 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Surgical Instruction Generation with Transformers
Jul 14, 2021
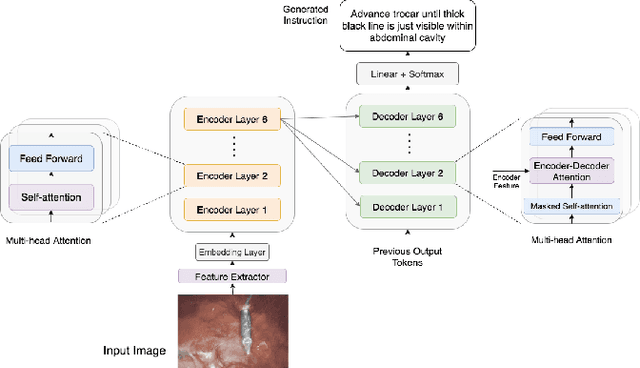
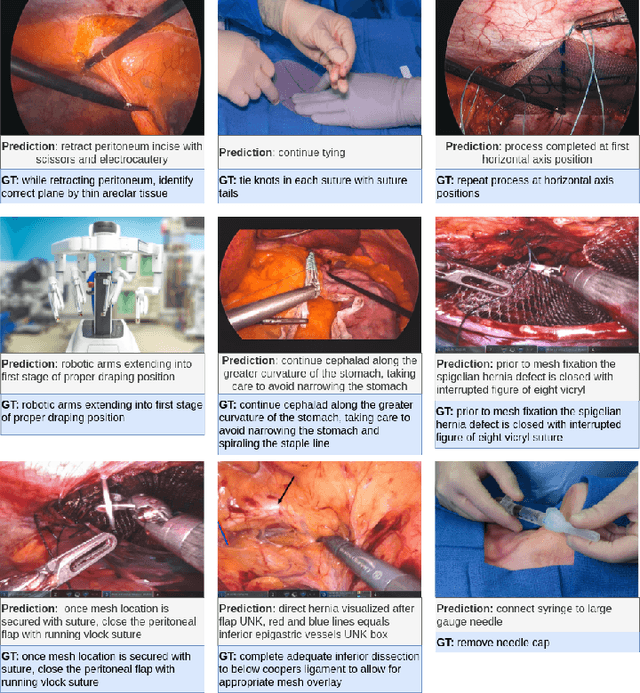
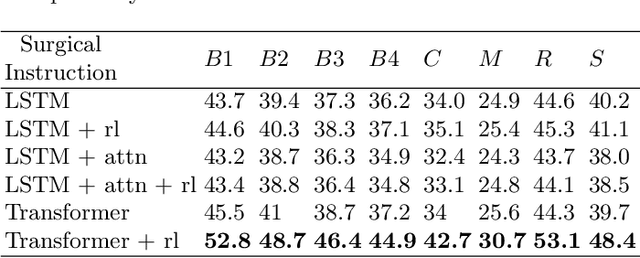
Automatic surgical instruction generation is a prerequisite towards intra-operative context-aware surgical assistance. However, generating instructions from surgical scenes is challenging, as it requires jointly understanding the surgical activity of current view and modelling relationships between visual information and textual description. Inspired by the neural machine translation and imaging captioning tasks in open domain, we introduce a transformer-backboned encoder-decoder network with self-critical reinforcement learning to generate instructions from surgical images. We evaluate the effectiveness of our method on DAISI dataset, which includes 290 procedures from various medical disciplines. Our approach outperforms the existing baseline over all caption evaluation metrics. The results demonstrate the benefits of the encoder-decoder structure backboned by transformer in handling multimodal context.
TFRD: A Benchmark Dataset for Research on Temperature Field Reconstruction of Heat-Source Systems
Aug 20, 2021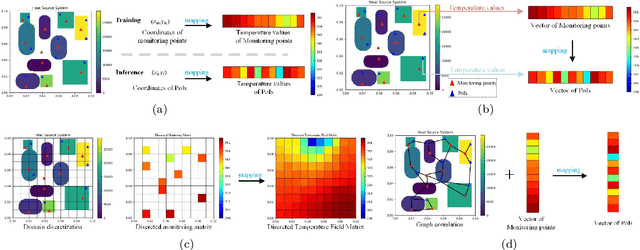
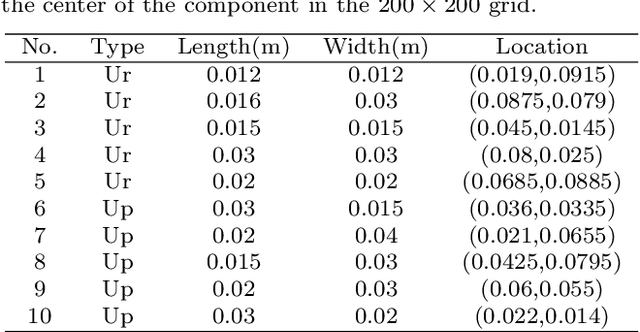
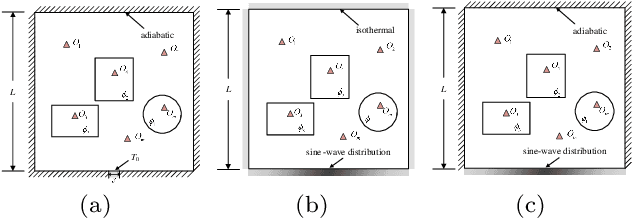
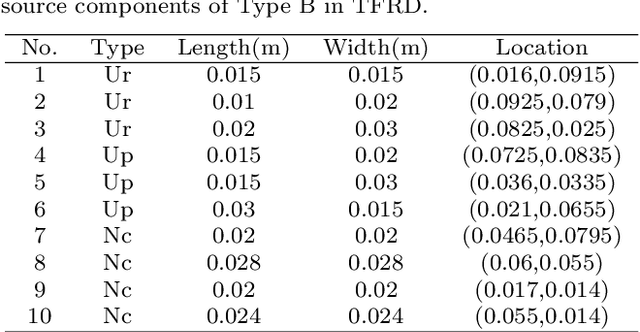
Temperature field reconstruction of heat source systems (TFR-HSS) with limited monitoring sensors occurred in thermal management plays an important role in real time health detection system of electronic equipment in engineering. However, prior methods with common interpolations usually cannot provide accurate reconstruction. In addition, there exists no public dataset for widely research of reconstruction methods to further boost the field reconstruction in engineering. To overcome this problem, this work constructs a specific dataset, namely Temperature Field Reconstruction Dataset (TFRD), for TFR-HSS task with commonly used methods, including the interpolation methods and the machine learning based methods, as baselines to advance the research over temperature field reconstruction. First, the TFR-HSS task is mathematically modelled from real-world engineering problem and four types of numerically modellings have been constructed to transform the problem into discrete mapping forms. Besides, this work selects three typical reconstruction problem over heat-source systems with different heat-source information and boundary conditions, and generate the training and testing samples for further research. Finally, a comprehensive review of the prior methods for TFR-HSS task as well as recent widely used deep learning methods is given and we provide a performance analysis of typical methods on TFRD, which can be served as the baseline results on this benchmark.
Knowledge Perceived Multi-modal Pretraining in E-commerce
Aug 20, 2021

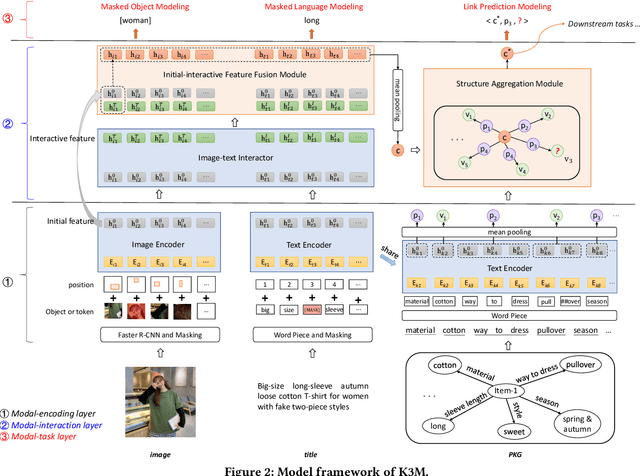
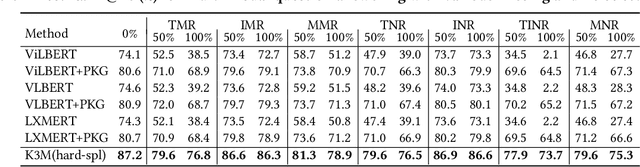
In this paper, we address multi-modal pretraining of product data in the field of E-commerce. Current multi-modal pretraining methods proposed for image and text modalities lack robustness in the face of modality-missing and modality-noise, which are two pervasive problems of multi-modal product data in real E-commerce scenarios. To this end, we propose a novel method, K3M, which introduces knowledge modality in multi-modal pretraining to correct the noise and supplement the missing of image and text modalities. The modal-encoding layer extracts the features of each modality. The modal-interaction layer is capable of effectively modeling the interaction of multiple modalities, where an initial-interactive feature fusion model is designed to maintain the independence of image modality and text modality, and a structure aggregation module is designed to fuse the information of image, text, and knowledge modalities. We pretrain K3M with three pretraining tasks, including masked object modeling (MOM), masked language modeling (MLM), and link prediction modeling (LPM). Experimental results on a real-world E-commerce dataset and a series of product-based downstream tasks demonstrate that K3M achieves significant improvements in performances than the baseline and state-of-the-art methods when modality-noise or modality-missing exists.
PKSpell: Data-Driven Pitch Spelling and Key Signature Estimation
Jul 27, 2021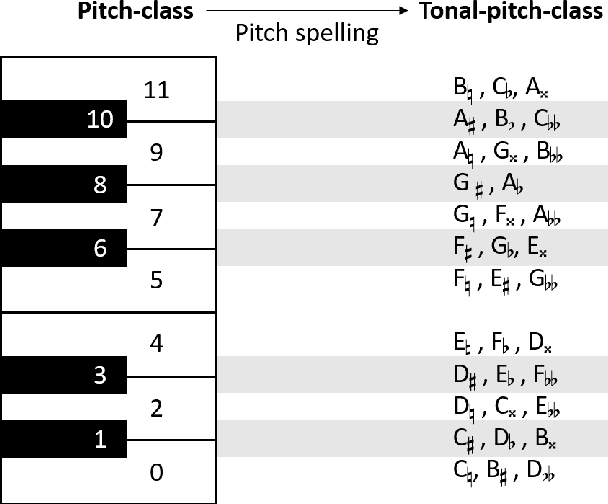
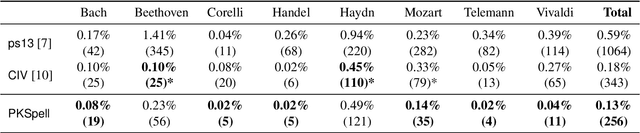

We present PKSpell: a data-driven approach for the joint estimation of pitch spelling and key signatures from MIDI files. Both elements are fundamental for the production of a full-fledged musical score and facilitate many MIR tasks such as harmonic analysis, section identification, melodic similarity, and search in a digital music library. We design a deep recurrent neural network model that only requires information readily available in all kinds of MIDI files, including performances, or other symbolic encodings. We release a model trained on the ASAP dataset. Our system can be used with these pre-trained parameters and is easy to integrate into a MIR pipeline. We also propose a data augmentation procedure that helps retraining on small datasets. PKSpell achieves strong key signature estimation performance on a challenging dataset. Most importantly, this model establishes a new state-of-the-art performance on the MuseData pitch spelling dataset without retraining.
A distillation based approach for the diagnosis of diseases
Aug 07, 2021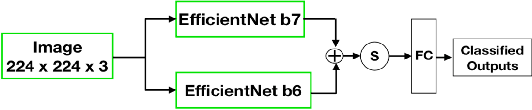
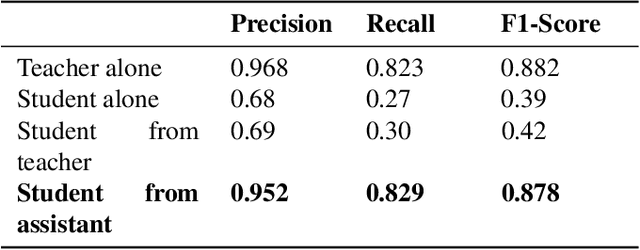
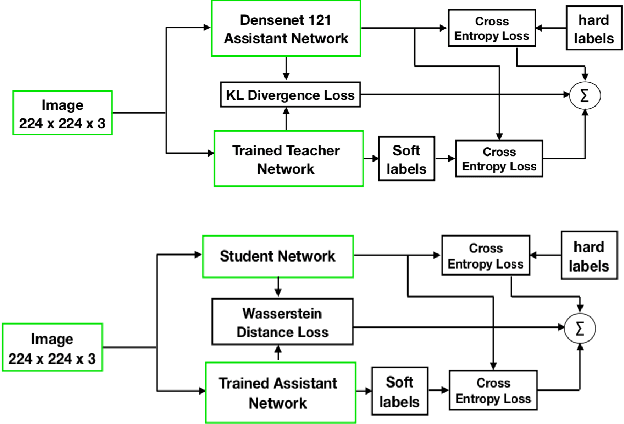
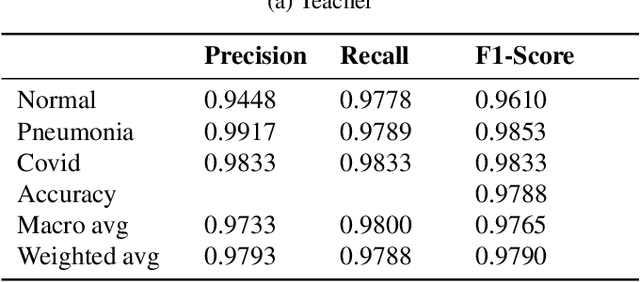
Presently, Covid-19 is a serious threat to the world at large. Efforts are being made to reduce disease screening times and in the development of a vaccine to resist this disease, even as thousands succumb to it everyday. We propose a novel method of automated screening of diseases like Covid-19 and pneumonia from Chest X-Ray images with the help of Computer Vision. Unlike computer vision classification algorithms which come with heavy computational costs, we propose a knowledge distillation based approach which allows us to bring down the model depth, while preserving the accuracy. We make use of an augmentation of the standard distillation module with an auxiliary intermediate assistant network that aids in the continuity of the flow of information. Following this approach, we are able to build an extremely light student network, consisting of just 3 convolutional blocks without any compromise on accuracy. We thus propose a method of classification of diseases which can not only lead to faster screening, but can also operate seamlessly on low-end devices.
CausalRec: Causal Inference for Visual Debiasing in Visually-Aware Recommendation
Jul 09, 2021
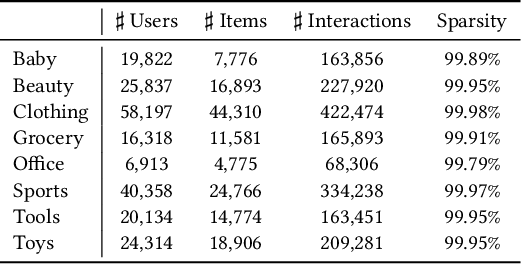
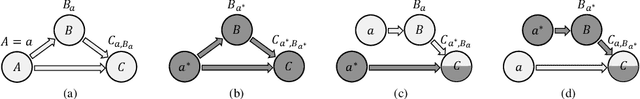
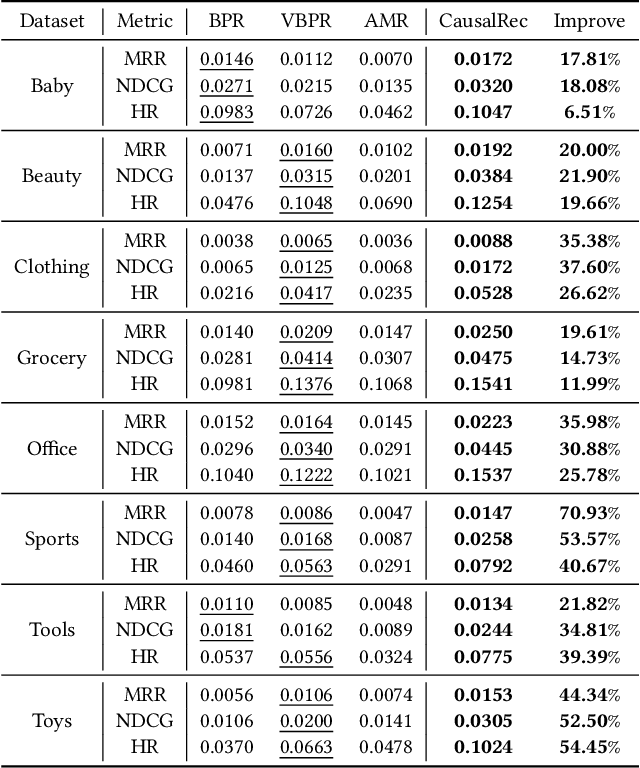
Visually-aware recommendation on E-commerce platforms aims to leverage visual information of items to predict a user's preference. It is commonly observed that user's attention to visual features does not always reflect the real preference. Although a user may click and view an item in light of a visual satisfaction of their expectations, a real purchase does not always occur due to the unsatisfaction of other essential features (e.g., brand, material, price). We refer to the reason for such a visually related interaction deviating from the real preference as a visual bias. Existing visually-aware models make use of the visual features as a separate collaborative signal similarly to other features to directly predict the user's preference without considering a potential bias, which gives rise to a visually biased recommendation. In this paper, we derive a causal graph to identify and analyze the visual bias of these existing methods. In this causal graph, the visual feature of an item acts as a mediator, which could introduce a spurious relationship between the user and the item. To eliminate this spurious relationship that misleads the prediction of the user's real preference, an intervention and a counterfactual inference are developed over the mediator. Particularly, the Total Indirect Effect is applied for a debiased prediction during the testing phase of the model. This causal inference framework is model agnostic such that it can be integrated into the existing methods. Furthermore, we propose a debiased visually-aware recommender system, denoted as CausalRec to effectively retain the supportive significance of the visual information and remove the visual bias. Extensive experiments are conducted on eight benchmark datasets, which shows the state-of-the-art performance of CausalRec and the efficacy of debiasing.
Integrated Radar Sensing and Communication-assisted Orthogonal Time Frequency Space Transmission for Vehicular Networks
May 07, 2021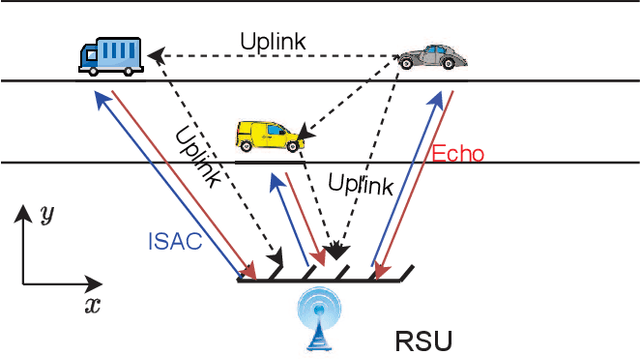
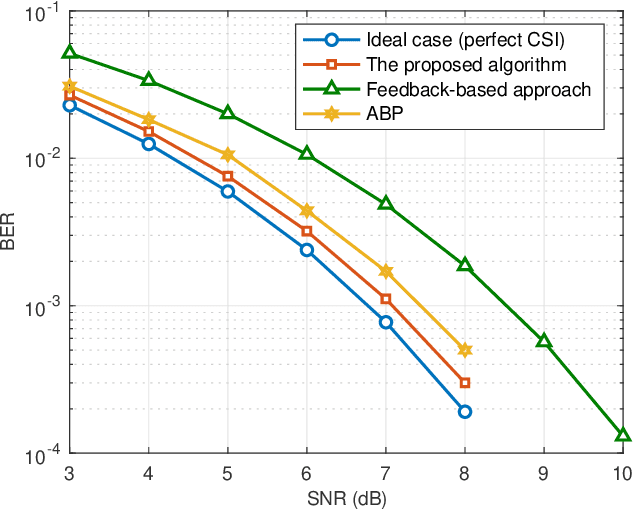
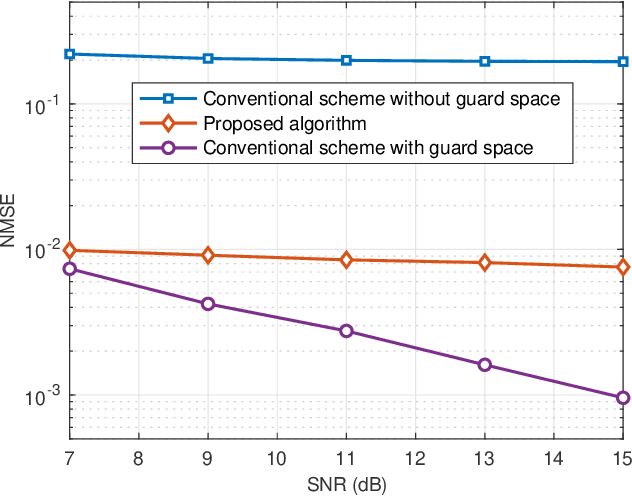
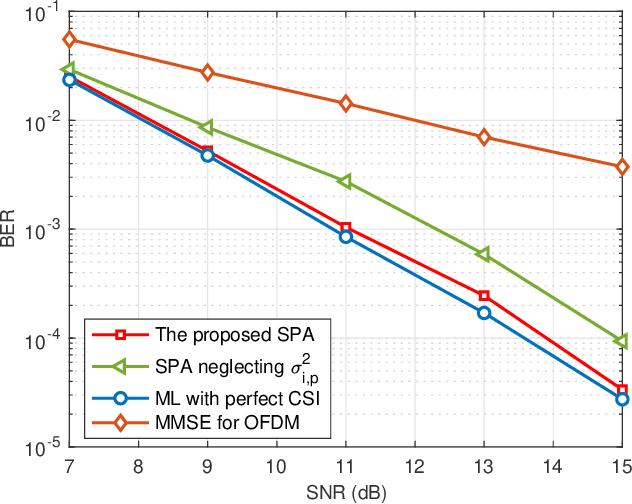
Orthogonal time frequency space (OTFS) modulation is a promising candidate for supporting reliable information transmission in high-mobility vehicular networks. In this paper, we consider the employment of the integrated (radar) sensing and communication (ISAC) technique for assisting OTFS transmission in both uplink and downlink vehicular communication systems. Benefiting from the OTFS-ISAC signals, the roadside unit (RSU) is capable of simultaneously transmitting downlink information to the vehicles and estimating the sensing parameters of vehicles, e.g., locations and speeds, based on the reflected echoes. Then, relying on the estimated kinematic parameters of vehicles, the RSU can construct the topology of the vehicular network that enables the prediction of the vehicle states in the following time instant. Consequently, the RSU can effectively formulate the transmit downlink beamformers according to the predicted parameters to counteract the channel adversity such that the vehicles can directly detect the information without the need of performing channel estimation. As for the uplink transmission, the RSU can infer the delays and Dopplers associated with different channel paths based on the aforementioned dynamic topology of the vehicular network. Thus, inserting guard space as in conventional methods are not needed for uplink channel estimation which removes the required training overhead. Finally, an efficient uplink detector is proposed by taking into account the channel estimation uncertainty. Through numerical simulations, we demonstrate the benefits of the proposed ISAC-assisted OTFS transmission scheme.
The State of Infodemic on Twitter
May 17, 2021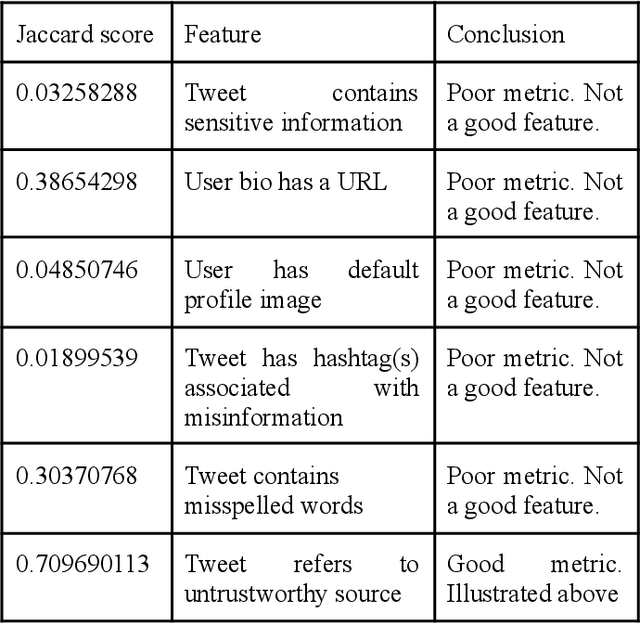
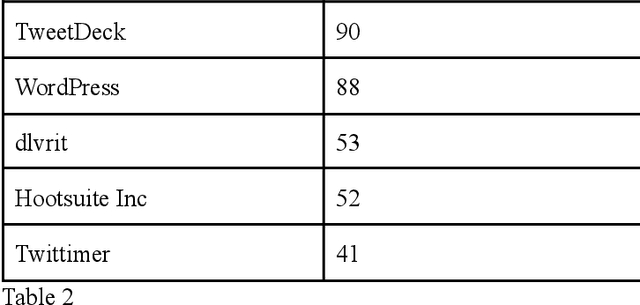
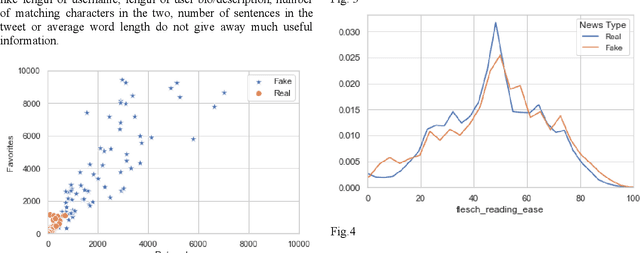
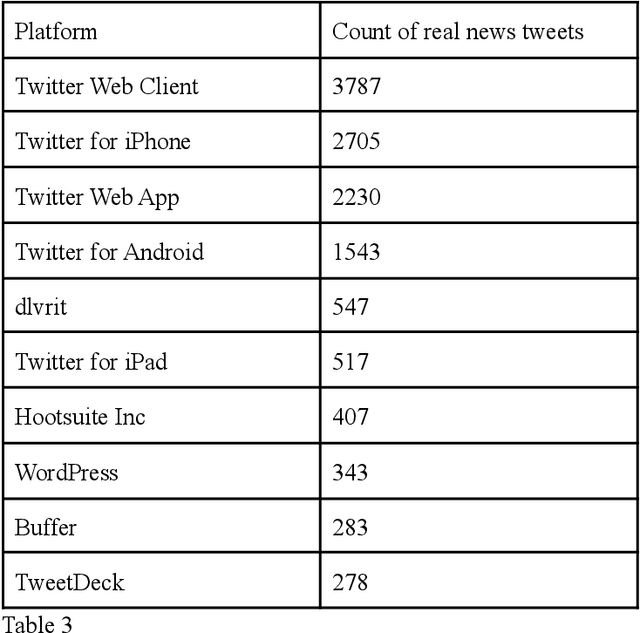
Following the wave of misinterpreted, manipulated and malicious information growing on the Internet, the misinformation surrounding COVID-19 has become a paramount issue. In the context of the current COVID-19 pandemic, social media posts and platforms are at risk of rumors and misinformation in the face of the serious uncertainty surrounding the virus itself. At the same time, the uncertainty and new nature of COVID-19 means that other unconfirmed information that may appear "rumored" may be an important indicator of the behavior and impact of this new virus. Twitter, in particular, has taken a center stage in this storm where Covid-19 has been a much talked about subject. We have presented an exploratory analysis of the tweets and the users who are involved in spreading misinformation and then delved into machine learning models and natural language processing techniques to identify if a tweet contains misinformation.
Stereo Waterdrop Removal with Row-wise Dilated Attention
Aug 07, 2021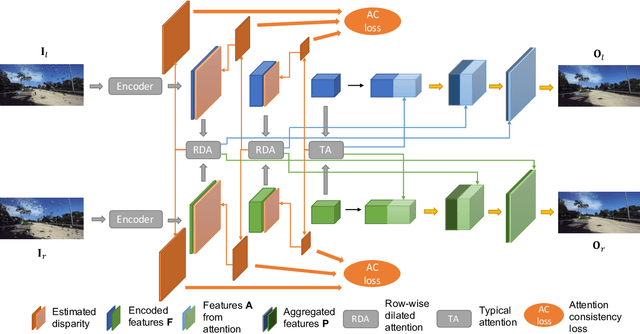
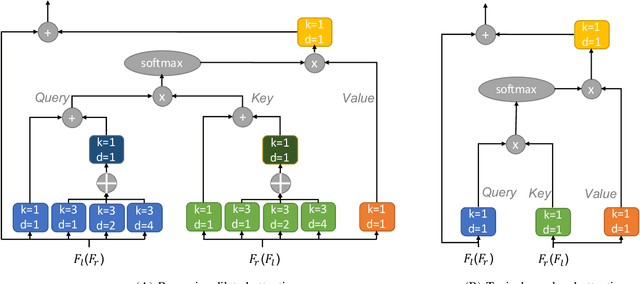


Existing vision systems for autonomous driving or robots are sensitive to waterdrops adhered to windows or camera lenses. Most recent waterdrop removal approaches take a single image as input and often fail to recover the missing content behind waterdrops faithfully. Thus, we propose a learning-based model for waterdrop removal with stereo images. To better detect and remove waterdrops from stereo images, we propose a novel row-wise dilated attention module to enlarge attention's receptive field for effective information propagation between the two stereo images. In addition, we propose an attention consistency loss between the ground-truth disparity map and attention scores to enhance the left-right consistency in stereo images. Because of related datasets' unavailability, we collect a real-world dataset that contains stereo images with and without waterdrops. Extensive experiments on our dataset suggest that our model outperforms state-of-the-art methods both quantitatively and qualitatively. Our source code and the stereo waterdrop dataset are available at \href{https://github.com/VivianSZF/Stereo-Waterdrop-Removal}{https://github.com/VivianSZF/Stereo-Waterdrop-Removal}
Did you miss it? Automatic lung nodule detection combined with gaze information improves radiologists' screening performance
Oct 09, 2019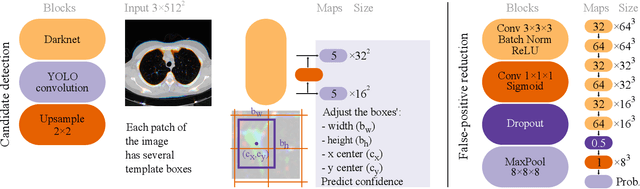
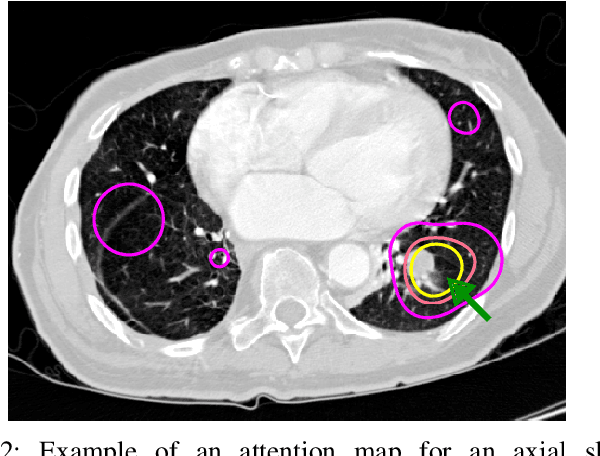
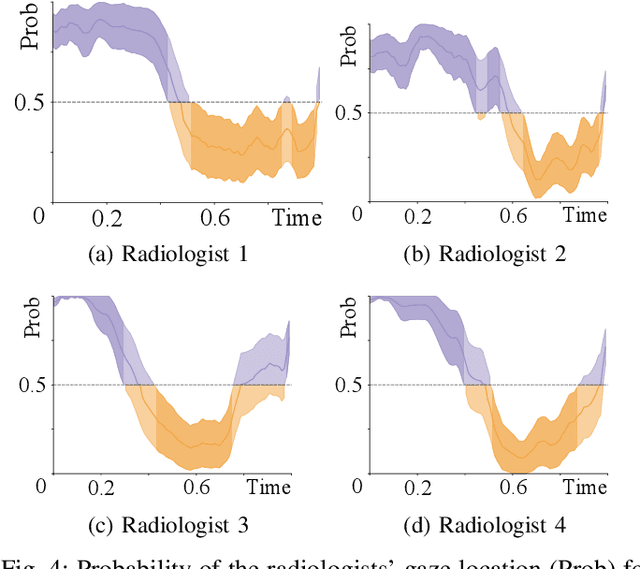
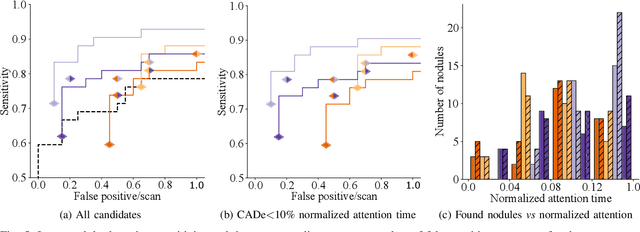
Early diagnosis of lung cancer via computed tomography can significantly reduce the morbidity and mortality rates associated with the pathology. However, search lung nodules is a high complexity task, which affects the success of screening programs. Whilst computer-aided detection systems can be used as second observers, they may bias radiologists and introduce significant time overheads. With this in mind, this study assesses the potential of using gaze information for integrating automatic detection systems in the clinical practice. For that purpose, 4 radiologists were asked to annotate 20 scans from a public dataset while being monitored by an eye tracker device and an automatic lung nodule detection system was developed. Our results show that radiologists follow a similar search routine and tend to have lower fixation periods in regions where finding errors occur. The overall detection sensitivity of the specialists was 0.67$\pm$0.07, whereas the system achieved 0.69. Combining the annotations of one radiologist with the automatic system significantly improves the detection performance to similar levels of two annotators. Likewise, combining the findings of radiologist with the detection algorithm only for low fixation regions still significantly improves the detection sensitivity without increasing the number of false-positives. The combination of the automatic system with the gaze information allows to mitigate possible errors of the radiologist without some of the issues usually associated with automatic detection system.