 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Lossy Compression for Lossless Prediction
Jul 07, 2021


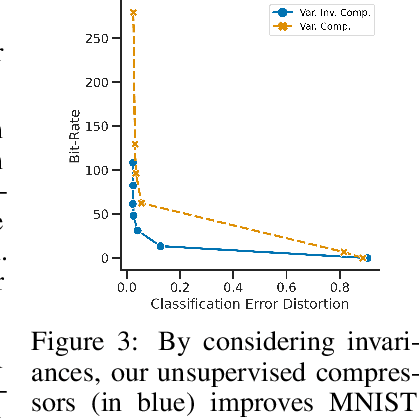
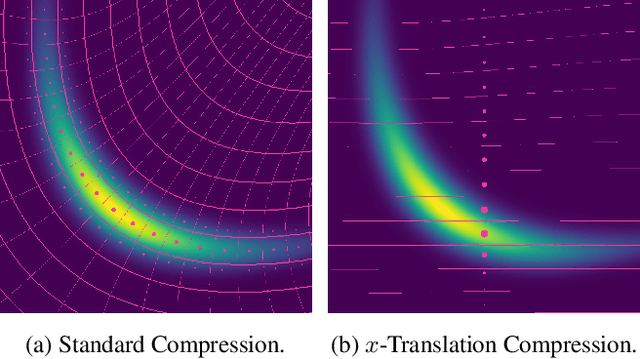
Most data is automatically collected and only ever "seen" by algorithms. Yet, data compressors preserve perceptual fidelity rather than just the information needed by algorithms performing downstream tasks. In this paper, we characterize the bit-rate required to ensure high performance on all predictive tasks that are invariant under a set of transformations, such as data augmentations. Based on our theory, we design unsupervised objectives for training neural compressors. Using these objectives, we train a generic image compressor that achieves substantial rate savings (more than $1000\times$ on ImageNet) compared to JPEG on 8 datasets, without decreasing downstream classification performance.
Weakly Supervised Continual Learning
Aug 14, 2021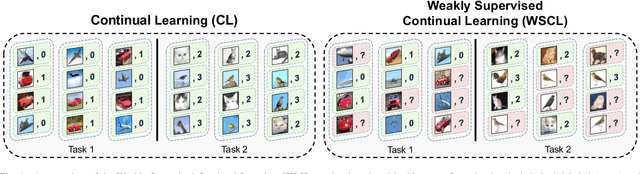
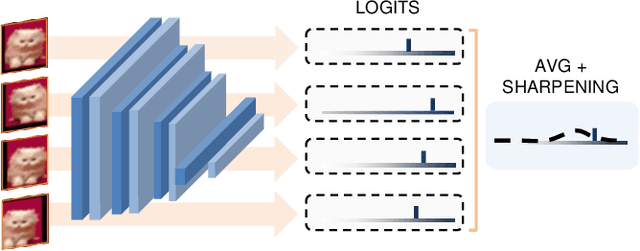
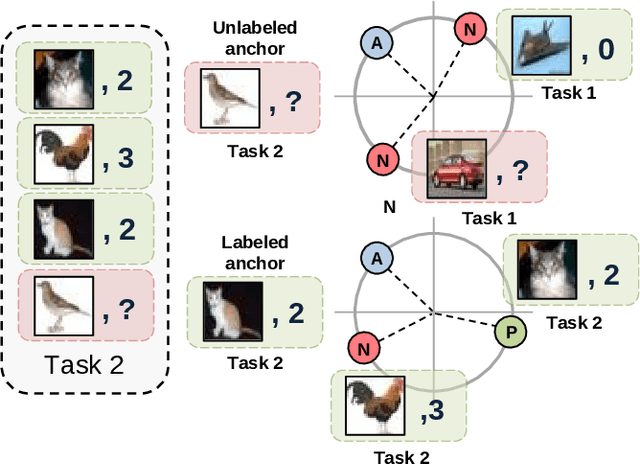
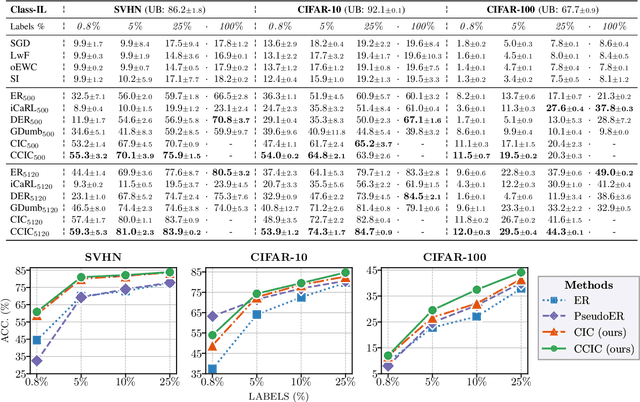
Continual Learning (CL) investigates how to train Deep Networks on a stream of tasks without incurring catastrophic forgetting. CL settings proposed in the literature assume that every incoming example is paired with ground-truth annotations. However, this clashes with many real-world applications: gathering labeled data, which is in itself tedious and expensive, becomes indeed infeasible when data flow as a stream and must be consumed in real-time. This work explores Weakly Supervised Continual Learning (WSCL): here, only a small fraction of labeled input examples are shown to the learner. We assess how current CL methods (e.g.: EWC, LwF, iCaRL, ER, GDumb, DER) perform in this novel and challenging scenario, in which overfitting entangles forgetting. Subsequently, we design two novel WSCL methods which exploit metric learning and consistency regularization to leverage unsupervised data while learning. In doing so, we show that not only our proposals exhibit higher flexibility when supervised information is scarce, but also that less than 25% labels can be enough to reach or even outperform SOTA methods trained under full supervision.
Learning to Diversify for Single Domain Generalization
Aug 27, 2021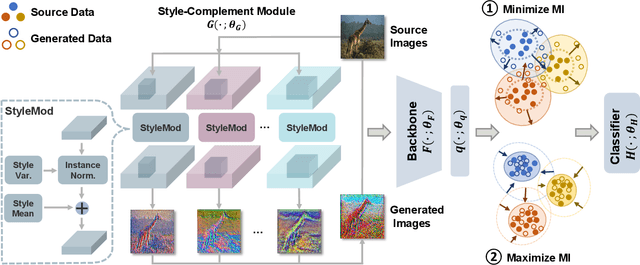
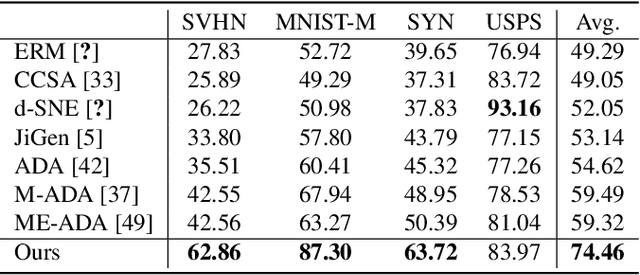
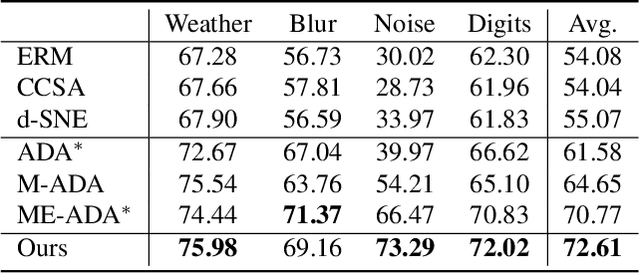
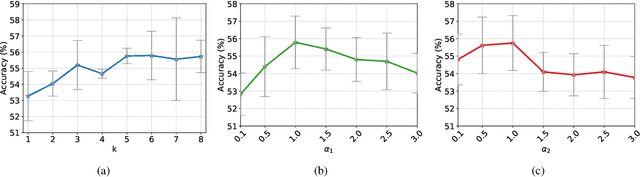
Domain generalization (DG) aims to generalize a model trained on multiple source (i.e., training) domains to a distributionally different target (i.e., test) domain. In contrast to the conventional DG that strictly requires the availability of multiple source domains, this paper considers a more realistic yet challenging scenario, namely Single Domain Generalization (Single-DG), where only one source domain is available for training. In this scenario, the limited diversity may jeopardize the model generalization on unseen target domains. To tackle this problem, we propose a style-complement module to enhance the generalization power of the model by synthesizing images from diverse distributions that are complementary to the source ones. More specifically, we adopt a tractable upper bound of mutual information (MI) between the generated and source samples and perform a two-step optimization iteratively: (1) by minimizing the MI upper bound approximation for each sample pair, the generated images are forced to be diversified from the source samples; (2) subsequently, we maximize the MI between the samples from the same semantic category, which assists the network to learn discriminative features from diverse-styled images. Extensive experiments on three benchmark datasets demonstrate the superiority of our approach, which surpasses the state-of-the-art single-DG methods by up to 25.14%.
Exploration in Deep Reinforcement Learning: A Comprehensive Survey
Sep 15, 2021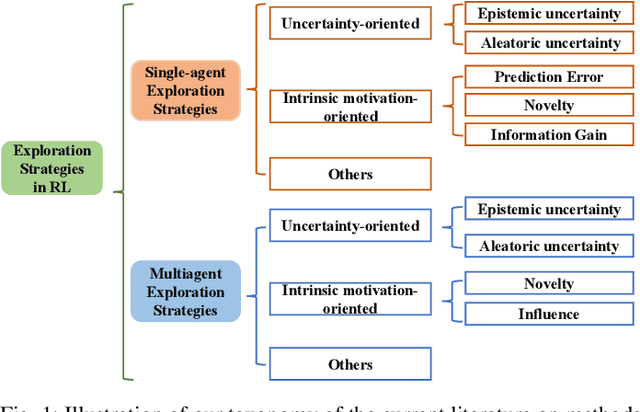
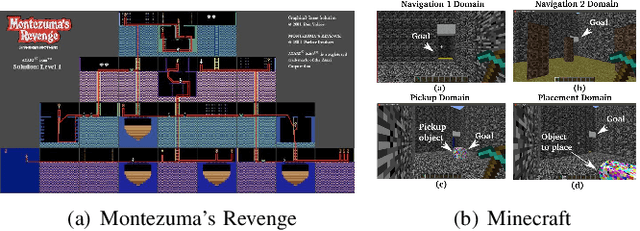

Deep Reinforcement Learning (DRL) and Deep Multi-agent Reinforcement Learning (MARL) have achieved significant success across a wide range of domains, such as game AI, autonomous vehicles, robotics and finance. However, DRL and deep MARL agents are widely known to be sample-inefficient and millions of interactions are usually needed even for relatively simple game settings, thus preventing the wide application in real-industry scenarios. One bottleneck challenge behind is the well-known exploration problem, i.e., how to efficiently explore the unknown environments and collect informative experiences that could benefit the policy learning most. In this paper, we conduct a comprehensive survey on existing exploration methods in DRL and deep MARL for the purpose of providing understandings and insights on the critical problems and solutions. We first identify several key challenges to achieve efficient exploration, which most of the exploration methods aim at addressing. Then we provide a systematic survey of existing approaches by classifying them into two major categories: uncertainty-oriented exploration and intrinsic motivation-oriented exploration. The essence of uncertainty-oriented exploration is to leverage the quantification of the epistemic and aleatoric uncertainty to derive efficient exploration. By contrast, intrinsic motivation-oriented exploration methods usually incorporate different reward agnostic information for intrinsic exploration guidance. Beyond the above two main branches, we also conclude other exploration methods which adopt sophisticated techniques but are difficult to be classified into the above two categories. In addition, we provide a comprehensive empirical comparison of exploration methods for DRL on a set of commonly used benchmarks. Finally, we summarize the open problems of exploration in DRL and deep MARL and point out a few future directions.
Pyramid R-CNN: Towards Better Performance and Adaptability for 3D Object Detection
Sep 06, 2021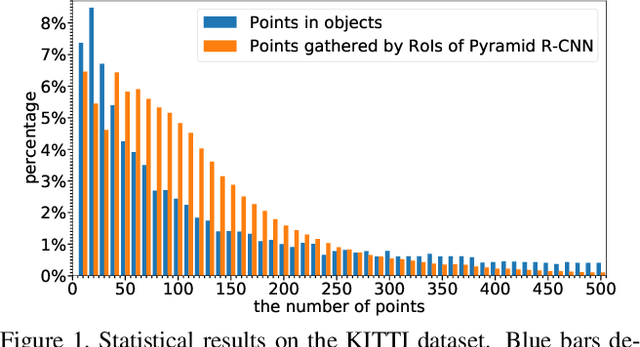
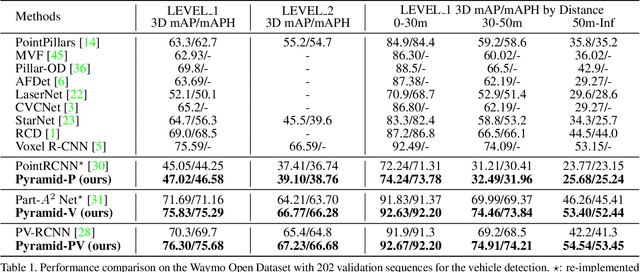
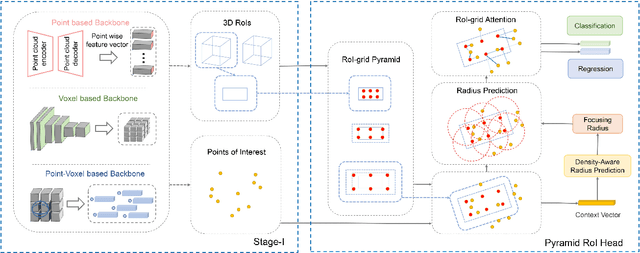

We present a flexible and high-performance framework, named Pyramid R-CNN, for two-stage 3D object detection from point clouds. Current approaches generally rely on the points or voxels of interest for RoI feature extraction on the second stage, but cannot effectively handle the sparsity and non-uniform distribution of those points, and this may result in failures in detecting objects that are far away. To resolve the problems, we propose a novel second-stage module, named pyramid RoI head, to adaptively learn the features from the sparse points of interest. The pyramid RoI head consists of three key components. Firstly, we propose the RoI-grid Pyramid, which mitigates the sparsity problem by extensively collecting points of interest for each RoI in a pyramid manner. Secondly, we propose RoI-grid Attention, a new operation that can encode richer information from sparse points by incorporating conventional attention-based and graph-based point operators into a unified formulation. Thirdly, we propose the Density-Aware Radius Prediction (DARP) module, which can adapt to different point density levels by dynamically adjusting the focusing range of RoIs. Combining the three components, our pyramid RoI head is robust to the sparse and imbalanced circumstances, and can be applied upon various 3D backbones to consistently boost the detection performance. Extensive experiments show that Pyramid R-CNN outperforms the state-of-the-art 3D detection models by a large margin on both the KITTI dataset and the Waymo Open dataset.
HDRUNet: Single Image HDR Reconstruction with Denoising and Dequantization
Jun 19, 2021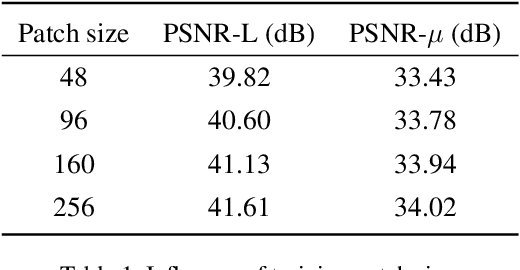
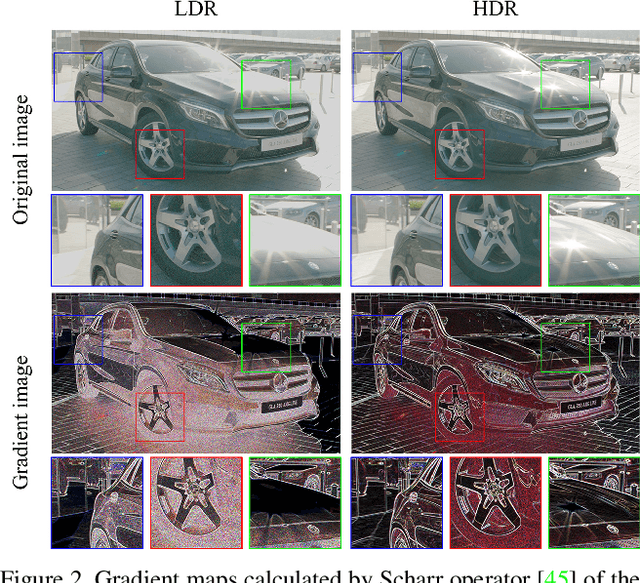
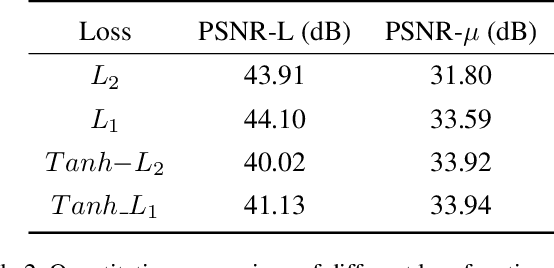
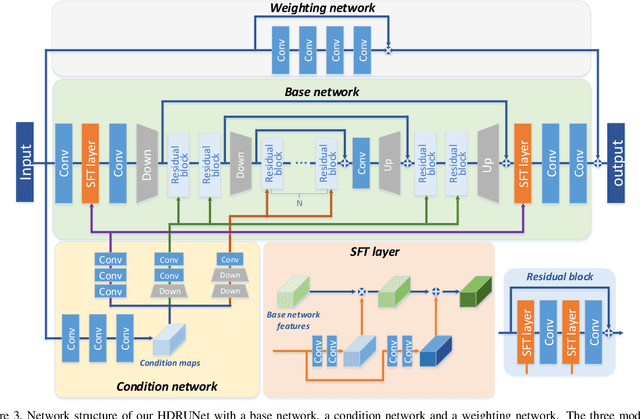
Most consumer-grade digital cameras can only capture a limited range of luminance in real-world scenes due to sensor constraints. Besides, noise and quantization errors are often introduced in the imaging process. In order to obtain high dynamic range (HDR) images with excellent visual quality, the most common solution is to combine multiple images with different exposures. However, it is not always feasible to obtain multiple images of the same scene and most HDR reconstruction methods ignore the noise and quantization loss. In this work, we propose a novel learning-based approach using a spatially dynamic encoder-decoder network, HDRUNet, to learn an end-to-end mapping for single image HDR reconstruction with denoising and dequantization. The network consists of a UNet-style base network to make full use of the hierarchical multi-scale information, a condition network to perform pattern-specific modulation and a weighting network for selectively retaining information. Moreover, we propose a Tanh_L1 loss function to balance the impact of over-exposed values and well-exposed values on the network learning. Our method achieves the state-of-the-art performance in quantitative comparisons and visual quality. The proposed HDRUNet model won the second place in the single frame track of NITRE2021 High Dynamic Range Challenge.
M4Depth: A motion-based approach for monocular depth estimation on video sequences
May 21, 2021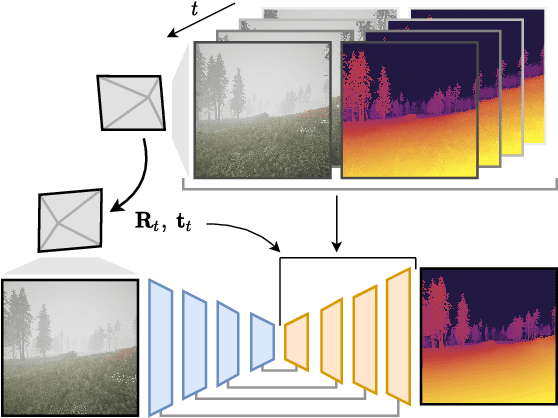
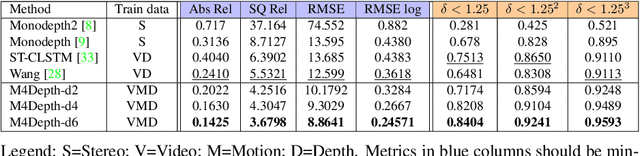
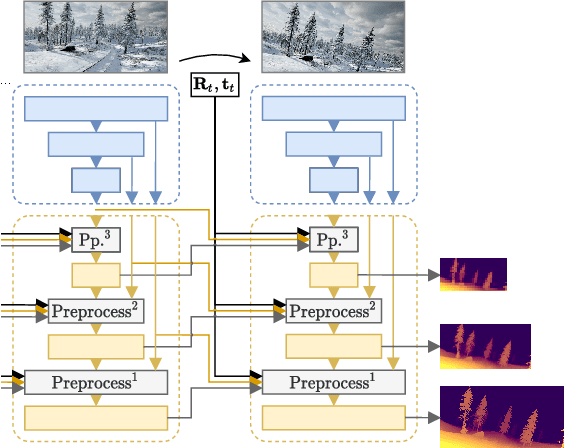
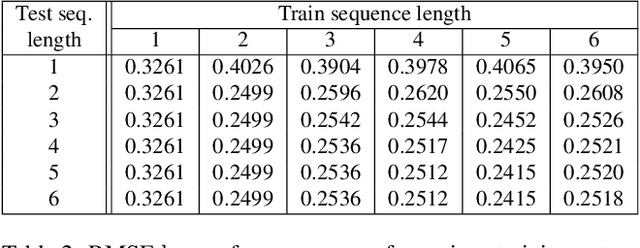
Getting the distance to objects is crucial for autonomous vehicles. In instances where depth sensors cannot be used, this distance has to be estimated from RGB cameras. As opposed to cars, the task of estimating depth from on-board mounted cameras is made complex on drones because of the lack of constrains on motion during flights. In this paper, we present a method to estimate the distance of objects seen by an on-board mounted camera by using its RGB video stream and drone motion information. Our method is built upon a pyramidal convolutional neural network architecture and uses time recurrence in pair with geometric constraints imposed by motion to produce pixel-wise depth maps. In our architecture, each level of the pyramid is designed to produce its own depth estimate based on past observations and information provided by the previous level in the pyramid. We introduce a spatial reprojection layer to maintain the spatio-temporal consistency of the data between the levels. We analyse the performance of our approach on Mid-Air, a public drone dataset featuring synthetic drone trajectories recorded in a wide variety of unstructured outdoor environments. Our experiments show that our network outperforms state-of-the-art depth estimation methods and that the use of motion information is the main contributing factor for this improvement. The code of our method is publicly available on GitHub; see https://github.com/michael-fonder/M4Depth
AutoReCon: Neural Architecture Search-based Reconstruction for Data-free Compression
May 25, 2021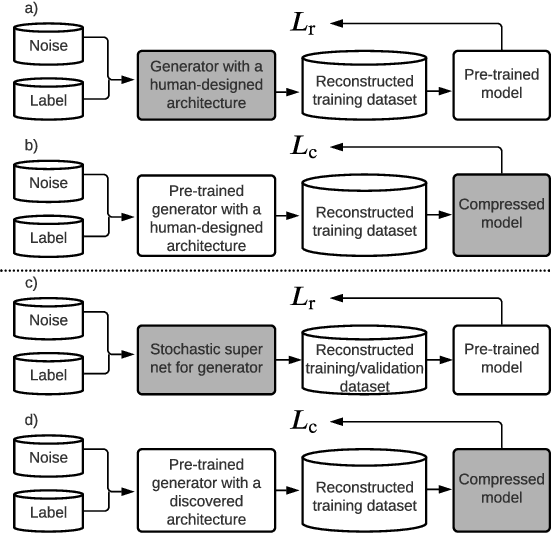
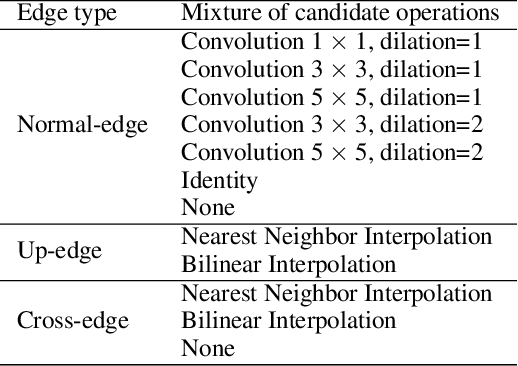
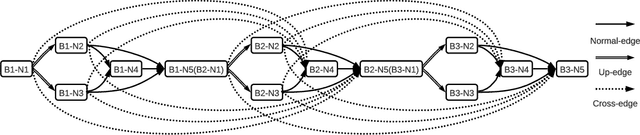
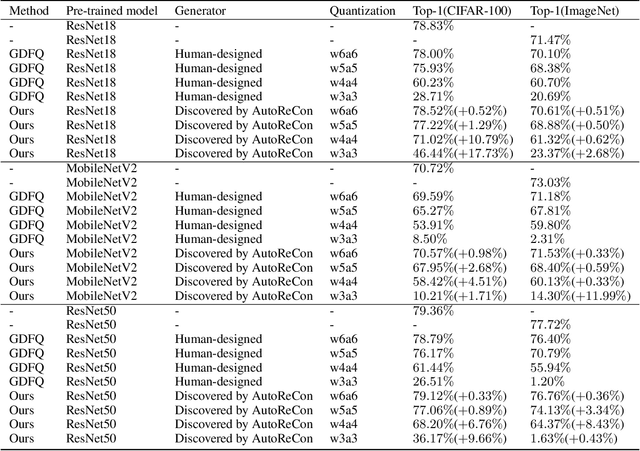
Data-free compression raises a new challenge because the original training dataset for a pre-trained model to be compressed is not available due to privacy or transmission issues. Thus, a common approach is to compute a reconstructed training dataset before compression. The current reconstruction methods compute the reconstructed training dataset with a generator by exploiting information from the pre-trained model. However, current reconstruction methods focus on extracting more information from the pre-trained model but do not leverage network engineering. This work is the first to consider network engineering as an approach to design the reconstruction method. Specifically, we propose the AutoReCon method, which is a neural architecture search-based reconstruction method. In the proposed AutoReCon method, the generator architecture is designed automatically given the pre-trained model for reconstruction. Experimental results show that using generators discovered by the AutoRecon method always improve the performance of data-free compression.
Conditional Generation of Synthetic Geospatial Images from Pixel-level and Feature-level Inputs
Sep 11, 2021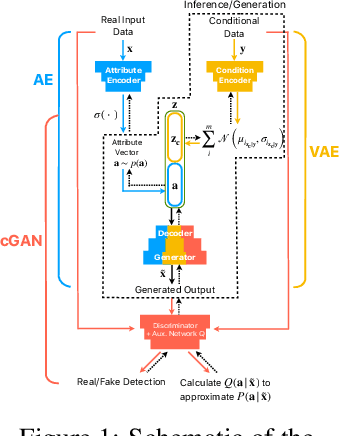
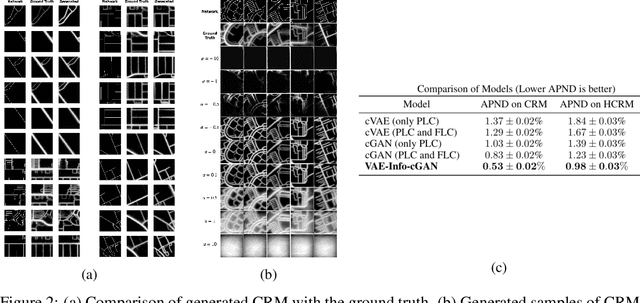
Training robust supervised deep learning models for many geospatial applications of computer vision is difficult due to dearth of class-balanced and diverse training data. Conversely, obtaining enough training data for many applications is financially prohibitive or may be infeasible, especially when the application involves modeling rare or extreme events. Synthetically generating data (and labels) using a generative model that can sample from a target distribution and exploit the multi-scale nature of images can be an inexpensive solution to address scarcity of labeled data. Towards this goal, we present a deep conditional generative model, called VAE-Info-cGAN, that combines a Variational Autoencoder (VAE) with a conditional Information Maximizing Generative Adversarial Network (InfoGAN), for synthesizing semantically rich images simultaneously conditioned on a pixel-level condition (PLC) and a macroscopic feature-level condition (FLC). Dimensionally, the PLC can only vary in the channel dimension from the synthesized image and is meant to be a task-specific input. The FLC is modeled as an attribute vector in the latent space of the generated image which controls the contributions of various characteristic attributes germane to the target distribution. Experiments on a GPS trajectories dataset show that the proposed model can accurately generate various forms of spatiotemporal aggregates across different geographic locations while conditioned only on a raster representation of the road network. The primary intended application of the VAE-Info-cGAN is synthetic data (and label) generation for targeted data augmentation for computer vision-based modeling of problems relevant to geospatial analysis and remote sensing.
Causal Bandits on General Graphs
Jul 06, 2021
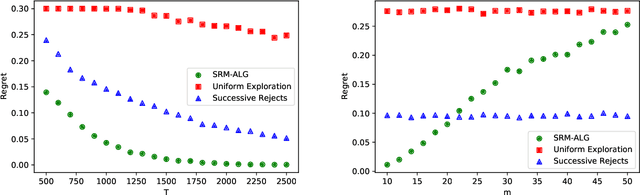
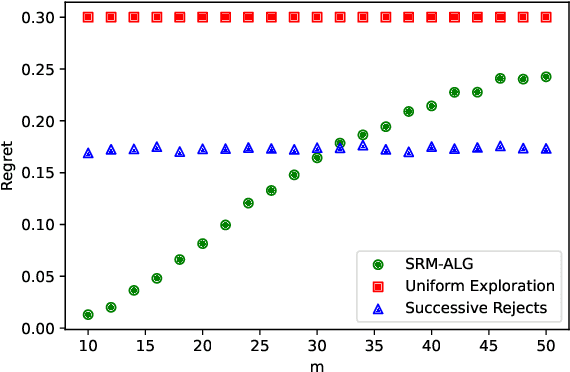
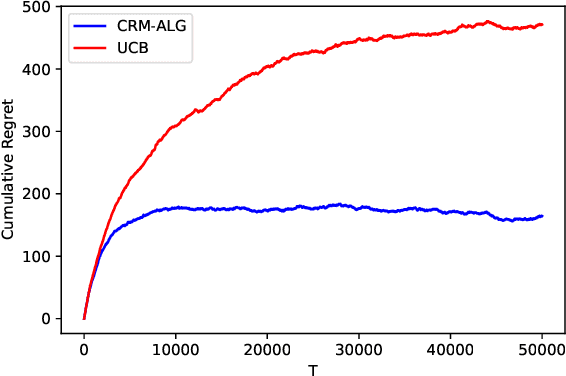
We study the problem of determining the best intervention in a Causal Bayesian Network (CBN) specified only by its causal graph. We model this as a stochastic multi-armed bandit (MAB) problem with side-information, where the interventions correspond to the arms of the bandit instance. First, we propose a simple regret minimization algorithm that takes as input a semi-Markovian causal graph with atomic interventions and possibly unobservable variables, and achieves $\tilde{O}(\sqrt{M/T})$ expected simple regret, where $M$ is dependent on the input CBN and could be very small compared to the number of arms. We also show that this is almost optimal for CBNs described by causal graphs having an $n$-ary tree structure. Our simple regret minimization results, both upper and lower bound, subsume previous results in the literature, which assumed additional structural restrictions on the input causal graph. In particular, our results indicate that the simple regret guarantee of our proposed algorithm can only be improved by considering more nuanced structural restrictions on the causal graph. Next, we propose a cumulative regret minimization algorithm that takes as input a general causal graph with all observable nodes and atomic interventions and performs better than the optimal MAB algorithm that does not take causal side-information into account. We also experimentally compare both our algorithms with the best known algorithms in the literature. To the best of our knowledge, this work gives the first simple and cumulative regret minimization algorithms for CBNs with general causal graphs under atomic interventions and having unobserved confounders.