 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Study of visual processing techniques for dynamic speckles: a comparative analysis
Jun 16, 2021
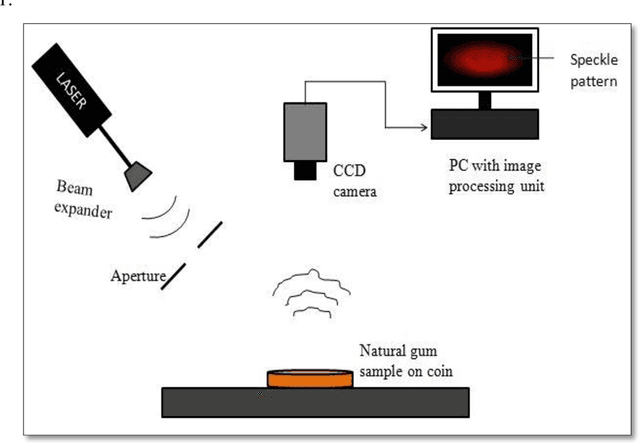
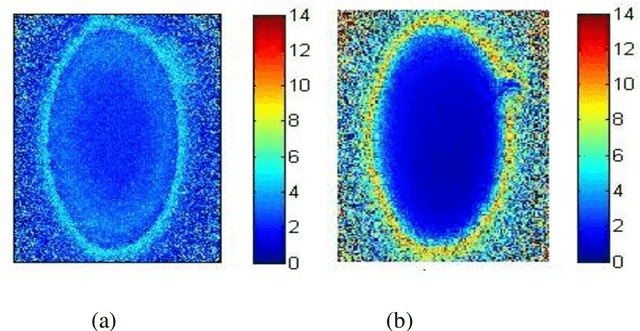
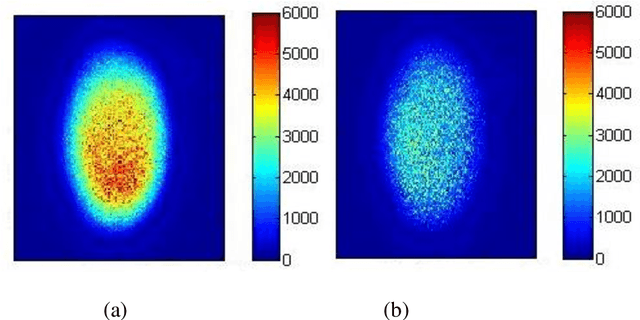
Main visual techniques used to obtain information from speckle patterns are Fujii method, generalized difference, weighted generalized difference, mean windowed difference, structural function (SF), modified SF, etc. In this work, a comparative analysis of major visual techniques for natural gum sample is carried out. Obtained results conclusively establish SF based method as an optimum tool for visual inspection of dynamic speckle data.
Adversarial Robustness via Fisher-Rao Regularization
Jun 12, 2021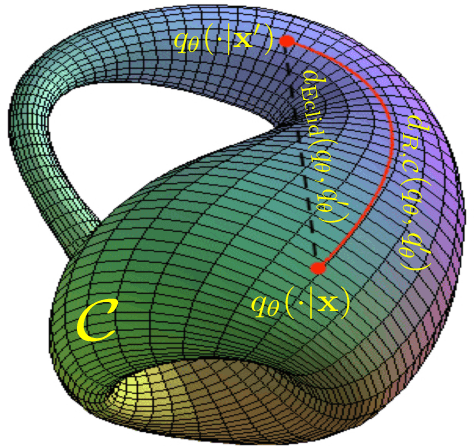
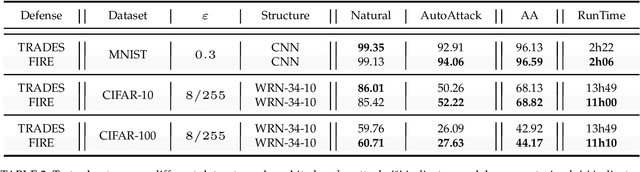
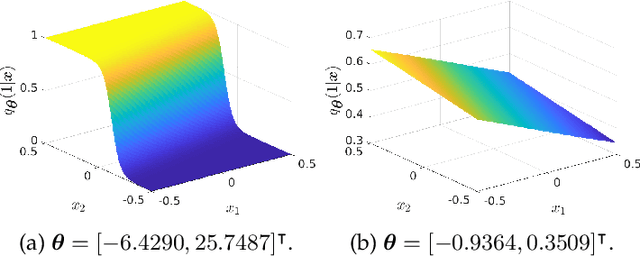
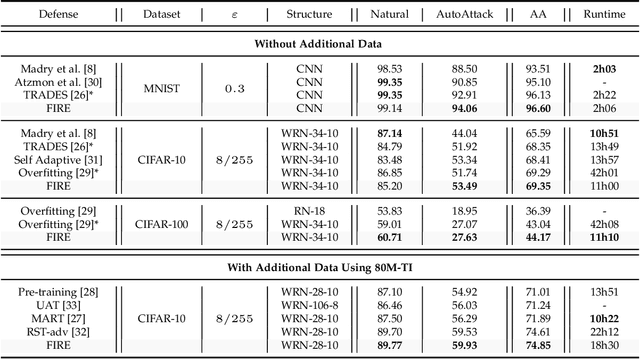
Adversarial robustness has become a topic of growing interest in machine learning since it was observed that neural networks tend to be brittle. We propose an information-geometric formulation of adversarial defense and introduce FIRE, a new Fisher-Rao regularization for the categorical cross-entropy loss, which is based on the geodesic distance between natural and perturbed input features. Based on the information-geometric properties of the class of softmax distributions, we derive an explicit characterization of the Fisher-Rao Distance (FRD) for the binary and multiclass cases, and draw some interesting properties as well as connections with standard regularization metrics. Furthermore, for a simple linear and Gaussian model, we show that all Pareto-optimal points in the accuracy-robustness region can be reached by FIRE while other state-of-the-art methods fail. Empirically, we evaluate the performance of various classifiers trained with the proposed loss on standard datasets, showing up to 2\% of improvements in terms of robustness while reducing the training time by 20\% over the best-performing methods.
Unsupervised Cross-Domain Prerequisite Chain Learning using Variational Graph Autoencoders
May 27, 2021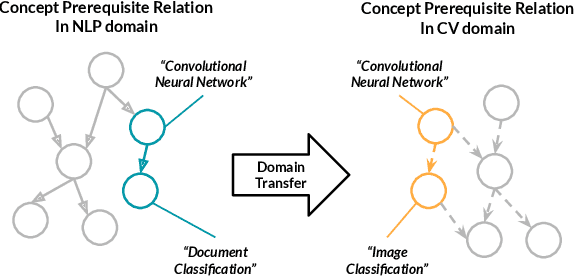
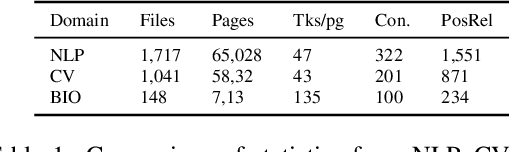
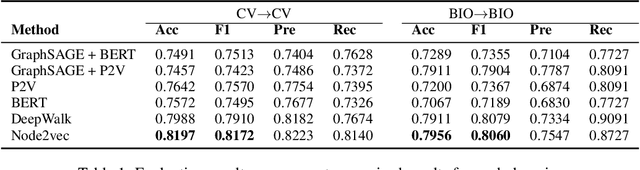
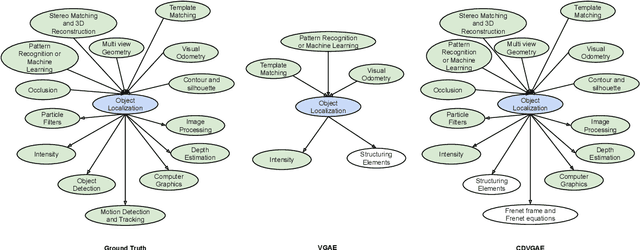
Learning prerequisite chains is an essential task for efficiently acquiring knowledge in both known and unknown domains. For example, one may be an expert in the natural language processing (NLP) domain but want to determine the best order to learn new concepts in an unfamiliar Computer Vision domain (CV). Both domains share some common concepts, such as machine learning basics and deep learning models. In this paper, we propose unsupervised cross-domain concept prerequisite chain learning using an optimized variational graph autoencoder. Our model learns to transfer concept prerequisite relations from an information-rich domain (source domain) to an information-poor domain (target domain), substantially surpassing other baseline models. Also, we expand an existing dataset by introducing two new domains: CV and Bioinformatics (BIO). The annotated data and resources, as well as the code, will be made publicly available.
Prediction of Metacarpophalangeal joint angles and Classification of Hand configurations based on Ultrasound Imaging of the Forearm
Sep 26, 2021

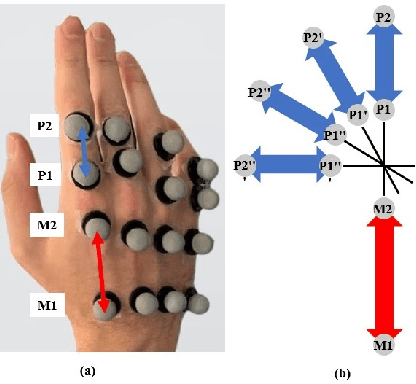
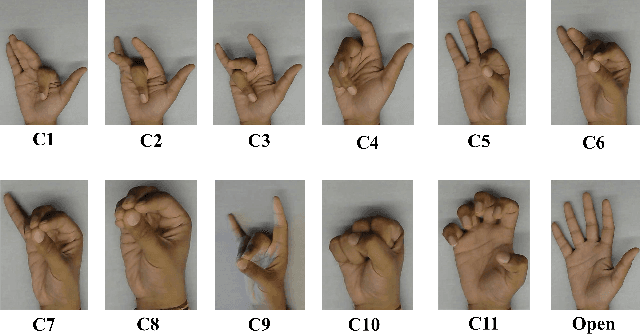
With the advancement in computing and robotics, it is necessary to develop fluent and intuitive methods for interacting with digital systems, AR/VR interfaces, and physical robotic systems. Hand movement recognition is widely used to enable this interaction. Hand configuration classification and Metacarpophalangeal (MCP) joint angle detection are important for a comprehensive reconstruction of the hand motion. Surface electromyography and other technologies have been used for the detection of hand motions. Ultrasound images of the forearm offer a way to visualize the internal physiology of the hand from a musculoskeletal perspective. Recent work has shown that these images can be classified using machine learning to predict various hand configurations. In this paper, we propose a Convolutional Neural Network (CNN) based deep learning pipeline for predicting the MCP joint angles. We supplement our results by using a Support Vector Classifier (SVC) to classify the ultrasound information into several predefined hand configurations based on activities of daily living (ADL). Ultrasound data from the forearm was obtained from 6 subjects who were instructed to move their hands according to predefined hand configurations relevant to ADLs. Motion capture data was acquired as the ground truth for hand movements at different speeds (0.5 Hz, 1 Hz, & 2 Hz) for the index, middle, ring, and pinky fingers. We were able to get promising SVC classification results on a subset of our collected data set. We demonstrated a correspondence between the predicted MCP joint angles and the actual MCP joint angles for the fingers, with an average root mean square error of 7.35 degrees. We implemented a low latency (6.25 - 9.1 Hz) pipeline for the prediction of both MCP joint angles and hand configuration estimation aimed at real-time control of digital devices, AR/VR interfaces, and physical robots.
GLocal-K: Global and Local Kernels for Recommender Systems
Aug 27, 2021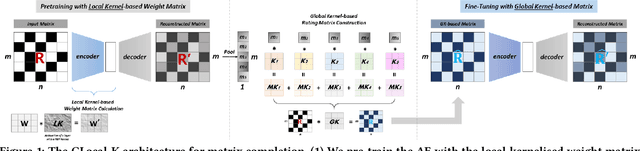
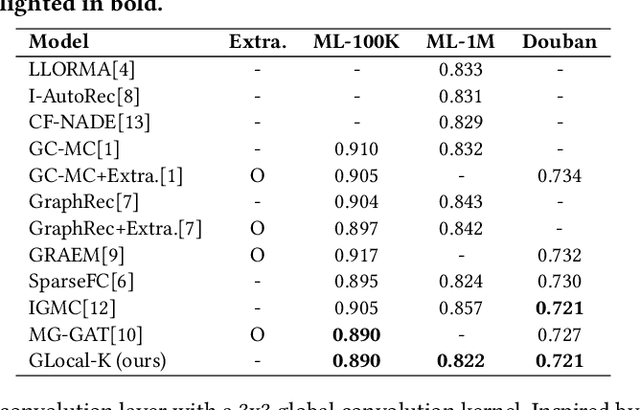
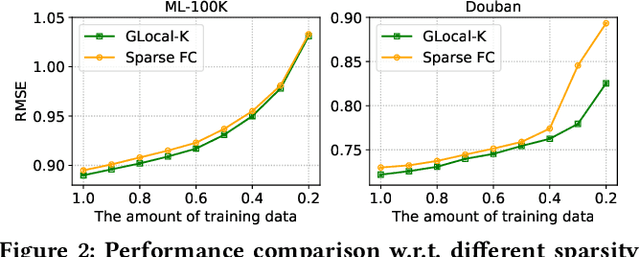
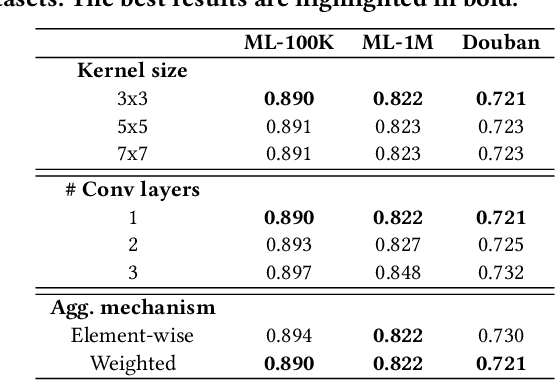
Recommender systems typically operate on high-dimensional sparse user-item matrices. Matrix completion is a very challenging task to predict one's interest based on millions of other users having each seen a small subset of thousands of items. We propose a Global-Local Kernel-based matrix completion framework, named GLocal-K, that aims to generalise and represent a high-dimensional sparse user-item matrix entry into a low dimensional space with a small number of important features. Our GLocal-K can be divided into two major stages. First, we pre-train an auto encoder with the local kernelised weight matrix, which transforms the data from one space into the feature space by using a 2d-RBF kernel. Then, the pre-trained auto encoder is fine-tuned with the rating matrix, produced by a convolution-based global kernel, which captures the characteristics of each item. We apply our GLocal-K model under the extreme low-resource setting, which includes only a user-item rating matrix, with no side information. Our model outperforms the state-of-the-art baselines on three collaborative filtering benchmarks: ML-100K, ML-1M, and Douban.
Easing Embedding Learning by Comprehensive Transcription of Heterogeneous Information Networks
Jul 10, 2018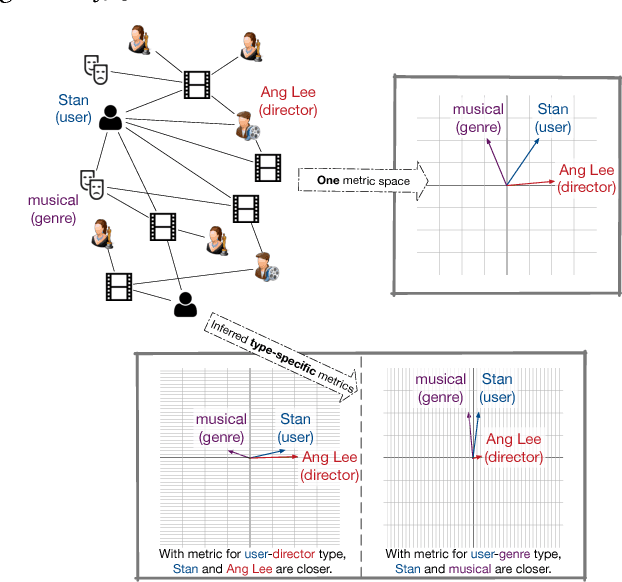

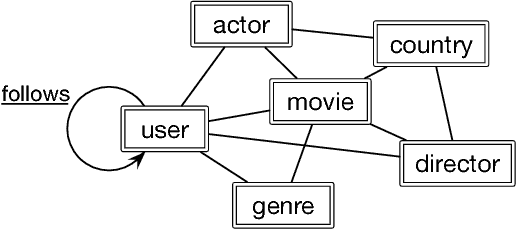

Heterogeneous information networks (HINs) are ubiquitous in real-world applications. In the meantime, network embedding has emerged as a convenient tool to mine and learn from networked data. As a result, it is of interest to develop HIN embedding methods. However, the heterogeneity in HINs introduces not only rich information but also potentially incompatible semantics, which poses special challenges to embedding learning in HINs. With the intention to preserve the rich yet potentially incompatible information in HIN embedding, we propose to study the problem of comprehensive transcription of heterogeneous information networks. The comprehensive transcription of HINs also provides an easy-to-use approach to unleash the power of HINs, since it requires no additional supervision, expertise, or feature engineering. To cope with the challenges in the comprehensive transcription of HINs, we propose the HEER algorithm, which embeds HINs via edge representations that are further coupled with properly-learned heterogeneous metrics. To corroborate the efficacy of HEER, we conducted experiments on two large-scale real-words datasets with an edge reconstruction task and multiple case studies. Experiment results demonstrate the effectiveness of the proposed HEER model and the utility of edge representations and heterogeneous metrics. The code and data are available at https://github.com/GentleZhu/HEER.
One-shot Information Extraction from Document Images using Neuro-Deductive Program Synthesis
Jun 06, 2019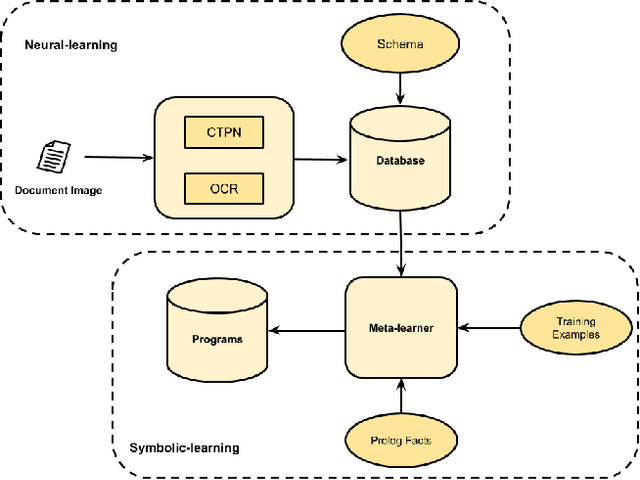


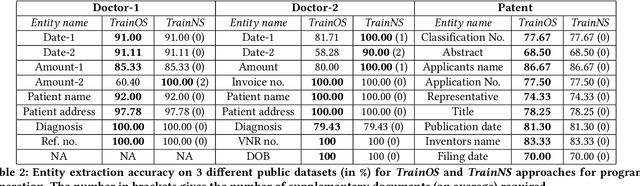
Our interest in this paper is in meeting a rapidly growing industrial demand for information extraction from images of documents such as invoices, bills, receipts etc. In practice users are able to provide a very small number of example images labeled with the information that needs to be extracted. We adopt a novel two-level neuro-deductive, approach where (a) we use pre-trained deep neural networks to populate a relational database with facts about each document-image; and (b) we use a form of deductive reasoning, related to meta-interpretive learning of transition systems to learn extraction programs: Given task-specific transitions defined using the entities and relations identified by the neural detectors and a small number of instances (usually 1, sometimes 2) of images and the desired outputs, a resource-bounded meta-interpreter constructs proofs for the instance(s) via logical deduction; a set of logic programs that extract each desired entity is easily synthesized from such proofs. In most cases a single training example together with a noisy-clone of itself suffices to learn a program-set that generalizes well on test documents, at which time the value of each entity is determined by a majority vote across its program-set. We demonstrate our two-level neuro-deductive approach on publicly available datasets ("Patent" and "Doctor's Bills") and also describe its use in a real-life industrial problem.
PUNCH: Positive UNlabelled Classification based information retrieval in Hyperspectral images
Apr 09, 2019
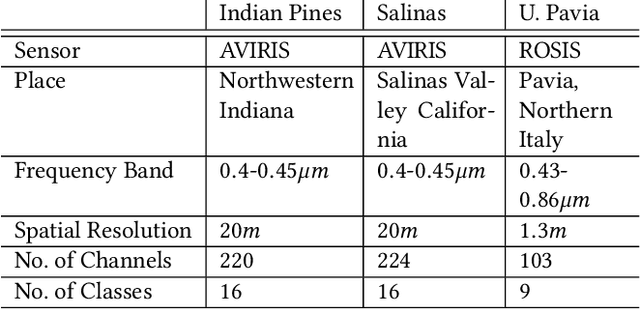
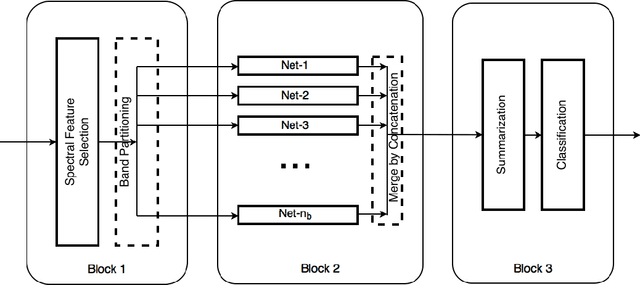

Hyperspectral images of land-cover captured by airborne or satellite-mounted sensors provide a rich source of information about the chemical composition of the materials present in a given place. This makes hyperspectral imaging an important tool for earth sciences, land-cover studies, and military and strategic applications. However, the scarcity of labeled training examples and spatial variability of spectral signature are two of the biggest challenges faced by hyperspectral image classification. In order to address these issues, we aim to develop a framework for material-agnostic information retrieval in hyperspectral images based on Positive-Unlabelled (PU) classification. Given a hyperspectral scene, the user labels some positive samples of a material he/she is looking for and our goal is to retrieve all the remaining instances of the query material in the scene. Additionally, we require the system to work equally well for any material in any scene without the user having to disclose the identity of the query material. This material-agnostic nature of the framework provides it with superior generalization abilities. We explore two alternative approaches to solve the hyperspectral image classification problem within this framework. The first approach is an adaptation of non-negative risk estimation based PU learning for hyperspectral data. The second approach is based on one-versus-all positive-negative classification where the negative class is approximately sampled using a novel spectral-spatial retrieval model. We propose two annotator models - uniform and blob - that represent the labelling patterns of a human annotator. We compare the performances of the proposed algorithms for each annotator model on three benchmark hyperspectral image datasets - Indian Pines, Pavia University and Salinas.
Energy-Efficient Multi-Orchestrator Mobile Edge Learning
Sep 02, 2021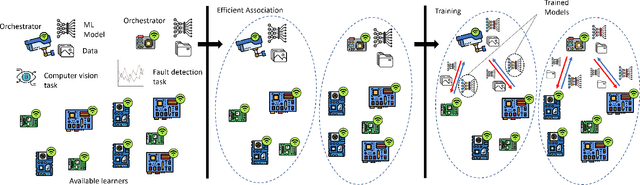
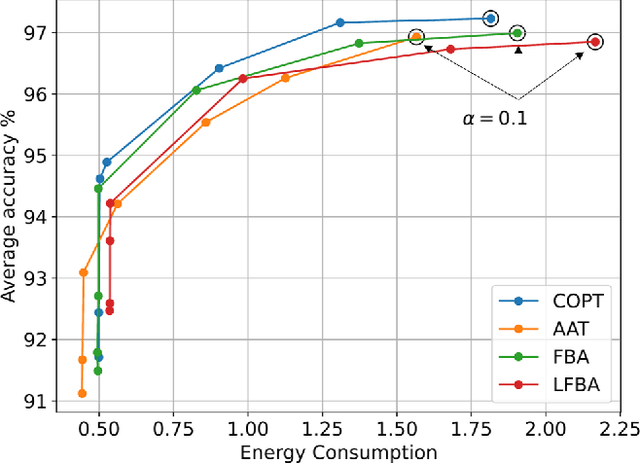
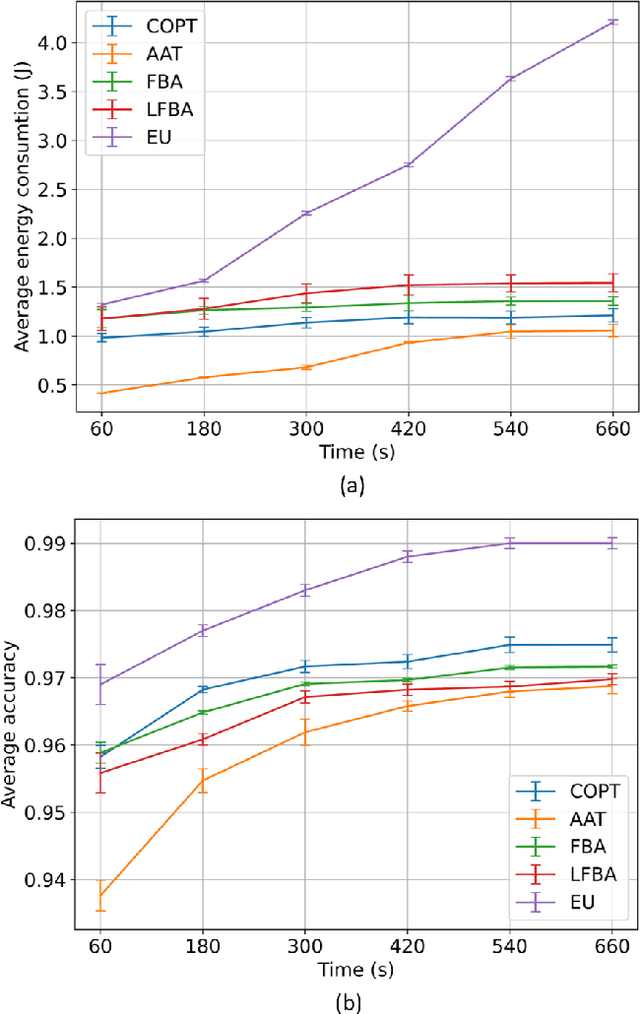
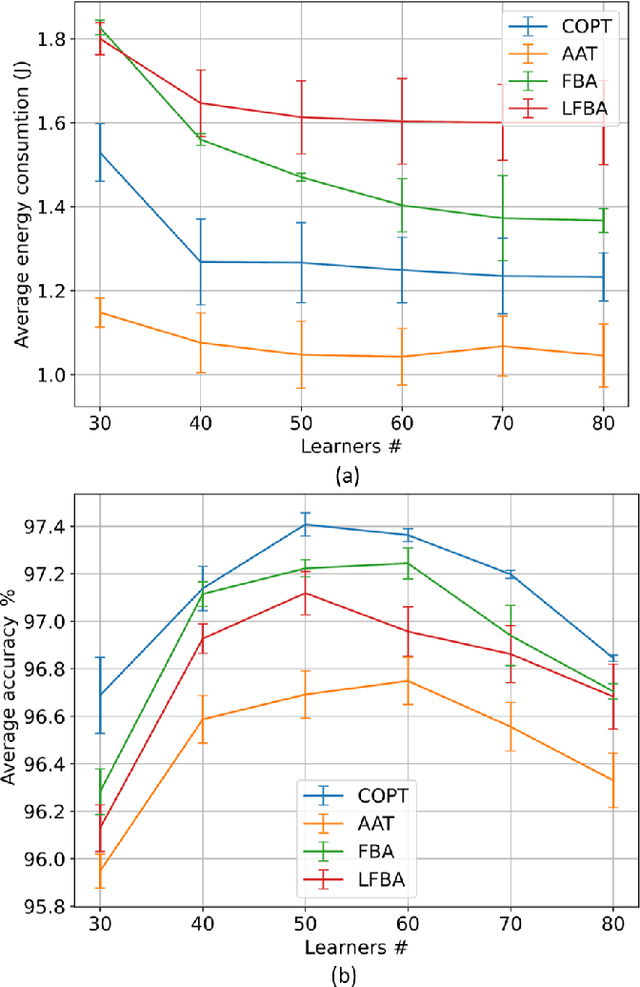
Mobile Edge Learning (MEL) is a collaborative learning paradigm that features distributed training of Machine Learning (ML) models over edge devices (e.g., IoT devices). In MEL, possible coexistence of multiple learning tasks with different datasets may arise. The heterogeneity in edge devices' capabilities will require the joint optimization of the learners-orchestrator association and task allocation. To this end, we aim to develop an energy-efficient framework for learners-orchestrator association and learning task allocation, in which each orchestrator gets associated with a group of learners with the same learning task based on their communication channel qualities and computational resources, and allocate the tasks accordingly. Therein, a multi objective optimization problem is formulated to minimize the total energy consumption and maximize the learning tasks' accuracy. However, solving such optimization problem requires centralization and the presence of the whole environment information at a single entity, which becomes impractical in large-scale systems. To reduce the solution complexity and to enable solution decentralization, we propose lightweight heuristic algorithms that can achieve near-optimal performance and facilitate the trade-offs between energy consumption, accuracy, and solution complexity. Simulation results show that the proposed approaches reduce the energy consumption significantly while executing multiple learning tasks compared to recent state-of-the-art methods.
Dealing with Typos for BERT-based Passage Retrieval and Ranking
Aug 27, 2021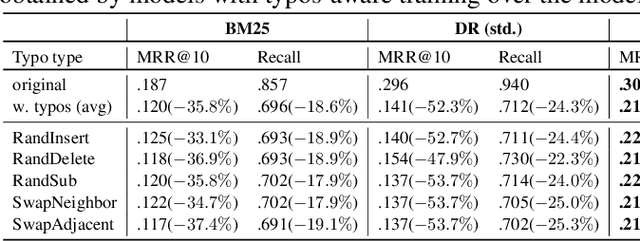
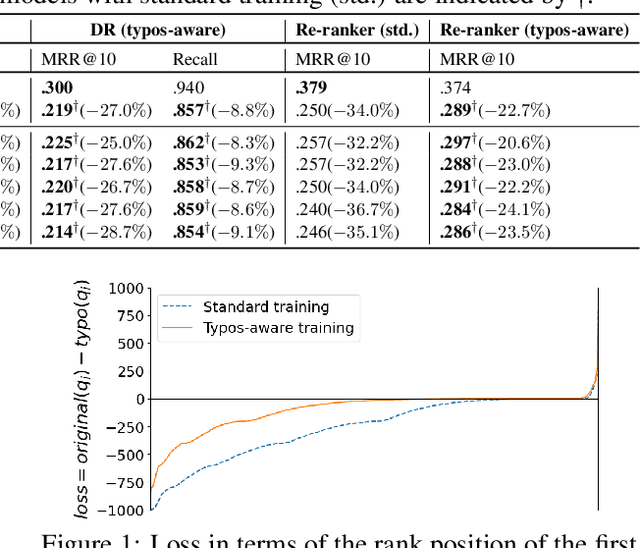
Passage retrieval and ranking is a key task in open-domain question answering and information retrieval. Current effective approaches mostly rely on pre-trained deep language model-based retrievers and rankers. These methods have been shown to effectively model the semantic matching between queries and passages, also in presence of keyword mismatch, i.e. passages that are relevant to a query but do not contain important query tokens. In this paper we consider the Dense Retriever (DR), a passage retrieval method, and the BERT re-ranker, a popular passage re-ranking method. In this context, we formally investigate how these models respond and adapt to a specific type of keyword mismatch -- that caused by keyword typos occurring in queries. Through empirical investigation, we find that typos can lead to a significant drop in retrieval and ranking effectiveness. We then propose a simple typos-aware training framework for DR and BERT re-ranker to address this issue. Our experimental results on the MS MARCO passage ranking dataset show that, with our proposed typos-aware training, DR and BERT re-ranker can become robust to typos in queries, resulting in significantly improved effectiveness compared to models trained without appropriately accounting for typos.