 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
MULTIMODAL ANALYSIS: Informed content estimation and audio source separation
Apr 27, 2021
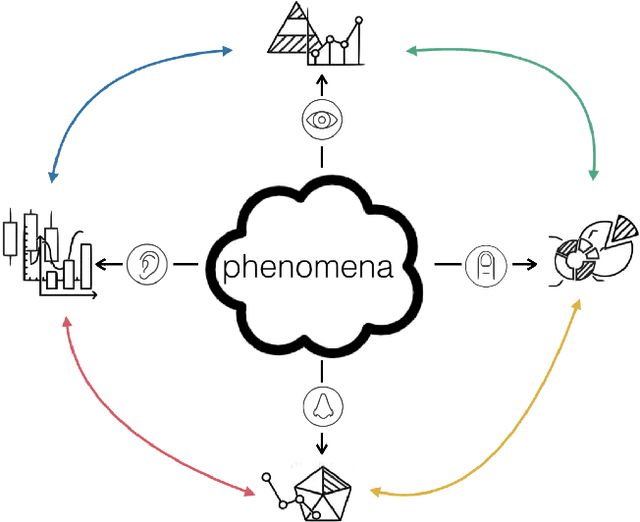
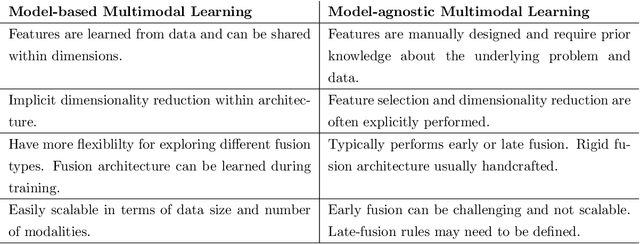
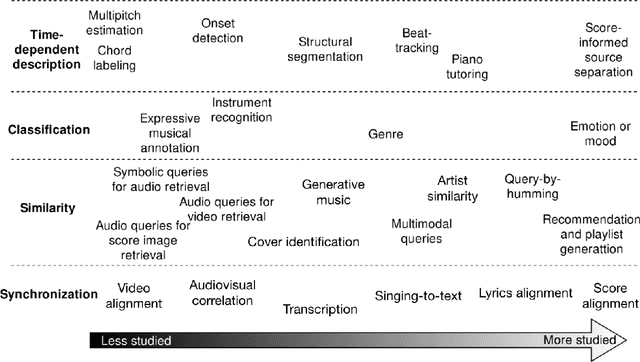
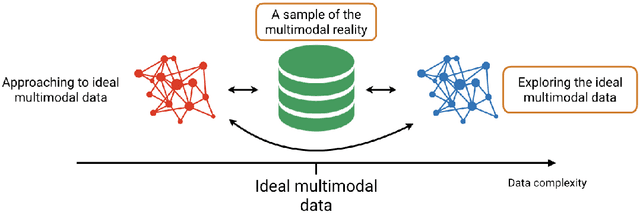
This dissertation proposes the study of multimodal learning in the context of musical signals. Throughout, we focus on the interaction between audio signals and text information. Among the many text sources related to music that can be used (e.g. reviews, metadata, or social network feedback), we concentrate on lyrics. The singing voice directly connects the audio signal and the text information in a unique way, combining melody and lyrics where a linguistic dimension complements the abstraction of musical instruments. Our study focuses on the audio and lyrics interaction for targeting source separation and informed content estimation.
A Reinforcement Learning Approach for GNSS Spoofing Attack Detection of Autonomous Vehicles
Aug 19, 2021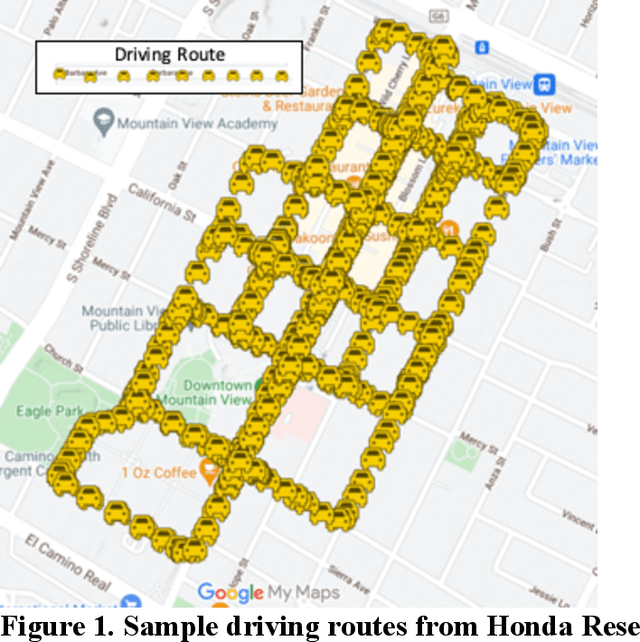
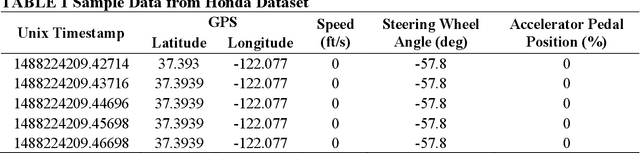
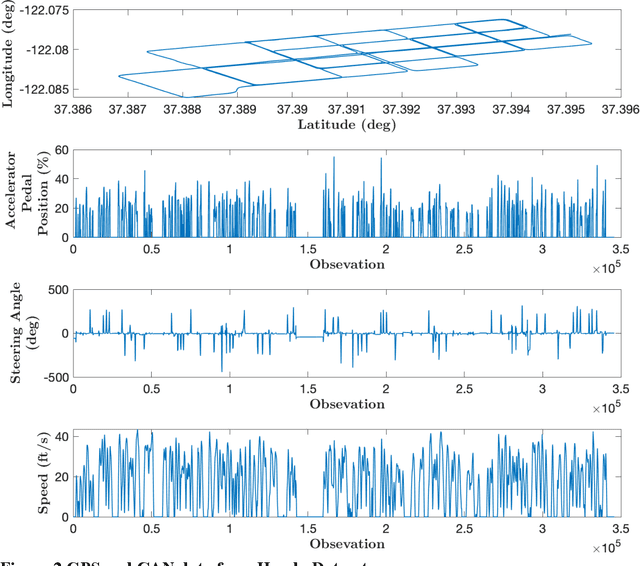
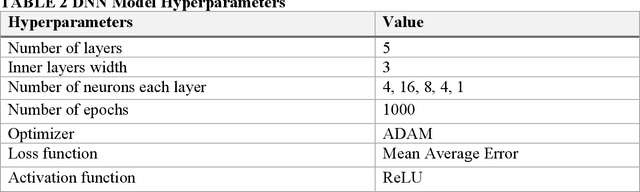
A resilient and robust positioning, navigation, and timing (PNT) system is a necessity for the navigation of autonomous vehicles (AVs). Global Navigation Satelite System (GNSS) provides satellite-based PNT services. However, a spoofer can temper an authentic GNSS signal and could transmit wrong position information to an AV. Therefore, a GNSS must have the capability of real-time detection and feedback-correction of spoofing attacks related to PNT receivers, whereby it will help the end-user (autonomous vehicle in this case) to navigate safely if it falls into any compromises. This paper aims to develop a deep reinforcement learning (RL)-based turn-by-turn spoofing attack detection using low-cost in-vehicle sensor data. We have utilized Honda Driving Dataset to create attack and non-attack datasets, develop a deep RL model, and evaluate the performance of the RL-based attack detection model. We find that the accuracy of the RL model ranges from 99.99% to 100%, and the recall value is 100%. However, the precision ranges from 93.44% to 100%, and the f1 score ranges from 96.61% to 100%. Overall, the analyses reveal that the RL model is effective in turn-by-turn spoofing attack detection.
InfoGraph: Unsupervised and Semi-supervised Graph-Level Representation Learning via Mutual Information Maximization
Jul 31, 2019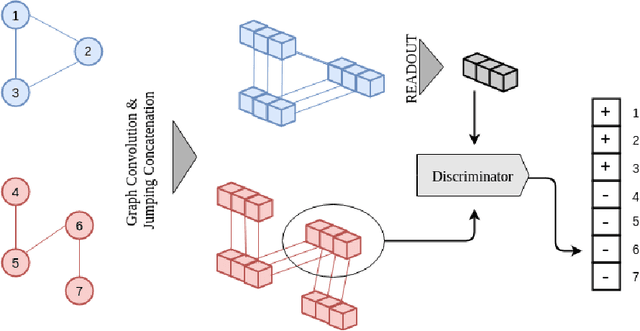
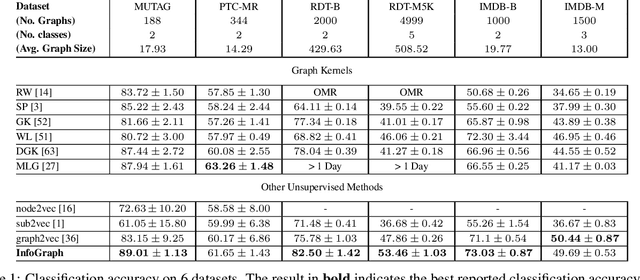
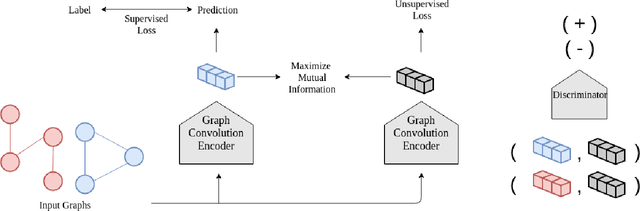

This paper studies learning the representations of whole graphs in both unsupervised and semi-supervised scenarios. Graph-level representations are critical in a variety of real-world applications such as predicting the properties of molecules and community analysis in social networks. Traditional graph kernel based methods are simple, yet effective for obtaining fixed-length representations for graphs but they suffer from poor generalization due to hand-crafted designs. There are also some recent methods based on language models (e.g. graph2vec) but they tend to only consider certain substructures (e.g. subtrees) as graph representatives. Inspired by recent progress of unsupervised representation learning, in this paper we proposed a novel method called InfoGraph for learning graph-level representations. We maximize the mutual information between the graph-level representation and the representations of substructures of different scales (e.g., nodes, edges, triangles). By doing so, the graph-level representations encode aspects of the data that are shared across different scales of substructures. Furthermore, we further propose InfoGraph*, an extension of InfoGraph for semi-supervised scenarios. InfoGraph* maximizes the mutual information between unsupervised graph representations learned by InfoGraph and the representations learned by existing supervised methods. As a result, the supervised encoder learns from unlabeled data while preserving the latent semantic space favored by the current supervised task. Experimental results on the tasks of graph classification and molecular property prediction show that InfoGraph is superior to state-of-the-art baselines and InfoGraph* can achieve performance competitive with state-of-the-art semi-supervised models.
SVSNet: An End-to-end Speaker Voice Similarity Assessment Model
Jul 20, 2021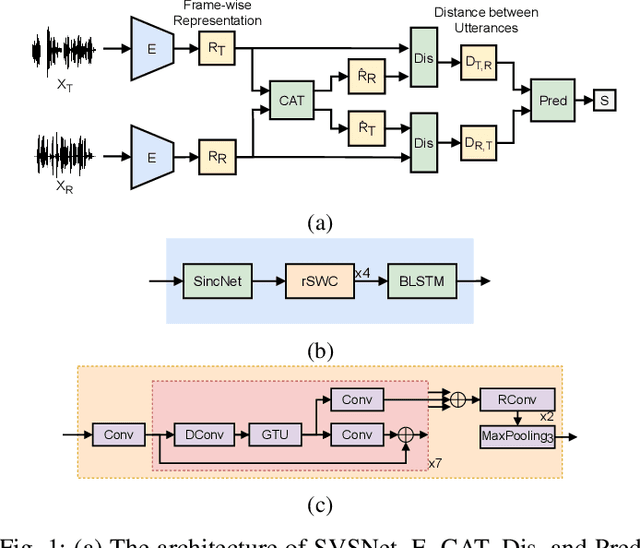
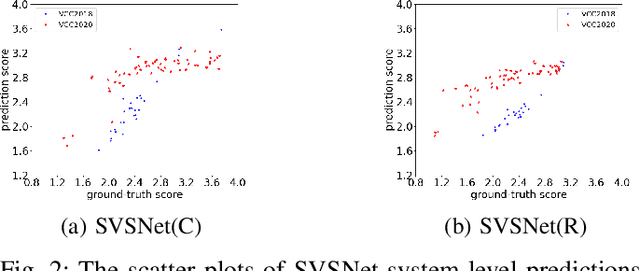
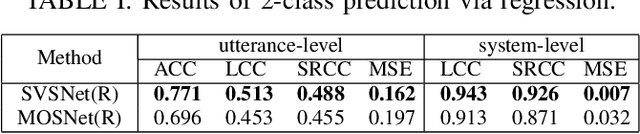
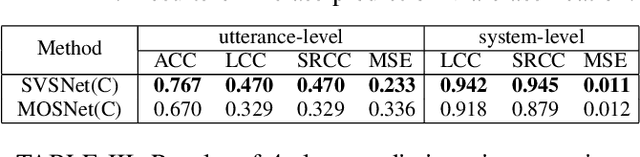
Neural evaluation metrics derived for numerous speech generation tasks have recently attracted great attention. In this paper, we propose SVSNet, the first end-to-end neural network model to assess the speaker voice similarity between natural speech and synthesized speech. Unlike most neural evaluation metrics that use hand-crafted features, SVSNet directly takes the raw waveform as input to more completely utilize speech information for prediction. SVSNet consists of encoder, co-attention, distance calculation, and prediction modules and is trained in an end-to-end manner. The experimental results on the Voice Conversion Challenge 2018 and 2020 (VCC2018 and VCC2020) datasets show that SVSNet notably outperforms well-known baseline systems in the assessment of speaker similarity at the utterance and system levels.
Towards Sample-Optimal Compressive Phase Retrieval with Sparse and Generative Priors
Jun 29, 2021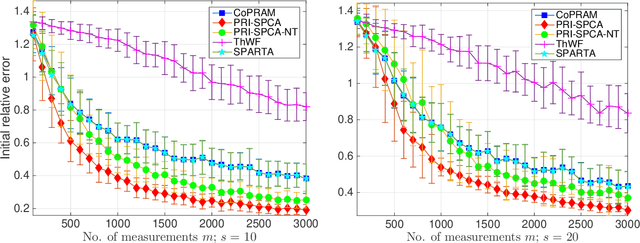
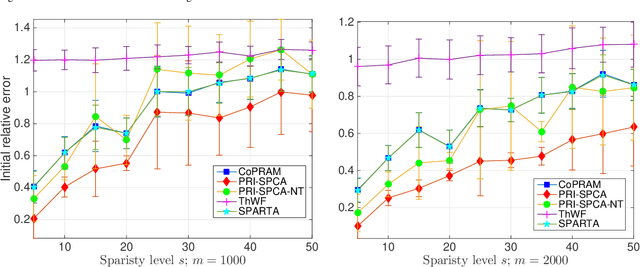
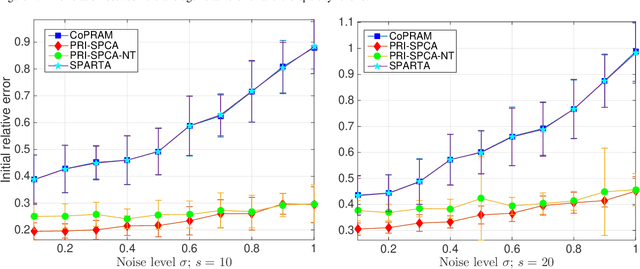
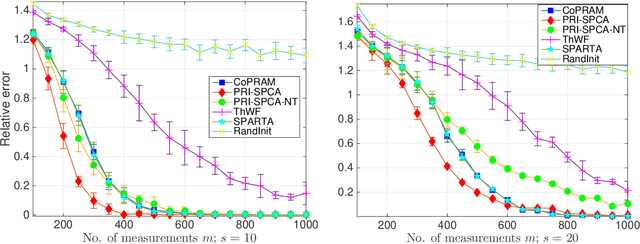
Compressive phase retrieval is a popular variant of the standard compressive sensing problem, in which the measurements only contain magnitude information. In this paper, motivated by recent advances in deep generative models, we provide recovery guarantees with order-optimal sample complexity bounds for phase retrieval with generative priors. We first show that when using i.i.d. Gaussian measurements and an $L$-Lipschitz continuous generative model with bounded $k$-dimensional inputs, roughly $O(k \log L)$ samples suffice to guarantee that the signal is close to any vector that minimizes an amplitude-based empirical loss function. Attaining this sample complexity with a practical algorithm remains a difficult challenge, and a popular spectral initialization method has been observed to pose a major bottleneck. To partially address this, we further show that roughly $O(k \log L)$ samples ensure sufficient closeness between the signal and any {\em globally optimal} solution to an optimization problem designed for spectral initialization (though finding such a solution may still be challenging). We adapt this result to sparse phase retrieval, and show that $O(s \log n)$ samples are sufficient for a similar guarantee when the underlying signal is $s$-sparse and $n$-dimensional, matching an information-theoretic lower bound. While our guarantees do not directly correspond to a practical algorithm, we propose a practical spectral initialization method motivated by our findings, and experimentally observe significant performance gains over various existing spectral initialization methods of sparse phase retrieval.
Fairness-Aware Unsupervised Feature Selection
Jun 04, 2021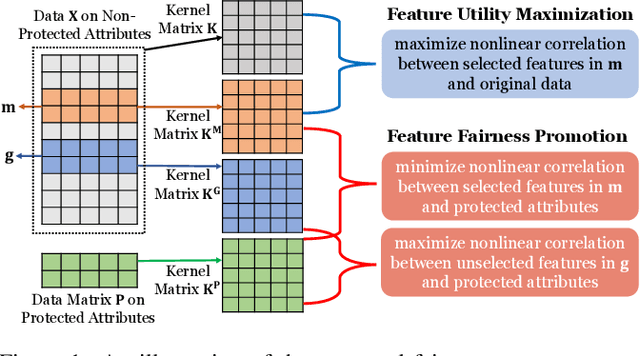

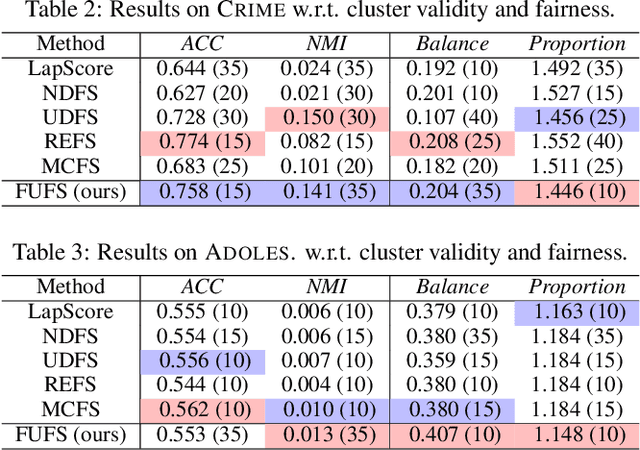
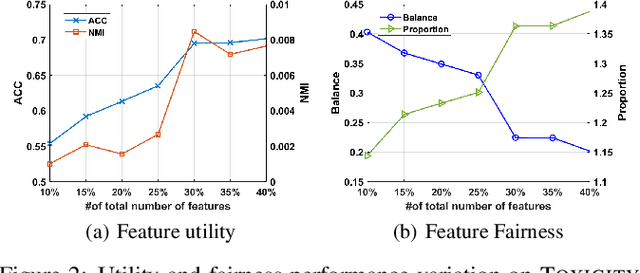
Feature selection is a prevalent data preprocessing paradigm for various learning tasks. Due to the expensive cost of acquiring supervision information, unsupervised feature selection sparks great interests recently. However, existing unsupervised feature selection algorithms do not have fairness considerations and suffer from a high risk of amplifying discrimination by selecting features that are over associated with protected attributes such as gender, race, and ethnicity. In this paper, we make an initial investigation of the fairness-aware unsupervised feature selection problem and develop a principled framework, which leverages kernel alignment to find a subset of high-quality features that can best preserve the information in the original feature space while being minimally correlated with protected attributes. Specifically, different from the mainstream in-processing debiasing methods, our proposed framework can be regarded as a model-agnostic debiasing strategy that eliminates biases and discrimination before downstream learning algorithms are involved. Experimental results on multiple real-world datasets demonstrate that our framework achieves a good trade-off between utility maximization and fairness promotion.
Quantum Continual Learning Overcoming Catastrophic Forgetting
Aug 05, 2021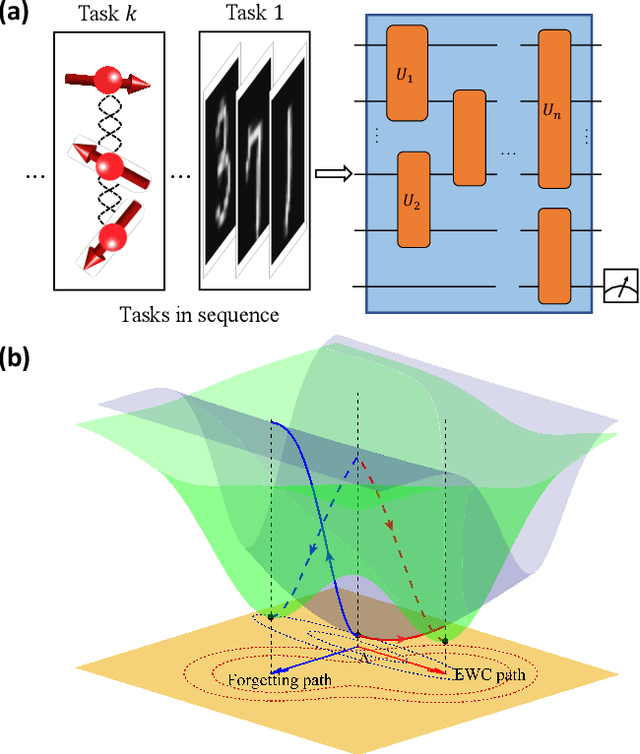
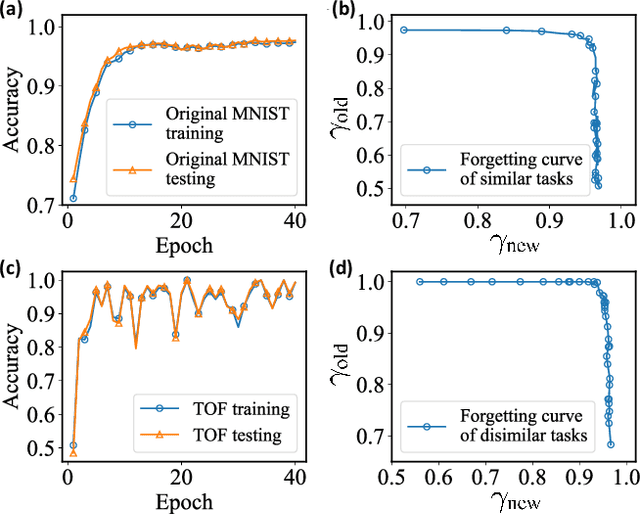
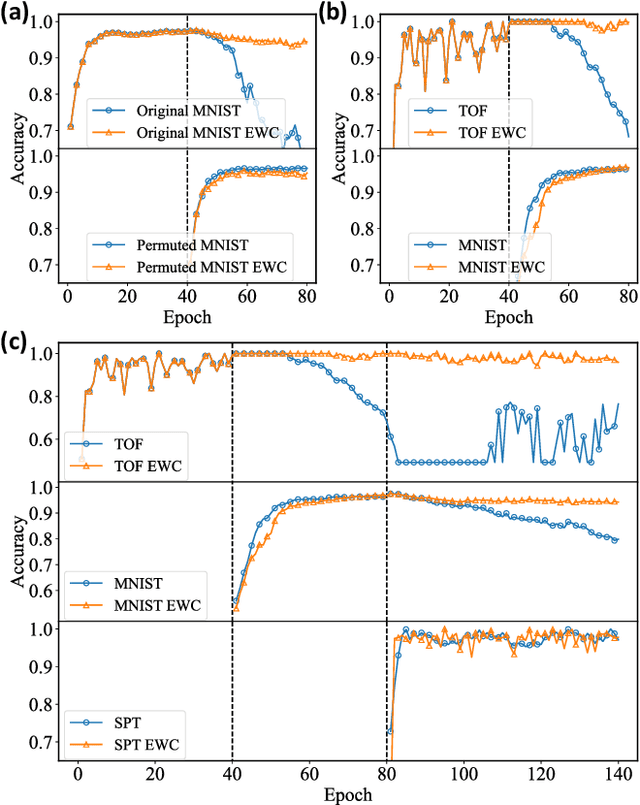
Catastrophic forgetting describes the fact that machine learning models will likely forget the knowledge of previously learned tasks after the learning process of a new one. It is a vital problem in the continual learning scenario and recently has attracted tremendous concern across different communities. In this paper, we explore the catastrophic forgetting phenomena in the context of quantum machine learning. We find that, similar to those classical learning models based on neural networks, quantum learning systems likewise suffer from such forgetting problem in classification tasks emerging from various application scenes. We show that based on the local geometrical information in the loss function landscape of the trained model, a uniform strategy can be adapted to overcome the forgetting problem in the incremental learning setting. Our results uncover the catastrophic forgetting phenomena in quantum machine learning and offer a practical method to overcome this problem, which opens a new avenue for exploring potential quantum advantages towards continual learning.
A Model-Agnostic Algorithm for Bayes Error Determination in Binary Classification
Jul 24, 2021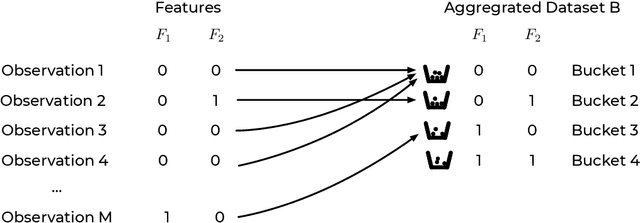

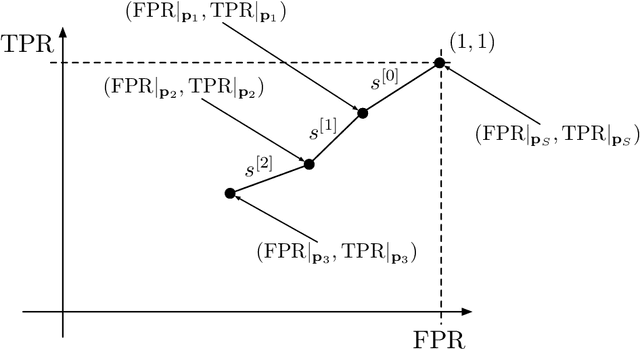
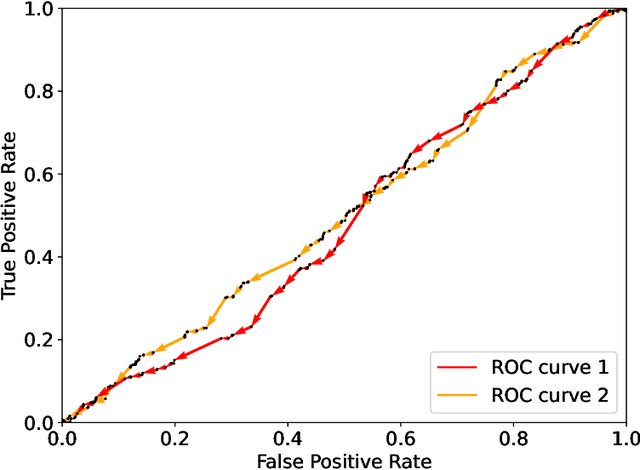
This paper presents the intrinsic limit determination algorithm (ILD Algorithm), a novel technique to determine the best possible performance, measured in terms of the AUC (area under the ROC curve) and accuracy, that can be obtained from a specific dataset in a binary classification problem with categorical features {\sl regardless} of the model used. This limit, namely the Bayes error, is completely independent of any model used and describes an intrinsic property of the dataset. The ILD algorithm thus provides important information regarding the prediction limits of any binary classification algorithm when applied to the considered dataset. In this paper the algorithm is described in detail, its entire mathematical framework is presented and the pseudocode is given to facilitate its implementation. Finally, an example with a real dataset is given.
Context-aware Adversarial Training for Name Regularity Bias in Named Entity Recognition
Jul 24, 2021In this work, we examine the ability of NER models to use contextual information when predicting the type of an ambiguous entity. We introduce NRB, a new testbed carefully designed to diagnose Name Regularity Bias of NER models. Our results indicate that all state-of-the-art models we tested show such a bias; BERT fine-tuned models significantly outperforming feature-based (LSTM-CRF) ones on NRB, despite having comparable (sometimes lower) performance on standard benchmarks. To mitigate this bias, we propose a novel model-agnostic training method that adds learnable adversarial noise to some entity mentions, thus enforcing models to focus more strongly on the contextual signal, leading to significant gains on NRB. Combining it with two other training strategies, data augmentation and parameter freezing, leads to further gains.
* MIT Press\TACL 2021\Presented at ACL 2021 This is the exact same content of the TACL version, except the figures and tables are better aligned
Contrastive Identification of Covariate Shift in Image Data
Aug 19, 2021



Identifying covariate shift is crucial for making machine learning systems robust in the real world and for detecting training data biases that are not reflected in test data. However, detecting covariate shift is challenging, especially when the data consists of high-dimensional images, and when multiple types of localized covariate shift affect different subspaces of the data. Although automated techniques can be used to detect the existence of covariate shift, our goal is to help human users characterize the extent of covariate shift in large image datasets with interfaces that seamlessly integrate information obtained from the detection algorithms. In this paper, we design and evaluate a new visual interface that facilitates the comparison of the local distributions of training and test data. We conduct a quantitative user study on multi-attribute facial data to compare two different learned low-dimensional latent representations (pretrained ImageNet CNN vs. density ratio) and two user analytic workflows (nearest-neighbor vs. cluster-to-cluster). Our results indicate that the latent representation of our density ratio model, combined with a nearest-neighbor comparison, is the most effective at helping humans identify covariate shift.