 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Emotion Recognition with Incomplete Labels Using Modified Multi-task Learning Technique
Jul 09, 2021
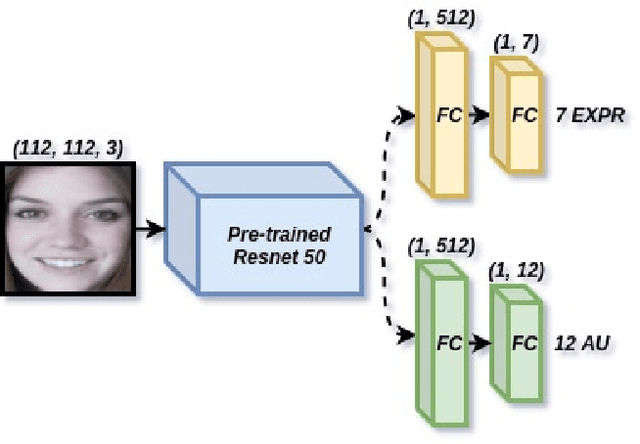
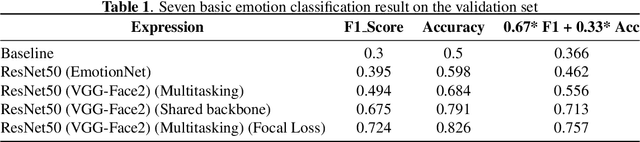
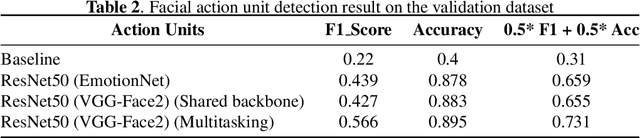
The task of predicting affective information in the wild such as seven basic emotions or action units from human faces has gradually become more interesting due to the accessibility and availability of massive annotated datasets. In this study, we propose a method that utilizes the association between seven basic emotions and twelve action units from the AffWild2 dataset. The method based on the architecture of ResNet50 involves the multi-task learning technique for the incomplete labels of the two tasks. By combining the knowledge for two correlated tasks, both performances are improved by a large margin compared to those with the model employing only one kind of label.
Improving ClusterGAN Using Self-AugmentedInformation Maximization of Disentangling LatentSpaces
Jul 27, 2021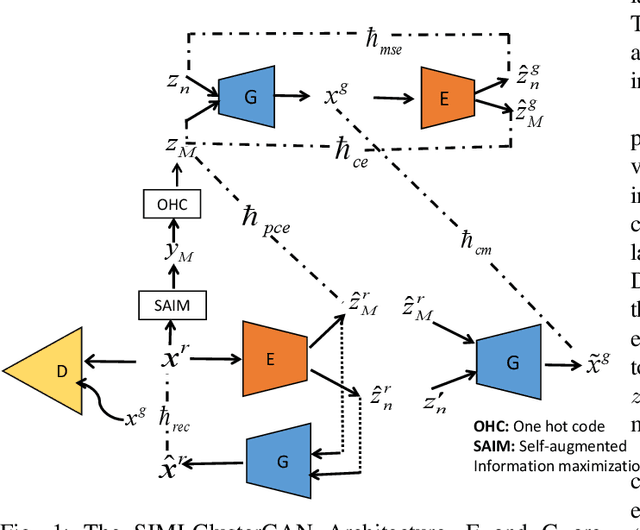



The Latent Space Clustering in Generative adversarial networks (ClusterGAN) method has been successful with high-dimensional data. However, the method assumes uniformlydistributed priors during the generation of modes, which isa restrictive assumption in real-world data and cause loss ofdiversity in the generated modes. In this paper, we proposeself-augmentation information maximization improved Clus-terGAN (SIMI-ClusterGAN) to learn the distinctive priorsfrom the data. The proposed SIMI-ClusterGAN consists offour deep neural networks: self-augmentation prior network,generator, discriminator and clustering inference autoencoder.The proposed method has been validated using seven bench-mark data sets and has shown improved performance overstate-of-the art methods. To demonstrate the superiority ofSIMI-ClusterGAN performance on imbalanced dataset, wehave discussed two imbalanced conditions on MNIST datasetswith one-class imbalance and three classes imbalanced cases.The results highlight the advantages of SIMI-ClusterGAN.
MODETR: Moving Object Detection with Transformers
Jun 21, 2021
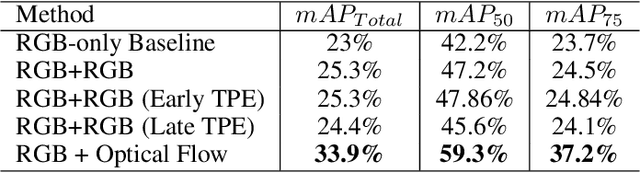

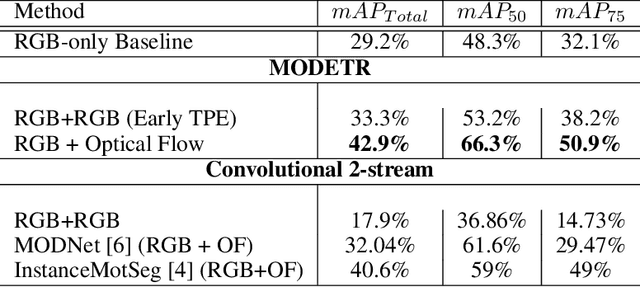
Moving Object Detection (MOD) is a crucial task for the Autonomous Driving pipeline. MOD is usually handled via 2-stream convolutional architectures that incorporates both appearance and motion cues, without considering the inter-relations between the spatial or motion features. In this paper, we tackle this problem through multi-head attention mechanisms, both across the spatial and motion streams. We propose MODETR; a Moving Object DEtection TRansformer network, comprised of multi-stream transformer encoders for both spatial and motion modalities, and an object transformer decoder that produces the moving objects bounding boxes using set predictions. The whole architecture is trained end-to-end using bi-partite loss. Several methods of incorporating motion cues with the Transformer model are explored, including two-stream RGB and Optical Flow (OF) methods, and multi-stream architectures that take advantage of sequence information. To incorporate the temporal information, we propose a new Temporal Positional Encoding (TPE) approach to extend the Spatial Positional Encoding(SPE) in DETR. We explore two architectural choices for that, balancing between speed and time. To evaluate the our network, we perform the MOD task on the KITTI MOD [6] data set. Results show significant 5% mAP of the Transformer network for MOD over the state-of-the art methods. Moreover, the proposed TPE encoding provides 10% mAP improvement over the SPE baseline.
An Anatomy of Graph Neural Networks Going Deep via the Lens of Mutual Information: Exponential Decay vs. Full Preservation
Oct 22, 2019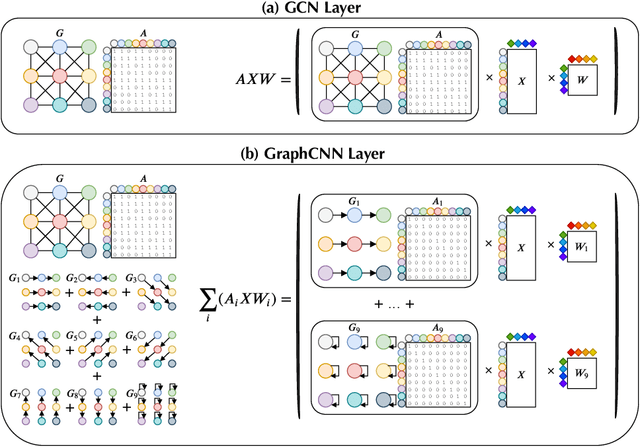

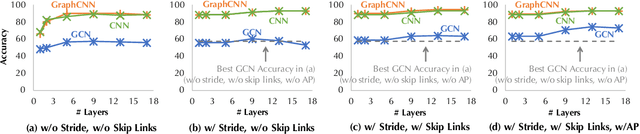
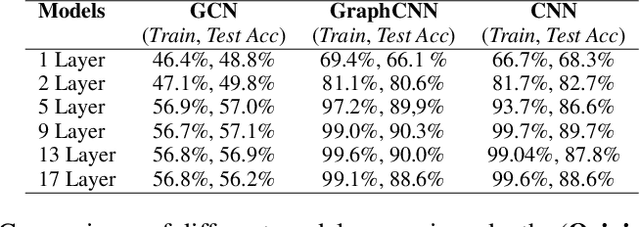
Graph Convolutional Network (GCN) has attracted intensive interests recently. One major limitation of GCN is that it often cannot benefit from using a deep architecture, while traditional CNN and an alternative Graph Neural Network architecture, namely GraphCNN, often achieve better quality with a deeper neural architecture. How can we explain this phenomenon? In this paper, we take the first step towards answering this question. We first conduct a systematic empirical study on the accuracy of GCN, GraphCNN, and ResNet-18 on 2D images and identified relative importance of different factors in architectural design. This inspired a novel theoretical analysis on the mutual information between the input and the output after $l$ GCN and GraphCNN layers. We identified regimes in which GCN suffers exponentially fast information lose and show that GraphCNN requires a much weaker condition for similar behavior to happen.
M-ar-K-Fast Independent Component Analysis
Aug 17, 2021
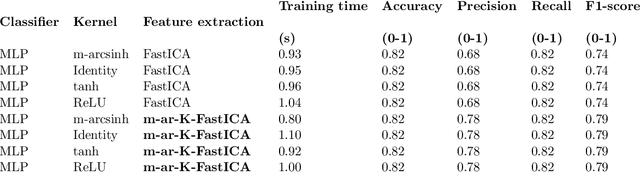
This study presents the m-arcsinh Kernel ('m-ar-K') Fast Independent Component Analysis ('FastICA') method ('m-ar-K-FastICA') for feature extraction. The kernel trick has enabled dimensionality reduction techniques to capture a higher extent of non-linearity in the data; however, reproducible, open-source kernels to aid with feature extraction are still limited and may not be reliable when projecting features from entropic data. The m-ar-K function, freely available in Python and compatible with its open-source library 'scikit-learn', is hereby coupled with FastICA to achieve more reliable feature extraction in presence of a high extent of randomness in the data, reducing the need for pre-whitening. Different classification tasks were considered, as related to five (N = 5) open access datasets of various degrees of information entropy, available from scikit-learn and the University California Irvine (UCI) Machine Learning repository. Experimental results demonstrate improvements in the classification performance brought by the proposed feature extraction. The novel m-ar-K-FastICA dimensionality reduction approach is compared to the 'FastICA' gold standard method, supporting its higher reliability and computational efficiency, regardless of the underlying uncertainty in the data.
Long-Term, in-the-Wild Study of Feedback about Speech Intelligibility for K-12 Students Attending Class via a Telepresence Robot
Aug 24, 2021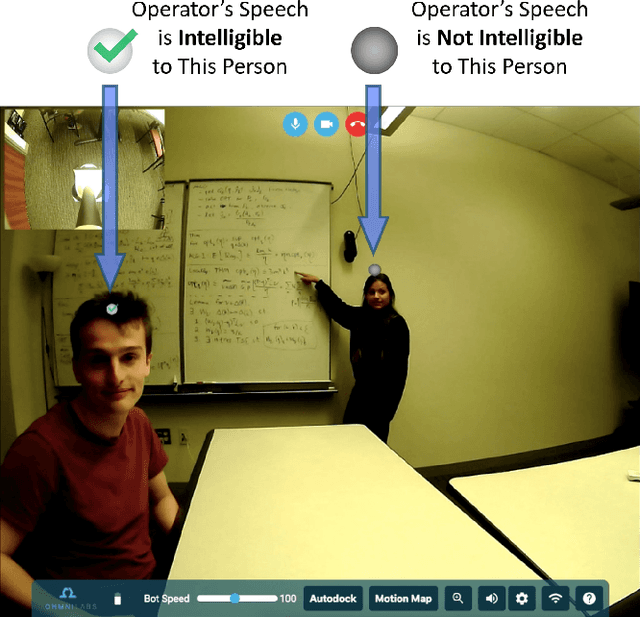

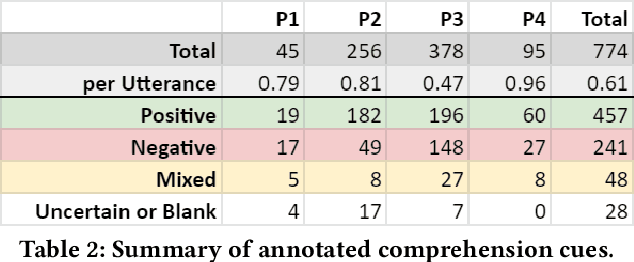
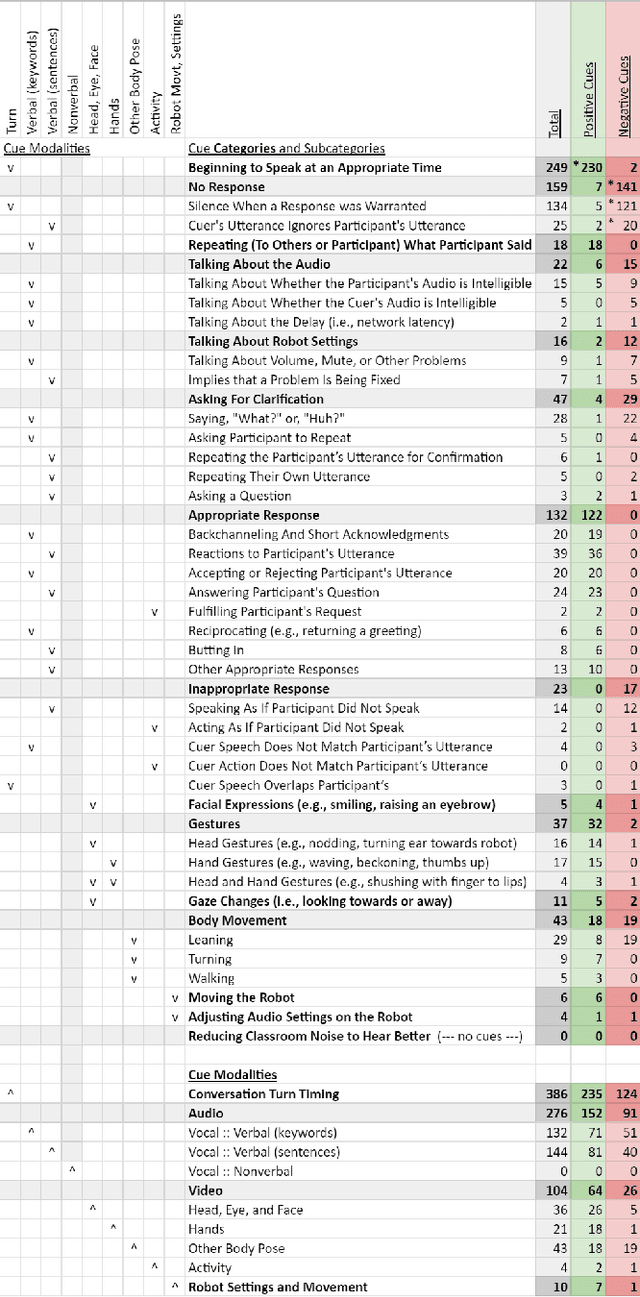
Telepresence robots offer presence, embodiment, and mobility to remote users, making them promising options for homebound K-12 students. It is difficult, however, for robot operators to know how well they are being heard in remote and noisy classroom environments. One solution is to estimate the operator's speech intelligibility to their listeners in order to provide feedback about it to the operator. This work contributes the first evaluation of a speech intelligibility feedback system for homebound K-12 students attending class remotely. In our four long-term, in-the-wild deployments we found that students speak at different volumes instead of adjusting the robot's volume, and that detailed audio calibration and network latency feedback are needed. We also contribute the first findings about the types and frequencies of multimodal comprehension cues given to homebound students by listeners in the classroom. By annotating and categorizing over 700 cues, we found that the most common cue modalities were conversation turn timing and verbal content. Conversation turn timing cues occurred more frequently overall, whereas verbal content cues contained more information and might be the most frequent modality for negative cues. Our work provides recommendations for telepresence systems that could intervene to ensure that remote users are being heard.
Self-Supervised Graph Learning with Hyperbolic Embedding for Temporal Health Event Prediction
Jun 09, 2021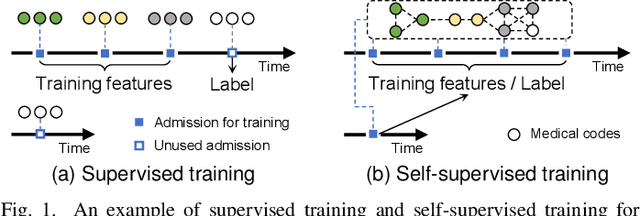
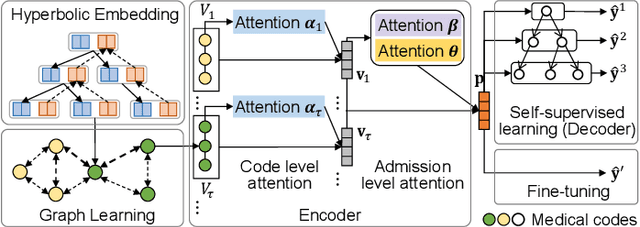
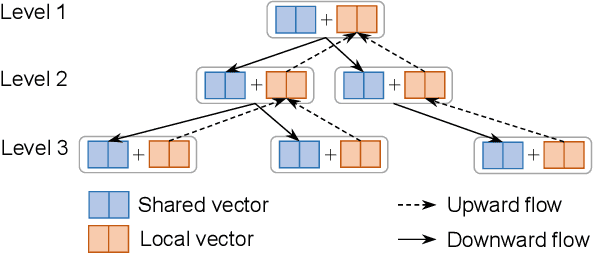
Electronic Health Records (EHR) have been heavily used in modern healthcare systems for recording patients' admission information to hospitals. Many data-driven approaches employ temporal features in EHR for predicting specific diseases, readmission times, or diagnoses of patients. However, most existing predictive models cannot fully utilize EHR data, due to an inherent lack of labels in supervised training for some temporal events. Moreover, it is hard for existing works to simultaneously provide generic and personalized interpretability. To address these challenges, we first propose a hyperbolic embedding method with information flow to pre-train medical code representations in a hierarchical structure. We incorporate these pre-trained representations into a graph neural network to detect disease complications, and design a multi-level attention method to compute the contributions of particular diseases and admissions, thus enhancing personalized interpretability. We present a new hierarchy-enhanced historical prediction proxy task in our self-supervised learning framework to fully utilize EHR data and exploit medical domain knowledge. We conduct a comprehensive set of experiments and case studies on widely used publicly available EHR datasets to verify the effectiveness of our model. The results demonstrate our model's strengths in both predictive tasks and interpretable abilities.
A stepped sampling method for video detection using LSTM
Jul 18, 2021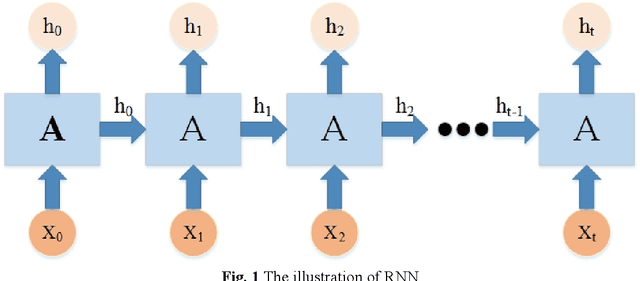
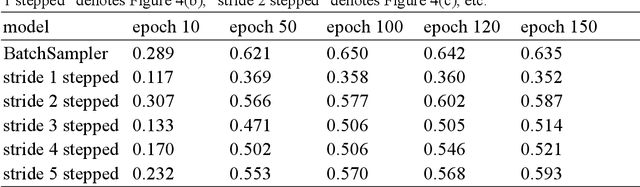


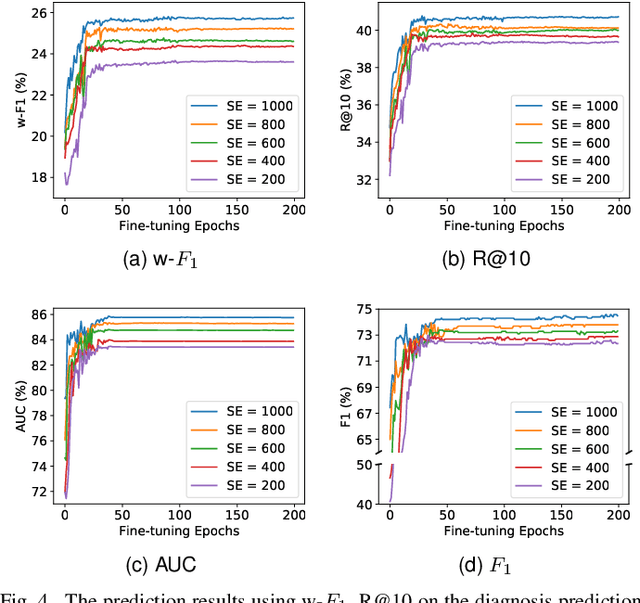
Artificial neural networks that simulate human achieves great successes. From the perspective of simulating human memory method, we propose a stepped sampler based on the "repeated input". We repeatedly inputted data to the LSTM model stepwise in a batch. The stepped sampler is used to strengthen the ability of fusing the temporal information in LSTM. We tested the stepped sampler on the LSTM built-in in PyTorch. Compared with the traditional sampler of PyTorch, such as sequential sampler, batch sampler, the training loss of the proposed stepped sampler converges faster in the training of the model, and the training loss after convergence is more stable. Meanwhile, it can maintain a higher test accuracy. We quantified the algorithm of the stepped sampler.
Blind and neural network-guided convolutional beamformer for joint denoising, dereverberation, and source separation
Aug 04, 2021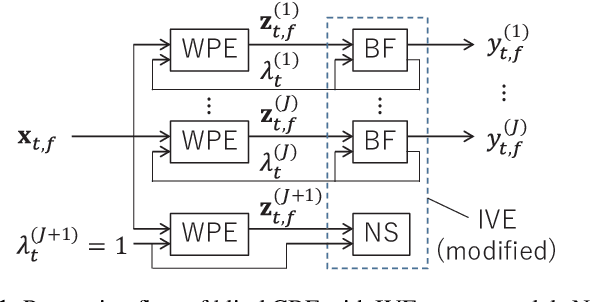
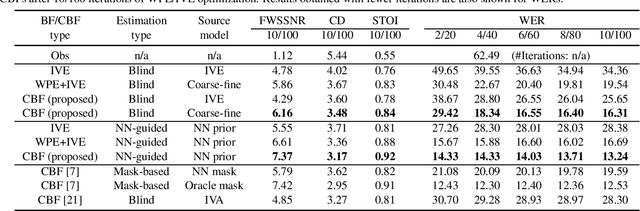
This paper proposes an approach for optimizing a Convolutional BeamFormer (CBF) that can jointly perform denoising (DN), dereverberation (DR), and source separation (SS). First, we develop a blind CBF optimization algorithm that requires no prior information on the sources or the room acoustics, by extending a conventional joint DR and SS method. For making the optimization computationally tractable, we incorporate two techniques into the approach: the Source-Wise Factorization (SW-Fact) of a CBF and the Independent Vector Extraction (IVE). To further improve the performance, we develop a method that integrates a neural network(NN) based source power spectra estimation with CBF optimization by an inverse-Gamma prior. Experiments using noisy reverberant mixtures reveal that our proposed method with both blind and NN-guided scenarios greatly outperforms the conventional state-of-the-art NN-supported mask-based CBF in terms of the improvement in automatic speech recognition and signal distortion reduction performance.
Evaluating Fairness in Argument Retrieval
Aug 23, 2021
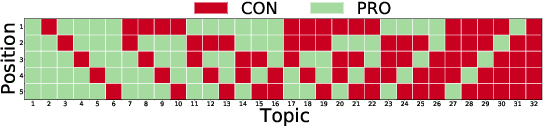
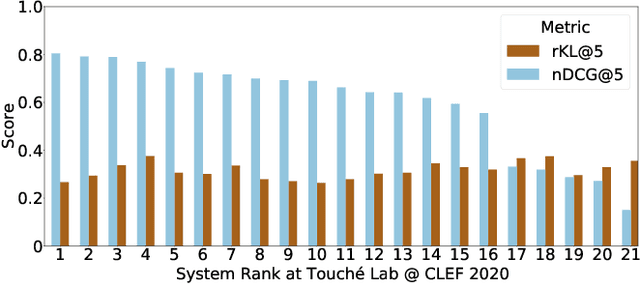

Existing commercial search engines often struggle to represent different perspectives of a search query. Argument retrieval systems address this limitation of search engines and provide both positive (PRO) and negative (CON) perspectives about a user's information need on a controversial topic (e.g., climate change). The effectiveness of such argument retrieval systems is typically evaluated based on topical relevance and argument quality, without taking into account the often differing number of documents shown for the argument stances (PRO or CON). Therefore, systems may retrieve relevant passages, but with a biased exposure of arguments. In this work, we analyze a range of non-stochastic fairness-aware ranking and diversity metrics to evaluate the extent to which argument stances are fairly exposed in argument retrieval systems. Using the official runs of the argument retrieval task Touch\'e at CLEF 2020, as well as synthetic data to control the amount and order of argument stances in the rankings, we show that systems with the best effectiveness in terms of topical relevance are not necessarily the most fair or the most diverse in terms of argument stance. The relationships we found between (un)fairness and diversity metrics shed light on how to evaluate group fairness -- in addition to topical relevance -- in argument retrieval settings.