 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Towards Continual Entity Learning in Language Models for Conversational Agents
Jul 30, 2021
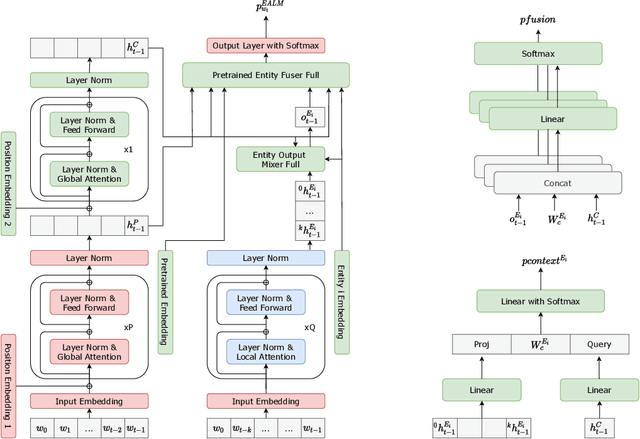
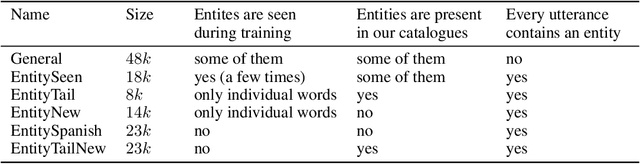

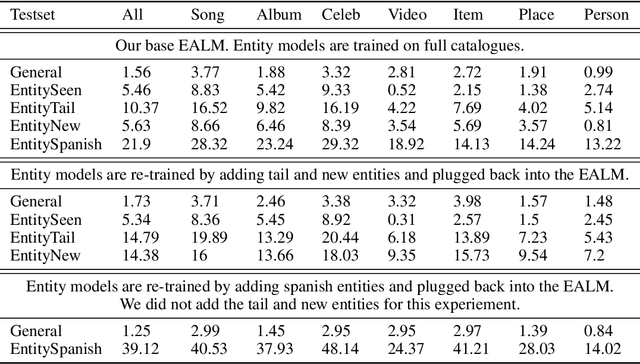
Neural language models (LM) trained on diverse corpora are known to work well on previously seen entities, however, updating these models with dynamically changing entities such as place names, song titles and shopping items requires re-training from scratch and collecting full sentences containing these entities. We aim to address this issue, by introducing entity-aware language models (EALM), where we integrate entity models trained on catalogues of entities into the pre-trained LMs. Our combined language model adaptively adds information from the entity models into the pre-trained LM depending on the sentence context. Our entity models can be updated independently of the pre-trained LM, enabling us to influence the distribution of entities output by the final LM, without any further training of the pre-trained LM. We show significant perplexity improvements on task-oriented dialogue datasets, especially on long-tailed utterances, with an ability to continually adapt to new entities (to an extent).
Predicting the Success of Domain Adaptation in Text Similarity
Jun 23, 2021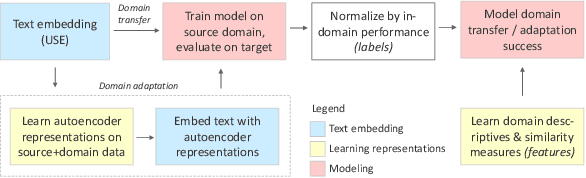
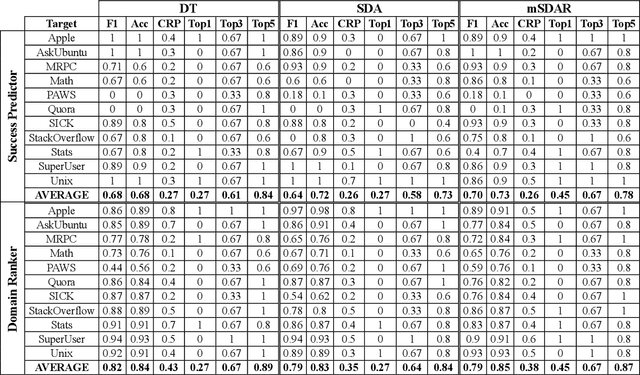
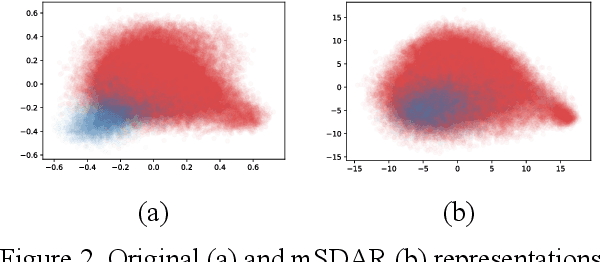
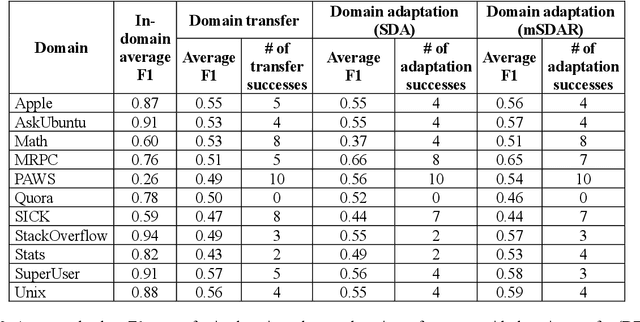
Transfer learning methods, and in particular domain adaptation, help exploit labeled data in one domain to improve the performance of a certain task in another domain. However, it is still not clear what factors affect the success of domain adaptation. This paper models adaptation success and selection of the most suitable source domains among several candidates in text similarity. We use descriptive domain information and cross-domain similarity metrics as predictive features. While mostly positive, the results also point to some domains where adaptation success was difficult to predict.
TransFER: Learning Relation-aware Facial Expression Representations with Transformers
Aug 25, 2021
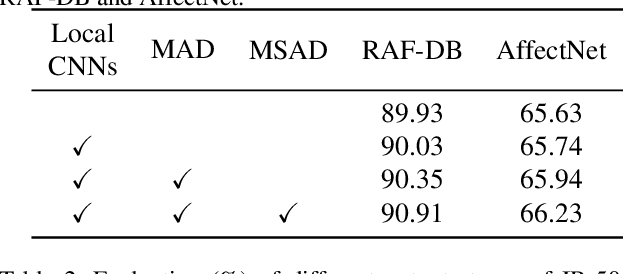
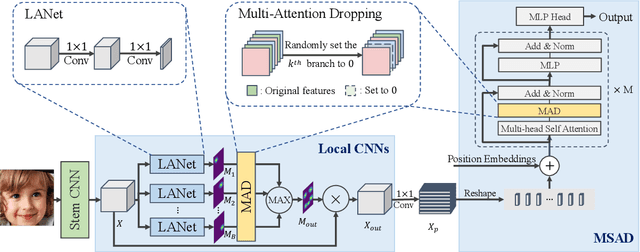

Facial expression recognition (FER) has received increasing interest in computer vision. We propose the TransFER model which can learn rich relation-aware local representations. It mainly consists of three components: Multi-Attention Dropping (MAD), ViT-FER, and Multi-head Self-Attention Dropping (MSAD). First, local patches play an important role in distinguishing various expressions, however, few existing works can locate discriminative and diverse local patches. This can cause serious problems when some patches are invisible due to pose variations or viewpoint changes. To address this issue, the MAD is proposed to randomly drop an attention map. Consequently, models are pushed to explore diverse local patches adaptively. Second, to build rich relations between different local patches, the Vision Transformers (ViT) are used in FER, called ViT-FER. Since the global scope is used to reinforce each local patch, a better representation is obtained to boost the FER performance. Thirdly, the multi-head self-attention allows ViT to jointly attend to features from different information subspaces at different positions. Given no explicit guidance, however, multiple self-attentions may extract similar relations. To address this, the MSAD is proposed to randomly drop one self-attention module. As a result, models are forced to learn rich relations among diverse local patches. Our proposed TransFER model outperforms the state-of-the-art methods on several FER benchmarks, showing its effectiveness and usefulness.
Multichannel LSTM-CNN for Telugu Technical Domain Identification
Feb 24, 2021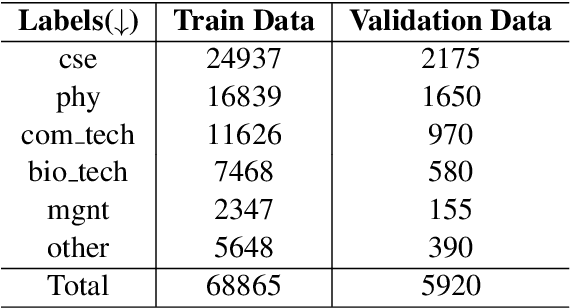
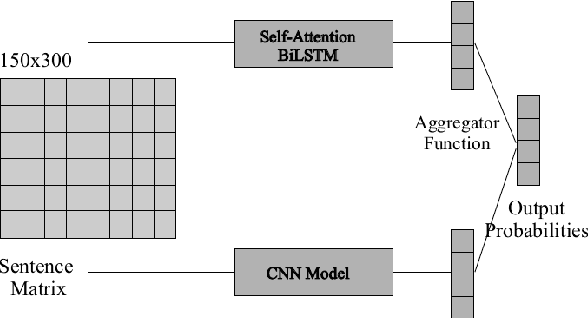
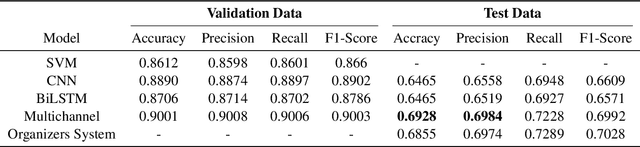
With the instantaneous growth of text information, retrieving domain-oriented information from the text data has a broad range of applications in Information Retrieval and Natural language Processing. Thematic keywords give a compressed representation of the text. Usually, Domain Identification plays a significant role in Machine Translation, Text Summarization, Question Answering, Information Extraction, and Sentiment Analysis. In this paper, we proposed the Multichannel LSTM-CNN methodology for Technical Domain Identification for Telugu. This architecture was used and evaluated in the context of the ICON shared task TechDOfication 2020 (task h), and our system got 69.9% of the F1 score on the test dataset and 90.01% on the validation set.
A Conversational Agent System for Dietary Supplements Use
Apr 04, 2021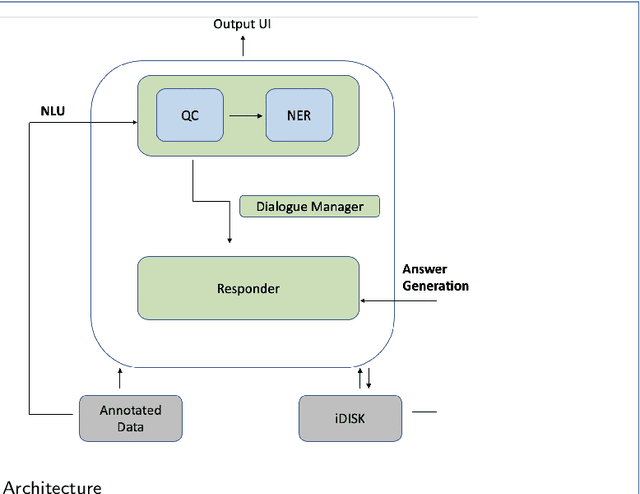

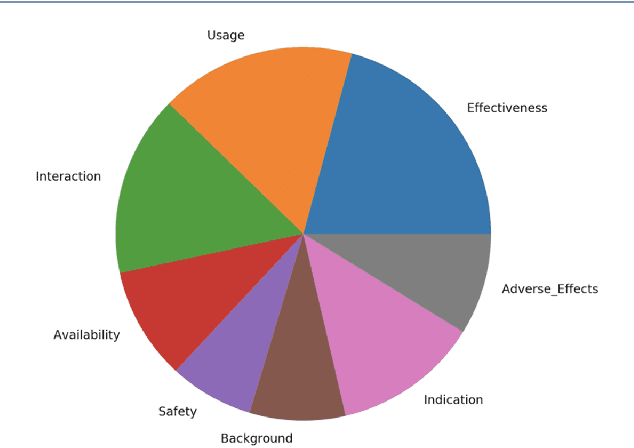
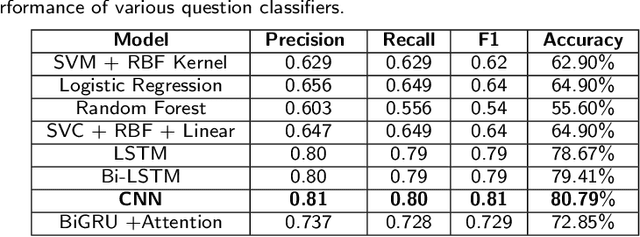
Dietary supplements (DS) have been widely used by consumers, but the information around the effectiveness and safety of DS is disparate or incomplete, making barriers to consumers to find information effectively. Conversational agent systems have been applied to the healthcare domain but there is no such a system to answer consumers regarding DS use, although widespread use of the dietary supplement. In this study, we develop the first conversational agent system for DS use.
Hybrid attention network based on progressive embedding scale-context for crowd counting
Jun 04, 2021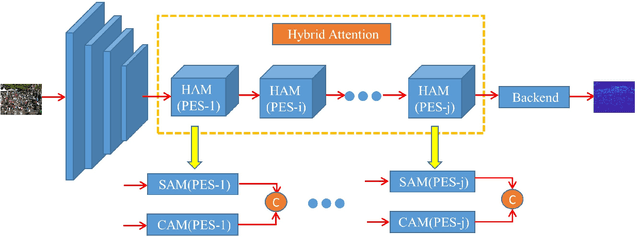
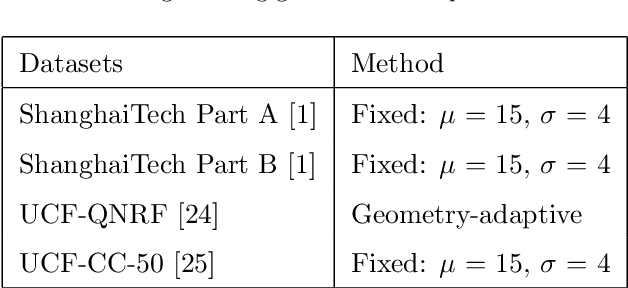
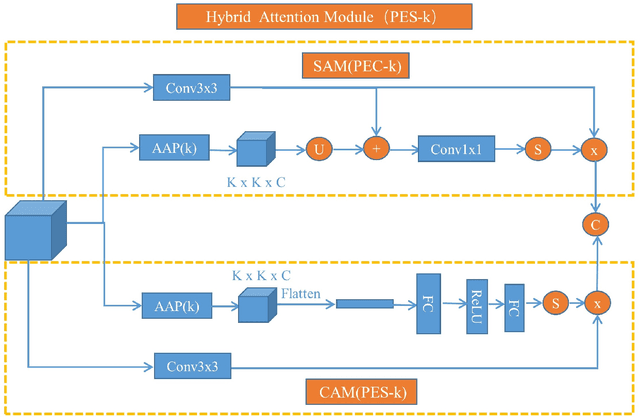
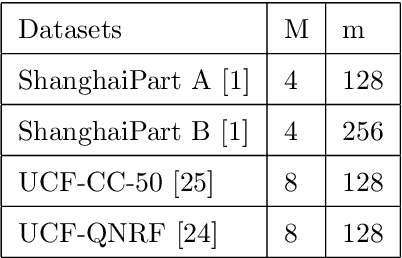
The existing crowd counting methods usually adopted attention mechanism to tackle background noise, or applied multi-level features or multi-scales context fusion to tackle scale variation. However, these approaches deal with these two problems separately. In this paper, we propose a Hybrid Attention Network (HAN) by employing Progressive Embedding Scale-context (PES) information, which enables the network to simultaneously suppress noise and adapt head scale variation. We build the hybrid attention mechanism through paralleling spatial attention and channel attention module, which makes the network to focus more on the human head area and reduce the interference of background objects. Besides, we embed certain scale-context to the hybrid attention along the spatial and channel dimensions for alleviating these counting errors caused by the variation of perspective and head scale. Finally, we propose a progressive learning strategy through cascading multiple hybrid attention modules with embedding different scale-context, which can gradually integrate different scale-context information into the current feature map from global to local. Ablation experiments provides that the network architecture can gradually learn multi-scale features and suppress background noise. Extensive experiments demonstrate that HANet obtain state-of-the-art counting performance on four mainstream datasets.
EqGNN: Equalized Node Opportunity in Graphs
Aug 19, 2021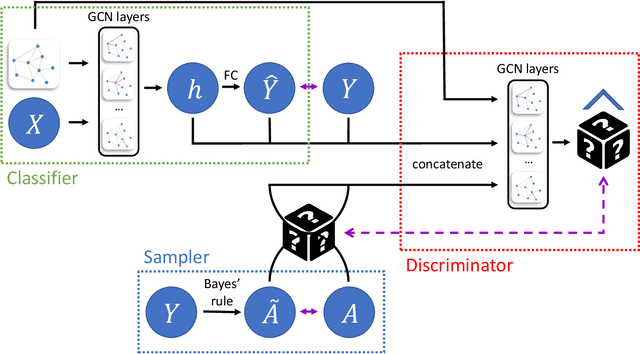
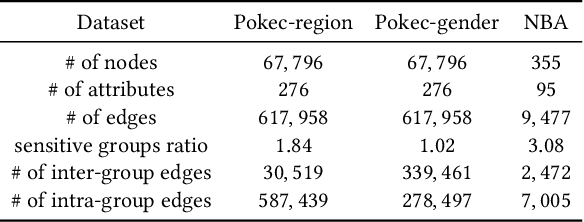
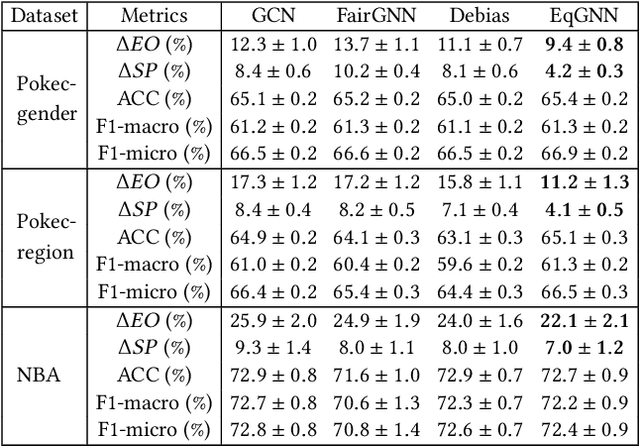
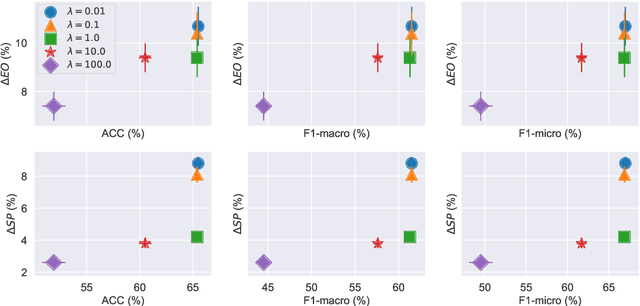
Graph neural networks (GNNs), has been widely used for supervised learning tasks in graphs reaching state-of-the-art results. However, little work was dedicated to creating unbiased GNNs, i.e., where the classification is uncorrelated with sensitive attributes, such as race or gender. Some ignore the sensitive attributes or optimize for the criteria of statistical parity for fairness. However, it has been shown that neither approaches ensure fairness, but rather cripple the utility of the prediction task. In this work, we present a GNN framework that allows optimizing representations for the notion of Equalized Odds fairness criteria. The architecture is composed of three components: (1) a GNN classifier predicting the utility class, (2) a sampler learning the distribution of the sensitive attributes of the nodes given their labels. It generates samples fed into a (3) discriminator that discriminates between true and sampled sensitive attributes using a novel "permutation loss" function. Using these components, we train a model to neglect information regarding the sensitive attribute only with respect to its label. To the best of our knowledge, we are the first to optimize GNNs for the equalized odds criteria. We evaluate our classifier over several graph datasets and sensitive attributes and show our algorithm reaches state-of-the-art results.
Multi-Frequency Phase Retrieval for Antenna Measurements
May 20, 2021

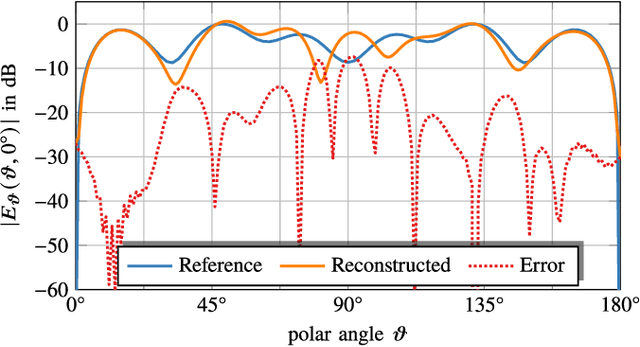
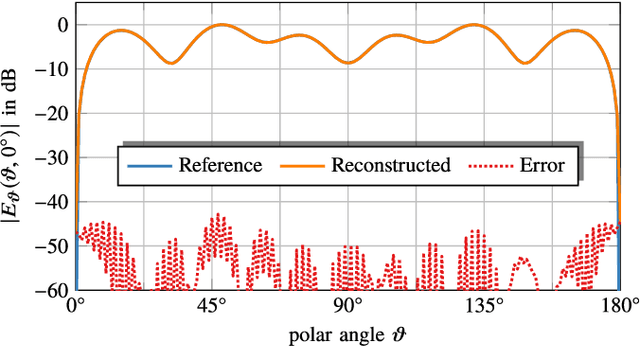
Phase retrieval problems in antenna measurements arise when a reference phase cannot be provided to all measurement locations. Phase retrieval algorithms require sufficiently many independent measurement samples of the radiated fields to be successful. Larger amounts of independent data may improve the reconstruction of the phase information from magnitude-only measurements. We show how the knowledge of relative phases among the spectral components of a modulated signal at the individual measurement locations may be employed to reconstruct the relative phases between different measurement locations at all frequencies. Projection matrices map the estimated phases onto the space of fields possibly generated by equivalent antenna under test (AUT) sources at all frequencies. In this way, the phase of the reconstructed solution is not only restricted by the measurement samples at one frequency, but by the samples at allfrequencies simultaneously. The proposed method can increase the amount of independent phase information even if all probes are located in the far field of the AUT.
* 14 pages, 29 figures, 1 table, published in IEEE Transactions on Antennas and Propagation
Electrocardio Panorama: Synthesizing New ECG Views with Self-supervision
May 12, 2021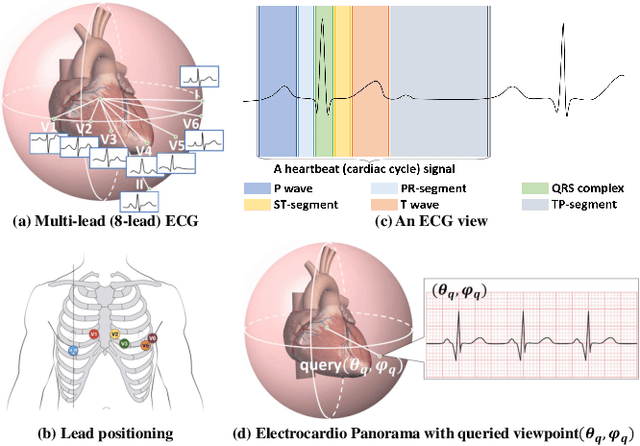
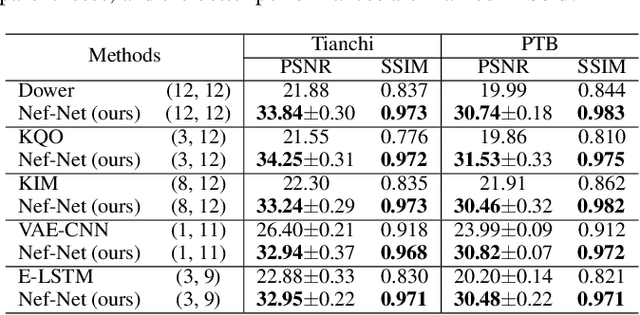
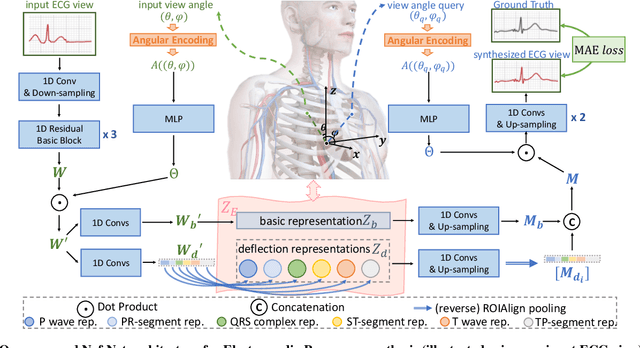
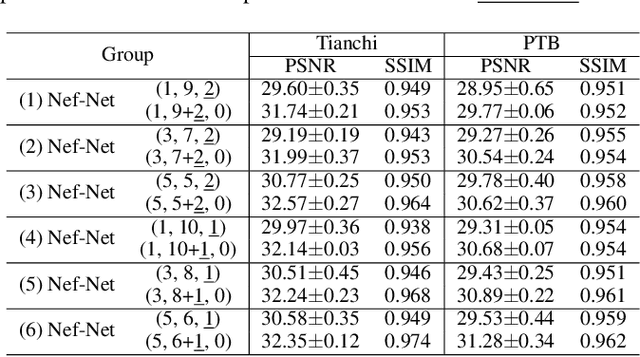
Multi-lead electrocardiogram (ECG) provides clinical information of heartbeats from several fixed viewpoints determined by the lead positioning. However, it is often not satisfactory to visualize ECG signals in these fixed and limited views, as some clinically useful information is represented only from a few specific ECG viewpoints. For the first time, we propose a new concept, Electrocardio Panorama, which allows visualizing ECG signals from any queried viewpoints. To build Electrocardio Panorama, we assume that an underlying electrocardio field exists, representing locations, magnitudes, and directions of ECG signals. We present a Neural electrocardio field Network (Nef-Net), which first predicts the electrocardio field representation by using a sparse set of one or few input ECG views and then synthesizes Electrocardio Panorama based on the predicted representations. Specially, to better disentangle electrocardio field information from viewpoint biases, a new Angular Encoding is proposed to process viewpoint angles. Also, we propose a self-supervised learning approach called Standin Learning, which helps model the electrocardio field without direct supervision. Further, with very few modifications, Nef-Net can also synthesize ECG signals from scratch. Experiments verify that our Nef-Net performs well on Electrocardio Panorama synthesis, and outperforms the previous work on the auxiliary tasks (ECG view transformation and ECG synthesis from scratch). The codes and the division labels of cardiac cycles and ECG deflections on Tianchi ECG and PTB datasets are available at https://github.com/WhatAShot/Electrocardio-Panorama.
Towards Zero-shot Language Modeling
Aug 06, 2021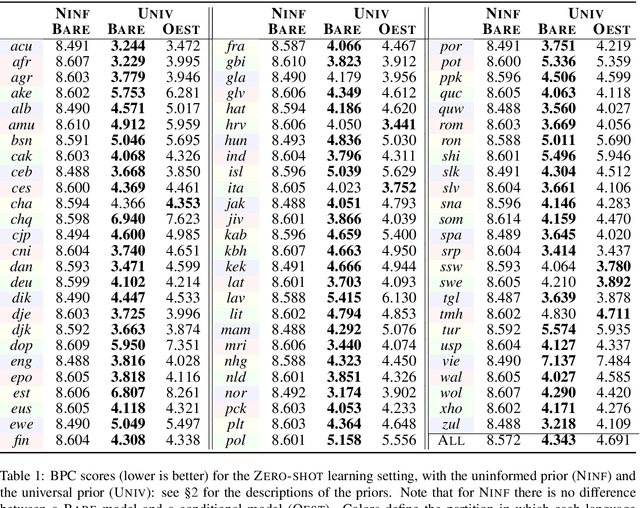
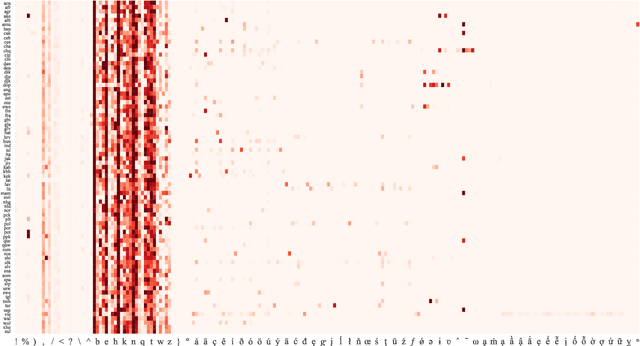
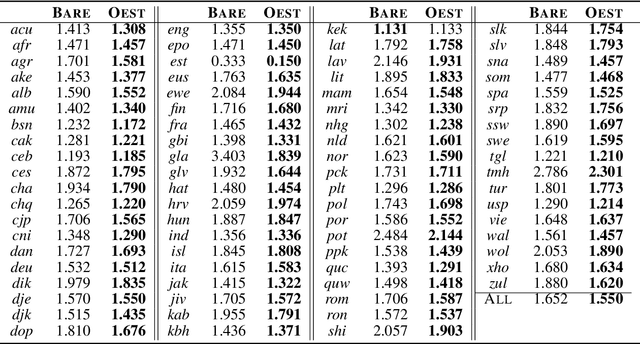
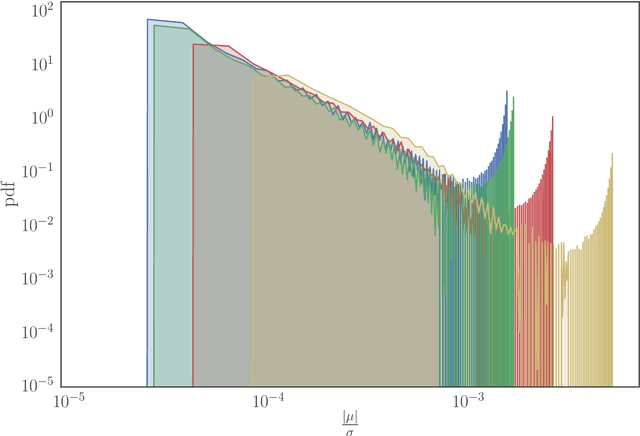
Can we construct a neural model that is inductively biased towards learning human languages? Motivated by this question, we aim at constructing an informative prior over neural weights, in order to adapt quickly to held-out languages in the task of character-level language modeling. We infer this distribution from a sample of typologically diverse training languages via Laplace approximation. The use of such a prior outperforms baseline models with an uninformative prior (so-called "fine-tuning") in both zero-shot and few-shot settings. This shows that the prior is imbued with universal phonological knowledge. Moreover, we harness additional language-specific side information as distant supervision for held-out languages. Specifically, we condition language models on features from typological databases, by concatenating them to hidden states or generating weights with hyper-networks. These features appear beneficial in the few-shot setting, but not in the zero-shot setting. Since the paucity of digital texts affects the majority of the world's languages, we hope that these findings will help broaden the scope of applications for language technology.