 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
VALUE: A Multi-Task Benchmark for Video-and-Language Understanding Evaluation
Jun 08, 2021


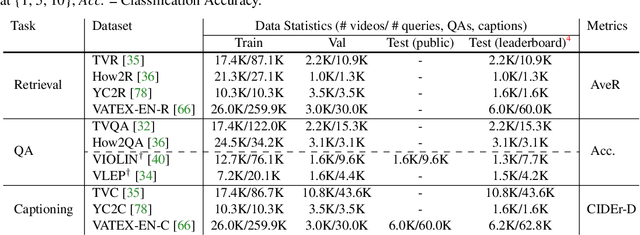
Most existing video-and-language (VidL) research focuses on a single dataset, or multiple datasets of a single task. In reality, a truly useful VidL system is expected to be easily generalizable to diverse tasks, domains, and datasets. To facilitate the evaluation of such systems, we introduce Video-And-Language Understanding Evaluation (VALUE) benchmark, an assemblage of 11 VidL datasets over 3 popular tasks: (i) text-to-video retrieval; (ii) video question answering; and (iii) video captioning. VALUE benchmark aims to cover a broad range of video genres, video lengths, data volumes, and task difficulty levels. Rather than focusing on single-channel videos with visual information only, VALUE promotes models that leverage information from both video frames and their associated subtitles, as well as models that share knowledge across multiple tasks. We evaluate various baseline methods with and without large-scale VidL pre-training, and systematically investigate the impact of video input channels, fusion methods, and different video representations. We also study the transferability between tasks, and conduct multi-task learning under different settings. The significant gap between our best model and human performance calls for future study for advanced VidL models. VALUE is available at https://value-leaderboard.github.io/.
Cell-free Massive MIMO with Short Packets
Jul 22, 2021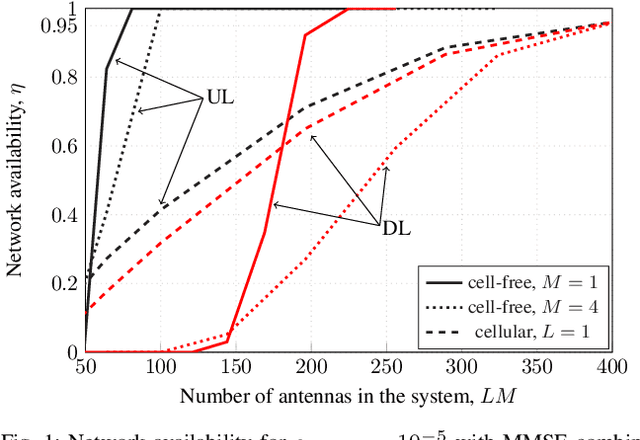
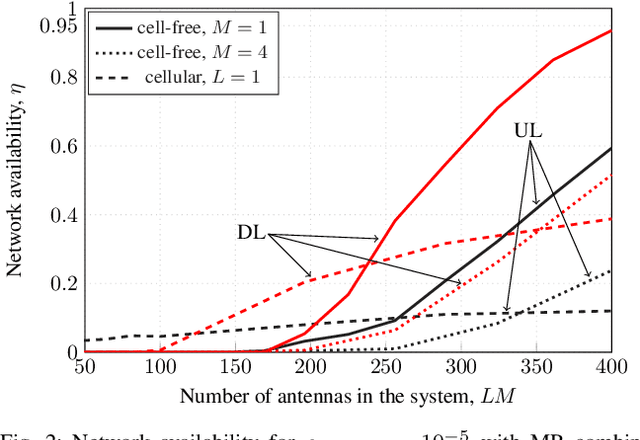
In this paper, we adapt to cell-free Massive MIMO (multiple-input multiple-output) the finite-blocklength framework introduced by \"Ostman et al. (2020) for the characterization of the packet error probability achievable with Massive MIMO, in the ultra-reliable low-latency communications (URLLC) regime. The framework considered in this paper encompasses a cell-free architecture with imperfect channel-state information, and arbitrary linear signal processing performed at a central-processing unit connected to the access points via fronthaul links. By means of numerical simulations, we show that, to achieve the high reliability requirements in URLLC, MMSE signal processing must be used. Comparisons are also made with both small-cell and Massive MIMO cellular networks. Both require a much larger number of antennas to achieve comparable performance to cell-free Massive MIMO.
Information-Theoretic Bounds and Approximations in Neural Population Coding
Nov 07, 2017While Shannon's mutual information has widespread applications in many disciplines, for practical applications it is often difficult to calculate its value accurately for high-dimensional variables because of the curse of dimensionality. This paper is focused on effective approximation methods for evaluating mutual information in the context of neural population coding. For large but finite neural populations, we derive several information-theoretic asymptotic bounds and approximation formulas that remain valid in high-dimensional spaces. We prove that optimizing the population density distribution based on these approximation formulas is a convex optimization problem which allows efficient numerical solutions. Numerical simulation results confirmed that our asymptotic formulas were highly accurate for approximating mutual information for large neural populations. In special cases, the approximation formulas are exactly equal to the true mutual information. We also discuss techniques of variable transformation and dimensionality reduction to facilitate computation of the approximations.
Impact Mitigation for Dynamic Legged Robots with Steel Wire Transmission Using Nonlinear Active Compliance Control
Aug 03, 2021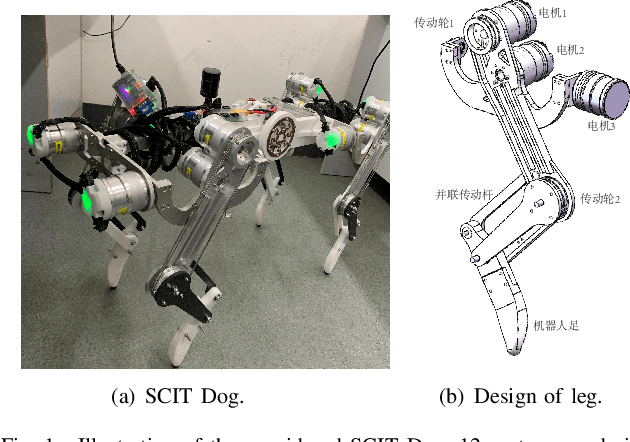
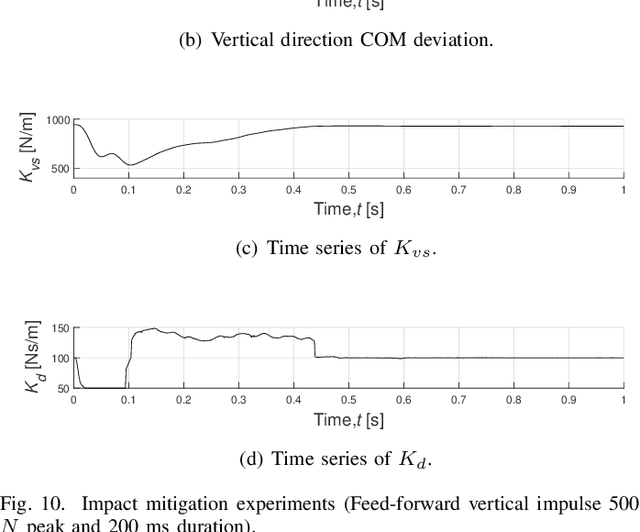
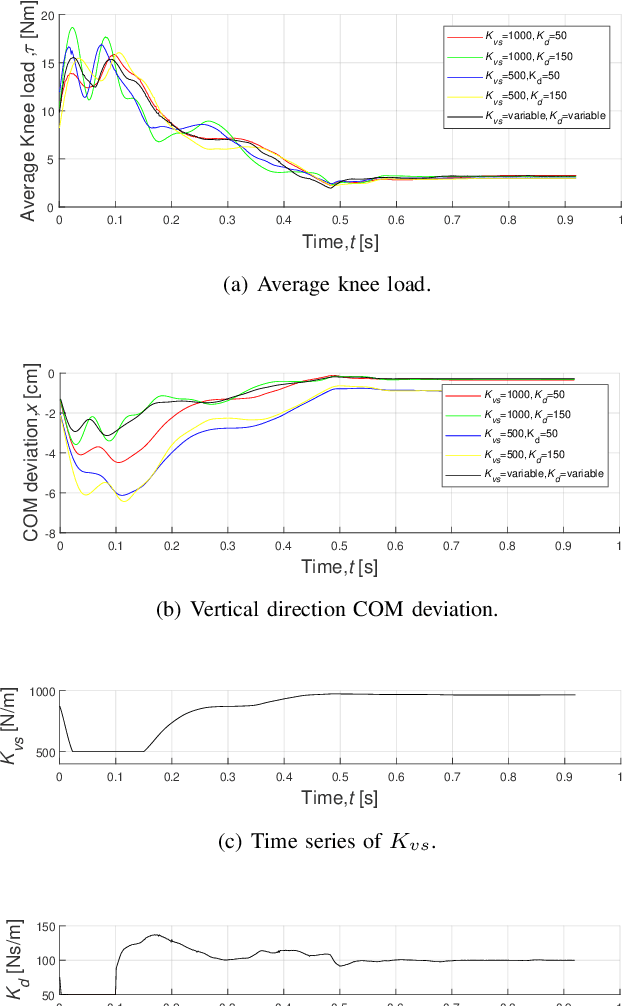
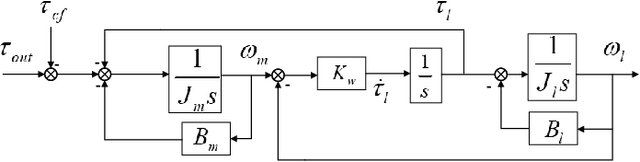
Impact mitigation is crucial to the stable locomotion of legged robots, especially in high-speed dynamic locomotion. This paper presents a leg locomotion system including the nonlinear active compliance control and the active impedance control for the steel wire transmission-based legged robot. The developed control system enables high-speed dynamic locomotion with excellent impact mitigation and leg position tracking performance, where three strategies are applied. a) The feed-forward controller is designed according to the linear motor-leg model with the information of Coulomb friction and viscous friction. b) Steel wire transmission model-based compensation guarantees ideal virtual spring compliance characteristics. c) Nonlinear active compliance control and active impedance control ensure better impact mitigation performance than linear scheme and guarantee position tracking performance. The proposed control system is verified on a real robot named SCIT Dog and the experiment demonstrates the ideal impact mitigation ability in high-speed dynamic locomotion without any passive spring mechanism.
Cross-sentence Neural Language Models for Conversational Speech Recognition
Jun 15, 2021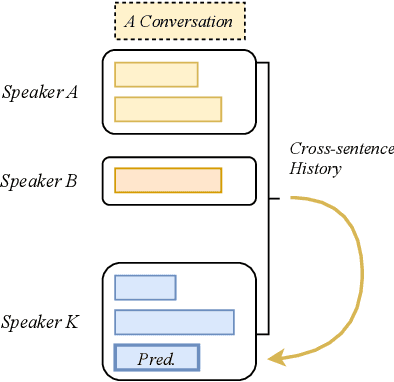
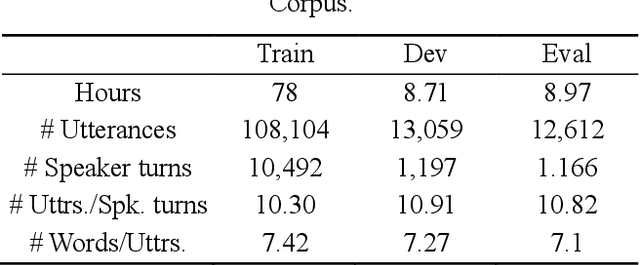
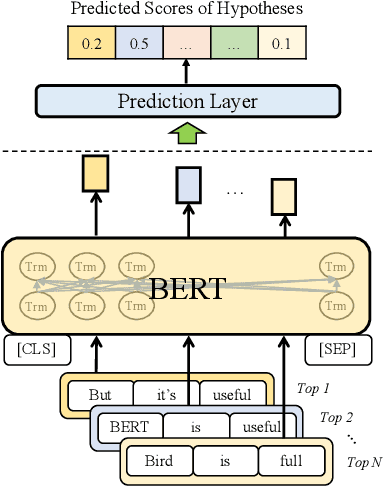
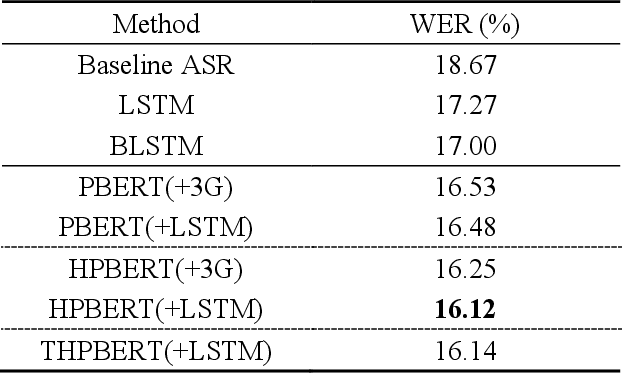
An important research direction in automatic speech recognition (ASR) has centered around the development of effective methods to rerank the output hypotheses of an ASR system with more sophisticated language models (LMs) for further gains. A current mainstream school of thoughts for ASR N-best hypothesis reranking is to employ a recurrent neural network (RNN)-based LM or its variants, with performance superiority over the conventional n-gram LMs across a range of ASR tasks. In real scenarios such as a long conversation, a sequence of consecutive sentences may jointly contain ample cues of conversation-level information such as topical coherence, lexical entrainment and adjacency pairs, which however remains to be underexplored. In view of this, we first formulate ASR N-best reranking as a prediction problem, putting forward an effective cross-sentence neural LM approach that reranks the ASR N-best hypotheses of an upcoming sentence by taking into consideration the word usage in its precedent sentences. Furthermore, we also explore to extract task-specific global topical information of the cross-sentence history in an unsupervised manner for better ASR performance. Extensive experiments conducted on the AMI conversational benchmark corpus indicate the effectiveness and feasibility of our methods in comparison to several state-of-the-art reranking methods.
Decentralized Multi-Agent Reinforcement Learning for Task Offloading Under Uncertainty
Jul 26, 2021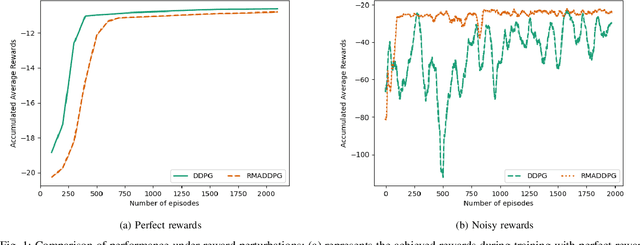
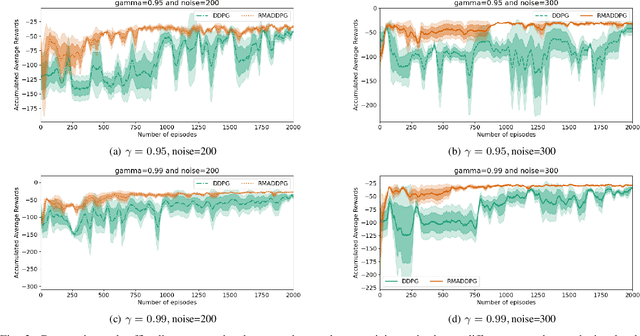
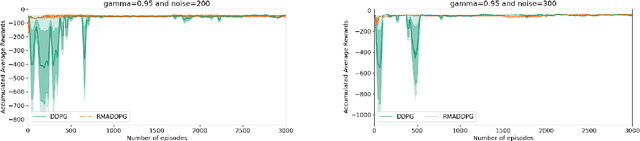
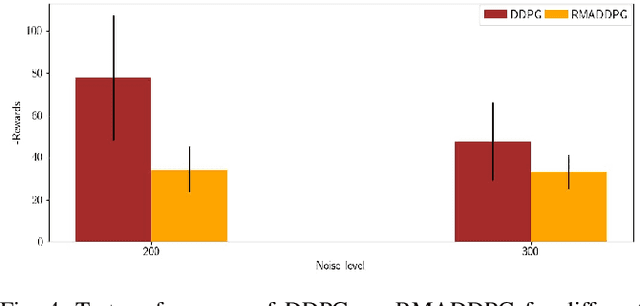
Multi-Agent Reinforcement Learning (MARL) is a challenging subarea of Reinforcement Learning due to the non-stationarity of the environments and the large dimensionality of the combined action space. Deep MARL algorithms have been applied to solve different task offloading problems. However, in real-world applications, information required by the agents (i.e. rewards and states) are subject to noise and alterations. The stability and the robustness of deep MARL to practical challenges is still an open research problem. In this work, we apply state-of-the art MARL algorithms to solve task offloading with reward uncertainty. We show that perturbations in the reward signal can induce decrease in the performance compared to learning with perfect rewards. We expect this paper to stimulate more research in studying and addressing the practical challenges of deploying deep MARL solutions in wireless communications systems.
COVID19-HPSMP: COVID-19 Adopted Hybrid and Parallel Deep Information Fusion Framework for Stock Price Movement Prediction
Jan 02, 2021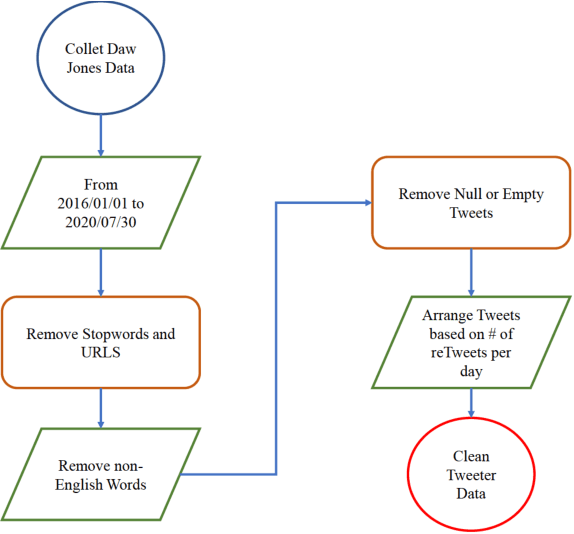

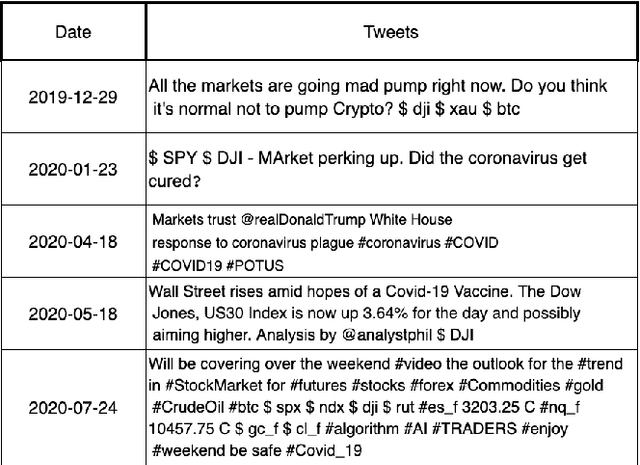
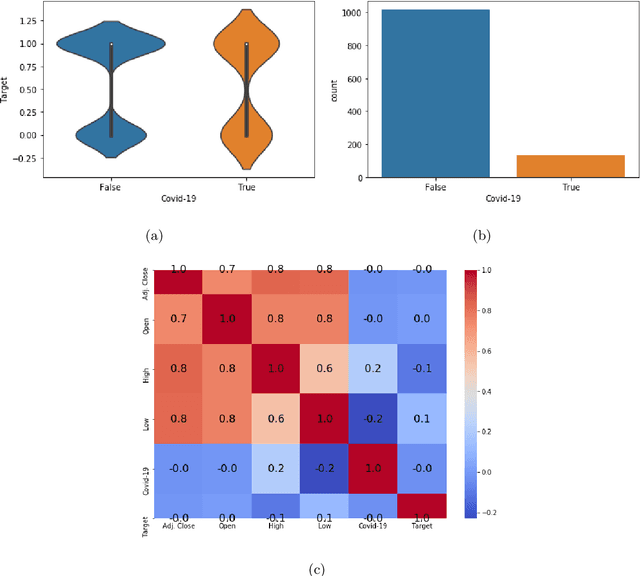
The novel of coronavirus (COVID-19) has suddenly and abruptly changed the world as we knew at the start of the 3rd decade of the 21st century. Particularly, COVID-19 pandemic has negatively affected financial econometrics and stock markets across the globe. Artificial Intelligence (AI) and Machine Learning (ML)-based prediction models, especially Deep Neural Network (DNN) architectures, have the potential to act as a key enabling factor to reduce the adverse effects of the COVID-19 pandemic and future possible ones on financial markets. In this regard, first, a unique COVID-19 related PRIce MOvement prediction (COVID19 PRIMO) dataset is introduced in this paper, which incorporates effects of social media trends related to COVID-19 on stock market price movements. Afterwards, a novel hybrid and parallel DNN-based framework is proposed that integrates different and diversified learning architectures. Referred to as the COVID-19 adopted Hybrid and Parallel deep fusion framework for Stock price Movement Prediction (COVID19-HPSMP), innovative fusion strategies are used to combine scattered social media news related to COVID-19 with historical mark data. The proposed COVID19-HPSMP consists of two parallel paths (hence hybrid), one based on Convolutional Neural Network (CNN) with Local/Global Attention modules, and one integrated CNN and Bi-directional Long Short term Memory (BLSTM) path. The two parallel paths are followed by a multilayer fusion layer acting as a fusion centre that combines localized features. Performance evaluations are performed based on the introduced COVID19 PRIMO dataset illustrating superior performance of the proposed framework.
COMBO: a new module for EUD parsing
Jul 08, 2021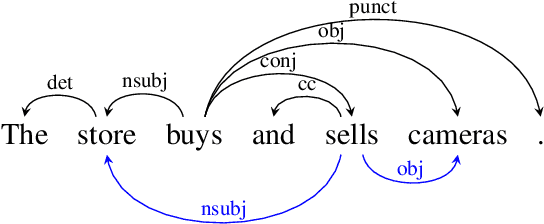

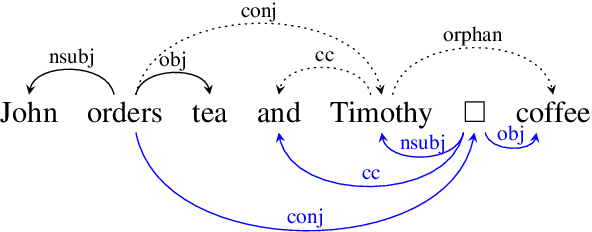
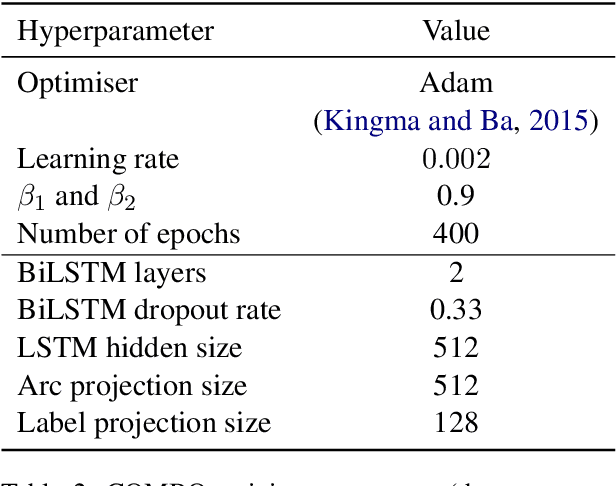
We introduce the COMBO-based approach for EUD parsing and its implementation, which took part in the IWPT 2021 EUD shared task. The goal of this task is to parse raw texts in 17 languages into Enhanced Universal Dependencies (EUD). The proposed approach uses COMBO to predict UD trees and EUD graphs. These structures are then merged into the final EUD graphs. Some EUD edge labels are extended with case information using a single language-independent expansion rule. In the official evaluation, the solution ranked fourth, achieving an average ELAS of 83.79%. The source code is available at https://gitlab.clarin-pl.eu/syntactic-tools/combo.
BanditMF: Multi-Armed Bandit Based Matrix Factorization Recommender System
Jun 21, 2021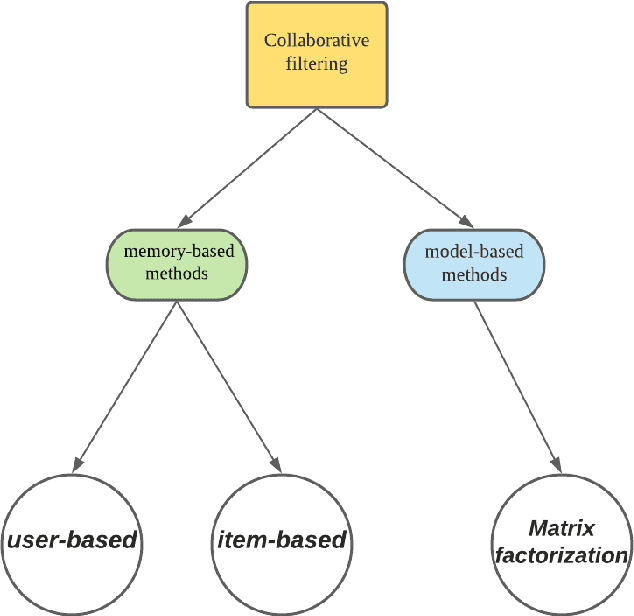
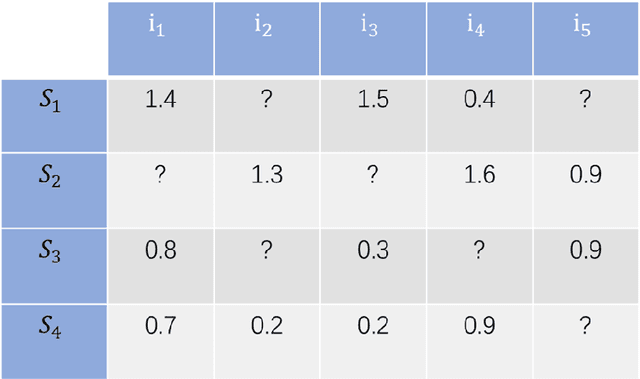
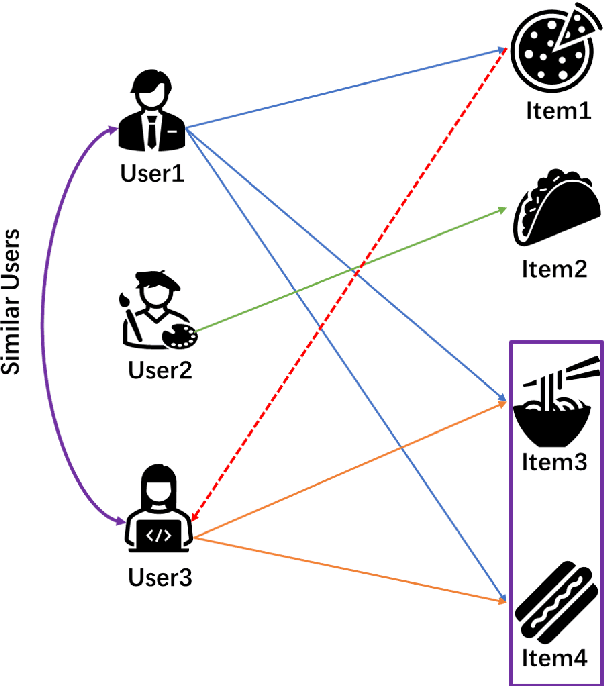
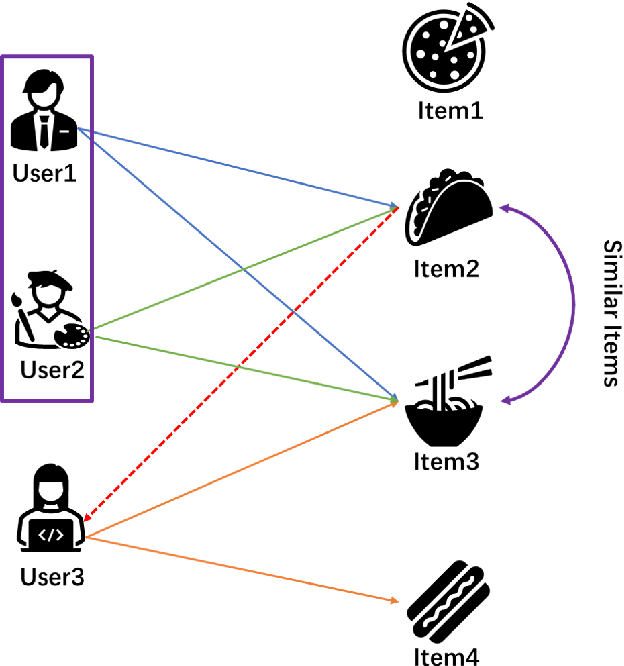
Multi-armed bandits (MAB) provide a principled online learning approach to attain the balance between exploration and exploitation.Due to the superior performance and low feedback learning without the learning to act in multiple situations, Multi-armed Bandits drawing widespread attention in applications ranging such as recommender systems. Likewise, within the recommender system, collaborative filtering (CF) is arguably the earliest and most influential method in the recommender system. Crucially, new users and an ever-changing pool of recommended items are the challenges that recommender systems need to address. For collaborative filtering, the classical method is training the model offline, then perform the online testing, but this approach can no longer handle the dynamic changes in user preferences which is the so-called \textit{cold start}. So how to effectively recommend items to users in the absence of effective information? To address the aforementioned problems, a multi-armed bandit based collaborative filtering recommender system has been proposed, named BanditMF. BanditMF is designed to address two challenges in the multi-armed bandits algorithm and collaborative filtering: (1) how to solve the cold start problem for collaborative filtering under the condition of scarcity of valid information, (2) how to solve the sub-optimal problem of bandit algorithms in strong social relations domains caused by independently estimating unknown parameters associated with each user and ignoring correlations between users.
Correlation Clustering Reconstruction in Semi-Adversarial Models
Aug 10, 2021
Correlation Clustering is an important clustering problem with many applications. We study the reconstruction version of this problem in which one is seeking to reconstruct a latent clustering that has been corrupted by random noise and adversarial modifications. Concerning the latter, we study a standard "post-adversarial" model, in which adversarial modifications come after the noise, and also introduce and analyze a "pre-adversarial" model in which adversarial modifications come before the noise. Given an input coming from such a semi-adversarial generative model, the goal is to reconstruct almost perfectly and with high probability the latent clustering. We focus on the case where the hidden clusters have equal size and show the following. In the pre-adversarial setting, spectral algorithms are optimal, in the sense that they reconstruct all the way to the information-theoretic threshold beyond which no reconstruction is possible. In contrast, in the post-adversarial setting their ability to restore the hidden clusters stops before the threshold, but the gap is optimally filled by SDP-based algorithms.