 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Modelling and Reasoning Techniques for Context Aware Computing in Intelligent Transportation System
Jul 29, 2021
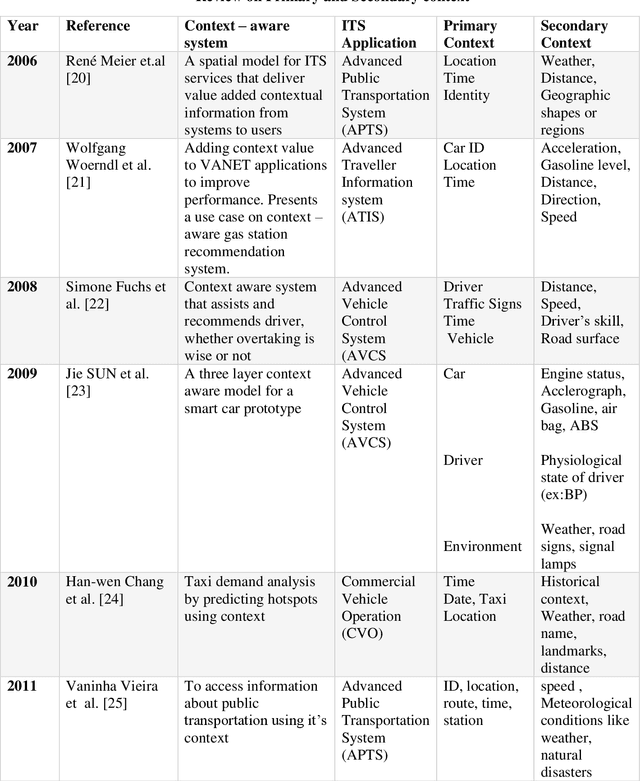
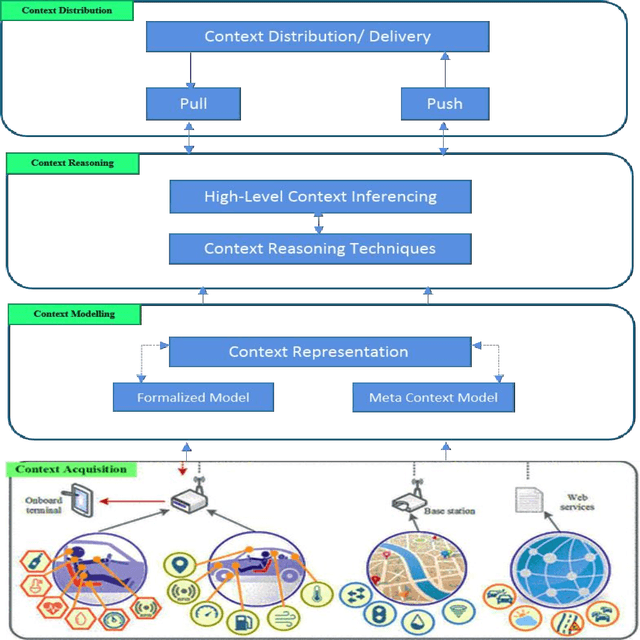
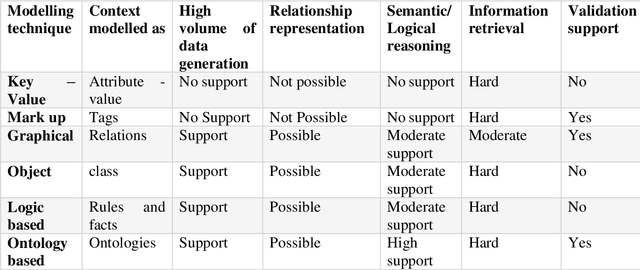
The emergence of Internet of Things technology and recent advancement in sensor networks enabled transportation systems to a new dimension called Intelligent Transportation System. Due to increased usage of vehicles and communication among entities in road traffic scenarios, the amount of raw data generation in Intelligent Transportation System is huge. This raw data are to be processed to infer contextual information and provide new services related to different modes of road transport such as traffic signal management, accident prediction, object detection etc. To understand the importance of context, this article aims to study context awareness in the Intelligent Transportation System. We present a review on prominent applications developed in the literature concerning context awareness in the intelligent transportation system. The objective of this research paper is to highlight context and its features in ITS and to address the applicability of modelling techniques and reasoning approaches in Intelligent Transportation System. Also to shed light on impact of Internet of Things and machine learning in Intelligent Transportation System development.
Dual-Tuning: Joint Prototype Transfer and Structure Regularization for Compatible Feature Learning
Aug 06, 2021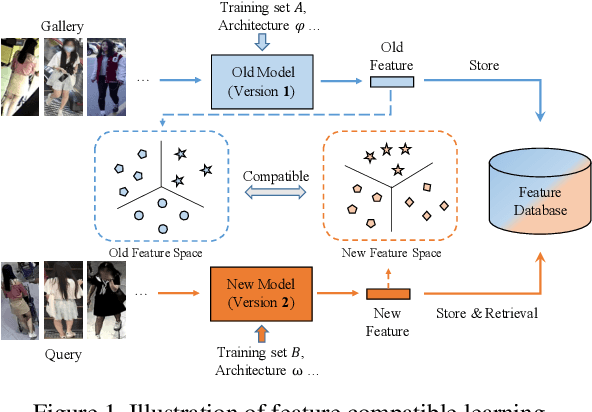
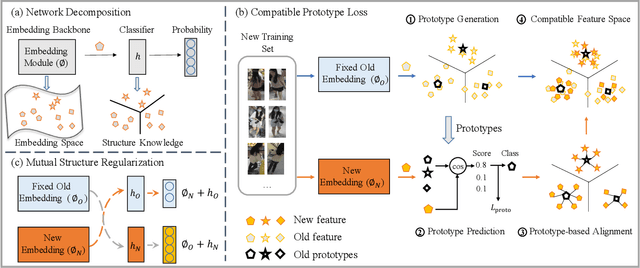
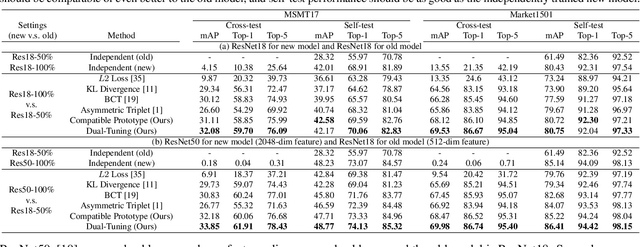
Visual retrieval system faces frequent model update and deployment. It is a heavy workload to re-extract features of the whole database every time.Feature compatibility enables the learned new visual features to be directly compared with the old features stored in the database. In this way, when updating the deployed model, we can bypass the inflexible and time-consuming feature re-extraction process. However, the old feature space that needs to be compatible is not ideal and faces the distribution discrepancy problem with the new space caused by different supervision losses. In this work, we propose a global optimization Dual-Tuning method to obtain feature compatibility against different networks and losses. A feature-level prototype loss is proposed to explicitly align two types of embedding features, by transferring global prototype information. Furthermore, we design a component-level mutual structural regularization to implicitly optimize the feature intrinsic structure. Experimental results on million-scale datasets demonstrate that our Dual-Tuning is able to obtain feature compatibility without sacrificing performance. (Our code will be avaliable at https://github.com/yanbai1993/Dual-Tuning)
IMG2SMI: Translating Molecular Structure Images to Simplified Molecular-input Line-entry System
Sep 03, 2021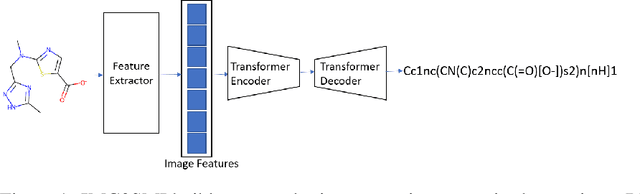
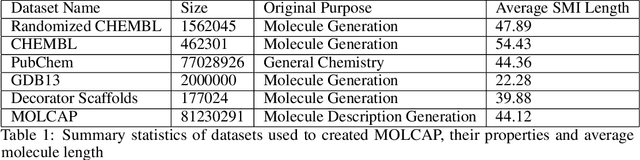

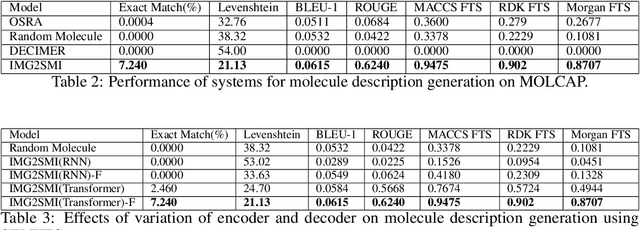
Like many scientific fields, new chemistry literature has grown at a staggering pace, with thousands of papers released every month. A large portion of chemistry literature focuses on new molecules and reactions between molecules. Most vital information is conveyed through 2-D images of molecules, representing the underlying molecules or reactions described. In order to ensure reproducible and machine-readable molecule representations, text-based molecule descriptors like SMILES and SELFIES were created. These text-based molecule representations provide molecule generation but are unfortunately rarely present in published literature. In the absence of molecule descriptors, the generation of molecule descriptors from the 2-D images present in the literature is necessary to understand chemistry literature at scale. Successful methods such as Optical Structure Recognition Application (OSRA), and ChemSchematicResolver are able to extract the locations of molecules structures in chemistry papers and infer molecular descriptions and reactions. While effective, existing systems expect chemists to correct outputs, making them unsuitable for unsupervised large-scale data mining. Leveraging the task formulation of image captioning introduced by DECIMER, we introduce IMG2SMI, a model which leverages Deep Residual Networks for image feature extraction and an encoder-decoder Transformer layers for molecule description generation. Unlike previous Neural Network-based systems, IMG2SMI builds around the task of molecule description generation, which enables IMG2SMI to outperform OSRA-based systems by 163% in molecule similarity prediction as measured by the molecular MACCS Fingerprint Tanimoto Similarity. Additionally, to facilitate further research on this task, we release a new molecule prediction dataset. including 81 million molecules for molecule description generation
COVID-19 Vaccines: Characterizing Misinformation Campaigns and Vaccine Hesitancy on Twitter
Jun 15, 2021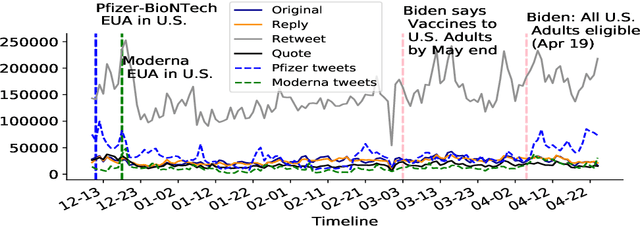
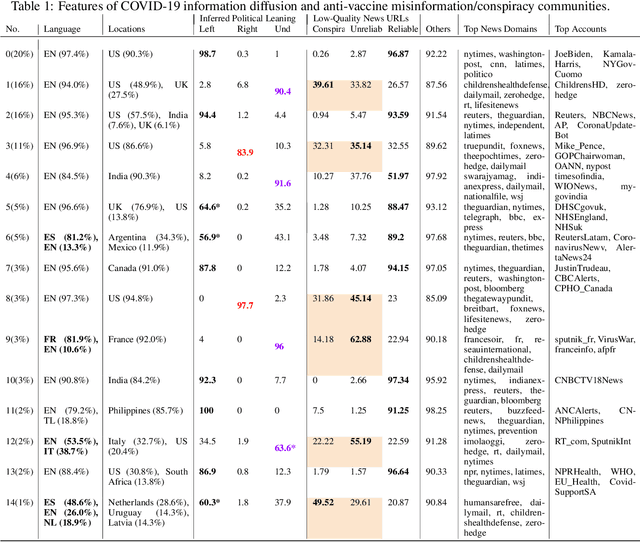
Vaccine hesitancy and misinformation on social media has increased concerns about COVID-19 vaccine uptake required to achieve herd immunity and overcome the pandemic. However anti-science and political misinformation and conspiracies have been rampant throughout the pandemic. For COVID-19 vaccines, we investigate misinformation and conspiracy campaigns and their characteristic behaviours. We identify whether coordinated efforts are used to promote misinformation in vaccine related discussions, and find accounts coordinately promoting a `Great Reset' conspiracy group promoting vaccine related misinformation and strong anti-vaccine and anti-social messages such as boycott vaccine passports, no lock-downs and masks. We characterize other misinformation communities from the information diffusion structure, and study the large anti-vaccine misinformation community and smaller anti-vaccine communities, including a far-right anti-vaccine conspiracy group. In comparison with the mainstream and health news, left-leaning group, which are more pro-vaccine, the right-leaning group is influenced more by the anti-vaccine and far-right misinformation/conspiracy communities. The misinformation communities are more vocal either specific to the vaccine discussion or political discussion, and we find other differences in the characteristic behaviours of different communities. Lastly, we investigate misinformation narratives and tactics of information distortion that can increase vaccine hesitancy, using topic modeling and comparison with reported vaccine side-effects (VAERS) finding rarer side-effects are more frequently discussed on social media.
Monte Carlo Information Geometry: The dually flat case
Mar 20, 2018
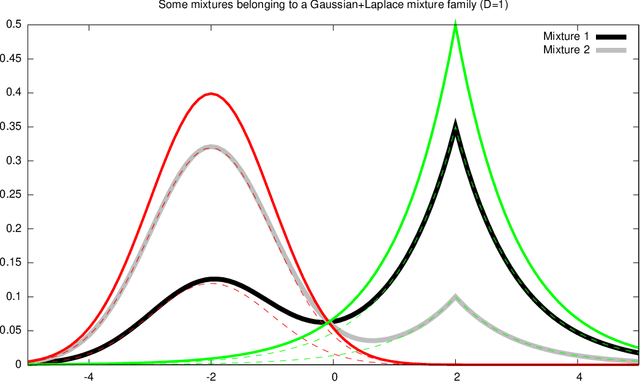
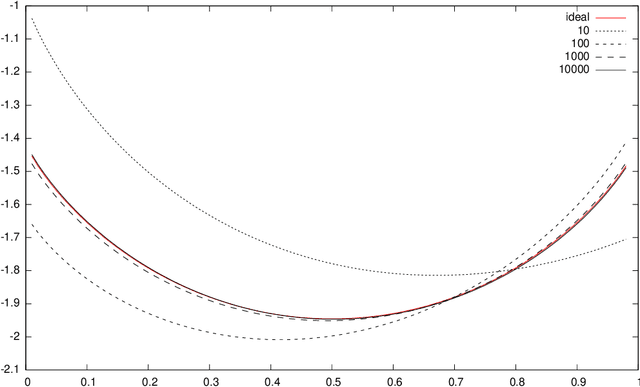
Exponential families and mixture families are parametric probability models that can be geometrically studied as smooth statistical manifolds with respect to any statistical divergence like the Kullback-Leibler (KL) divergence or the Hellinger divergence. When equipping a statistical manifold with the KL divergence, the induced manifold structure is dually flat, and the KL divergence between distributions amounts to an equivalent Bregman divergence on their corresponding parameters. In practice, the corresponding Bregman generators of mixture/exponential families require to perform definite integral calculus that can either be too time-consuming (for exponentially large discrete support case) or even do not admit closed-form formula (for continuous support case). In these cases, the dually flat construction remains theoretical and cannot be used by information-geometric algorithms. To bypass this problem, we consider performing stochastic Monte Carlo (MC) estimation of those integral-based mixture/exponential family Bregman generators. We show that, under natural assumptions, these MC generators are almost surely Bregman generators. We define a series of dually flat information geometries, termed Monte Carlo Information Geometries, that increasingly-finely approximate the untractable geometry. The advantage of this MCIG is that it allows a practical use of the Bregman algorithmic toolbox on a wide range of probability distribution families. We demonstrate our approach with a clustering task on a mixture family manifold.
KO codes: Inventing Nonlinear Encoding and Decoding for Reliable Wireless Communication via Deep-learning
Aug 29, 2021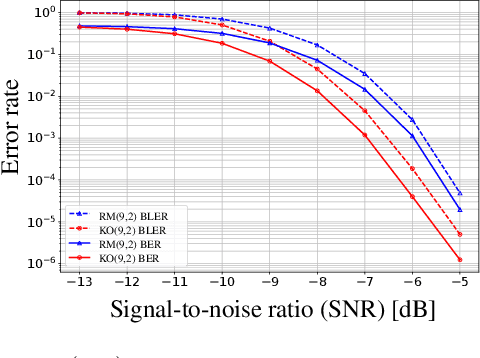
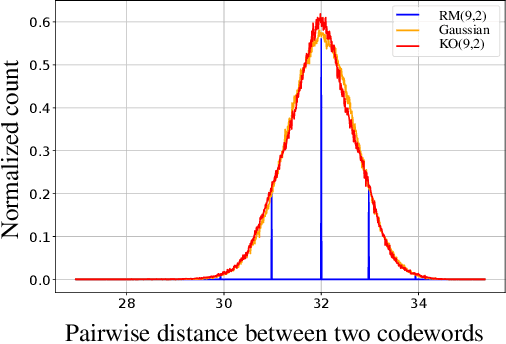
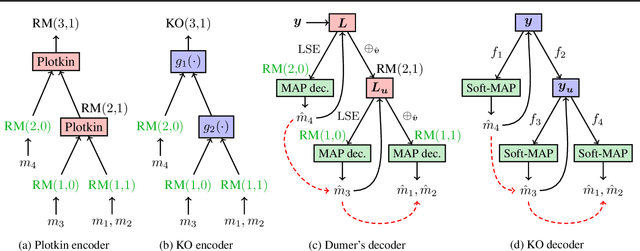
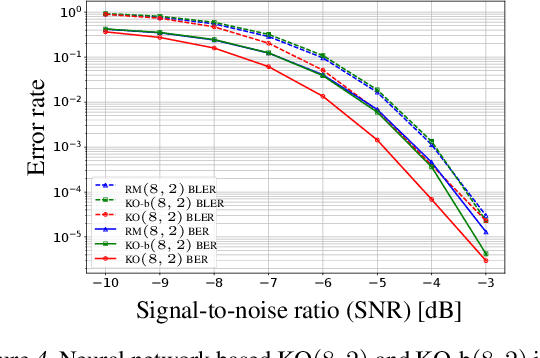
Landmark codes underpin reliable physical layer communication, e.g., Reed-Muller, BCH, Convolution, Turbo, LDPC and Polar codes: each is a linear code and represents a mathematical breakthrough. The impact on humanity is huge: each of these codes has been used in global wireless communication standards (satellite, WiFi, cellular). Reliability of communication over the classical additive white Gaussian noise (AWGN) channel enables benchmarking and ranking of the different codes. In this paper, we construct KO codes, a computationaly efficient family of deep-learning driven (encoder, decoder) pairs that outperform the state-of-the-art reliability performance on the standardized AWGN channel. KO codes beat state-of-the-art Reed-Muller and Polar codes, under the low-complexity successive cancellation decoding, in the challenging short-to-medium block length regime on the AWGN channel. We show that the gains of KO codes are primarily due to the nonlinear mapping of information bits directly to transmit real symbols (bypassing modulation) and yet possess an efficient, high performance decoder. The key technical innovation that renders this possible is design of a novel family of neural architectures inspired by the computation tree of the {\bf K}ronecker {\bf O}peration (KO) central to Reed-Muller and Polar codes. These architectures pave way for the discovery of a much richer class of hitherto unexplored nonlinear algebraic structures. The code is available at \href{https://github.com/deepcomm/KOcodes}{https://github.com/deepcomm/KOcodes}
Dual-Modality Vehicle Anomaly Detection via Bilateral Trajectory Tracing
Jun 09, 2021
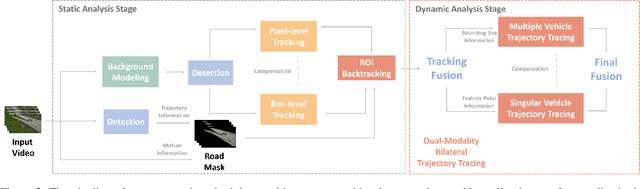
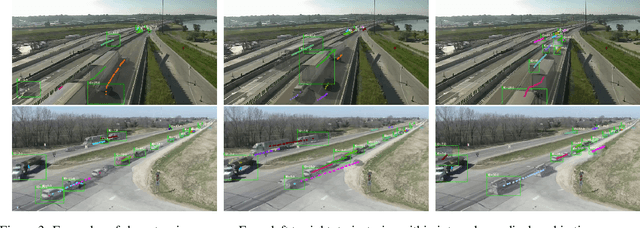
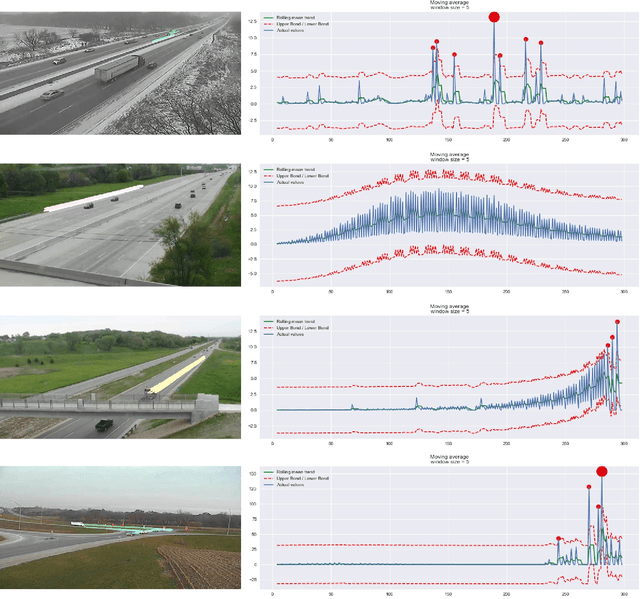
Traffic anomaly detection has played a crucial role in Intelligent Transportation System (ITS). The main challenges of this task lie in the highly diversified anomaly scenes and variational lighting conditions. Although much work has managed to identify the anomaly in homogenous weather and scene, few resolved to cope with complex ones. In this paper, we proposed a dual-modality modularized methodology for the robust detection of abnormal vehicles. We introduced an integrated anomaly detection framework comprising the following modules: background modeling, vehicle tracking with detection, mask construction, Region of Interest (ROI) backtracking, and dual-modality tracing. Concretely, we employed background modeling to filter the motion information and left the static information for later vehicle detection. For the vehicle detection and tracking module, we adopted YOLOv5 and multi-scale tracking to localize the anomalies. Besides, we utilized the frame difference and tracking results to identify the road and obtain the mask. In addition, we introduced multiple similarity estimation metrics to refine the anomaly period via backtracking. Finally, we proposed a dual-modality bilateral tracing module to refine the time further. The experiments conducted on the Track 4 testset of the NVIDIA 2021 AI City Challenge yielded a result of 0.9302 F1-Score and 3.4039 root mean square error (RMSE), indicating the effectiveness of our framework.
Monotonicity Marking from Universal Dependency Trees
Apr 17, 2021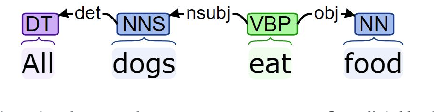
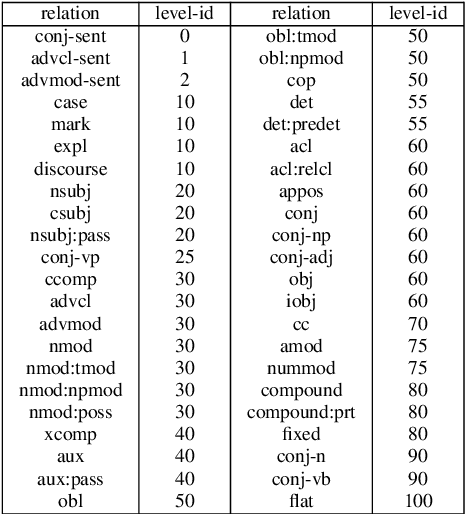
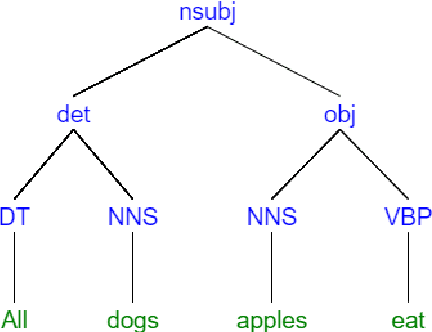

Dependency parsing is a tool widely used in the field of Natural language processing and computational linguistics. However, there is hardly any work that connects dependency parsing to monotonicity, which is an essential part of logic and linguistic semantics. In this paper, we present a system that automatically annotates monotonicity information based on Universal Dependency parse trees. Our system utilizes surface-level monotonicity facts about quantifiers, lexical items, and token-level polarity information. We compared our system's performance with existing systems in the literature, including NatLog and ccg2mono, on a small evaluation dataset. Results show that our system outperforms NatLog and ccg2mono.
Semiparametric Latent Topic Modeling on Consumer-Generated Corpora
Jul 13, 2021

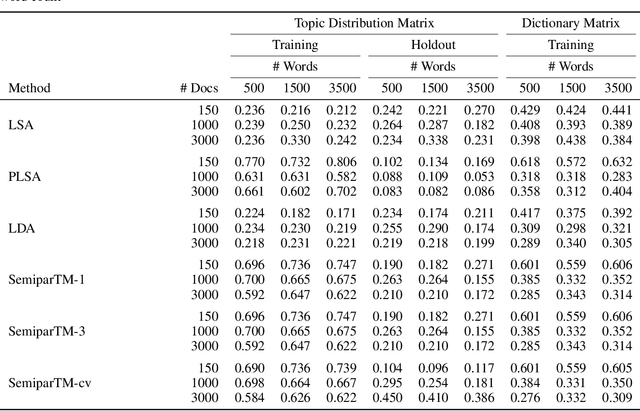
Legacy procedures for topic modelling have generally suffered problems of overfitting and a weakness towards reconstructing sparse topic structures. With motivation from a consumer-generated corpora, this paper proposes semiparametric topic model, a two-step approach utilizing nonnegative matrix factorization and semiparametric regression in topic modeling. The model enables the reconstruction of sparse topic structures in the corpus and provides a generative model for predicting topics in new documents entering the corpus. Assuming the presence of auxiliary information related to the topics, this approach exhibits better performance in discovering underlying topic structures in cases where the corpora are small and limited in vocabulary. In an actual consumer feedback corpus, the model also demonstrably provides interpretable and useful topic definitions comparable with those produced by other methods.
Single-Read Reconstruction for DNA Data Storage Using Transformers
Sep 12, 2021

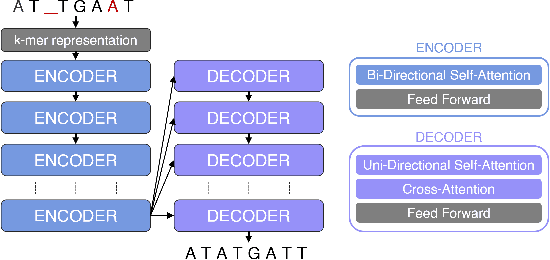
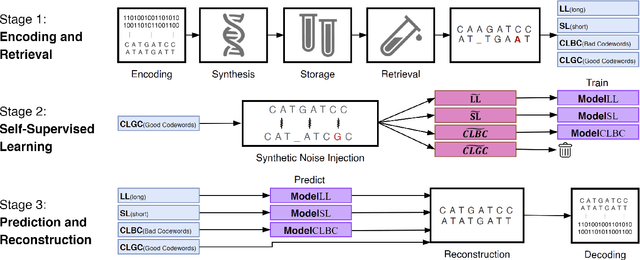
As the global need for large-scale data storage is rising exponentially, existing storage technologies are approaching their theoretical and functional limits in terms of density and energy consumption, making DNA based storage a potential solution for the future of data storage. Several studies introduced DNA based storage systems with high information density (petabytes/gram). However, DNA synthesis and sequencing technologies yield erroneous outputs. Algorithmic approaches for correcting these errors depend on reading multiple copies of each sequence and result in excessive reading costs. The unprecedented success of Transformers as a deep learning architecture for language modeling has led to its repurposing for solving a variety of tasks across various domains. In this work, we propose a novel approach for single-read reconstruction using an encoder-decoder Transformer architecture for DNA based data storage. We address the error correction process as a self-supervised sequence-to-sequence task and use synthetic noise injection to train the model using only the decoded reads. Our approach exploits the inherent redundancy of each decoded file to learn its underlying structure. To demonstrate our proposed approach, we encode text, image and code-script files to DNA, produce errors with high-fidelity error simulator, and reconstruct the original files from the noisy reads. Our model achieves lower error rates when reconstructing the original data from a single read of each DNA strand compared to state-of-the-art algorithms using 2-3 copies. This is the first demonstration of using deep learning models for single-read reconstruction in DNA based storage which allows for the reduction of the overall cost of the process. We show that this approach is applicable for various domains and can be generalized to new domains as well.