 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Adversarial Robustness through the Lens of Causality
Jun 11, 2021
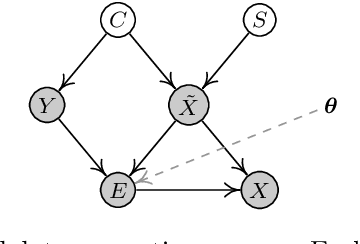
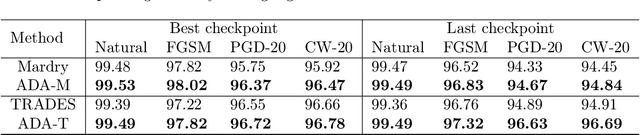
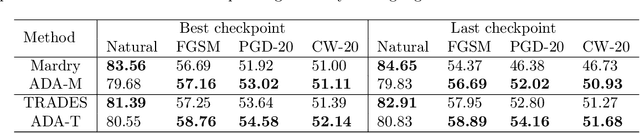
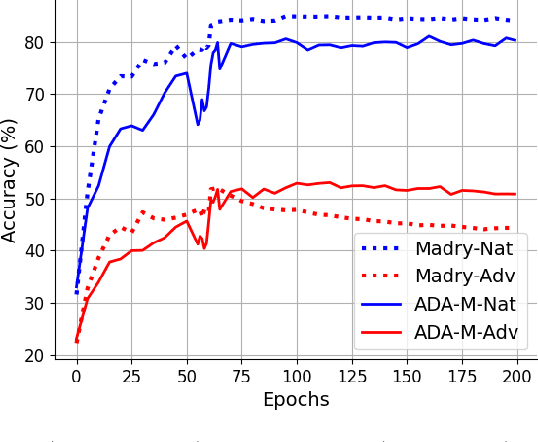
The adversarial vulnerability of deep neural networks has attracted significant attention in machine learning. From a causal viewpoint, adversarial attacks can be considered as a specific type of distribution change on natural data. As causal reasoning has an instinct for modeling distribution change, we propose to incorporate causality into mitigating adversarial vulnerability. However, causal formulations of the intuition of adversarial attack and the development of robust DNNs are still lacking in the literature. To bridge this gap, we construct a causal graph to model the generation process of adversarial examples and define the adversarial distribution to formalize the intuition of adversarial attacks. From a causal perspective, we find that the label is spuriously correlated with the style (content-independent) information when an instance is given. The spurious correlation implies that the adversarial distribution is constructed via making the statistical conditional association between style information and labels drastically different from that in natural distribution. Thus, DNNs that fit the spurious correlation are vulnerable to the adversarial distribution. Inspired by the observation, we propose the adversarial distribution alignment method to eliminate the difference between the natural distribution and the adversarial distribution. Extensive experiments demonstrate the efficacy of the proposed method. Our method can be seen as the first attempt to leverage causality for mitigating adversarial vulnerability.
Point-wise posteriori phase estimation in high-precision fringe projection profilometry
Jul 31, 2021
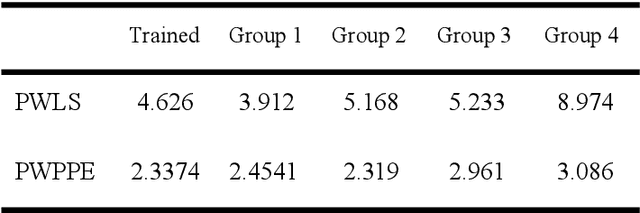

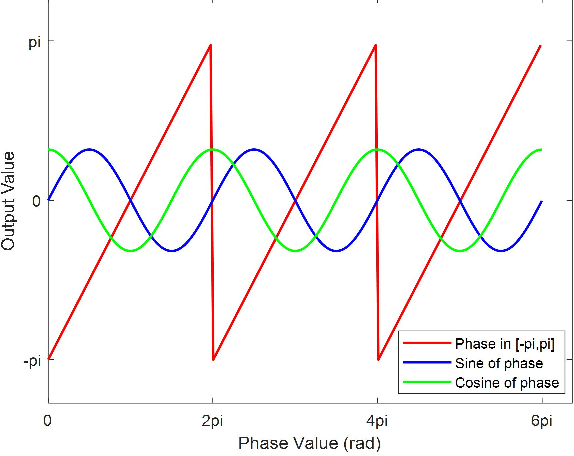
In fringe projection profilometry, the high-order harmonics information of non-sinusoidal fringes will lead to errors in the phase estimation. In order to solve this problem, a point-wise posterior phase estimation (PWPPE) method based on deep learning technique is proposed in this paper. The complex nonlinear mapping relationship between the multiple gray values and the sine / cosine value of the phase is constructed by using the feedforward neural network model. After the model training, it can estimate the phase values of each pixel location, and the accuracy is higher than the point-wise least-square (PWLS) method. To further verify the effectiveness of this method, a face mask is measured, the traditional PWLS method and the proposed PWPPE method are employed, respectively. The comparison results show that the traditional method is with periodic phase errors, while the proposed PWPPE method can effectively eliminate such phase errors caused by non-sinusoidal fringes.
CLIP: A Dataset for Extracting Action Items for Physicians from Hospital Discharge Notes
Jun 04, 2021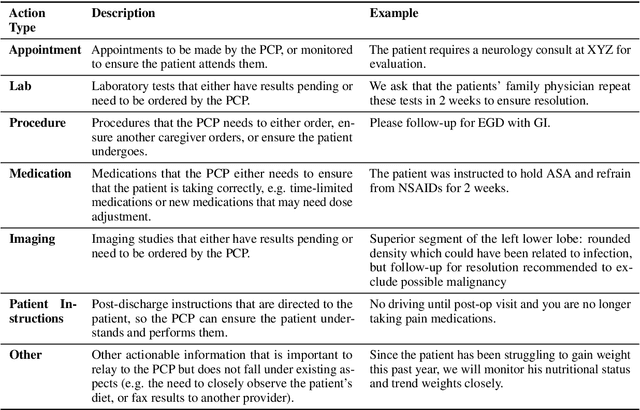
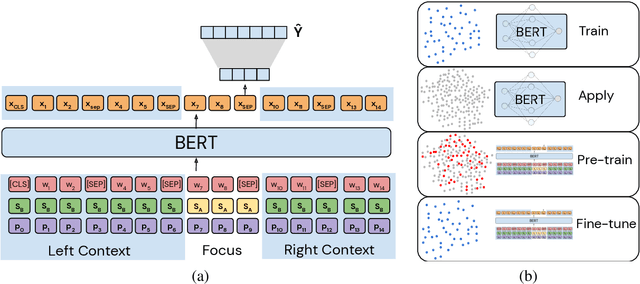

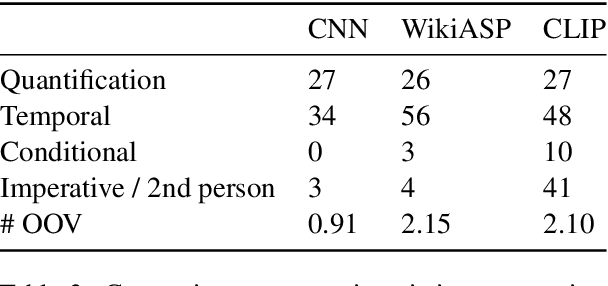
Continuity of care is crucial to ensuring positive health outcomes for patients discharged from an inpatient hospital setting, and improved information sharing can help. To share information, caregivers write discharge notes containing action items to share with patients and their future caregivers, but these action items are easily lost due to the lengthiness of the documents. In this work, we describe our creation of a dataset of clinical action items annotated over MIMIC-III, the largest publicly available dataset of real clinical notes. This dataset, which we call CLIP, is annotated by physicians and covers 718 documents representing 100K sentences. We describe the task of extracting the action items from these documents as multi-aspect extractive summarization, with each aspect representing a type of action to be taken. We evaluate several machine learning models on this task, and show that the best models exploit in-domain language model pre-training on 59K unannotated documents, and incorporate context from neighboring sentences. We also propose an approach to pre-training data selection that allows us to explore the trade-off between size and domain-specificity of pre-training datasets for this task.
Bi-Temporal Semantic Reasoning for the Semantic Change Detection of HR Remote Sensing Images
Aug 25, 2021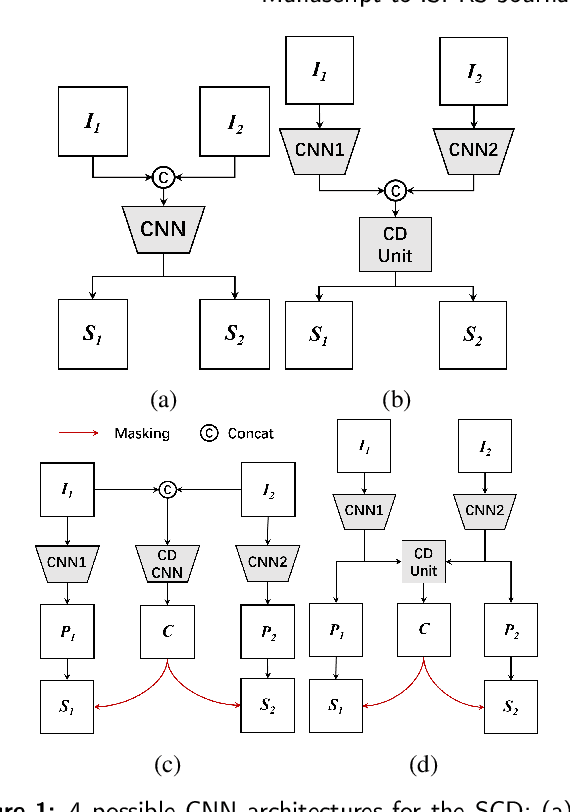

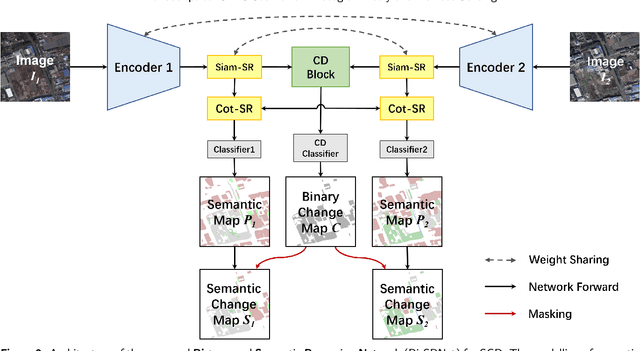
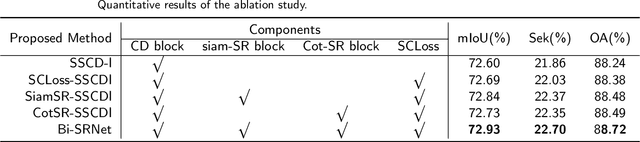
Semantic change detection (SCD) extends the multi-class change detection (MCD) task to provide not only the change locations but also the detailed land-cover/land-use (LC/LU) categories before and after the observation intervals. This fine-grained semantic change information is very useful in many applications. Recent studies indicate that the SCD can be modeled through a triple-branch Convolutional Neural Network (CNN), which contains two temporal branches and a change branch. However, in this architecture, the communications between the temporal branches and the change branch are in-sufficient. To overcome the limitations in existing methods, we propose a novel CNN architecture for the SCD, where the semantic temporal features are merged in a deep CD unit. Furthermore, we elaborate on this architecture to reason the bi-temporal semantic correlations. The resulting Bi-temporal Semantic Reasoning Network (Bi-SRNet) contains two types of semantic reasoning blocks to reason both single-temporal and cross-temporal semantic correlations, as well as a novel loss function to improve the semantic consistency of change detection results. Experimental results on a benchmark dataset show that the proposed architecture obtains significant accuracy improvements over the existing approaches, while the added designs in the Bi-SRNet further improves the segmentation of both semantic categories and the changed areas. The codes in this paper are accessible at: https://github.com/ggsDing/Bi-SRNet
Unsupervised Path Representation Learning with Curriculum Negative Sampling
Jun 17, 2021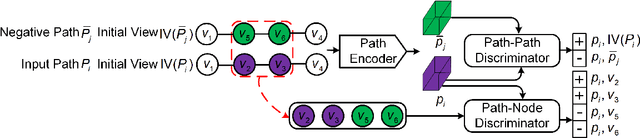
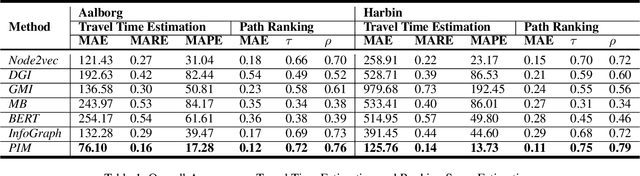
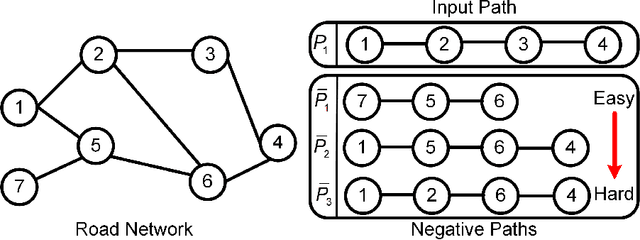
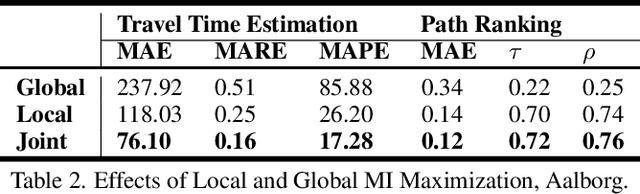
Path representations are critical in a variety of transportation applications, such as estimating path ranking in path recommendation systems and estimating path travel time in navigation systems. Existing studies often learn task-specific path representations in a supervised manner, which require a large amount of labeled training data and generalize poorly to other tasks. We propose an unsupervised learning framework Path InfoMax (PIM) to learn generic path representations that work for different downstream tasks. We first propose a curriculum negative sampling method, for each input path, to generate a small amount of negative paths, by following the principles of curriculum learning. Next, \emph{PIM} employs mutual information maximization to learn path representations from both a global and a local view. In the global view, PIM distinguishes the representations of the input paths from those of the negative paths. In the local view, \emph{PIM} distinguishes the input path representations from the representations of the nodes that appear only in the negative paths. This enables the learned path representations to encode both global and local information at different scales. Extensive experiments on two downstream tasks, ranking score estimation and travel time estimation, using two road network datasets suggest that PIM significantly outperforms other unsupervised methods and is also able to be used as a pre-training method to enhance supervised path representation learning.
The Atlas of Lane Changes: Investigating Location-dependent Lane Change Behaviors Using Measurement Data from a Customer Fleet
Jun 23, 2021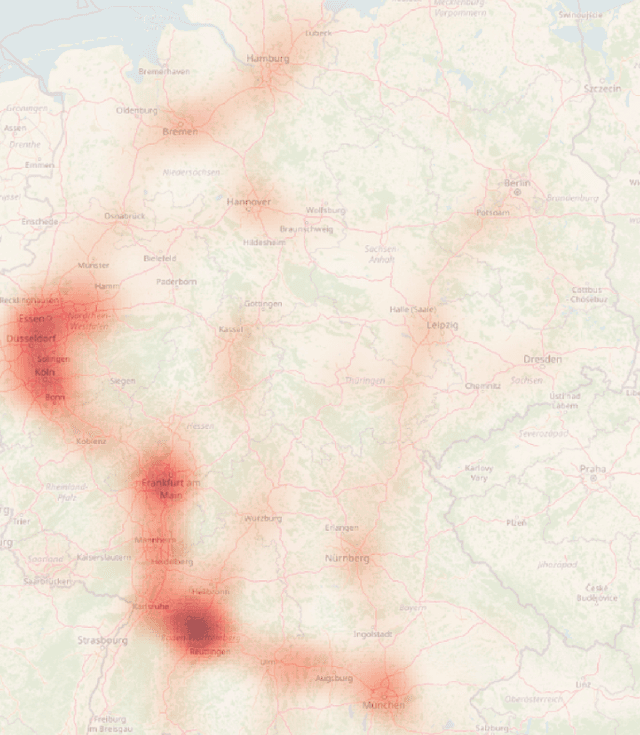
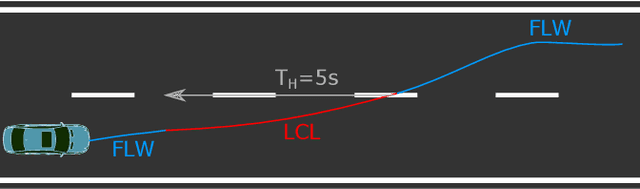
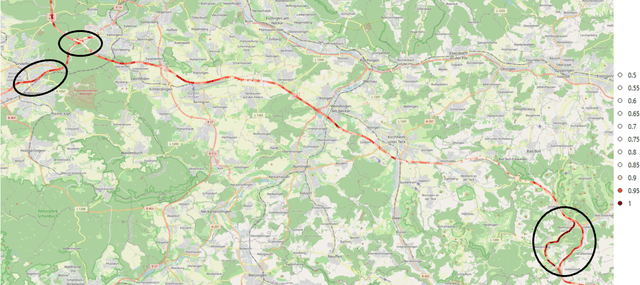
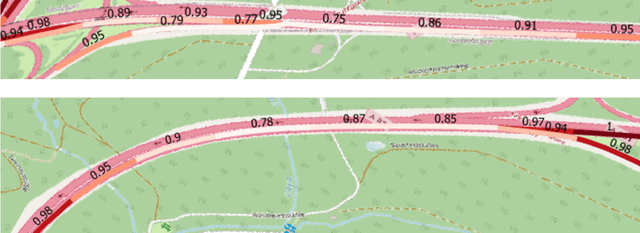
The prediction of surrounding traffic participants behavior is a crucial and challenging task for driver assistance and autonomous driving systems. Today's approaches mainly focus on modeling dynamic aspects of the traffic situation and try to predict traffic participants behavior based on this. In this article we take a first step towards extending this common practice by calculating location-specific a-priori lane change probabilities. The idea behind this is straight forward: The driving behavior of humans may vary in exactly the same traffic situation depending on the respective location. E.g. drivers may ask themselves: Should I pass the truck in front of me immediately or should I wait until reaching the less curvy part of my route lying only a few kilometers ahead? Although, such information is far away from allowing behavior prediction on its own, it is obvious that today's approaches will greatly benefit when incorporating such location-specific a-priori probabilities into their predictions. For example, our investigations show that highway interchanges tend to enhance driver's motivation to perform lane changes, whereas curves seem to have lane change-dampening effects. Nevertheless, the investigation of all considered local conditions shows that superposition of various effects can lead to unexpected probabilities at some locations. We thus suggest dynamically constructing and maintaining a lane change probability map based on customer fleet data in order to support onboard prediction systems with additional information. For deriving reliable lane change probabilities a broad customer fleet is the key to success.
Exploiting temporal and depth information for multi-frame face anti-spoofing
Nov 26, 2018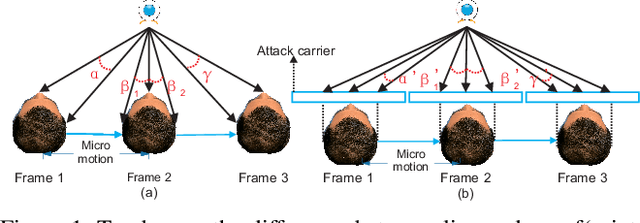
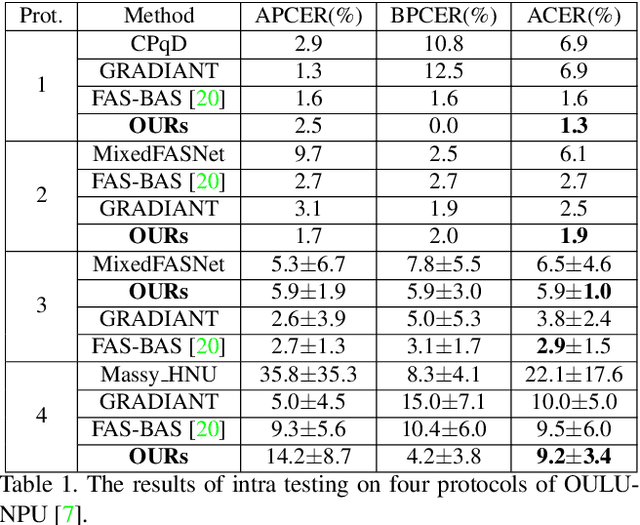
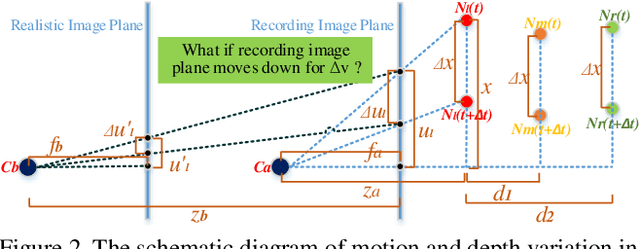
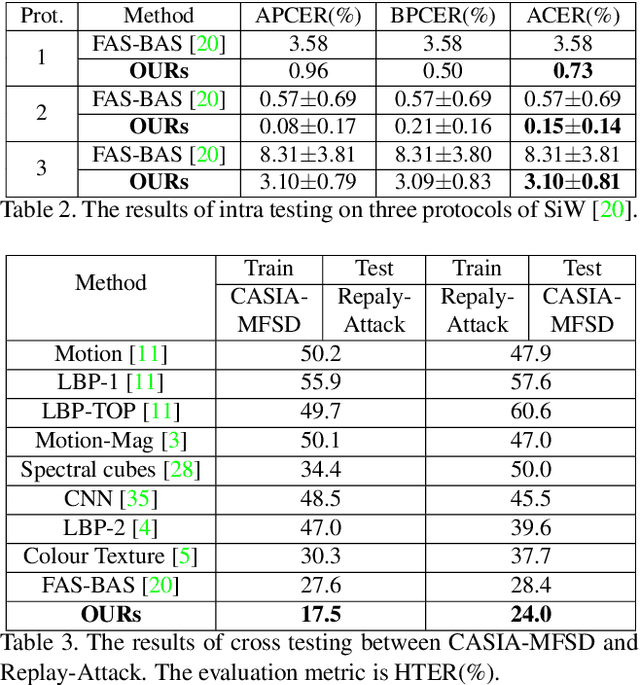
Face anti-spoofing is significant to the security of face recognition systems. Previous works on depth supervised learning have proved the effectiveness for face anti-spoofing. Nevertheless, they only considered the depth as an auxiliary supervision in the single frame. Different from these methods, we develop a new method to estimate depth information from multiple RGB frames and propose a depth-supervised architecture which can efficiently encodes spatiotemporal information for presentation attack detection. It includes two novel modules: optical flow guided feature block (OFFB) and convolution gated recurrent units (ConvGRU) module, which are designed to extract short-term and long-term motion to discriminate living and spoofing faces. Extensive experiments demonstrate that the proposed approach achieves state-of-the-art results on four benchmark datasets, namely OULU-NPU, SiW, CASIA-MFSD, and Replay-Attack.
Learning the Physics of Particle Transport via Transformers
Sep 08, 2021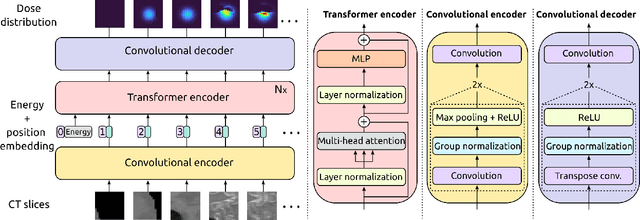
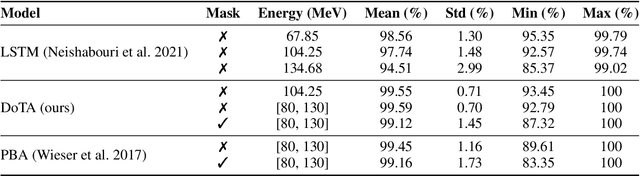
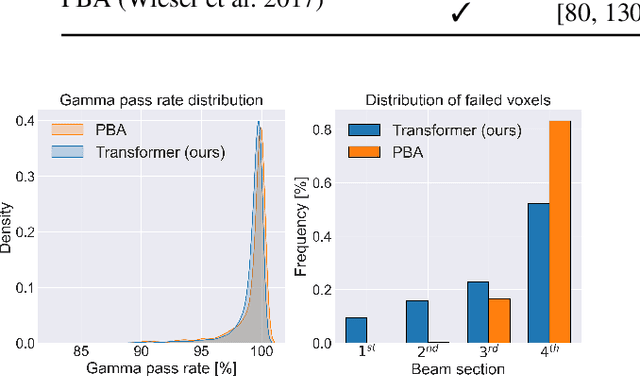
Particle physics simulations are the cornerstone of nuclear engineering applications. Among them radiotherapy (RT) is crucial for society, with 50% of cancer patients receiving radiation treatments. For the most precise targeting of tumors, next generation RT treatments aim for real-time correction during radiation delivery, necessitating particle transport algorithms that yield precise dose distributions in sub-second times even in highly heterogeneous patient geometries. This is infeasible with currently available, purely physics based simulations. In this study, we present a data-driven dose calculation algorithm predicting the dose deposited by mono-energetic proton beams for arbitrary energies and patient geometries. Our approach frames particle transport as sequence modeling, where convolutional layers extract important spatial features into tokens and the transformer self-attention mechanism routes information between such tokens in the sequence and a beam energy token. We train our network and evaluate prediction accuracy using computationally expensive but accurate Monte Carlo (MC) simulations, considered the gold standard in particle physics. Our proposed model is 33 times faster than current clinical analytic pencil beam algorithms, improving upon their accuracy in the most heterogeneous and challenging geometries. With a relative error of 0.34% and very high gamma pass rate of 99.59% (1%, 3 mm), it also greatly outperforms the only published similar data-driven proton dose algorithm, even at a finer grid resolution. Offering MC precision 400 times faster, our model could overcome a major obstacle that has so far prohibited real-time adaptive proton treatments and significantly increase cancer treatment efficacy. Its potential to model physics interactions of other particles could also boost heavy ion treatment planning procedures limited by the speed of traditional methods.
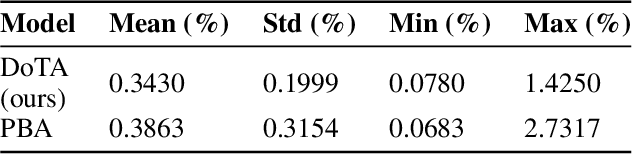
DouZero: Mastering DouDizhu with Self-Play Deep Reinforcement Learning
Jun 11, 2021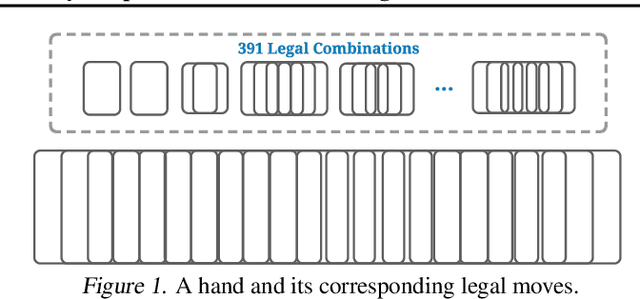
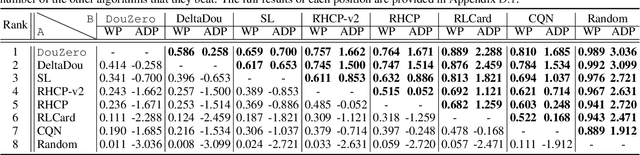
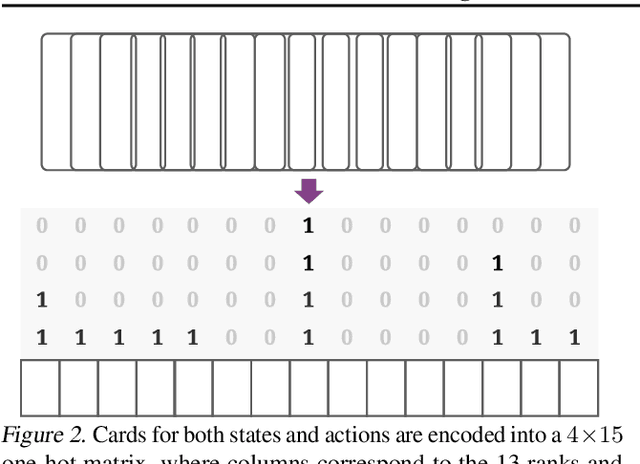

Games are abstractions of the real world, where artificial agents learn to compete and cooperate with other agents. While significant achievements have been made in various perfect- and imperfect-information games, DouDizhu (a.k.a. Fighting the Landlord), a three-player card game, is still unsolved. DouDizhu is a very challenging domain with competition, collaboration, imperfect information, large state space, and particularly a massive set of possible actions where the legal actions vary significantly from turn to turn. Unfortunately, modern reinforcement learning algorithms mainly focus on simple and small action spaces, and not surprisingly, are shown not to make satisfactory progress in DouDizhu. In this work, we propose a conceptually simple yet effective DouDizhu AI system, namely DouZero, which enhances traditional Monte-Carlo methods with deep neural networks, action encoding, and parallel actors. Starting from scratch in a single server with four GPUs, DouZero outperformed all the existing DouDizhu AI programs in days of training and was ranked the first in the Botzone leaderboard among 344 AI agents. Through building DouZero, we show that classic Monte-Carlo methods can be made to deliver strong results in a hard domain with a complex action space. The code and an online demo are released at https://github.com/kwai/DouZero with the hope that this insight could motivate future work.
Screen2Words: Automatic Mobile UI Summarization with Multimodal Learning
Aug 07, 2021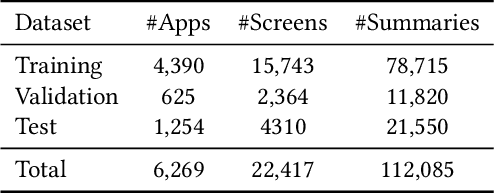

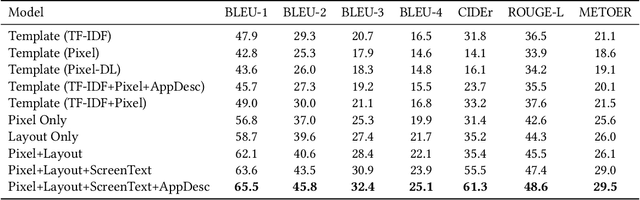
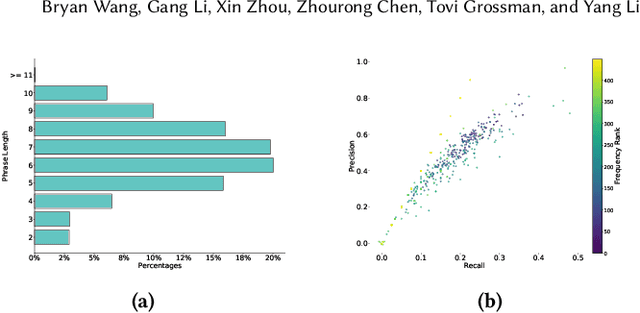
Mobile User Interface Summarization generates succinct language descriptions of mobile screens for conveying important contents and functionalities of the screen, which can be useful for many language-based application scenarios. We present Screen2Words, a novel screen summarization approach that automatically encapsulates essential information of a UI screen into a coherent language phrase. Summarizing mobile screens requires a holistic understanding of the multi-modal data of mobile UIs, including text, image, structures as well as UI semantics, motivating our multi-modal learning approach. We collected and analyzed a large-scale screen summarization dataset annotated by human workers. Our dataset contains more than 112k language summarization across $\sim$22k unique UI screens. We then experimented with a set of deep models with different configurations. Our evaluation of these models with both automatic accuracy metrics and human rating shows that our approach can generate high-quality summaries for mobile screens. We demonstrate potential use cases of Screen2Words and open-source our dataset and model to lay the foundations for further bridging language and user interfaces.