 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Depth Completion using Plane-Residual Representation
Apr 15, 2021
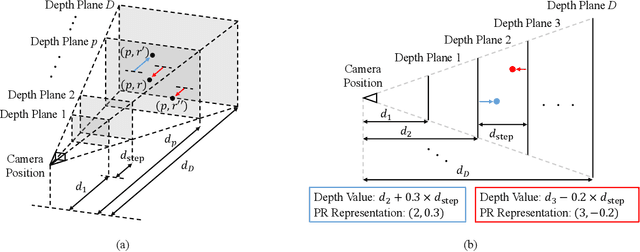
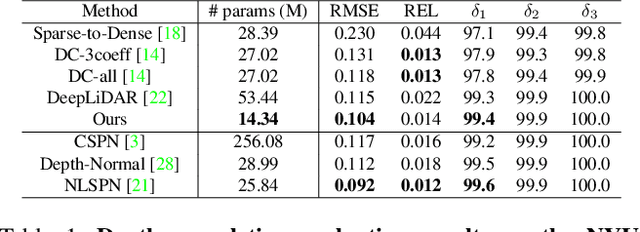
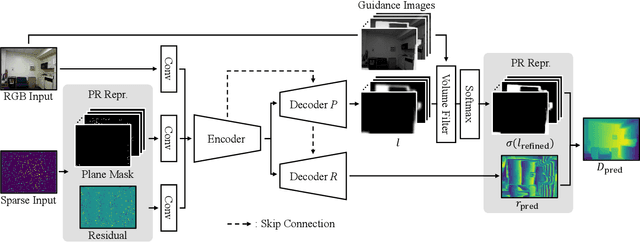
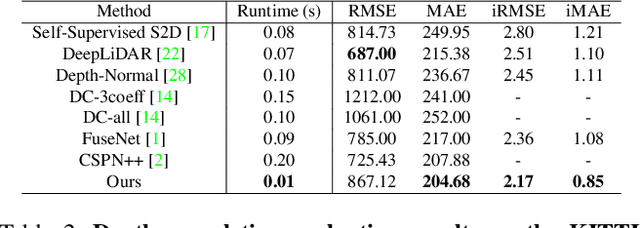
The basic framework of depth completion is to predict a pixel-wise dense depth map using very sparse input data. In this paper, we try to solve this problem in a more effective way, by reformulating the regression-based depth estimation problem into a combination of depth plane classification and residual regression. Our proposed approach is to initially densify sparse depth information by figuring out which plane a pixel should lie among a number of discretized depth planes, and then calculate the final depth value by predicting the distance from the specified plane. This will help the network to lessen the burden of directly regressing the absolute depth information from none, and to effectively obtain more accurate depth prediction result with less computation power and inference time. To do so, we firstly introduce a novel way of interpreting depth information with the closest depth plane label $p$ and a residual value $r$, as we call it, Plane-Residual (PR) representation. We also propose a depth completion network utilizing PR representation consisting of a shared encoder and two decoders, where one classifies the pixel's depth plane label, while the other one regresses the normalized distance from the classified depth plane. By interpreting depth information in PR representation and using our corresponding depth completion network, we were able to acquire improved depth completion performance with faster computation, compared to previous approaches.
Using Depth for Improving Referring Expression Comprehension in Real-World Environments
Jul 09, 2021
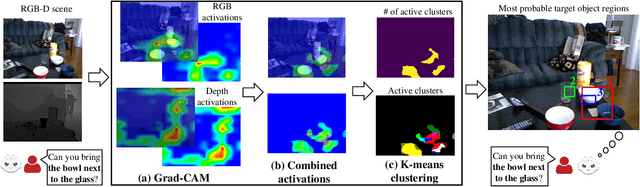

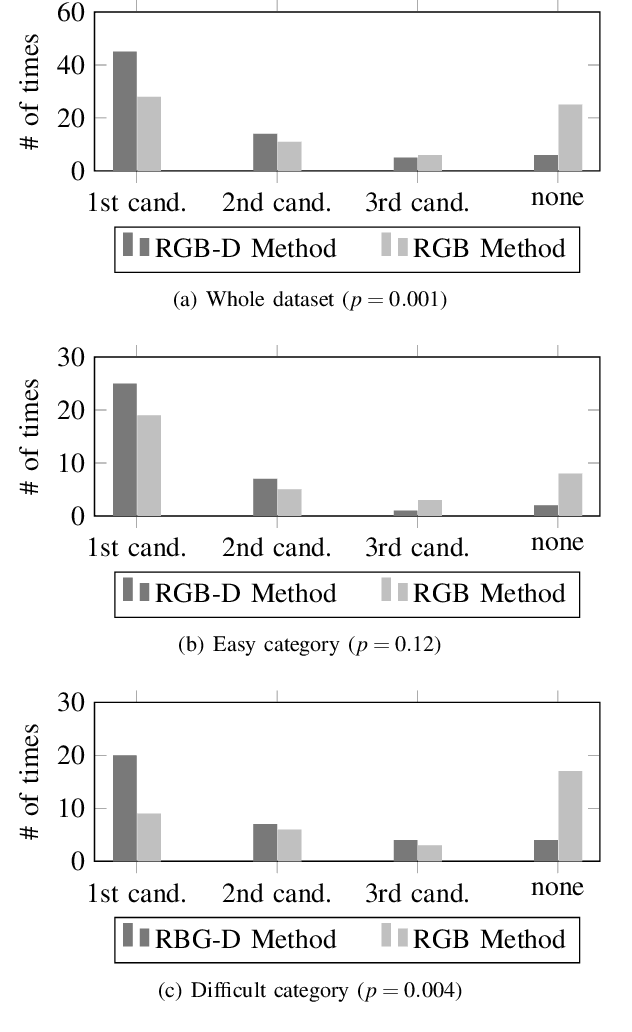
In a human-robot collaborative task where a robot helps its partner by finding described objects, the depth dimension plays a critical role in successful task completion. Existing studies have mostly focused on comprehending the object descriptions using RGB images. However, 3-dimensional space perception that includes depth information is fundamental in real-world environments. In this work, we propose a method to identify the described objects considering depth dimension data. Using depth features significantly improves performance in scenes where depth data is critical to disambiguate the objects and across our whole evaluation dataset that contains objects that can be specified with and without the depth dimension.
Learning to generate shape from global-local spectra
Aug 04, 2021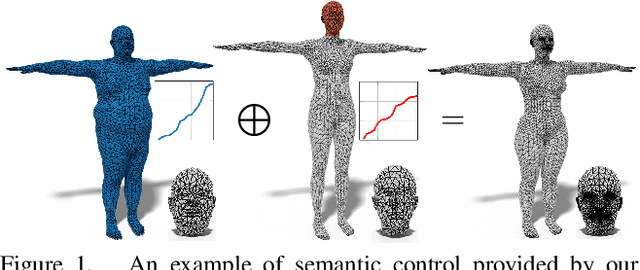
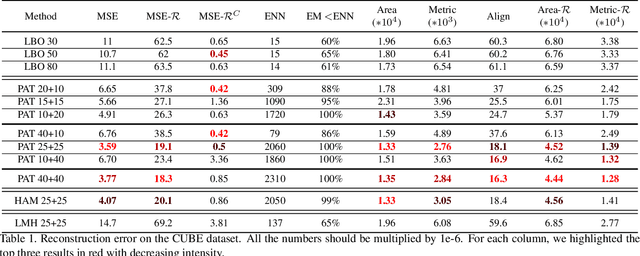
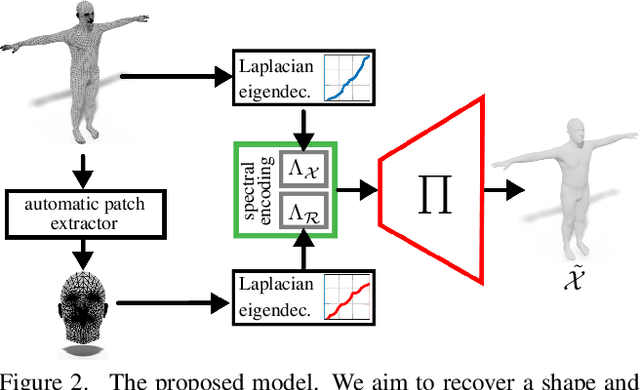
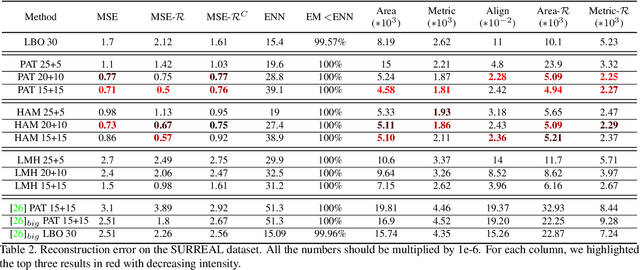
In this work, we present a new learning-based pipeline for the generation of 3D shapes. We build our method on top of recent advances on the so called shape-from-spectrum paradigm, which aims at recovering the full 3D geometric structure of an object only from the eigenvalues of its Laplacian operator. In designing our learning strategy, we consider the spectrum as a natural and ready to use representation to encode variability of the shapes. Therefore, we propose a simple decoder-only architecture that directly maps spectra to 3D embeddings; in particular, we combine information from global and local spectra, the latter being obtained from localized variants of the manifold Laplacian. This combination captures the relations between the full shape and its local parts, leading to more accurate generation of geometric details and an improved semantic control in shape synthesis and novel editing applications. Our results confirm the improvement of the proposed approach in comparison to existing and alternative methods.
Joint Multiple Intent Detection and Slot Filling via Self-distillation
Aug 18, 2021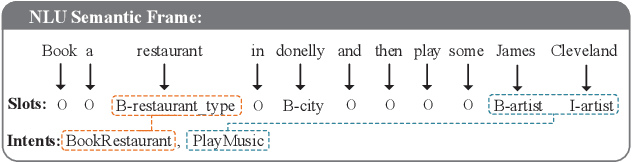
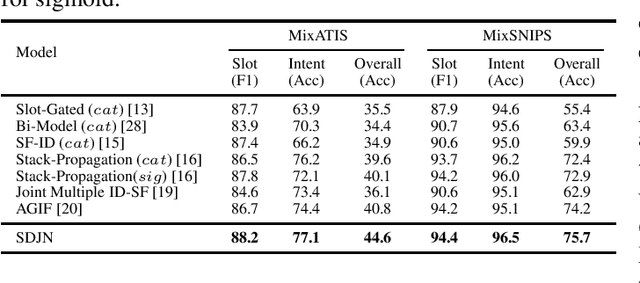
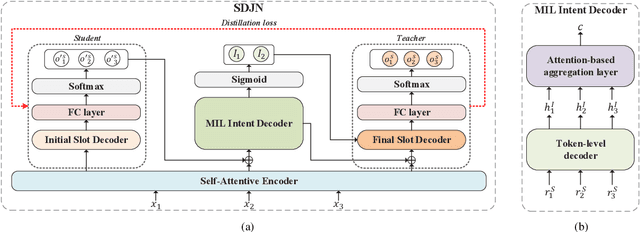
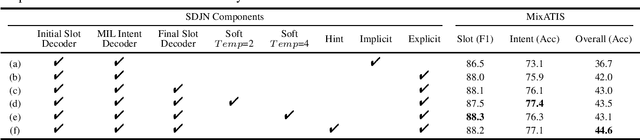
Intent detection and slot filling are two main tasks in natural language understanding (NLU) for identifying users' needs from their utterances. These two tasks are highly related and often trained jointly. However, most previous works assume that each utterance only corresponds to one intent, ignoring the fact that a user utterance in many cases could include multiple intents. In this paper, we propose a novel Self-Distillation Joint NLU model (SDJN) for multi-intent NLU. First, we formulate multiple intent detection as a weakly supervised problem and approach with multiple instance learning (MIL). Then, we design an auxiliary loop via self-distillation with three orderly arranged decoders: Initial Slot Decoder, MIL Intent Decoder, and Final Slot Decoder. The output of each decoder will serve as auxiliary information for the next decoder. With the auxiliary knowledge provided by the MIL Intent Decoder, we set Final Slot Decoder as the teacher model that imparts knowledge back to Initial Slot Decoder to complete the loop. The auxiliary loop enables intents and slots to guide mutually in-depth and further boost the overall NLU performance. Experimental results on two public multi-intent datasets indicate that our model achieves strong performance compared to others.
Support-Set Based Cross-Supervision for Video Grounding
Aug 24, 2021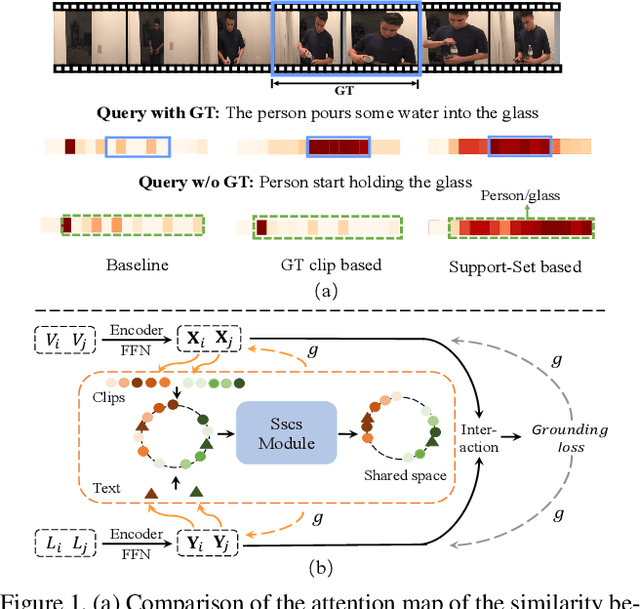
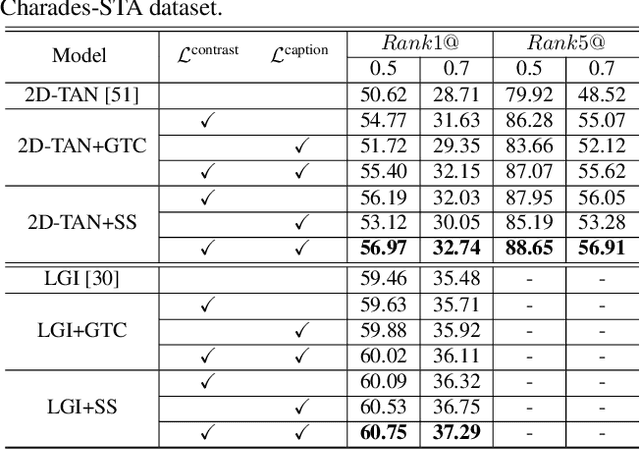

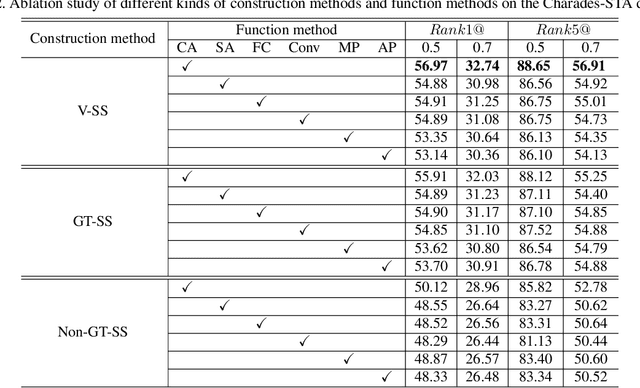
Current approaches for video grounding propose kinds of complex architectures to capture the video-text relations, and have achieved impressive improvements. However, it is hard to learn the complicated multi-modal relations by only architecture designing in fact. In this paper, we introduce a novel Support-set Based Cross-Supervision (Sscs) module which can improve existing methods during training phase without extra inference cost. The proposed Sscs module contains two main components, i.e., discriminative contrastive objective and generative caption objective. The contrastive objective aims to learn effective representations by contrastive learning, while the caption objective can train a powerful video encoder supervised by texts. Due to the co-existence of some visual entities in both ground-truth and background intervals, i.e., mutual exclusion, naively contrastive learning is unsuitable to video grounding. We address the problem by boosting the cross-supervision with the support-set concept, which collects visual information from the whole video and eliminates the mutual exclusion of entities. Combined with the original objectives, Sscs can enhance the abilities of multi-modal relation modeling for existing approaches. We extensively evaluate Sscs on three challenging datasets, and show that our method can improve current state-of-the-art methods by large margins, especially 6.35% in terms of R1@0.5 on Charades-STA.
Multimodal Image-to-Image Translation via Mutual Information Estimation and Maximization
Aug 24, 2020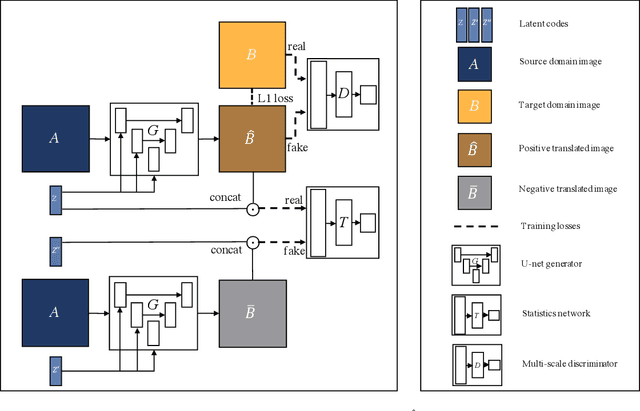
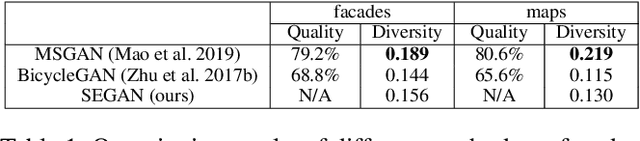

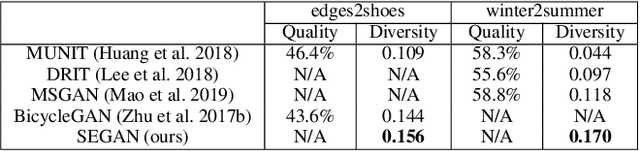
In this paper, we present a novel framework that can achieve multimodal image-to-image translation by simply encouraging the statistical dependence between the latent code and the output image in conditional generative adversarial networks. In addition, by incorporating a U-net generator into our framework, our method only needs to learn a one-sided translation model from the source image domain to the target image domain for both supervised and unsupervised multimodal image-to-image translation. Furthermore, our method also achieves disentanglement between the source domain content and the target domain style for free. We conduct experiments under supervised and unsupervised settings on various benchmark image-to-image translation datasets compared with the state-of-the-art methods, showing the effectiveness and simplicity of our method to achieve multimodal and high-quality results.
StyleAugment: Learning Texture De-biased Representations by Style Augmentation without Pre-defined Textures
Aug 24, 2021
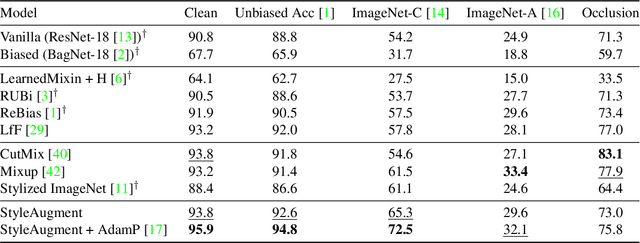


Recent powerful vision classifiers are biased towards textures, while shape information is overlooked by the models. A simple attempt by augmenting training images using the artistic style transfer method, called Stylized ImageNet, can reduce the texture bias. However, Stylized ImageNet approach has two drawbacks in fidelity and diversity. First, the generated images show low image quality due to the significant semantic gap betweeen natural images and artistic paintings. Also, Stylized ImageNet training samples are pre-computed before training, resulting in showing the lack of diversity for each sample. We propose a StyleAugment by augmenting styles from the mini-batch. StyleAugment does not rely on the pre-defined style references, but generates augmented images on-the-fly by natural images in the mini-batch for the references. Hence, StyleAugment let the model observe abundant confounding cues for each image by on-the-fly the augmentation strategy, while the augmented images are more realistic than artistic style transferred images. We validate the effectiveness of StyleAugment in the ImageNet dataset with robustness benchmarks, such as texture de-biased accuracy, corruption robustness, natural adversarial samples, and occlusion robustness. StyleAugment shows better generalization performances than previous unsupervised de-biasing methods and state-of-the-art data augmentation methods in our experiments.
Large-Scale Modeling of Mobile User Click Behaviors Using Deep Learning
Aug 11, 2021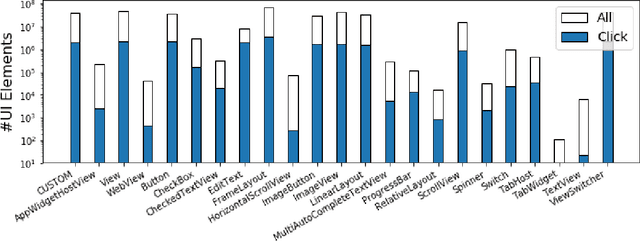
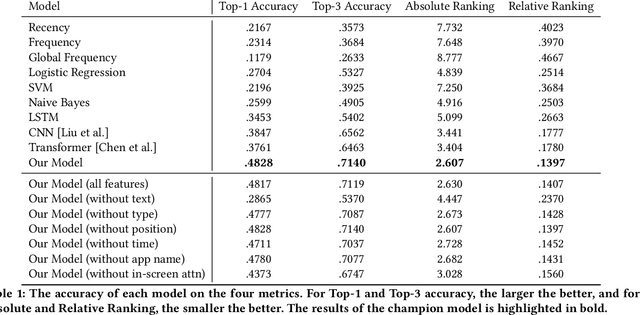
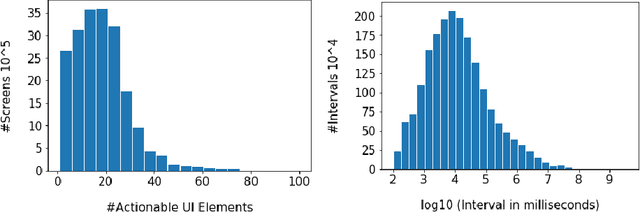
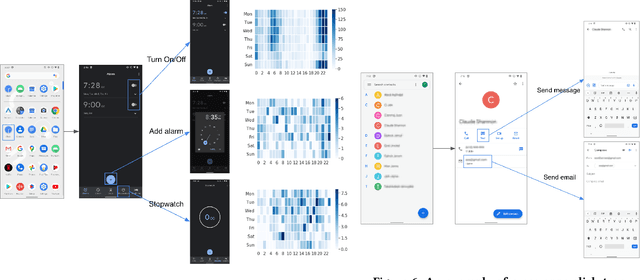
Modeling tap or click sequences of users on a mobile device can improve our understandings of interaction behavior and offers opportunities for UI optimization by recommending next element the user might want to click on. We analyzed a large-scale dataset of over 20 million clicks from more than 4,000 mobile users who opted in. We then designed a deep learning model that predicts the next element that the user clicks given the user's click history, the structural information of the UI screen, and the current context such as the time of the day. We thoroughly investigated the deep model by comparing it with a set of baseline methods based on the dataset. The experiments show that our model achieves 48% and 71% accuracy (top-1 and top-3) for predicting next clicks based on a held-out dataset of test users, which significantly outperformed all the baseline methods with a large margin. We discussed a few scenarios for integrating the model in mobile interaction and how users can potentially benefit from the model.
Making Person Search Enjoy the Merits of Person Re-identification
Aug 24, 2021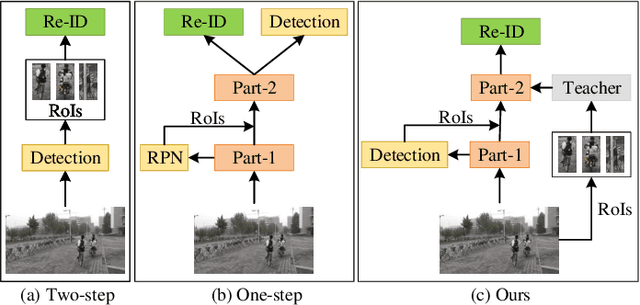
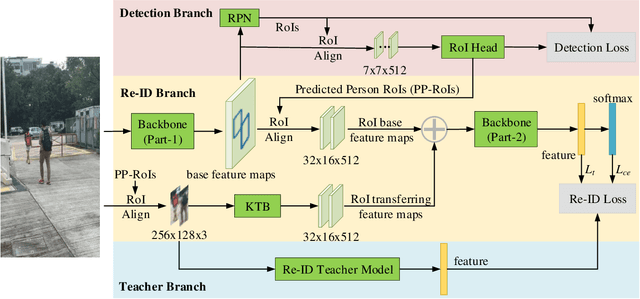

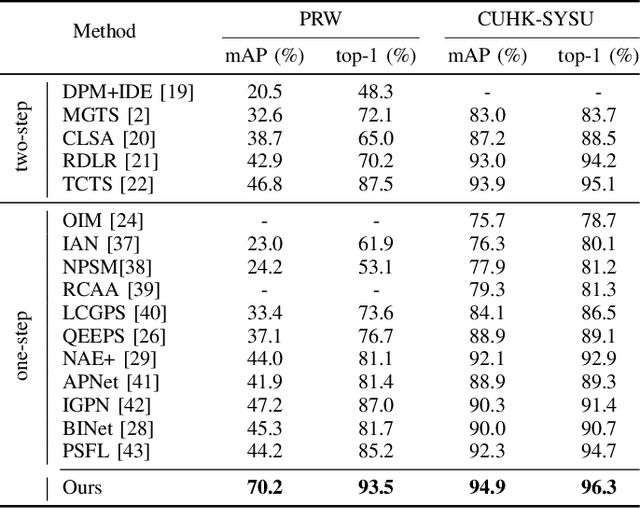
Person search is an extended task of person re-identification (Re-ID). However, most existing one-step person search works have not studied how to employ existing advanced Re-ID models to boost the one-step person search performance due to the integration of person detection and Re-ID. To address this issue, we propose a faster and stronger one-step person search framework, the Teacher-guided Disentangling Networks (TDN), to make the one-step person search enjoy the merits of the existing Re-ID researches. The proposed TDN can significantly boost the person search performance by transferring the advanced person Re-ID knowledge to the person search model. In the proposed TDN, for better knowledge transfer from the Re-ID teacher model to the one-step person search model, we design a strong one-step person search base framework by partially disentangling the two subtasks. Besides, we propose a Knowledge Transfer Bridge module to bridge the scale gap caused by different input formats between the Re-ID model and one-step person search model. During testing, we further propose the Ranking with Context Persons strategy to exploit the context information in panoramic images for better retrieval. Experiments on two public person search datasets demonstrate the favorable performance of the proposed method.
Multimodal Representation for Neural Code Search
Jul 23, 2021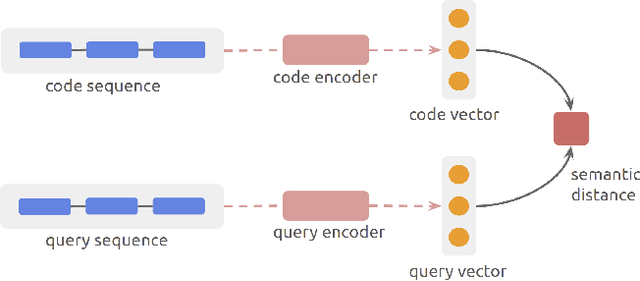
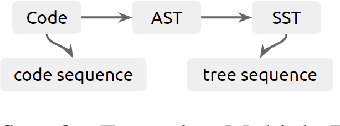
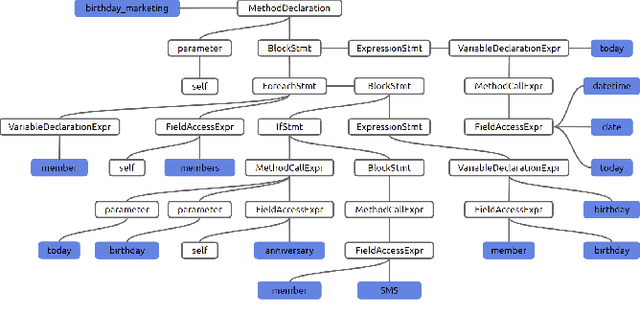
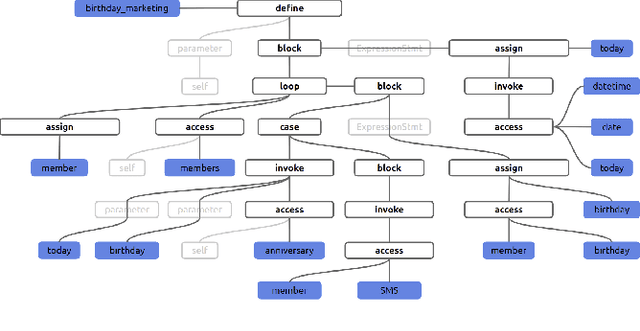
Semantic code search is about finding semantically relevant code snippets for a given natural language query. In the state-of-the-art approaches, the semantic similarity between code and query is quantified as the distance of their representation in the shared vector space. In this paper, to improve the vector space, we introduce tree-serialization methods on a simplified form of AST and build the multimodal representation for the code data. We conduct extensive experiments using a single corpus that is large-scale and multi-language: CodeSearchNet. Our results show that both our tree-serialized representations and multimodal learning model improve the performance of code search. Last, we define intuitive quantification metrics oriented to the completeness of semantic and syntactic information of the code data, to help understand the experimental findings.