 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
Integrate-and-Fire Neurons for Low-Powered Pattern Recognition
Jun 28, 2021
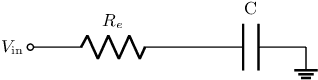

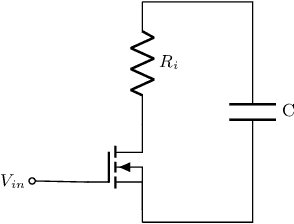
Embedded systems acquire information about the real world from sensors and process it to make decisions and/or for transmission. In some situations, the relationship between the data and the decision is complex and/or the amount of data to transmit is large (e.g. in biologgers). Artificial Neural Networks (ANNs) can efficiently detect patterns in the input data which makes them suitable for decision making or compression of information for data transmission. However, ANNs require a substantial amount of energy which reduces the lifetime of battery-powered devices. Therefore, the use of Spiking Neural Networks can improve such systems by providing a way to efficiently process sensory data without being too energy-consuming. In this work, we introduce a low-powered neuron model called Integrate-and-Fire which exploits the charge and discharge properties of the capacitor. Using parallel and series RC circuits, we developed a trainable neuron model that can be expressed in a recurrent form. Finally, we trained its simulation with an artificially generated dataset of dog postures and implemented it as hardware that showed promising energetic properties. This paper is the full text of the research, presented at the 20th International Conference on Artificial Intelligence and Soft Computing Web System (ICAISC 2021)
Deep Context- and Relation-Aware Learning for Aspect-based Sentiment Analysis
Jun 07, 2021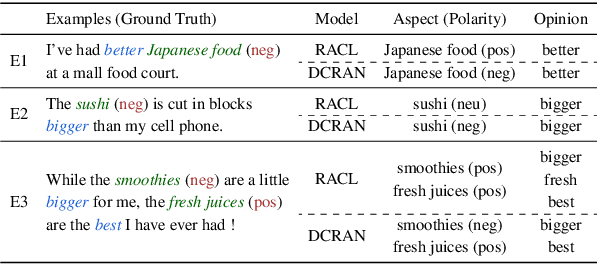
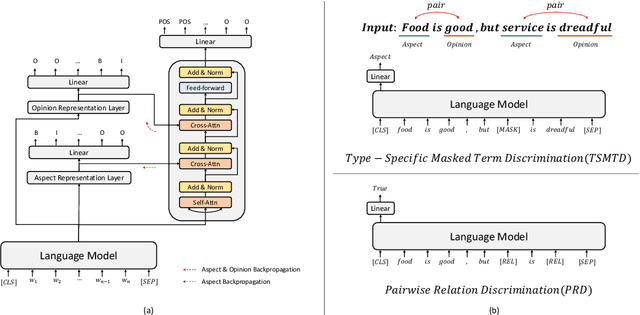
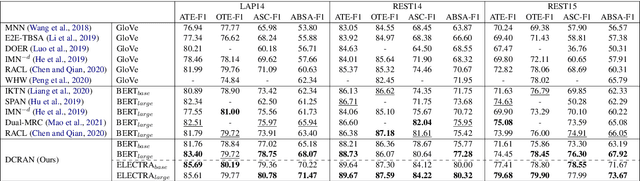
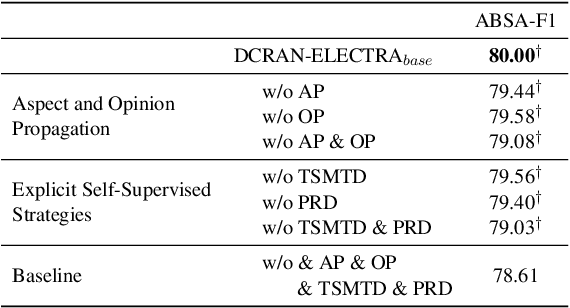
Existing works for aspect-based sentiment analysis (ABSA) have adopted a unified approach, which allows the interactive relations among subtasks. However, we observe that these methods tend to predict polarities based on the literal meaning of aspect and opinion terms and mainly consider relations implicitly among subtasks at the word level. In addition, identifying multiple aspect-opinion pairs with their polarities is much more challenging. Therefore, a comprehensive understanding of contextual information w.r.t. the aspect and opinion are further required in ABSA. In this paper, we propose Deep Contextualized Relation-Aware Network (DCRAN), which allows interactive relations among subtasks with deep contextual information based on two modules (i.e., Aspect and Opinion Propagation and Explicit Self-Supervised Strategies). Especially, we design novel self-supervised strategies for ABSA, which have strengths in dealing with multiple aspects. Experimental results show that DCRAN significantly outperforms previous state-of-the-art methods by large margins on three widely used benchmarks.
CS-Based CSIT Estimation for Downlink Pilot Decontamination in Multi-Cell FDD Massive MIMO
Aug 23, 2021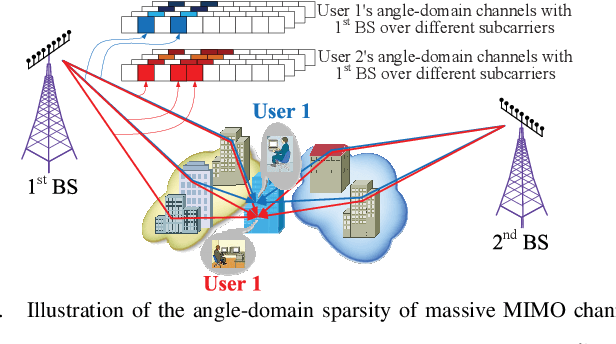
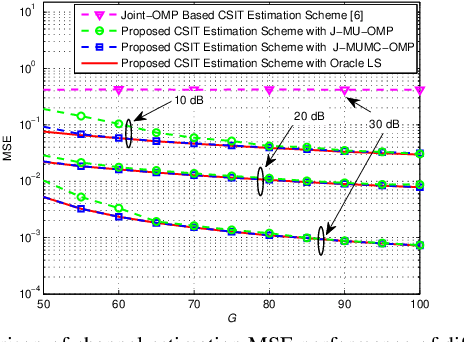
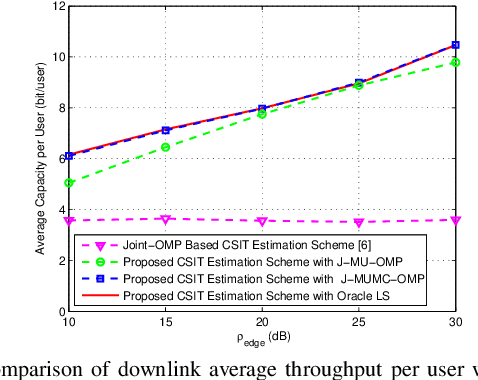
Efficient channel state information at transmitter (CSIT) for frequency division duplex (FDD) massive MIMO can facilitate its backward compatibility with existing FDD cellular networks. To date, several CSIT estimation schemes have been proposed for FDD single-cell massive MIMO systems, but they fail to consider inter-cell-interference (ICI) and suffer from downlink pilot contamination in multi-cell scenario. To solve this problem, this paper proposes a compressive sensing (CS)-based CSIT estimation scheme to combat ICI in FDD multi-cell massive MIMO systems. Specifically, angle-domain massive MIMO channels exhibit the common sparsity over different subcarriers, and such sparsity is partially shared by adjacent users. By exploiting these sparsity properties, we design the pilot signal and the associated channel estimation algorithm under the framework of CS theory, where the channels associated with multiple adjacent BSs can be reliably estimated with low training overhead for downlink pilot decontamination. Simulation results verify the good downlink pilot decontamination performance of the proposed solution compared to its conventional counterparts in multi-cell FDD massive MIMO.
Open Information Extraction on Scientific Text: An Evaluation
Jun 04, 2018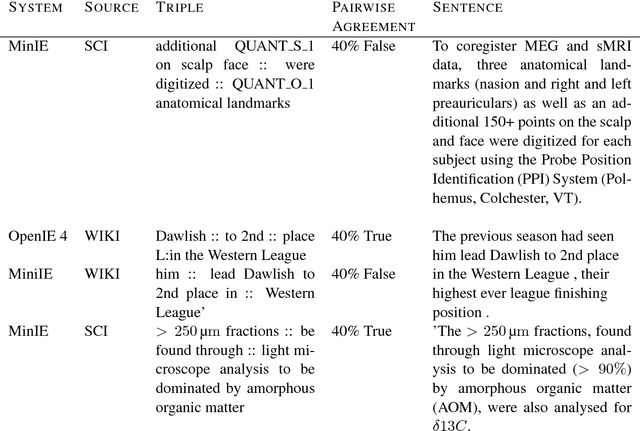
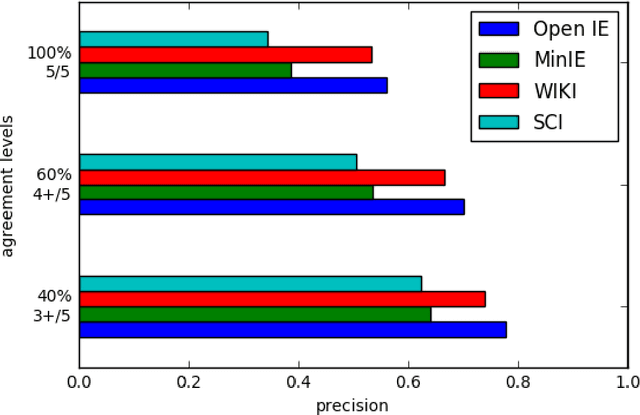
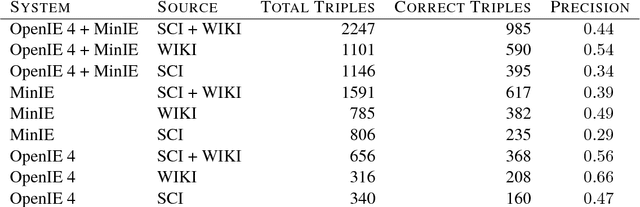

Open Information Extraction (OIE) is the task of the unsupervised creation of structured information from text. OIE is often used as a starting point for a number of downstream tasks including knowledge base construction, relation extraction, and question answering. While OIE methods are targeted at being domain independent, they have been evaluated primarily on newspaper, encyclopedic or general web text. In this article, we evaluate the performance of OIE on scientific texts originating from 10 different disciplines. To do so, we use two state-of-the-art OIE systems applying a crowd-sourcing approach. We find that OIE systems perform significantly worse on scientific text than encyclopedic text. We also provide an error analysis and suggest areas of work to reduce errors. Our corpus of sentences and judgments are made available.
* 10 pages
Multimodal analysis of the predictability of hand-gesture properties
Aug 12, 2021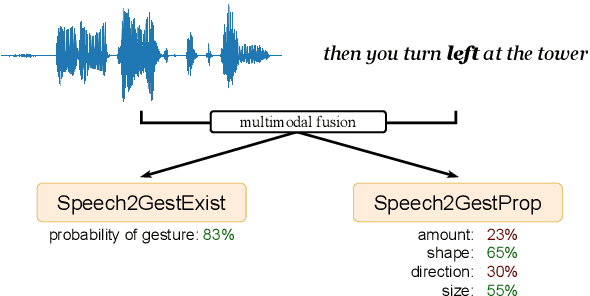
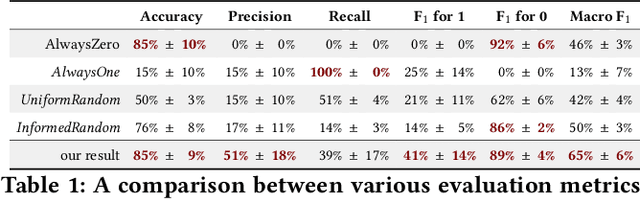
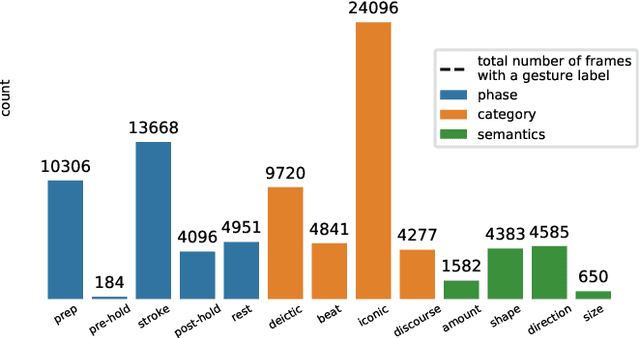
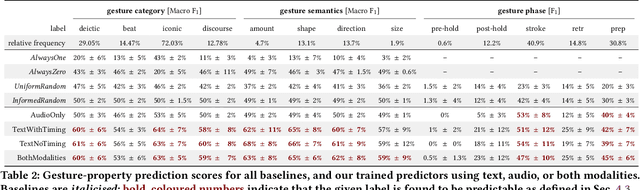
Embodied conversational agents benefit from being able to accompany their speech with gestures. Although many data-driven approaches to gesture generation have been proposed in recent years, it is still unclear whether such systems can consistently generate gestures that convey meaning. We investigate which gesture properties (phase, category, and semantics) can be predicted from speech text and/or audio using contemporary deep learning. In extensive experiments, we show that gesture properties related to gesture meaning (semantics and category) are predictable from text features (time-aligned BERT embeddings) alone, but not from prosodic audio features, while rhythm-related gesture properties (phase) on the other hand can be predicted from either audio, text (with word-level timing information), or both. These results are encouraging as they indicate that it is possible to equip an embodied agent with content-wise meaningful co-speech gestures using a machine-learning model.
Geometric Deep Learning on Molecular Representations
Jul 26, 2021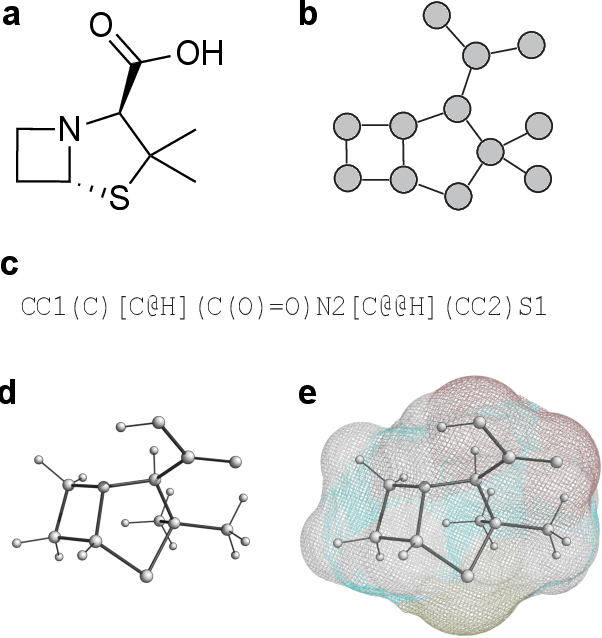
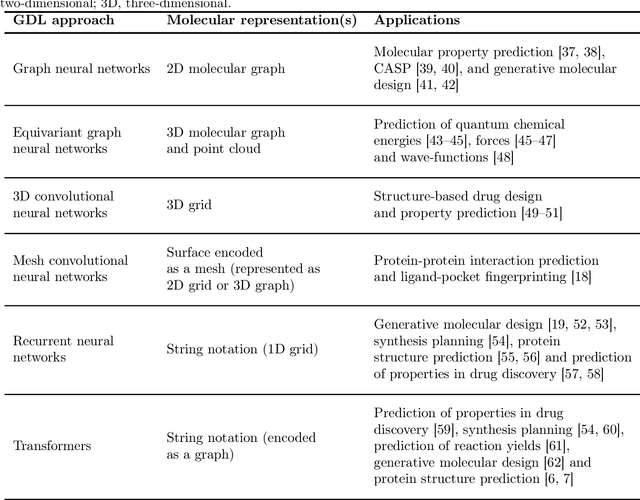
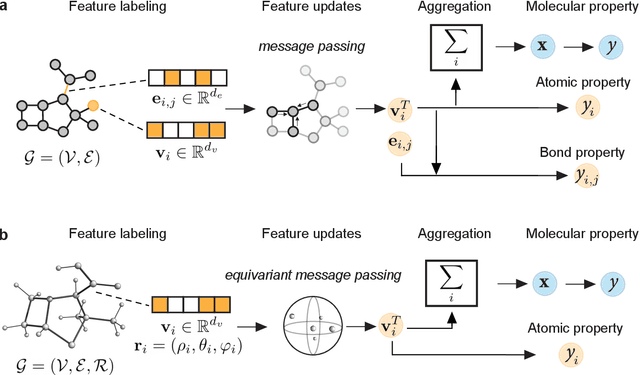
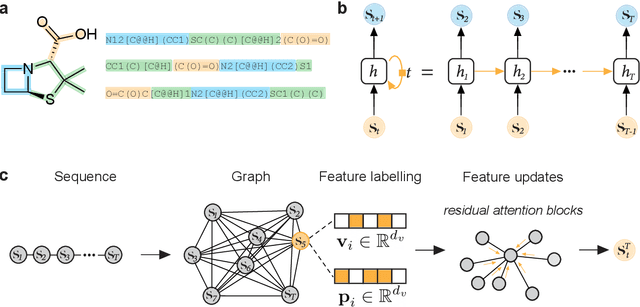
Geometric deep learning (GDL), which is based on neural network architectures that incorporate and process symmetry information, has emerged as a recent paradigm in artificial intelligence. GDL bears particular promise in molecular modeling applications, in which various molecular representations with different symmetry properties and levels of abstraction exist. This review provides a structured and harmonized overview of molecular GDL, highlighting its applications in drug discovery, chemical synthesis prediction, and quantum chemistry. Emphasis is placed on the relevance of the learned molecular features and their complementarity to well-established molecular descriptors. This review provides an overview of current challenges and opportunities, and presents a forecast of the future of GDL for molecular sciences.
PyPhi: A toolbox for integrated information theory
Jun 27, 2018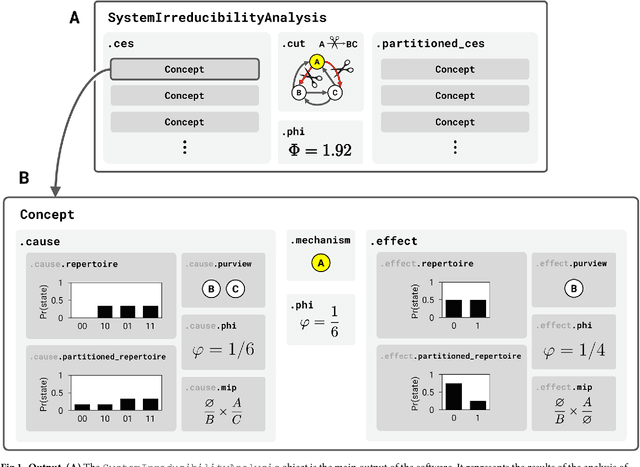

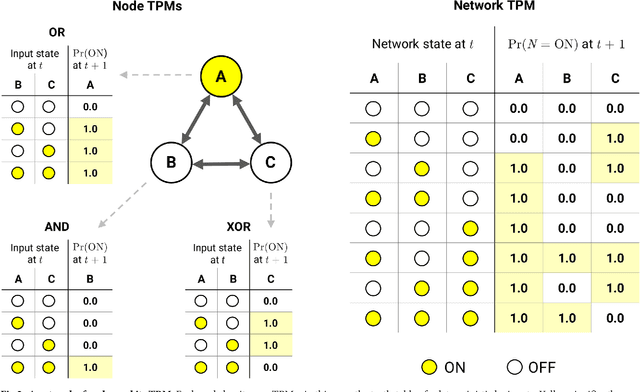
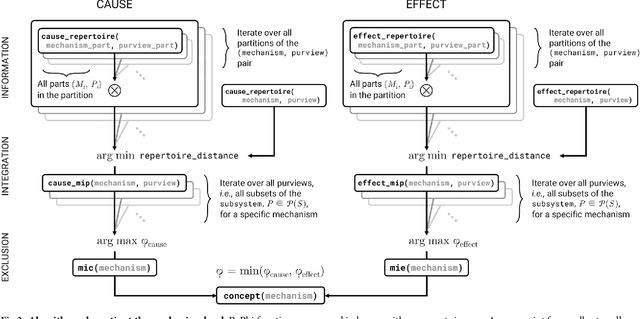
Integrated information theory provides a mathematical framework to fully characterize the cause-effect structure of a physical system. Here, we introduce PyPhi, a Python software package that implements this framework for causal analysis and unfolds the full cause-effect structure of discrete dynamical systems of binary elements. The software allows users to easily study these structures, serves as an up-to-date reference implementation of the formalisms of integrated information theory, and has been applied in research on complexity, emergence, and certain biological questions. We first provide an overview of the main algorithm and demonstrate PyPhi's functionality in the course of analyzing an example system, and then describe details of the algorithm's design and implementation. PyPhi can be installed with Python's package manager via the command 'pip install pyphi' on Linux and macOS systems equipped with Python 3.4 or higher. PyPhi is open-source and licensed under the GPLv3; the source code is hosted on GitHub at https://github.com/wmayner/pyphi . Comprehensive and continually-updated documentation is available at https://pyphi.readthedocs.io/ . The pyphi-users mailing list can be joined at https://groups.google.com/forum/#!forum/pyphi-users . A web-based graphical interface to the software is available at http://integratedinformationtheory.org/calculate.html .
* 22 pages, 4 figures, 6 pages of appendices. Supporting information "S1 Calculating Phi" can be found in the ancillary files
Dizygotic Conditional Variational AutoEncoder for Multi-Modal and Partial Modality Absent Few-Shot Learning
Jun 28, 2021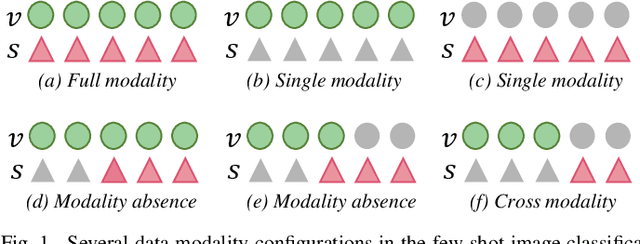
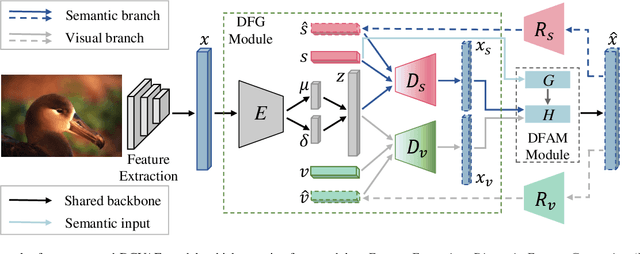
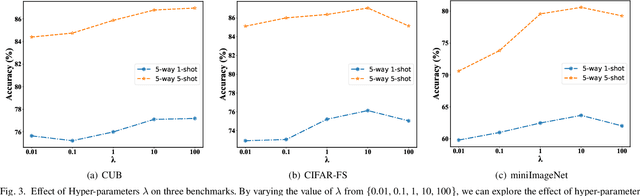
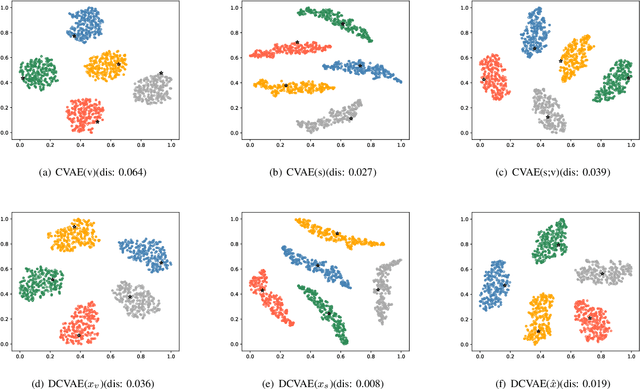
Data augmentation is a powerful technique for improving the performance of the few-shot classification task. It generates more samples as supplements, and then this task can be transformed into a common supervised learning issue for solution. However, most mainstream data augmentation based approaches only consider the single modality information, which leads to the low diversity and quality of generated features. In this paper, we present a novel multi-modal data augmentation approach named Dizygotic Conditional Variational AutoEncoder (DCVAE) for addressing the aforementioned issue. DCVAE conducts feature synthesis via pairing two Conditional Variational AutoEncoders (CVAEs) with the same seed but different modality conditions in a dizygotic symbiosis manner. Subsequently, the generated features of two CVAEs are adaptively combined to yield the final feature, which can be converted back into its paired conditions while ensuring these conditions are consistent with the original conditions not only in representation but also in function. DCVAE essentially provides a new idea of data augmentation in various multi-modal scenarios by exploiting the complement of different modality prior information. Extensive experimental results demonstrate our work achieves state-of-the-art performances on miniImageNet, CIFAR-FS and CUB datasets, and is able to work well in the partial modality absence case.
Logician: A Unified End-to-End Neural Approach for Open-Domain Information Extraction
Apr 29, 2019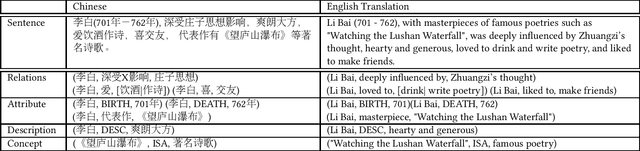
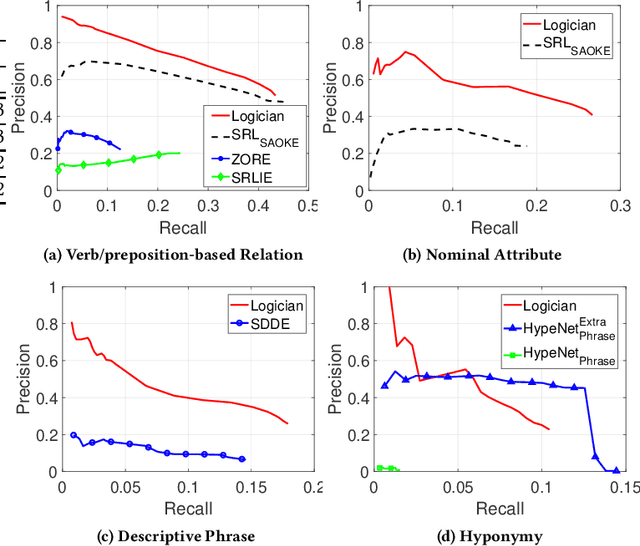
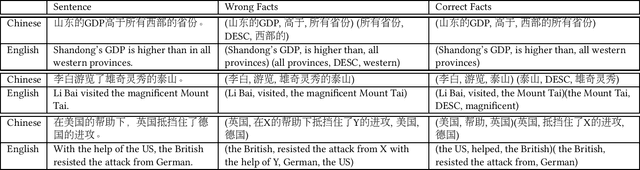

In this paper, we consider the problem of open information extraction (OIE) for extracting entity and relation level intermediate structures from sentences in open-domain. We focus on four types of valuable intermediate structures (Relation, Attribute, Description, and Concept), and propose a unified knowledge expression form, SAOKE, to express them. We publicly release a data set which contains more than forty thousand sentences and the corresponding facts in the SAOKE format labeled by crowd-sourcing. To our knowledge, this is the largest publicly available human labeled data set for open information extraction tasks. Using this labeled SAOKE data set, we train an end-to-end neural model using the sequenceto-sequence paradigm, called Logician, to transform sentences into facts. For each sentence, different to existing algorithms which generally focus on extracting each single fact without concerning other possible facts, Logician performs a global optimization over all possible involved facts, in which facts not only compete with each other to attract the attention of words, but also cooperate to share words. An experimental study on various types of open domain relation extraction tasks reveals the consistent superiority of Logician to other states-of-the-art algorithms. The experiments verify the reasonableness of SAOKE format, the valuableness of SAOKE data set, the effectiveness of the proposed Logician model, and the feasibility of the methodology to apply end-to-end learning paradigm on supervised data sets for the challenging tasks of open information extraction.
Multi-behavior Graph Contextual Aware Network for Session-based Recommendation
Sep 24, 2021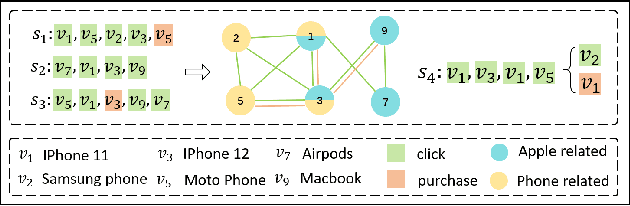
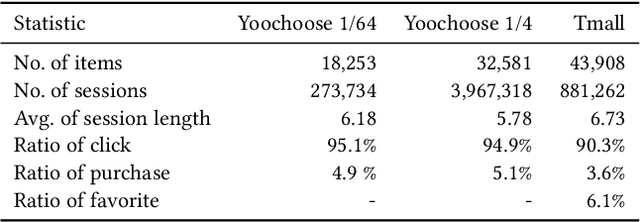
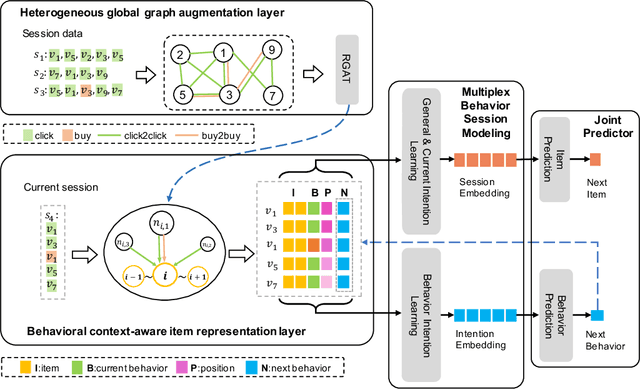
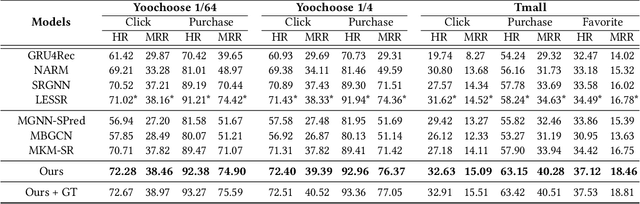
Predicting the next interaction of a short-term sequence is a challenging task in session-based recommendation (SBR).Multi-behavior session recommendation considers session sequence with multiple interaction types, such as click and purchase, to capture more effective user intention representation sufficiently.Despite the superior performance of existing multi-behavior based methods for SBR, there are still several severe limitations:(i) Almost all existing works concentrate on single target type of next behavior and fail to model multiplex behavior sessions uniformly.(ii) Previous methods also ignore the semantic relations between various next behavior and historical behavior sequence, which are significant signals to obtain current latent intention for SBR.(iii) The global cross-session item-item graph established by some existing models may incorporate semantics and context level noise for multi-behavior session-based recommendation. To overcome the limitations (i) and (ii), we propose two novel tasks for SBR, which require the incorporation of both historical behaviors and next behaviors into unified multi-behavior recommendation modeling. To this end, we design a Multi-behavior Graph Contextual Aware Network (MGCNet) for multi-behavior session-based recommendation for the two proposed tasks. Specifically, we build a multi-behavior global item transition graph based on all sessions involving all interaction types. Based on the global graph, MGCNet attaches the global interest representation to final item representation based on local contextual intention to address the limitation (iii). In the end, we utilize the next behavior information explicitly to guide the learning of general interest and current intention for SBR. Experiments on three public benchmark datasets show that MGCNet can outperform state-of-the-art models for multi-behavior session-based recommendation.