with magnitudes below 1.0 occurred a day to hours prior to the mainshock, shedding light about the rupture initiation and earthquake interaction leading to the occurrence of this productive seismic sequence. Our observations show that for the study period, the model was 100% exhaustive and 82% precise, resulting in an F1 score of 0.90. This effort represents the very first attempt for automatically detecting earthquakes in Costa Rica using deep learning methods and demonstrates that, in the near future, earthquake monitoring routines will be carried out entirely by AI algorithms.