 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Anatomical-Guided Attention Enhances Unsupervised PET Image Denoising Performance
Sep 08, 2021
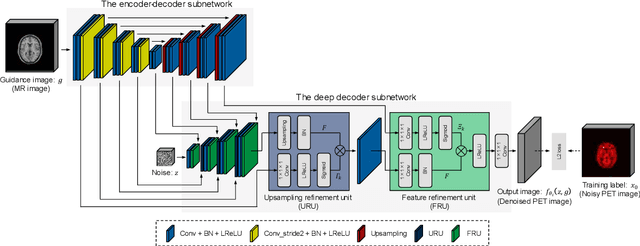
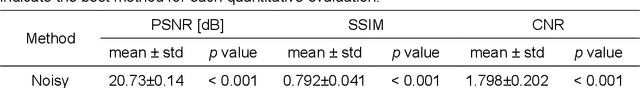
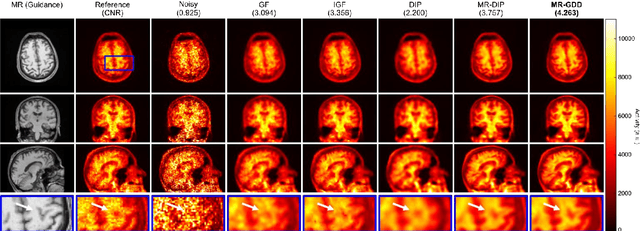
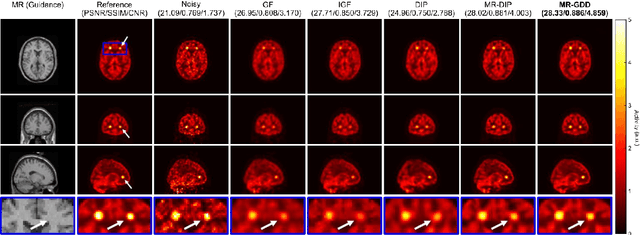
Although supervised convolutional neural networks (CNNs) often outperform conventional alternatives for denoising positron emission tomography (PET) images, they require many low- and high-quality reference PET image pairs. Herein, we propose an unsupervised 3D PET image denoising method based on an anatomical information-guided attention mechanism. The proposed magnetic resonance-guided deep decoder (MR-GDD) utilizes the spatial details and semantic features of MR-guidance image more effectively by introducing encoder-decoder and deep decoder subnetworks. Moreover, the specific shapes and patterns of the guidance image do not affect the denoised PET image, because the guidance image is input to the network through an attention gate. In a Monte Carlo simulation of [$^{18}$F]fluoro-2-deoxy-D-glucose (FDG), the proposed method achieved the highest peak signal-to-noise ratio and structural similarity (27.92 $\pm$ 0.44 dB/0.886 $\pm$ 0.007), as compared with Gaussian filtering (26.68 $\pm$ 0.10 dB/0.807 $\pm$ 0.004), image guided filtering (27.40 $\pm$ 0.11 dB/0.849 $\pm$ 0.003), deep image prior (DIP) (24.22 $\pm$ 0.43 dB/0.737 $\pm$ 0.017), and MR-DIP (27.65 $\pm$ 0.42 dB/0.879 $\pm$ 0.007). Furthermore, we experimentally visualized the behavior of the optimization process, which is often unknown in unsupervised CNN-based restoration problems. For preclinical (using [$^{18}$F]FDG and [$^{11}$C]raclopride) and clinical (using [$^{18}$F]florbetapir) studies, the proposed method demonstrates state-of-the-art denoising performance while retaining spatial resolution and quantitative accuracy, despite using a common network architecture for various noisy PET images with 1/10th of the full counts. These results suggest that the proposed MR-GDD can reduce PET scan times and PET tracer doses considerably without impacting patients.
* 30 pages, 12 figures
PP-Rec: News Recommendation with Personalized User Interest and Time-aware News Popularity
Jun 10, 2021
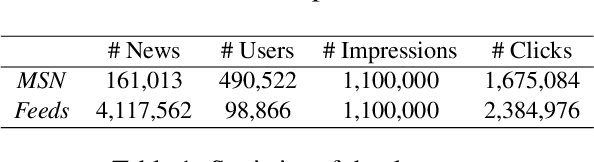
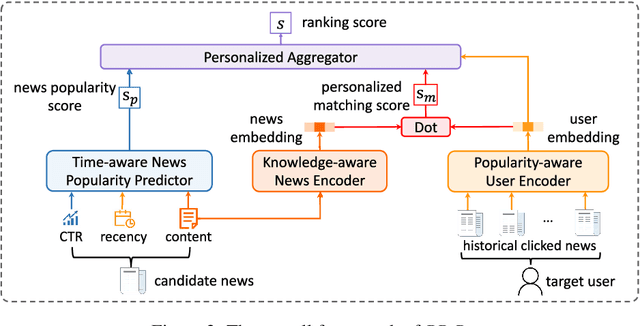
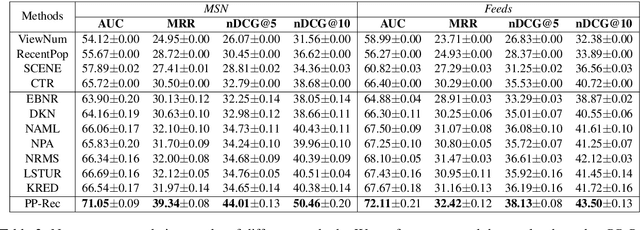
Personalized news recommendation methods are widely used in online news services. These methods usually recommend news based on the matching between news content and user interest inferred from historical behaviors. However, these methods usually have difficulties in making accurate recommendations to cold-start users, and tend to recommend similar news with those users have read. In general, popular news usually contain important information and can attract users with different interests. Besides, they are usually diverse in content and topic. Thus, in this paper we propose to incorporate news popularity information to alleviate the cold-start and diversity problems for personalized news recommendation. In our method, the ranking score for recommending a candidate news to a target user is the combination of a personalized matching score and a news popularity score. The former is used to capture the personalized user interest in news. The latter is used to measure time-aware popularity of candidate news, which is predicted based on news content, recency, and real-time CTR using a unified framework. Besides, we propose a popularity-aware user encoder to eliminate the popularity bias in user behaviors for accurate interest modeling. Experiments on two real-world datasets show our method can effectively improve the accuracy and diversity for news recommendation.
Dual-Tuning: Joint Prototype Transfer and Structure Regularization for Compatible Feature Learning
Aug 06, 2021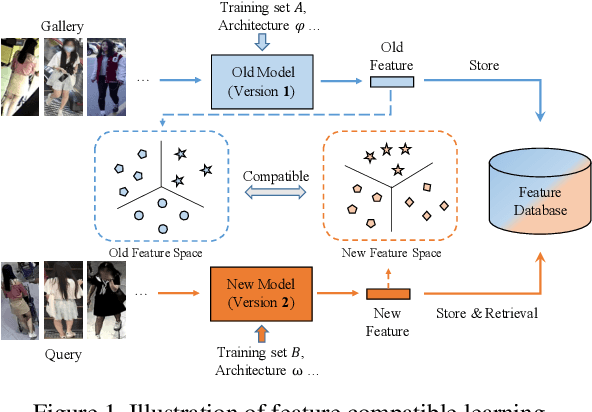
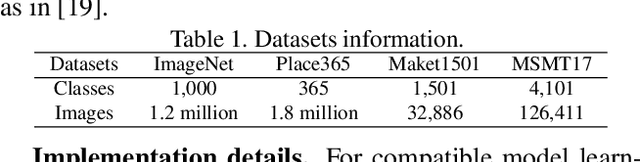
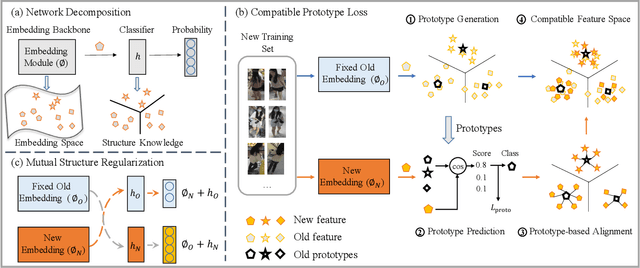
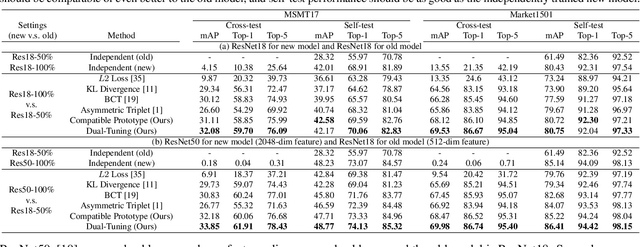
Visual retrieval system faces frequent model update and deployment. It is a heavy workload to re-extract features of the whole database every time.Feature compatibility enables the learned new visual features to be directly compared with the old features stored in the database. In this way, when updating the deployed model, we can bypass the inflexible and time-consuming feature re-extraction process. However, the old feature space that needs to be compatible is not ideal and faces the distribution discrepancy problem with the new space caused by different supervision losses. In this work, we propose a global optimization Dual-Tuning method to obtain feature compatibility against different networks and losses. A feature-level prototype loss is proposed to explicitly align two types of embedding features, by transferring global prototype information. Furthermore, we design a component-level mutual structural regularization to implicitly optimize the feature intrinsic structure. Experimental results on million-scale datasets demonstrate that our Dual-Tuning is able to obtain feature compatibility without sacrificing performance. (Our code will be avaliable at https://github.com/yanbai1993/Dual-Tuning)
Order Effects in Bayesian Updates
May 16, 2021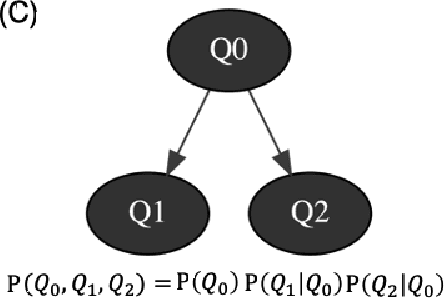

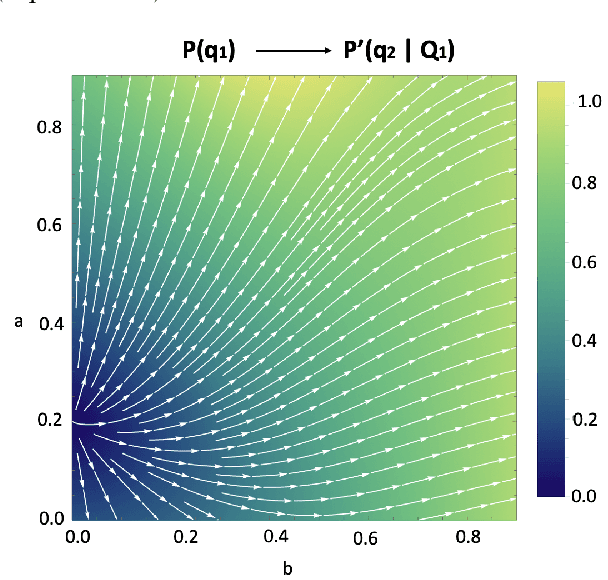
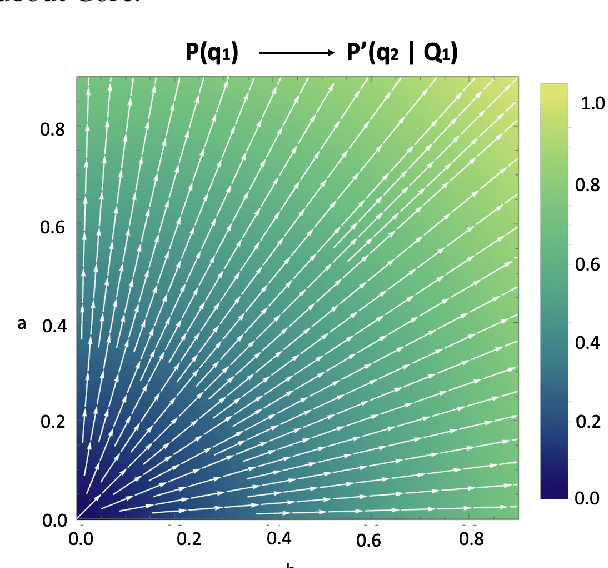
Order effects occur when judgments about a hypothesis's probability given a sequence of information do not equal the probability of the same hypothesis when the information is reversed. Different experiments have been performed in the literature that supports evidence of order effects. We proposed a Bayesian update model for order effects where each question can be thought of as a mini-experiment where the respondents reflect on their beliefs. We showed that order effects appear, and they have a simple cognitive explanation: the respondent's prior belief that two questions are correlated. The proposed Bayesian model allows us to make several predictions: (1) we found certain conditions on the priors that limit the existence of order effects; (2) we show that, for our model, the QQ equality is not necessarily satisfied (due to symmetry assumptions); and (3) the proposed Bayesian model has the advantage of possessing fewer parameters than its quantum counterpart.
Designing AI-based Conversational Agent for Diabetes Care in a Multilingual Context
May 20, 2021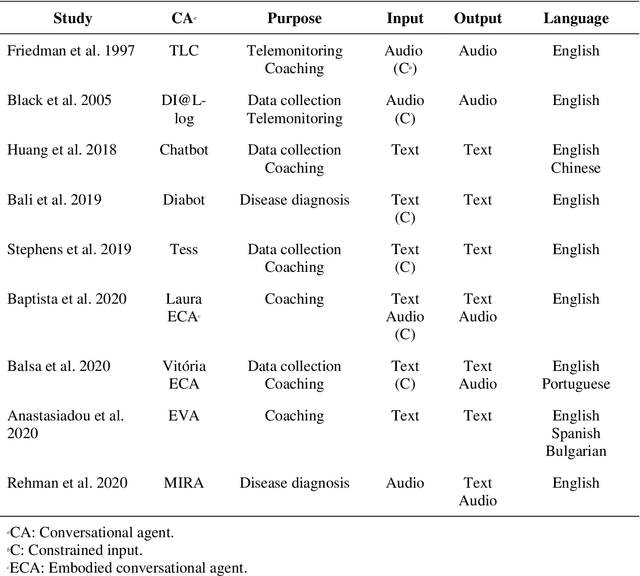
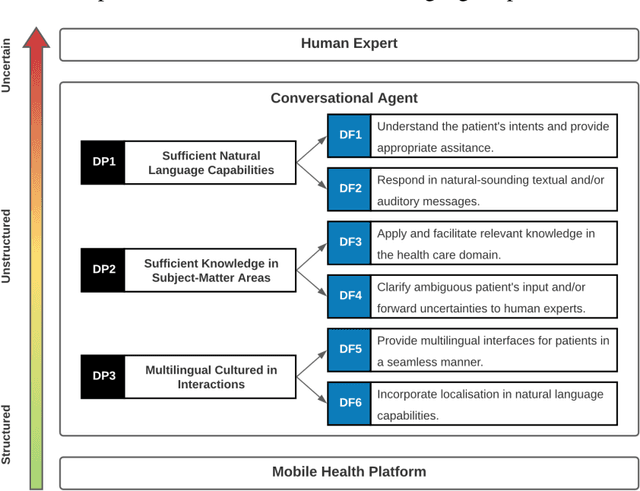
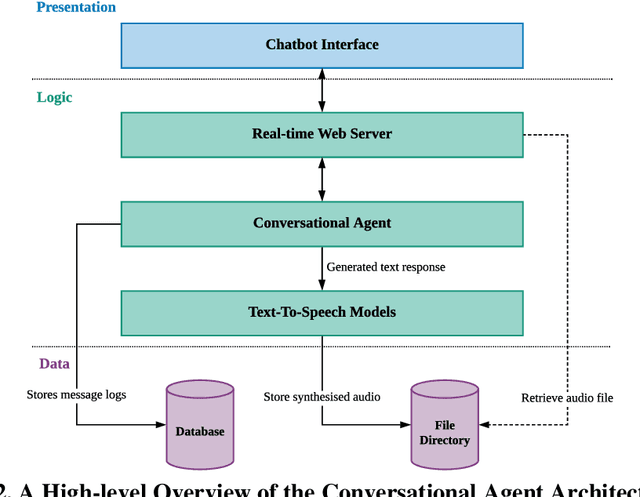
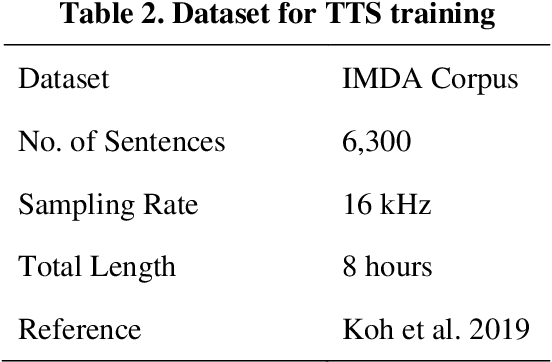
Conversational agents (CAs) represent an emerging research field in health information systems, where there are great potentials in empowering patients with timely information and natural language interfaces. Nevertheless, there have been limited attempts in establishing prescriptive knowledge on designing CAs in the healthcare domain in general, and diabetes care specifically. In this paper, we conducted a Design Science Research project and proposed three design principles for designing health-related CAs that embark on artificial intelligence (AI) to address the limitations of existing solutions. Further, we instantiated the proposed design and developed AMANDA - an AI-based multilingual CA in diabetes care with state-of-the-art technologies for natural-sounding localised accent. We employed mean opinion scores and system usability scale to evaluate AMANDA's speech quality and usability, respectively. This paper provides practitioners with a blueprint for designing CAs in diabetes care with concrete design guidelines that can be extended into other healthcare domains.
Modelling and Reasoning Techniques for Context Aware Computing in Intelligent Transportation System
Jul 29, 2021
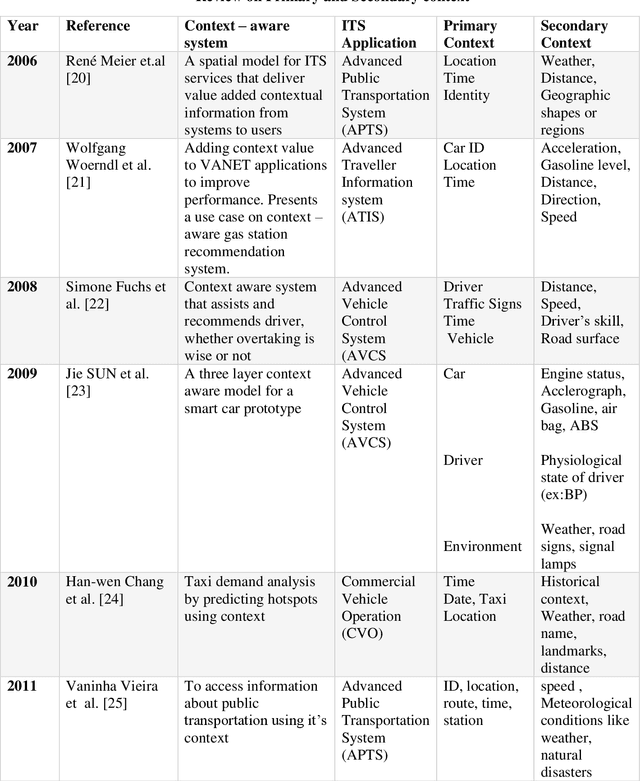
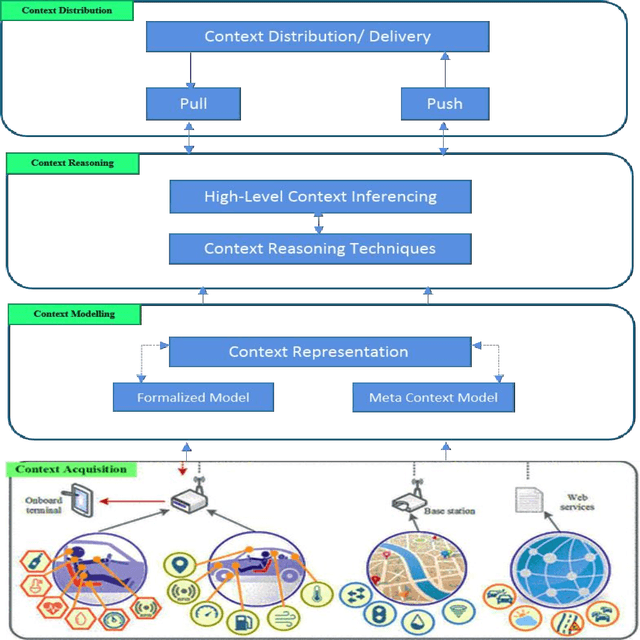
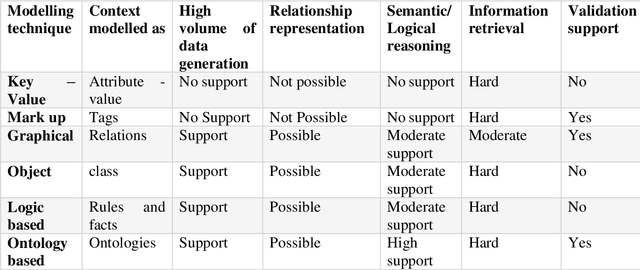
The emergence of Internet of Things technology and recent advancement in sensor networks enabled transportation systems to a new dimension called Intelligent Transportation System. Due to increased usage of vehicles and communication among entities in road traffic scenarios, the amount of raw data generation in Intelligent Transportation System is huge. This raw data are to be processed to infer contextual information and provide new services related to different modes of road transport such as traffic signal management, accident prediction, object detection etc. To understand the importance of context, this article aims to study context awareness in the Intelligent Transportation System. We present a review on prominent applications developed in the literature concerning context awareness in the intelligent transportation system. The objective of this research paper is to highlight context and its features in ITS and to address the applicability of modelling techniques and reasoning approaches in Intelligent Transportation System. Also to shed light on impact of Internet of Things and machine learning in Intelligent Transportation System development.
Learning from Partially Overlapping Labels: Image Segmentation under Annotation Shift
Jul 13, 2021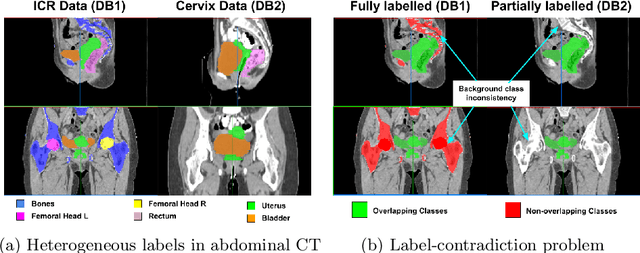
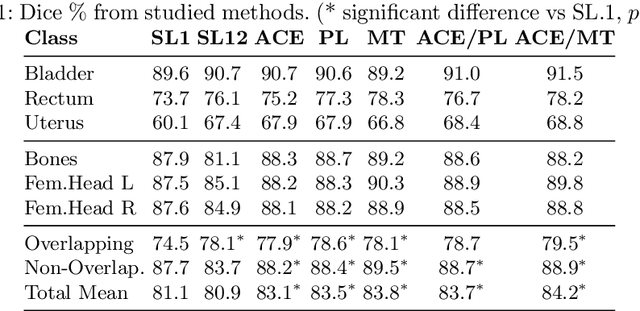
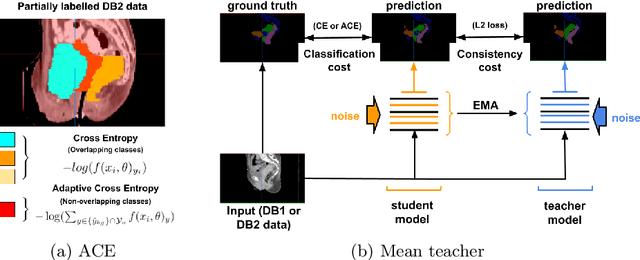
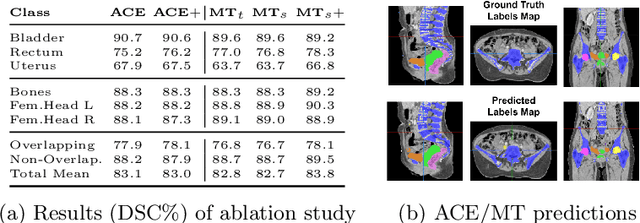
Scarcity of high quality annotated images remains a limiting factor for training accurate image segmentation models. While more and more annotated datasets become publicly available, the number of samples in each individual database is often small. Combining different databases to create larger amounts of training data is appealing yet challenging due to the heterogeneity as a result of differences in data acquisition and annotation processes, often yielding incompatible or even conflicting information. In this paper, we investigate and propose several strategies for learning from partially overlapping labels in the context of abdominal organ segmentation. We find that combining a semi-supervised approach with an adaptive cross entropy loss can successfully exploit heterogeneously annotated data and substantially improve segmentation accuracy compared to baseline and alternative approaches.
Lymph Node Graph Neural Networks for Cancer Metastasis Prediction
Jun 03, 2021
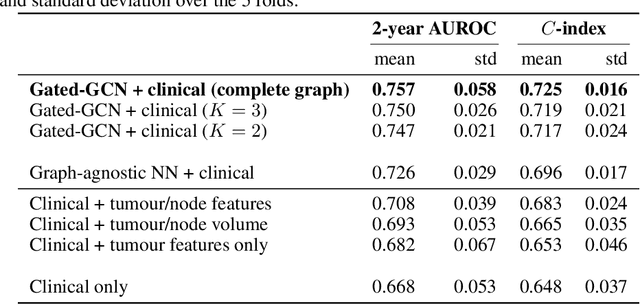
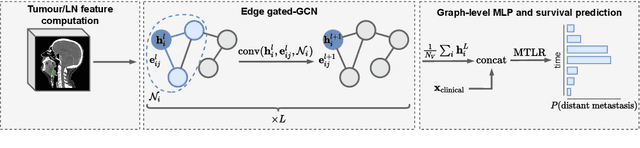

Predicting outcomes, such as survival or metastasis for individual cancer patients is a crucial component of precision oncology. Machine learning (ML) offers a promising way to exploit rich multi-modal data, including clinical information and imaging to learn predictors of disease trajectory and help inform clinical decision making. In this paper, we present a novel graph-based approach to incorporate imaging characteristics of existing cancer spread to local lymph nodes (LNs) as well as their connectivity patterns in a prognostic ML model. We trained an edge-gated Graph Convolutional Network (Gated-GCN) to accurately predict the risk of distant metastasis (DM) by propagating information across the LN graph with the aid of soft edge attention mechanism. In a cohort of 1570 head and neck cancer patients, the Gated-GCN achieves AUROC of 0.757 for 2-year DM classification and $C$-index of 0.725 for lifetime DM risk prediction, outperforming current prognostic factors as well as previous approaches based on aggregated LN features. We also explored the importance of graph structure and individual lymph nodes through ablation experiments and interpretability studies, highlighting the importance of considering individual LN characteristics as well as the relationships between regions of cancer spread.
Airplane Type Identification Based on Mask RCNN and Drone Images
Aug 29, 2021
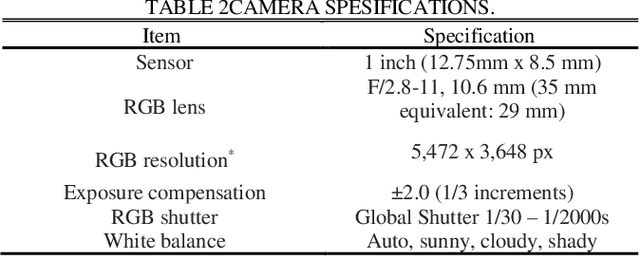
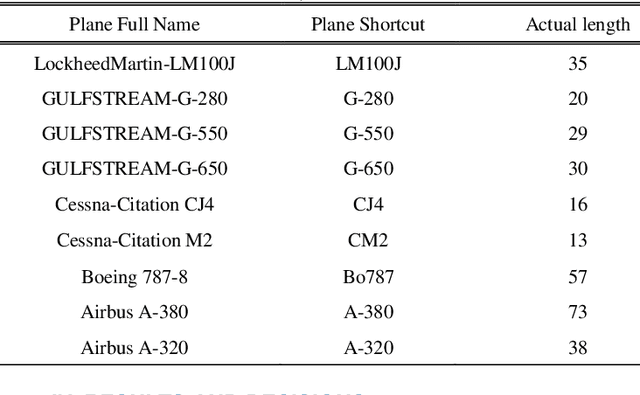
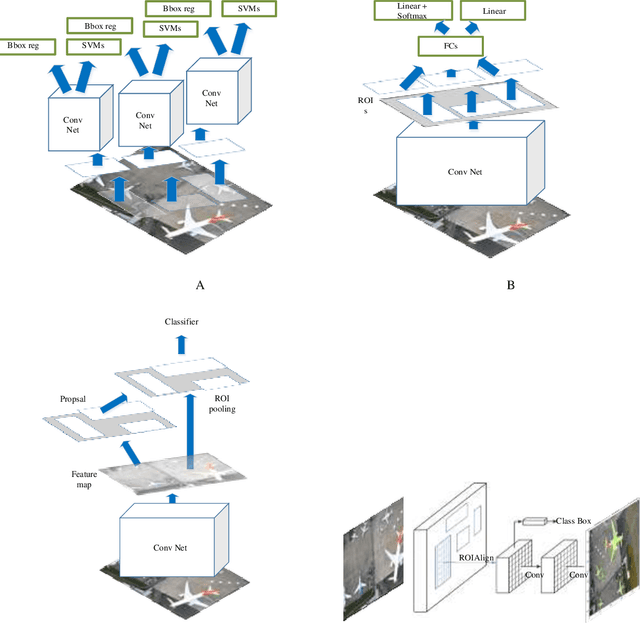
For dealing with traffic bottlenecks at airports, aircraft object detection is insufficient. Every airport generally has a variety of planes with various physical and technological requirements as well as diverse service requirements. Detecting the presence of new planes will not address all traffic congestion issues. Identifying the type of airplane, on the other hand, will entirely fix the problem because it will offer important information about the plane's technical specifications (i.e., the time it needs to be served and its appropriate place in the airport). Several studies have provided various contributions to address airport traffic jams; however, their ultimate goal was to determine the existence of airplane objects. This paper provides a practical approach to identify the type of airplane in airports depending on the results provided by the airplane detection process using mask region convolution neural network. The key feature employed to identify the type of airplane is the surface area calculated based on the results of airplane detection. The surface area is used to assess the estimated cabin length which is considered as an additional key feature for identifying the airplane type. The length of any detected plane may be calculated by measuring the distance between the detected plane's two furthest points. The suggested approach's performance is assessed using average accuracies and a confusion matrix. The findings show that this method is dependable. This method will greatly aid in the management of airport traffic congestion.
TCCT: Tightly-Coupled Convolutional Transformer on Time Series Forecasting
Aug 29, 2021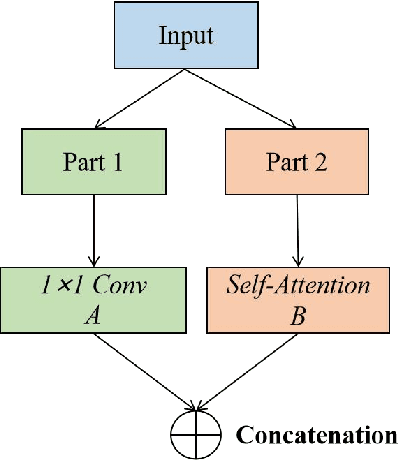
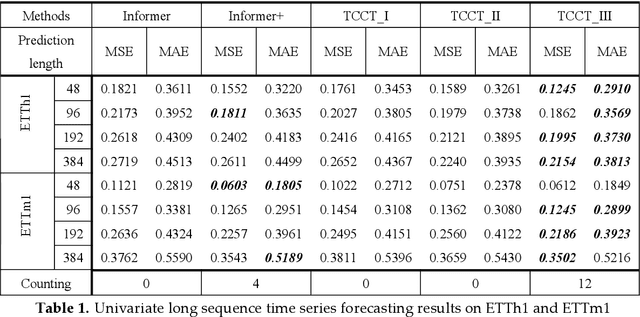
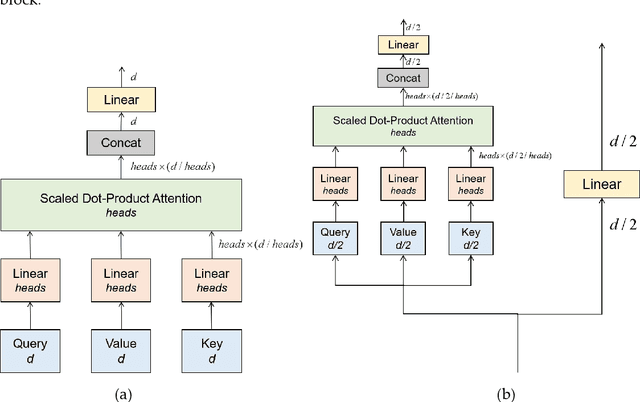
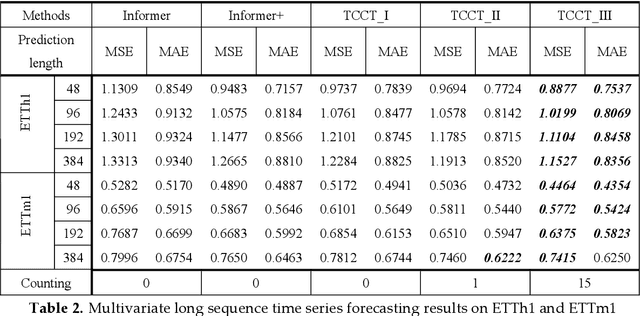
Time series forecasting is essential for a wide range of real-world applications. Recent studies have shown the superiority of Transformer in dealing with such problems, especially long sequence time series input(LSTI) and long sequence time series forecasting(LSTF) problems. To improve the efficiency and enhance the locality of Transformer, these studies combine Transformer with CNN in varying degrees. However, their combinations are loosely-coupled and do not make full use of CNN. To address this issue, we propose the concept of tightly-coupled convolutional Transformer(TCCT) and three TCCT architectures which apply transformed CNN architectures into Transformer: (1) CSPAttention: through fusing CSPNet with self-attention mechanism, the computation cost of self-attention mechanism is reduced by 30% and the memory usage is reduced by 50% while achieving equivalent or beyond prediction accuracy. (2) Dilated causal convolution: this method is to modify the distilling operation proposed by Informer through replacing canonical convolutional layers with dilated causal convolutional layers to gain exponentially receptive field growth. (3) Passthrough mechanism: the application of passthrough mechanism to stack of self-attention blocks helps Transformer-like models get more fine-grained information with negligible extra computation costs. Our experiments on real-world datasets show that our TCCT architectures could greatly improve the performance of existing state-of-art Transformer models on time series forecasting with much lower computation and memory costs, including canonical Transformer, LogTrans and Informer.