 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning the CSI Denoising and Feedback Without Supervision
Apr 11, 2021

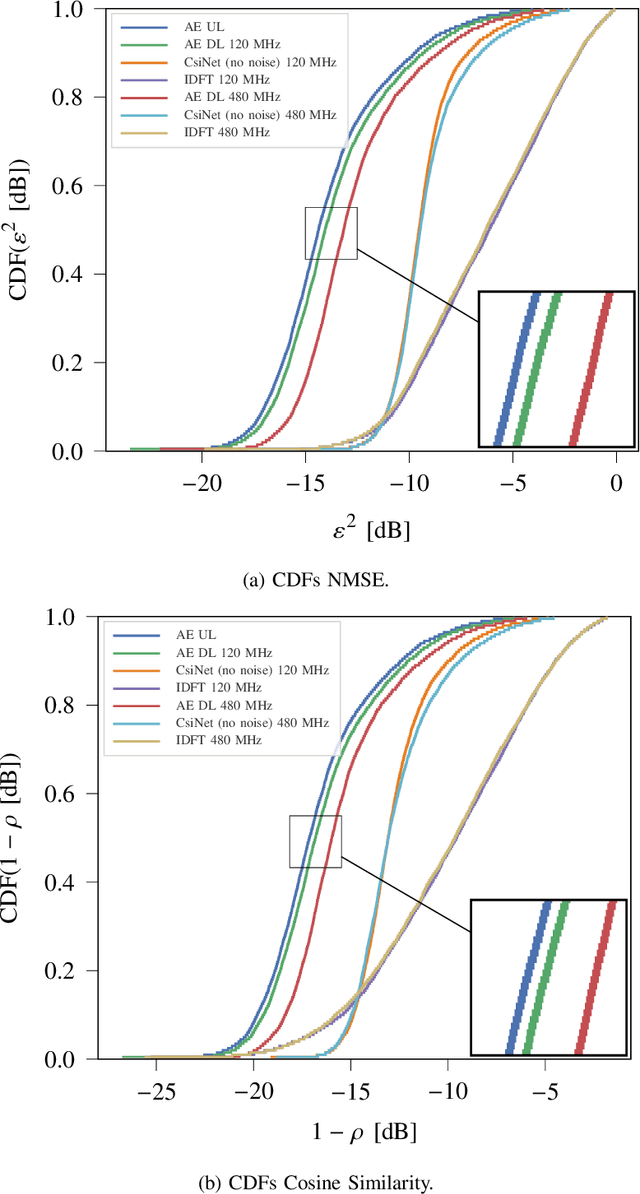
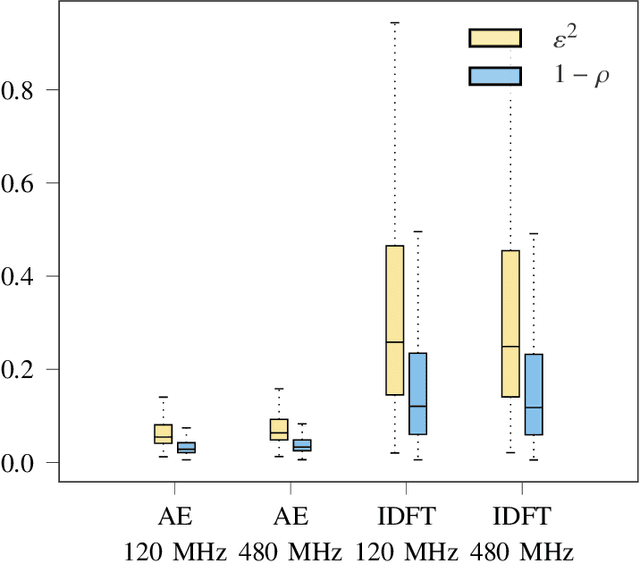
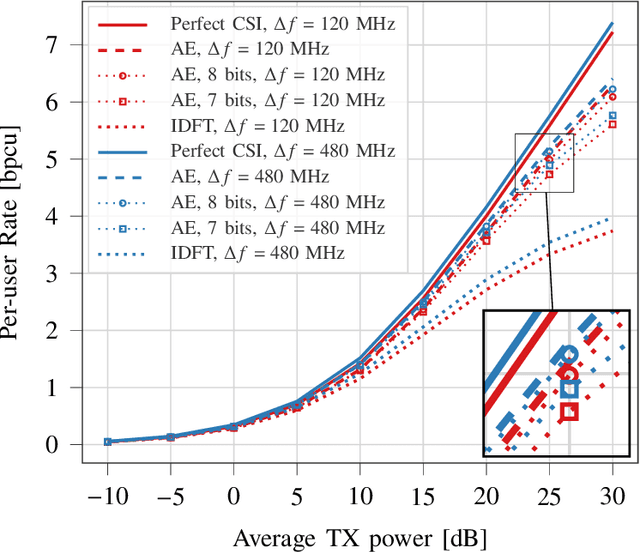
In this work, we develop a joint denoising and feedback strategy for channel state information in frequency division duplex systems. In such systems, the biggest challenge is the overhead incurred when the mobile terminal has to send the downlink channel state information or corresponding partial information to the base station, where the complete estimates can subsequently be restored. To this end, we propose a novel learning-based framework for denoising and compression of channel estimates. Unlike existing studies, we extend a recently proposed approach and show that based solely on noisy uplink data available at the base station, it is possible to learn an autoencoder neural network that generalizes to downlink data. Subsequently, half of the autoencoder can be offloaded to the mobile terminal to generate channel feedback there as efficiently as possible, without any training effort at the mobile terminal or corresponding transfer of training data to the base station. Numerical simulations demonstrate the near optimal performance of the proposed method.
Human strategic decision making in parametrized games
Apr 30, 2021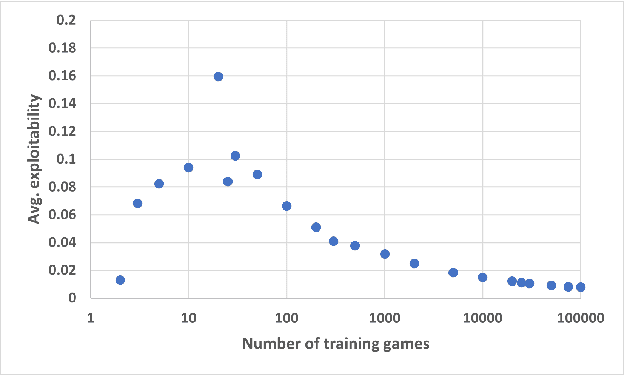
Many real-world games contain parameters which can affect payoffs, action spaces, and information states. For fixed values of the parameters, the game can be solved using standard algorithms. However, in many settings agents must act without knowing the values of the parameters that will be encountered in advance. Often the decisions must be made by a human under time and resource constraints, and it is unrealistic to assume that a human can solve the game in real time. We present a new framework that enables human decision makers to make fast decisions without the aid of real-time solvers. We demonstrate applicability to a variety of situations including settings with multiple players and imperfect information.
The State of Infodemic on Twitter
May 17, 2021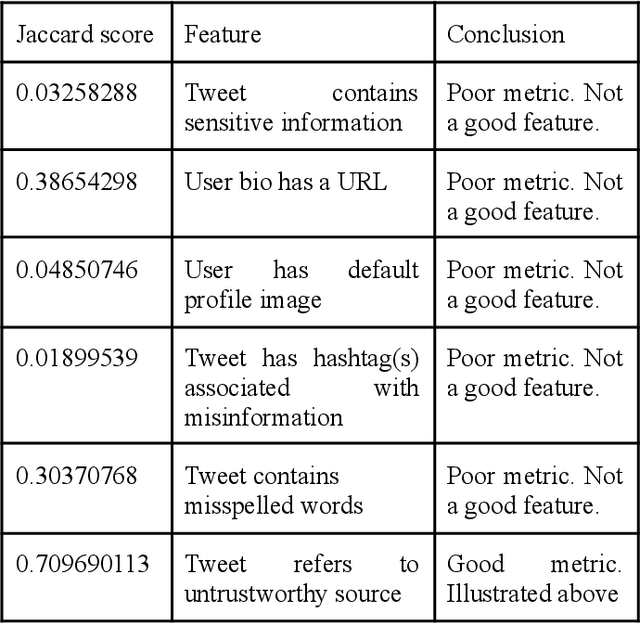
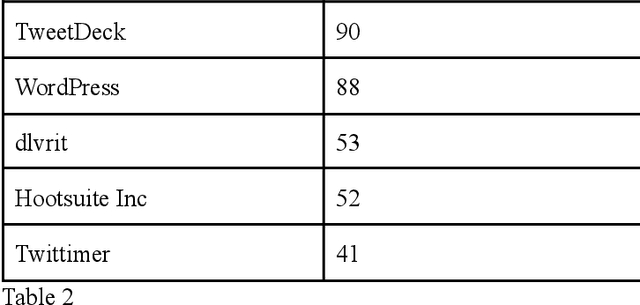
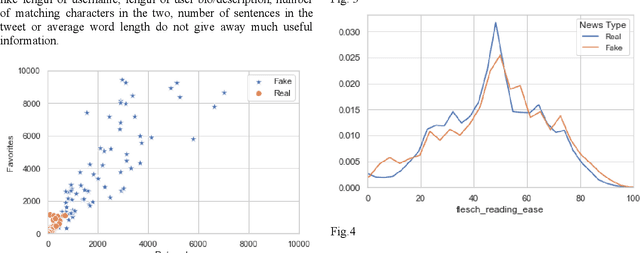
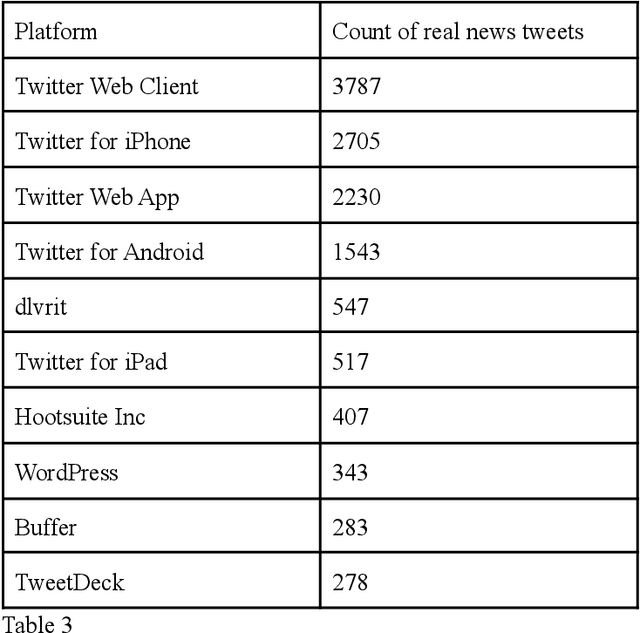
Following the wave of misinterpreted, manipulated and malicious information growing on the Internet, the misinformation surrounding COVID-19 has become a paramount issue. In the context of the current COVID-19 pandemic, social media posts and platforms are at risk of rumors and misinformation in the face of the serious uncertainty surrounding the virus itself. At the same time, the uncertainty and new nature of COVID-19 means that other unconfirmed information that may appear "rumored" may be an important indicator of the behavior and impact of this new virus. Twitter, in particular, has taken a center stage in this storm where Covid-19 has been a much talked about subject. We have presented an exploratory analysis of the tweets and the users who are involved in spreading misinformation and then delved into machine learning models and natural language processing techniques to identify if a tweet contains misinformation.
Multichannel LSTM-CNN for Telugu Technical Domain Identification
Feb 24, 2021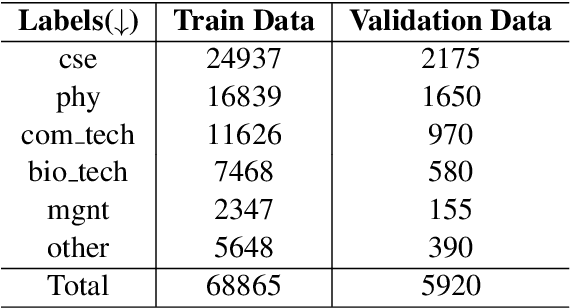
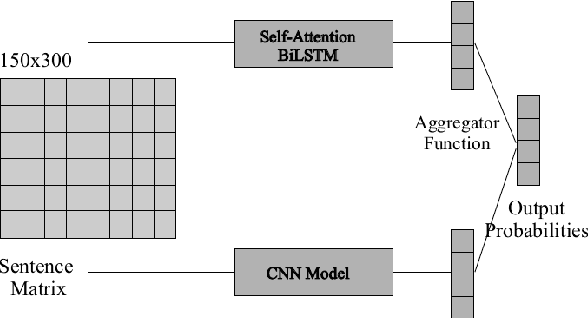
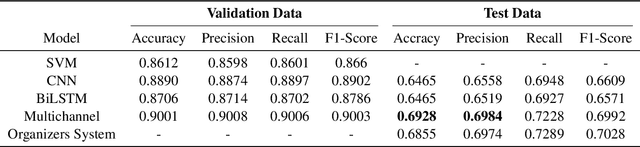
With the instantaneous growth of text information, retrieving domain-oriented information from the text data has a broad range of applications in Information Retrieval and Natural language Processing. Thematic keywords give a compressed representation of the text. Usually, Domain Identification plays a significant role in Machine Translation, Text Summarization, Question Answering, Information Extraction, and Sentiment Analysis. In this paper, we proposed the Multichannel LSTM-CNN methodology for Technical Domain Identification for Telugu. This architecture was used and evaluated in the context of the ICON shared task TechDOfication 2020 (task h), and our system got 69.9% of the F1 score on the test dataset and 90.01% on the validation set.
Deep Reader: Information extraction from Document images via relation extraction and Natural Language
Dec 11, 2018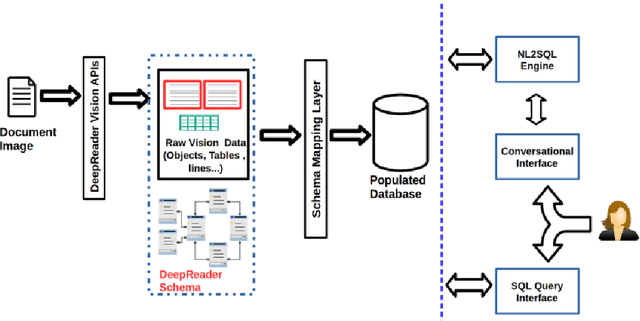
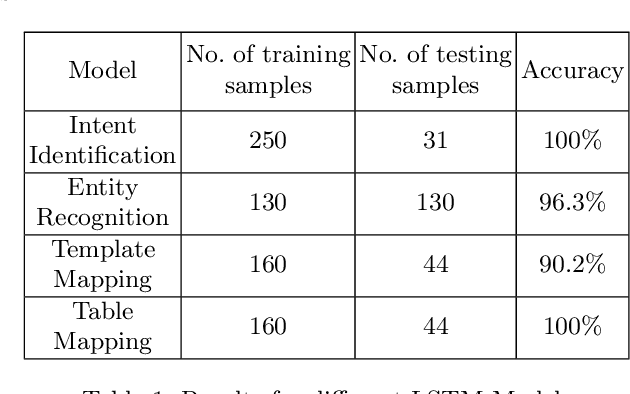
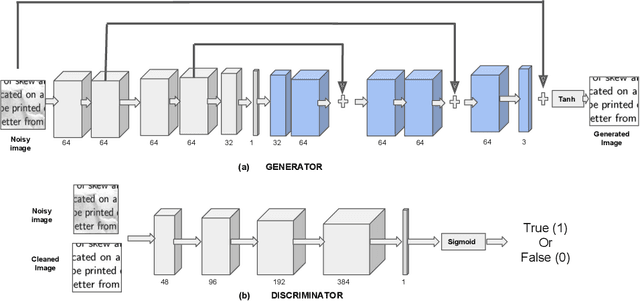

Recent advancements in the area of Computer Vision with state-of-art Neural Networks has given a boost to Optical Character Recognition (OCR) accuracies. However, extracting characters/text alone is often insufficient for relevant information extraction as documents also have a visual structure that is not captured by OCR. Extracting information from tables, charts, footnotes, boxes, headings and retrieving the corresponding structured representation for the document remains a challenge and finds application in a large number of real-world use cases. In this paper, we propose a novel enterprise based end-to-end framework called DeepReader which facilitates information extraction from document images via identification of visual entities and populating a meta relational model across different entities in the document image. The model schema allows for an easy to understand abstraction of the entities detected by the deep vision models and the relationships between them. DeepReader has a suite of state-of-the-art vision algorithms which are applied to recognize handwritten and printed text, eliminate noisy effects, identify the type of documents and detect visual entities like tables, lines and boxes. Deep Reader maps the extracted entities into a rich relational schema so as to capture all the relevant relationships between entities (words, textboxes, lines etc) detected in the document. Relevant information and fields can then be extracted from the document by writing SQL queries on top of the relationship tables. A natural language based interface is added on top of the relationship schema so that a non-technical user, specifying the queries in natural language, can fetch the information with minimal effort. In this paper, we also demonstrate many different capabilities of Deep Reader and report results on a real-world use case.
Disentangling What and Where for 3D Object-Centric Representations Through Active Inference
Aug 26, 2021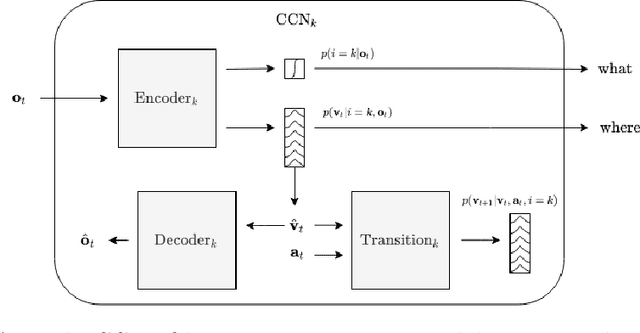
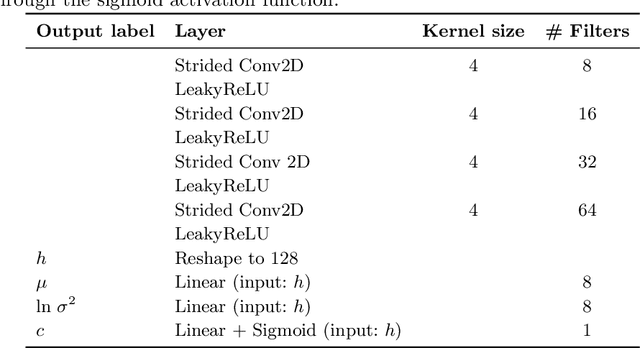
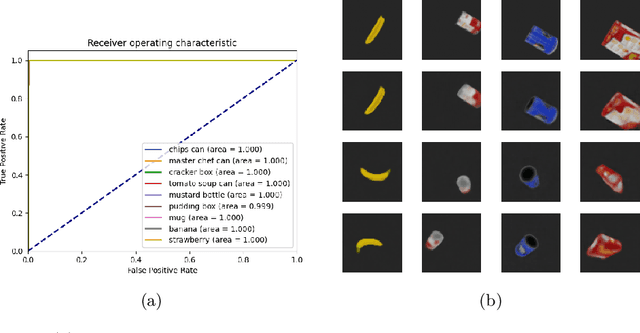
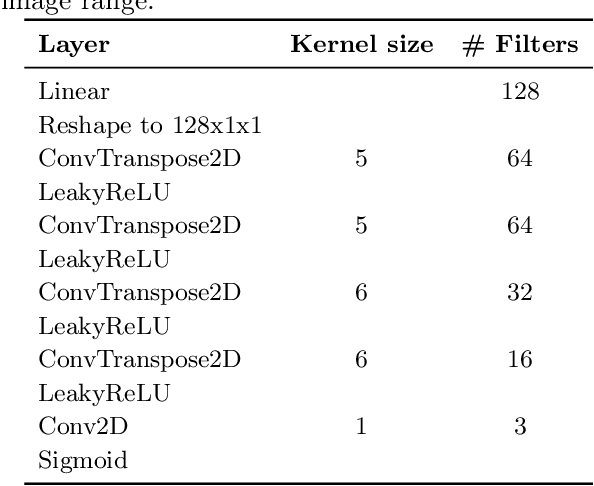
Although modern object detection and classification models achieve high accuracy, these are typically constrained in advance on a fixed train set and are therefore not flexible to deal with novel, unseen object categories. Moreover, these models most often operate on a single frame, which may yield incorrect classifications in case of ambiguous viewpoints. In this paper, we propose an active inference agent that actively gathers evidence for object classifications, and can learn novel object categories over time. Drawing inspiration from the human brain, we build object-centric generative models composed of two information streams, a what- and a where-stream. The what-stream predicts whether the observed object belongs to a specific category, while the where-stream is responsible for representing the object in its internal 3D reference frame. We show that our agent (i) is able to learn representations for many object categories in an unsupervised way, (ii) achieves state-of-the-art classification accuracies, actively resolving ambiguity when required and (iii) identifies novel object categories. Furthermore, we validate our system in an end-to-end fashion where the agent is able to search for an object at a given pose from a pixel-based rendering. We believe that this is a first step towards building modular, intelligent systems that can be used for a wide range of tasks involving three dimensional objects.
Effective and scalable clustering of SARS-CoV-2 sequences
Sep 10, 2021
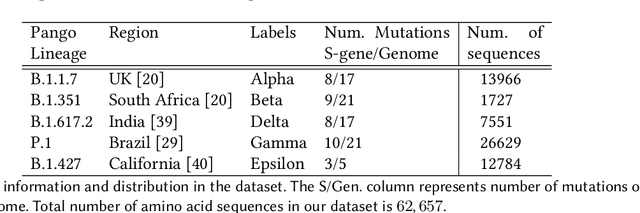
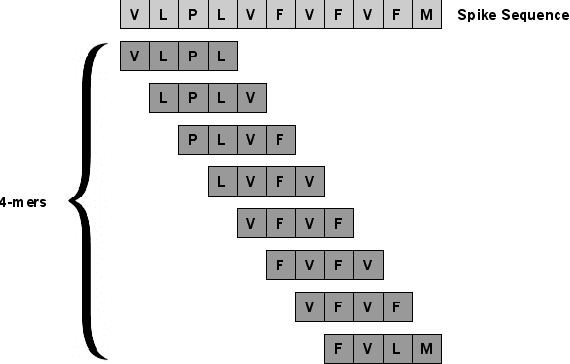
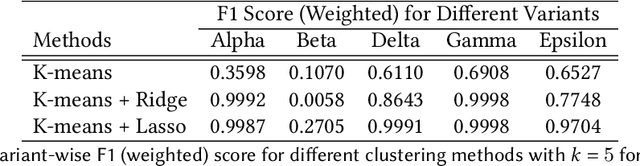
SARS-CoV-2, like any other virus, continues to mutate as it spreads, according to an evolutionary process. Unlike any other virus, the number of currently available sequences of SARS-CoV-2 in public databases such as GISAID is already several million. This amount of data has the potential to uncover the evolutionary dynamics of a virus like never before. However, a million is already several orders of magnitude beyond what can be processed by the traditional methods designed to reconstruct a virus's evolutionary history, such as those that build a phylogenetic tree. Hence, new and scalable methods will need to be devised in order to make use of the ever increasing number of viral sequences being collected. Since identifying variants is an important part of understanding the evolution of a virus, in this paper, we propose an approach based on clustering sequences to identify the current major SARS-CoV-2 variants. Using a $k$-mer based feature vector generation and efficient feature selection methods, our approach is effective in identifying variants, as well as being efficient and scalable to millions of sequences. Such a clustering method allows us to show the relative proportion of each variant over time, giving the rate of spread of each variant in different locations -- something which is important for vaccine development and distribution. We also compute the importance of each amino acid position of the spike protein in identifying a given variant in terms of information gain. Positions of high variant-specific importance tend to agree with those reported by the USA's Centers for Disease Control and Prevention (CDC), further demonstrating our approach.
Linguistic Structures as Weak Supervision for Visual Scene Graph Generation
May 28, 2021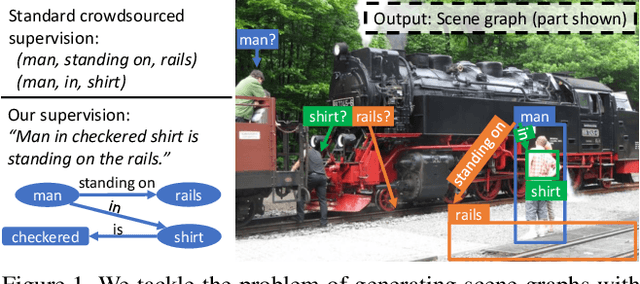

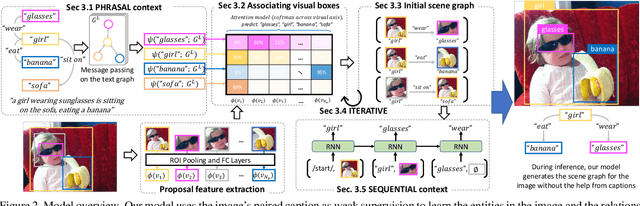
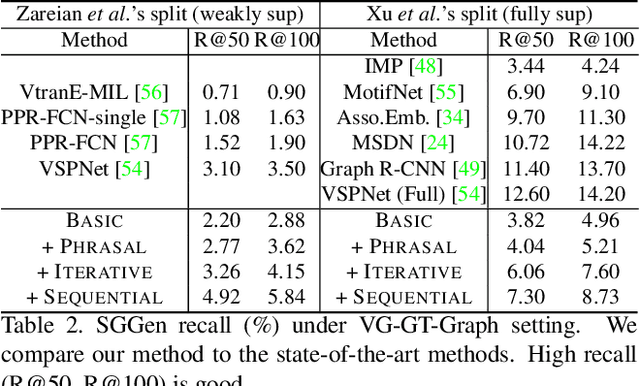
Prior work in scene graph generation requires categorical supervision at the level of triplets - subjects and objects, and predicates that relate them, either with or without bounding box information. However, scene graph generation is a holistic task: thus holistic, contextual supervision should intuitively improve performance. In this work, we explore how linguistic structures in captions can benefit scene graph generation. Our method captures the information provided in captions about relations between individual triplets, and context for subjects and objects (e.g. visual properties are mentioned). Captions are a weaker type of supervision than triplets since the alignment between the exhaustive list of human-annotated subjects and objects in triplets, and the nouns in captions, is weak. However, given the large and diverse sources of multimodal data on the web (e.g. blog posts with images and captions), linguistic supervision is more scalable than crowdsourced triplets. We show extensive experimental comparisons against prior methods which leverage instance- and image-level supervision, and ablate our method to show the impact of leveraging phrasal and sequential context, and techniques to improve localization of subjects and objects.
A Conversational Agent System for Dietary Supplements Use
Apr 04, 2021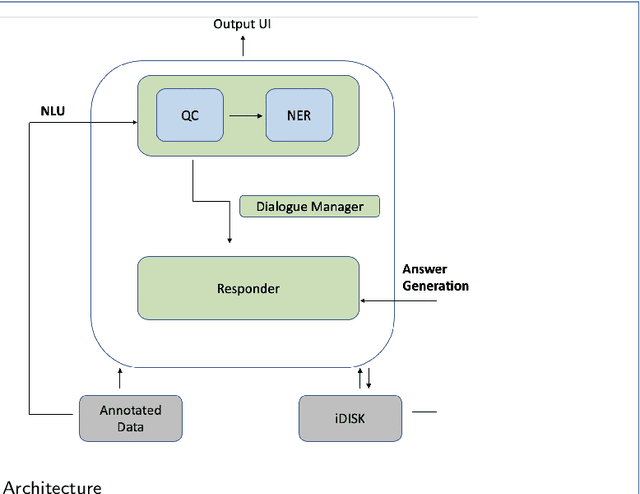

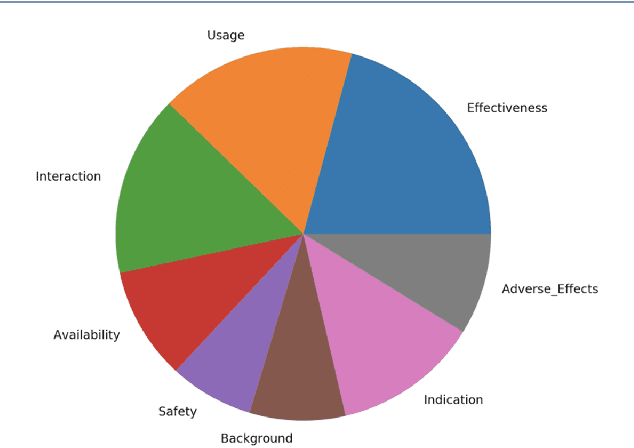
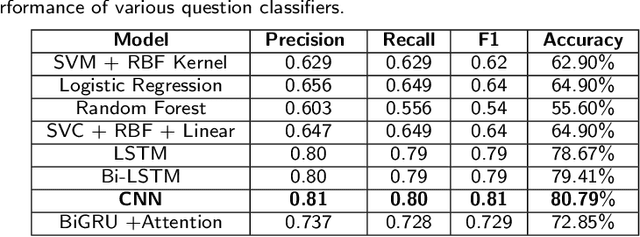
Dietary supplements (DS) have been widely used by consumers, but the information around the effectiveness and safety of DS is disparate or incomplete, making barriers to consumers to find information effectively. Conversational agent systems have been applied to the healthcare domain but there is no such a system to answer consumers regarding DS use, although widespread use of the dietary supplement. In this study, we develop the first conversational agent system for DS use.
CausalRec: Causal Inference for Visual Debiasing in Visually-Aware Recommendation
Jul 09, 2021
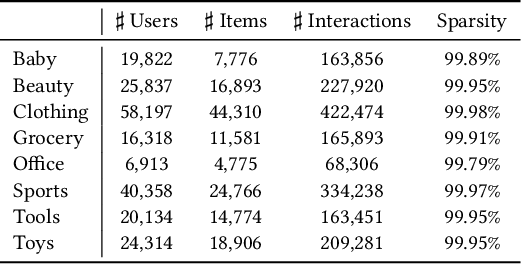
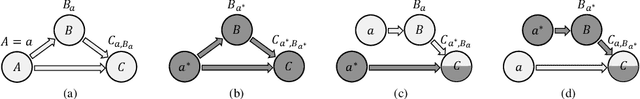
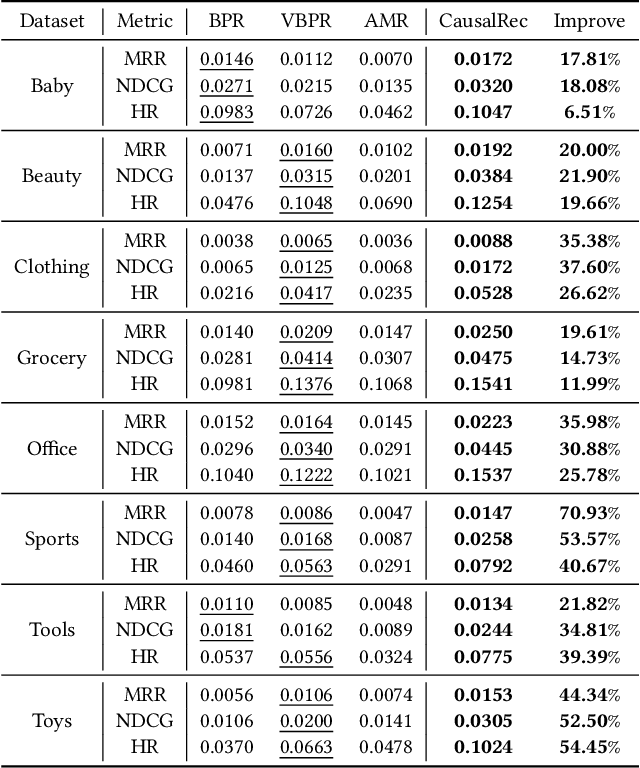
Visually-aware recommendation on E-commerce platforms aims to leverage visual information of items to predict a user's preference. It is commonly observed that user's attention to visual features does not always reflect the real preference. Although a user may click and view an item in light of a visual satisfaction of their expectations, a real purchase does not always occur due to the unsatisfaction of other essential features (e.g., brand, material, price). We refer to the reason for such a visually related interaction deviating from the real preference as a visual bias. Existing visually-aware models make use of the visual features as a separate collaborative signal similarly to other features to directly predict the user's preference without considering a potential bias, which gives rise to a visually biased recommendation. In this paper, we derive a causal graph to identify and analyze the visual bias of these existing methods. In this causal graph, the visual feature of an item acts as a mediator, which could introduce a spurious relationship between the user and the item. To eliminate this spurious relationship that misleads the prediction of the user's real preference, an intervention and a counterfactual inference are developed over the mediator. Particularly, the Total Indirect Effect is applied for a debiased prediction during the testing phase of the model. This causal inference framework is model agnostic such that it can be integrated into the existing methods. Furthermore, we propose a debiased visually-aware recommender system, denoted as CausalRec to effectively retain the supportive significance of the visual information and remove the visual bias. Extensive experiments are conducted on eight benchmark datasets, which shows the state-of-the-art performance of CausalRec and the efficacy of debiasing.