 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Improved Representation Learning for Session-based Recommendation
Jul 04, 2021
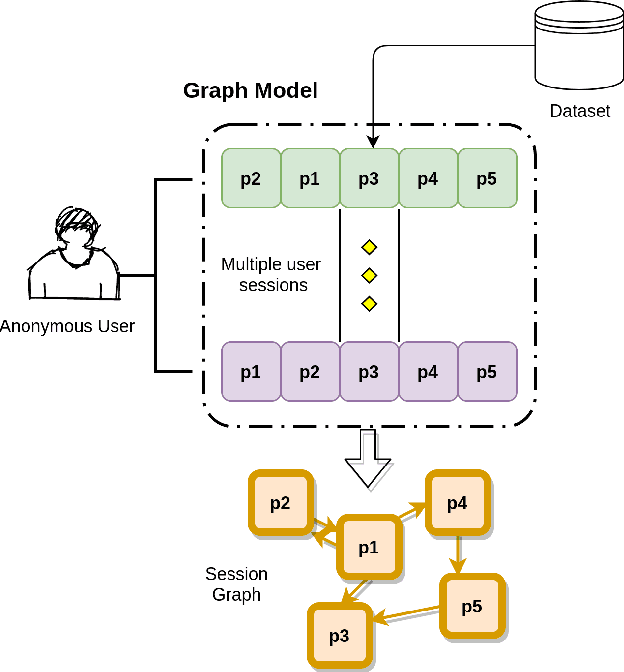

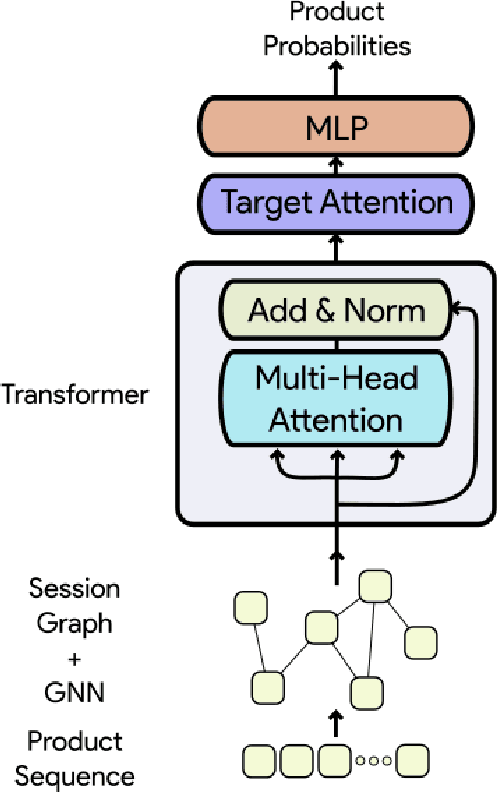
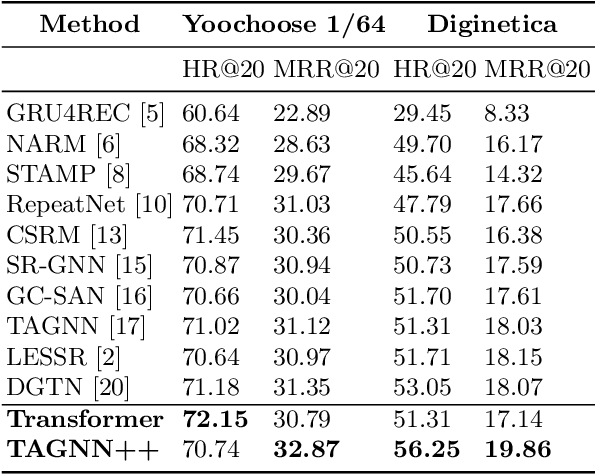
Session-based recommendation systems suggest relevant items to users by modeling user behavior and preferences using short-term anonymous sessions. Existing methods leverage Graph Neural Networks (GNNs) that propagate and aggregate information from neighboring nodes i.e., local message passing. Such graph-based architectures have representational limits, as a single sub-graph is susceptible to overfit the sequential dependencies instead of accounting for complex transitions between items in different sessions. We propose using a Transformer in combination with a target attentive GNN, which allows richer Representation Learning. Our experimental results and ablation show that our proposed method outperforms the existing methods on real-world benchmark datasets.
Designing AI-based Conversational Agent for Diabetes Care in a Multilingual Context
May 20, 2021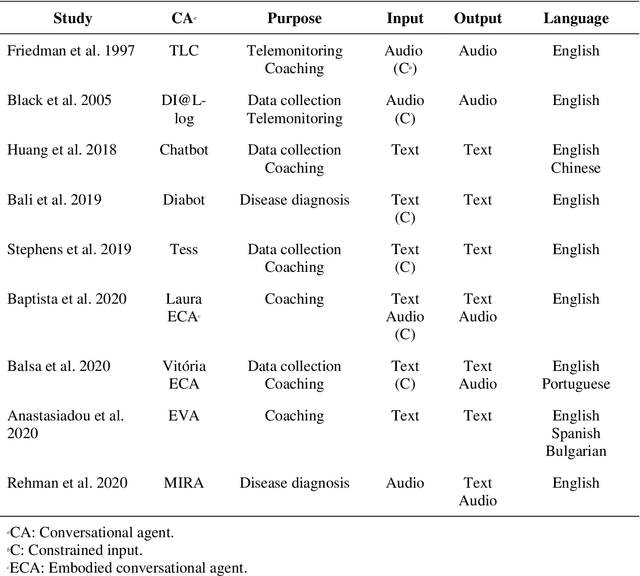
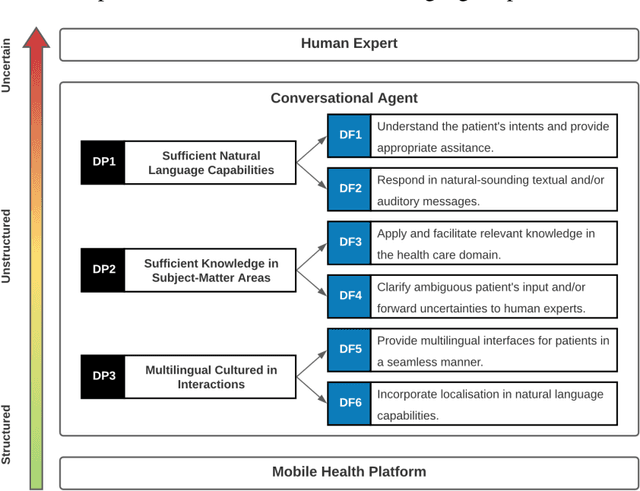
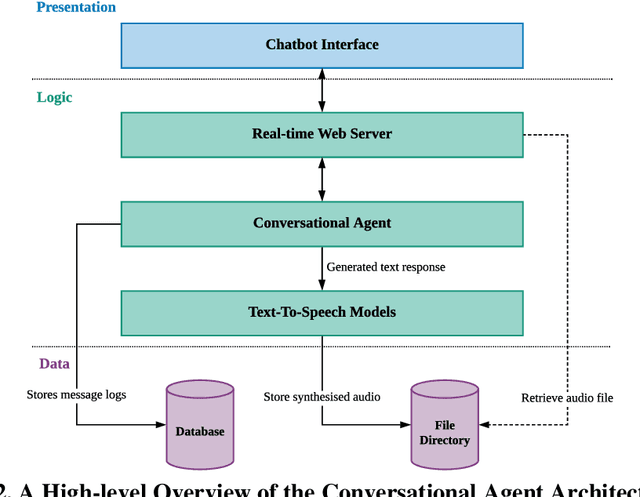
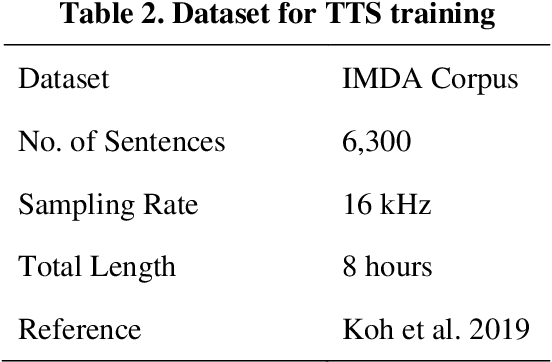
Conversational agents (CAs) represent an emerging research field in health information systems, where there are great potentials in empowering patients with timely information and natural language interfaces. Nevertheless, there have been limited attempts in establishing prescriptive knowledge on designing CAs in the healthcare domain in general, and diabetes care specifically. In this paper, we conducted a Design Science Research project and proposed three design principles for designing health-related CAs that embark on artificial intelligence (AI) to address the limitations of existing solutions. Further, we instantiated the proposed design and developed AMANDA - an AI-based multilingual CA in diabetes care with state-of-the-art technologies for natural-sounding localised accent. We employed mean opinion scores and system usability scale to evaluate AMANDA's speech quality and usability, respectively. This paper provides practitioners with a blueprint for designing CAs in diabetes care with concrete design guidelines that can be extended into other healthcare domains.
No reference image quality assessment metric based on regional mutual information among images
Jan 17, 2019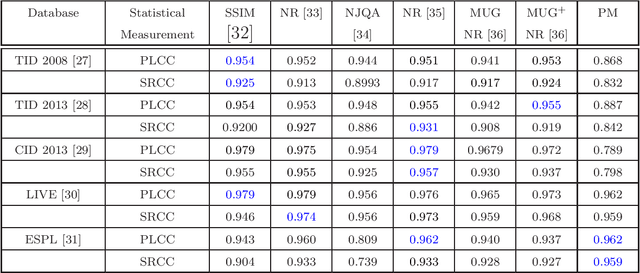
With the inclusion of camera in daily life, an automatic no reference image quality evaluation index is required for automatic classification of images. The present manuscripts proposes a new No Reference Regional Mutual Information based technique for evaluating the quality of an image. We use regional mutual information on subsets of the complete image. Proposed technique is tested on four benchmark natural image databases, and one benchmark synthetic database. A comparative analysis with classical and state-of-art methods indicate superiority of the present technique for high quality images and comparable for other images of the respective databases.
Full-Duplex Strategy for Video Object Segmentation
Aug 06, 2021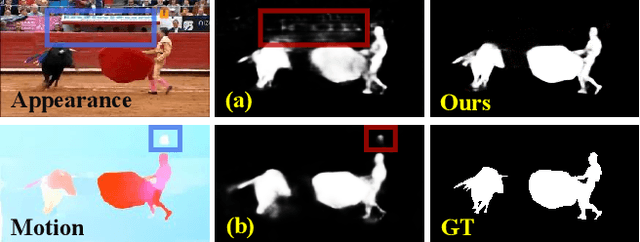

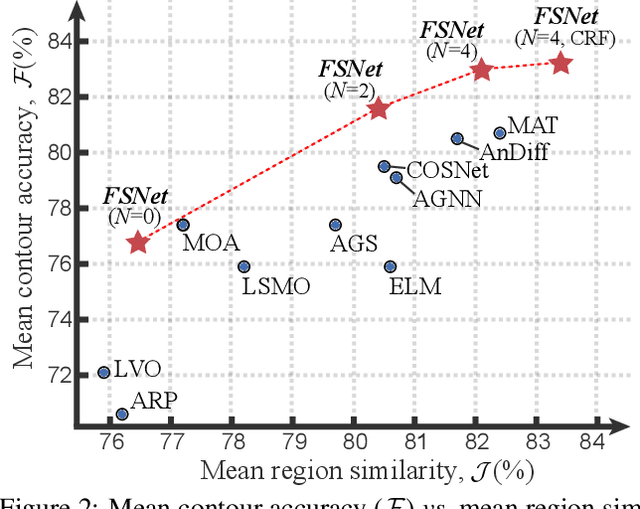
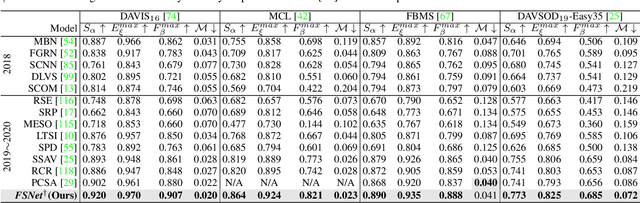
Appearance and motion are two important sources of information in video object segmentation (VOS). Previous methods mainly focus on using simplex solutions, lowering the upper bound of feature collaboration among and across these two cues. In this paper, we study a novel framework, termed the FSNet (Full-duplex Strategy Network), which designs a relational cross-attention module (RCAM) to achieve the bidirectional message propagation across embedding subspaces. Furthermore, the bidirectional purification module (BPM) is introduced to update the inconsistent features between the spatial-temporal embeddings, effectively improving the model robustness. By considering the mutual restraint within the full-duplex strategy, our FSNet performs the cross-modal feature-passing (i.e., transmission and receiving) simultaneously before the fusion and decoding stage, making it robust to various challenging scenarios (e.g., motion blur, occlusion) in VOS. Extensive experiments on five popular benchmarks (i.e., DAVIS$_{16}$, FBMS, MCL, SegTrack-V2, and DAVSOD$_{19}$) show that our FSNet outperforms other state-of-the-arts for both the VOS and video salient object detection tasks.
PP-Rec: News Recommendation with Personalized User Interest and Time-aware News Popularity
Jun 10, 2021
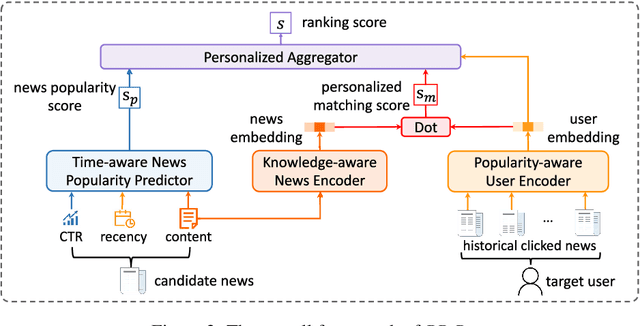
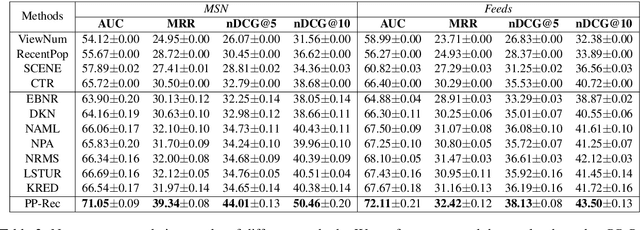
Personalized news recommendation methods are widely used in online news services. These methods usually recommend news based on the matching between news content and user interest inferred from historical behaviors. However, these methods usually have difficulties in making accurate recommendations to cold-start users, and tend to recommend similar news with those users have read. In general, popular news usually contain important information and can attract users with different interests. Besides, they are usually diverse in content and topic. Thus, in this paper we propose to incorporate news popularity information to alleviate the cold-start and diversity problems for personalized news recommendation. In our method, the ranking score for recommending a candidate news to a target user is the combination of a personalized matching score and a news popularity score. The former is used to capture the personalized user interest in news. The latter is used to measure time-aware popularity of candidate news, which is predicted based on news content, recency, and real-time CTR using a unified framework. Besides, we propose a popularity-aware user encoder to eliminate the popularity bias in user behaviors for accurate interest modeling. Experiments on two real-world datasets show our method can effectively improve the accuracy and diversity for news recommendation.
An Anatomy of Graph Neural Networks Going Deep via the Lens of Mutual Information: Exponential Decay vs. Full Preservation
Oct 10, 2019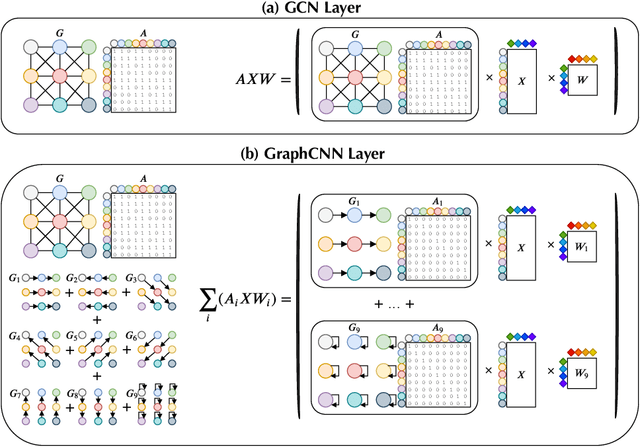

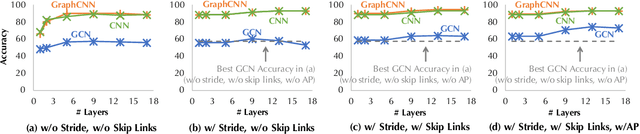
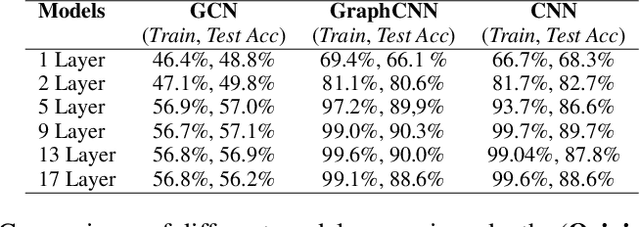
Graph Convolutional Network (GCN) has attracted intensive interests recently. One major limitation of GCN is that it often cannot benefit from using a deep architecture, while traditional CNN and an alternative Graph Neural Network architecture, namely GraphCNN, often achieve better quality with a deeper neural architecture. How can we explain this phenomenon? In this paper, we take the first step towards answering this question. We first conduct a systematic empirical study on the accuracy of GCN, GraphCNN, and ResNet-18 on 2D images and identified relative importance of different factors in architectural design. This inspired a novel theoretical analysis on the mutual information between the input and the output after l GCN and GraphCNN layers. We identified regimes in which GCN suffers exponentially fast information lose and show that GraphCNN requires a much weaker condition for similar behavior to happen.
Synth-by-Reg (SbR): Contrastive learning for synthesis-based registration of paired images
Jul 30, 2021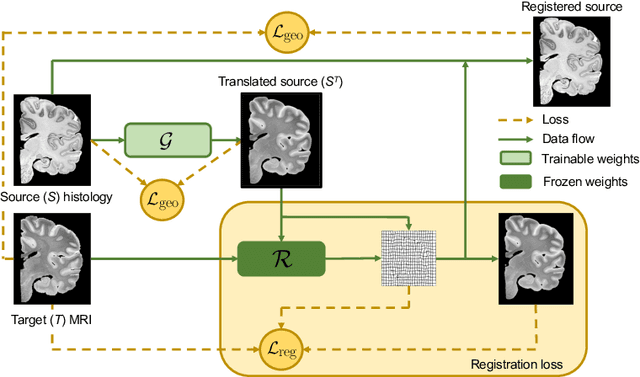
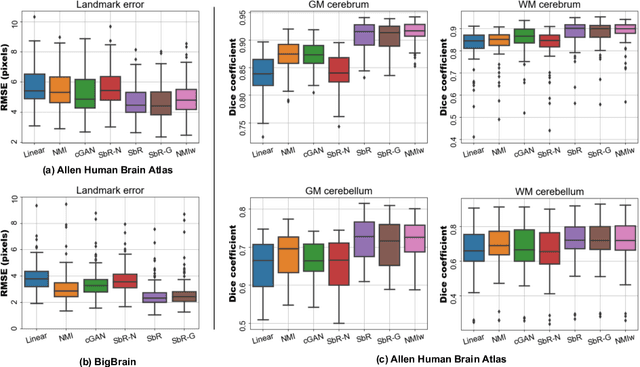
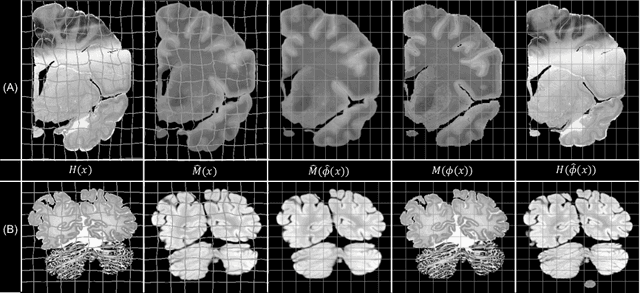
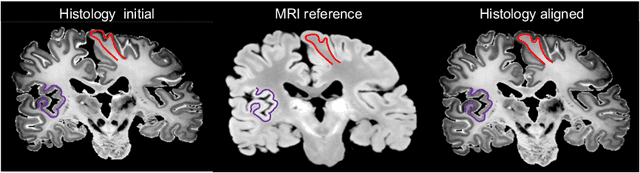
Nonlinear inter-modality registration is often challenging due to the lack of objective functions that are good proxies for alignment. Here we propose a synthesis-by-registration method to convert this problem into an easier intra-modality task. We introduce a registration loss for weakly supervised image translation between domains that does not require perfectly aligned training data. This loss capitalises on a registration U-Net with frozen weights, to drive a synthesis CNN towards the desired translation. We complement this loss with a structure preserving constraint based on contrastive learning, which prevents blurring and content shifts due to overfitting. We apply this method to the registration of histological sections to MRI slices, a key step in 3D histology reconstruction. Results on two different public datasets show improvements over registration based on mutual information (13% reduction in landmark error) and synthesis-based algorithms such as CycleGAN (11% reduction), and are comparable to a registration CNN with label supervision.
Trajectory Synthesis for Fisher Information Maximization
Sep 11, 2017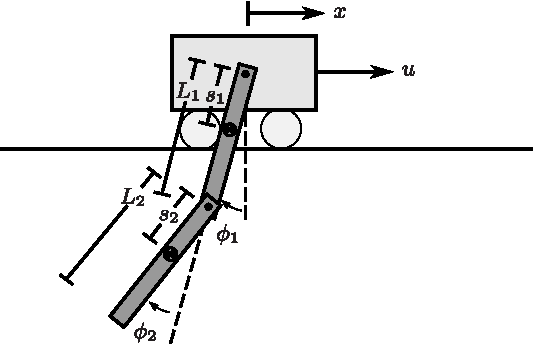
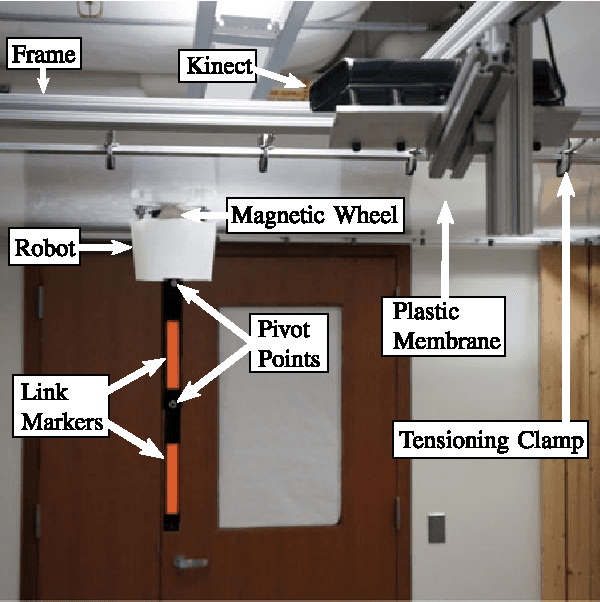

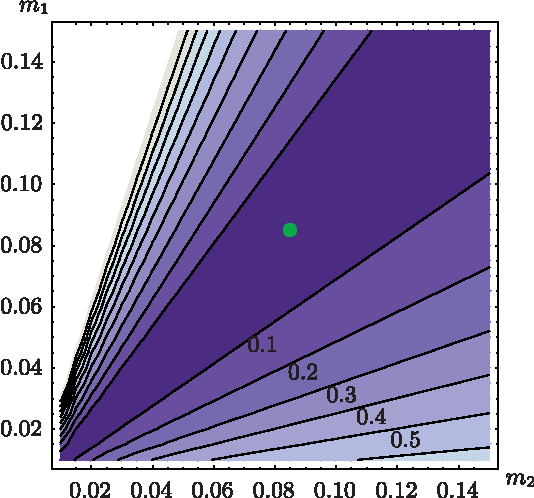
Estimation of model parameters in a dynamic system can be significantly improved with the choice of experimental trajectory. For general, nonlinear dynamic systems, finding globally "best" trajectories is typically not feasible; however, given an initial estimate of the model parameters and an initial trajectory, we present a continuous-time optimization method that produces a locally optimal trajectory for parameter estimation in the presence of measurement noise. The optimization algorithm is formulated to find system trajectories that improve a norm on the Fisher information matrix. A double-pendulum cart apparatus is used to numerically and experimentally validate this technique. In simulation, the optimized trajectory increases the minimum eigenvalue of the Fisher information matrix by three orders of magnitude compared to the initial trajectory. Experimental results show that this optimized trajectory translates to an order of magnitude improvement in the parameter estimate error in practice.
* 12 pages
IMG2SMI: Translating Molecular Structure Images to Simplified Molecular-input Line-entry System
Sep 03, 2021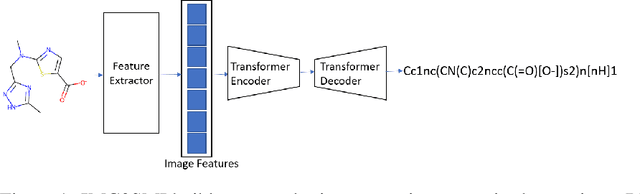
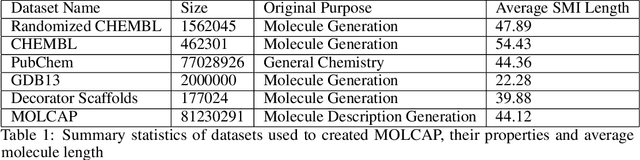

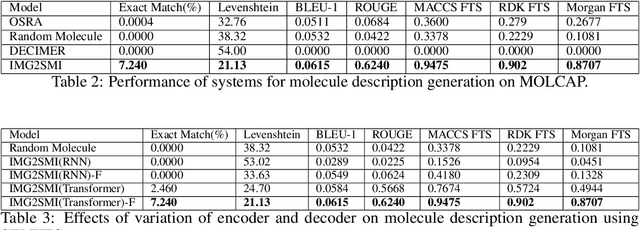
Like many scientific fields, new chemistry literature has grown at a staggering pace, with thousands of papers released every month. A large portion of chemistry literature focuses on new molecules and reactions between molecules. Most vital information is conveyed through 2-D images of molecules, representing the underlying molecules or reactions described. In order to ensure reproducible and machine-readable molecule representations, text-based molecule descriptors like SMILES and SELFIES were created. These text-based molecule representations provide molecule generation but are unfortunately rarely present in published literature. In the absence of molecule descriptors, the generation of molecule descriptors from the 2-D images present in the literature is necessary to understand chemistry literature at scale. Successful methods such as Optical Structure Recognition Application (OSRA), and ChemSchematicResolver are able to extract the locations of molecules structures in chemistry papers and infer molecular descriptions and reactions. While effective, existing systems expect chemists to correct outputs, making them unsuitable for unsupervised large-scale data mining. Leveraging the task formulation of image captioning introduced by DECIMER, we introduce IMG2SMI, a model which leverages Deep Residual Networks for image feature extraction and an encoder-decoder Transformer layers for molecule description generation. Unlike previous Neural Network-based systems, IMG2SMI builds around the task of molecule description generation, which enables IMG2SMI to outperform OSRA-based systems by 163% in molecule similarity prediction as measured by the molecular MACCS Fingerprint Tanimoto Similarity. Additionally, to facilitate further research on this task, we release a new molecule prediction dataset. including 81 million molecules for molecule description generation
External Human-Machine Interface on Delivery Robots: Expression of Navigation Intent of the Robot
Aug 06, 2021
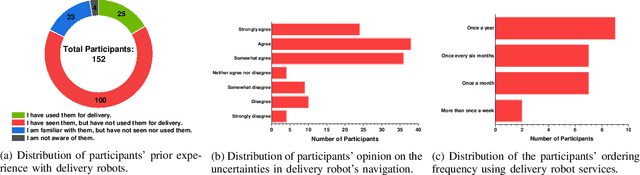

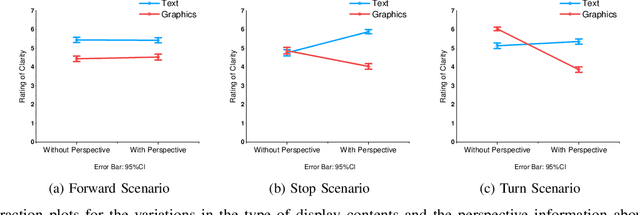
External Human-Machine Interfaces (eHMI) are widely used on robots and autonomous vehicles to convey the machine's intent to humans. Delivery robots are getting common, and they share the sidewalk along with the pedestrians. Current research has explored the design of eHMI and its effectiveness for social robots and autonomous vehicles, but the use of eHMIs on delivery robots still remains unexplored. There is a knowledge gap on the effective use of eHMIs on delivery robots for indicating the robot's navigational intent to the pedestrians. An online survey with 152 participants was conducted to investigate the comprehensibility of the display and light-based eHMIs that convey the delivery robot's navigational intent under common navigation scenarios. Results show that display is preferred over lights in conveying the intent. The preferred type of content to be displayed varies according to the scenarios. Additionally, light is preferred as an auxiliary eHMI to present redundant information. The findings of this study can contribute to the development of future designs of eHMI on delivery robots.