 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Reference Service Model for Federated Identity Management
Aug 15, 2021
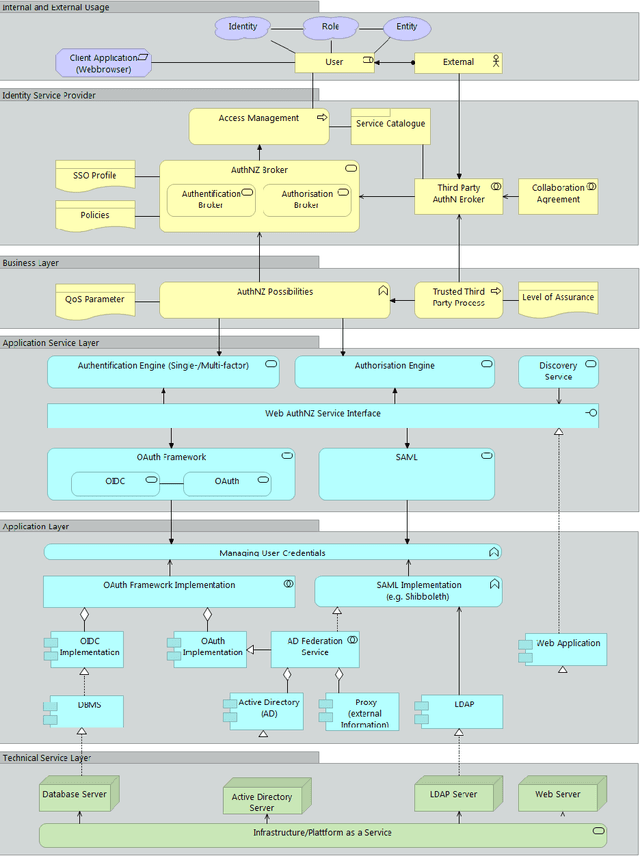
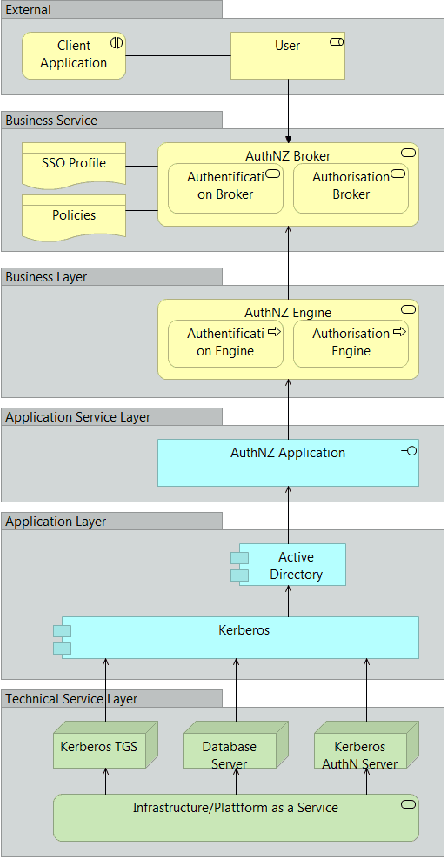
With the pandemic of COVID-19, people around the world increasingly work from home. Each natural person typically has several digital identities with different associated information. During the last years, various identity and access management approaches have gained attraction, helping for example to access other organization's services within trust boundaries. The resulting heterogeneity creates a high complexity to differentiate between these approaches and scenarios as participating entity; combining them is even harder. Last but not least, various actors have a different understanding or perspective of the terms, like 'service', in this context. Our paper describes a reference service with standard components in generic federated identity management. This is utilized with modern Enterprise Architecture using the framework ArchiMate. The proposed universal federated identity management service model (FIMSM) is applied to describe various federated identity management scenarios in a generic service-oriented way. The presented reference design is approved in multiple aspects and is easily applicable in numerous scenarios.
Spatial-Temporal Correlation and Topology Learning for Person Re-Identification in Videos
Apr 15, 2021
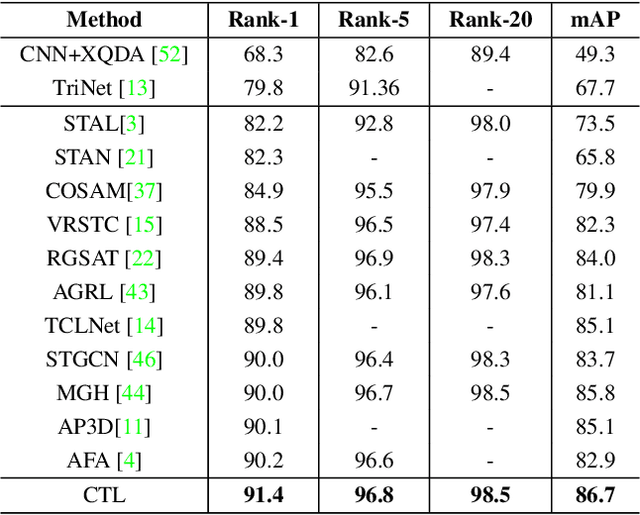
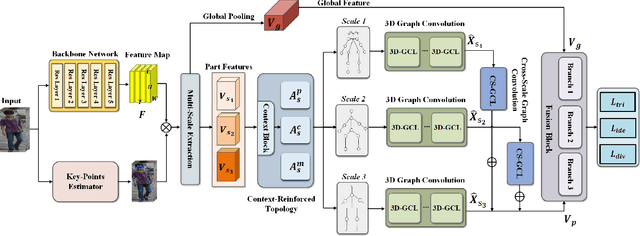
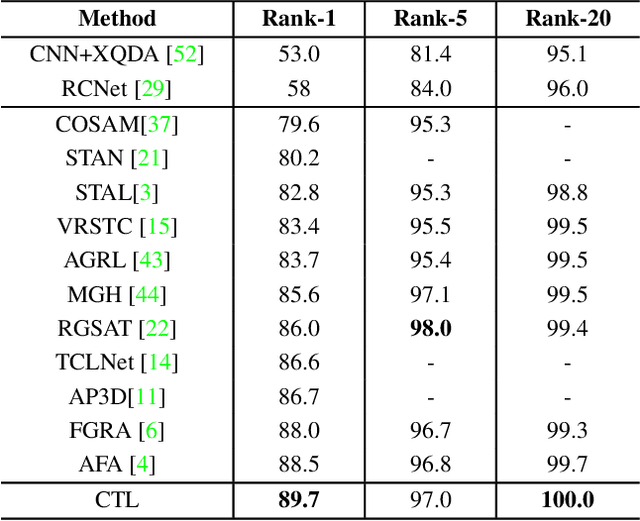
Video-based person re-identification aims to match pedestrians from video sequences across non-overlapping camera views. The key factor for video person re-identification is to effectively exploit both spatial and temporal clues from video sequences. In this work, we propose a novel Spatial-Temporal Correlation and Topology Learning framework (CTL) to pursue discriminative and robust representation by modeling cross-scale spatial-temporal correlation. Specifically, CTL utilizes a CNN backbone and a key-points estimator to extract semantic local features from human body at multiple granularities as graph nodes. It explores a context-reinforced topology to construct multi-scale graphs by considering both global contextual information and physical connections of human body. Moreover, a 3D graph convolution and a cross-scale graph convolution are designed, which facilitate direct cross-spacetime and cross-scale information propagation for capturing hierarchical spatial-temporal dependencies and structural information. By jointly performing the two convolutions, CTL effectively mines comprehensive clues that are complementary with appearance information to enhance representational capacity. Extensive experiments on two video benchmarks have demonstrated the effectiveness of the proposed method and the state-of-the-art performance.
The Atlas of Lane Changes: Investigating Location-dependent Lane Change Behaviors Using Measurement Data from a Customer Fleet
Jul 09, 2021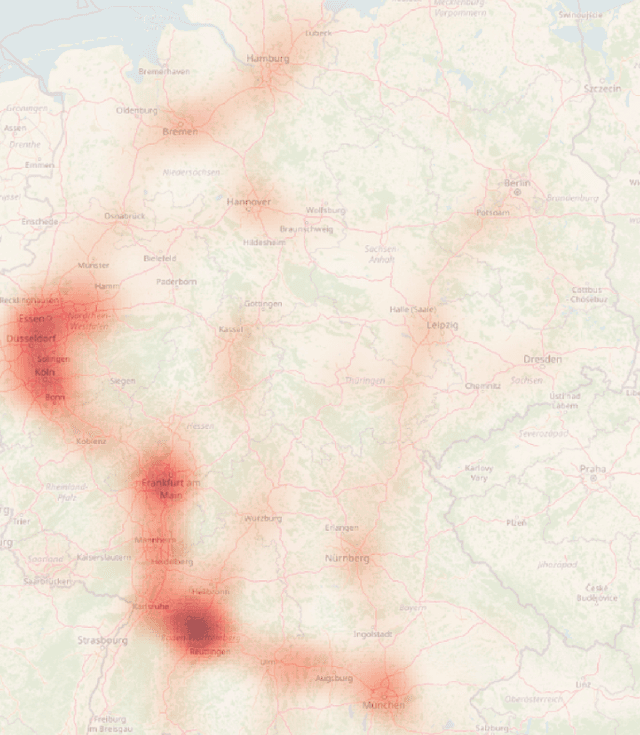
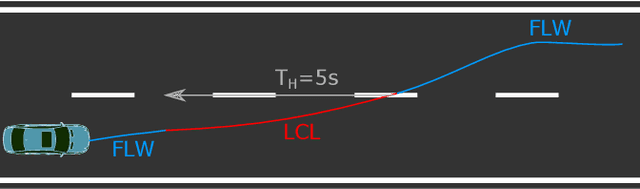
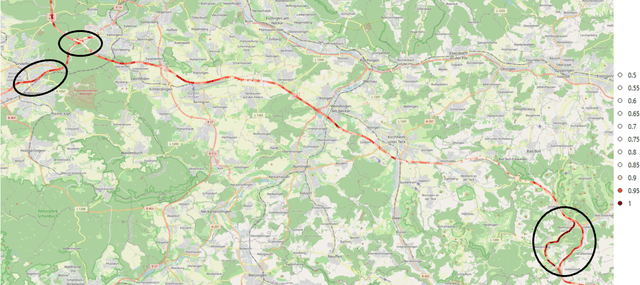
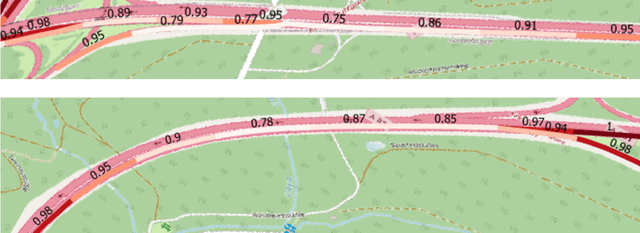
The prediction of surrounding traffic participants behavior is a crucial and challenging task for driver assistance and autonomous driving systems. Today's approaches mainly focus on modeling dynamic aspects of the traffic situation and try to predict traffic participants behavior based on this. In this article we take a first step towards extending this common practice by calculating location-specific a-priori lane change probabilities. The idea behind this is straight forward: The driving behavior of humans may vary in exactly the same traffic situation depending on the respective location. E.g. drivers may ask themselves: Should I pass the truck in front of me immediately or should I wait until reaching the less curvy part of my route lying only a few kilometers ahead? Although, such information is far away from allowing behavior prediction on its own, it is obvious that today's approaches will greatly benefit when incorporating such location-specific a-priori probabilities into their predictions. For example, our investigations show that highway interchanges tend to enhance driver's motivation to perform lane changes, whereas curves seem to have lane change-dampening effects. Nevertheless, the investigation of all considered local conditions shows that superposition of various effects can lead to unexpected probabilities at some locations. We thus suggest dynamically constructing and maintaining a lane change probability map based on customer fleet data in order to support onboard prediction systems with additional information. For deriving reliable lane change probabilities a broad customer fleet is the key to success.
Faces in the Wild: Efficient Gender Recognition in Surveillance Conditions
Jul 14, 2021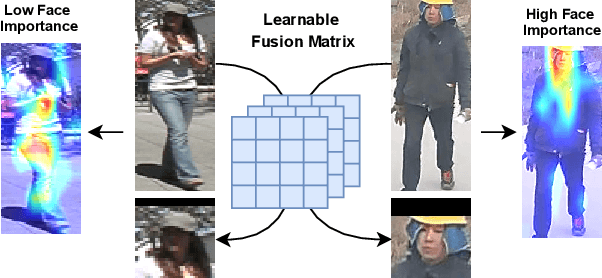
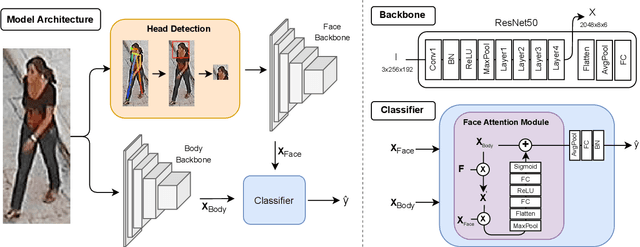


Soft biometrics inference in surveillance scenarios is a topic of interest for various applications, particularly in security-related areas. However, soft biometric analysis is not extensively reported in wild conditions. In particular, previous works on gender recognition report their results in face datasets, with relatively good image quality and frontal poses. Given the uncertainty of the availability of the facial region in wild conditions, we consider that these methods are not adequate for surveillance settings. To overcome these limitations, we: 1) present frontal and wild face versions of three well-known surveillance datasets; and 2) propose a model that effectively and dynamically combines facial and body information, which makes it suitable for gender recognition in wild conditions. The frontal and wild face datasets derive from widely used Pedestrian Attribute Recognition (PAR) sets (PETA, PA-100K, and RAP), using a pose-based approach to filter the frontal samples and facial regions. This approach retrieves the facial region of images with varying image/subject conditions, where the state-of-the-art face detectors often fail. Our model combines facial and body information through a learnable fusion matrix and a channel-attention sub-network, focusing on the most influential body parts according to the specific image/subject features. We compare it with five PAR methods, consistently obtaining state-of-the-art results on gender recognition, and reducing the prediction errors by up to 24% in frontal samples. The announced PAR datasets versions and model serve as the basis for wild soft biometrics classification and are available in https://github.com/Tiago-Roxo.
PIMNet: A Parallel, Iterative and Mimicking Network for Scene Text Recognition
Sep 09, 2021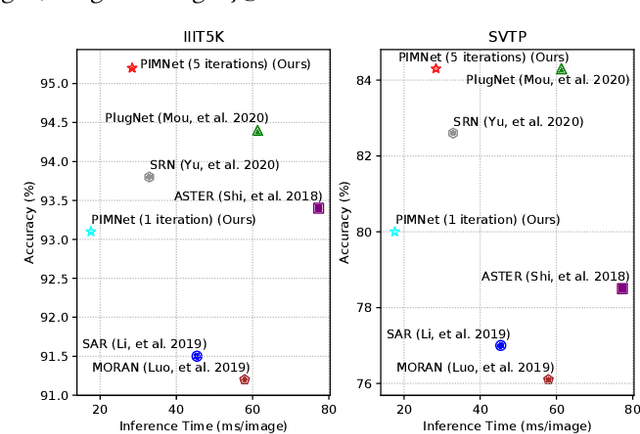
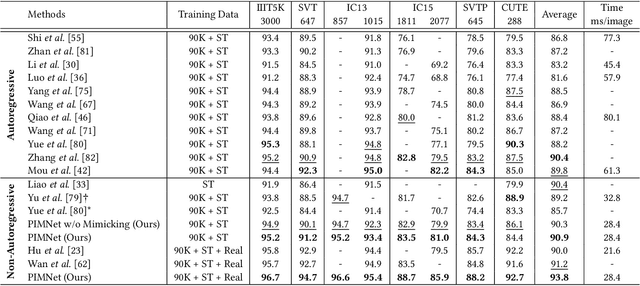
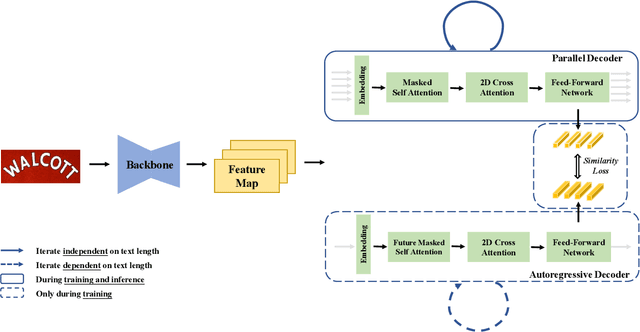

Nowadays, scene text recognition has attracted more and more attention due to its various applications. Most state-of-the-art methods adopt an encoder-decoder framework with attention mechanism, which generates text autoregressively from left to right. Despite the convincing performance, the speed is limited because of the one-by-one decoding strategy. As opposed to autoregressive models, non-autoregressive models predict the results in parallel with a much shorter inference time, but the accuracy falls behind the autoregressive counterpart considerably. In this paper, we propose a Parallel, Iterative and Mimicking Network (PIMNet) to balance accuracy and efficiency. Specifically, PIMNet adopts a parallel attention mechanism to predict the text faster and an iterative generation mechanism to make the predictions more accurate. In each iteration, the context information is fully explored. To improve learning of the hidden layer, we exploit the mimicking learning in the training phase, where an additional autoregressive decoder is adopted and the parallel decoder mimics the autoregressive decoder with fitting outputs of the hidden layer. With the shared backbone between the two decoders, the proposed PIMNet can be trained end-to-end without pre-training. During inference, the branch of the autoregressive decoder is removed for a faster speed. Extensive experiments on public benchmarks demonstrate the effectiveness and efficiency of PIMNet. Our code will be available at https://github.com/Pay20Y/PIMNet.
Recalling Holistic Information for Semantic Segmentation
Nov 24, 2016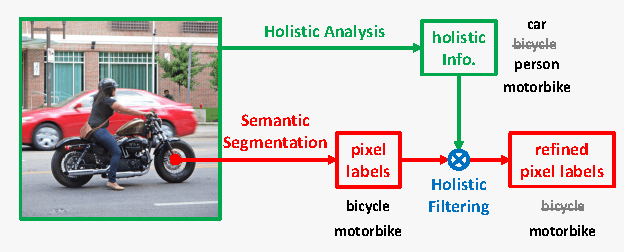
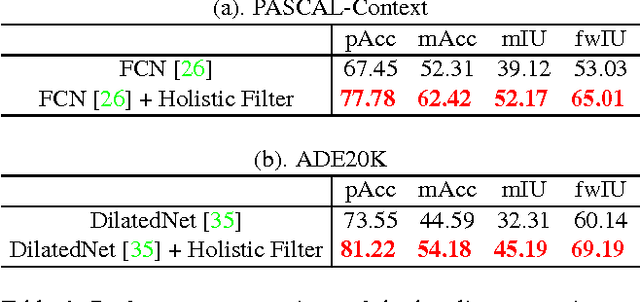
Semantic segmentation requires a detailed labeling of image pixels by object category. Information derived from local image patches is necessary to describe the detailed shape of individual objects. However, this information is ambiguous and can result in noisy labels. Global inference of image content can instead capture the general semantic concepts present. We advocate that high-recall holistic inference of image concepts provides valuable information for detailed pixel labeling. We build a two-stream neural network architecture that facilitates information flow from holistic information to local pixels, while keeping common image features shared among the low-level layers of both the holistic analysis and segmentation branches. We empirically evaluate our network on four standard semantic segmentation datasets. Our network obtains state-of-the-art performance on PASCAL-Context and NYUDv2, and ablation studies verify its effectiveness on ADE20K and SIFT-Flow.
Hard Clusters Maximize Mutual Information
Aug 17, 2016

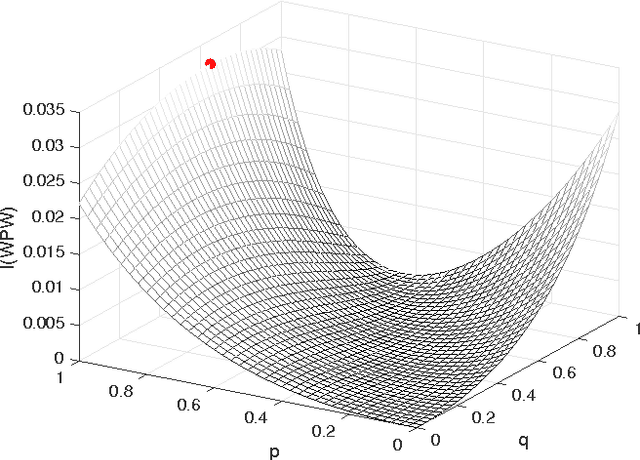
In this paper, we investigate mutual information as a cost function for clustering, and show in which cases hard, i.e., deterministic, clusters are optimal. Using convexity properties of mutual information, we show that certain formulations of the information bottleneck problem are solved by hard clusters. Similarly, hard clusters are optimal for the information-theoretic co-clustering problem that deals with simultaneous clustering of two dependent data sets. If both data sets have to be clustered using the same cluster assignment, hard clusters are not optimal in general. We point at interesting and practically relevant special cases of this so-called pairwise clustering problem, for which we can either prove or have evidence that hard clusters are optimal. Our results thus show that one can relax the otherwise combinatorial hard clustering problem to a real-valued optimization problem with the same global optimum.
AutoSmart: An Efficient and Automatic Machine Learning framework for Temporal Relational Data
Sep 09, 2021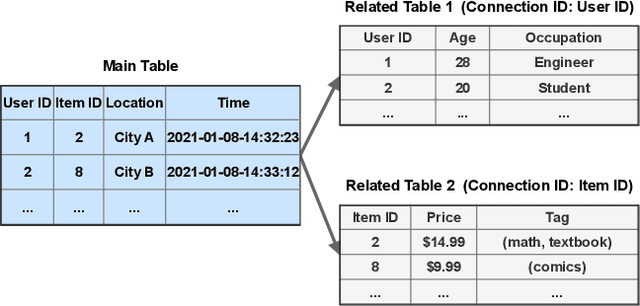

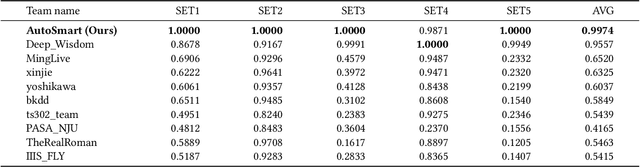
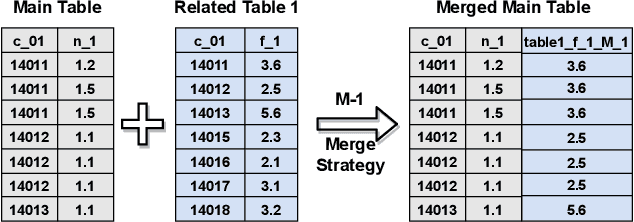
Temporal relational data, perhaps the most commonly used data type in industrial machine learning applications, needs labor-intensive feature engineering and data analyzing for giving precise model predictions. An automatic machine learning framework is needed to ease the manual efforts in fine-tuning the models so that the experts can focus more on other problems that really need humans' engagement such as problem definition, deployment, and business services. However, there are three main challenges for building automatic solutions for temporal relational data: 1) how to effectively and automatically mining useful information from the multiple tables and the relations from them? 2) how to be self-adjustable to control the time and memory consumption within a certain budget? and 3) how to give generic solutions to a wide range of tasks? In this work, we propose our solution that successfully addresses the above issues in an end-to-end automatic way. The proposed framework, AutoSmart, is the winning solution to the KDD Cup 2019 of the AutoML Track, which is one of the largest AutoML competition to date (860 teams with around 4,955 submissions). The framework includes automatic data processing, table merging, feature engineering, and model tuning, with a time\&memory controller for efficiently and automatically formulating the models. The proposed framework outperforms the baseline solution significantly on several datasets in various domains.
End-to-end Learning of a Constellation Shape Robust to Variations in SNR and Laser Linewidth
Jun 01, 2021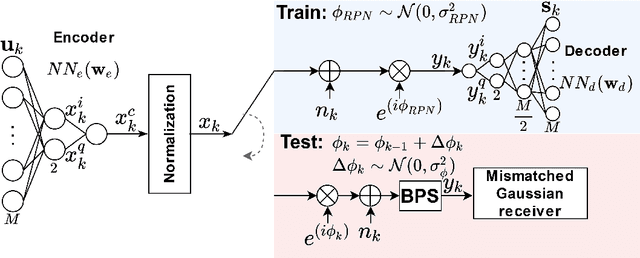
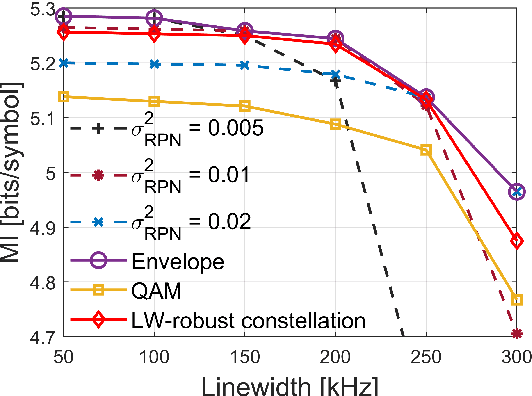
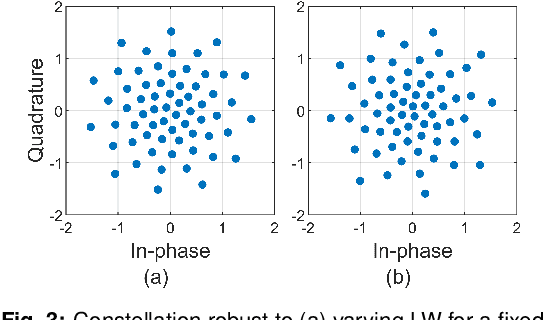
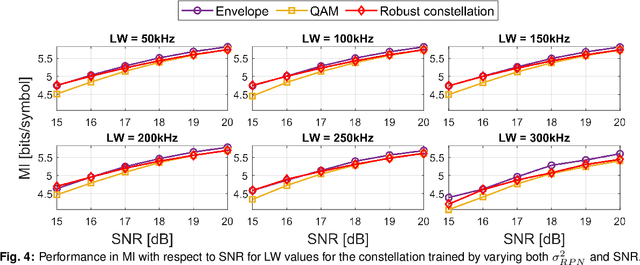
We propose an autoencoder-based geometric shaping that learns a constellation robust to SNR and laser linewidth estimation errors. This constellation maintains shaping gain in mutual information (up to 0.3 bits/symbol) with respect to QAM over various SNR and laser linewidth values.
Hierarchical Object-to-Zone Graph for Object Navigation
Sep 09, 2021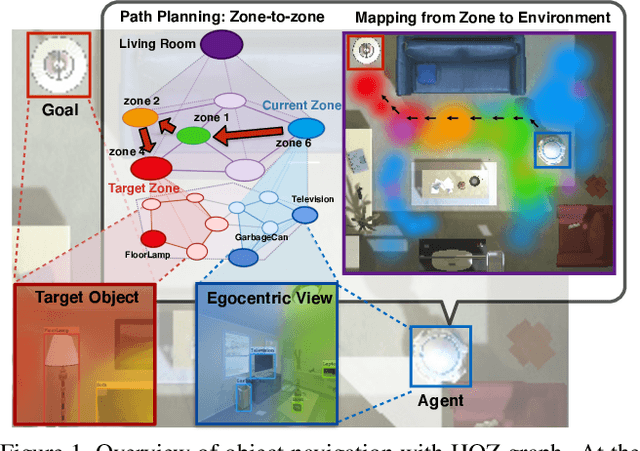
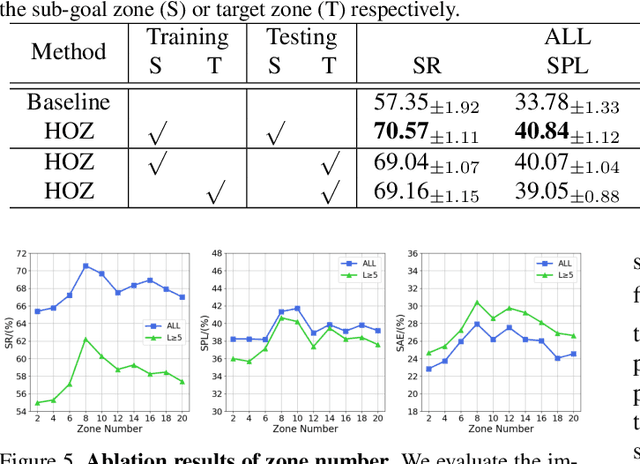
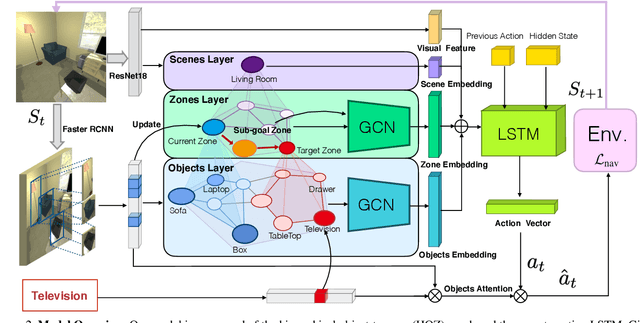
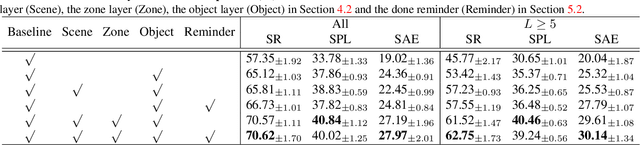
The goal of object navigation is to reach the expected objects according to visual information in the unseen environments. Previous works usually implement deep models to train an agent to predict actions in real-time. However, in the unseen environment, when the target object is not in egocentric view, the agent may not be able to make wise decisions due to the lack of guidance. In this paper, we propose a hierarchical object-to-zone (HOZ) graph to guide the agent in a coarse-to-fine manner, and an online-learning mechanism is also proposed to update HOZ according to the real-time observation in new environments. In particular, the HOZ graph is composed of scene nodes, zone nodes and object nodes. With the pre-learned HOZ graph, the real-time observation and the target goal, the agent can constantly plan an optimal path from zone to zone. In the estimated path, the next potential zone is regarded as sub-goal, which is also fed into the deep reinforcement learning model for action prediction. Our methods are evaluated on the AI2-Thor simulator. In addition to widely used evaluation metrics SR and SPL, we also propose a new evaluation metric of SAE that focuses on the effective action rate. Experimental results demonstrate the effectiveness and efficiency of our proposed method.