 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Learning to Diversify for Single Domain Generalization
Aug 26, 2021
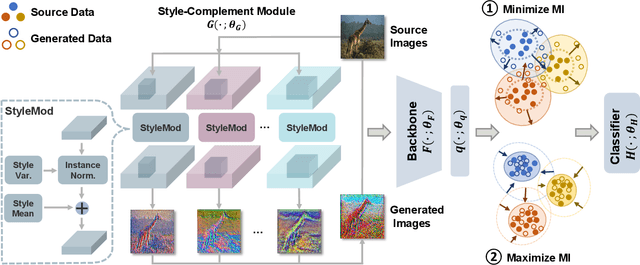
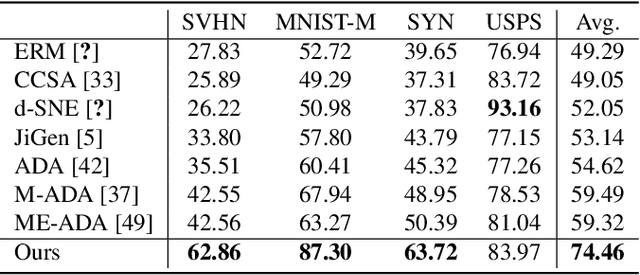
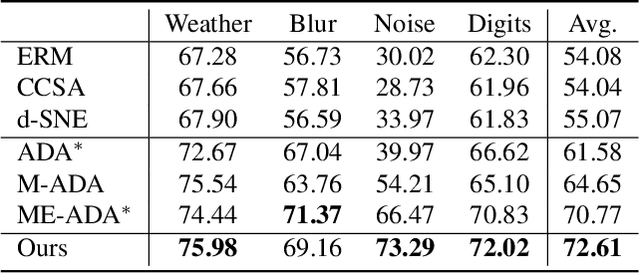
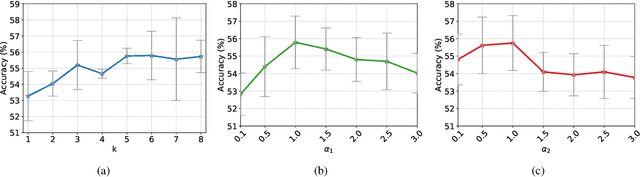
Domain generalization (DG) aims to generalize a model trained on multiple source (i.e., training) domains to a distributionally different target (i.e., test) domain. In contrast to the conventional DG that strictly requires the availability of multiple source domains, this paper considers a more realistic yet challenging scenario, namely Single Domain Generalization (Single-DG), where only one source domain is available for training. In this scenario, the limited diversity may jeopardize the model generalization on unseen target domains. To tackle this problem, we propose a style-complement module to enhance the generalization power of the model by synthesizing images from diverse distributions that are complementary to the source ones. More specifically, we adopt a tractable upper bound of mutual information (MI) between the generated and source samples and perform a two-step optimization iteratively: (1) by minimizing the MI upper bound approximation for each sample pair, the generated images are forced to be diversified from the source samples; (2) subsequently, we maximize the MI between the samples from the same semantic category, which assists the network to learn discriminative features from diverse-styled images. Extensive experiments on three benchmark datasets demonstrate the superiority of our approach, which surpasses the state-of-the-art single-DG methods by up to 25.14%.
Is Pseudo-Lidar needed for Monocular 3D Object detection?
Aug 13, 2021
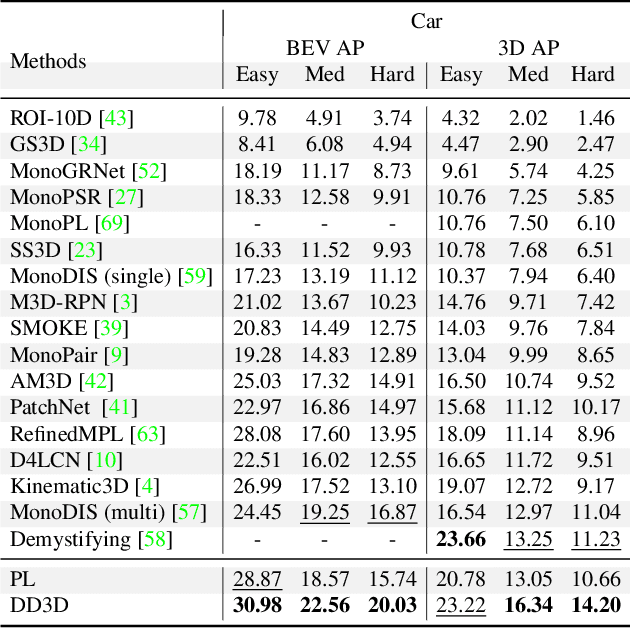
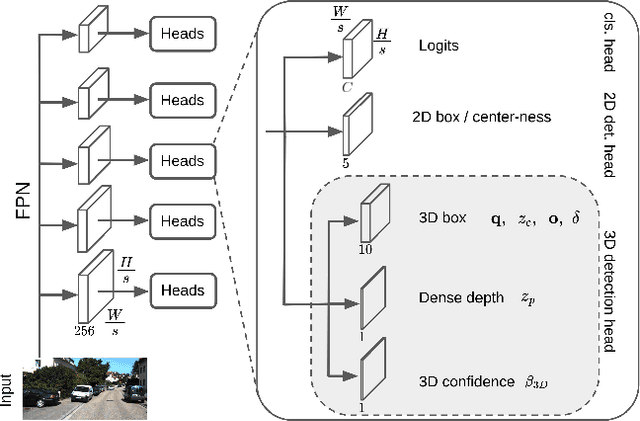
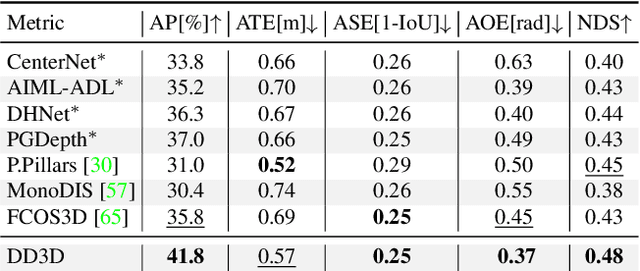
Recent progress in 3D object detection from single images leverages monocular depth estimation as a way to produce 3D pointclouds, turning cameras into pseudo-lidar sensors. These two-stage detectors improve with the accuracy of the intermediate depth estimation network, which can itself be improved without manual labels via large-scale self-supervised learning. However, they tend to suffer from overfitting more than end-to-end methods, are more complex, and the gap with similar lidar-based detectors remains significant. In this work, we propose an end-to-end, single stage, monocular 3D object detector, DD3D, that can benefit from depth pre-training like pseudo-lidar methods, but without their limitations. Our architecture is designed for effective information transfer between depth estimation and 3D detection, allowing us to scale with the amount of unlabeled pre-training data. Our method achieves state-of-the-art results on two challenging benchmarks, with 16.34% and 9.28% AP for Cars and Pedestrians (respectively) on the KITTI-3D benchmark, and 41.5% mAP on NuScenes.
Learning High-order Structural and Attribute information by Knowledge Graph Attention Networks for Enhancing Knowledge Graph Embedding
Oct 10, 2019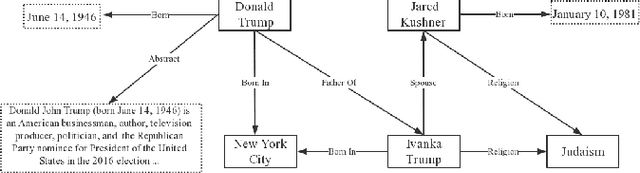
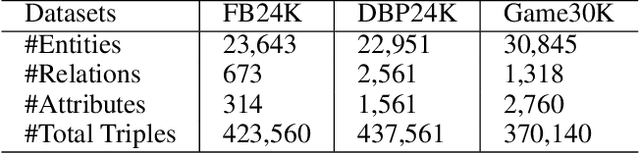
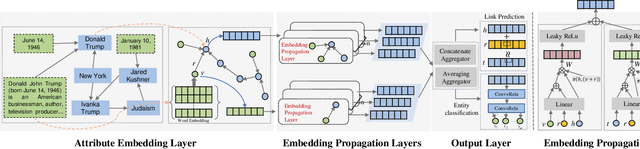
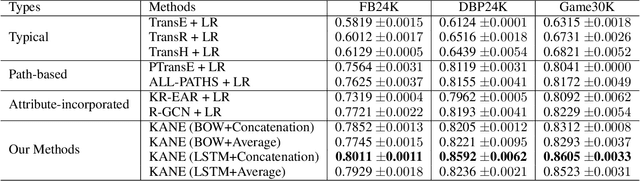
The goal of representation learning of knowledge graph is to encode both entities and relations into a low-dimensional embedding spaces. Many recent works have demonstrated the benefits of knowledge graph embedding on knowledge graph completion task, such as relation extraction. However, we observe that: 1) existing method just take direct relations between entities into consideration and fails to express high-order structural relationship between entities; 2) these methods just leverage relation triples of KGs while ignoring a large number of attribute triples that encoding rich semantic information. To overcome these limitations, this paper propose a novel knowledge graph embedding method, named KANE, which is inspired by the recent developments of graph convolutional networks (GCN). KANE can capture both high-order structural and attribute information of KGs in an efficient, explicit and unified manner under the graph convolutional networks framework. Empirical results on three datasets show that KANE significantly outperforms seven state-of-arts methods. Further analysis verify the efficiency of our method and the benefits brought by the attention mechanism.
Ranking labs-of-origin for genetically engineered DNA using Metric Learning
Jul 16, 2021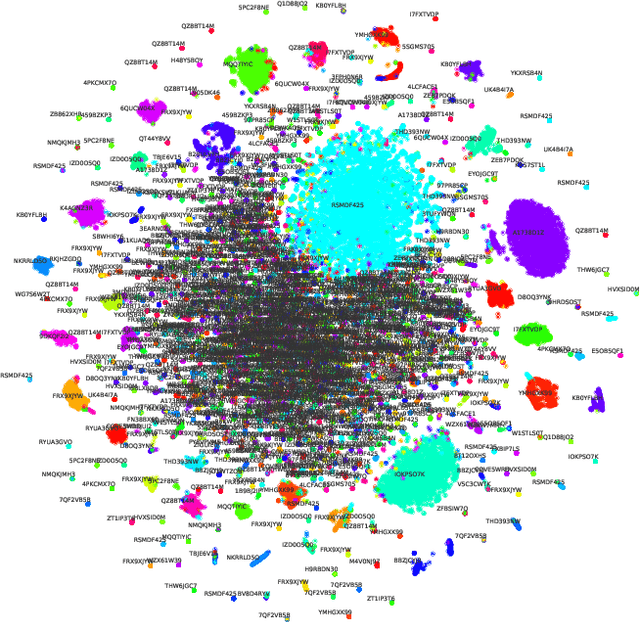
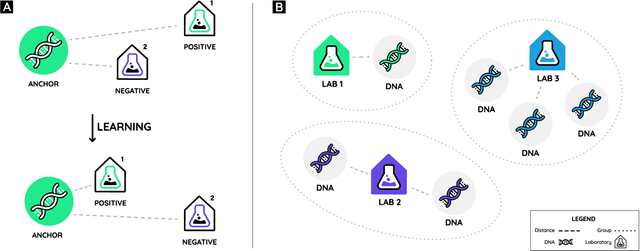
With the constant advancements of genetic engineering, a common concern is to be able to identify the lab-of-origin of genetically engineered DNA sequences. For that reason, AltLabs has hosted the genetic Engineering Attribution Challenge to gather many teams to propose new tools to solve this problem. Here we show our proposed method to rank the most likely labs-of-origin and generate embeddings for DNA sequences and labs. These embeddings can also perform various other tasks, like clustering both DNA sequences and labs and using them as features for Machine Learning models applied to solve other problems. This work demonstrates that our method outperforms the classic training method for this task while generating other helpful information.
SketchLattice: Latticed Representation for Sketch Manipulation
Aug 26, 2021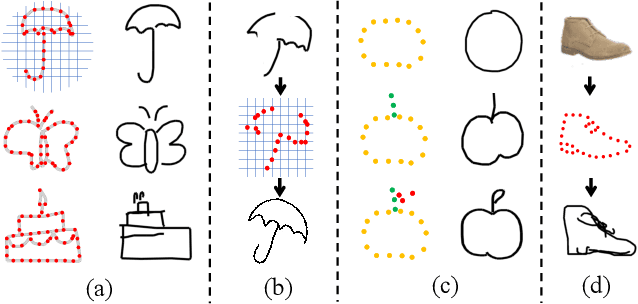

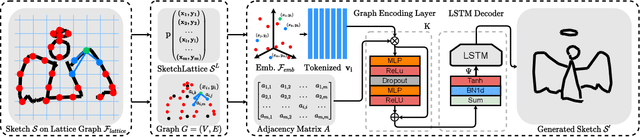
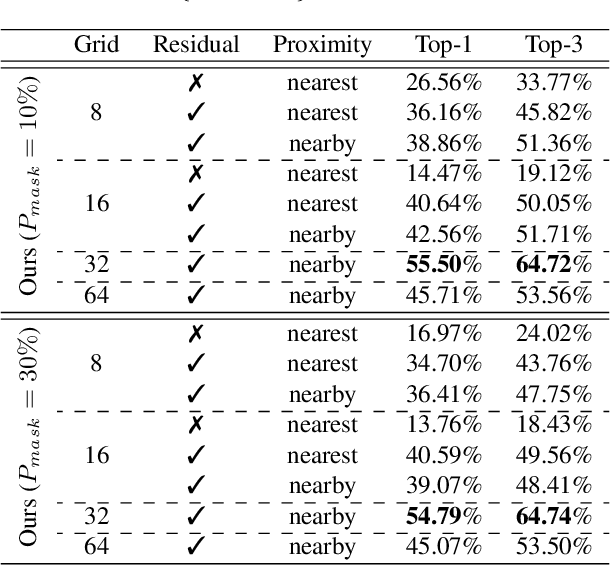
The key challenge in designing a sketch representation lies with handling the abstract and iconic nature of sketches. Existing work predominantly utilizes either, (i) a pixelative format that treats sketches as natural images employing off-the-shelf CNN-based networks, or (ii) an elaborately designed vector format that leverages the structural information of drawing orders using sequential RNN-based methods. While the pixelative format lacks intuitive exploitation of structural cues, sketches in vector format are absent in most cases limiting their practical usage. Hence, in this paper, we propose a lattice structured sketch representation that not only removes the bottleneck of requiring vector data but also preserves the structural cues that vector data provides. Essentially, sketch lattice is a set of points sampled from the pixelative format of the sketch using a lattice graph. We show that our lattice structure is particularly amenable to structural changes that largely benefits sketch abstraction modeling for generation tasks. Our lattice representation could be effectively encoded using a graph model, that uses significantly fewer model parameters (13.5 times lesser) than existing state-of-the-art. Extensive experiments demonstrate the effectiveness of sketch lattice for sketch manipulation, including sketch healing and image-to-sketch synthesis.
Distantly-Supervised Long-Tailed Relation Extraction Using Constraint Graphs
May 24, 2021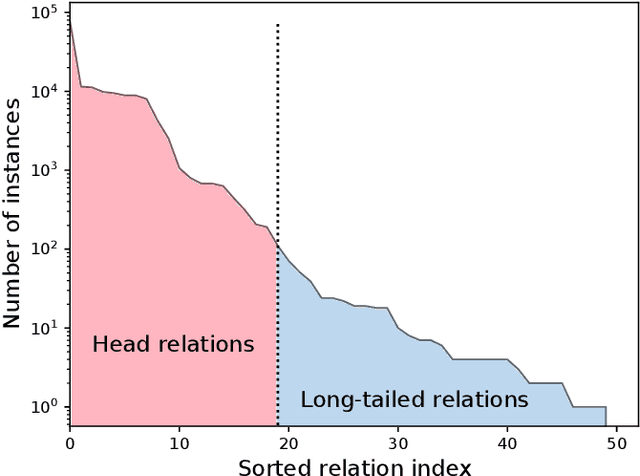

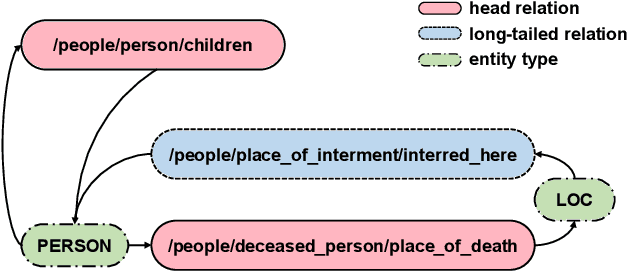
Label noise and long-tailed distributions are two major challenges in distantly supervised relation extraction. Recent studies have shown great progress on denoising, but pay little attention to the problem of long-tailed relations. In this paper, we introduce constraint graphs to model the dependencies between relation labels. On top of that, we further propose a novel constraint graph-based relation extraction framework(CGRE) to handle the two challenges simultaneously. CGRE employs graph convolution networks (GCNs) to propagate information from data-rich relation nodes to data-poor relation nodes, and thus boosts the representation learning of long-tailed relations. To further improve the noise immunity, a constraint-aware attention module is designed in CGRE to integrate the constraint information. Experimental results on a widely-used benchmark dataset indicate that our approach achieves significant improvements over the previous methods for both denoising and long-tailed relation extraction.
Multi-agent deep reinforcement learning (MADRL) meets multi-user MIMO systems
Sep 10, 2021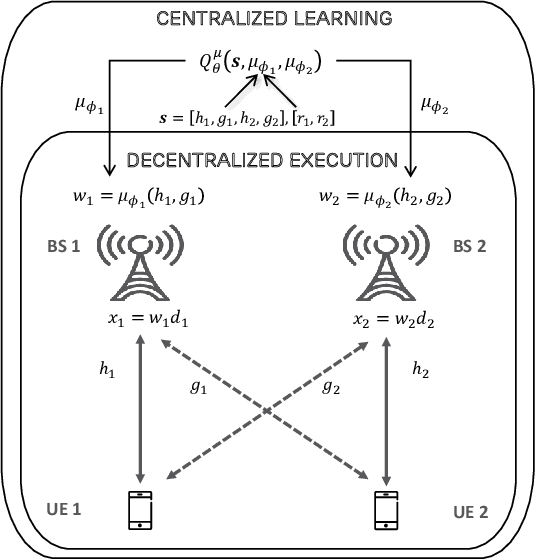
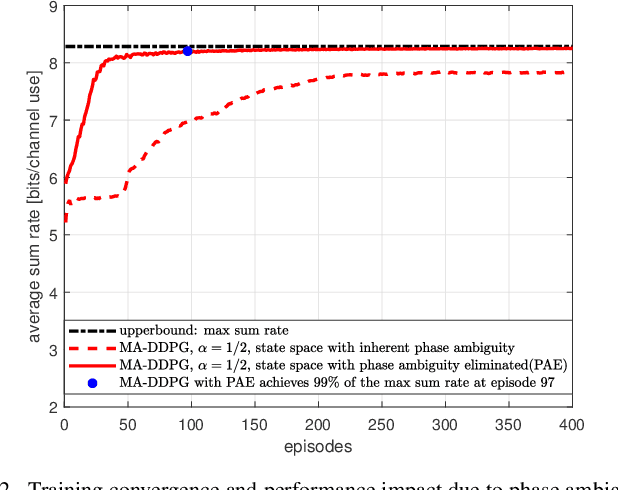
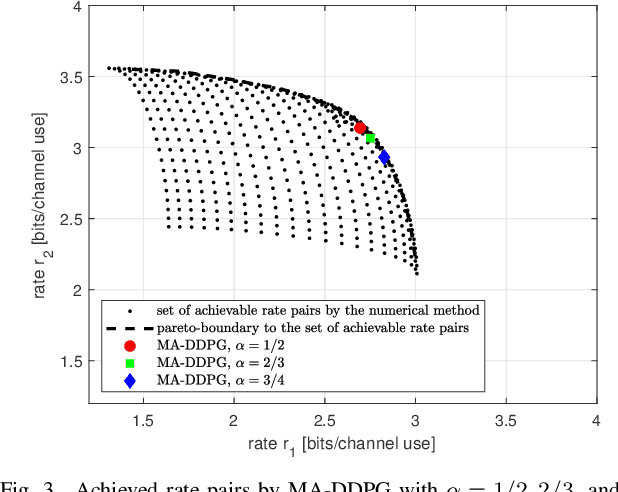
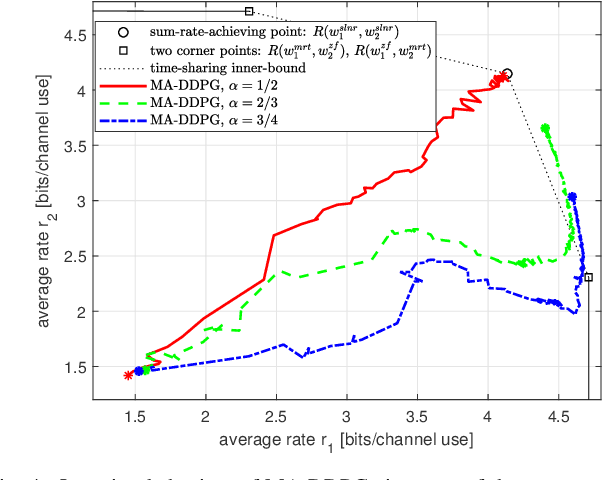
A multi-agent deep reinforcement learning (MADRL) is a promising approach to challenging problems in wireless environments involving multiple decision-makers (or actors) with high-dimensional continuous action space. In this paper, we present a MADRL-based approach that can jointly optimize precoders to achieve the outer-boundary, called pareto-boundary, of the achievable rate region for a multiple-input single-output (MISO) interference channel (IFC). In order to address two main challenges, namely, multiple actors (or agents) with partial observability and multi-dimensional continuous action space in MISO IFC setup, we adopt a multi-agent deep deterministic policy gradient (MA-DDPG) framework in which decentralized actors with partial observability can learn a multi-dimensional continuous policy in a centralized manner with the aid of shared critic with global information. Meanwhile, we will also address a phase ambiguity issue with the conventional complex baseband representation of signals widely used in radio communications. In order to mitigate the impact of phase ambiguity on training performance, we propose a training method, called phase ambiguity elimination (PAE), that leads to faster learning and better performance of MA-DDPG in wireless communication systems. The simulation results exhibit that MA-DDPG is capable of learning a near-optimal precoding strategy in a MISO IFC environment. To the best of our knowledge, this is the first work to demonstrate that the MA-DDPG framework can jointly optimize precoders to achieve the pareto-boundary of achievable rate region in a multi-cell multi-user multi-antenna system.
Multimodal Image-to-Image Translation via Mutual Information Estimation and Maximization
Sep 01, 2020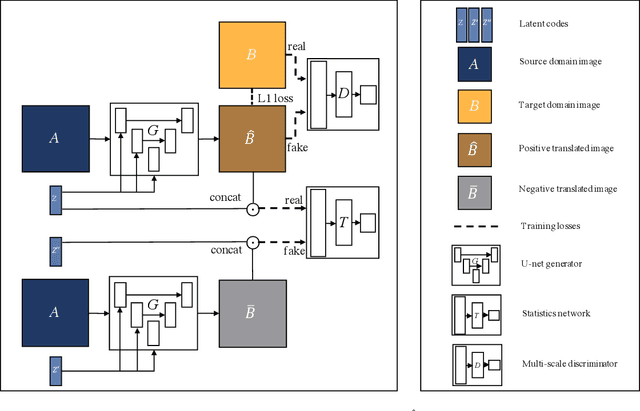
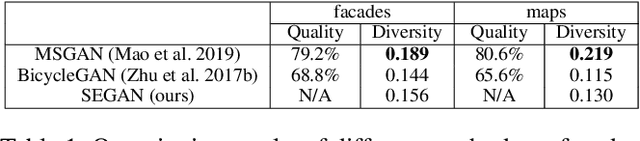

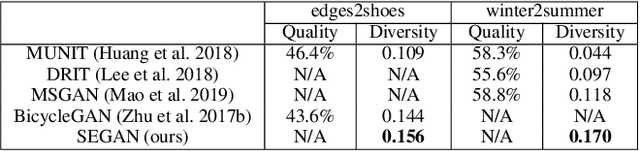
In this paper, we present a novel framework that can achieve multimodal image-to-image translation by simply encouraging the statistical dependence between the latent code and the output image in conditional generative adversarial networks. In addition, by incorporating a U-net generator into our framework, our method only needs to learn a one-sided translation model from the source image domain to the target image domain for both supervised and unsupervised multimodal image-to-image translation. Furthermore, our method also achieves disentanglement between the source domain content and the target domain style for free. We conduct experiments under supervised and unsupervised settings on various benchmark image-to-image translation datasets compared with the state-of-the-art methods, showing the effectiveness and simplicity of our method to achieve multimodal and high-quality results.
Enhancing ensemble learning and transfer learning in multimodal data analysis by adaptive dimensionality reduction
May 08, 2021
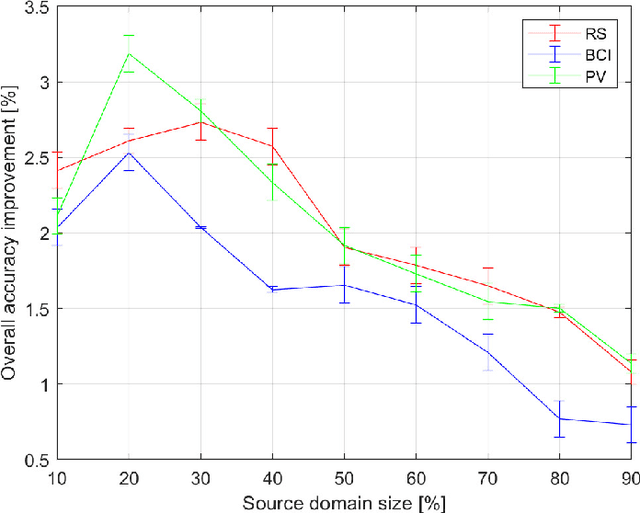
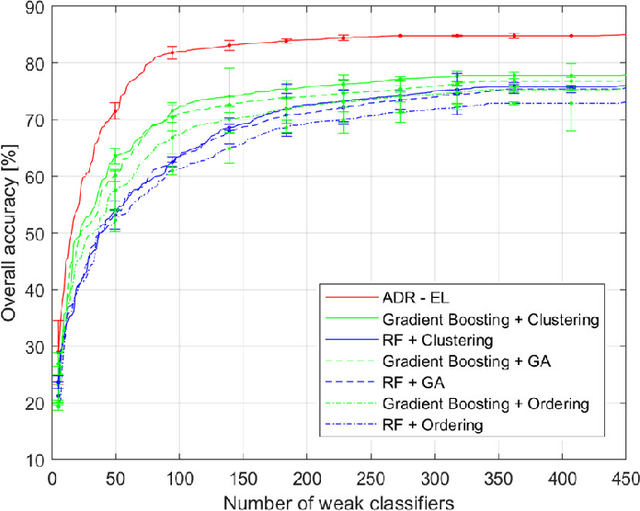
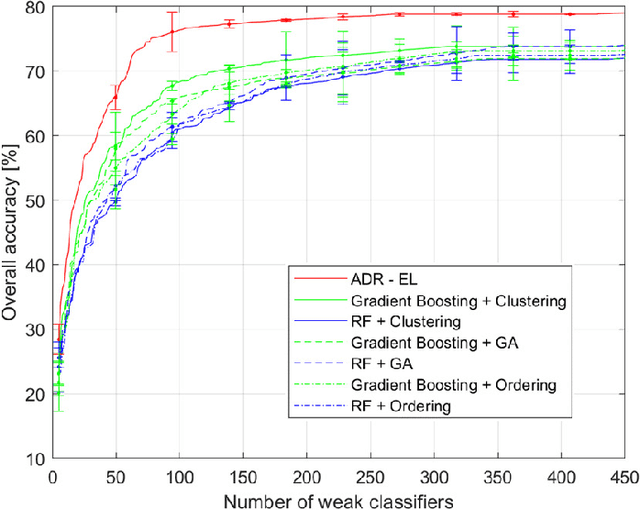
Modern data analytics take advantage of ensemble learning and transfer learning approaches to tackle some of the most relevant issues in data analysis, such as lack of labeled data to use to train the analysis models, sparsity of the information, and unbalanced distributions of the records. Nonetheless, when applied to multimodal datasets (i.e., datasets acquired by means of multiple sensing techniques or strategies), the state-of-theart methods for ensemble learning and transfer learning might show some limitations. In fact, in multimodal data analysis, not all observations would show the same level of reliability or information quality, nor an homogeneous distribution of errors and uncertainties. This condition might undermine the classic assumptions ensemble learning and transfer learning methods rely on. In this work, we propose an adaptive approach for dimensionality reduction to overcome this issue. By means of a graph theory-based approach, the most relevant features across variable size subsets of the considered datasets are identified. This information is then used to set-up ensemble learning and transfer learning architectures. We test our approach on multimodal datasets acquired in diverse research fields (remote sensing, brain-computer interfaces, photovoltaic energy). Experimental results show the validity and the robustness of our approach, able to outperform state-of-the-art techniques.
Large-vocabulary Audio-visual Speech Recognition in Noisy Environments
Sep 10, 2021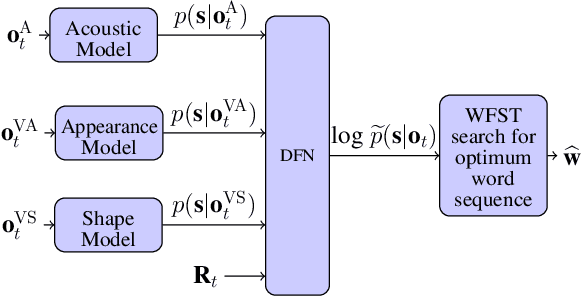
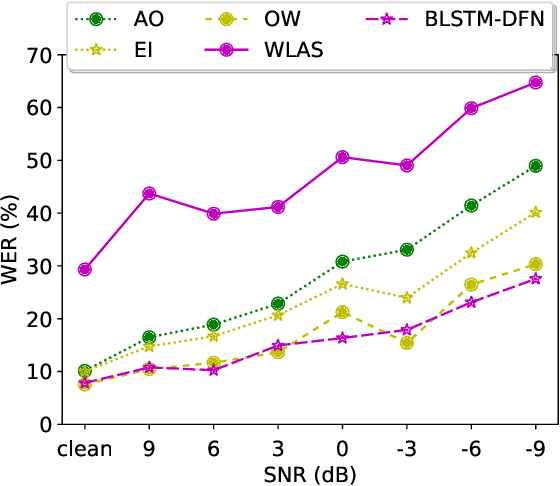

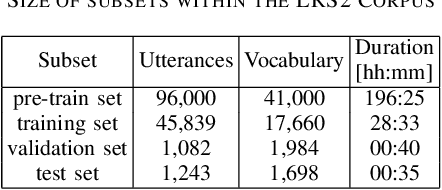
Audio-visual speech recognition (AVSR) can effectively and significantly improve the recognition rates of small-vocabulary systems, compared to their audio-only counterparts. For large-vocabulary systems, however, there are still many difficulties, such as unsatisfactory video recognition accuracies, that make it hard to improve over audio-only baselines. In this paper, we specifically consider such scenarios, focusing on the large-vocabulary task of the LRS2 database, where audio-only performance is far superior to video-only accuracies, making this an interesting and challenging setup for multi-modal integration. To address the inherent difficulties, we propose a new fusion strategy: a recurrent integration network is trained to fuse the state posteriors of multiple single-modality models, guided by a set of model-based and signal-based stream reliability measures. During decoding, this network is used for stream integration within a hybrid recognizer, where it can thus cope with the time-variant reliability and information content of its multiple feature inputs. We compare the results with end-to-end AVSR systems as well as with competitive hybrid baseline models, finding that the new fusion strategy shows superior results, on average even outperforming oracle dynamic stream weighting, which has so far marked the -- realistically unachievable -- upper bound for standard stream weighting. Even though the pure lipreading performance is low, audio-visual integration is helpful under all -- clean, noisy, and reverberant -- conditions. On average, the new system achieves a relative word error rate reduction of 42.18\% compared to the audio-only model, pointing at a high effectiveness of the proposed integration approach.