 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Information": models, code, and papers
PAIR: Leveraging Passage-Centric Similarity Relation for Improving Dense Passage Retrieval
Aug 13, 2021
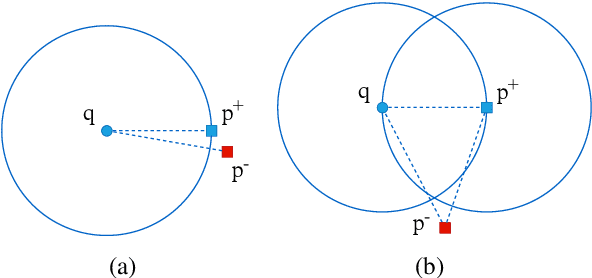

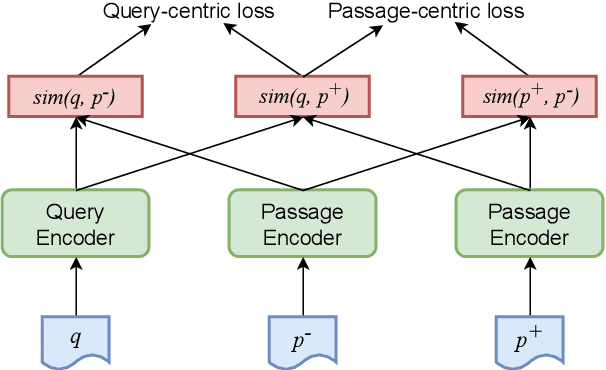
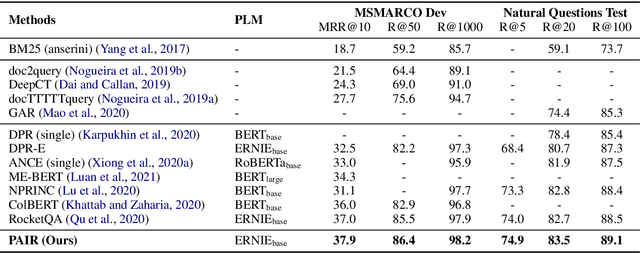
Recently, dense passage retrieval has become a mainstream approach to finding relevant information in various natural language processing tasks. A number of studies have been devoted to improving the widely adopted dual-encoder architecture. However, most of the previous studies only consider query-centric similarity relation when learning the dual-encoder retriever. In order to capture more comprehensive similarity relations, we propose a novel approach that leverages both query-centric and PAssage-centric sImilarity Relations (called PAIR) for dense passage retrieval. To implement our approach, we make three major technical contributions by introducing formal formulations of the two kinds of similarity relations, generating high-quality pseudo labeled data via knowledge distillation, and designing an effective two-stage training procedure that incorporates passage-centric similarity relation constraint. Extensive experiments show that our approach significantly outperforms previous state-of-the-art models on both MSMARCO and Natural Questions datasets.
Logician: A Unified End-to-End Neural Approach for Open-Domain Information Extraction
Apr 29, 2019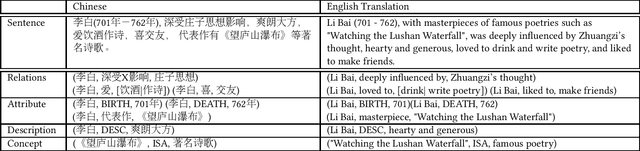
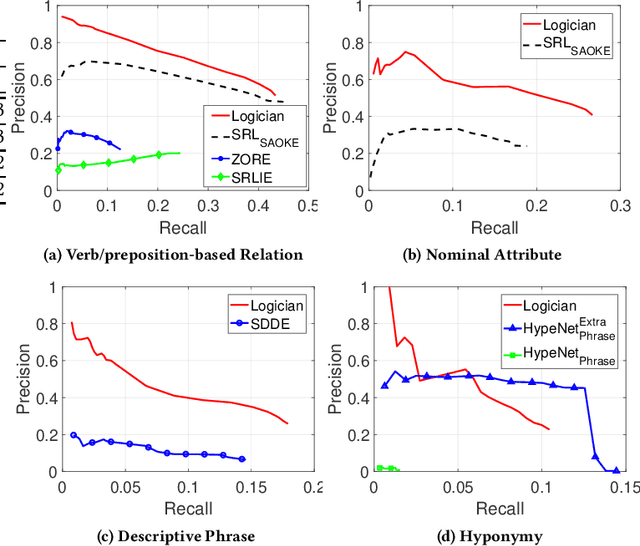
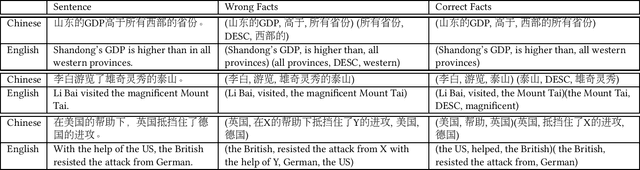

In this paper, we consider the problem of open information extraction (OIE) for extracting entity and relation level intermediate structures from sentences in open-domain. We focus on four types of valuable intermediate structures (Relation, Attribute, Description, and Concept), and propose a unified knowledge expression form, SAOKE, to express them. We publicly release a data set which contains more than forty thousand sentences and the corresponding facts in the SAOKE format labeled by crowd-sourcing. To our knowledge, this is the largest publicly available human labeled data set for open information extraction tasks. Using this labeled SAOKE data set, we train an end-to-end neural model using the sequenceto-sequence paradigm, called Logician, to transform sentences into facts. For each sentence, different to existing algorithms which generally focus on extracting each single fact without concerning other possible facts, Logician performs a global optimization over all possible involved facts, in which facts not only compete with each other to attract the attention of words, but also cooperate to share words. An experimental study on various types of open domain relation extraction tasks reveals the consistent superiority of Logician to other states-of-the-art algorithms. The experiments verify the reasonableness of SAOKE format, the valuableness of SAOKE data set, the effectiveness of the proposed Logician model, and the feasibility of the methodology to apply end-to-end learning paradigm on supervised data sets for the challenging tasks of open information extraction.
Ranking Biomarkers Through Mutual Information
Dec 05, 2016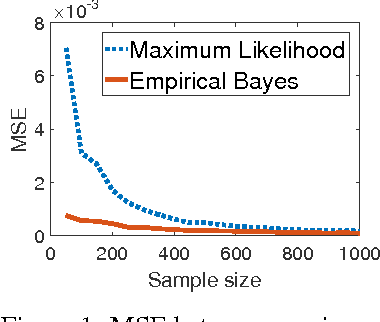
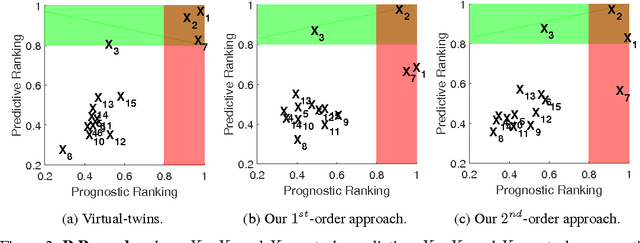
We study information theoretic methods for ranking biomarkers. In clinical trials there are two, closely related, types of biomarkers: predictive and prognostic, and disentangling them is a key challenge. Our first step is to phrase biomarker ranking in terms of optimizing an information theoretic quantity. This formalization of the problem will enable us to derive rankings of predictive/prognostic biomarkers, by estimating different, high dimensional, conditional mutual information terms. To estimate these terms, we suggest efficient low dimensional approximations, and we derive an empirical Bayes estimator, which is suitable for small or sparse datasets. Finally, we introduce a new visualisation tool that captures the prognostic and the predictive strength of a set of biomarkers. We believe this representation will prove to be a powerful tool in biomarker discovery.
Soft Hierarchical Graph Recurrent Networks for Many-Agent Partially Observable Environments
Sep 05, 2021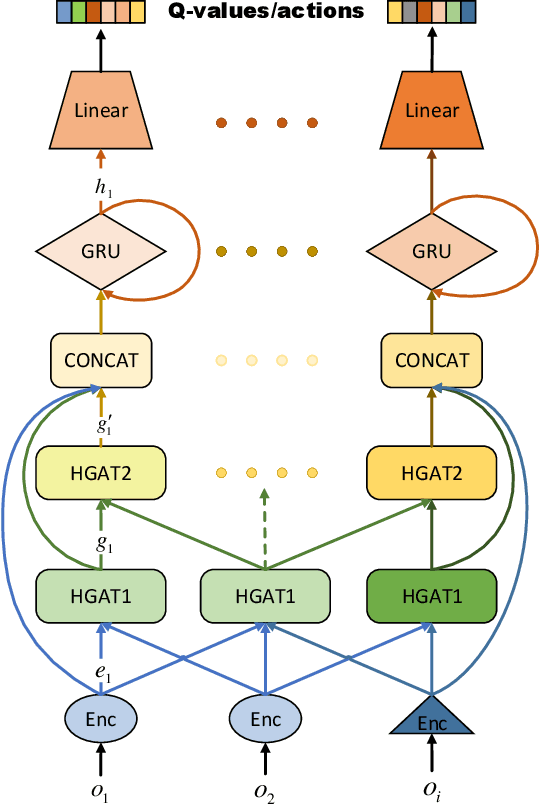
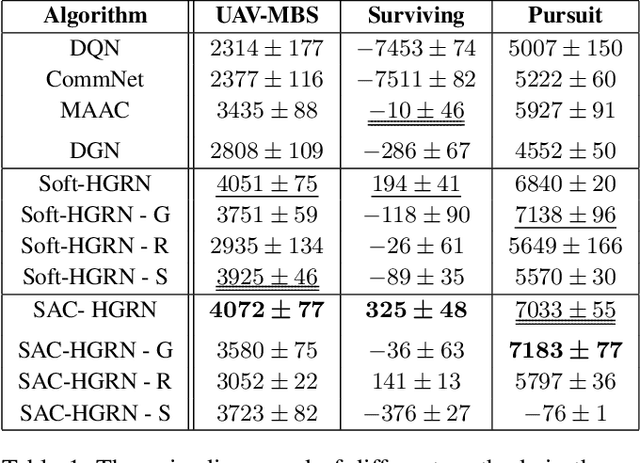
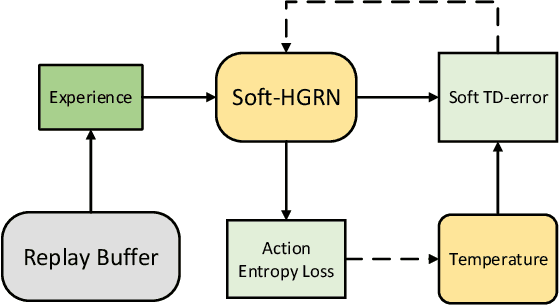
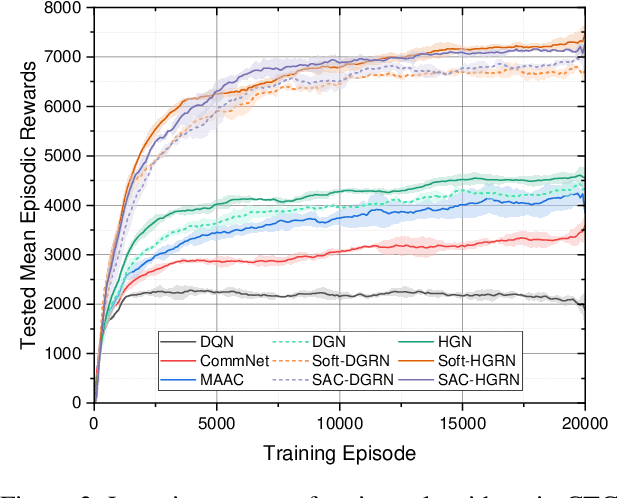
The recent progress in multi-agent deep reinforcement learning(MADRL) makes it more practical in real-world tasks, but its relatively poor scalability and the partially observable constraints raise challenges to its performance and deployment. Based on our intuitive observation that the human society could be regarded as a large-scale partially observable environment, where each individual has the function of communicating with neighbors and remembering its own experience, we propose a novel network structure called hierarchical graph recurrent network(HGRN) for multi-agent cooperation under partial observability. Specifically, we construct the multi-agent system as a graph, use the hierarchical graph attention network(HGAT) to achieve communication between neighboring agents, and exploit GRU to enable agents to record historical information. To encourage exploration and improve robustness, we design a maximum-entropy learning method to learn stochastic policies of a configurable target action entropy. Based on the above technologies, we proposed a value-based MADRL algorithm called Soft-HGRN and its actor-critic variant named SAC-HRGN. Experimental results based on three homogeneous tasks and one heterogeneous environment not only show that our approach achieves clear improvements compared with four baselines, but also demonstrates the interpretability, scalability, and transferability of the proposed model. Ablation studies prove the function and necessity of each component.
Jointly Multiple Events Extraction via Attention-based Graph Information Aggregation
Oct 23, 2018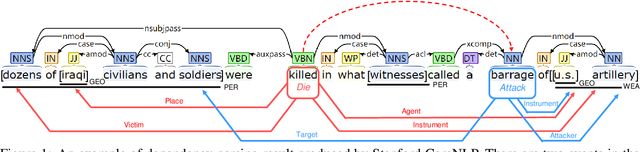
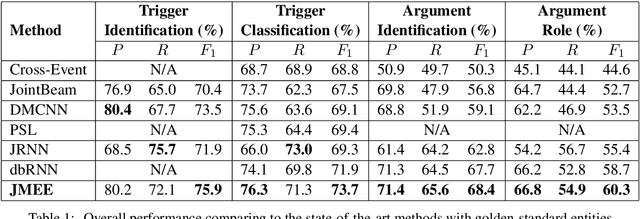
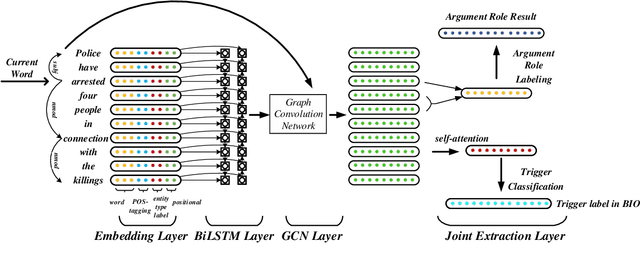
Event extraction is of practical utility in natural language processing. In the real world, it is a common phenomenon that multiple events existing in the same sentence, where extracting them are more difficult than extracting a single event. Previous works on modeling the associations between events by sequential modeling methods suffer a lot from the low efficiency in capturing very long-range dependencies. In this paper, we propose a novel Jointly Multiple Events Extraction (JMEE) framework to jointly extract multiple event triggers and arguments by introducing syntactic shortcut arcs to enhance information flow and attention-based graph convolution networks to model graph information. The experiment results demonstrate that our proposed framework achieves competitive results compared with state-of-the-art methods.
* accepted by EMNLP 2018
Voice Reconstruction from Silent Speech with a Sequence-to-Sequence Model
Jul 31, 2021
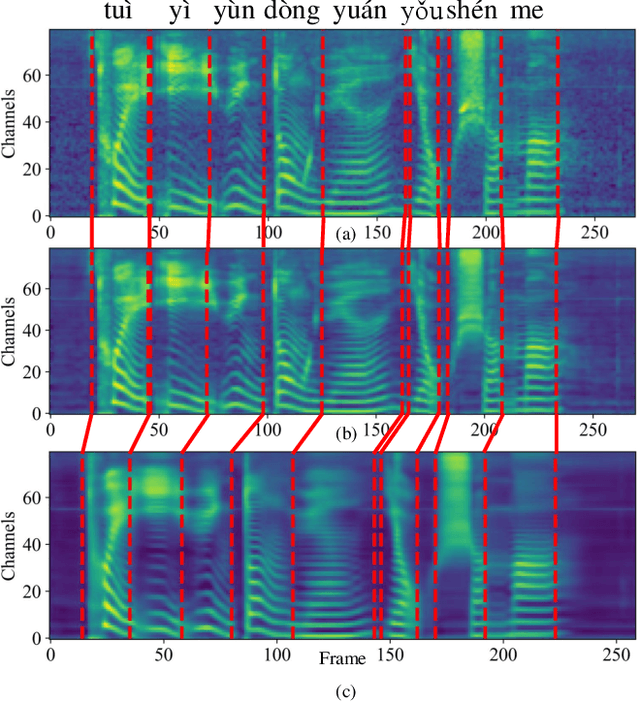
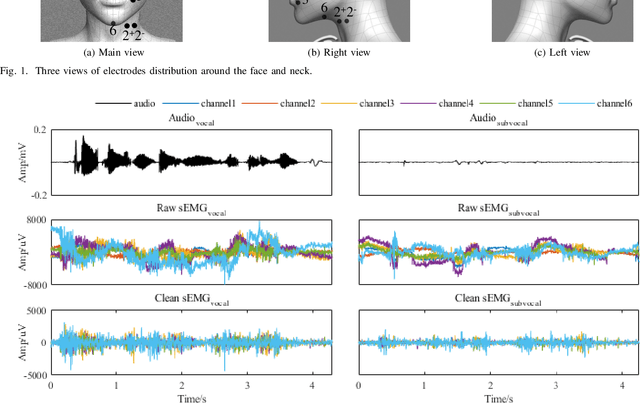
Silent Speech Decoding (SSD) based on Surface electromyography (sEMG) has become a prevalent task in recent years. Though revolutions have been proposed to decode sEMG to audio successfully, some problems still remain. In this paper, we propose an optimized sequence-to-sequence (Seq2Seq) approach to synthesize voice from subvocal sEMG. Both subvocal and vocal sEMG are collected and preprocessed to provide data information. Then, we extract durations from the alignment between subvocal and vocal signals to regulate the subvocal sEMG following audio length. Besides, we use phoneme classification and vocal sEMG reconstruction modules to improve the model performance. Finally, experiments on a Mandarin speaker dataset, which consists of 6.49 hours of data, demonstrate that the proposed model improves the mapping accuracy and voice quality of reconstructed voice.
A Multilingual Information Extraction Pipeline for Investigative Journalism
Sep 01, 2018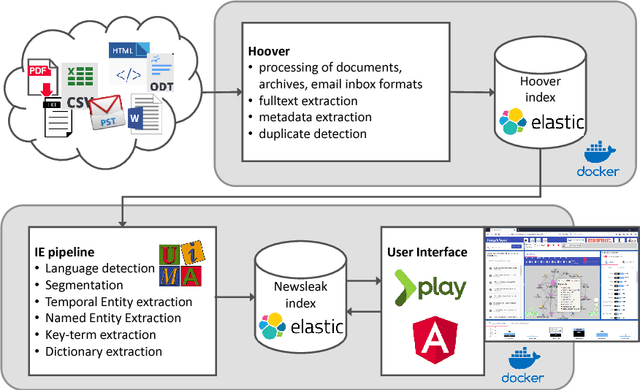
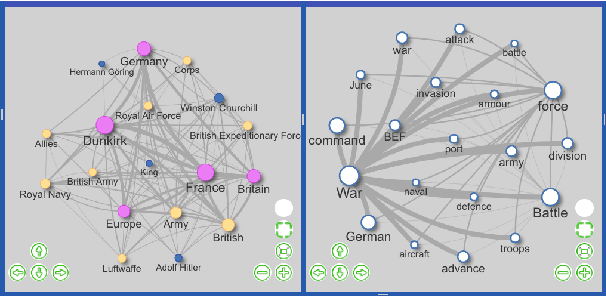
We introduce an advanced information extraction pipeline to automatically process very large collections of unstructured textual data for the purpose of investigative journalism. The pipeline serves as a new input processor for the upcoming major release of our New/s/leak 2.0 software, which we develop in cooperation with a large German news organization. The use case is that journalists receive a large collection of files up to several Gigabytes containing unknown contents. Collections may originate either from official disclosures of documents, e.g. Freedom of Information Act requests, or unofficial data leaks. Our software prepares a visually-aided exploration of the collection to quickly learn about potential stories contained in the data. It is based on the automatic extraction of entities and their co-occurrence in documents. In contrast to comparable projects, we focus on the following three major requirements particularly serving the use case of investigative journalism in cross-border collaborations: 1) composition of multiple state-of-the-art NLP tools for entity extraction, 2) support of multi-lingual document sets up to 40 languages, 3) fast and easy-to-use extraction of full-text, metadata and entities from various file formats.
Pose-Controllable Talking Face Generation by Implicitly Modularized Audio-Visual Representation
Apr 22, 2021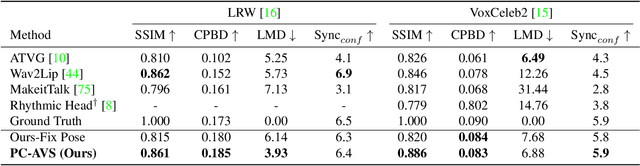
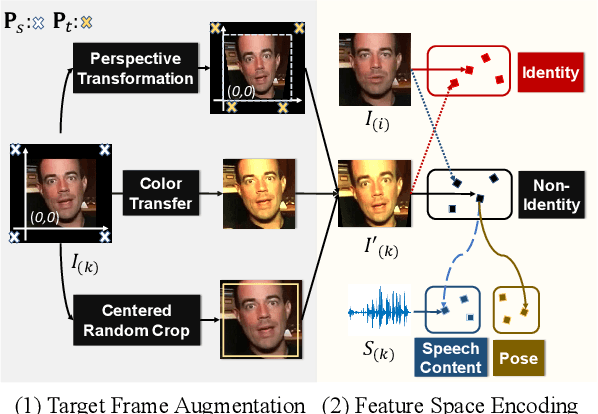

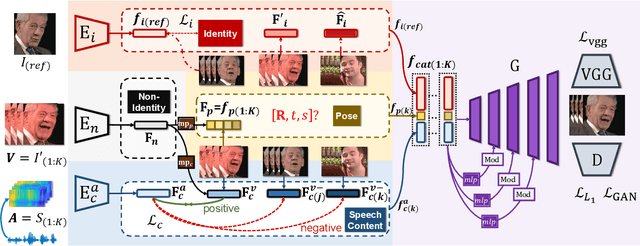
While accurate lip synchronization has been achieved for arbitrary-subject audio-driven talking face generation, the problem of how to efficiently drive the head pose remains. Previous methods rely on pre-estimated structural information such as landmarks and 3D parameters, aiming to generate personalized rhythmic movements. However, the inaccuracy of such estimated information under extreme conditions would lead to degradation problems. In this paper, we propose a clean yet effective framework to generate pose-controllable talking faces. We operate on raw face images, using only a single photo as an identity reference. The key is to modularize audio-visual representations by devising an implicit low-dimension pose code. Substantially, both speech content and head pose information lie in a joint non-identity embedding space. While speech content information can be defined by learning the intrinsic synchronization between audio-visual modalities, we identify that a pose code will be complementarily learned in a modulated convolution-based reconstruction framework. Extensive experiments show that our method generates accurately lip-synced talking faces whose poses are controllable by other videos. Moreover, our model has multiple advanced capabilities including extreme view robustness and talking face frontalization. Code, models, and demo videos are available at https://hangz-nju-cuhk.github.io/projects/PC-AVS.
Real-Time Multi-Level Neonatal Heart and Lung Sound Quality Assessment for Telehealth Applications
Sep 29, 2021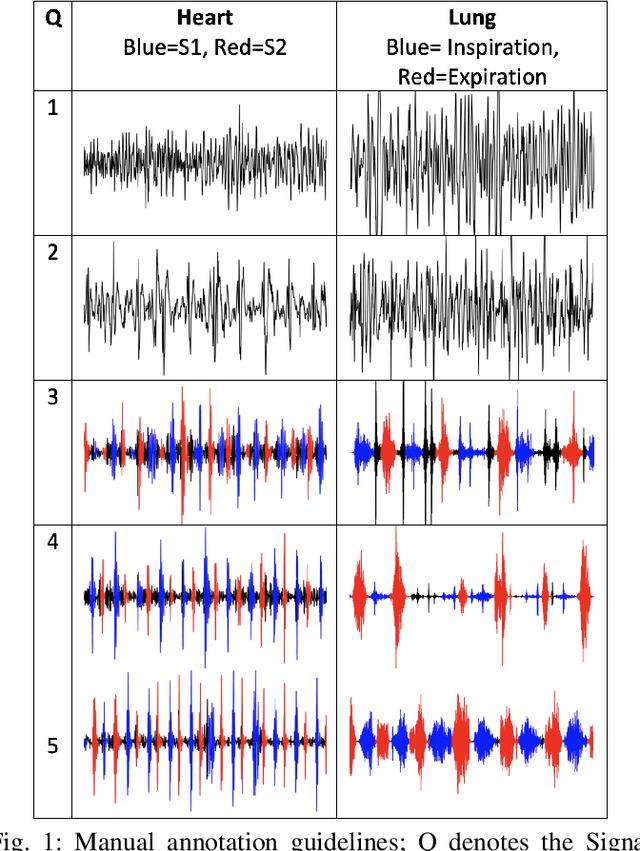
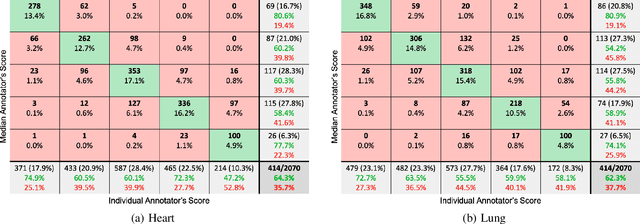
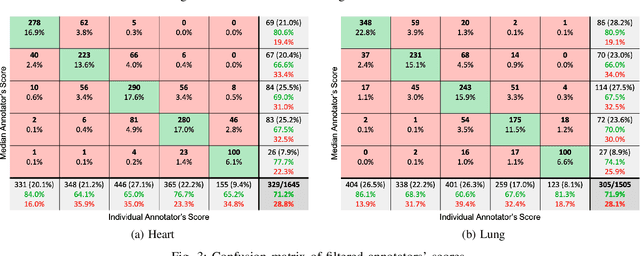
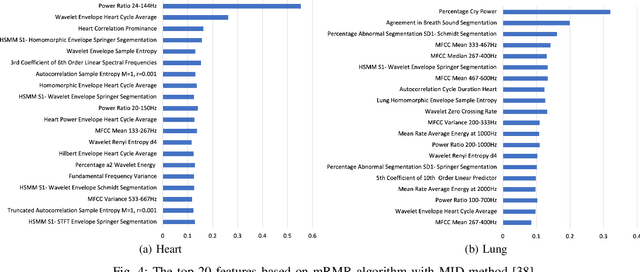
Digital stethoscopes in combination with telehealth allow chest sounds to be easily collected and transmitted for remote monitoring and diagnosis. Chest sounds contain important information about a newborn's cardio-respiratory health. However, low-quality recordings complicate the remote monitoring and diagnosis. In this study, a new method is proposed to objectively and automatically assess heart and lung signal quality on a 5-level scale in real-time and to assess the effect of signal quality on vital sign estimation. For the evaluation, a total of 207 10s long chest sounds were taken from 119 preterm and full-term babies. Thirty of the recordings from ten subjects were obtained with synchronous vital signs from the Neonatal Intensive Care Unit (NICU) based on electrocardiogram recordings. As reference, seven annotators independently assessed the signal quality. For automatic quality classification, 400 features were extracted from the chest sounds. After feature selection using minimum redundancy and maximum relevancy algorithm, class balancing, and hyper-parameter optimization, a variety of multi-class and ordinal classification and regression algorithms were trained. Then, heart rate and breathing rate were automatically estimated from the chest sounds using adapted pre-existing methods. The results of subject-wise leave-one-out cross-validation show that the best-performing models had a mean squared error (MSE) of 0.49 and 0.61, and balanced accuracy of 57% and 51% for heart and lung qualities, respectively. The best-performing models for real-time analysis (<200ms) had MSE of 0.459 and 0.67, and balanced accuracy of 57% and 46%, respectively. Our experimental results underscore that increasing the signal quality leads to a reduction in vital sign error, with only high-quality recordings having a mean absolute error of less than 5 beats per minute, as required for clinical usage.
Model Pruning Based on Quantified Similarity of Feature Maps
May 13, 2021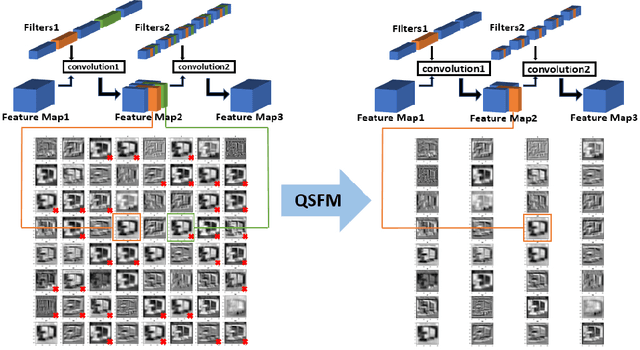

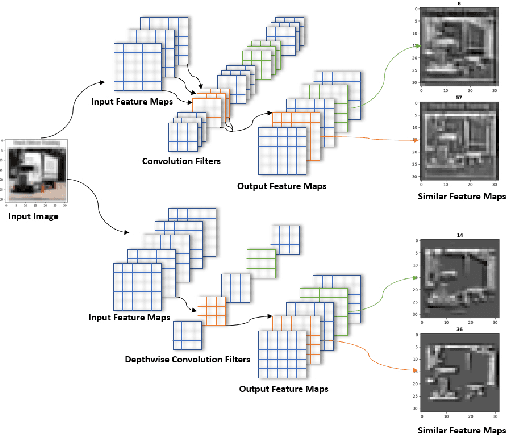
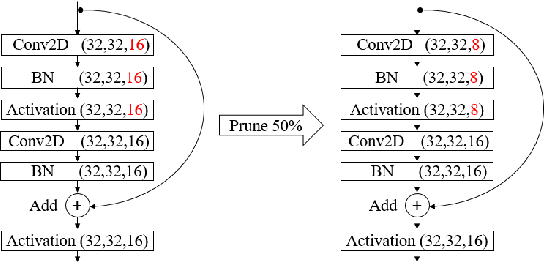
A high-accuracy CNN is often accompanied by huge parameters, which are usually stored in the high-dimensional tensors. However, there are few methods can figure out the redundant information of the parameters stored in the high-dimensional tensors, which leads to the lack of theoretical guidance for the compression of CNNs. In this paper, we propose a novel theory to find redundant information in three dimensional tensors, namely Quantified Similarity of Feature Maps (QSFM), and use this theory to prune convolutional neural networks to enhance the inference speed. Our method belongs to filter pruning, which can be implemented without using any special libraries. We perform our method not only on common convolution layers but also on special convolution layers, such as depthwise separable convolution layers. The experiments prove that QSFM can find the redundant information in the neural network effectively. Without any fine-tuning operation, QSFM can compress ResNet-56 on CIFAR-10 significantly (48.27% FLOPs and 57.90% parameters reduction) with only a loss of 0.54% in the top-1 accuracy. QSFM also prunes ResNet-56, VGG-16 and MobileNetV2 with fine-tuning operation, which also shows excellent results.