 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Binocular Mutual Learning for Improving Few-shot Classification
Aug 27, 2021
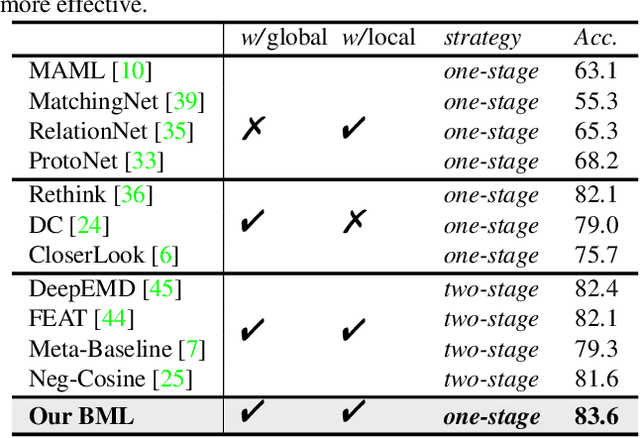
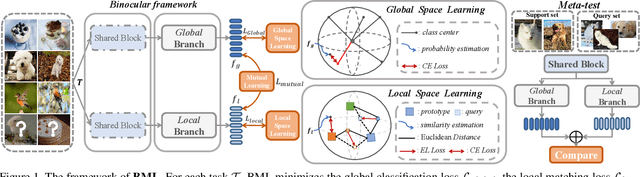
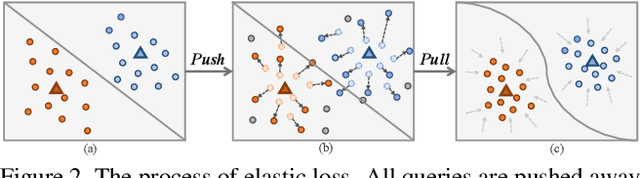
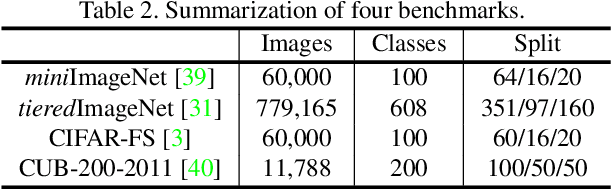
Most of the few-shot learning methods learn to transfer knowledge from datasets with abundant labeled data (i.e., the base set). From the perspective of class space on base set, existing methods either focus on utilizing all classes under a global view by normal pretraining, or pay more attention to adopt an episodic manner to train meta-tasks within few classes in a local view. However, the interaction of the two views is rarely explored. As the two views capture complementary information, we naturally think of the compatibility of them for achieving further performance gains. Inspired by the mutual learning paradigm and binocular parallax, we propose a unified framework, namely Binocular Mutual Learning (BML), which achieves the compatibility of the global view and the local view through both intra-view and cross-view modeling. Concretely, the global view learns in the whole class space to capture rich inter-class relationships. Meanwhile, the local view learns in the local class space within each episode, focusing on matching positive pairs correctly. In addition, cross-view mutual interaction further promotes the collaborative learning and the implicit exploration of useful knowledge from each other. During meta-test, binocular embeddings are aggregated together to support decision-making, which greatly improve the accuracy of classification. Extensive experiments conducted on multiple benchmarks including cross-domain validation confirm the effectiveness of our method.
Supervised Compression for Resource-constrained Edge Computing Systems
Aug 21, 2021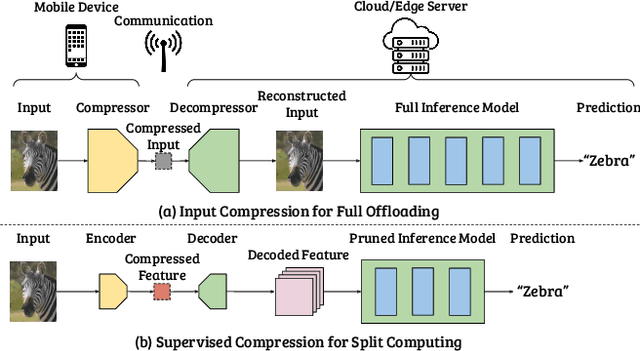
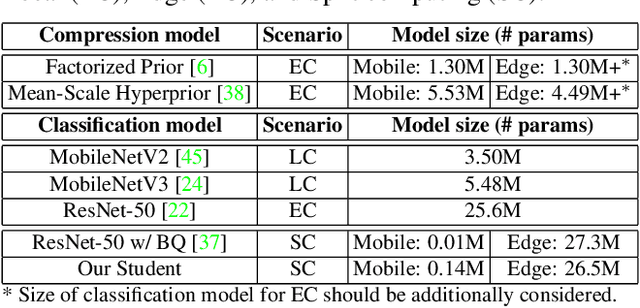
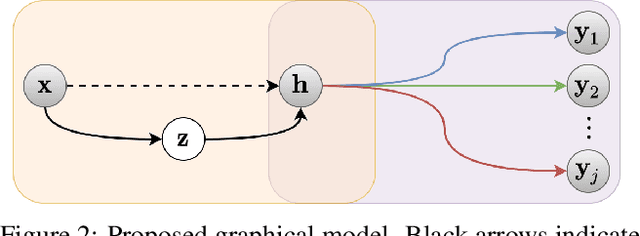
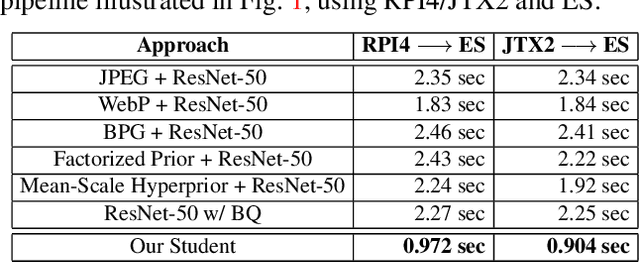
There has been much interest in deploying deep learning algorithms on low-powered devices, including smartphones, drones, and medical sensors. However, full-scale deep neural networks are often too resource-intensive in terms of energy and storage. As a result, the bulk part of the machine learning operation is therefore often carried out on an edge server, where the data is compressed and transmitted. However, compressing data (such as images) leads to transmitting information irrelevant to the supervised task. Another popular approach is to split the deep network between the device and the server while compressing intermediate features. To date, however, such split computing strategies have barely outperformed the aforementioned naive data compression baselines due to their inefficient approaches to feature compression. This paper adopts ideas from knowledge distillation and neural image compression to compress intermediate feature representations more efficiently. Our supervised compression approach uses a teacher model and a student model with a stochastic bottleneck and learnable prior for entropy coding. We compare our approach to various neural image and feature compression baselines in three vision tasks and found that it achieves better supervised rate-distortion performance while also maintaining smaller end-to-end latency. We furthermore show that the learned feature representations can be tuned to serve multiple downstream tasks.
Online Trading Models in the Forex Market Considering Transaction Costs
Jun 06, 2021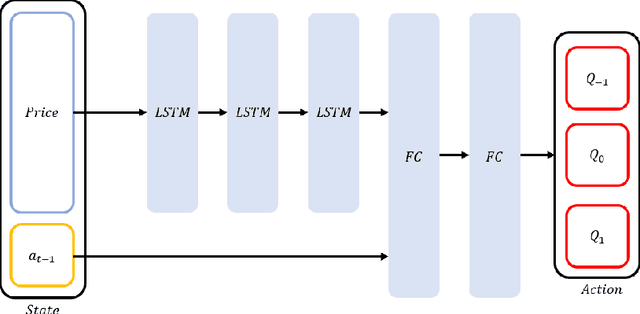
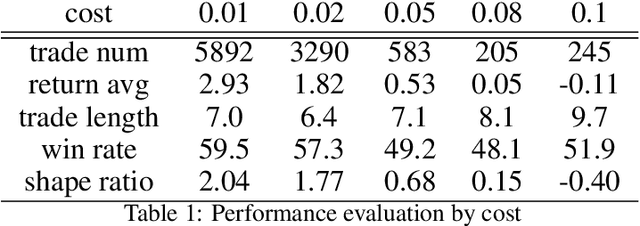
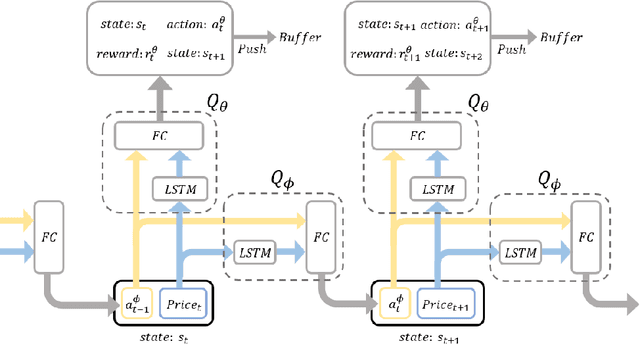

In recent years, a wide range of investment models have been created using artificial intelligence. Automatic trading by artificial intelligence can expand the range of trading methods, such as by conferring the ability to operate 24 hours a day and the ability to trade with high frequency. Automatic trading can also be expected to trade with more information than is available to humans if it can sufficiently consider past data. In this paper, we propose an investment agent based on a deep reinforcement learning model, which is an artificial intelligence model. The model considers the transaction costs involved in actual trading and creates a framework for trading over a long period of time so that it can make a large profit on a single trade. In doing so, it can maximize the profit while keeping transaction costs low. In addition, in consideration of actual operations, we use online learning so that the system can continue to learn by constantly updating the latest online data instead of learning with static data. This makes it possible to trade in non-stationary financial markets by always incorporating current market trend information.
QUBO transformation using Eigenvalue Decomposition
Jun 19, 2021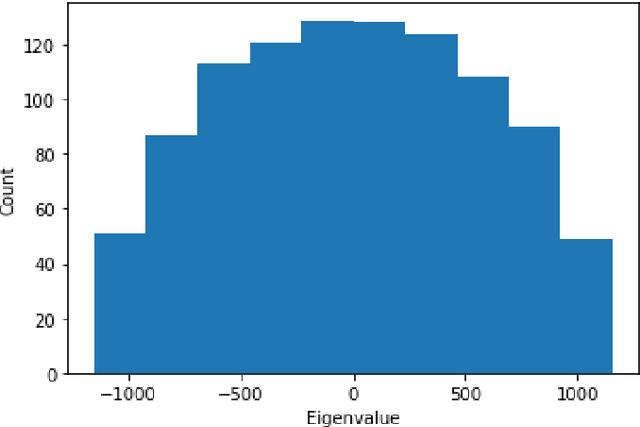
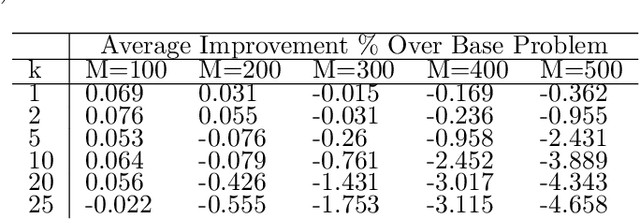
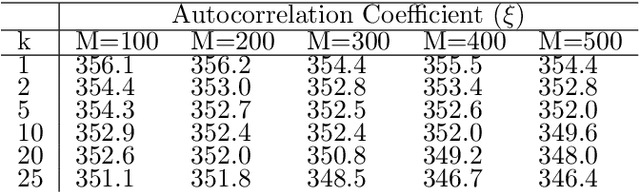
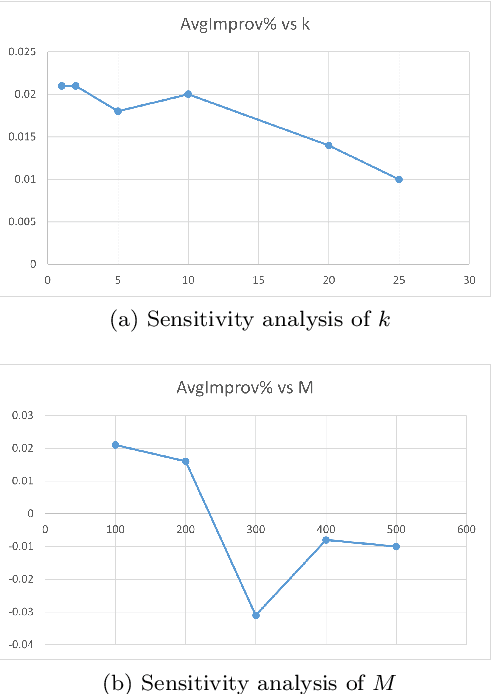
Quadratic Unconstrained Binary Optimization (QUBO) is a general-purpose modeling framework for combinatorial optimization problems and is a requirement for quantum annealers. This paper utilizes the eigenvalue decomposition of the underlying Q matrix to alter and improve the search process by extracting the information from dominant eigenvalues and eigenvectors to implicitly guide the search towards promising areas of the solution landscape. Computational results on benchmark datasets illustrate the efficacy of our routine demonstrating significant performance improvements on problems with dominant eigenvalues.
Continual learning under domain transfer with sparse synaptic bursting
Aug 26, 2021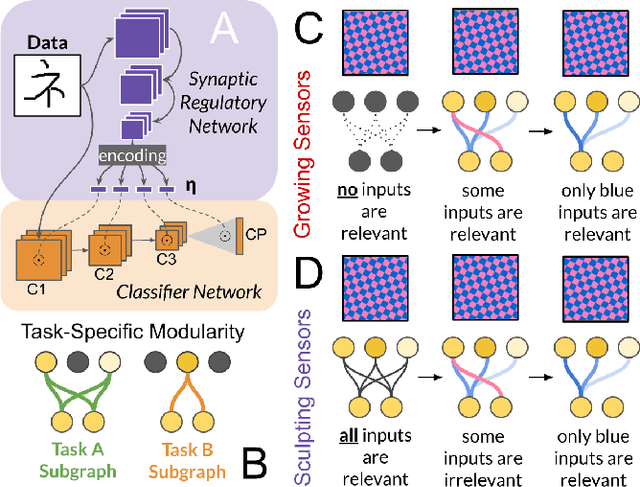
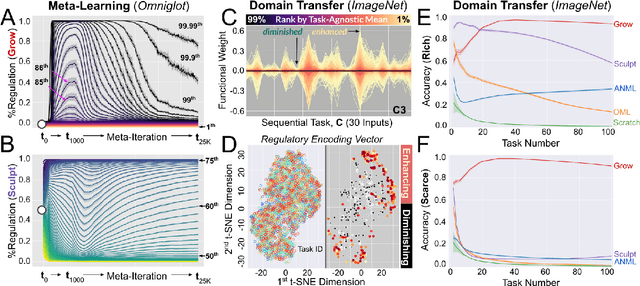
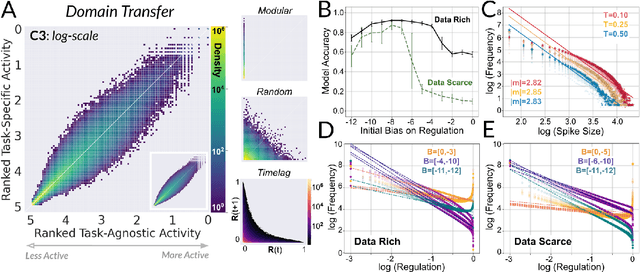
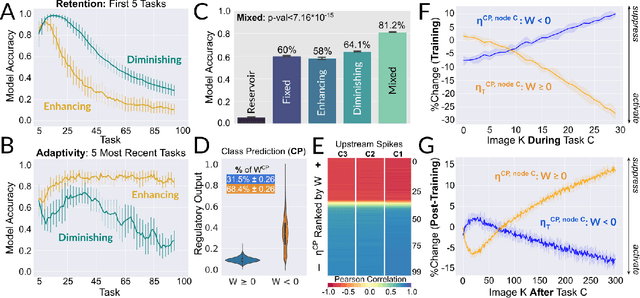
Existing machines are functionally specific tools that were made for easy prediction and control. Tomorrow's machines may be closer to biological systems in their mutability, resilience, and autonomy. But first they must be capable of learning, and retaining, new information without repeated exposure to it. Past efforts to engineer such systems have sought to build or regulate artificial neural networks using task-specific modules with constrained circumstances of application. This has not yet enabled continual learning over long sequences of previously unseen data without corrupting existing knowledge: a problem known as catastrophic forgetting. In this paper, we introduce a system that can learn sequentially over previously unseen datasets (ImageNet, CIFAR-100) with little forgetting over time. This is accomplished by regulating the activity of weights in a convolutional neural network on the basis of inputs using top-down modulation generated by a second feed-forward neural network. We find that our method learns continually under domain transfer with sparse bursts of activity in weights that are recycled across tasks, rather than by maintaining task-specific modules. Sparse synaptic bursting is found to balance enhanced and diminished activity in a way that facilitates adaptation to new inputs without corrupting previously acquired functions. This behavior emerges during a prior meta-learning phase in which regulated synapses are selectively disinhibited, or grown, from an initial state of uniform suppression.
Federated Reconnaissance: Efficient, Distributed, Class-Incremental Learning
Sep 01, 2021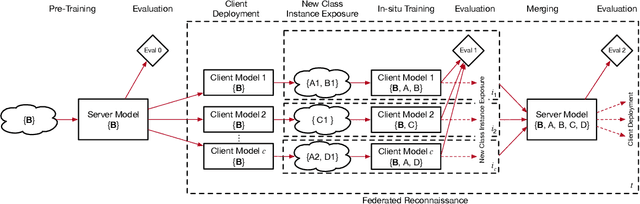
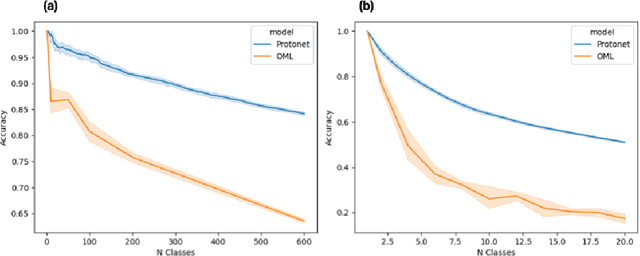
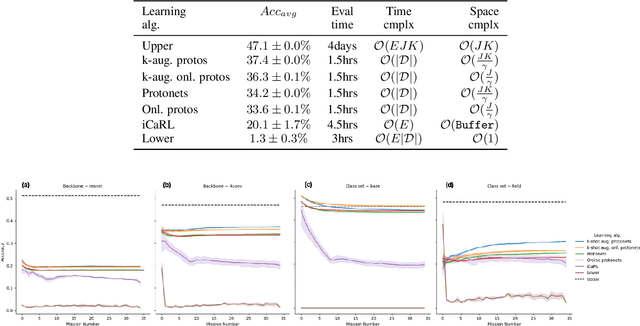
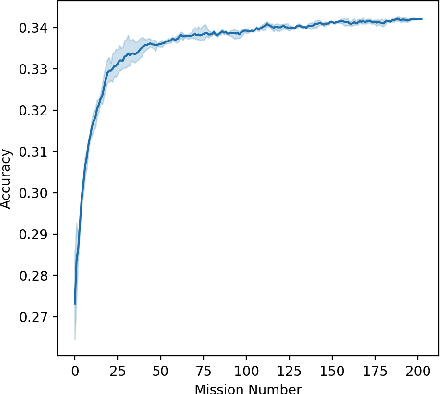
We describe federated reconnaissance, a class of learning problems in which distributed clients learn new concepts independently and communicate that knowledge efficiently. In particular, we propose an evaluation framework and methodological baseline for a system in which each client is expected to learn a growing set of classes and communicate knowledge of those classes efficiently with other clients, such that, after knowledge merging, the clients should be able to accurately discriminate between classes in the superset of classes observed by the set of clients. We compare a range of learning algorithms for this problem and find that prototypical networks are a strong approach in that they are robust to catastrophic forgetting while incorporating new information efficiently. Furthermore, we show that the online averaging of prototype vectors is effective for client model merging and requires only a small amount of communication overhead, memory, and update time per class with no gradient-based learning or hyperparameter tuning. Additionally, to put our results in context, we find that a simple, prototypical network with four convolutional layers significantly outperforms complex, state of the art continual learning algorithms, increasing the accuracy by over 22% after learning 600 Omniglot classes and over 33% after learning 20 mini-ImageNet classes incrementally. These results have important implications for federated reconnaissance and continual learning more generally by demonstrating that communicating feature vectors is an efficient, robust, and effective means for distributed, continual learning.
Whose Opinions Matter? Perspective-aware Models to Identify Opinions of Hate Speech Victims in Abusive Language Detection
Jun 30, 2021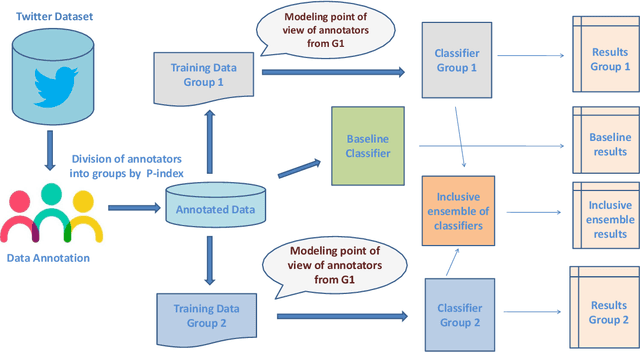
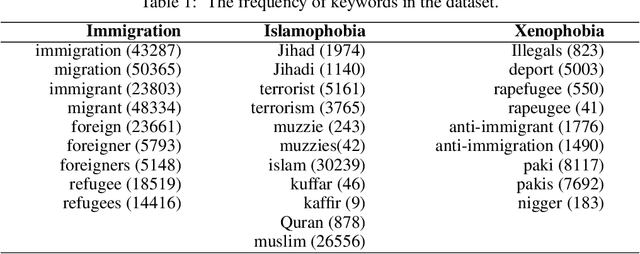
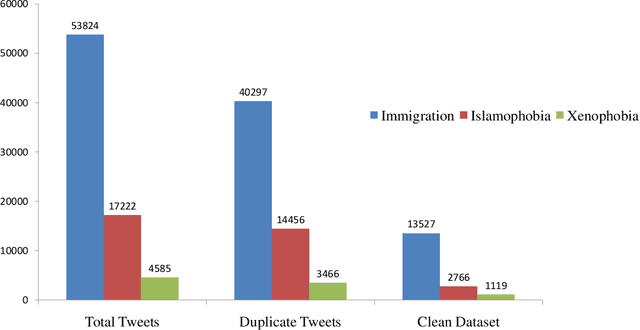

Social media platforms provide users the freedom of expression and a medium to exchange information and express diverse opinions. Unfortunately, this has also resulted in the growth of abusive content with the purpose of discriminating people and targeting the most vulnerable communities such as immigrants, LGBT, Muslims, Jews and women. Because abusive language is subjective in nature, there might be highly polarizing topics or events involved in the annotation of abusive contents such as hate speech (HS). Therefore, we need novel approaches to model conflicting perspectives and opinions coming from people with different personal and demographic backgrounds. In this paper, we present an in-depth study to model polarized opinions coming from different communities under the hypothesis that similar characteristics (ethnicity, social background, culture etc.) can influence the perspectives of annotators on a certain phenomenon. We believe that by relying on this information, we can divide the annotators into groups sharing similar perspectives. We can create separate gold standards, one for each group, to train state-of-the-art deep learning models. We can employ an ensemble approach to combine the perspective-aware classifiers from different groups to an inclusive model. We also propose a novel resource, a multi-perspective English language dataset annotated according to different sub-categories relevant for characterising online abuse: hate speech, aggressiveness, offensiveness and stereotype. By training state-of-the-art deep learning models on this novel resource, we show how our approach improves the prediction performance of a state-of-the-art supervised classifier.
Learn-Explain-Reinforce: Counterfactual Reasoning and Its Guidance to Reinforce an Alzheimer's Disease Diagnosis Model
Aug 21, 2021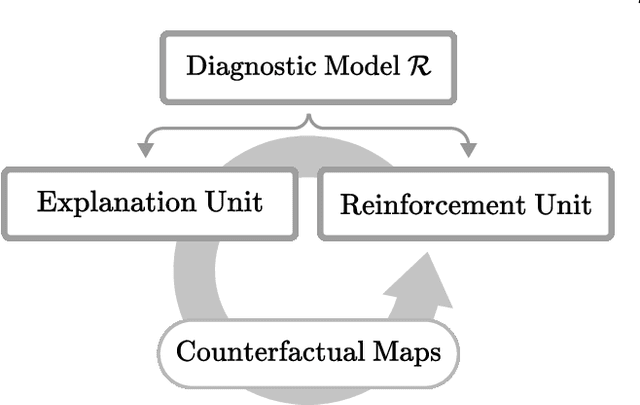
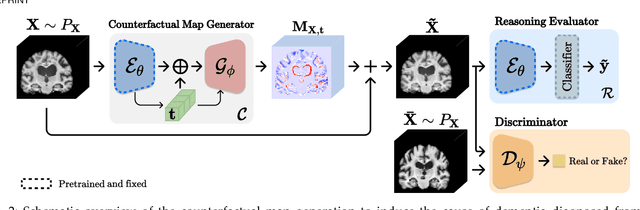
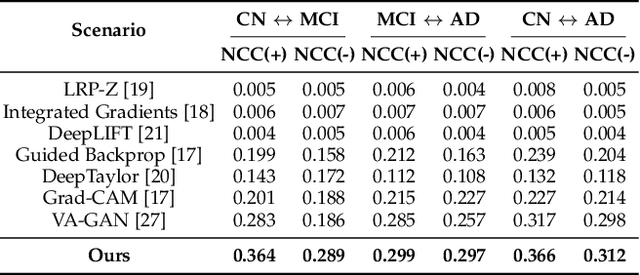
Existing studies on disease diagnostic models focus either on diagnostic model learning for performance improvement or on the visual explanation of a trained diagnostic model. We propose a novel learn-explain-reinforce (LEAR) framework that unifies diagnostic model learning, visual explanation generation (explanation unit), and trained diagnostic model reinforcement (reinforcement unit) guided by the visual explanation. For the visual explanation, we generate a counterfactual map that transforms an input sample to be identified as an intended target label. For example, a counterfactual map can localize hypothetical abnormalities within a normal brain image that may cause it to be diagnosed with Alzheimer's disease (AD). We believe that the generated counterfactual maps represent data-driven and model-induced knowledge about a target task, i.e., AD diagnosis using structural MRI, which can be a vital source of information to reinforce the generalization of the trained diagnostic model. To this end, we devise an attention-based feature refinement module with the guidance of the counterfactual maps. The explanation and reinforcement units are reciprocal and can be operated iteratively. Our proposed approach was validated via qualitative and quantitative analysis on the ADNI dataset. Its comprehensibility and fidelity were demonstrated through ablation studies and comparisons with existing methods.
Data Hiding with Deep Learning: A Survey Unifying Digital Watermarking and Steganography
Jul 20, 2021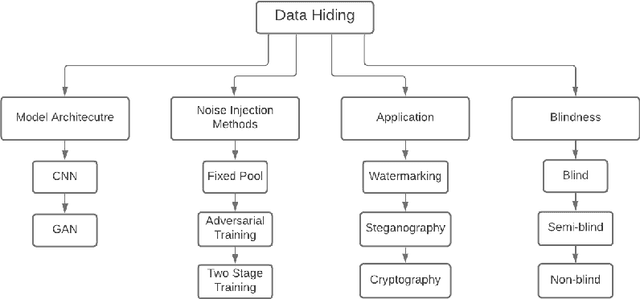
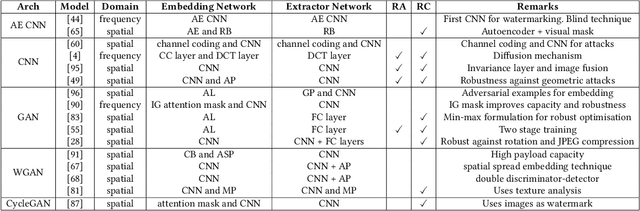
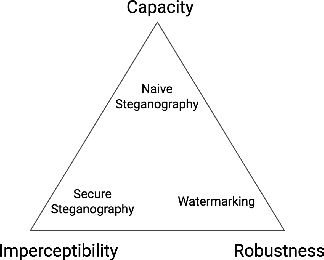
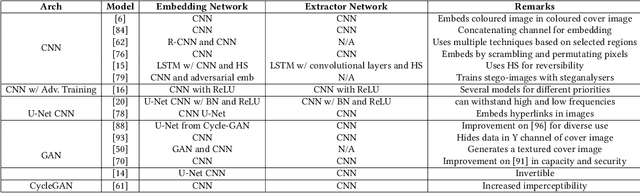
Data hiding is the process of embedding information into a noise-tolerant signal such as a piece of audio, video, or image. Digital watermarking is a form of data hiding where identifying data is robustly embedded so that it can resist tampering and be used to identify the original owners of the media. Steganography, another form of data hiding, embeds data for the purpose of secure and secret communication. This survey summarises recent developments in deep learning techniques for data hiding for the purposes of watermarking and steganography, categorising them based on model architectures and noise injection methods. The objective functions, evaluation metrics, and datasets used for training these data hiding models are comprehensively summarised. Finally, we propose and discuss possible future directions for research into deep data hiding techniques.
Deep Dual Support Vector Data Description for Anomaly Detection on Attributed Networks
Sep 01, 2021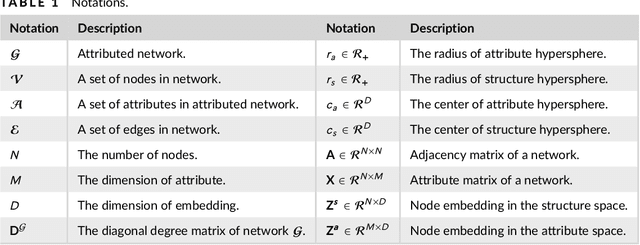
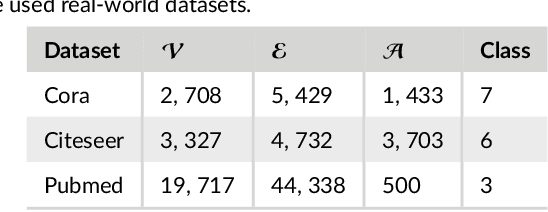
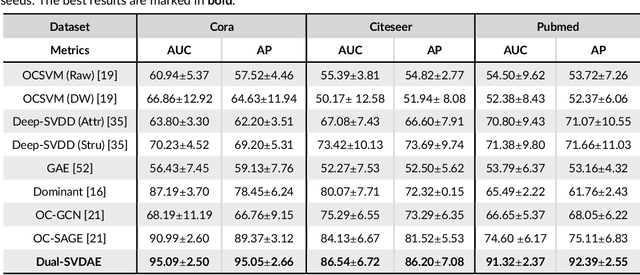
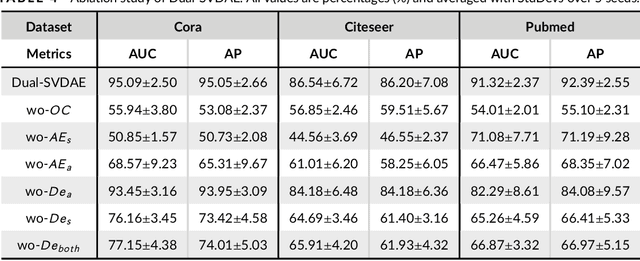
Networks are ubiquitous in the real world such as social networks and communication networks, and anomaly detection on networks aims at finding nodes whose structural or attributed patterns deviate significantly from the majority of reference nodes. However, most of the traditional anomaly detection methods neglect the relation structure information among data points and therefore cannot effectively generalize to the graph structure data. In this paper, we propose an end-to-end model of Deep Dual Support Vector Data description based Autoencoder (Dual-SVDAE) for anomaly detection on attributed networks, which considers both the structure and attribute for attributed networks. Specifically, Dual-SVDAE consists of a structure autoencoder and an attribute autoencoder to learn the latent representation of the node in the structure space and attribute space respectively. Then, a dual-hypersphere learning mechanism is imposed on them to learn two hyperspheres of normal nodes from the structure and attribute perspectives respectively. Moreover, to achieve joint learning between the structure and attribute of the network, we fuse the structure embedding and attribute embedding as the final input of the feature decoder to generate the node attribute. Finally, abnormal nodes can be detected by measuring the distance of nodes to the learned center of each hypersphere in the latent structure space and attribute space respectively. Extensive experiments on the real-world attributed networks show that Dual-SVDAE consistently outperforms the state-of-the-arts, which demonstrates the effectiveness of the proposed method.