 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Measuring the Impact of Blockchain and Smart Contract on Construction Supply Chain Visibility
Apr 15, 2021
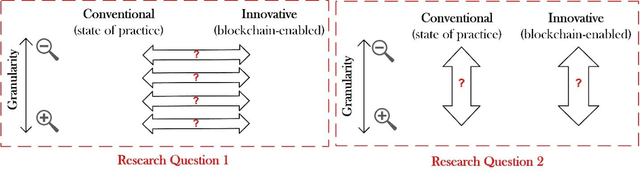

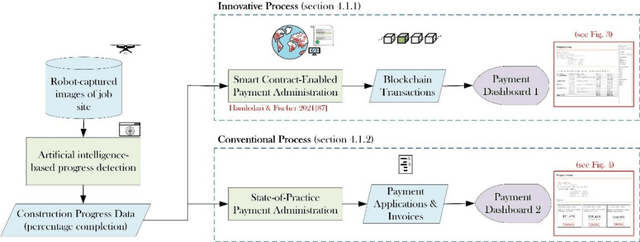

This work assesses the impact of blockchain and smart contract on the visibility of construction supply chain and in the context of payments (intersection of cash and product flows). It uses comparative empirical experiments (Charrette Test Method) to draw comparisons between the visibility of state-of-practice and blockchain-enabled payment systems in a commercial construction project. Comparisons were drawn across four levels of granularity. The findings are twofold: 1) blockchain improved information completeness and information accuracy respectively by an average 216% and 261% compared with the digital state-of-practice solution. The improvements were significantly more pronounced for inquiries that had higher product, trade, and temporal granularity; 2) blockchain-enabled solution was robust in the face of increased granularity, while the conventional solution experienced 50% and 66.7% decline respectively in completeness and accuracy of information. The paper concludes with a discussion of mechanisms contributing to visibility and technology adoption based on business objectives.
TFRD: A Benchmark Dataset for Research on Temperature Field Reconstruction of Heat-Source Systems
Aug 28, 2021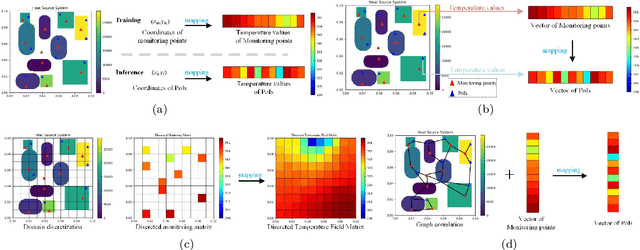
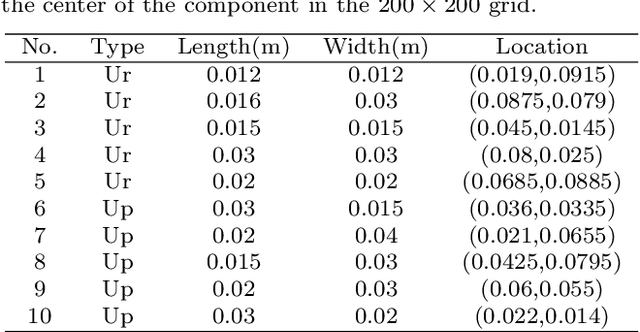
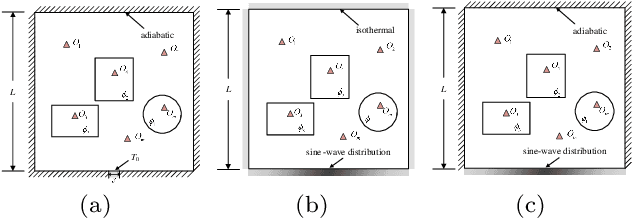
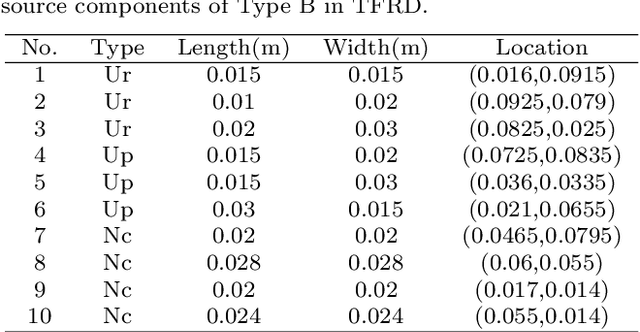
Temperature field reconstruction of heat source systems (TFR-HSS) with limited monitoring sensors occurred in thermal management plays an important role in real time health detection system of electronic equipment in engineering. However, prior methods with common interpolations usually cannot provide accurate reconstruction performance as needed. In addition, there exists no public dataset for widely research of reconstruction methods to further boost the reconstruction performance and engineering applications. To overcome this problem, this work constructs a novel dataset, namely Temperature Field Reconstruction Dataset (TFRD), for TFR-HSS task with commonly used methods, including the interpolation methods and the machine learning based methods, as baselines to advance the research over temperature field reconstruction. First, the TFR-HSS task is mathematically modelled from real-world engineering problem and four types of numerically modellings have been constructed to transform the problem into discrete mapping forms. Besides, this work selects three typical reconstruction problem over heat-source systems with different heat-source information and boundary conditions, and generate the training and testing samples for further research. Finally, a comprehensive review of the prior methods for TFR-HSS task as well as recent widely used deep learning methods is given and a performance analysis of typical methods is provided on TFRD, which can be served as the baseline results on this benchmark.
ROSITA: Enhancing Vision-and-Language Semantic Alignments via Cross- and Intra-modal Knowledge Integration
Aug 16, 2021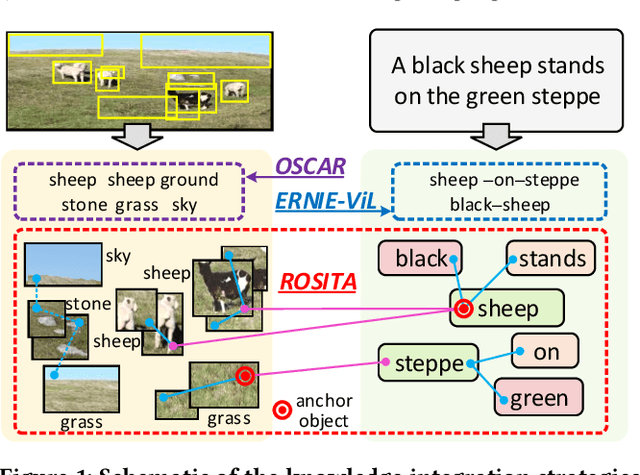
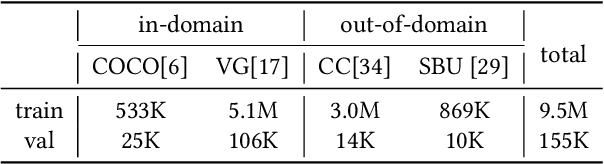
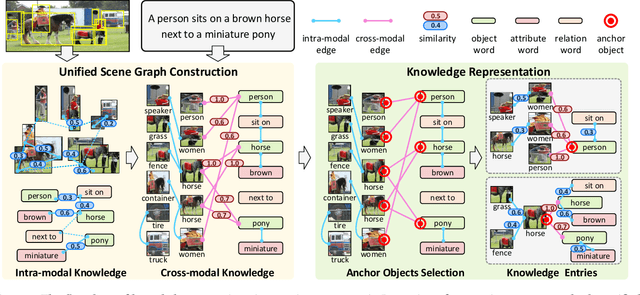
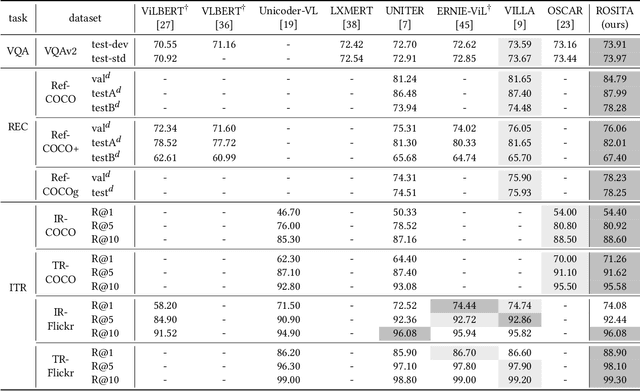
Vision-and-language pretraining (VLP) aims to learn generic multimodal representations from massive image-text pairs. While various successful attempts have been proposed, learning fine-grained semantic alignments between image-text pairs plays a key role in their approaches. Nevertheless, most existing VLP approaches have not fully utilized the intrinsic knowledge within the image-text pairs, which limits the effectiveness of the learned alignments and further restricts the performance of their models. To this end, we introduce a new VLP method called ROSITA, which integrates the cross- and intra-modal knowledge in a unified scene graph to enhance the semantic alignments. Specifically, we introduce a novel structural knowledge masking (SKM) strategy to use the scene graph structure as a priori to perform masked language (region) modeling, which enhances the semantic alignments by eliminating the interference information within and across modalities. Extensive ablation studies and comprehensive analysis verifies the effectiveness of ROSITA in semantic alignments. Pretrained with both in-domain and out-of-domain datasets, ROSITA significantly outperforms existing state-of-the-art VLP methods on three typical vision-and-language tasks over six benchmark datasets.
Forster Decomposition and Learning Halfspaces with Noise
Jul 12, 2021A Forster transform is an operation that turns a distribution into one with good anti-concentration properties. While a Forster transform does not always exist, we show that any distribution can be efficiently decomposed as a disjoint mixture of few distributions for which a Forster transform exists and can be computed efficiently. As the main application of this result, we obtain the first polynomial-time algorithm for distribution-independent PAC learning of halfspaces in the Massart noise model with strongly polynomial sample complexity, i.e., independent of the bit complexity of the examples. Previous algorithms for this learning problem incurred sample complexity scaling polynomially with the bit complexity, even though such a dependence is not information-theoretically necessary.
Exploiting Sentence-Level Representations for Passage Ranking
Jun 14, 2021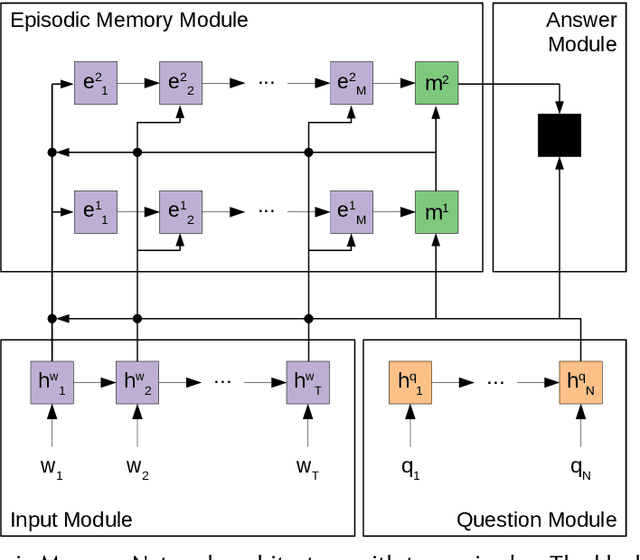
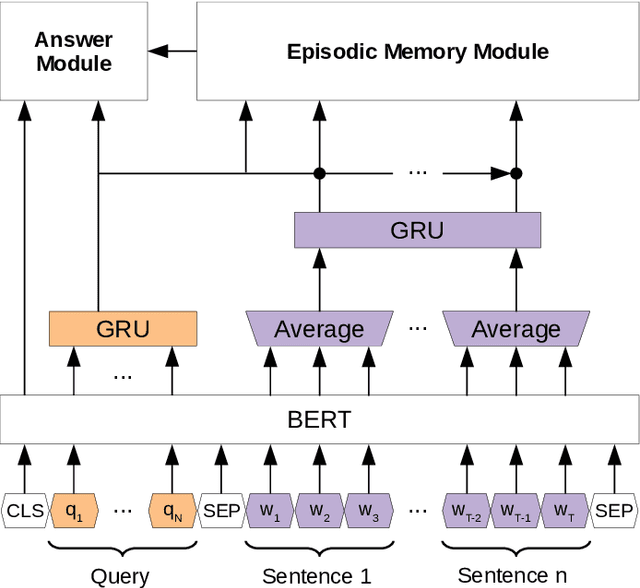
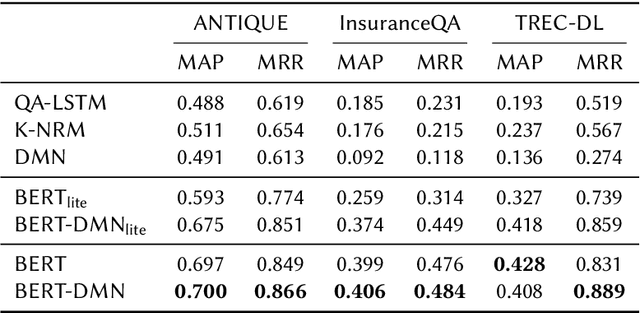
Recently, pre-trained contextual models, such as BERT, have shown to perform well in language related tasks. We revisit the design decisions that govern the applicability of these models for the passage re-ranking task in open-domain question answering. We find that common approaches in the literature rely on fine-tuning a pre-trained BERT model and using a single, global representation of the input, discarding useful fine-grained relevance signals in token- or sentence-level representations. We argue that these discarded tokens hold useful information that can be leveraged. In this paper, we explicitly model the sentence-level representations by using Dynamic Memory Networks (DMNs) and conduct empirical evaluation to show improvements in passage re-ranking over fine-tuned vanilla BERT models by memory-enhanced explicit sentence modelling on a diverse set of open-domain QA datasets. We further show that freezing the BERT model and only training the DMN layer still comes close to the original performance, while improving training efficiency drastically. This indicates that the usual fine-tuning step mostly helps to aggregate the inherent information in a single output token, as opposed to adapting the whole model to the new task, and only achieves rather small gains.
Cold Start Similar Artists Ranking with Gravity-Inspired Graph Autoencoders
Aug 02, 2021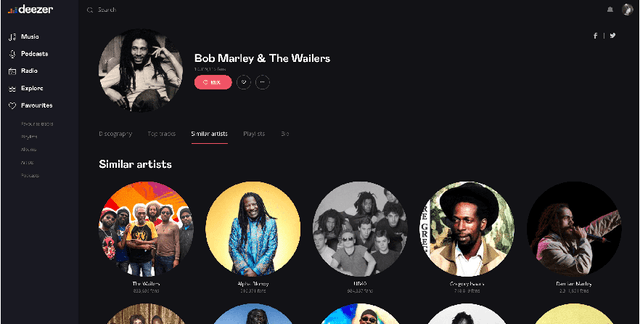
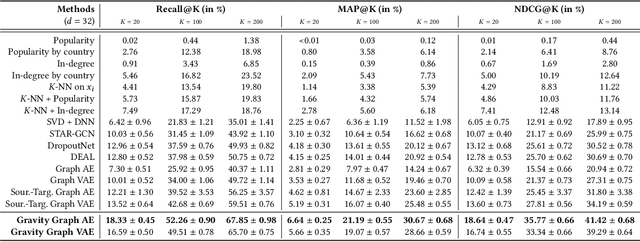
On an artist's profile page, music streaming services frequently recommend a ranked list of "similar artists" that fans also liked. However, implementing such a feature is challenging for new artists, for which usage data on the service (e.g. streams or likes) is not yet available. In this paper, we model this cold start similar artists ranking problem as a link prediction task in a directed and attributed graph, connecting artists to their top-k most similar neighbors and incorporating side musical information. Then, we leverage a graph autoencoder architecture to learn node embedding representations from this graph, and to automatically rank the top-k most similar neighbors of new artists using a gravity-inspired mechanism. We empirically show the flexibility and the effectiveness of our framework, by addressing a real-world cold start similar artists ranking problem on a global music streaming service. Along with this paper, we also publicly release our source code as well as the industrial graph data from our experiments.
Large-scale quantum machine learning
Aug 02, 2021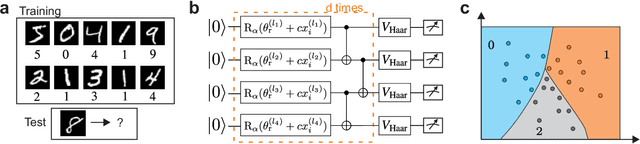
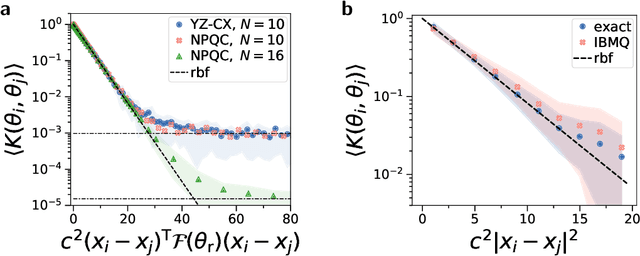
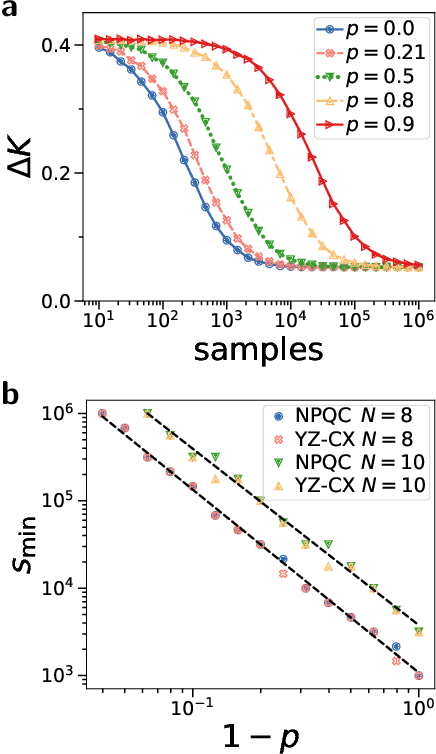
Quantum computers promise to enhance machine learning for practical applications. Quantum machine learning for real-world data has to handle extensive amounts of high-dimensional data. However, conventional methods for measuring quantum kernels are impractical for large datasets as they scale with the square of the dataset size. Here, we measure quantum kernels using randomized measurements to gain a quadratic speedup in computation time and quickly process large datasets. Further, we efficiently encode high-dimensional data into quantum computers with the number of features scaling linearly with the circuit depth. The encoding is characterized by the quantum Fisher information metric and is related to the radial basis function kernel. We demonstrate the advantages and speedups of our methods by classifying images with the IBM quantum computer. Our approach is exceptionally robust to noise via a complementary error mitigation scheme. Using currently available quantum computers, the MNIST database can be processed within 220 hours instead of 10 years which opens up industrial applications of quantum machine learning.
Using Large Pre-Trained Models with Cross-Modal Attention for Multi-Modal Emotion Recognition
Aug 22, 2021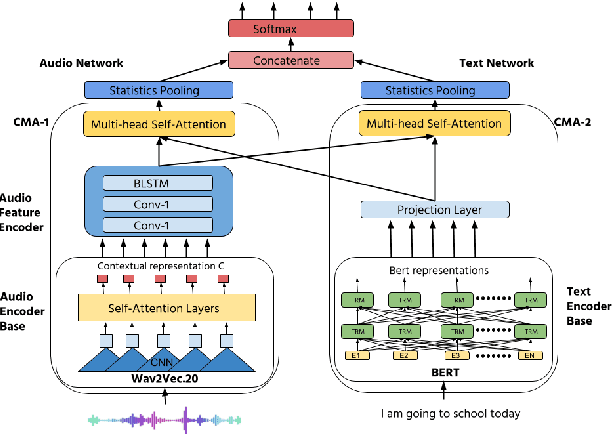
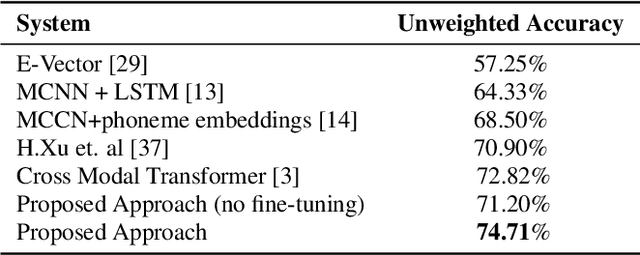
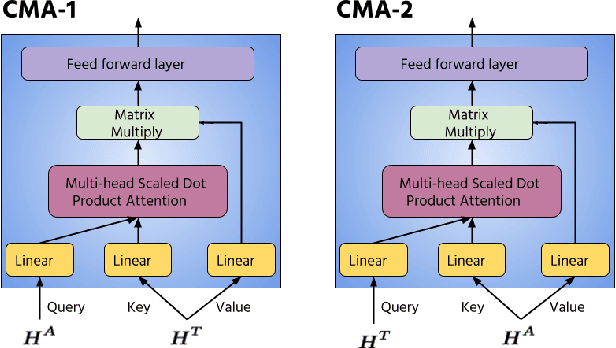
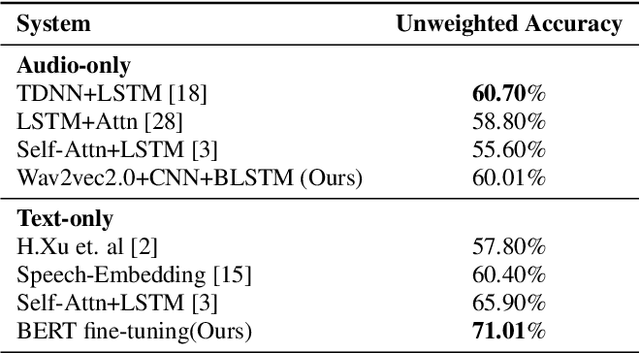
Recently, self-supervised pre-training has shown significant improvements in many areas of machine learning, including speech and NLP. We propose using large self-supervised pre-trained models for both audio and text modality with cross-modality attention for multimodal emotion recognition. We use Wav2Vec2.0 [1] as an audio encoder base for robust speech features extraction and the BERT model [2] as a text encoder base for better contextual representation of text. These high capacity models trained on large amounts of unlabeled data contain rich feature representations and improve the downstream task's performance. We use the cross-modal attention [3] mechanism to learn alignment between audio and text representations from self-supervised models. Cross-modal attention also helps in extracting interactive information between audio and text features. We obtain utterance-level feature representation from frame-level features using statistics pooling for both audio and text modality and combine them using the early fusion technique. Our experiments show that the proposed approach obtains a 1.88% absolute improvement in accuracy compared to the previous state-of-the-art method [3] on the IEMOCAP dataset [35]. We also conduct unimodal experiments for both audio and text modalities and compare them with previous best methods.
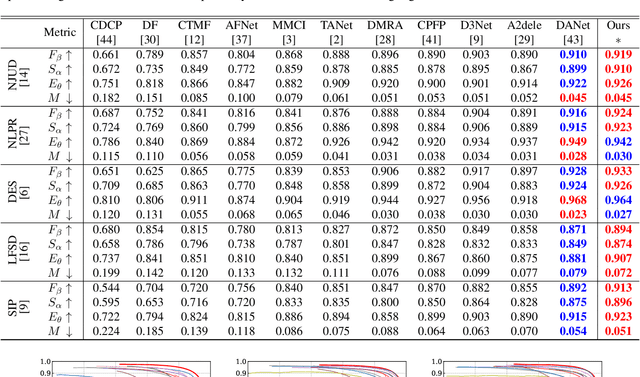
MTNet: A Multi-Task Neural Network for On-Field Calibration of Low-Cost Air Monitoring Sensors
May 10, 2021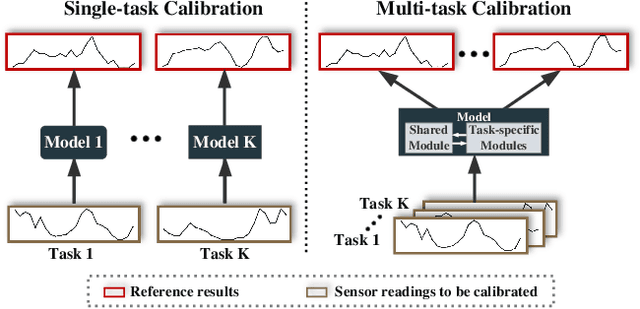
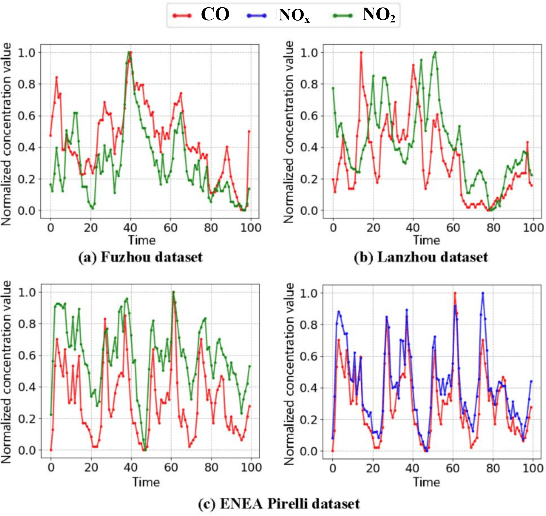
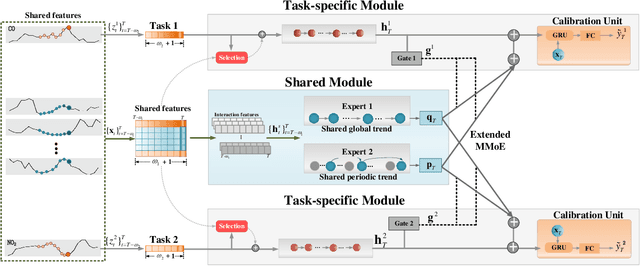
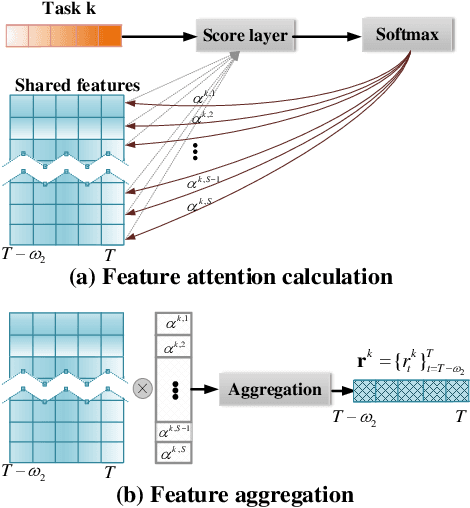
The advances of sensor technology enable people to monitor air quality through widely distributed low-cost sensors. However, measurements from these sensors usually encounter high biases and require a calibration step to reach an acceptable performance in down-streaming analytical tasks. Most existing calibration methods calibrate one type of sensor at a time, which we call single-task calibration. Despite the popularity of this single-task schema, it may neglect interactions among calibration tasks of different sensors, which encompass underlying information to promote calibration performance. In this paper, we propose a multi-task calibration network (MTNet) to calibrate multiple sensors (e.g., carbon monoxide and nitrogen oxide sensors) simultaneously, modeling the interactions among tasks. MTNet consists of a single shared module, and several task-specific modules. Specifically, in the shared module, we extend the multi-gate mixture-of-experts structure to harmonize the task conflicts and correlations among different tasks; in each task-specific module, we introduce a feature selection strategy to customize the input for the specific task. These improvements allow MTNet to learn interaction information shared across different tasks, and task-specific information for each calibration task as well. We evaluate MTNet on three real-world datasets and compare it with several established baselines. The experimental results demonstrate that MTNet achieves the state-of-the-art performance.
Progressive Multi-scale Fusion Network for RGB-D Salient Object Detection
Jun 07, 2021
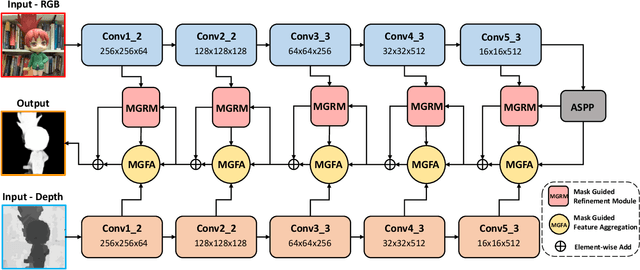
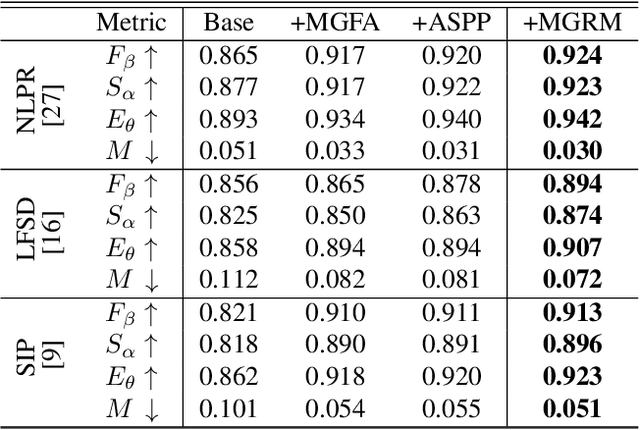
Salient object detection(SOD) aims at locating the most significant object within a given image. In recent years, great progress has been made in applying SOD on many vision tasks. The depth map could provide additional spatial prior and boundary cues to boost the performance. Combining the depth information with image data obtained from standard visual cameras has been widely used in recent SOD works, however, introducing depth information in a suboptimal fusion strategy may have negative influence in the performance of SOD. In this paper, we discuss about the advantages of the so-called progressive multi-scale fusion method and propose a mask-guided feature aggregation module(MGFA). The proposed framework can effectively combine the two features of different modalities and, furthermore, alleviate the impact of erroneous depth features, which are inevitably caused by the variation of depth quality. We further introduce a mask-guided refinement module(MGRM) to complement the high-level semantic features and reduce the irrelevant features from multi-scale fusion, leading to an overall refinement of detection. Experiments on five challenging benchmarks demonstrate that the proposed method outperforms 11 state-of-the-art methods under different evaluation metrics.